1. Introduction
It is a well-known fact that creating new fonts using deep learning is very efficient in terms of time and labor cost. When a font designer creates a new set of English fonts, they only need to design 52 uppercase and lowercase Roman characters. However, it is necessary to design 11,172 characters for Hangul and 70,000 to 100,000 characters for Chinese, which is labor-intensive and practically impossible. These labor-intensive tasks take around 700 days for Hangul and more than 10 years for Chinese, and it is almost impossible to design them in the same style, even if a designer makes one character every 30 min and works 8 h a day [
1].
With deep learning based on artificial intelligence, if you design only 256 characters, it is now possible to create a new set of Korean fonts in 30 min, and this can also be applied to Chinese characters. Therefore, interest in developing a model that automatically produces fonts for various languages has recently increased, and active research is being conducted on the generation of various characters, including Korean, Chinese, and English [
2,
3,
4,
5].
Most font generation models use the generative adversarial network (GAN) [
6,
7] as a basic frame, and various modified forms are used to achieve great results. However, in the case of Hangul and Hanja, which have a large number of characters and complex shapes, it is not easy to change their character style. This is because it is difficult to convert an image by acquiring style information from the content. In particular, it is difficult to successfully convert content images into complex Chinese characters [
8,
9,
10].
Figure 1 shows a sample failure case for the generation of Chinese characters.
To solve this problem, SKFont [
11] proposed a three-stage network based on character image skeletonization [
12] for generating Hangul font images. Additionally, the direct conversion of relatively simple components has also been attempted [
13,
14,
15,
16,
17,
18,
19,
20,
21].
Recently, a component-based method for Hangul was introduced that generated high-quality results [
20]. In Hangul, characters can be regenerated with a maximum of three components. In contrast, in Chinese characters, the number of components varies for each character, and many exceed 10 components. Therefore, a new model must be created to apply the component concepts to Chinese characters.
In this study, we proposed a component-based Chinese font generation (CCFont) model that further separates Chinese character radicals into components and automatically generates high-quality Chinese characters using all components. The CCFont is trained to separate all the components constituting Chinese characters from the 2003 traditional Chinese (TC) characters currently used in China and combines them in a new style. The CCFont model automatically generates not only almost all TC characters (max 17 components) but also all 7445 simplified Chinese (SC) characters of GB/T 2312-1980, which includes 99.99% of the Chinese characters currently used in China, in real time with a high-quality new style.
Because our proposed method obtains style information from the components and not from the glyphs, the model reduces the number of failure cases. It operates in an end-to-end manner that converts styles using component images of Chinese characters and can generate high-quality Chinese characters without additional training steps for unseen font styles.
The CCFont model is executed step by step as follows:
Data generation (Character-to-Radical-to-Components Module, CRC-Module);
Model training (CCFont Training Module);
Generating new character/style Chinese characters (CCFont Generating Chinese Characters, GC-Module).
The data generation module breaks Chinese characters into components to generate data for the CCFont Training Module, which receives the data and regenerates the images through training. For generating a new character, the GC-Module uses the CCFont training module to generate Chinese characters.
Figure 2 depicts an example of Chinese characters generated (out) by the CCFont model in the style of the target character (tgt) based on character input (src).
The CCFont model proposed in this study has the following advantages and contributions:
Decomposing Chinese characters into components decreases the rendering difficulties significantly.
Component image conversion, which is much simpler than character shapes, significantly reduces the number of failure cases and enables high-quality character generation.
Up to 17 components can be generated, making it possible to generate almost all Chinese characters (99.99% in use).
The development of TC and SC Chinese character automatic generation/con-version model (CCFont) using Chinese character components.
Experiments demonstrated zero-shot font generation and generated Korean (Hangul) and Thai fonts using the CCFont model.
There are two types of Chinese characters, TC and SC. In this paper, we trained our model with only TC characters and demonstrated that the model is generalized to generate the unseen SC characters. Additionally, we conducted experiments to demonstrate that the proposed method can also generate multi-lingual characters such as Korean Hangul and Thai characters.
