1. Introduction
Convolutional neural networks (CNNs) have been widely used in various domains, especially in computer vision. CNNs have satisfying learning capabilities as they can extract image features of different scales by multiple convolutional layers. However, various CNN architectures are vulnerable. The models will predict wrong results with small perturbations adding to the inputs that humans cannot recognize. In other words, adversarial examples [
1,
2,
3], which are similar to clean examples, will mislead the CNN to output incorrect results. Moreover, adversarial examples can transfer across different CNN models [
4,
5]. These phenomena indicate that the CNN learns some simple patterns to accomplish tasks exactly on specified data but does not recognize more robust advanced features like the human brain. So the CNN is not safe for medical care [
6], autonomous driving [
7], and other fields.
The potential serious harm of adversarial examples has drawn the attention of the scientific research community, forming a new field called adversarial machine learning. There are two main types of defense methods against adversarial examples, i.e., certified methods and empirical methods. Certified methods [
8,
9] can obtain provable robustness, but the provable robustness is low and most of them only aim at the attack with disturbance of
norm. Empirical methods account for the majority of defense methods, including stochastic activation pruning (SAP) [
10], distillation defense [
11], asymmetrical adversarial training [
12], ME-net [
13], etc. However, the robustness of empirical methods is not reliable, and it may be broken by stronger attacks [
14,
15].
Adversarial training (AT) [
16] is one of the most successful empirical defense methods at present which is a data augmentation technique for training models on both natural and adversarial examples. Although AT is an empirical method, it has been proved to be highly robust even under adaptive attack [
14]. AT effectively robustifies CNN but has two challenges: lower clean accuracy [
17] and the overfitting problem [
18,
19]. To address these challenges, many variants of AT have been proposed, such as TRADES [
20], customized adversarial training (CAT) [
21], dynamic adversarial training (DAT) [
22], and geometry-aware instance-reweighted adversarial training (GAIRAT) [
23]. However, these two problems are still unsolved very well. So this paper is devoted to them by considering the maximum margin.
The key insight is that the purpose of adversarial machine learning, i.e., the maximizing margin is very similar to that of SVM. Theoretically, the margin of the classifier in the input space is positively correlated with its robustness. However, for multi-layer neural networks, the margin on the input space is difficult to be calculated and constrained. AT can indirectly increase the margin of the classifier in the input space because the adversarial examples are obtained by moving clean examples toward the decision boundary. We find that ordinary training methods such as using cross-entropy loss cannot effectively increase the margin. So we propose adversarial training with supported vector machine (AT-SVM) that increases the margin by SVM. Specifically, we insert an SVM auxiliary classifier before the last layer in the network, which can maximize the margin on this feature space. The SVM is a better classifier for high-level feature space, so we use it to identify more confusing points which will be trained on the original network. With continuous learning, the boundary of the original network will gradually approach the boundary of the SVM. At the same time, in order to ensure that the margin on the feature space is consistent with the margin on the input space, we constrain the distance between the clean example and the corresponding adversarial example in the margin direction of this feature space. Experiments indicate that our proposed method can effectively improve the robustness against adversarial examples.
3. Proposed Method
In this section, we firstly introduce the motivation and basic theories of our proposed method. Then we consult its learning objective as well as its algorithmic implementation. Lastly, we compare our method with other existing defense methods.
3.1. Motivation
On the one hand, according to a common empirical result from researchers of adversarial defense [
16,
23], a larger model capacity is needed for adversarial examples. Therefore, in the case of insufficient model capacity, it is unwise to treat all examples equally. Training more important examples is helpful to make better use of the model capacity. On the other hand, intuitively, the examples close to the classification boundary are more vulnerable to adversarial attacks and are more important for the classification boundary. This widely accepted assumption can be proved empirically.
