
Prediction of Temperature and Carbon Concentration in Oxygen Steelmaking by Machine Learning: A Comparative Study





Abstract
:Featured Application
Abstract
1. Introduction
1.1. Presented Research Area in the Literature Review
1.2. Understanding of Steelmaking in LD Converter
2. Theoretical Background of Applied Method
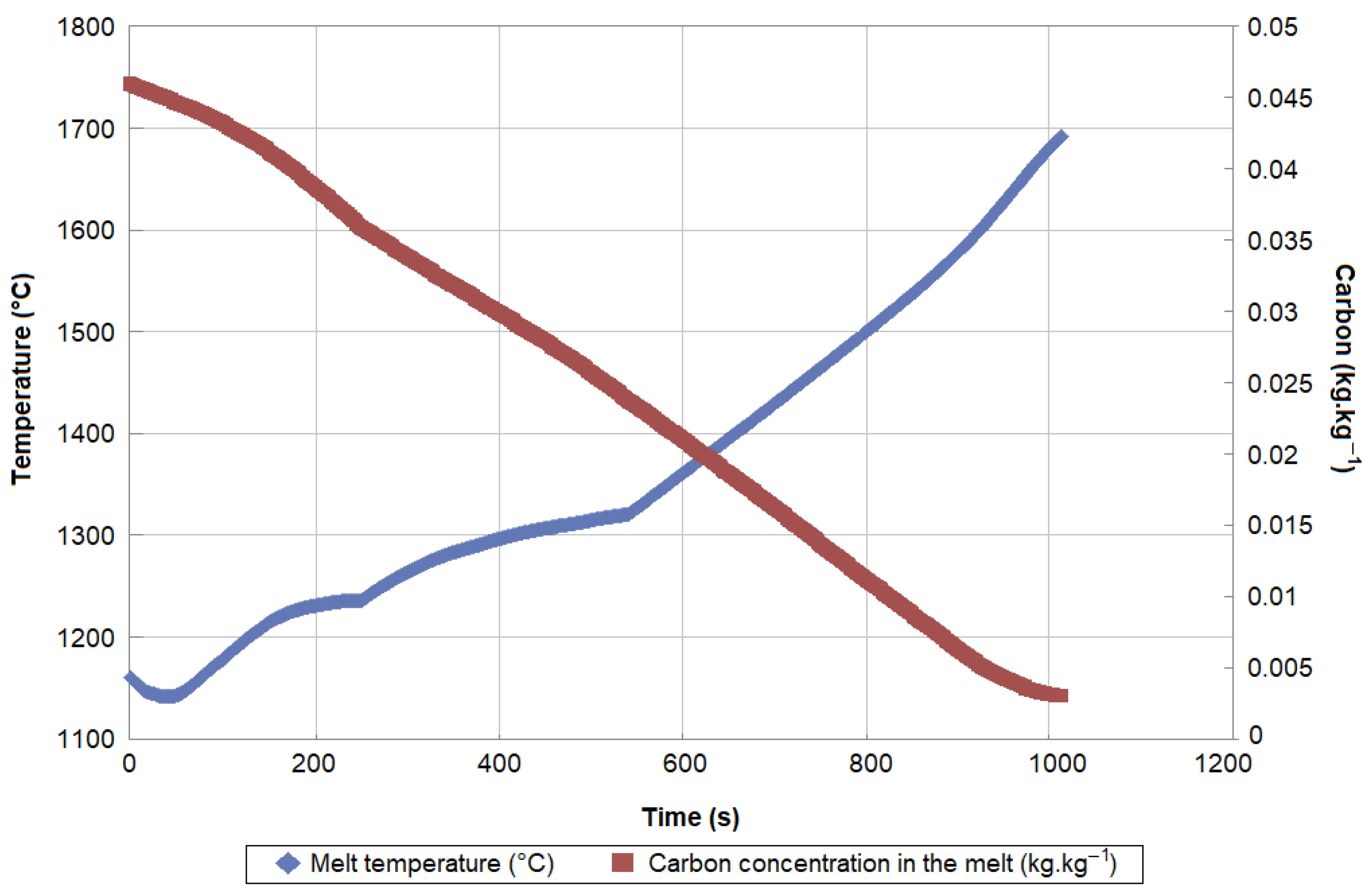
2.1. Observations and Targets in BOS
2.2. Multivariate Adaptive Regression Splines
2.3. Support-Vector Regression
- Gaussian kernel:where represents the kernel parameter, which controls the kernel function’s sensitivity.
- Polynomial kernel:where d is an integer.
2.4. Feed-Forward Neural Networks
2.5. k-Nearest Neighbors
2.6. Random Forest
- Sample, with replacement, n training examples from , ; call these , .
- Train a classification or regression tree on , .
2.7. Advantages and Disadvantages of Machine Learning Methods
2.8. Model Performance Indicators
- Coefficient of correlation ()—This coefficient expresses the force of the linear relationship (i.e., degree of dependence) between two variables. The range of this coefficient is (−1,1), and its formula is as follows:where and are average values of y and Y.
- Coefficient of determination ()—Expresses the degree of causal dependence of two variables. The coefficient gives information about the level of tightness, and the goodness of fit of the model, respectively (e.g., = 1 indicates that the model perfectly fits the measured target data, and < 1 corresponds to lower tightness between y and Y). The following formula can calculate the coefficient of determination :
- Root-mean-squared error (RMSE)—Represents the square root of mean square error (MSE). The value of RMSE may vary from 0 to positive infinity. The smaller MSE or RMSE, the better the model performance. The calculation formula is as follows:
- Relative root-mean-squared error (RRMSE)—Expresses RMSE divided by the average of measured value . The value of RRMSE may vary from 0 to positive infinity. The smaller RRMSE, the better the model performance. The formula to calculate RRMSE is as follows:
- Mean absolute percentage error (MAPE)—This error indicates how accurate a prediction method is. The MAPE expresses this accuracy in a percentage. If values of are very low, then MAPE can exceed 100% extremely. Otherwise, if values are very high (i.e., above ), MAPE will not exceed 100%. Therefore, the MAPE can be calculated according to the following formula:
- The absolute error is the difference between the measured value of the process variable y and the calculated value by the model Y. For example, the following equation can express the absolute error:The value of the absolute error is given unsigned in the evaluations, always as a positive number.
- The relative error is the ratio of the absolute error to the actual value of the process variable y. The relative error is usually expressed in percentages and can be expressed by the following equation:
3. Simulation Results
3.1. Prediction Based on Static Data
3.2. Prediction Based on Dynamic Data
4. Discussion of Results
5. Conclusions
- The speed of learning depends on the complexity of the algorithms of individual machine learning methods.
- The k-NN method proved to be the fastest machine learning method for BOS modeling from static and combined static and dynamic data.
- The RF method proved to be the slowest in training in all machine models.
- The MARS method was shown to be the most powerful machine learning method for predicting endpoint temperature and carbon based on static data. This method best approximated nonlinearities between static variables.
- In general, the prediction of melt carbon concentration from static data is less powerful than the prediction of melt temperature from static data.
- It was found that changing the number of input observations affects the performance of machine models in the testing phase, so it is necessary to look for the optimal number of relevant observations so that the prediction performance from static data does not decrease.
- In the case of observation number increases in lime and dolomitic lime, most models increased performance in training.
- It was found that changing the number of input observations in the case of prediction from dynamic data can change the model’s accuracy. The model’s accuracy, in addition to the algorithm, depends on the user inputs and their significance. For example, adding some insignificant observations may reduce the accuracy of the prediction.
- In case of temperature prediction from static data and observation number increase, only SVR with Gaussian kernel, NN, and piecewise-linear MARS model increased prediction performance in testing. In the case of carbon prediction from the static data and observation number increase, only SVR with a Gaussian kernel, NN, and the piecewise-linear MARS model improved prediction performance in testing.
- The prediction results from the dynamic observations of the BOS process using machine models showed an improvement in carbon prediction compared to the prediction from static data only.
- Predictions from dynamic melting observations make it possible to simulate the entire dynamic course of the target quantity.
- In terms of quality, dynamic behavior was best simulated by SVR, MARS, and k-NN-based models.