3. Structure of Chinese Character
The exact number of Chinese characters is unknown because anyone can create characters by combining sounds and meanings. In record, there are 47,035 characters in the 1716 Kangxi Zidian (康熙字典) dictionary. The 1989 Hanyu Da Zidian (漢語大字典) dictionary has 54,678 characters, the 1994 Zhonghua Zihai (中华字海) has 85,568, and the 2004 Yitizi Zidian (異体字字典) contains 106,230 characters. The Japanese 2003 Dai Kan-Wa Jiten (大漢和辞典), which uses Chinese characters, contains 50,305 characters, and Korea’s 2008 Han-Han Dae Sajeon (漢韓大辭典) contains 53,667 characters.
Owing to the complexity of Chinese characters, it is difficult not only to understand all Chinese characters but also to write them; therefore, SC characters have been used recently. SC is a simplified version of the number of strokes and shapes compared to the original TC.
GB2312-1980, published in 1980 by the Chinese government, contains 6763 SC Hanzi (汉字), currently used in mainland China and Singapore. In 1995, this was extended to GBK, including TC (20,914 characters), GBK21003 (21,003 characters), GBK26634 (26,634 characters), and GB18030 (70,244 characters), which were combined with GB2312. In 2013, the Chinese government classified the number of Chinese characters used into three grades according to the difficulty of Chinese characters and published 8105 standard characters including SC (Tōngyòng Guīfàn Hànzì Biǎo, 通用规范汉字表). There are 3500 characters in Level 1, 3000 characters in Level 2, and Level 3 has 1605 characters. Furthermore, Levels 1 and 2 are regulated by common Chinese characters.
Chinese characters can be divided into strokes and their components (radicals). A stroke is the smallest unit comprising a character. There are six types of basic strokes, as shown in
Figure 3, and a total of 41 types of strokes.
The strokes form part of a character but have no meaning. The strokes are useful for writing and identifying characters, but they are too small to be used as elements to form an image of a character.
Figure 4 shows examples of a large number of strokes and the complexity of Chinese characters. The characters with the most strokes currently in use are the 58 characters for BiangBiang noodles, a type of noodle from the Chinese province of Shaanxi. There are also characters with higher strokes (64, 84, etc.) to denote the complexity of Chinese characters, but they are seldom used.
3.2. Radicals and Components (http://hanzidb.org/, (accessed on 1 June 2022))
To find a Chinese character in a dictionary, you need an index of Chinese characters, similar to the Roman alphabet; this is called a radical (piānpáng, 偏旁) or indexing component (部首) [
20]. The exact number of radicals is unknown and depends on the number of characters in the character set. There are 214 Kangxi radicals used in China today and 188 in the
Oxford Concise English Chinese Dictionary (ISBN 0-19-596457-8). The standard GF 0011-2009 (汉字部首表) has 201 radicals in simplified Chinese characters. The number of Chinese characters commonly used today is approximately 3500, and there are approximately 500 unique radicals [
17].
Radicals are divided into phonetic and meaning radicals. For example, as shown in
Figure 5 (left), the TC character 媽 mā “mother” in the left part is the radical 女 nǚ “female”—the semantic component—and the right part 馬 mǎ “horse” is the phonetic component. In
Figure 5, the left side is traditional, the right side is simplified, and the same rule applies to both.
In addition, the same radical may change in shape, as shown in
Figure 6, depending on the location where it is used 心=忄, 手=扌=才, 火=灬, etc. Because the radical shape changes depending on character position, it is more difficult to change the style of Chinese characters. We solved this problem by using the image separated into the target character components and by using the modified radical image as is.
Radicals can again be separated into parts (components), which are then divided into lower subcomponents and divided again until they become basic components that cannot be further divided. For example, as shown in
Figure 7, a character can be divided into one to two radicals and 1 to 14 components until it cannot be divided further.
