

Predictability of COVID-19 Infections Based on Deep Learning and Historical Data
 , , ,
, , ,  ,
,  ,
,
Abstract
:1. Introduction
1.1. Study Motivation
1.2. Related Work
- •
- We used a prediction window of the 14 previous days to predict new infections one day ahead, which corresponds to the incubation period of COVID-19. Intuitively, any new infection may result from a person who was infected during the previous 14 days or less.
- •
- Through our study, the simple-structure DL techniques in use (RNN, GRU, and LSTM) are found to yield good forecasts although the available datasets are of limited size (due to the fact that COVID-19 data are released daily). Therefore, it is not necessary to train complex-structure DL algorithms for small (not guaranteed) improvements in accuracy. Simple DL algorithms are sufficient in the case of COVID-19.
- •
- To the best of the authors’ knowledge, our study is among a small number of works covering a dataset that includes the periods before and after the appearance of vaccines. For this reason, our study is expected to capture the effect of vaccination on the disease spread.
- •
- The case studies considered possess different features in terms of demographic patterns, climatic conditions, cultures, quality of health systems, economic situation, etc. This may help evaluate the predictability of new COVID-19 infections using the same DL tools as in various case studies.
2. Material and Methods
2.1. Design Methodology
2.2. Problem Statement
2.3. Recurrent Neural Networks
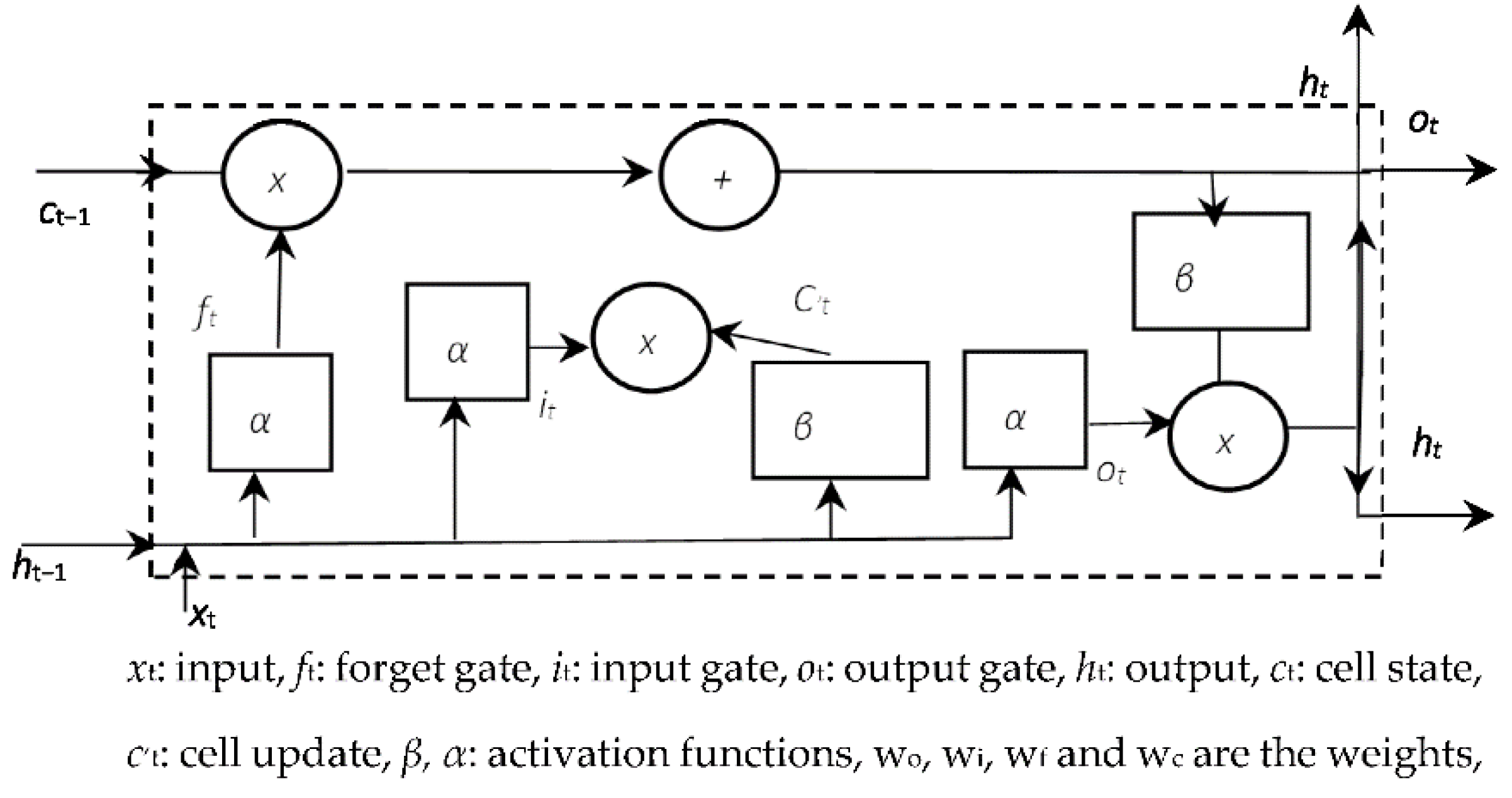
2.4. Long Short-Term Memory (LSTM)
2.5. Study Areas and Datasets
3. Results and Discussion
3.1. DL Algorithms’ Hyperparameters
3.2. Experimental Results
3.3. Discussion
- •
- Case of Saudi Arabia: From Table 3, the average MAPE of the three DL algorithms is around 25%, which is a moderate value. The higher the MAPE, the better the prediction. However, the three techniques’ R2 is about 0.8 (1 is the ideal value). Other studies, such as [34,35], have tackled the problem of predicting the number of COVID-19 infections in Saudi Arabia while covering different periods and datasets. Compared with other studies in the same territory, such as [35], our R-squared value can be considered good, since the period covered by our models is larger than the one covered by that study. This value can be considered good and reflects an interesting predictability of daily new infections in Saudi Arabia. The average RMSE is around 330 new infections per day. It can be observed also that RNN has been found to outperform GRU and LSTM, since it yielded the best MAPE, R2, and RMSE. Therefore, for the case study of Saudi Arabia, a less complex DL algorithm in terms of structure and training time is preferred for modeling daily new COVID-19 cases. Saudi Arabia’s population is a mixture of nationalities, religions, and culture. In addition, Saudi Arabia is a host to two holy