- The piecewise-linear MARS model proved to be the most accurate in predicting temperature, and the k-NN model was the most accurate in predicting carbon at the endpoint of melting from dynamic data.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fortuna, L.; Graziani, S.; Rizzo, A.; Xibilia, G.M. Soft Sensors for Monitoring and Control of Industrial Processes; Springer: London, UK, 2007; p. 271. [Google Scholar] [CrossRef]
- Hubmer, R.; Kühböck, H.; Pastucha, K. Latest Innovations in Converter Process Modelling. In Proceedings of the Metec ε, 2nd Estat, Dusseldorf, Germany, 25 June 2015; pp. 1–7. [Google Scholar]
- Weeks, R. Dynamic Model of the BOS Process, Mathematical Process Models in Iron and Steel Making; The Metals Society: Amsterdam, The Netherlands, 1973; pp. 103–116. [Google Scholar]
- Laciak, M.; Petráš, I.; Terpák, J.; Kačur, J.; Flegner, P.; Durdán, M.; Tréfa, G. Výskum Nepriameho Merania Teploty a Uhlíka v Procese Skujňovania. (Zmluva o Dielo č. P-101-0030/17) (en: Research on Indirect Measurement of Temperature and Carbon in the Process of Steelmaking (Contract for Work No. P-101-0030/17)); Technical Report 2018; Technical University of Košice, Faculty BERG, Institute of Control and Informatization of Production Processes: Košice, Slovakia, 2018. [Google Scholar]
- Laciak, M.; Kačur, J.; Flegner, P.; Terpák, J.; Durdán, M.; Tréfa, G. The Mathematical Model for Indirect Measurement of Temperature in the Steel-Making Process. In Proceedings of the 2020 21th International Carpathian Control Conference (ICCC), Kosice, Slovakia, 27–29 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Laciak, M.; Kačur, J.; Terpák, J.; Durdán, M.; Flegner, P. Comparison of Different Approaches to the Creation of a Mathematical Model of Melt Temperature in an LD Converter. Processes 2022, 10, 1378. [Google Scholar] [CrossRef]
- Wu, L.; Yang, N.; You, X.; Xing, K.; Hu, Y. A Temperature Prediction Model of Converters Based on Gas Analysis. Proc. Earth Planet. Sci. 2011, 2, 14–19. [Google Scholar] [CrossRef] [Green Version]
- Sarkar, R.; Gupta, P.; Basu, S.; Ballal, N.B. Dynamic Modeling of LD Converter Steelmaking: Reaction Modeling Using Gibbs’ Free Energy Minimization. Metall. Mater. Trans. B 2015, 46, 961–976. [Google Scholar] [CrossRef]
- Terpák, J.; Laciak, M.; Kačur, J.; Durdán, M.; Flegner, P.; Trefa, G. Endpoint Prediction of Basic Oxygen Furnace Steelmaking Based on Gradient of Relative Decarburization Rate. In Proceedings of the 2020 21th International Carpathian Control Conference (ICCC), Ostrava, Czech Republic, 27–29 October 2020. [Google Scholar] [CrossRef]
- Kumari, V. Mathematical Modeling of Basic Oxygen Steel Making Process; National Institute of Technology: Rourkela, India, 2015. [Google Scholar]
- Wang, X.; Xing, J.; Dong, J.; Wang, Z. Data driven based endpoint carbon content real time prediction for BOF steelmaking. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017. [Google Scholar] [CrossRef]
- Terpák, J.; Flegner, P.; Kačur, J.; Laciak, M.; Durdán, M.; Trefa, G. Utilization of the Mathematical Model of the Converter Process for the Sensitivity Analysis. In Proceedings of the 2019 20th International Carpathian Control Conference (ICCC), Krakow, Poland, 26–29 May 2019. [Google Scholar] [CrossRef]
- Asai, S.; Muchi, I. Theoretical Analysis by the Use of Mathematical Model in LD Converter Operation. Trans. Iron Steel Inst. Jpn. 1970, 10, 250–263. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Chai, T. Prediction of BOF Endpoint Temperature and Carbon Content. IFAC Proc. Vol. 1999, 32, 7039–7043. [Google Scholar] [CrossRef]
- Kostúr, K.; Laciak, M.; Truchlý, M. Systémy Nepriameho Merania (en: Systems of Indirect Measurement), 1st. ed.; Monograph; Reprocentrum: Košice, Slovakia, 2005; p. 172. [Google Scholar]
- Huang, W.; Liu, Y.; Dong, Z.; Yang, B. The Regression Equation of Oxygen Content and Temperature to End Point of Bath Based on Exhaust Gas Analysis. In Proceedings of the 2015 International Conference on Automation, Mechanical Control and Computational Engineering, Changsha, China, 24–25 October 2015. [Google Scholar] [CrossRef] [Green Version]
- Bouhouche, S.; Mentouri, Z.; Meradi, H.; Yazid, L. Combined Use of Support Vector Regression and Monte Carlo Simulation in Quality and Process Control Calibration. In Proceedings of the 2012 International Conference on Industrial Engineering and Operations Management, Istanbul, Turkey, 3–6 July 2012; pp. 2156–2165. [Google Scholar]
- Schlüter, J.; Odenthal, H.J.; Uebber, N.; Blom, H.; Morik, K. A novel data-driven prediction model for BOF endpoint. In Proceedings of the Association for Iron & Steel Technology Conference, Pittsburgh, PA, USA, 6–9 May 2013; pp. 1–6. [Google Scholar]
- Schlüter, J.; Uebber, N.; Odenthal, H.J.; Blom, H.; Beckers, T.; Morik, K. Reliable BOF endpoint prediction by novel data-driven modeling. In Proceedings of the Association for Iron & Steel Technology Conference, AISTech 2014 Proceedings, Pittsburgh, PA, USA, 16–18 May 2014; pp. 1159–1165. [Google Scholar]
- Duan, J.; Qu, Q.; Gao, C.; Chen, X. BOF steelmaking endpoint prediction based on FWA-TSVR. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 4507–4511. [Google Scholar] [CrossRef]
- Gao, C.; Shen, M.; Liu, X.; Wang, L.; Chu, M. End-Point Static Control of Basic Oxygen Furnace (BOF) Steelmaking Based on Wavelet Transform Weighted Twin Support Vector Regression. Complexity 2019, 2019, 7408725. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Wang, X.; Wang, X.; Wang, H. Endpoint Prediction of BOF Steelmaking based on BP Neural Network Combined with Improved PSO. Chem. Eng. Trans. 2016, 51, 475–480. [Google Scholar] [CrossRef]
- Cai, B.Y.; Zhao, H.; Yue, Y.J. Research on the BOF steelmaking endpoint temperature prediction. In Proceedings of the 2011 International Conference on Mechatronic Science, Electric Engineering and Computer (MEC), Jilin, China, 19–22 August 2011. [Google Scholar] [CrossRef]
- Han, M.; Liu, C. Endpoint prediction model for basic oxygen furnace steel-making based on membrane algorithm evolving extreme learning machine. Appl. Soft Comput. 2014, 19, 430–437. [Google Scholar] [CrossRef]
- Park, T.C.; Kim, B.S.; Kim, T.Y.; Jin, I.B.; Yeo, Y.K. Comparative Study of Estimation Methods of the Endpoint Temperature in Basic Oxygen Furnace Steelmaking Process with Selection of Input Parameters. Kor. J. Met. Mater. 2018, 56, 813–821. [Google Scholar] [CrossRef]
- Yue, Y.J.; Yao, Y.D.; Zhao, H.; Wang, H.J. BOF Endpoint Prediction Based on Multi-Neural Network Model. Appl. Mech. Mater. 2013, 441, 666–669. [Google Scholar] [CrossRef]
- Rajesh, N.; Khare, M.R.; Pabi, S.K. Feed forward neural network for prediction of end blow oxygen in LD converter steel making. Mater. Res. 2010, 13, 15–19. [Google Scholar] [CrossRef] [Green Version]
- Fileti, A.F.; Pacianotto, T.; Cunha, A.P. Neural modeling helps the BOS process to achieve aimed end-point conditions in liquid steel. Eng. Appl. Artif. Intell. 2006, 19, 9–17. [Google Scholar] [CrossRef]
- Jun, T.; Xin, W.; Tianyou, C.; Shuming, X. Intelligent Control Method and Application for BOF Steelmaking Process. IFAC Proc. Vol. 2002, 35, 439–444. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Han, M. Greedy Kernel Components Acting on ANFIS to Predict BOF Steelmaking Endpoint. IFAC Proc. Vol. 2008, 41, 11007–11012. [Google Scholar] [CrossRef] [Green Version]
- Han, M.; Cao, Z. An improved case-based reasoning method and its application in endpoint prediction of basic oxygen furnace. Neurocomputing 2015, 149, 1245–1252. [Google Scholar] [CrossRef]
- Ruuska, J.; Ollila, S.; Leiviskä, K. Temperature Model for LD-KG Converter. IFAC Proc. Vol. 2003, 36, 71–76. [Google Scholar] [CrossRef]
- Hu, Y.; Zheng, Z.; Yang, J. Application of Data Mining in BOF Steelmaking Endpoint Control. Adv. Mater. Res. 2011, 402, 96–99. [Google Scholar] [CrossRef]
- Sala, D.A.; Jalalvand, A.; Deyne, A.Y.D.; Mannens, E. Multivariate Time Series for Data-Driven Endpoint Prediction in the Basic Oxygen Furnace. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018. [Google Scholar] [CrossRef] [Green Version]
- Akundi, A.; Euresti, D.; Luna, S.; Ankobiah, W.; Lopes, A.; Edinbarough, I. State of Industry 5.0—Analysis and Identification of Current Research Trends. Appl. Syst. Innov. 2022, 5, 27. [Google Scholar] [CrossRef]
- Wang, X. Made in China 2025: Industrial country from great to powerful. Internet Things Technol. 2015, 5, 3–4. [Google Scholar] [CrossRef]
- Ma, H.; Huang, X.; Cui, X.; Wang, P.; Chen, Y.; Hu, Z.; Hua, L. Management Control and Integration Technology of Intelligent Production Line for Multi-Variety and Complex Aerospace Ring Forgings: A Review. Metals 2022, 12, 1079. [Google Scholar] [CrossRef]
- Beliatis, M.; Jensen, K.; Ellegaard, L.; Aagaard, A.; Presser, M. Next Generation Industrial IoT Digitalization for Traceability in Metal Manufacturing Industry: A Case Study of Industry 4.0. Electronics 2021, 10, 628. [Google Scholar] [CrossRef]
- Grabowska, S.; Saniuk, S.; Gajdzik, B. Industry 5.0: Improving humanization and sustainability of Industry 4.0. Scientometrics 2022, 127, 3117–3144. [Google Scholar] [CrossRef] [PubMed]
- Pehlke, R.D. An Overview of Contemporary Steelmaking Processes. JOM 1982, 34, 56–64. [Google Scholar] [CrossRef]
- Oeters, F. Metallurgy of Steelmaking; Verlag Stahleisen mbH: Dusseldoff, Germany, 1994; p. 512. [Google Scholar]
- Ban, T.E. Basic Oxygen Steel Making Process. U.S. Patent No. 3,301,662, 31 January 1967. [Google Scholar]
- Ghosh, A.; Chatterjee, A. Ironmaking and Steelmaking, Theory and Practice; PHI Learning, Private Limited: New Delhi, India, 2008; p. 494. [Google Scholar]
- Takemura, Y.; Saito, T.; Fukuda, S.; Kato, K. BOF Dynamic Control Using Sublance System; Nippon Steel Technical Report, No. 11, March 1978. UDC 669. 012.1-52: 669.184. 244. 66: 681. 3; Technical Report 11; Nippon Steel Corporation: Tokyo, Japan, 1978. [Google Scholar]
- Krumm, W.; Fett, F.N. Energiemodell eines LD-Stahlwerks. Stahl Und Eisen 1987, 107, 410–416. [Google Scholar]
- Takawa, T.; Katayama, K.; Katohgi, K.; Kuribayashi, T. Analysis of Converter Process Variables from Exhaust Gas. Trans. Iron Steel Inst. Jpn. 1988, 28, 59–67. [Google Scholar] [CrossRef]
- Friedman, J.H. Multivariate Adaptive Regression Splines. Ann. Stat. 1991, 19, 1–67. [Google Scholar] [CrossRef]
- Sephton, P. Forecasting Recessions: Can We Do Better on MARS? Federal Reserve Bank of St. Louis: St. Louis, MO, USA, 2001.