Basic components are sometimes used repeatedly such as 多, 晶, etc., and the basic components themselves become characters such as 言, 心, etc.
4. Training Methodology
In the case of a Chinese character with a complex shape, it is difficult to convert the style by mapping the character itself; therefore, we used a method of decomposing the character into components, transforming the decomposed components into styles, and then recombining the transformed components to generate a new style of character. This is different from [
13,
14,
15,
17,
18,
19], which separated character images into component images. These models cannot separate component images in the case of complex characters.
Figure 8 shows the process of decomposing the characters into components and composing the characters from the decomposed components. For example, separating the character of ‘說’ gives compositions of [‘兌’, ‘言’] (level 1), and by separating again ‘兌’ and ‘言’ (level 2) until they can no longer be separated (level 4), 說 is finally divided into five basic components of [‘丿’, ‘乚’, ‘口’, ‘八’, ‘言’] (decomposition). When the new style of ‘說’ is generated, the newly styled basic components are composed in the opposite direction (composition).
The sample input image to the CCFont model is shown in
Figure 9, where src represents the source image, tgt represents the target image, and all the basic components of the tgt image representing the target font style (tgt style-wised components) are demonstrated.
The components were provided separately in Python as ‘compositions’ of the ‘CJKradlib RadicalFinder’ API (
https://pypi.org/project/cjkradlib/, (accessed on 1 June 2022)). We decomposed and composed Python programs using API.
Most Chinese characters have fewer than 14 components (99.99%), but some have more than 14 components. In addition, SC character components had fewer than TC components. In the examples in
Figure 10, the character 鐵 (iron), which is the character with the greatest number of components among GB2312, is divided into 14 components, as shown in
Figure 10a, and is reduced to four components, shown in
Figure 10b, when divided into SC characters. SC radicals significantly reduced the number of components by converting traditional components into simple and non-separable components, i.e., 訁->讠, 釒->钅, 飠->饣, etc.
Figure 10c shows the TC characteristics with 15, 16, and 17 components, which are the three characters with the highest number of components in GBK21003 (21,003 characters).
According to the Chinese character set, the number of characters, radicals, and components vary, as does the number of characters and radicals.
Table 1 lists the number of unique radicals and components for each set of characters. It demonstrates the variation in character shape, number of characters based on the character set, number of radicals and components, and minimum number of characters necessary to obtain the component. As shown in
Table 1, GB2312 contained 281 unique components, GBK21003 contained 347 unique components, and GBK26634 contained 346 unique components.
In this study, 2000 commercial Chinese characters from standard Chinese GB2312 (up to 14 components) and three characters with 15, 16, and 17 components from GBK21003 were added. Therefore, the CCFont model was trained with 2003 TC characters, 603 unique radicals, and 249 basic components, covering up to 17 components (99.99% of common TC/SC). In other words, the model can regenerate all Chinese characters with 17 components or fewer. Therefore, the proposed model works for any character that can be separated into components (in less than 17s). As a result, it applies to Hangul (three components) and Thai (four components), as well as to TC/SC characters used in China, Japan, and Korea (CJK). The ability to generate multiple languages with the CCFont model trained with only TC characters demonstrates that the computer can generate new characters through deep learning by executing recombination regardless of the component contents.
