



Typhoon Track Prediction Based on Deep Learning

Abstract
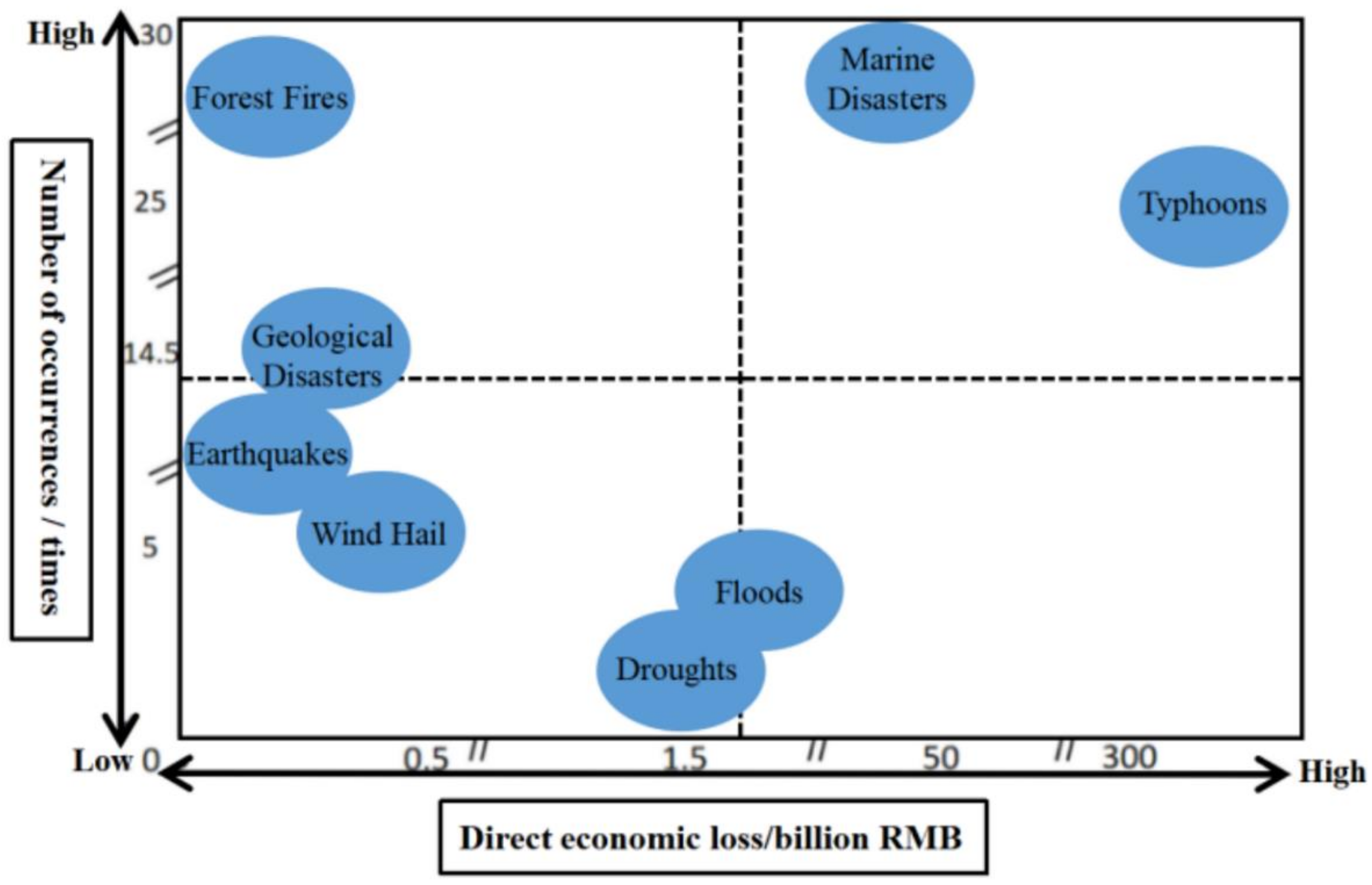
:1. Introduction
- Data Pre-processing
- Multi-feature selection
- Construction of prediction model
2. Materials and Methodology
2.1. Typhoon Dataset
2.1.1. Dataset Acquisition
2.1.2. Missing Filling
2.2. Typhoon Path Prediction Model Based on C-LSTM Network
2.2.1. Multi-Feature Selection
- Stability test.
