
Research on Image Matching of Improved SIFT Algorithm Based on Stability Factor and Feature Descriptor Simplification


Abstract
:1. Introduction
2. Original SIFT Algorithm
2.1. Scale Space Extreme Value Detection
2.2. Key Point Positioning
2.3. Direction Determination
2.4. Description of Key Points
3. Improved SIFT Algorithm
3.1. Scale Space Increases the Stability Factor
3.2. Simplified Feature Descriptor
4. Experimental Results and Analysis
4.1. Experimental Environment
4.2. Comparison of Experimental Results
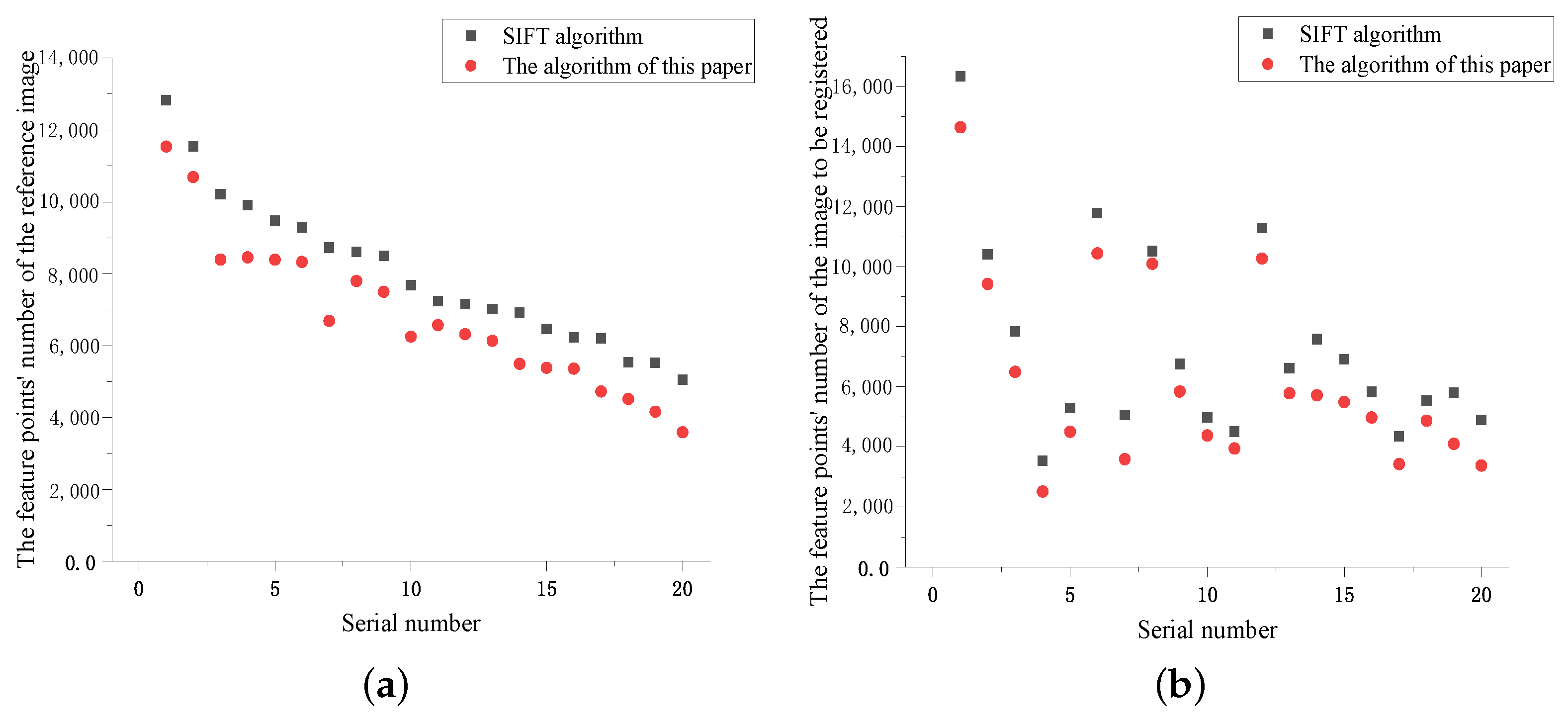
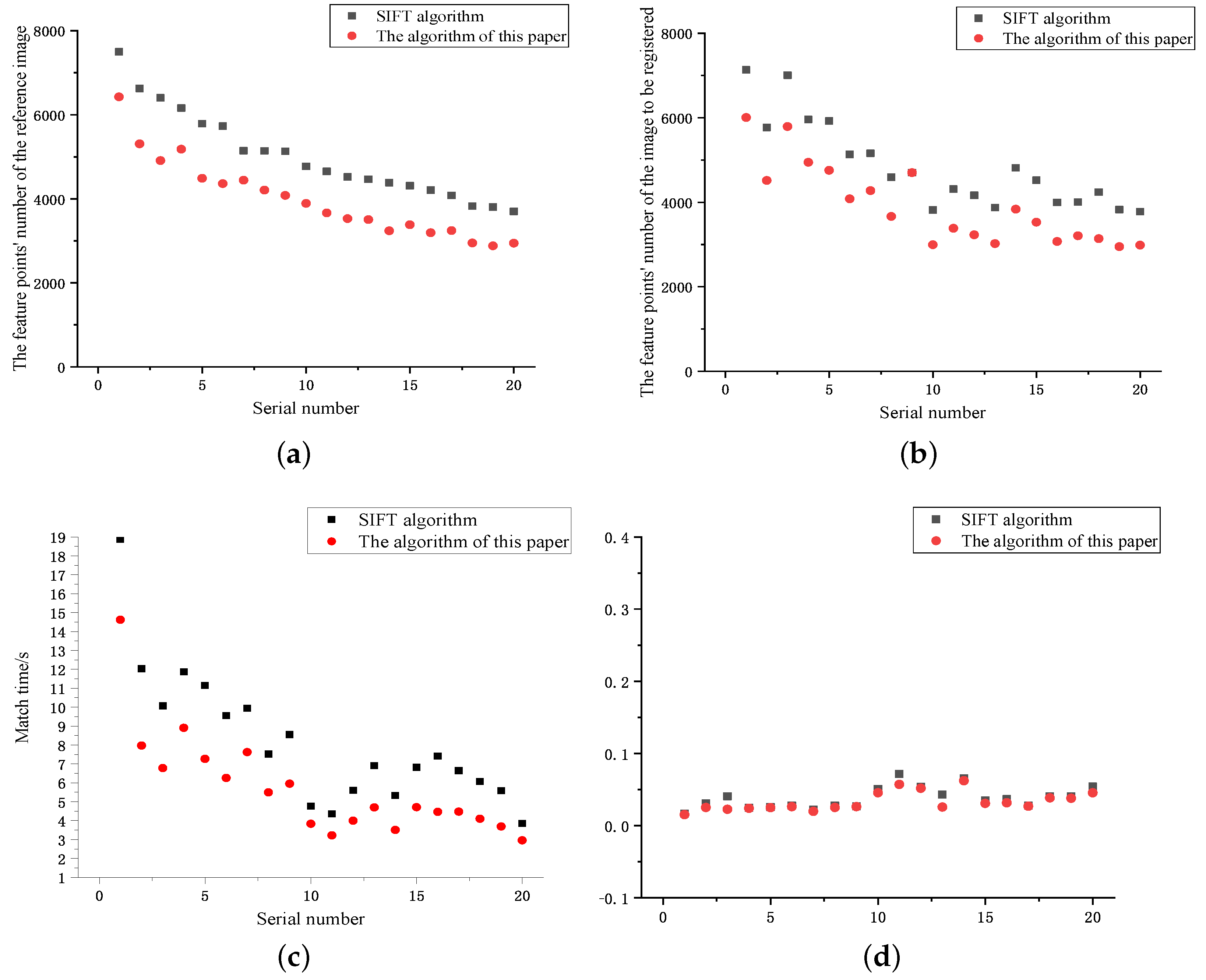
4.2.1. Comparison of Experimental Results Based on Kitti Dataset
4.2.2. Comparison of Experimental Results Based on the Euroc Dataset
4.3. Comparison with Other Algorithms
4.4. Summary of Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image matching from handcrafted to deep features: A survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Jiang, X.; Ma, J.; Xiao, G.; Shao, Z.; Guo, X. A review of multimodal image matching: Methods and applications. Inf. Fusion 2021, 73, 22–71. [Google Scholar] [CrossRef]
- Li, C.; Yu, L.; Fei, S. Large-scale, real-time 3D scene reconstruction using visual and IMU sensors. IEEE Sens. J. 2020, 20, 5597–5605. [Google Scholar] [CrossRef]
- Ciaparrone, G.; Sánchez, F.L.; Tabik, S.; Troiano, L.; Tagliaferri, R.; Herrera, F. Deep learning in video multi-object tracking: A survey. Neurocomputing 2020, 381, 61–88. [Google Scholar] [CrossRef]
- Kechagias-Stamatis, O.; Aouf, N. Automatic target recognition on synthetic aperture radar imagery: A survey. IEEE Aerosp. Electron. Syst. Mag. 2021, 36, 56–81. [Google Scholar] [CrossRef]
- Wang, M.; Li, H.; Tao, D.C.; Lu, K.; Wu, X.D. Multimodal graph-based reranking for web image search. IEEE Trans. Image Process. 2012, 21, 4649–4661. [Google Scholar] [CrossRef]
- Wang, M.; Yang, K.Y.; Hua, X.S.; Zhang, H.J. Towards a rele-vant and diverse search of social images. IEEE Trans. Multimed. 2010, 12, 829–842. [Google Scholar] [CrossRef]
- Li, J.; Allinson, N.M. A comprehensive review of current local features for computer vision. Neurocomputing 2008, 71, 1771–1787. [Google Scholar] [CrossRef]
- Erxue, C.; Zengyuan, L.; Xin, T.; Shiming, L. Application of scale invariant feature transformation to SAR imagery registration. Acta Autom. Sin. 2008, 34, 861–868. [Google Scholar]