- Chugh, M.; Thumsi, S.S.; Keshri, V. A Comparative Study Between Least Square Support Vector Machine(Lssvm) and Multivariate Adaptive Regression Spline(Mars) Methods for the Measurement of Load Storing Capacity of Driven Piles in Cohesion Less Soil. Int. J. Struct. Civ. Eng. Res. 2015, 4, 189–194. [Google Scholar] [CrossRef]
- Tselykh, V.R. Multivariate adaptive regression splines. Mach. Learn. Data Anal. 2012, 1, 272–278. [Google Scholar] [CrossRef]
- Samui, P.; Kothari, D.P. A Multivariate Adaptive Regression Spline Approach for Prediction of Maximum Shear Modulus and Minimum Damping Ratio. Eng. J. 2012, 16, 69–78. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning—Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Zhang, W.; Goh, A.T.C. Multivariate adaptive regression splines and neural network models for prediction of pile drivability. Geosci. Front. 2016, 7, 45–52. [Google Scholar] [CrossRef] [Green Version]
- Díaz, J.; Fernández, F.J.; Prieto, M.M. Hot Metal Temperature Forecasting at Steel Plant Using Multivariate Adaptive Regression Splines. Metals 2019, 10, 41. [Google Scholar] [CrossRef] [Green Version]
- Jekabsons, G. ARESLab: Adaptive Regression Splines Toolbox for Matlab/Octave. 2022. Available online: http://www.cs.rtu.lv/jekabsons/regression.html (accessed on 24 February 2022).
- Kačur, J.; Durdán, M.; Laciak, M.; Flegner, P. A Comparative Study of Data-Driven Modeling Methods for Soft-Sensing in Underground Coal Gasification. Acta Polytech. 2019, 59, 322–351. [Google Scholar] [CrossRef] [Green Version]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the 5th Annual Workshop on Computational Learning Theory—COLT ’92, Pittsburgh, PA, USA, 27–29 July 1992; ACM Press: Pittsburgh, PA, USA, 1992; pp. 144–152. [Google Scholar] [CrossRef]
- Vapnik, V.N. Constructing Learning Algorithms. In The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995; pp. 119–166. [Google Scholar] [CrossRef]
- Kačur, J.; Laciak, M.; Flegner, P.; Terpák, J.; Durdán, M.; Trefa, G. Application of Support Vector Regression for Data-Driven Modeling of Melt Temperature and Carbon Content in LD Converter. In Proceedings of the 2019 20th International Carpathian Control Conference (ICCC), Krakow, Poland, 26–29 May 2019. [Google Scholar] [CrossRef]
- Smola, A.; Schölkopf, B.; Müller, K.R. General cost functions for support vector regression. In Proceedings of the 9th Australian Conference on Neural Networks, Brisbane, Australia, 11–13 February 1999; Downs, T., Frean, M., Gallagher, M., Eds.; University of Queensland: Brisbane, Australia, 1999; pp. 79–83. [Google Scholar]
- Burges, C.J.C.; Schölkopf, B. Improving the accuracy and speed of support vector learning machines. In Advances in Neural Information Processing Systems 9; Mozer, M., Jordan, M., Petsche, T., Eds.; MIT Press: Cambridge, MA, USA, 1997; pp. 375–381. [Google Scholar]
- Lanckriet, G.; Cristianini, N.; Bartlett, P.; El, G.L.; Jordan, M. Learning the Kernel Matrix with Semidefinite Programming. J. Mach. Learn. Res. 2004, 5, 27–72. [Google Scholar]
- MathWorks. Matlab Statistics and Machine Learning Toolbox Release 2016b; MathWorks: Natick, MA, USA, 2016. [Google Scholar]
- MathWorks. Understanding Support Vector Machine Regression. In Statistics and Machine Learning Toolbox User’s Guide (R2022a); regression.html; MathWorks: Natick, MA, USA, 2022; Available online: https://www.mathworks.com/help/stats/understanding-support-vector-machine-regression.html (accessed on 24 February 2022).
- Smola, A.J.; Schölkopf, B. On a Kernel-Based Method for Pattern Recognition, Regression, Approximation, and Operator Inversion. Algorithmica 1998, 22, 211–231. [Google Scholar] [CrossRef]
- Kvasnička, V.; Beňušková, Ľ.; Pospíchal, J.; Farkaš, I.; Tiňo, P.; Kráľ, A. Úvod do Teórie Neurónových Sietí; IRIS: Bratislava, Slovakia, 1997. [Google Scholar]
- MathWorks. Deep Learning Toolbox; MathWorks: Natick, MA, USA, 2022. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Wiliams, R.J. Learning internal representation by error propagation. In Parallel Distributed Processing. Explorations in the Microstructure of Cognition. Vol 1: Foundation; Rumelhart, D.E., McClelland, J.L., PDP Research Group, Eds.; Stanford University: Stanford, CA, USA, 1987. [Google Scholar]
- Sampson, G.; Rumelhart, D.E.; McClelland, J.L.; Group, T.P.R. Parallel Distributed Processing: Explorations in the Microstructures of Cognition. Language 1987, 63, 871. [Google Scholar] [CrossRef]
- Fix, E.; Hodges, J.L. Discriminatory Analysis: Nonparametric Discrimination: Consistency Properties (Report). 1951. Available online: https://apps.dtic.mil/sti/pdfs/ADA800276.pdf (accessed on 24 February 2022).
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef] [Green Version]
- Piryonesi, S.M.; El-Diraby, T.E. Role of Data Analytics in Infrastructure Asset Management: Overcoming Data Size and Quality Problems. J. Transp. Eng. Part B Pavements 2020, 146, 04020022. [Google Scholar] [CrossRef]
- Han, M.; Wang, X. BOF Oxygen Control by Mixed Case Retrieve and Reuse CBR. IFAC Proc. Vol. 2011, 44, 3575–3580. [Google Scholar] [CrossRef] [Green Version]
- Kramer, O. K-Nearest Neighbors. In Dimensionality Reduction with Unsupervised Nearest Neighbors; Springer: Berlin/Heidelberg, Germany, 2013; pp. 13–23. [Google Scholar] [CrossRef]
- Ferreira, D. k-Nearest Neighbors (kNN) Regressor. GitHub. 2020. Available online: https://github.com/ferreirad08/kNNeighborsRegressor/releases/tag/1.0.1 (accessed on 24 February 2022).
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar] [CrossRef] [Green Version]
- Piryonesi, S.M.; El-Diraby, T.E. Using Machine Learning to Examine Impact of Type of Performance Indicator on Flexible Pavement Deterioration Modeling. J. Infrastruct. Syst. 2021, 27, 04021005. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Minitab. Random Forests Trademark of Health Care Productivity, Inc.—Registration Number 3185828—Serial Number 78642027. 2006. Available online: https://trademarks.justia.com/857/89/randomforests-85789388.html (accessed on 24 February 2022).
