
A Robust Countermeasures for Poisoning Attacks on Deep Neural Networks of Computer Interaction Systems


Abstract
:1. Introduction
- This study proposes a Data Washing algorithm. It can recover the poisoned training dataset algorithm
- This study proposes Integrated Detection Algorithm (IDA) to resist the DNN poisoning attacks proposed in [6,7,10] and the Category Diverse attack proposed in the present study. the IDA algorithm provides an accurate means of detecting datasets containing abnormal data and thus provides effective protection against paralysis attacks, targeted attacks, and others.
2. Background and Related Works
2.1. Overview of Deep Learning
Deep Neural Networks (DNNs)
- VGG: A deep neural network with the front part of the network consisting of a cyclic arrangement of convolutional layers and pooling layers. This deep neural network exists in several variants, with different numbers of layers in each case. For instance, VGG16 owns 13 convolutional layers and three fully connected layers, and VGG19 has 16 convolutional layers and three fully connected layers.
- GoogLeNet: GoogLeNet is a deeper neural network, having not only additional convolutional and pooling layers, but also the incorporation of inception modules. In its standard form, GoogLeNet owns 27 layers, where these layers include nine inception modules.
- ResNet: ResNet inherits some of the features of AlexNet [14] and LeNett [15]. However, ResNet also incorporates additional residual blocks. In these blocks, the input is added to the output. Adding these residual modules makes ResNet possible to deepen the network, which can avoid the vanishing gradient problem. ResNet also owns several versions with different combinations of layers, including ResNet18, consisting of one convolutional layer, eight residual modules, and one fully connected layer.
2.2. Attacks on Machine Learning Models
2.2.1. Adversarial Example Attack
2.2.2. Poisoning Attacks
2.2.3. Backdoor Attacks
2.3. The discussion on Poisoning Attacks
2.3.1. Poisoning Attacks on Non-DNNs
- Poisoning Attacks against Support Vector Machines [21]
- Poisoning Attacks against Linear Regression Models [17]
- Poisoning Attacks against SVM, Linear Regression, and Logistic Regression Models [22]
2.3.2. Poisoning Attack on DNNs
- TensorClog [10]
- Feature Collisions [6]
- Convex Polytope Attack [7]
2.3.3. Effect Comparisons for Poisoning Attacks on Non-DNN and DNN Models
2.4. Countermeasures against Attacks on Network Models
2.4.1. Countermeasures against Adversarial Examples
2.4.2. Countermeasures against Poisoning Attacks
3. System Structure
3.1. System Assumptions
- The status (i.e., normal or poisoned) of the dataset input to the system is unknown. However, the labels of the dataset are well-confirmed, and hence, the attacker cannot launch label flipping attacks or randomly destroy the data for this dataset. Furthermore, the method used by the attacker to poison the dataset is ruled to be out of the scope of the present research.
- Model training is performed using frozen transfer learning with all of the layers frozen except for the last fully connected layer. It can greatly reduce the model training time.
- Four poisoning attacks are considered, namely, TensorClog, Feature Collisions, Convex Polytope, and a newly developed Category Diverse attack proposed in [33]. Note that the TensorClog and Category Diverse attacks are paralysis attacks, while the Feature Collisions and Convex Polytope attacks are target attacks.