- 2.
- Cointegration test.
- 3.
- Granger causality test.
2.2.2. Model
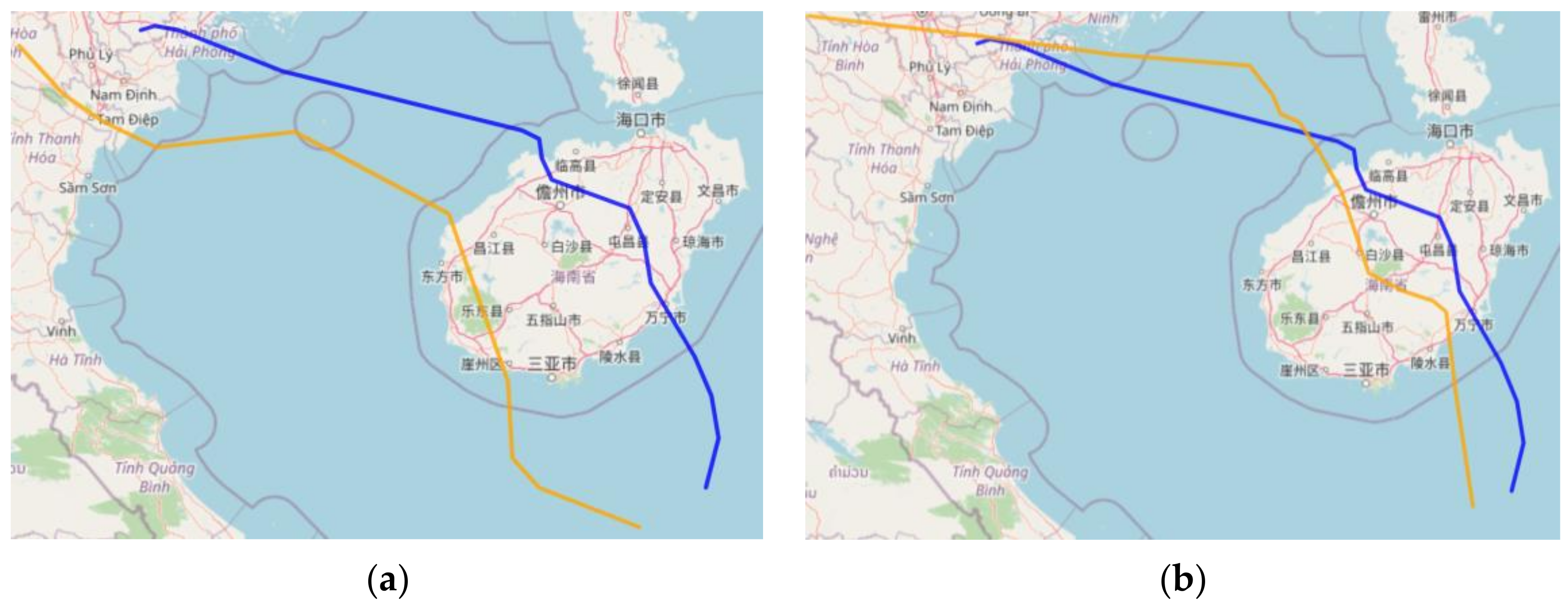
3. Experiment Results and Analysis
3.1. Number of Iterations Level
3.2. Comparison Experiments Level
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, X.Y. A synthesis of traditional models and neural networks for predicting typhoon tracks. Sci. Advis. (Sci. Technol.—Manag.) 2020, 4, 62–65. [Google Scholar]
- Liu, Y.D.; Wang, B.; Hou, Z.M. Application of the Optimal Decision Method to Typhoon Track Forecasting. J. Trop. Meteorol. 2003, 19, 219–224. [Google Scholar]
- Zou, J.P. Analysis of Typhoon “Rammasu” rainstorm in central and western Hainan Province. Mod. Agric. Sci. Technol. 2017, 24, 209–210. [Google Scholar]
- Burpee, R.W. The Sanders Barotropic Tropical Cyclone Track Prediction Model (SANBAR). Meteorol. Monogr. 2008, 33, 233–240. [Google Scholar] [CrossRef]
- Chen, Z.T.; Dai, G.F.; Luo, Q.H.; Zhong, S.X.; Zhang, Y.X.; Dao-Sheng, X.U.; Huang, Y.Y. Study on the Coupling of Model Dynamics and Physical Processes and Its Influence on the Forecast of Typhoons. J. Trop. Meteorol. 2016, 32. [Google Scholar] [CrossRef]
- Yang, C.; Min, J.; Liu, Z. Technology, The Impact of AMSR2 Radiance Data Assimilation on the Analysis and Forecast of Typhoon Son-Tinh. Chin. J. Atmos. Sci. 2017, 41, 13. [Google Scholar] [CrossRef]
- Neumann, C.J. An Alternate to the HURRAN (Hurricane Analog) Tropical Cyclone Forecast System; Scientific Services Division: Fort Worth, TX, USA, 1972. [Google Scholar]
- Liao, M.; Huang, L.; Hu, J. CLIPER Model of Track Prediction for Typhoons over the Northwestern Pacific on the Occasion of Shipping. Navig. China 1996, 43–50. [Google Scholar]
- Hu, J.; Chang, M.; Huang, L.; Liao, M. The CLIPER Models for Predicting Tracks of the South China Sea Typhoon. Trans. Oceanol. Limnol. 1994, 11, 191–201. [Google Scholar]
- Huang, L.; Liao, M.; Hu, J. CLIPER Model of Prediction for Tracks of Typhoon over the East China Sea. Mar. Forecast. 1994, 11, 12. [Google Scholar]
- Xiong, X.; Kai, Y.U.; Xiao, K. Prediction of Typhoon Path Based on Weather Similarity Condition. J. Geomat. 2017, 42, 3. [Google Scholar]
- Huo, Z.; Duan, W. The application of the orthogonal conditional nonlinear optimal perturbations method to typhoon track ensemble forecasts. Sci. China Earth Sci. 2019, 62, 376–388. [Google Scholar] [CrossRef]