- Laha, D.; Ren, Y.; Suganthan, P. Modeling of steelmaking process with effective machine learning techniques. Exp. Syst. Appl. 2015, 42, 4687–4696. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Banerjee, S. Generic Example Code and Generic Function for Random Forests. MATLAB Central File Exchange. 2022. Available online: https://www.mathworks.com/matlabcentral/fileexchange/63698-generic-example-code-and-generic-function-for-random-forests (accessed on 24 February 2022).
- Gandomi, A.H.; Roke, D.A. Intelligent formulation of structural engineering systems. In Proceedings of the Seventh MIT Conference on Computational Fluid and Solid Mechanics-Focus: Multiphysics and Multiscale, Cambridge, MA, USA, 12–14 June 2013. [Google Scholar]
- Gandomi, A.H.; Roke, D.A. Assessment of artificial neural network and genetic programming as predictive tools. Adv. Eng. Softw. 2015, 88, 63–72. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Observations | Ranges | Units | Targets | Ranges | Units |
|---|---|---|---|---|---|
| —Steel quality class | 444–959 | (-) | Endpoint melt temperature | 1580–1720 | (C) |
| —Amount of blown oxygen | 7000–8900 | (Nm) | Endpoint carbon concentration in melt | 0.02–0.08 | (%) |
| —Duration of oxygen blowing | 900–1100 | (s) | Melting duration | 25–80 | (min) |
| —Pig iron temperature | 1200–1400 | (C) | (Optional) | ||
| —Weight of pig iron | 1,300,000–170,000 | (kg) | |||
| —Carbon concentration in pig iron | 4.0–4.6 | (%) | |||
| —Silicon concentration in pig iron | 0.1–1.5 | (%) | |||
| —Manganese concentration in pig iron | 0.1–0.8 | (%) | |||
| —Phosphorus concentration in pig iron | 0.04–0.08 | (%) | |||
| —Sulfur concentration in pig iron | 0.002–0.02 | (%) | |||
| —Titanium concentration in pig iron | 0.005–0.05 | (%) | |||
| —Scrap weight added to pig iron | 23,000–5500 | (kg) | |||
| —Amount of added magnesite to the melt | 0–2000 | (kg) | |||
| —Amount of Fe in pig iron | 140,000–170,000 | (kg) | |||
| —Amount of after-blow oxygen | 0–1000 | (Nm) | |||
| Optional: | |||||
| Endpoint melt temperature | 1580–1720 | (C) | |||
| Endpoint carbon concentration in melt | 0.02–0.08 | (%) | |||
| Melting duration | 25–80 | (min) | |||
| Amount of lime added to the melt | 4500–1200 | (kg) | |||
| Amount of dolomitic lime added to the melt | 2100–6000 | (kg) |
| Observations | Ranges | Units | Targets | Ranges | Units |
|---|---|---|---|---|---|
| —Concentration of CO in waste gas | 0–85 | (%) | Melt tempearture | 1580–1720 | (C) |
| —Concentration of CO in waste gas | 0–35 | (%) | Carbon concentration in melt | 0.02–0.08 | (%) |
| —Temperature of waste gas | 80–1000 | (C) | |||
| —Accumulated amount of blown oxygen | 0–8500 | (Nm) | |||
| Optional: | |||||
| Concentration of O in waste gas | 0–23 | (%) | |||
| Concentration of H in waste gas | 0–12 | (%) | |||
| Volume flow of waste gas | 80,000–100,000 | (m/h) |
| Method | Advantages | Disadvantages |
|---|---|---|
| SVR | Can utilize predictive power of linear combinations of inputs. Works well outside of training data. A good solution for regression on nonlinear data. Not prone to overfitting. Durable to noise. Low generalization error. | Difficult to understand structure of algorithm. Depends on the kernel function. Needs normalizing of input data. |
| NN | Tolerant to noise and missing data. A good solution for regression on nonlinear data. Extensive literature. Good prediction, generally. Some tolerance to correlated inputs. Incorporating the predictive power of different combinations of inputs. | Difficult to understand structure of algorithm. Computationally expensive and prone to overfitting. Needs a lot of training data, often much more than that required for standard machine learning algorithms. Prediction outside of training data can be drastically incorrect. Unimportant inputs may worsen predictions. Requires manual tuning of nodes and layers. Computation costs are typically high. Depends on the training function. Not robust to outliers. Susceptible to irrelevant features. Difficult in dealing with big data with a complex model. |
| MARS | Works well with many predictor variables. Automatically detects interactions between variables. It is an efficient and fast algorithm, despite its complexity. MARS naturally handles mixed types of predictors (quantitative and qualitative). Robust to outliers. Ability to model large datasets more flexibly than linear models. The final regression model can be portable to various hardware. Automatically models non-linearities and interactions between variables. | Susceptible to overfitting. More difficult to understand and interpret than other methods. Not good with missing data. Typically slower to train. Besides speed, there is also the problem of global optimization vs. local optimization. Although correlated predictors do not necessarily impede model performance, they can make model interpretation difficult. |
| k-NN | Simple, adaptable to the problem. Accurate. Easy to understand. Uses spatial trees to improve space issues. Nonparametric. Intuitive approach. Robust to outliers on the predictors. Zero cost in the training process. | Memory intensive. Costly, all training data might be involved in decision making. Slow performance due to I/O operations. Selection of the optimal number of neighbors can be problematic. Choosing the wrong distance measures can produce inaccurate results. |
| RF | Not difficult to understand. High accuracy. A good starting point to solve a problem. Flexible and can fit a variety of different data well. Fast to execute. Easy to use. Useful for regression and classification problems. Can model missing values. High performing. | Slow in training. Overfitting. Not suitable for small samples. A small change in training data changes the model. Occasionally too simple for a very complex problem. |