mosques at Makkah and Madinah, which are visited by Muslim people who perform Hajj and Umrah, which may induce hidden features in terms of factors impacting new infections. The desert climate of Saudi Arabia may be one the factors negatively affecting daily new infections. From Figure 3a, it can be observed that the actual recorded new infections curve and the DL algorithms curves were almost the same during the first 100 days of the testing period (out-of-sample) and that there were some fluctuations during the remaining days of the same period, with a relatively small superiority for the RNN curve.
- •
- Case of Egypt: Based on Table 3’s performance measures, the MAPE of the three algorithms is around 8%, which can be considered good. In addition, the values of RMSE are also good (around 160 cases per day). However, the values of R2 are around 0.75. This value can be considered moderate, which may be due to jumps in new infections recorded around days 55 and 82 during the out-of-sample testing period. As observed from Figure 3b, sudden high daily new infections were recorded and the DL algorithms did not capture those jumps. As in the case of Saudi Arabia, the RNN has the best ability to capture the hidden features of the data for the case of Egypt. Therefore, an RNN can be recommended in this case study.
- •
- Case of Italy: The GRU was found to better model the dynamics of daily new infections since it yielded the lowest MAPE (24.4818%), the highest R2 (0.8499), and the lowest RMSE (2648 cases/day). However, the MAPE value can be considered high, which indicates bad predictability of the daily new infections using DL. The GRU DL network has an intermediately complex structure, situated between a simple structure (RNN) and a complex structure (LSTM). Therefore, this may result in a moderate training time. In conclusion, the GRU can be recommended for the case study of Italy. The relatively bad performance of the three DL techniques can be attributed to the fluctuations in daily new infections noticed particularly starting from Day 95 (Figure 3c). Note that, among recent studies concerning the prediction of the number COVID-19 infections in Italy, the authors of [36] focused on predicting the reproduction number, which is complementary to the number of infections predicted in our study. Future directions can be built around a combination of the two topics.
- •
- Case of India: The best MAPE was provided by the RNN (17.58%) and the best R2 and RMSE (0.8759 and 3902, respectively) were yielded by the GRU DL algorithm. In this case study, the GRU can be adopted as the best forecasting technique. From Figure 3d, it can be observed that LSTM fails in capturing the strong fluctuation in daily new infections occurring around Day 120. However, the average value of the MAPE of the three techniques is relatively high, which reflects the relatively bad predictability of the daily new infections using DL.