- Song, H.J.; Huh, S.H.; Kim, J.H.; Ho, C.H.; Park, S.K. Typhoon Track Prediction by a Support Vector Machine Using Data Reduction Methods. In Proceedings of the International Conference on Computational and Information Science, Xi’an, China, 15–19 December 2005. [Google Scholar]
- Huang, X.Y.; Long, J.; Shi, X.M. A Nonlinear Artificial Intelligence Ensemble Prediction Model Based on EOF for Typhoon Track. In Proceedings of the 2011 Fourth International Joint Conference on Computational Sciences and Optimization, Kunming/Lijiang, China, 15–19 April 2011. [Google Scholar]
- Kim, H.S.; Kim, J.H.; Ho, C.H.; Chu, P.S. Pattern classification of typhoon tracks using fuzzy c-means clustering method and related large-scale circulations. Proc. Korean Meteorol. Soc. Conf. 2010, 4, 171. [Google Scholar]
- Tan, J.; Chen, S.; Wang, J. Western North Pacific tropical cyclone track forecasts by a machine learning model. Stoch. Environ. Res. Risk Assess. 2021, 35, 1113–1126. [Google Scholar] [CrossRef]
- Kovordanyi, R.; Roy, C. Cyclone track forecasting based on satellite images using artificial neural networks. ISPRS J. Photogramm. Remote Sens. 2009, 64, 513–521. [Google Scholar] [CrossRef]
- Shao, L.M.; Fu, G.; Chao, X.C.; Zhou, J. Application of BP neural network to forecasting typhoon tracks. J. Nat. Disasters 2009, 18, 104–111. [Google Scholar]
- Gao, S.; Zhao, P.; Pan, B.; Li, Y.; Zhou, M.; Xu, J.; Zhong, S.; Shi, Z. A nowcasting model for the prediction of typhoon tracks based on a long short term memory neural network. Acta Oceanol. Sin. 2018, 37, 12–16. [Google Scholar] [CrossRef]
- Kerh, T.; Wu, S.H. Nonlinear Autoregressive Network with the Use of a Moving Average Method for Forecasting Typhoon Tracks. Int. J. Artif. Intell. Appl. 2017, 8, 57–71. [Google Scholar] [CrossRef]
- Xu, G.; Zheng, H.; Huang, G.; Wu, F.; Mathematics, S.O.; University, S.J. Typhoon Track Prediction Based on Gated Recurrent Unit Neural Network. Comput. Appl. Softw. 2019, 36, 7. [Google Scholar]
- Sophie, G.R.; Mo, Y.; Guillaume, C.; Christina, K.B.; Balázs, K.; Claire, M. Tropical Cyclone Track Forecasting Using Fused Deep Learning from Aligned Reanalysis Data. Front. Big Data 2020, 3, 1. [Google Scholar]
- Sun, Y.; Song, Y.; Qiao, B.; Li, B. Distributed Typhoon Track Prediction Based on Complex Features and Multitask Learning. Complexity 2021, 2021, 5661292. [Google Scholar] [CrossRef]