| Method | Training | Testing | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Time (s) | MSE | RMSE | RRMSE (%) | MAPE (%) | PI | MSE | RMSE | RRMSE (%) | MAPE (%) | PI | |||||
| SVR (polynomial kernel) | 0.1006 | 0.7384 | 0.5452 | 244.6054 | 15.6399 | 0.9432 | 0.7008 | 0.5426 | 0.5884 | 0.3462 | 310.0572 | 17.6084 | 1.0615 | 0.8277 | 0.6683 |
| SVR (Gaussian kernel) | 0.1075 | 0.7985 | 0.6376 | 200.1204 | 14.1464 | 0.8532 | 0.6167 | 0.4744 | 0.6439 | 0.4146 | 275.6026 | 16.6013 | 1.0008 | 0.7894 | 0.6088 |
| NN | 0.4690 | 0.4890 | 0.2391 | 397.3077 | 19.9326 | 1.2021 | 0.9460 | 0.8074 | 0.0904 | 0.0082 | 537.4529 | 23.1830 | 1.3976 | 1.1224 | 1.2817 |
| MARS (piecewise-linear) | 8.1688 | 0.7324 | 0.5364 | 241.7318 | 15.5477 | 0.9377 | 0.7463 | 0.5413 | 0.7007 | 0.4910 | 245.1000 | 15.6557 | 0.9438 | 0.7297 | 0.5549 |
| MARS (piecewise-cubic) | 8.1951 | 0.7053 | 0.4974 | 262.0617 | 16.1883 | 0.9763 | 0.7747 | 0.5725 | 0.7518 | 0.5652 | 209.0871 | 14.4598 | 0.8717 | 0.6891 | 0.4976 |
| k-NN | 0.0010 | 0.5584 | 0.3118 | 361.3029 | 19.0080 | 1.1464 | 0.9070 | 0.7356 | 0.3890 | 0.1513 | 417.6730 | 20.4370 | 1.2320 | 0.9927 | 0.8870 |
| RF | 64.5802 | 0.9368 | 0.8776 | 113.0654 | 10.6332 | 0.6413 | 0.4946 | 0.3311 | 0.6178 | 0.3817 | 304.9878 | 17.4639 | 1.0528 | 0.8388 | 0.6508 |
| Method | Endpoint Relative Error in Testing (%) | Endpoint Absolute Error in Testing (°C) | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Melting # | Average | Melting # | Average | |||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| SVR (polynomial kernel) | 2.05 | 0.58 | 1.34 | 0.77 | 0.33 | 0.64 | 0.44 | 0.93 | 0.46 | 0.15 | 0.77 | 32.66 | 9.74 | 21.83 | 13.00 | 5.53 | 10.72 | 7.32 | 15.30 | 7.58 | 2.44 | 12.61 |
| SVR (Gaussian kernel) | 1.64 | 0.46 | 1.45 | 0.44 | 0.49 | 0.48 | 0.54 | 0.95 | 0.36 | 0.44 | 0.72 | 26.14 | 7.72 | 23.70 | 7.41 | 8.16 | 8.13 | 8.95 | 15.53 | 5.98 | 7.26 | 11.90 |
| NN | 1.64 | 0.05 | 0.34 | 1.77 | 0.88 | 0.67 | 0.47 | 1.55 | 0.47 | 0.25 | 0.81 | 26.15 | 0.87 | 5.57 | 29.88 | 14.60 | 11.28 | 7.75 | 25.41 | 7.85 | 4.08 | 13.34 |
| MARS (piecewise-linear) | 1.54 | 0.42 | 1.57 | 0.49 | 0.31 | 0.52 | 0.56 | 0.72 | 0.39 | 0.38 | 0.69 | 24.56 | 7.09 | 25.66 | 8.34 | 5.14 | 8.83 | 9.34 | 11.79 | 6.51 | 6.32 | 11.36 |
| MARS (piecewise-cubic) | 1.93 | 0.22 | 1.57 | 0.66 | 0.08 | 0.56 | 0.42 | 1.18 | 0.23 | 0.07 | 0.69 | 30.81 | 3.71 | 25.63 | 11.20 | 1.28 | 9.50 | 6.96 | 19.28 | 3.79 | 1.23 | 11.34 |
| k-NN | 2.36 | 0.08 | 1.69 | 1.14 | 0.27 | 0.52 | 0.47 | 1.25 | 0.06 | 0.01 | 0.78 | 37.66 | 1.26 | 27.58 | 19.18 | 4.48 | 8.82 | 7.84 | 20.44 | 0.98 | 0.14 | 12.84 |
| RF | 1.85 | 0.83 | 1.13 | 0.96 | 0.53 | 0.25 | 0.61 | 0.76 | 0.44 | 0.23 | 0.76 | 29.58 | 13.81 | 18.41 | 16.26 | 8.81 | 4.20 | 10.06 | 12.39 | 7.32 | 3.86 | 12.47 |
| Method | Training | Testing | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Time (s) | MSE | RMSE | RRMSE (%) | MAPE (%) | PI | MSE | RMSE | RRMSE (%) | MAPE (%) | PI | |||||
| SVR (polynomial kernel) | 2.7453 | 0.9377 | 0.8793 | 0.0000 | 0.0040 | 9.0594 | 323.4241 | 4.6753 | 0.2722 | 0.0741 | 0.0004 | 0.0190 | 39.1046 | 27.9480 | 30.7378 |
| SVR (Gaussian kernel) | 0.1034 | 0.7063 | 0.4989 | 0.0001 | 0.0085 | 19.2427 | 900.9556 | 11.2772 | 0.3970 | 0.1576 | 0.0002 | 0.0125 | 25.7343 | 18.1771 | 18.3893 |
| NN | 0.4909 | 0.1056 | 0.0112 | 0.0003 | 0.0166 | 37.4686 | 1623.7490 | 33.8898 | 0.1623 | 0.0263 | 0.0004 | 0.0196 | 40.2912 | 28.7549 | 34.6651 |
| MARS (piecewise-linear) | 9.4032 | 0.6296 | 0.3964 | 0.0001 | 0.0090 | 20.1894 | 634.5756 | 12.3893 | 0.3674 | 0.1350 | 0.0002 | 0.0123 | 25.4229 | 17.7828 | 18.5920 |
| MARS (piecewise-cubic) | 10.4514 | 0.6038 | 0.3646 | 0.0001 | 0.0092 | 20.7141 | 705.0538 | 12.9155 | 0.3994 | 0.1595 | 0.0001 | 0.0120 | 24.8100 | 17.4491 | 17.7590 |
| k-NN | 0.0016 | 0.5466 | 0.2988 | 0.0001 | 0.0097 | 21.8553 | 1022.7833 | 14.1312 | 0.2364 | 0.0559 | 0.0002 | 0.0131 | 27.0069 | 19.7905 | 21.8427 |
| RF | 68.7665 | 0.9036 | 0.8165 | 0.0000 | 0.0065 | 14.7035 | 857.1016 | 7.7241 | 0.3368 | 0.1134 | 0.0002 | 0.0125 | 25.8377 | 18.5165 | 19.3283 |
| Method | Endpoint Relative Error in Testing (%) | Endpoint Absolute Error in Testing (Vol.%) | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Melting # | Average | Melting # | Average | |||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| SVR (polynomial kernel) | 15.12 | 29.43 | 11.23 | 31.32 | 17.05 | 4.40 | 17.12 | 4.83 | 11.91 | 8.88 | 15.13 | 0.0067 | 0.0109 | 0.0036 | 0.0094 | 0.0080 | 0.0014 | 0.0079 | 0.0014 | 0.0057 | 0.0029 | 0.0058 |
| SVR (Gaussian kernel) | 14.39 | 13.41 | 16.76 | 17.25 | 9.81 | 6.27 | 1.10 | 16.21 | 12.33 | 1.70 | 10.92 | 0.0063 | 0.0050 | 0.0054 | 0.0052 | 0.0046 | 0.0020 | 0.0005 | 0.0045 | 0.0059 | 0.0006 | 0.0040 |
| NN | 22.52 | 5.19 | 0.30 | 44.00 | 33.92 | 9.41 | 1.63 | 30.32 | 20.53 | 28.89 | 19.67 | 0.0099 | 0.0019 | 0.0001 | 0.0132 | 0.0159 | 0.0030 | 0.0008 | 0.0085 | 0.0099 | 0.0095 | 0.0073 |
| MARS (piecewise-linear) | 0.07 | 18.78 | 13.80 | 15.32 | 14.28 | 12.88 | 2.07 | 17.32 | 12.86 | 5.56 | 11.29 | 0.0000 | 0.0069 | 0.0044 | 0.0046 | 0.0067 | 0.0041 | 0.0010 | 0.0049 | 0.0062 | 0.0018 | 0.0041 |
| MARS (piecewise-cubic) | 2.69 | 16.99 | 15.70 | 3.58 | 3.61 | 15.67 | 1.52 | 14.32 | 9.79 | 11.55 | 9.54 | 0.0012 | 0.0063 | 0.0050 | 0.0011 | 0.0017 | 0.0050 | 0.0007 | 0.0040 | 0.0047 | 0.0038 | 0.0034 |
| k-NN | 6.36 | 8.70 | 19.88 | 16.53 | 7.45 | 18.44 | 8.52 | 18.50 | 16.42 | 2.97 | 12.38 | 0.0028 | 0.0032 | 0.0064 | 0.0050 | 0.0035 | 0.0059 | 0.0039 | 0.0052 | 0.0079 | 0.0010 | 0.0045 |
| RF | 5.42 | 18.74 | 15.00 | 18.64 | 8.39 | 10.25 | 3.01 | 19.77 | 7.02 | 12.70 | 11.89 | 0.0024 | 0.0069 | 0.0048 | 0.0056 | 0.0039 | 0.0033 | 0.0014 | 0.0055 | 0.0034 | 0.0042 | 0.0041 |
| BF | Equation | BF | Equation |
|---|---|---|---|
| BF1 | C( | −1, 367.76, 735.52, 984.31) | BF12 | BF5 × C( | +1, 83650, 147100, 157750) |
| BF2 | C( | −1, 0.003, 0.006, 0.052) | BF13 | BF5 × C( | −1, 83650, 147100, 157750) |