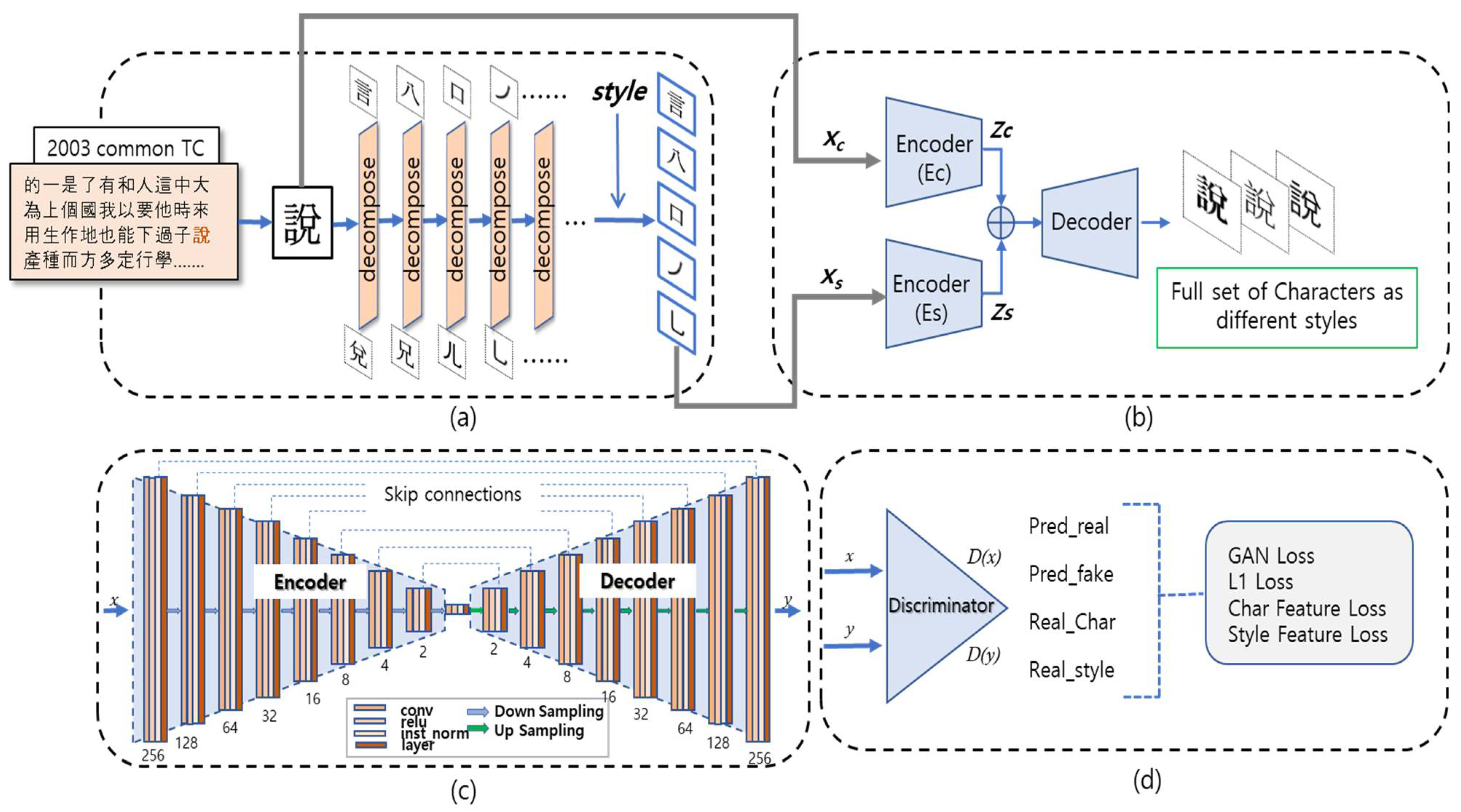
5. CCFont Model
5.1. Model Architecture
To generate high-quality converted images from complex-shaped Chinese characters, it is necessary to accurately extract target-style information features such that no information is lost during learning.
As shown in
Figure 11, we used two encoders for this purpose, which modified a general GAN structure, one to generate font content information (Ec) and the other to generate target font style information (Es). This was intended to obtain more precise style information from the target font components, and the image for each component was maintained to prevent loss.
As shown in
Figure 11, the CCFont is a concise model that utilizes the composition and components of Chinese characters in a one-to-many framework. It is a conditional GAN [
30] structure that uses the content image (Xc) and the style image (Xs) of the character component to be converted as input and has two encoder structures (Ec, Es) to input them separately using the concatenated vector.