3.2. Robust Denoising Algorithm and IDA Detection Algorithm
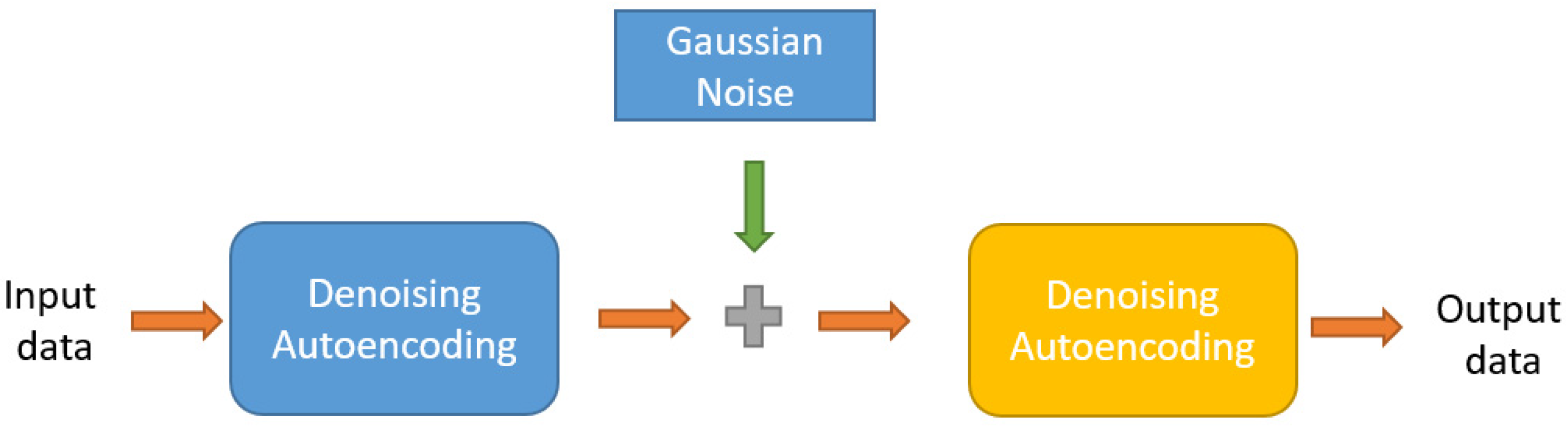
3.2.1. Data Washing Algorithm
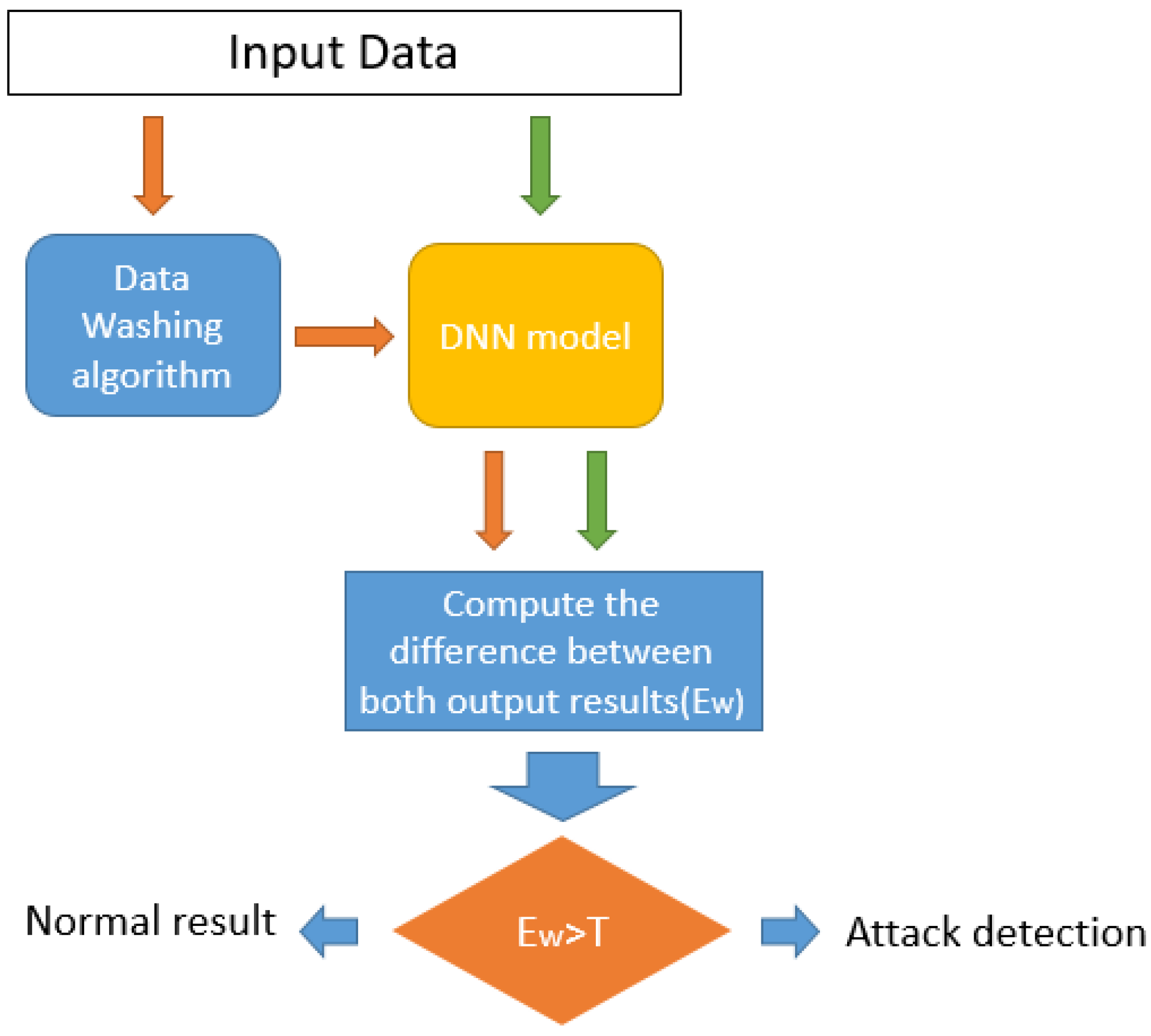
3.2.2. IDA Detection Algorithm
4. Experimental Results
4.1. Data Washing Algorithm
4.1.1. Effectiveness of Data Washing Algorithm against Paralysis Attacks
4.1.2. Effectiveness of Data Washing Algorithm against Target Attacks
4.2. Integrated Detection Algorithm
4.2.1. Effectiveness of IDA Detection Algorithm against Paralysis Attacks
4.2.2. Effectiveness of IDA Detection Algorithm against Target Attacks
4.2.3. Effectiveness of IDA Detection Algorithm against Other Attacks
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goldblum, M.; Tsipras, D.; Xie, C.; Chen, X.; Schwarzschild, A.; Song, D.; Madry, A.; Li, B.; Goldstein, T. Dataset Security for Machine Learning: Data Poisoning, Backdoor Attacks, and Defenses. IEEE Trans. Pattern Anal. Mach. Intell. 2022; in press. [Google Scholar] [CrossRef] [PubMed]
- Sun, G.; Cong, Y.; Dong, J.; Wang, Q.; Lyu, L.; Liu, J. Data Poisoning Attacks on Federated Machine Learning. IEEE Internet Things J. 2022, 9, 11365–11375. [Google Scholar] [CrossRef]
- Shen, S.; Tople, S.; Saxena, P. Auror: Defending against poisoning attacks in collaborative deep learning systems. In Proceedings of the 32nd Annual Conference on Computer Security Applications, Los Angeles, CA, USA, 5–9 December 2016. [Google Scholar]
- Ilahi, I.; Usama, M.; Qadir, J.; Janjua, M.U.; Al-Fuqaha, A.; Hoang, D.T.; Niyato, D. Challenges and Countermeasures for Adversarial Attacks on Deep Reinforcement Learning. IEEE Trans. Artif. Intell. 2022, 3, 90–109. [Google Scholar] [CrossRef]
- Mozaffari-Kermani, M.; Sur-Kolay, S.; Raghunathan, A.; Jha, N.K. Systematic poisoning attacks on and defenses for machine learning in healthcare. IEEE J. Biomed. Health Inform. 2014, 19, 1893–1905. [Google Scholar] [CrossRef] [PubMed]