| BF3 | C( | +1, 5294.8, 7856.6, 8392.6) | BF14 | BF1 × C( | −1, 597, 1194, 2171.5) |
| BF4 | C( | −1, 5294.8, 7856.6, 8392.6) | BF15 | BF3 × C( | +1, 0.2045, 0.306, 0.3185) |
| BF5 | C( | +1, 18900, 37800, 46450) | BF16 | BF10 × C( | −1, 627.5, 694, 826.5) |
| BF6 | C( | −1, 18900, 37800, 46450) | BF17 | BF1 × C( | +1, 0.017, 0.034, 0.044) |
| BF7 | C( | +1, 1250.3, 1301.5, 1331.5) | BF18 | BF2 × C( | −1, 0.19371, 0.358, 0.5185) |
| BF8 | C( | −1, 1250.3, 1301.5, 1331.5) | BF19 | C( | −1, 0.003, 0.006, 0.052) × C( | +1, 0.19371, 0.358, 0.5185) × C( | +1, 1331.5, 1361.6, 1453.3) |
| BF9 | C( | −1, 0.5185, 0.679, 1.8595) | BF20 | C( | −1, 0.003, 0.006, 0.052) × C( | +1, 0.19371, 0.358, 0.5185) × C( | −1, 1331.5, 1361.6, 1453.3) |
| BF10 | C( | −1, 0.044, 0.054, 0.093) | BF21 | C( | −1, 367.76, 735.52, 984.31) × C( | +1, 662.5, 959, 1085) × C( | +1, 0.3185, 0.331, 0.87139) |
| BF11 | BF3 × C( | −1, 285, 561, 627.5) | BF22 | C( | −1, 367.76, 735.52, 984.31) × C( | +1, 662.5, 959, 1085) × C( | −1, 0.3185, 0.331, 0.87139) |
| BF | Equation | BF | Equation |
|---|---|---|---|
| BF1 | C( | +1, 1632, 1687, 1705) | BF14 | C( | −1, 44550, 50300, 52700) |
| BF2 | C( | −1, 1632, 1687, 1705) | BF15 | C( | +1, 644, 922, 927) × C( | +1, 0.63971, 1.25, 2.145) |
| BF3 | C( | +1, 0.34472, 0.58643, 0.99911) | BF16 | C( | +1, 644, 922, 927) × C( | −1, 0.63971, 1.25, 2.145) |
| BF4 | C( | −1, 0.34472, 0.58643, 0.99911) | BF17 | BF2 × C( |+1, 1010, 1085, 2117) |
| BF5 | C( | +1, 1266.5, 1333.9, 1439.5) | BF18 | BF2 × C( |−1, 1010, 1085, 2117) |
| BF6 | C( | +1, 83100, 146,000, 157,200) | BF19 | C( | −1, 1632, 1687, 1705) × C( | −1, 577.03, 647.5, 940.3) × C( | +1, 467.5,935, 1010) |
| BF7 | C( | −1, 0.0145, 0.028, 0.046) | BF20 | C( | −1, 1632, 1687, 1705) × C( | −1, 577.03, 647.5, 940.3) × C( | −1, 467.5, 935, 1010) |
| BF8 | C( | −1, 644, 922, 927) | BF21 | BF18 × C( | +1, 253.28, 506.55, 577.03) |
| BF9 | BF6 × C( | +1, 5618, 8503, 8715.8) | BF22 | BF18 × C( | −1, 253.28, 506.55, 577.03) |
| BF10 | C( | +1, 83100, 146000, 157200) × C( | −1, 5618, 8503, 8715.8) × C( | −1, 19400, 38800, 44550) | BF23 | C( | −1, 1266.5, 1333.9, 1439.5) × C( | −1, 2.5825, 4.605, 4.63) |
| BF11 | BF5 × C( | +1, 442, 875, 917) | BF24 | C( | +1, 927, 932, 1071.5) |
| BF12 | BF5 × C( | −1, 442, 875, 917) | BF25 | C( | −1, 927,932, 1071.5) |
| BF13 | C( |+1, 44,550, 50,300, 52,700) |
| Method | Training | Testing | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Time (s) | MSE | RMSE | RRMSE (%) | MAPE (%) | PI | MSE | RMSE | RRMSE (%) | MAPE (%) | PI | |||||
| SVR (polynomial kernel) | 0.1926 | 0.7636 | 0.5831 | 224.9944 | 14.9998 | 0.9046 | 0.6646 | 0.5130 | 0.6057 | 0.3669 | 306.4681 | 17.5062 | 1.0553 | 0.8391 | 0.6572 |
| SVR (Gaussian kernel) | 0.1046 | 0.8145 | 0.6634 | 186.7076 | 13.6641 | 0.8241 | 0.5917 | 0.4542 | 0.6556 | 0.4298 | 273.3737 | 16.5340 | 0.9967 | 0.7807 | 0.6020 |
| NN | 0.2750 | 0.1519 | 0.0231 | 1445.2063 | 38.0159 | 2.2927 | 1.7939 | 1.9904 | 0.1081 | 0.0117 | 1453.5004 | 38.1248 | 2.2983 | 1.8851 | 2.0741 |
| MARS (piecewise-linear) | 10.8102 | 0.7484 | 0.5601 | 229.3880 | 15.1456 | 0.9134 | 0.7204 | 0.5224 | 0.6653 | 0.4426 | 296.5315 | 17.2201 | 1.0381 | 0.8216 | 0.6234 |
| MARS (piecewise-cubic) | 10.8143 | 0.7071 | 0.5000 | 260.6863 | 16.1458 | 0.9737 | 0.7684 | 0.5704 | 0.6714 | 0.4508 | 270.3367 | 16.4419 | 0.9912 | 0.7737 | 0.5930 |
| k-NN | 0.0012 | 0.6098 | 0.3719 | 331.4534 | 18.2059 | 1.0980 | 0.8646 | 0.6821 | 0.1137 | 0.0129 | 537.7687 | 23.1898 | 1.3980 | 1.1326 | 1.2552 |
| RF | 67.6480 | 0.9414 | 0.8862 | 105.0343 | 10.2486 | 0.6181 | 0.4757 | 0.3184 | 0.6119 | 0.3744 | 306.8707 | 17.5177 | 1.0560 | 0.8610 | 0.6551 |
| Method | Training | Testing | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Time (s) | MSE | RMSE | RRMSE (%) | MAPE (%) | PI | MSE | RMSE | RRMSE (%) | MAPE (%) | PI | |||||
| SVR (polynomial kernel) | 2.1406 | 0.9710 | 0.9428 | 0.0000 | 0.0028 | 6.2736 | 169.6273 | 3.1830 | 0.0861 | 0.0074 | 0.0040 | 0.0630 | 129.6704 | 47.7670 | 119.3862 |
| SVR (Gaussian kernel) | 0.1017 | 0.7426 | 0.5515 | 0.0001 | 0.0081 | 18.3250 | 899.9417 | 10.5157 | 0.3803 | 0.1446 | 0.0002 | 0.0126 | 25.9159 | 18.0279 | 18.3772 |
| NN | 0.6165 | 0.1047 | 0.0110 | 0.0004 | 0.0200 | 44.9654 | 1800.2448 | 40.7037 | 0.2020 | 0.0408 | 0.0003 | 0.0165 | 33.9825 | 25.1977 | 28.2707 |
| MARS (piecewise-linear) | 13.3011 | 0.6304 | 0.3974 | 0.0001 | 0.0090 | 20.1725 | 725.0324 | 12.3728 | 0.4102 | 0.1683 | 0.0001 | 0.0122 | 25.0724 | 17.3692 | 18.1648 |
| MARS (piecewise-cubic) | 12.7149 | 0.5945 | 0.3534 | 0.0001 | 0.0093 | 20.8945 | 1028.9877 | 13.1037 | 0.2757 | 0.0760 | 0.0002 | 0.0128 | 26.3574 | 18.1886 | 20.6616 |
| k-NN | 0.0010 | 0.5569 | 0.3101 | 0.0001 | 0.0096 | 21.6641 | 1022.7053 | 13.9148 | 0.1112 | 0.0124 | 0.0002 | 0.0137 | 28.1985 | 21.6507 | 25.3777 |
| RF | 71.9077 | 0.9087 | 0.8257 | 0.0000 | 0.0064 | 14.4773 | 849.7621 | 7.5849 | 0.3266 | 0.1067 | 0.0002 | 0.0126 | 25.8663 | 18.6019 | 19.4980 |
| BF | Equation | BF | Equation |
|---|---|---|---|
| BF1 | C( | −1, 367.76, 735.52, 984.31) | BF13 | BF4 × C( | −1, 83650, 147100, 157750) |
| BF2 | C( | −1, 0.0045, 0.006, 0.052) | BF14 | C( | +1, 5294.8, 7856.6, 8179.8) × C( | −1, 7162, 8803, 10922) × C( | −1, 362.5, 725, 1937) |
| BF3 | C( | −1, 5294.8, 7856.6, 8179.8) | BF15 | BF1 × C( | +1, 683, 1000, 1105.5) |
| BF4 | C( | +1, 18900, 37800, 46450) | BF16 | C( | −1, 0.0045, 0.006, 0.052) × C( | +1, 2760.5, 5521, 7162) × C( | −1, 69.5, 130, 345.5) |
| BF5 | C( | −1, 18900, 37800, 46450) | BF17 | BF10 × C( | −1, 345.5, 561, 760) |
| BF6 | C( | +1, 1250.3, 1301.5, 1313.7) | BF18 | C( | +1, 5294.8, 7856.6, 8179.8) × C( | −1, 0.221, 0.339, 0.87539) |
| BF7 | C( | −1, 1250.3, 1301.5, 1313.7) | BF19 | BF4 × C( | −1, 0.0015, 0.003, 0.0045) |
| BF8 | C( | −1, 0.35421, 0.679, 1.8595) | BF20 | BF14 × C( | −1, 1313.7, 1325.9, 1343.3) |
| BF9 | C( | −1, 0.027, 0.054, 0.093) | BF21 | BF8 × C( | +1, 8179.8, 8503, 8715.8) |