- Yan, Z.; Dong, C.; Wei, W.; Jianda, H.; Yuechao, W. Status and development of natural scene understanding for vision-based outdoor mobile robot. Acta Autom. Sin. 2010, 36, 1–11. [Google Scholar]
- Haifeng, L.; Yufeng, M.; Tao, S. Research on object tracking algorithm based on SIFT. Acta Autom. Sin. 2010, 36, 1204–1208. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Ooi, B.C.; McDonell, K.J.; Sacks-Davis, R. Spatial Kd-tree: An indexing mechanism for spatial databases. In Proceedings of the IEEE International Computers Software and Applications Conference, Tokyo, Japan, 7–9 October 1987. [Google Scholar]
- Weinberger, K.Q.; Saul, L.K. Distance Metric Learning for Large Margin Nearest Neighbor Classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Chen, J.H.; Chen, C.S.; Chen, Y.S. Fast algorithm for robust template matching with M-estimators. IEEE Trans. Signal Process. 2003, 51, 230–243. [Google Scholar] [CrossRef]
- Torr, P.H.S.; Zisserman, A. MLESAC: A new robust estimator with application to estimating image geometry. Comput. Vis. Image Underst. 2000, 78, 138–156. [Google Scholar] [CrossRef]
- Choi, S.; Kim, T.; Yu, W. Performance evaluation of RANSAC family. In Proceedings of the British Machine Vision Conference, London, UK, 7–10 September 2009. [Google Scholar]
- Yan, K.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Mikolajczyk, K.; Schmid, C. A performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. A sparse texture representation using local affine regions. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1265–1278. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. SURF: Speeded up robust features. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution grayscale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Ahonen, T.; Hadid, A.; Pietiainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef]
- Jian, X.; Xiaoqing, D.; Shengjin, W.; Youshou, W. Background subtraction based on a combination of local texture and color. Acta Autom. Sin. 2009, 35, 1145–1150. [Google Scholar]
- Huang, D.; Ardabilian, M.; Wang, Y.H.; Chen, L.M. Asymmetric 3D/2D face recognition based on LBP facial representation and canonical correlation analysis. In Proceedings of the 16th International Conference on Image Procesing, Cairo, Egypt, 7–10 November 2009. [Google Scholar]