- −
- We conducted various experiments (for the four case studies) while varying the number of iterations (epochs). The quality of the DL models was measured by calculating three performance metrics (the RMSE, the coefficient of determination (R2), and the mean absolute percentage error (MAPE)) for the out-of-sample datasets.
- −
- As seen from Table 4 and Table 5, the coefficient of determination was found to be more than 0.8 and reached 0.97 in some cases (this value varies between 0 and 1 for the ideal fit). In addition, the MAPE and RMSE were in good ranges, which indicates the “good” quality of our investigated models and no overfitting.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, P.; Yang, X.-L.; Wang, X.-G.; Hu, B.; Zhang, L.; Zhang, W.; Si, H.-R.; Zhu, Y.; Li, B.; Huang, C.-L.; et al. A pneumonia outbreak associated with a new coronavirus of probable bat origin. Nature 2020, 579, 270–273. [Google Scholar] [CrossRef] [PubMed]
- Gorbalenya, A.E.; Baker, S.C.; Baric, R.S.; de Groot, R.J.; Drosten, C.; Gulyaeva, A.A.; Haagmans, B.L.; Lauber, C.; Leontovich, A.M.; Neuman, B.W.; et al. Coronaviridae Study Group of the International Committee on Taxonomy of Viruses. The species Severe acute respiratory syndrome-related coronavirus: Classifying 2019-nCoV and naming it SARS-CoV-2. Nat. Microbiol. 2020, 5, 536–544. [Google Scholar] [CrossRef]
- Nikolaidis, M.; Papakyriakou, A.; Chlichlia, K.; Markoulatos, P.; Oliver, S.G.; Amoutzias, G.D. Comparative Analysis of SARS-CoV-2 Variants of Concern, Including Omicron, Highlights Their Common and Distinctive Amino Acid Substitution Patterns, Especially at the Spike ORF. Viruses 2022, 14, 707. [Google Scholar] [CrossRef] [PubMed]
- Nikolaidis, M.; Markoulatos, P.; Van de Peer, Y.; Oliver, S.G.; Amoutzias, G.D. The Neighborhood of the Spike Gene Is a Hotspot for Modular Intertypic Homologous and Nonhomologous Recombination in Coronavirus Genomes. Mol. Biol. Evol. 2022, 39, 1. [Google Scholar] [CrossRef] [PubMed]
- Cameroni, E.; Bowen, J.E.; Rosen, L.E.; Saliba, C.; Zepeda, S.K.; Culap, K.; Pinto, D.; VanBlargan, L.A.; De Marco, A.; di Iulio, J.; et al. Broadly neutralizing antibodies overcome SARS-CoV-2 Omicron antigenic shift. Nature 2022, 602, 664–670. [Google Scholar] [CrossRef]
- Amoutzias, G.D.; Nikolaidis, M.; Tryfonopoulou, E.; Chlichlia, K.; Markoulatos, P.; Oliver, S.G. The Remarkable Evolutionary Plasticity of Coronaviruses by Mutation and Recombination: Insights for the COVID-19 Pandemic and the Future Evolutionary Paths of SARS-CoV-2. Viruses 2022, 14, 78. [Google Scholar] [CrossRef]
- Shahid, F.; Aneela, Z.; Muneeb, M. Predictions for COVID-19 with deep learning models of LSTM, GRU and Bi-LSTM. Chaos Solitons Fractals 2020, 140, 110212. [Google Scholar] [CrossRef]
- Farooq, J.; Bazaz, M.A. A deep learning algorithm for modeling and forecasting of COVID-19 in five worst affected states of India. Alex. Eng. J. 2021, 60, 587–596. [Google Scholar] [CrossRef]
- Nathan, C. A Deep Learning Model for Predicting COVID-19 Transmission in Connecticut 2021. Honors Scholar Theses. 782. Available online: https://opencommons.uconn.edu/srhonors_theses/782 (accessed on 20 March 2022).