| BF10 | BF2 × C( | −1, 2760.5, 5521, 7162) | BF22 | C( | +1, 5294.8, 7856.6, 8179.8) × C( | +1, 1343.3, 1360.7, 1452.9) |
| BF11 | C( | +1, 5294.8, 7856.6, 8179.8) × C( | +1, 7162, 8803, 10922) | BF23 | C( | +1, 5294.8, 7856.6, 8179.8) × C( | −1, 1343.3, 1360.7, 1452.9) |
| BF12 | BF4 × C( | +1, 83650, 147100, 157750) |
| BF | Equation | BF | Equation |
|---|---|---|---|
| BF1 | max(0, 1687−) | BF14 | max(0, 1333.9−) × max(0, ) × max(0, 8151.8−) |
| BF2 | max(0, −0.58643) | BF15 | BF14 × max(0, −971) |
| BF3 | max(0, 0.58643−) | BF16 | BF1 × max(0, −647.5) |
| BF4 | max(0, −1333.9) | BF17 | BF4 × max(0, −875) |
| BF5 | max(0, −146,000) | BF18 | BF4 × max(0, 875−) |
| BF6 | max(0, 146,000−) | BF19 | max(0, 1333.9−) × max(0, −8044.3) |
| BF7 | max(0, 0.028−) | BF20 | max(0, 1333.9−) × max(0, 8044.3−) |
| BF8 | max(0, 922−) | BF21 | max(0, −922) × max(0, −406.53) |
| BF9 | max(0, −9722) | BF22 | max(0, −922) × max(0, 406.53−) |
| BF10 | max(0, 9722−) | BF23 | BF19 × max(0, −150100) |
| BF11 | max(0, −50300) | BF24 | BF19 × max(0, 150100−) |
| BF12 | max(0, 50300−) | BF25 | max(0, 1333.9− ) × max(0, ) × max(0, 8151.8−) × max(0, 971−) × max(0, 596−) |
| BF13 | BF5 × max(0, −8503) |
| Method | Training | |||||||
|---|---|---|---|---|---|---|---|---|
| Time (s) | MSE | RMSE | RRMSE (%) | MAPE (%) | PI | |||
| SVR (polynomial kernel) | 1.0183 | 0.9842 | 0.9686 | 969.8928 | 31.1431 | 2.0959 | 1.5849 | 1.0563 |
| SVR (Gaussian kernel) | 0.2528 | 0.9883 | 0.9767 | 723.7140 | 26.9019 | 1.8104 | 1.3153 | 0.9105 |
| NN | 1.6471 | 0.9757 | 0.9520 | 1491.0892 | 38.6146 | 2.5987 | 1.6227 | 1.6227 |
| MARS (piecewise-linear) | 2.4166 | 0.9850 | 0.9702 | 919.6555 | 30.3258 | 2.0409 | 1.4773 | 1.0281 |
| MARS (piecewise-cubic) | 2.7178 | 0.9837 | 0.9677 | 1002.3017 | 31.6591 | 2.1306 | 1.6113 | 1.0741 |
| k-NN | 0.0015 | 0.9877 | 0.9756 | 754.7641 | 27.4730 | 1.8489 | 1.4295 | 0.9301 |
| RF | 59.0626 | 0.9918 | 0.9837 | 506.5556 | 22.5068 | 1.5147 | 1.1175 | 0.7604 |
| Method | Endpoint Relative Error in Testing (%) | Endpoint Absolute Error in Testing (°C) | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Melting # | Average | Melting # | Average | |||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| SVR (polynomial kernel) | 0.07 | 1.15 | 4.39 | 0.29 | 0.01 | 1.32 | 1.08 | 0.89 | 1.38 | 1.68 | 1.23 | 1.10 | 19.03 | 74.79 | 4.72 | 0.21 | 21.67 | 17.92 | 14.91 | 22.94 | 28.37 | 20.56 |
| SVR (Gaussian kernel) | 1.03 | 0.50 | 7.41 | 6.84 | 1.45 | 0.39 | 0.52 | 4.45 | 4.88 | 9.37 | 3.68 | 16.97 | 8.25 | 126.18 | 112.69 | 23.99 | 6.33 | 8.63 | 74.27 | 81.28 | 158.18 | 61.68 |
| NN | 2.40 | 2.49 | 1.66 | 2.49 | 5.97 | 0.43 | 1.35 | 7.98 | 3.28 | 3.87 | 3.19 | 39.69 | 41.00 | 28.23 | 41.00 | 98.81 | 7.08 | 22.42 | 133.07 | 54.53 | 65.35 | 53.12 |
| MARS (piecewise-linear) | 0.15 | 0.59 | 1.27 | 1.68 | 0.29 | 0.78 | 0.03 | 0.85 | 0.68 | 1.00 | 0.73 | 2.47 | 9.69 | 21.55 | 27.73 | 4.78 | 12.86 | 0.55 | 14.20 | 11.24 | 16.88 | 12.19 |
| MARS (piecewise-cubic) | 0.07 | 0.65 | 1.28 | 1.81 | 0.41 | 0.89 | 0.07 | 0.88 | 0.76 | 0.93 | 0.77 | 1.12 | 10.67 | 21.79 | 29.75 | 6.73 | 14.66 | 1.11 | 14.72 | 12.63 | 15.69 | 12.89 |
| k-NN | 1.29 | 1.60 | 2.26 | 2.77 | 1.47 | 1.11 | 0.17 | 0.16 | 0.11 | 1.04 | 1.20 | 21.40 | 26.40 | 38.40 | 45.60 | 24.40 | 18.20 | 2.80 | 2.60 | 1.80 | 17.60 | 19.92 |
| RF | 0.35 | 1.11 | 3.13 | 0.35 | 1.05 | 0.58 | 1.40 | 1.35 | 1.53 | 2.46 | 1.33 | 5.80 | 18.36 | 53.33 | 5.81 | 17.43 | 9.47 | 23.16 | 22.60 | 25.53 | 41.60 | 22.31 |
| Method | Training | |||||||
|---|---|---|---|---|---|---|---|---|
| Time (s) | MSE | RMSE | RRMSE (%) | MAPE (%) | PI | |||
| SVR (polynomial kernel) | 3.1040 | 0.9948 | 0.9896 | 0.0702 | 0.2650 | 12.0035 | 864.6450 | 6.0174 |
| SVR (Gaussian kernel) | 0.2451 | 0.9933 | 0.9866 | 0.0744 | 0.2727 | 12.3531 | 1350.4329 | 6.1973 |
| NN | 0.8467 | 0.9876 | 0.9754 | 0.1164 | 0.3412 | 15.4534 | 2542.8869 | 7.7748 |
| MARS (piecewise-linear) | Failed | |||||||
| MARS (piecewise-cubic) | Failed | |||||||
| k-NN | 0.0018 | 0.9955 | 0.9910 | 0.0489 | 0.2211 | 10.0151 | 595.5354 | 5.0188 |
| RF | 51.5903 | 0.9960 | 0.9920 | 0.0376 | 0.1938 | 8.7776 | 15.9674 | 4.3976 |
| Method | Endpoint Relative Error in Testing (%) | Endpoint Absolute Error in Testing (Vol.%) | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Melting # | Average | Melting # | Average | |||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| SVR (polynomial kernel) | 116.00 | 20.32 | 250.43 | 142.38 | 386.25 | 147.20 | 134.69 | 284.12 | 97.67 | 329.35 | 190.84 | 0.0661 | 0.0106 | 0.0902 | 0.0584 | 0.1699 | 0.0559 | 0.0660 | 0.1193 | 0.0420 | 0.1449 | 0.0823 |
| SVR (Gaussian kernel) | 193.88 | 168.60 | 2279.79 | 2899.48 | 1521.79 | 1.31 | 24.51 | 2225.60 | 1596.32 | 2853.40 | 1376.47 | 0.1105 | 0.0877 | 0.8207 | 1.1888 | 0.6696 | 0.0005 | 0.0120 | 0.9347 | 0.6864 | 1.2555 | 0.5766 |
| NN | 252.69 | 393.18 | 84.70 | 1742.12 | 450.99 | 28.59 | 197.22 | 1527.45 | 531.81 | 2196.87 | 740.56 | 0.1440 | 0.2045 | 0.0305 | 0.7143 | 0.1984 | 0.0109 | 0.0966 | 0.6415 | 0.2287 | 0.9666 | 0.3236 |
| MARS (piecewise-linear) | Failed | Failed | ||||||||||||||||||||
| MARS (piecewise-cubic) | Failed | Failed | ||||||||||||||||||||
| k-NN | 30.18 | 26.92 | 16.11 | 12.68 | 15.91 | 1.58 | 1.63 | 14.29 | 3.26 | 3.64 | 12.62 | 0.0172 | 0.0140 | 0.0058 | 0.0052 | 0.0070 | 0.0006 | 0.0008 | 0.0060 | 0.0014 | 0.0016 | 0.0060 |
| RF | 16.29 | 334.95 | 352.63 | 335.99 | 364.71 | 459.68 | 135.39 | 317.87 | 354.29 | 435.79 | 310.76 | 0.0093 | 0.1742 | 0.1269 | 0.1378 | 0.1605 | 0.1747 | 0.0663 | 0.1335 | 0.1523 | 0.1917 | 0.1327 |
| BF | Equation | BF | Equation |
|---|---|---|---|
| BF1 | max(0, −7662.7) | BF8 | max(0, 5402.7−) × max(0, 0.54977−) |
| BF2 | max(0, 7662.7−) | BF9 | max(0, −12.992) |
| BF3 | BF2 × max(0, 0.11574−) | BF10 | max(0, 12.992−) |
| BF4 | max(0, 7662.7−) × max(0, −0.11574) × max(0, −20.747) | BF11 | BF7 × max(0, −30.642) |