- Guo, Z.H.; Zhang, L.; Zhang, D.; Mou, X.Q. Hierarchical multiscale LBP for face and palmprint recognition. In Proceedings of the 16th International Conference on Image Procesing, Hong Kong, China, 26–29 September 2010. [Google Scholar]
- Guo, Z.H.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar] [PubMed]
- Heikkila, M.; Pietikainen, M.; Schmid, C. Description of interest regions with local binary patterns. Pattern Recognit. 2009, 42, 425–436. [Google Scholar] [CrossRef]
- Tan, X.Y.; Triggs, B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [PubMed]
- Mikolajczyk, K.; Schmid, C. A performance evaluation of local descriptors. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003. [Google Scholar]
- Abdel Hakim, A.E.; Farag, A.A. CSIFT: A SIFT descriptor with color invariant characteristics. In Proceedings of the International Conferenceon Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Morel, J.M.; Yu, G. ASIFT: A new framework for fully affine invariant image comparison. SIAM J. Imaging Sci. 2009, 2, 438–469. [Google Scholar] [CrossRef]
- Li, L.; Fuyuan, P.; Kun, Z. Simplified SIFT algorithm for fast image matching. Infrared Laser Eng. 2008, 37, 181–184. [Google Scholar]
- Cai, G.R.; Li, S.; Wu, Y.; Su, S.; Chen, S. A perspective invariant image matching algorithm. Acta Autom. Sin. 2013, 39, 1053–1061. [Google Scholar] [CrossRef]
- Yonghe, T.; Huanzhang, L.; Moufa, H. Local feature description algorithm based on Laplacian. Opt. Precis. Eng. 2011, 19, 2999–3006. [Google Scholar]
- Hossein-Nejad, Z.; Agahi, H.; Mahmoodzadeh, A. Image matching based on the adaptive redundant keypoint elimination method in the SIFT algorithm. Pattern Anal. Appl. 2021, 24, 669–683. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | SIFT Algorithm | The Algorithm of This Paper | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RN | WN | MN | PT(s) | rems | RN | WN | MN | PT(s) | rems | |
| 1 | 12,823 | 16,329 | 66 | 6.839 | 0.146 | 11,537 | 14,633 | 44 | 6.055 | 0.001 |
| 2 | 11,545 | 10,407 | 86 | 6.450 | 0.134 | 10,686 | 9419 | 54 | 5.817 | 0.131 |
| 3 | 10,204 | 7845 | 66 | 5.049 | 0.227 | 8387 | 6490 | 46 | 4.067 | 0.132 |
| 4 | 9909 | 3540 | 71 | 4.490 | 0.204 | 8452 | 2509 | 45 | 3.627 | 0.065 |