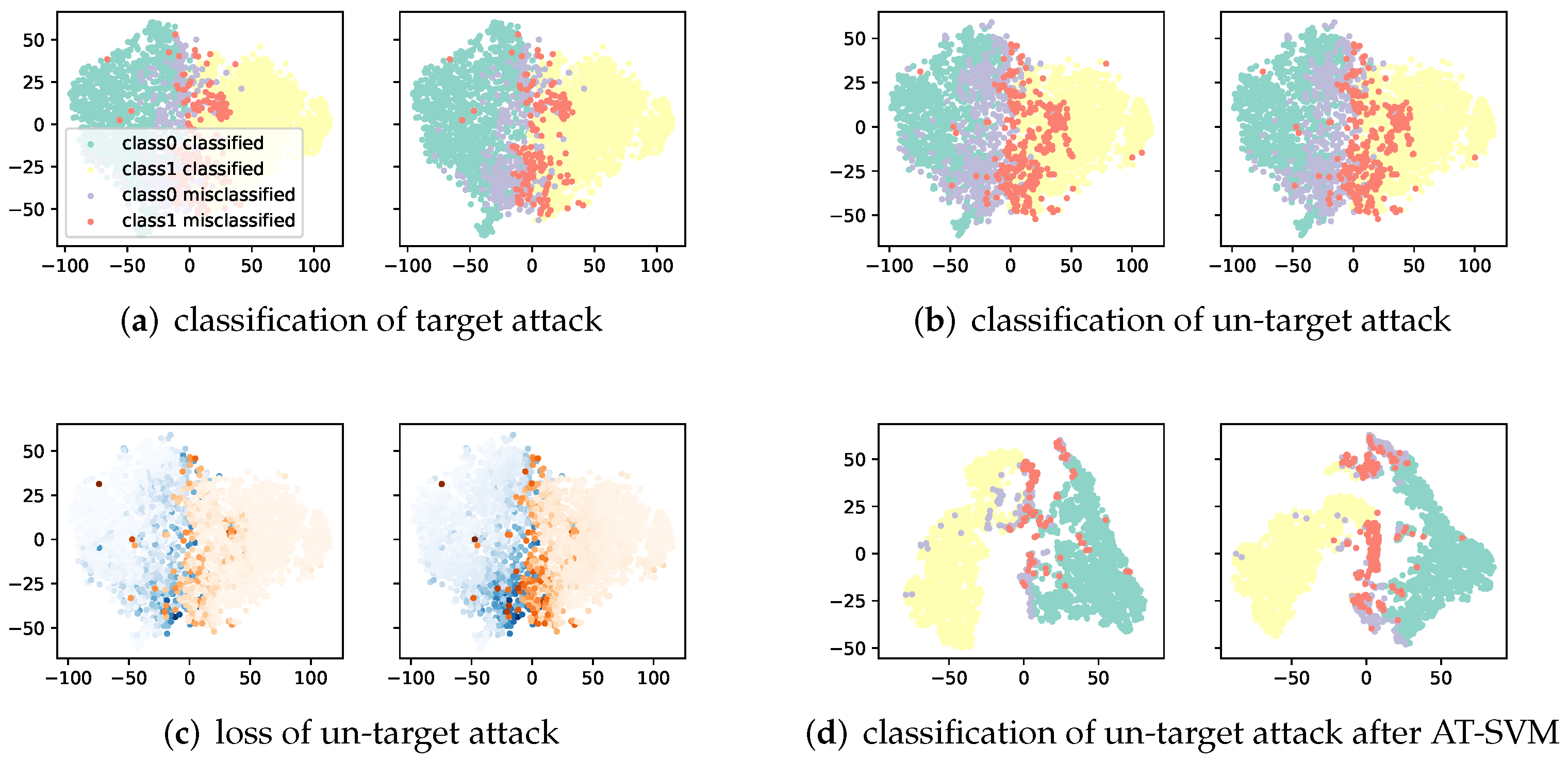
Figure 1 shows the distribution of the feature map before the last layer of the two randomly selected classes in the CIFAR-10 dataset. It can be seen that the features of the misclassified examples are concentrated near the boundary no matter whether it is adversarial examples using targeted or untargeted attack.