- Shafahi, A.; Huang, W.R.; Najibi, M.; Suciu, O.; Studer, C.; Dumitras, T.; Goldstein, T. Poison frogs! targeted clean-label poisoning attacks on neural networks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Zhu, C.; Huang, W.R.; Li, H.; Taylor, G.; Studer, C.; Goldstein, T. Transferable Clean-Label Poisoning Attacks on Deep Neural Nets. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Chen, X.; Liu, C.; Li, B.; Lu, K.; Song, D. Targeted backdoor attacks on deep learning systems using data poisoning. arXiv 2017. [Google Scholar] [CrossRef]
- Subedar, M.; Ahuja, N.; Krishnan, R.; Ndiour, I.J.; Tickoo, O. Deep Probabilistic Models to Detect Data Poisoning. In Proceedings of the Fourth Workshop on Bayesian Deep Learning (NeurIPS 2019), Vancouver, BC, Canada, 13 December 2019. [Google Scholar]
- Shen, J.; Zhu, X.; Ma, D. TensorClog: An Imperceptible Poisoning Attack on Deep Neural Network Application. IEEE Access 2019, 7, 41498–41506. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erha, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2015. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–8 December 2012. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Xiao, H.; Biggio, B.; Brown, G.; Fumera, G.; Eckert, C.; Roli, F. Is feature selection secure against training data poisoning? In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Jagielski, M.; Oprea, A.; Biggio, B.; Liu, C.; Nita-Rotaru, C.; Li, B. Manipulating machine learning: Poisoning attacks and countermeasures for regression learning. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Frossard, P. DeepFool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning attacks against support vector machines. In Proceedings of the International Conference on Machine Learning, Edinburgh, UK, 26 June–1 July 2012. [Google Scholar]
- Mei, S.; Zhu, X. Using machine teaching to identify optimal training-set attacks on machine learners. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–29 January 2015. [Google Scholar]