- Mario, R.; Sangseung, L.; Soohwan, J.; Donghyun, Y. Prediction of a typhoon track using a generative adversarial network and satellite images. Sci. Rep. 2019, 9, 6057. [Google Scholar]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Bates, J.M.; Granger, C. The Combination of Forecasts. J. Oper. Res. Soc. 1969, 20, 451–468. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control. 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Huang, S.Y.; Jin, L.; Yao, C.; Huang, M.C. An Objective Forecasting Method for the Movement Path of Typhoons in the South China Sea in Summer. J. Nanjing Meteorol. Inst. 2008, 31, 287–292. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Description | Variable Name | Description |
|---|---|---|---|
| SID | Tropical cyclone number | BASIN | Ocean area code where the typhoon center is located, WP Northwest Pacific region |
| SEASON | Year | ||
| NUMBER | The base number of the system | ||
| IFLAG | Identifies the observation point that provides data at the current moment | GUSTS | Maximum instantaneous wind speed near the center (i.e., gust). Unit: knot |
| WIND | Maximum sustained wind speed at the current moment. Unit: knot | R_DIR | The direction of the quadrant corresponds to the radius. NE-Northeast, SE-Southeast, SW-Southwest, NW-Northwest |
| PRES | Minimum sea level pressure. Unit: hPa | ||
| SUBREGION | Sub-region code where the typhoon center is located | R_LONG | The radius of maximum wind. Unit: nm |
| NAME | International name of the typhoon | R_SHORT | Minimum wind radius. Unit: nm |
| ISO_TIME | ISO format time. Recorded at 3-h intervals | TRACK_TYPE | Track type |
| CAT | cyclone nature or category. DS-disturbance, TS-tropical storm, SS-subtropical storm, ET-extrapolation, NR-unreported, MM-mixed (conflicting reports among multiple agencies) | SPEED | The speed at which the center of a typhoon moves. Unit: knot |
| DIR | The direction of movement of the typhoon center. Unit: ° | ||
| EYE | The diameter of the wind eye. Unit: nm | ||
| LAT | Latitude at which the typhoon is currently located | LON | Current longitude of the typhoon |
| LANDFALL | Used to determine whether landfall is possible within 6 h | POCI | Outermost isobaric pressure (i.e., outer pressure). Unit: hPa |
| DIST2LAND | Distance from the current position to the nearest land. Unit: km | ROCI | Radius of outermost isobar. Unit: nm |
| Meteorological Variables | WIND | PRES | ROCI | EYE |
|---|---|---|---|---|