According to the idea of SVM [
36], to obtain a linear binary classifier that maximizes the margin between two classes, only the examples closest to the decision boundary, i.e., the support vectors, are needed. For a CNN network, although it is not a linear classifier, the last layer is always a fully connected (FC) layer that is linear. So the examples can be transformed into linearly separable high-order feature space after passing the front layers. According to these high-order features, we can find out which examples are support vectors that are close to the boundary. Training models on these examples can improve the efficiency of adversarial training.
For linear classification tasks, SVM can learn the classifier with the largest margin. We extend the SVM and add an SVM auxiliary layer into the CNNs when training so that the features extracted by the CNNs have a larger margin, hence improving the adversarial robustness of the CNN.
3.2. Theories
3.2.1. Linear Binary-Classification Task
For a binary linearly separable classification problem, there exist many hyperplanes that might classify the data. SVM is designed to compute the classification hyperplane which represents the largest separation, or margin, between two classes. The max-margin hyperplane is also known as the optimal classification hyperplane.
The main idea of finding the optimal classification hyperplane is to maximize the distance between different classes. Because of the possible inseparable points in data, slack variable
and penalty coefficient
C are generally added. So the essence is to solve the following optimization problems, as shown in Equation (
3)
where
indicate that
is a positive or negative example.
These constraints of the optimization problem in Equation (
3) can be solved by mathematical methods such as the sequential minimal optimization (SMO) [
37] algorithm. However, in order to replace the original linear FC layer in the training of CNN, this formula cannot be directly used as a new loss function, as there are inequality constraints. So the following content will deform this optimization problem.
The constraints are equivalent to Equation (
4).
The inequality constraint in Equation (
4) shows the lower bound of
. When solving the minimization problem outside, we approximately replace
with the lower bound of it. Let
. Equation (
3) can be written as Equation (
5).
Since there is no inequality constraint, the new formula can be directly used as the loss function. Notice that is the hinge loss function. The other item can be regarded as a regularization term added to improve the generalization performance of the model.
3.2.2. Linear Multi-Classification Task
For a multi-class classifier, the predicted label is chosen by the maximal logit attained over all classes:
where
is the output of
corresponds to the
kth class. In linear case,
.
For any two classes
, the decision boundary between them is called
.
The geometric distance of a point
from
is:
Some margin-based methods only consider the margin between the ground truth class and the most easily misclassified class, i.e., setting
. Instead, our method considers all margins between each class and the other classes. In other words, we regard a multi-classification task as a multiply binary classification task. Equation (
5) can be generalized to the following optimization problem in Equation (
8).
where
n is the class number,
indicate
is/not belong to class
j.
3.2.3. General Classification Task
For a nonlinear classifier, the approximation scheme from Elsayed et al. [
38] can be adopted to capture the distance of a point to the decision boundary which is a first-order Taylor approximation to the true distance. Equation (
8) can be extended to:
Using this approximation, we can calculate margins on all layers, just replace the input
in the above formula with intermediate features
on different layers. The training data
induces a distribution of distances at each layer
l which, following earlier naming convention [
39,
40], we refer to as margin distribution (at layer
l).
Intuitively, constraining the margin distribution of the total network to be large enough can lead to a robust model. However, this approximation will lose accuracy fast as inputs move away from the decision boundary. Moreover, it is difficult to learn a model with large margin distribution. So that our proposed method only constrains the margin distribution on the last FC layer, just solve the optimization problem in Equation (
8). At the same time, use
introduced later to limit the deviation between the margin distribution on the last FC layer and the margin distribution of the total network.
3.3. AT-SVM
In this section, we introduce our supported vector machine adversarial training (AT-SVM) method, which dynamically learns an SVM auxiliary classifier and restricts the decision boundary of the original network to achieve a large margin.