The encoder Ec/Es downsamples the input image into eight layers. Each convolution layer uses kernel = 4 and stride = 2, followed by instance normalization, with the exception of the first layer, which uses kernel = 7 and stride = 1. We used LeakyRelu as the activation function, and all the layers had a skip connection structure.
The resulting latent vectors from the two encoders, Zc and Zs, are merged and used as inputs to the decoder and then upsampled again through eight convolutional layers to generate content in a transformed style. Each layer undergoes deconvolution using kernel = 5, stride = 1, instance normalization, and ReLU functions. All layers have a skip connection structure, in which the encoder layer and content/style are merged with the upsampled vectors. Finally, the resulting image G(x) is generated through convolution and tanh functions. The generated result is input to discriminator D, and the GAN loss is calculated by comparing the source image and the generated result image. Character and style loss is achieved by comparing the vector generated from the source image with the resulting image vector, and the quality of the image is improved by comparing the target image and the generated image (L1 loss).
5.2. Loss Functions
The total loss function L of the model is expressed as the sum of adversarial loss (
LADV), style loss (
Ls), and L1 loss (
LL1), as shown in Equation (1).
λs and
λL1 are hyperparameters for style and L1 loss during training and serve as weights for each loss.
The loss functions in Equation (1) are as follows:
Adversarial Loss (LADV): The
LADV of cGAN is expressed as Equation (2), known as min-max adversarial loss [
6], where
G minimizes (generator loss) and
D maximizes (discriminator loss). The discriminator
D determines whether the received fake image (
G(
x)) is real (true: 1) or fake (false: 0) and maximizes it (
D(
y) = 1). Generator G generates a fake image (
G(
x)) and forces D to predict it as a real image (
D(
G(
x)) = 1), such that
G(
x) is minimal (
G(
x) = 0).
where
y is the real image of the character that corresponds to
Yc, and
x equals
Zc +
Zs. By predicting
y as a real image and
x as a fake image from
G, the discriminator
D attempts to minimize this loss function. In comparison, the generator
G attempts to maximize
x as a true image to deceive the discriminator
D.
Style Classification Loss (Ls): To create a one-to-many style-converted image,
D determines whether the style is the same as the target style while discriminating the real from the fake style (
D(
yS)). To maintain the font style of the image,
D predicts the font style (0–1) and feeds it back to
G to reduce loss and lets
G generate a font with the correct style. This concept is the same as adversarial loss, and it applies to character and is the same as Equation (3), which maximizes
D(
yS) and minimizes
G(
xS).
L1 Loss (LL1): LL1 makes the two images equal to
G, generating a fake image (
G(
x)) and reducing the mean absolute error (MAE) compared with the pixel in the target image (
Y), which can be expressed as Equation (4):
6. Experiments and Results
6.1. Data Set Preparation (Character-to-Radical-to-Components)
To obtain the basic components of a Chinese character, as depicted in
Figure 6, all characters must be decomposed to level N (for example, N = 12 for 17 components), and to convert the components into the target style, the target character must be decomposed into the basic components in advance.
To create a training dataset, 2000 random Chinese characters were extracted from the Chinese national standard GB2312 (6763 characters, including 99.99% Chinese characters), along with 15 (霽), 16 (齾), and 17 (钀) component characters from GBK21003 (21,003 characters) were added, and 19 font styles were used for training. We used 2003 Chinese characters with a maximum of 17 components and 19 Chinese character font styles.
By using Python CJKradlib RadicalFinder’s API, all characters could be separated into basic components (up to 17 components), and the style of the separated components is extracted through the component images of the target character style and combined with the character content (source character). The images of resolution 256 × 256 × 19 (256 × 4864) with total number of 38,057 images (2003 × 19) and respective component images 160,341 were prepared.
For font style, 19 styles that generally work for all characters were extracted among the many font styles, and the font list is as follows; 19 styled example characters are shown in
Figure 12.