- Muñoz-González, L.; Biggio, B.; Demontis, A.; Paudice, A.; Wongrassamee, V.; Lupu, E.C.; Roli, F. Towards poisoning of deep learning algorithms with back-gradient optimization. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017. [Google Scholar]
- Hearst, M.A. Support vector machines. IEEE Intell. Syst. Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Wu, Q.; Li, H.; Chen, Y. Generative poisoning attack method against neural networks. arXiv 2017. [Google Scholar] [CrossRef]
- Yuan, X.; He, P.; Zhu, Q.; Li, X. Adversarial Examples: Attacks and Defenses for Deep Learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2805–2824. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 23–25 May 2016. [Google Scholar]
- Metzen, J.H.; Genewein, T.; Fischer, V.; Bischoff, B. On detecting adversarial perturbations. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. Pixeldefend: Leveraging generative models to understand and defend against adversarial examples. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gu, S.; Rigazio, L. Towards deep neural network architectures robust to adversarial examples. In Proceedings of the International Conference on Learning Representations Workshop, San Diego, CA, USA, 8 May 2015. [Google Scholar]
- Meng, D.; Chen, H. Magnet: A two-pronged defense against adversarial examples. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 3 October–3 November 2017. [Google Scholar]
- Steinhardt, J.; Koh, P.W.; Liang, P. Certified defenses for data poisoning attacks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Li, J.-S.; Peng, Y.-C.; Liu, I.-H.; Liu, C.-G. A New Poisoning Attacks on Deep Neural Networks. In Proceedings of the ICMHI 2022, Kyoto, Japan, 13–15 May 2022. [Google Scholar]
- Tensorflow. Available online: https://www.tensorflow.org/ (accessed on 5 August 2020).