3.3.1. Overview
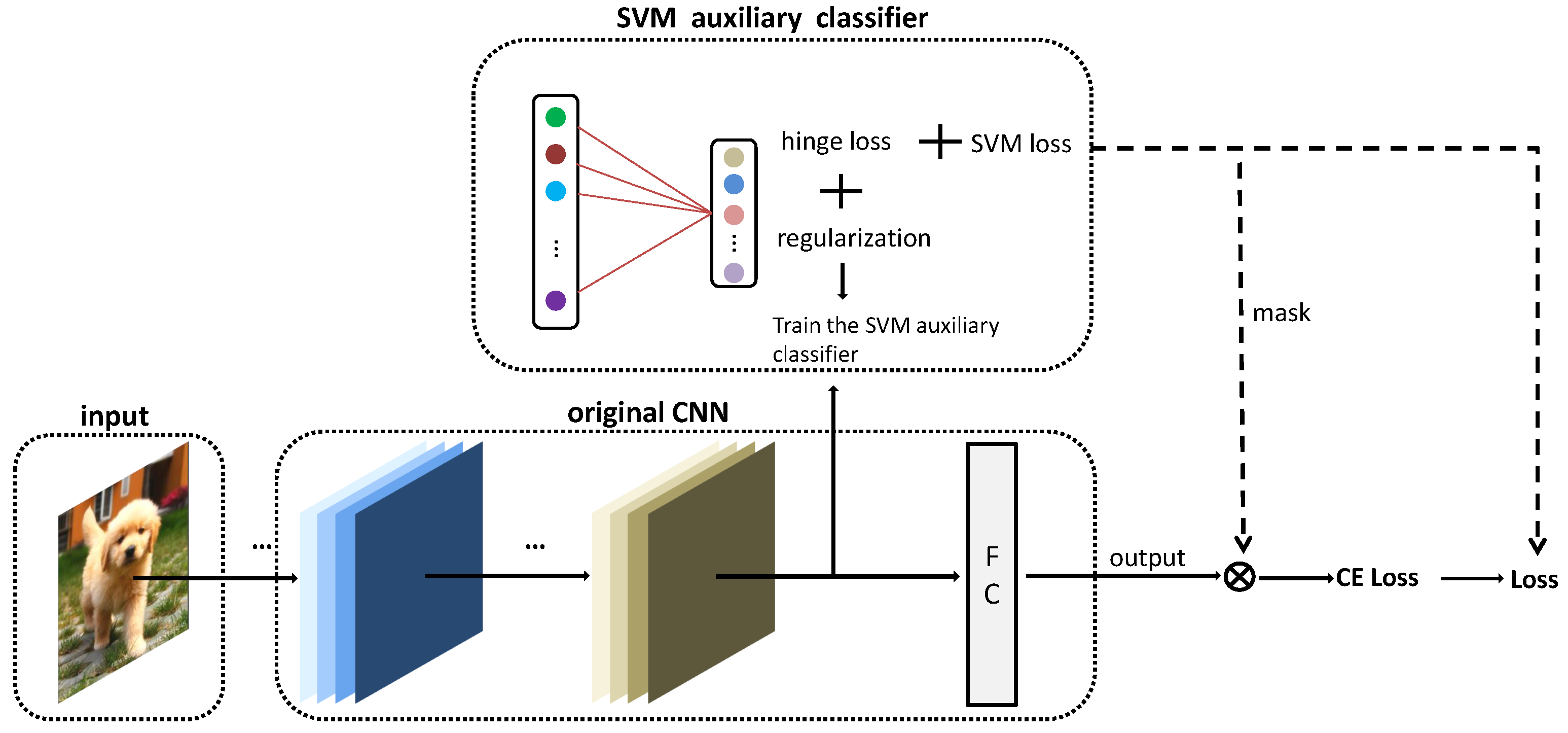
As
Figure 2 shows, our method is mainly inserting an auxiliary SVM classifier in the penultimate layer of the network, which is parallel to the last layer. The SVM layer contains as many neurons as the number of classes and is purposed to obtain the maximum margin decision boundary in this feature space. The SVM auxiliary classifier treats the front layer of the original network as a feature extractor and uses a separate optimizer for training. In each epoch of training, the SVM auxiliary classifier and the original network are trained successively, and a mask on which examples will be trained is produced by the SVM auxiliary classifier. The SVM auxiliary classifier is discarded during inference. The specific implementation will be introduced in the algorithm.