| RMSE | 0.035081 | 0.03641 | 0.03694 | 0.03589 |
| Meteorological Variables | p-Value | Meteorological Variables | p-Value |
|---|---|---|---|
| CAT | <0.01 | R_LONG | 0.06493 |
| LAT | <0.01 | R_SHORT | 0.08179 |
| LON | <0.01 | POCI | 0.6398 |
| TRACK_TYPE | <0.01 | ROCI | <0.01 |
| DIST2LAND | <0.01 | RMW | <0.01 |
| LANDFALL | <0.01 | EYE | 0.03763 |
| WIND | <0.01 | GUSTS | 0.4172 |
| PRES | 0.5646 | SPEED | <0.01 |
| R_DIR | <0.01 | DIR | <0.01 |
| Meteorological Variables | p-Value (lon) | p-Value (lat) | Meteorological Variables | p-Value (lon) | p-Value (lat) |
|---|---|---|---|---|---|
| CAT | <1 | <0.001 | R_SHORT | <1 | <0.05 |
| TRACK_TYPE | <0.05 | <1 | POCI | <1 | <0.05 |
| DIST2LAND | <0.001 | <0.05 | ROCI | <1 | <1 |
| LANDFALL | <0.001 | <0.1 | RMW | <1 | <1 |
| WIND | <0.001 | <0.001 | EYE | <1 | <1 |
| PRES | <0.1 | <0.001 | GUSTS | <0.05 | <1 |
| R_DIR | <0.05 | <0.1 | SPEED | <0.001 | <1 |
| R_LONG | <1 | <0.1 | DIR | <0.001 | <0.001 |
| Model Structure | Average Surface Distance Error (km) | |
|---|---|---|
| C-LSTM + MSE + Adam | Training set | 19.795 |
| Test set | 20.651 | |
| Validation set | 20.232 | |
| C-LSTM + cross-entropy loss function + Adam | Training set | 14.215 |
| Test set | 14.291 | |
| Validation set | 15.487 | |
| C-LSTM + cross-entropy loss function + SGD | Training set | 20.716 |
| Test set | 21.623 | |
| Validation set | 21.303 | |
| LSTM + MSE + Adam | Training set | 23.999 |
| Test set | 24.15 | |
| Validation set | 23.546 | |
| LSTM + cross-entropy loss function + Adam | Training set | 22.69 |
| Test set | 23.981 | |
| Validation set | 22.011 | |
| LSTM + cross-entropy loss function + SGD | Training set | 37.0865 |
| Test set | 37.289 | |
| Validation set | 37.44 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, J.; Xu, N.; Cui, Y. Typhoon Track Prediction Based on Deep Learning. Appl. Sci. 2022, 12, 8028. https://doi.org/10.3390/app12168028
Ren J, Xu N, Cui Y. Typhoon Track Prediction Based on Deep Learning. Applied Sciences. 2022; 12(16):8028. https://doi.org/10.3390/app12168028
Chicago/Turabian StyleRen, Jia, Nan Xu, and Yani Cui. 2022. "Typhoon Track Prediction Based on Deep Learning" Applied Sciences 12, no. 16: 8028. https://doi.org/10.3390/app12168028
APA StyleRen, J., Xu, N., & Cui, Y. (2022). Typhoon Track Prediction Based on Deep Learning. Applied Sciences, 12(16), 8028. https://doi.org/10.3390/app12168028