- Scarabaggio, P.; Carli, R.; Cavone, G.; Epicoco, N.; Dotoli, M. Nonpharmaceutical Stochastic Optimal Control Strategies to Mitigate the COVID-19 Spread. IEEE Trans. Autom. Sci. Eng. 2022, 19, 560–575. [Google Scholar] [CrossRef]
- Carli, R.; Cavone, G.; Epicoco, N.; Scarabaggio, P.; Dotoli, M. Model predictive control to mitigate the COVID-19 outbreak in a multi-region scenario. Annu. Rev. Control 2020, 50, 373–393. [Google Scholar] [CrossRef]
- Zrieq, R.; Boubaker, S.; Kamel, S.; Alzain, M.; Algahtani, F.D. Analysis and Modeling of COVID-19 Epidemic Dynamics in Saudi Arabia Using SIR-PSO and Machine Learning Approaches. J. Infect. Dev. Ctries. 2022, 16, 90–100. [Google Scholar] [CrossRef] [PubMed]
- Scarabaggio, P.; Carli, R.; Cavone, G.; Epicoco, N.; Dotoli, M. Modeling, Estimation, and Optimal Control of Anti-COVID-19 Multi-dose Vaccine Administration. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 990–995. [Google Scholar] [CrossRef]
- Moein, S.; Nickaeen, N.; Roointan, A.; Borhani, N.; Heidary, Z.; Javanmard, S.H.; Ghaisari, J.; Gheisari, Y. Inefficiency of SIR models in forecasting COVID-19 epidemic: A case study of Isfahan. Sci. Rep. 2021, 11, 4725. [Google Scholar] [CrossRef] [PubMed]
- Cooper, I.; Mondal, A.; Antonopoulos, C.G. A SIR model assumption for the spread of COVID-19 in different communities. Chaos Solitons Fractals 2020, 139, 110057. [Google Scholar] [CrossRef] [PubMed]
- Alzahrani, S.I.; Aljamaan, I.A.; Al-Fakih, E.A. Forecasting the spread of the COVID-19 pandemic in Saudi Arabia using ARIMA prediction model under current public health interventions. J. Infect. Public Health 2020, 13, 914–919. [Google Scholar] [CrossRef]
- Alabdulrazzaq, H.; Alenezi, M.N.; Rawajfih, Y.; Alghannam, B.A.; Al-Hassan, A.A.; Al-Anzi, F.S. On the accuracy of ARIMA based prediction of COVID-19 spread. Results Phys. 2021, 27, 104509. [Google Scholar] [CrossRef]
- Zreiq, R.; Kamel, S.; Boubaker, S.; Al-Shammary, A.A.; Algahtani, F.D.; Alshammari, F. Generalized Richards model for predicting COVID-19 dynamics in Saudi Arabia based on particle swarm optimization Algorithm. AIMS Public Health 2020, 7, 828–843. [Google Scholar] [CrossRef]
- Abbasimehr, H.; Paki, R.; Bahrini, A. A novel approach based on combining deep learning models with statistical methods for COVID-19 time series forecasting. Neural Comput. Appl. 2022, 34, 3135–3149. [Google Scholar] [CrossRef]
- Shastri, S.; Singh, K.; Deswal, M.; Kumar, S.; Mansotra, V. CoBiD-net: A tailored deep learning ensemble model for time series forecasting of covid-19. Spat. Inf. Res. 2022, 30, 9–22. [Google Scholar] [CrossRef]
- Mohimont, L.; Chemchem, A.; Alin, F.; Krajecki, M.; Steffenel, L.A. Convolutional neural networks and temporal CNNs for COVID-19 forecasting in France. Appl. Intell. 2021, 51, 8784–8809. [Google Scholar] [CrossRef]
- Zeroual, A.; Harrou, F.; Dairi, A.; Sun, Y. Deep learning methods for forecasting COVID-19 time-Series data: A Comparative study. Chaos Solitons Fractals 2020, 140, 110121. [Google Scholar] [CrossRef]
- Marzouk, M.; Elshaboury, N.; Abdel-Latif, A.; Azab, S. Deep learning model for forecasting COVID-19 outbreak in Egypt. Process Saf. Environ. Prot. 2021, 153, 363–375. [Google Scholar] [CrossRef] [PubMed]
- Elsheikh, A.H.; Saba, A.I.; Abd Elaziz, M.; Lu, S.; Shanmugan, S.; Muthuramalingam, T.; Kumar, R.; Mosleh, A.O.; Essa, F.A.; Shehabeldeen, T.A. Deep learning-based forecasting model for COVID-19 outbreak in Saudi Arabia. Process Saf. Environ. Prot. 2021, 149, 223–233. [Google Scholar] [CrossRef] [PubMed]