In CNNs, the last FC layer is linear, so we regard the front layers as a feature extractor. Using
to denote the extracted feature, we can train an SVM auxiliary classifier using Equation (
10).
where the first item is the hinge loss represented by
below. However, there is a problem in training the network with Equation (
10) that the feature space
is constantly changing. Accordingly, maximizing the margins in Equation (
10) can be trivially attained by scaling up the space
. This problem can be solved by using the SVM auxiliary layers, because
only helps training the SVM auxiliary and indirectly affects
. The training of the main network is only using
, which constrains the feature extractor to separate input examples of different classes in the feature space. The auxiliary classifier is affected by both
and
, and continuously obtains a better classification boundary. The change of the boundary will also affect the value of
. The boundary and
will be converged under the continuous alternating training of the original network and the auxiliary classifier.
The distance from
to the binary decision boundary of class
j is:
For a clean example
, we denote its adversarial example as
. Only a large margin in SVM auxiliary cannot guarantee robustness because the extracted feature
of
may have large distance with
. So we will constrain the movement of the adversarial examples relative to the clean examples in the margin direction, as shown in Equation (
12).
After normalization, the following objective function can be obtained, as shown in Equation (
13).
In each epoch, we will first train the SVM auxiliary classifier using Equation (
10). Then compute
,
and add them to the loss of the original network to train.
3.3.2. Algorithm Implementation
In order to pick out the important examples close to the decision boundary, AT-SVM adds an SVM auxiliary classifier before the last layer. For each mini-batch, adversarial examples will be generated using the gradient of the original network, and a mask of all examples is obtained according to the results of the SVM auxiliary classifier to pick out the more important examples. Finally, the original network trains only on these selected examples. In the final inference, the SVM auxiliary is removed.
In each mini-batch, first, we train the SVM auxiliary classifier with all parameters of the original model fixed. When training the SVM layer, the loss is as Equation (
10) including both hinge loss and the weights’
norm as a regularization term. Then we set the SVM layer fixed and recalculate the hinge loss
and compute loss
from SVM auxiliary classifier using Equation (
13), send them to backpropagation. At the same time, use whether this loss is 0 to generate a binary mask, and multiply the output from the original model with the mask before calculating the cross-entropy loss. The procedure is summarized in Algorithm 1.
| Algorithm 1 AT-SVM |
| Require: network , SVM auxiliary classifier, training dataset , loss function , learning rate , number of epochs T, batch size m, number of batches M, weight of loss from SVM auxiliary classifier |
| Ensure: robust network |
| 1: | Initialize , |
| 2: | fordo |
| 3: | for do |
| 4: | Sample a mini-batch from |
| | training dataset S |
| 5: | for do |
| 6: | Use Equation (1) to generate PGD attack examples |
| | |
| 7: | Get the feature before the last FC layer |
| 8: | end for |
| 9: | Use Algorithm 2 to train an SVM auxiliary |
| | classifier |
| 10: | Use the SVM auxiliary classifier to obtain a |
| | mask for all as well as compute loss |
| | using Equation (13) |
| 11: | |
| 12: | |
| 13: | end for |
| 14: | end for |
Algorithm 2 is an SVM auxiliary classifier, which is trained using both the adversarial data and the natural data and returns a mask for them at the same time. AT-SVM leverages Algorithm 2 for obtaining the mask for all examples. For each mini-batch, AT-SVM selects examples that will be misclassified by the SVM auxiliary classifier and then updates the model parameters by minimizing the sum of the selected examples’ loss.