Figure 13 shows examples of styled input images for random characters with one to nine components.
Figure 14 shows the input representing a styled component for each font style for a random character.
Figure 15 shows the overall data flow of the CCFont model.
Figure 15a shows the data flow input to the CRC module. It demonstrates each Character-to-Radical-to-Components flow by decomposing and adding style information as an input style. This module generates content (Xc) and style (Xs), which are fed into encoders (Ec, Es) as inputs (Xc, Xs), converted to Zc and Zs, and then concatenated (
Figure 15b). A new character set was generated through the decoder.
6.2. CCFont Model Training
The data generated by the CRC module were fed into the CCFont model training module and trained (
Figure 15c,d). It took NVIDIA GTX-2080Ti GPU 12 GB-Memory size 23 h to train 306,794,188 parameters (10 epochs, 160,341 iterations for each epoch). Compared to a standard deep learning model trained on a high-performance GPU, the training time for this model was only 23 h, indicating that it is concise and resource-saving.
6.3. Results of Font Generation (Generates Chinese and Multi-Lingual)
The result of generating a new style of Chinese characters using the training module with the CCFont model is shown in
Figure 16. The model was trained only on 2003 TC characters and successfully generated TC characters as well as SC characters that were seen for the first time. This result demonstrates that the model creates characters regardless of the component content by combining them. Through this, we verified that it is possible to create multiple languages using the TC character model, CCFont.
Figure 16 shows the results of generating 100 TC Chinese characters and 10 font styles for the first time using the CCFont model, where new characters were created by accurately reflecting the target character’s content and style.
Figure 17 shows the results of generating 300 SC Chinese characters and ten font styles. Despite being the first SC character, it has successfully generated new characters and demonstrated that it can be useful for TC-to-SC conversions.