- Nabi, K.N.; Tahmid, M.T.; Rafi, A.; Kader, M.E.; Haider, M.A. Forecasting COVID-19 cases: A comparative analysis between recurrent and convolutional neural networks. Results Phys. 2021, 24, 104137. [Google Scholar] [CrossRef] [PubMed]
- Devaraj, J.; Elavarasan, R.M.; Pugazhendhi, R. Forecasting of COVID-19 cases using deep learning models: Is it reliable and practically significant? Results Phys. 2021, 21, 103817. [Google Scholar] [CrossRef] [PubMed]
- Kumar, R.L.; Khan, F.; Din, S.; Band, S.S.; Mosavi, A.; Ibeke, E. Recurrent Neural Network and Reinforcement Learning Model for COVID-19 Prediction. Front. Public Health 2021, 9, 744100. [Google Scholar] [CrossRef] [PubMed]
- Liao, Z.; Lan, P.; Fan, X.; Kelly, B.; Innes, A.; Liao, Z. SIRVD-DL: A COVID-19 deep learning prediction model based on time-dependent SIRVD. Comput. Biol. Med. 2021, 138, 104868. [Google Scholar] [CrossRef]
- Rauf, H.T.; Lali, M.I.U.; Khan, M.A.; Kadry, S.; Alolaian, H.; Razaq, A.; Irfan, R. Time series forecasting of COVID-19 transmission in Asia Pacific countries using deep neural networks. Pers. Ubiquitous Comput. 2021, 25, 1–18. [Google Scholar] [CrossRef]
- Ayoobi, N.; Sharifrazi, D.; Alizadehsani, R. Time series forecasting of new cases and new deaths rate for COVID-19 using deep learning methods. Results Phys. 2021, 27, 104495. [Google Scholar] [CrossRef]
- Alassafi, M.O.; Jarrah, M.; Alotaibi, R. Time series predicting of COVID-19 based on deep learning. Neurocomputing 2022, 468, 335–344. [Google Scholar] [CrossRef]
- Tanaka, H.; Ogata, T.; Shibata, T.; Nagai, H.; Takahashi, Y.; Kinoshita, M.; Matsubayashi, K.; Hattori, S.; Taniguchi, C. Shorter Incubation Period among COVID-19 Cases with the BA.1 Omicron Variant. Int. J. Environ. Res. Public Health 2022, 19, 6330. [Google Scholar] [CrossRef]
- Koureas, M.; Amoutzias, G.D.; Vontas, A.; Kyritsi, M.; Pinaka, O.; Papakonstantinou, A.; Dadouli, K.; Hatzinikou, M.; Koutsolioutsou, A.; Mouchtouri, V.A.; et al. Wastewater monitoring as a supplementary surveillance tool for capturing SARS-COV-2 community spread. A case study in two Greek municipalities. Environ. Res. 2021, 200, 111749. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, H.F.; Khaloofi, H.; Azhar, Z.; Algosaibi, A.; Hussain, J. An Improved COVID-19 Forecasting by Infectious Disease Modelling Using Machine Learning. Appl. Sci. 2021, 11, 11426. [Google Scholar] [CrossRef]
- Shahin, A.I.; Almotairi, S. A Deep Learning BiLSTM Encoding-Decoding Model for COVID-19 Pandemic Spread Forecasting. Fractal Fract. 2021, 5, 175. [Google Scholar] [CrossRef]
- Gatto, A.; Aloisi, V.; Accarino, G.; Immorlano, F.; Chiarelli, M.; Aloisio, G. An Artificial Neural Network-Based Approach for Predicting the COVID-19 Daily Effective Reproduction Number Rt in Italy. AI 2022, 3, 146–163. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Ref. | Country/Location | Used Technique | Period | Results | Advantages | Shortcomings |
|---|---|---|---|---|---|---|
| [7] | Brazil, Germany, India, Italy, Russia | LSTM, Bi-LSTM | 22 January 2020–27 June 2020 | Bi-LSTM: Best MAE = 0.0070, RMSE = 0.0077, R2 = 0.9997 | Good generalization | Requires data scaling |
| [8] | India | DL using incremental learning | March 2020–August 2020 | Results are different from one state to another (minimum MAE around 1.18%) | Ability to forecast 30 days. No need to retrain the model when new data are available | Training back-propagation algorithm may be trapped into local minima |
| [9] | USA/Connecticut | LSTM, GCN-LSTM | 20 May 2020–8 October 2020 | Worse than classical ARIMA | Ability to work at the macro level | ARIMA model provided better results than DL |