| Algorithm 2 SVM auxiliary classifier |
| Require: input feature and labels , number of classes k, weights and bias for SVM auxiliary classifier, weight of regularization term C in Equation (10) |
| Ensure: a for all input data, new weights and bias for SVM auxiliary classifier |
| 1: | Initialize |
| 2: | fordo |
| 3: | for and do |
| 4: | |
| 5: | if then |
| 6: | end if |
| 7: | end for |
| 8: | end for |
| 9: | |
| 10: | |
3.3.3. Feasibility Verification
We train a standard model using AT first. This model is fixed as a feature extractor and adds the SVM auxiliary classifier before the last FC layer. Then we train the SVM layer. As
Figure 1a,b show, the SVM auxiliary classifier can learn the correct decision boundary, which ensures that it will pass the correct mask and loss to the original network. It can be seen that, in general, the points which are misclassified are distributed near the boundary. Adversarial training can be regarded as a data augmentation making trained examples close to decision boundary and then getting larger loss.
In
Figure 1c, we compare the original cross-entropy loss with the loss from the SVM auxiliary classifier. Points with darker colors have a greater loss. It can be found that the latter is more significant which is the reason why using the SVM auxiliary classifier: loss in the original CNN network will decrease to nearly zero after training so that training becomes difficult, but the loss of the SVM auxiliary layer is still significant, so training on this loss will make model efficiently learn a large margin on this layer.
With the help of SVM, the high-order features of the example can be separated more effectively. As shown in
Figure 1a, using the SAT-trained classifier, the high-order features of the examples and their adversarial examples are not well separated, and a large number of them are distributed near the boundary to cause confusion. Using the classifier trained by the proposed method, the high-order features of the examples are more concentrated and the distance between classes is larger shown in
Figure 1d. The misclassified examples are also separated from the correctly classified examples, and several small clusters are formed nearby. This shows that the SVM auxiliary classifier achieves the effect of increasing the inter-class distance and reducing the intra-class distance on high-order features. Empirically, this helps adversarial robustness. For the above reasons, the SVM auxiliary classifier can provide a more significant loss compared with the standard setting and therefore improve the adversarial robustness.
3.4. Comparisons to Other Adversarial-Based Defense Methods
First, the main idea of many variants of adversarial training is to weaken the adversarial examples when training [
21,
28] or use attacks from the weak to the strong drawing on the ideas of curriculum training [
22,
26]. Unlike these methods, AT-SVM does not change the attack. Moreover, stronger adversarial examples are more likely to be misclassified by the SVM auxiliary classifier and have the opportunity to be trained by the original network rather than being discarded.
Second, some methods treat adversarial data differently by explicitly assigning different weights to their losses, such as MART [
27] and GAIRAT [
23]. This kind of method is similar to ours because our method is equivalent to assigning a weight of 0 or 1 to all examples. However, our method is more concerned with finding more important examples near the decision boundary than assigning reasonable weights to all examples. We believe that as long as the training is carried out under the appropriate data, the original surrogate loss will be sufficient. Furthermore, MART regards natural examples which are misclassified as outliers and suppresses the influence of adversarial examples corresponding to these examples. On the contrary, AT-SVM will train more on these misclassified natural examples to avoid the decline in the accuracy of natural examples caused by adversarial training.
Last, max-margin adversarial (MMA) training [
41] (Ding et al., 2019) is also declared to improve adversarial robustness by the maximum “margin” like SVM. We emphasize that our AT-SVM is different from MMA in the following aspects: (1) the “margin” in MMA means the “shortest successful perturbation” which is obtained from a PGD attack while the “margin” in AT-SVM is just the loss in SVM auxiliary classifier. So AT-SVM can increase the margin more simply, without using other objective function indirectly like MMA; (2) MMA will first test whether the classification of clean examples are correct or not. For correctly classified examples, MMA adopts cross-entropy loss on adversarial examples; for misclassified examples, MMA directly applies cross-entropy loss on natural examples. Our AT-SVM treats all examples the same because we believe that the importance of examples can be adequately reflected by the SVM auxiliary classifier.








{kind=link}
{kind=link}
{kind=link}