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.-A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 8 April 2009. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Kinds of Attacks | Adversarial Example Attack | Poisoning Attacks | Backdoor Attacks |
|---|---|---|---|
| Attack target | The test dataset | The training dataset | The test dataset |
| Algorithm | Original | TensorClog | Category Diverse | |
|---|---|---|---|---|
| Statistic | ||||
| Accuracy | 0.8316 | 0.6166 | 0.1660 | |
| Accuracy after DW | 0.8178 | 0.7446 | 0.7044 | |
| Accuracy increment | −0.0138 | 0.1280 | 0.5384 | |
| Algorithm | Original | TensorClog | Category Diverse | |
|---|---|---|---|---|
| Statistic | ||||
| Accuracy after DW | 0.8178 | 0.7446 | 0.7044 | |
| Accuracy after DAE | 0.8270 | 0.6936 | 0.5372 | |
| Accuracy increment | −0.0092 | 0.0510 | 0.1672 | |
| Algorithm | FC Attack [6] ImageNet [37] | FC Attack [6] Cifar10 [36] | CP Attack [7] Cifar10 [36] | |
|---|---|---|---|---|
| Statistic | ||||
| Accuracy | 98.00% | 99.50% | 93.34% | |
| Target Number | 100 | 200 | 10 | |
| Misclassified | 98 | 185 | 9 | |
| Target’s False Positive Rate | 98.00% | 92.50% | 90% | |
| Algorithm | FC Attack [6] ImageNet [37] | FC Attack [6] Cifar10 [36] | CP Attack [7] Cifar10 [36] | |
|---|---|---|---|---|
| Statistic | ||||
| Accuracy | 99.00% | 100% | 93.33% | |
| Target Number | 100 | 200 | 10 | |
| Misclassified | 1 | 0 | 0 | |
| Target’s False Positive Rate | 1.00% | 0.00% | 0.00% | |
| Algorithm | TensorClog Clip 0.05 | Category Diverse Clip 0.05 | TensorClog Clip 0.1 | Category Diverse Clip 0.1 | |
|---|---|---|---|---|---|
| Statistic | |||||
| Accuracy Increment | 0.0266 | 0.1990 | 0.0748 | 0.3690 | |
| Algorithm | Original ImageNet | FC Attack ImageNet | Original Cifar10 | FC Attack Cifar10 | |
|---|---|---|---|---|---|
| L2-Norm | |||||
| Mean | 18.2909 | 2.9688 | 19.3545 | 3.6706 | |
| Standard deviation | 2.6572 | 0.2671 | 2.7426 | 0.5807 | |
| Algorithm | FC Attack ImageNet | FC Attack Cifar10 | |
|---|---|---|---|
| Statistic | |||
| Accuracy | 0.9991 | 0.9970 | |
| Precision | 0.9901 | 1.0000 | |
| Recall | 1.0000 | 0.9700 | |
| F1 Score | 0.9950 | 0.9848 | |
| Algorithm | Original Cifar10 | CP Attack Cifar10 | 0.1 Gaussian Cifar10 | |
|---|---|---|---|---|
| Statistic | ||||
| Mean | 1.0319 | 2.9455 | 4.4168 | |
| Standard deviation | 0.0485 | 0.0132 | 0.1720 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, I.-H.; Li, J.-S.; Peng, Y.-C.; Liu, C.-G. A Robust Countermeasures for Poisoning Attacks on Deep Neural Networks of Computer Interaction Systems. Appl. Sci. 2022, 12, 7753. https://doi.org/10.3390/app12157753
Liu I-H, Li J-S, Peng Y-C, Liu C-G. A Robust Countermeasures for Poisoning Attacks on Deep Neural Networks of Computer Interaction Systems. Applied Sciences. 2022; 12(15):7753. https://doi.org/10.3390/app12157753
Chicago/Turabian StyleLiu, I-Hsien, Jung-Shian Li, Yen-Chu Peng, and Chuan-Gang Liu. 2022. "A Robust Countermeasures for Poisoning Attacks on Deep Neural Networks of Computer Interaction Systems" Applied Sciences 12, no. 15: 7753. https://doi.org/10.3390/app12157753
APA StyleLiu, I. -H., Li, J. -S., Peng, Y. -C., & Liu, C. -G. (2022). A Robust Countermeasures for Poisoning Attacks on Deep Neural Networks of Computer Interaction Systems. Applied Sciences, 12(15), 7753. https://doi.org/10.3390/app12157753