| BF5 | max(0, 7662.7−) × max(0, −0.11574) × max(0, 20.747−) | BF12 | BF7 × max(0, 30.642−) |
| BF6 | BF5 × max(0, −717.4) | BF13 | max(0, 7662.7−) × max(0, −0.11574) × max(0, −30.642) |
| BF7 | max(0, 5402.7−) × max(0, −0.54977) | BF14 | BF9 × max(0, - 51.765) |
| Method | Added Observation(s) | Training | Testing | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Time (s) | r | r | MSE | RMSE | RRMSE (%) | MAPE (%) | PI | Average Relative Error in Endpoint (%) | Average Absolute error in Endpoint (C) | ||
| SVR (polynomial kernel) | O (%) | 1.4019 | 0.9847 | 0.9696 | 940.7080 | 30.6710 | 2.0641 | 1.5918 | 1.0400 | 1.64 | 27.39 |
| H (%) | 0.0510 | 0.9829 | 0.9661 | 1049.0229 | 32.3886 | 2.1797 | 1.6523 | 1.0992 | 1.60 | 26.85 | |
| O, H (%) | 0.1439 | 0.9838 | 0.9679 | 994.9295 | 31.5425 | 2.1227 | 1.6045 | 1.0700 | 2.14 | 35.80 | |
| SVR (Gaussian kernel) | O (%) | 0.0333 | 0.989 | 0.9781 | 679.3708 | 26.0647 | 1.7541 | 1.4389 | 0.8819 | 4.78 | 79.97 |
| H (%) | 0.0282 | 0.9867 | 0.9736 | 820.0818 | 28.6371 | 1.9272 | 1.5261 | 0.9700 | 2.64 | 44.07 | |
| O, H (%) | 0.0330 | 0.989 | 0.9781 | 685.3073 | 26.1784 | 1.7617 | 1.4452 | 0.8858 | 4.01 | 67.13 | |
| 0]*NN | O (%) | 1.2520 | 0.9786 | 0.9577 | 1313.0513 | 36.236 | 2.4386 | 1.8238 | 1.2325 | 2.26 | 37.66 |
| H (%) | 0.5802 | 0.9786 | 0.9577 | 1318.2917 | 36.3083 | 2.4435 | 1.7894 | 1.2349 | 2.79 | 46.36 | |
| O, H (%) | 0.5887 | 0.9788 | 0.9580 | 1308.9262 | 36.1791 | 2.4348 | 1.7751 | 1.2304 | 2.22 | 37.06 | |
| MARS (piecewise-linear) | O (%) | 1.8643 | 0.9850 | 0.9702 | 921.9392 | 30.3635 | 2.0434 | 1.5745 | 1.0294 | 0.77 | 12.91 |
| H (%) | 2.6286 | 0.9847 | 0.9696 | 941.7202 | 30.6875 | 2.0652 | 1.5791 | 1.0406 | 0.84 | 14.01 | |
| O, H (%) | 2.2213 | 0.985 | 0.9702 | 921.9392 | 30.3635 | 2.0434 | 1.5745 | 1.0294 | 0.77 | 12.91 | |
| MARS (piecewise-cubic) | O (%) | 2.0915 | 0.9845 | 0.9692 | 949.7489 | 30.8180 | 2.074 | 1.5895 | 1.0451 | 0.70 | 11.71 |
| H (%) | 2.6845 | 0.9845 | 0.9692 | 951.9365 | 30.8535 | 2.0764 | 1.5937 | 1.0463 | 0.91 | 15.20 | |
| O, H (%) | 2.3626 | 0.9845 | 0.9692 | 949.7489 | 30.818 | 2.074 | 1.5895 | 1.0451 | 0.70 | 11.71 | |
| k-NN | O (%) | 0.0015 | 0.9878 | 0.9757 | 750.9376 | 27.4032 | 1.8442 | 1.4299 | 0.9277 | 1.20 | 19.97 |
| H (%) | 0.0015 | 0.9877 | 0.9756 | 755.1083 | 27.4792 | 1.8493 | 1.4290 | 0.9304 | 1.20 | 19.97 | |
| O, H (%) | 0.0013 | 0.9878 | 0.9757 | 753.6573 | 27.4528 | 1.8475 | 1.4336 | 0.9294 | 1.20 | 19.97 | |
| RF | O (%) | 52.7746 | 0.9918 | 0.9837 | 507.8521 | 22.5356 | 1.5166 | 1.1332 | 0.7614 | 1.80 | 30.15 |
| H (%) | 52.1179 | 0.9917 | 0.9835 | 513.2911 | 22.6559 | 1.5247 | 1.1285 | 0.7655 | 1.77 | 29.55 | |
| O, H (%) | 53.3313 | 0.9917 | 0.9835 | 518.2623 | 22.7654 | 1.5321 | 1.1387 | 0.7692 | 2.31 | 38.54 | |
| Method | Added Observation(s) | Training | Testing | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Time (s) | r | r | MSE | RMSE | RRMSE (%) | MAPE (%) | PI | Average Relative Error in Endpoint (%) | Average Absolute Error in Endpoint (vol.%) | ||
| SVR (polynomial kernel) | O (%) | 9.8700 | 0.9935 | 0.9870 | 0.0617 | 0.2484 | 11.2522 | 1936.6827 | 5.6446 | 422.30 | 0.1807 |
| H (%) | 0.7264 | 0.9930 | 0.9860 | 0.0708 | 0.2661 | 12.0543 | 406.0649 | 6.0483 | 457.08 | 0.2029 | |
| O, H (%) | 6.8941 | 0.9933 | 0.9866 | 0.0661 | 0.2571 | 11.6462 | 477.8318 | 5.8428 | 449.68 | 0.2060 | |
| SVR (Gaussian kernel) | O (%) | 0.2335 | 0.9971 | 0.9942 | 0.0585 | 0.2419 | 10.9565 | 802.7950 | 5.4861 | 2240.19 | 0.9385 |
| H (%) | 0.2324 | 0.9946 | 0.9892 | 0.0645 | 0.2540 | 11.5071 | 1021.0557 | 5.7692 | 964.71 | 0.4144 | |
| O, H (%) | 0.2321 | 0.9958 | 0.9916 | 0.0494 | 0.2222 | 10.0664 | 913.7527 | 5.0439 | 1508.12 | 0.6346 | |
| NN | O (%) | 0.8624 | 0.9892 | 0.9785 | 0.1016 | 0.3188 | 14.4382 | 2395.4597 | 7.2582 | 1324.38 | 0.5667 |
| H (%) | 1.0127 | 0.9860 | 0.9722 | 0.1320 | 0.3633 | 16.4536 | 2763.2608 | 8.2849 | 1361.82 | 0.6014 | |
| O, H (%) | 0.8246 | 0.9888 | 0.9777 | 0.1055 | 0.3247 | 14.7090 | 2875.5355 | 7.3959 | 814.47 | 0.3571 | |
| MARS (piecewise-linear) | O (%) | Failed | |||||||||
| H (%) | Failed | ||||||||||
| O, H (%) | Failed | ||||||||||
| MARS (piecewise-cubic) | O (%) | Failed | |||||||||
| H (%) | Failed | ||||||||||
| O, H (%) | Failed | ||||||||||
| k-NN | O (%) | 0.0014 | 0.9948 | 0.9896 | 0.0494 | 0.2222 | 10.0633 | 486.1327 | 5.0448 | 12.62 | 0.0060 |
| H (%) | 0.0014 | 0.9948 | 0.9896 | 0.0489 | 0.2211 | 10.0165 | 631.1686 | 5.0213 | 12.62 | 0.0060 | |
| O, H (%) | 0.0014 | 0.9948 | 0.9896 | 0.0494 | 0.2222 | 10.0655 | 492.8121 | 5.0460 | 12.62 | 0.0060 | |
| RF | O (%) | 43.1992 | 0.9960 | 0.9920 | 0.0379 | 0.1947 | 8.8184 | 15.9738 | 4.4180 | 592.91 | 0.2530 |
| H (%) | 44.9515 | 0.9961 | 0.9922 | 0.0375 | 0.1937 | 8.7750 | 15.9797 | 4.3961 | 609.86 | 0.2625 | |
| O, H (%) | 44.0530 | 0.9959 | 0.9918 | 0.0398 | 0.1994 | 9.0315 | 15.9870 | 4.5252 | 901.37 | 0.3868 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kačur, J.; Flegner, P.; Durdán, M.; Laciak, M. Prediction of Temperature and Carbon Concentration in Oxygen Steelmaking by Machine Learning: A Comparative Study. Appl. Sci. 2022, 12, 7757. https://doi.org/10.3390/app12157757
Kačur J, Flegner P, Durdán M, Laciak M. Prediction of Temperature and Carbon Concentration in Oxygen Steelmaking by Machine Learning: A Comparative Study. Applied Sciences. 2022; 12(15):7757. https://doi.org/10.3390/app12157757
Chicago/Turabian StyleKačur, Ján, Patrik Flegner, Milan Durdán, and Marek Laciak. 2022. "Prediction of Temperature and Carbon Concentration in Oxygen Steelmaking by Machine Learning: A Comparative Study" Applied Sciences 12, no. 15: 7757. https://doi.org/10.3390/app12157757
APA StyleKačur, J., Flegner, P., Durdán, M., & Laciak, M. (2022). Prediction of Temperature and Carbon Concentration in Oxygen Steelmaking by Machine Learning: A Comparative Study. Applied Sciences, 12(15), 7757. https://doi.org/10.3390/app12157757