| 5 | 9486 | 5295 | 90 | 4.344 | 0.161 | 8390 | 4505 | 63 | 3.678 | 0.122 |
| 6 | 9276 | 11,774 | 71 | 5.346 | 0.384 | 8326 | 10,443 | 48 | 5.102 | 0.154 |
| 7 | 8725 | 5057 | 69 | 4.244 | 0.192 | 6689 | 3589 | 48 | 3.216 | 0.129 |
| 8 | 8604 | 10,518 | 83 | 4.850 | 0.147 | 7797 | 10,094 | 60 | 4.069 | 0.118 |
| 9 | 8497 | 6751 | 66 | 4.244 | 0.199 | 7497 | 5837 | 46 | 3.520 | 0.071 |
| 10 | 7674 | 4971 | 80 | 3.994 | 2.465 | 6251 | 4376 | 57 | 3.545 | 0.152 |
| 11 | 7240 | 4507 | 71 | 3.635 | 0.176 | 6567 | 3947 | 45 | 3.115 | 0.0.131 |
| 12 | 7152 | 11,281 | 65 | 4.014 | 0.517 | 6318 | 10,269 | 45 | 3.495 | 0.015 |
| 13 | 7011 | 6622 | 78 | 3.949 | 0.119 | 6136 | 5778 | 53 | 3.615 | 0.134 |
| 14 | 6914 | 7581 | 72 | 3.701 | 0.130 | 5391 | 5716 | 54 | 2.938 | 0.103 |
| 15 | 6457 | 6914 | 65 | 3.748 | 0.028 | 5383 | 5491 | 45 | 2.859 | 0.103 |
| 16 | 6223 | 5830 | 72 | 3.521 | 0.145 | 4355 | 4976 | 52 | 2.940 | 0.143 |
| 17 | 6203 | 4348 | 74 | 3.283 | 0.153 | 4725 | 3429 | 53 | 2.629 | 0.121 |
| 18 | 5538 | 5531 | 79 | 3.205 | 0.142 | 4514 | 4871 | 58 | 2.452 | 0.114 |
| 19 | 5520 | 5799 | 80 | 3.304 | 0.150 | 4159 | 4102 | 57 | 2.225 | 0.108 |
| 20 | 5057 | 4900 | 65 | 2.710 | 0.145 | 3589 | 3381 | 47 | 1.911 | 0.128 |
| Number | SIFT Algorithm | The Algorithm of This Paper | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RN | WN | MN | PT(s) | rems | RN | WN | MN | PT(s) | rems | |
| 1 | 7497 | 7131 | 1132 | 18.869 | 0.016 | 6425 | 6005 | 1002 | 14.621 | 0.015 |
| 2 | 6623 | 5770 | 501 | 12.036 | 0.030 | 5307 | 4513 | 430 | 7.963 | 0.025 |
| 3 | 6400 | 7003 | 346 | 10.063 | 0.040 | 4908 | 5790 | 270 | 6.777 | 0.022 |
| 4 | 6156 | 5960 | 692 | 11.869 | 0.024 | 5178 | 4942 | 523 | 8.904 | 0.023 |
| 5 | 5784 | 5922 | 441 | 11.150 | 0.025 | 4485 | 4752 | 375 | 7.266 | 0.024 |
| 6 | 5729 | 5130 | 531 | 9.542 | 0.027 | 4360 | 4079 | 428 | 6.252 | 0.026 |
| 7 | 5141 | 5159 | 677 | 9.933 | 0.021 | 4441 | 4273 | 513 | 7.617 | 0.019 |
| 8 | 5138 | 4589 | 306 | 7.522 | 0.027 | 4206 | 3662 | 281 | 5.497 | 0.025 |
| 9 | 5130 | 4698 | 424 | 8.551 | 0.026 | 4079 | 4698 | 380 | 5.955 | 0.026 |
| 10 | 4774 | 3817 | 158 | 4.764 | 0.050 | 3891 | 2991 | 128 | 3.828 | 0.045 |
| 11 | 4649 | 4308 | 91 | 4.354 | 0.071 | 3662 | 3383 | 72 | 3.224 | 0.057 |
| 12 | 4518 | 4161 | 160 | 5.595 | 0.053 | 3529 | 3228 | 110 | 3.993 | 0.051 |