| [19] | USA, Brazil, India, France, Russia, UK, Italy, Spain, Turkey, Germany | GRU, LSTM, CNN | 20 January 2020–28 March 2021 | Good results in terms of symmetric MAPE and RMSE | Use of an augmentation time-series technique to generate a larger dataset | Difficulty of hyperparameter selection |
| [20] | USA, India, Brazil | Bi-LSTM, Convolutional LSTM and ensemble method including both methods | January 2020–April 2021 | MAPE = 0.87–1.90, Accuracy = 98.10–99.13% | Combining two DL algorithms has provided good forecasts | No indication about the historical data used to predict the future values |
| [21] | France | CNN | Jan. 2020–March 2020 | 1% error rate in the national level | Ability to predict using a limited dataset | Relative discrepancy between national and regional levels |
| [22] | Italy, Spain, France, China, USA, Australia | RNN, LSTM, Bi-LSTM, GRU, VAE | 22 January 2020–17 June 2020 | VAE outperformed the other DL algorithms | Ability to predict using a limited dataset | Use of a limited number of features (only 1) |
| [23] | Egypt | LSTM, CNN, MLP | 14 February 2020–15 August 2020 | Determination coefficient more than 0.999 for DL algorithms | Forecasting horizon of 1 week and 1 month ahead | Using 20 previous data, which are more than the incubation period (14 days) |
| [24] | Saudi Arabia, Brazil, India, South Africa, Spain, USA | LSTM | 2 March 2020–10 October 2020 | LSTM 11% better than ARIMA | Capability of learning nonlinear features of COVID-19 data | Hyperparameters determined using a parametric study |
| [25] | Brazil, Russia, UK | LSTM, GRU, CNN, MCNN | Up to 18 November 2020 | CNN has outperformed in terms of performance metrics | Good performances with few data | LSTM provided bad results for long run forecasts |
| [26] | India/Chennai | ARIMA, LSTM, SLSTM, Prophet | 22 January 2020–8 May 2020 | LSTM 2% better than other DL algorithms | Good performances are reported by the authors | Reliability depends on the dataset and location |
| [27] | India | RNN, Modified LSTM, DRL | 30 January 2020–16 August 2020 | MLSTM-DRL was found to outperform the other methods | High predictability and good agreement between predicted and recorded data | Case-sensitive |
| [28] | India, Argentina, France, South Korea, Germany, Russia, UK, Italy | Combination of SIRVD and DL algorithms | 15 January 2021–27 May 2021 | SIRVD-DL: R2 = 0.995 and MAPE = 0.92 outperformed standalone DL methods | Hybrid methods yielded better results than standalone methods | Computationally hard |
| [29] | Pakistan, Afghanistan, India, Bangladesh | LSTM, RNN, GRU | 22 January 2020–21 June 2020 | Accuracy rate greater than 90% | Ability to forecast the next 10 coming days | No details about hyperparameters’ choice |
| [30] | Australia, Iran | LSTM, Conv-LSTM, GRU, Bi-LSTM, Bi-Conv-LSTM, Bi-GRU | 25 January 2020–19 August 2020 (Australia) 3 January 2020–6 October 2020 (Iran) | Bidirectional models were found to yield better than their simple form (without backward components) | Two techniques were reported by the authors to be used for the first time at the time of their study | No information about the hyperparameters settings |
| [31] | Malaysia, Morocco, Saudi Arabia | RNN, LSTM | 15 March 2020–3 December 2020 | 98.58% of accuracy LSTM and 93.45% RNN | Seven-day-ahead forecasts | High computational burden |
| [10] | Italy | SIRCQTHE epidemiological model | Italian real data | Efficient feedback control laws | Benefiting from modeling to design control strategies | Modeling context (the purpose of the paper is more for control not for prediction) |