Figure 18 compares the generated results of TC and SC characters for the same characters and font styles.
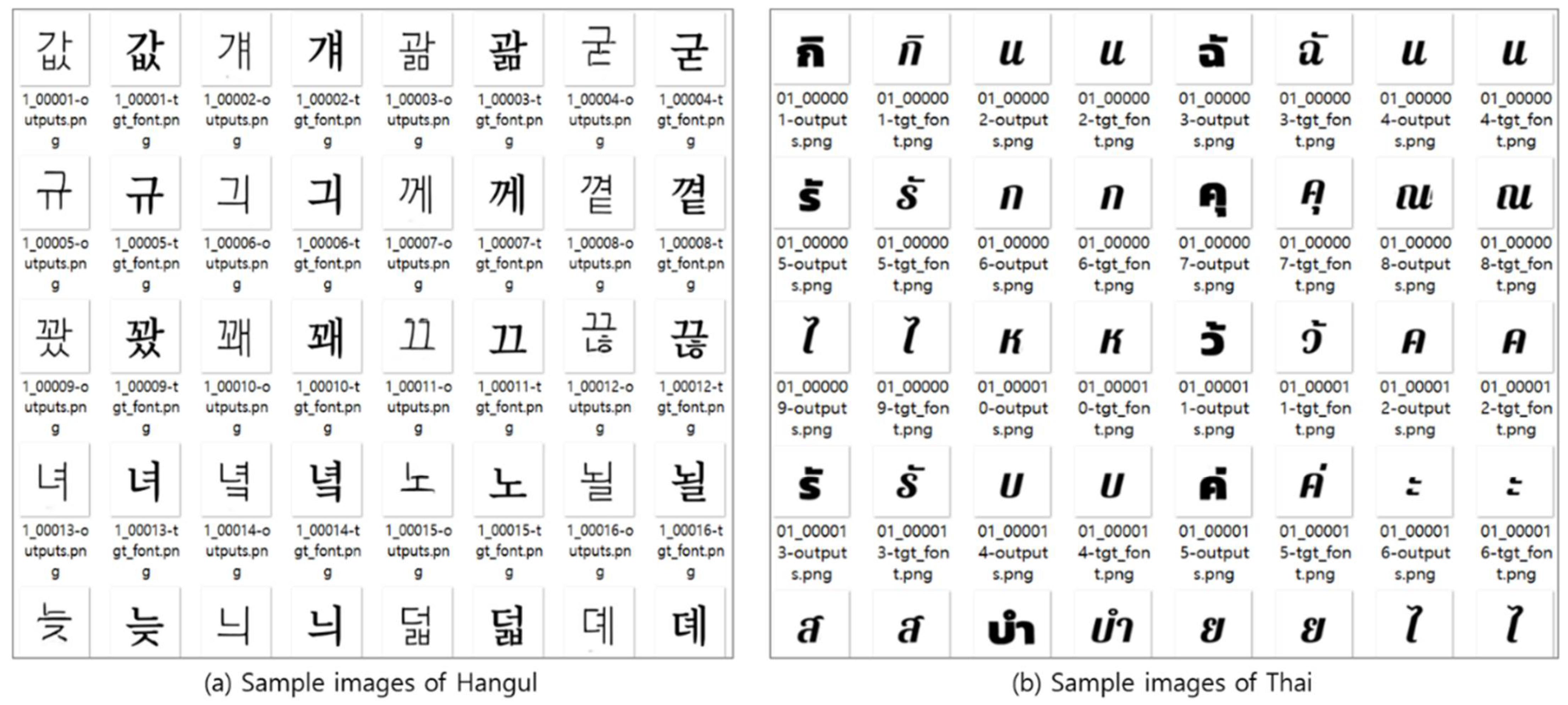
Figure 19a shows the result of generating 10 styles for the first 512 Korean characters seen for the first time, and
Figure 19b shows the result of generating two styles for the first 13 Thai characters seen for the first time (zero-shot multi-lingual generation).
Hangul has 14 consonants and 10 vowels, and the sum of the initial (19 consonants) + middle (21 vowels) + final (28 consonants) forms 11,172 characters (19 × 21 × 28) [
20]. Thai has 44 consonants, seven upper vowels, and nine highest, and four lower vowels (including cases without each) composed of initial (consonant) + vowel + final (consonant), making a total of 11,088 characters (44 × 7 × 9 × 4) (
https://en.wikipedia.org/wiki/Thai_script, (accessed on 1 July 2022)).
In both Hangul and Thai, each character can be decomposed into components, resulting in the generation of each character by inputting the Chinese character component into a trained model. The content of the generated character is regenerated well, but style conversion is not performed because the fonts used for each language are different. The model trained only Chinese characters; however, if any language, including Korean and Thai, can be decomposed into its component parts, then the CCFont model can work on it.
8. Conclusions
In this study, we proposed a CCFont model that can convert high-quality Chinese character styles using Chinese character components and can generate Hangul and Thai with zero-shot without any additional training. CCFont is an automatic Chinese character generation model with a simple structure that conserves time and resources and produces high-quality results. To generate new Chinese fonts, it separates up to 17 Chinese characters and converts most Chinese characters into styles in a short amount of time. It is possible to generate not only TC Chinese characters but also SC Chinese, Korean, and Thai characters, and it can be applied to all fonts that can be separated into unattended components, including Japanese.