| 13 | 4463 | 3870 | 273 | 6.903 | 0.042 | 3505 | 3019 | 266 | 4.696 | 0.025 |
| 14 | 4382 | 4813 | 127 | 5.330 | 0.065 | 3238 | 3835 | 101 | 3.509 | 0.062 |
| 15 | 4308 | 4518 | 324 | 6.813 | 0.034 | 3193 | 3529 | 308 | 4.704 | 0.030 |
| 16 | 4204 | 3994 | 390 | 7.408 | 0.036 | 3243 | 3068 | 298 | 4.463 | 0.031 |
| 17 | 4081 | 4003 | 455 | 6.639 | 0.027 | 3243 | 3207 | 311 | 4.473 | 0.026 |
| 18 | 3826 | 4238 | 253 | 6.064 | 0.040 | 2947 | 3137 | 239 | 4.096 | 0.038 |
| 19 | 3802 | 3826 | 247 | 5.588 | 0.040 | 2879 | 2947 | 227 | 3.691 | 0.037 |
| 20 | 3697 | 3777 | 117 | 3.851 | 0.053 | 2941 | 2985 | 131 | 2.958 | 0.045 |
| Algorithm | MN | REMS | FT(s) | PT(s) | ST(s) |
|---|---|---|---|---|---|
| SIFT | 479 | ||||
| Adaptive RKEM | 245 | ||||
| This paper | 166 |
| Algorithm | MN | REMS | FT(s) | PT(s) | ST(s) |
|---|---|---|---|---|---|
| SIFT | 263 | ||||
| Adaptive RKEM | 179 | ||||
| This paper | 114 |
| Algorithm | MN | REMS | FT(s) | PT(s) | ST(s) |
|---|---|---|---|---|---|
| SIFT | 361 | ||||
| Adaptive SIFT | 228 | ||||
| This paper | 184 |
| Dataset | PM | PT | REMS |
|---|---|---|---|
| Kitti dataset | |||
| Euroc dataset | |||
| Different affine distortion images | |||
| Different scale images | |||
| Different illumination images | |||
| Overall |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, L.; Ma, S.; Ma, X.; You, H. Research on Image Matching of Improved SIFT Algorithm Based on Stability Factor and Feature Descriptor Simplification. Appl. Sci. 2022, 12, 8448. https://doi.org/10.3390/app12178448
Tang L, Ma S, Ma X, You H. Research on Image Matching of Improved SIFT Algorithm Based on Stability Factor and Feature Descriptor Simplification. Applied Sciences. 2022; 12(17):8448. https://doi.org/10.3390/app12178448
Chicago/Turabian StyleTang, Liang, Shuhua Ma, Xianchun Ma, and Hairong You. 2022. "Research on Image Matching of Improved SIFT Algorithm Based on Stability Factor and Feature Descriptor Simplification" Applied Sciences 12, no. 17: 8448. https://doi.org/10.3390/app12178448
APA StyleTang, L., Ma, S., Ma, X., & You, H. (2022). Research on Image Matching of Improved SIFT Algorithm Based on Stability Factor and Feature Descriptor Simplification. Applied Sciences, 12(17), 8448. https://doi.org/10.3390/app12178448