| [11] | Italy | Model predictive optimal control based on SIR model | Italian multi-region study during 2020 | Synthesis of model predictive control in regional and national levels | SIRQTHE model used for a model predictive optimal control strategy | The study is relatively old and does not cover a large period of the COVID-19 pandemic |
| [16] | Saudi Arabia | ARIMA time-series model for predicting the number of people who were newly infected | 2 March 2020 to 20 April 2020 | Prediction with a horizon of 4 weeks | Useful models particularly in the beginning of the pandemic in Saudi Arabia | The results were not sufficiently accurate |
| [18] | Saudi Arabia | Generalized Richards model calibrated by particle swarm optimization (PSO) | 2 March 2020 to 10 October 2020 | Forecasting of the number of cumulative infection and the pandemic probable end date (R2 = 0.9953) | The end of the first wave of the disease in Saudi Arabia was accurately estimated | An increasing bias was observed |
| [12] | Saudi Arabia | SIR and ML learning models for predicting COVID-19 dynamics | 2 March 2020 to 21 February 2021 | Prediction of infections, recoveries, and deaths (MAPE = 7%) | Simple and generic models | Data processed forward and no effect of the neurons’ historical states |
| Country | Geographic Location | Climate | Population * |
|---|---|---|---|
| Saudi Arabia | 25°00′ N 45°00′ E | Desert | 35,836,864 |
| Egypt | 30°20′ N 31°13′ E | Dry and hot | 105,975,920 |
| India | 8°4′–37°6′ N 68°7′–7°25′ E 97°25′ east longitude | Hot and humid | 1,405,606,396 |
| Italy | 41°87′ N 12°56′ E | Mediterranean | 60,294,088 |
| Hyperparameter | Set Value |
|---|---|
| Units | 200 |
| Activation | ReLu |
| Batch size | 64 |
| Epochs | 1000 |
| Scaler | Min–Max |
| Optimizer | Adam |
| Country | Saudi Arabia | Egypt | ||||
|---|---|---|---|---|---|---|
| DL model | MAPE (%) | R2 | RMSE (case) | MAPE (%) | R2 | RMSE (case) |
| RNN | 12.09 | 0.9754 | 299 | 7.53 | 0.7984 | 164 |
| GRU | 13.30 | 0.9690 | 336 | 8.79 | 0.7609 | 179 |
| LSTM | 17.98 | 0.9438 | 453 | 8.44 | 0.7961 | 165 |
| Country | Italy | India | ||||
|---|---|---|---|---|---|---|
| DL model | MAPE (%) | R2 | RMSE (case) | MAPE (%) | R2 | RMSE (case) |
| RNN | 25.72 | 0.8245 | 2863 | 17.58 | 0.8747 | 3920 |
| GRU | 24.48 | 0.8499 | 2648 | 21.59 | 0.8759 | 3902 |
| LSTM | 25.86 | 0.8089 | 2987 | 26.27 | 0.8438 | 4378 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zrieq, R.; Kamel, S.; Boubaker, S.; Algahtani, F.D.; Alzain, M.A.; Alshammari, F.; Aldhmadi, B.K.; Alshammari, F.S.; J. Araúzo-Bravo, M. Predictability of COVID-19 Infections Based on Deep Learning and Historical Data. Appl. Sci. 2022, 12, 8029. https://doi.org/10.3390/app12168029
Zrieq R, Kamel S, Boubaker S, Algahtani FD, Alzain MA, Alshammari F, Aldhmadi BK, Alshammari FS, J. Araúzo-Bravo M. Predictability of COVID-19 Infections Based on Deep Learning and Historical Data. Applied Sciences. 2022; 12(16):8029. https://doi.org/10.3390/app12168029
Chicago/Turabian StyleZrieq, Rafat, Souad Kamel, Sahbi Boubaker, Fahad D. Algahtani, Mohamed Ali Alzain, Fares Alshammari, Badr Khalaf Aldhmadi, Fahad Saud Alshammari, and Marcos J. Araúzo-Bravo. 2022. "Predictability of COVID-19 Infections Based on Deep Learning and Historical Data" Applied Sciences 12, no. 16: 8029. https://doi.org/10.3390/app12168029
APA StyleZrieq, R., Kamel, S., Boubaker, S., Algahtani, F. D., Alzain, M. A., Alshammari, F., Aldhmadi, B. K., Alshammari, F. S., & J. Araúzo-Bravo, M. (2022). Predictability of COVID-19 Infections Based on Deep Learning and Historical Data. Applied Sciences, 12(16), 8029. https://doi.org/10.3390/app12168029