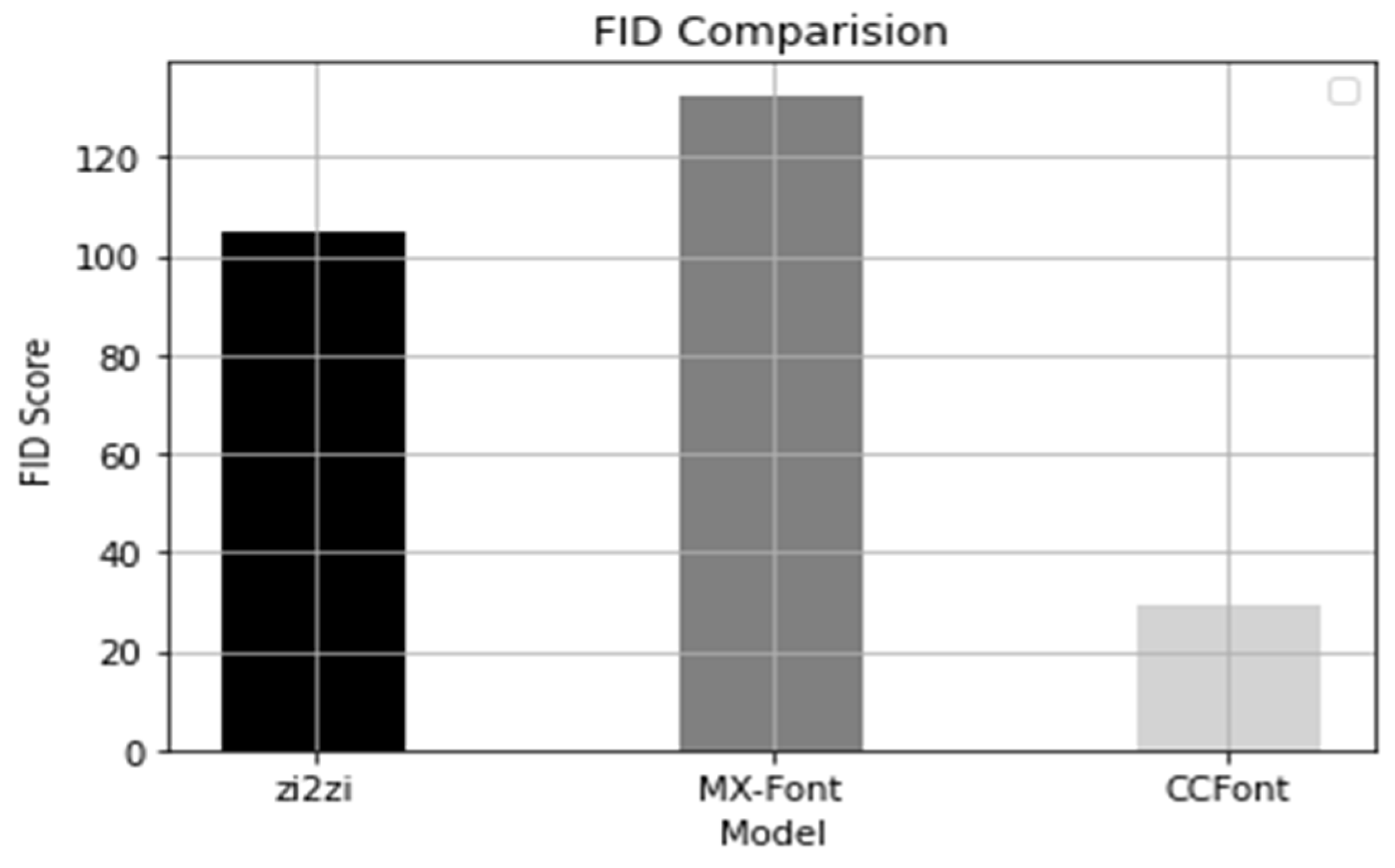
We also demonstrated that converting style images using component images can reduce failure cases, produce high-quality images, and save time and resources because of the concise structure of the model. In addition, we compared our results with those of relevant models to demonstrate better performance. In SSIM, the CCFont model was slightly inferior to the finetuned zi2zi model but superior to the MX-Font model, and the FID score was the best of the three models.
In contrast to structural issues, some of the failure cases can be attributed to the incompatibility of different fonts between countries and the method of separating components. This aspect needs to be developed and improved in the near future.



 ) is generated without failure. In addition, there is a problem with compatibility owing to the font style of different characters for each country.
) is generated without failure. In addition, there is a problem with compatibility owing to the font style of different characters for each country.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}