

Evaluation and Comparison of Spatial Clustering for Solar Irradiance Time Series


Abstract
:1. Introduction
- The development of energy storages: They will allow us to store the energy in excess and to restore it when the load requires it [6];
- The development of smart concepts of electrical grid: The produced and consumed energy and power must be managed efficiently with smart algorithms, using information and communication technologies [7];
- The forecasting of the intermittent renewable energy production: Solar- or wind-prediction tools must be integrated into energy and power management systems to anticipate the future actions [8].
- To evaluate the quality of the data provided by the meteorological stations because the measure of solar irradiation is often accompanied by errors due to pyranometer calibration, surrounding effects, or data-acquisition-system failure;
- To determine the best descriptors of static (e.g., descriptive statistics measures) and dynamic (e.g., Hurst exponent (H), forecastability coefficient (F), etc.) characteristics of the series and to determine the redundancy of these descriptors;
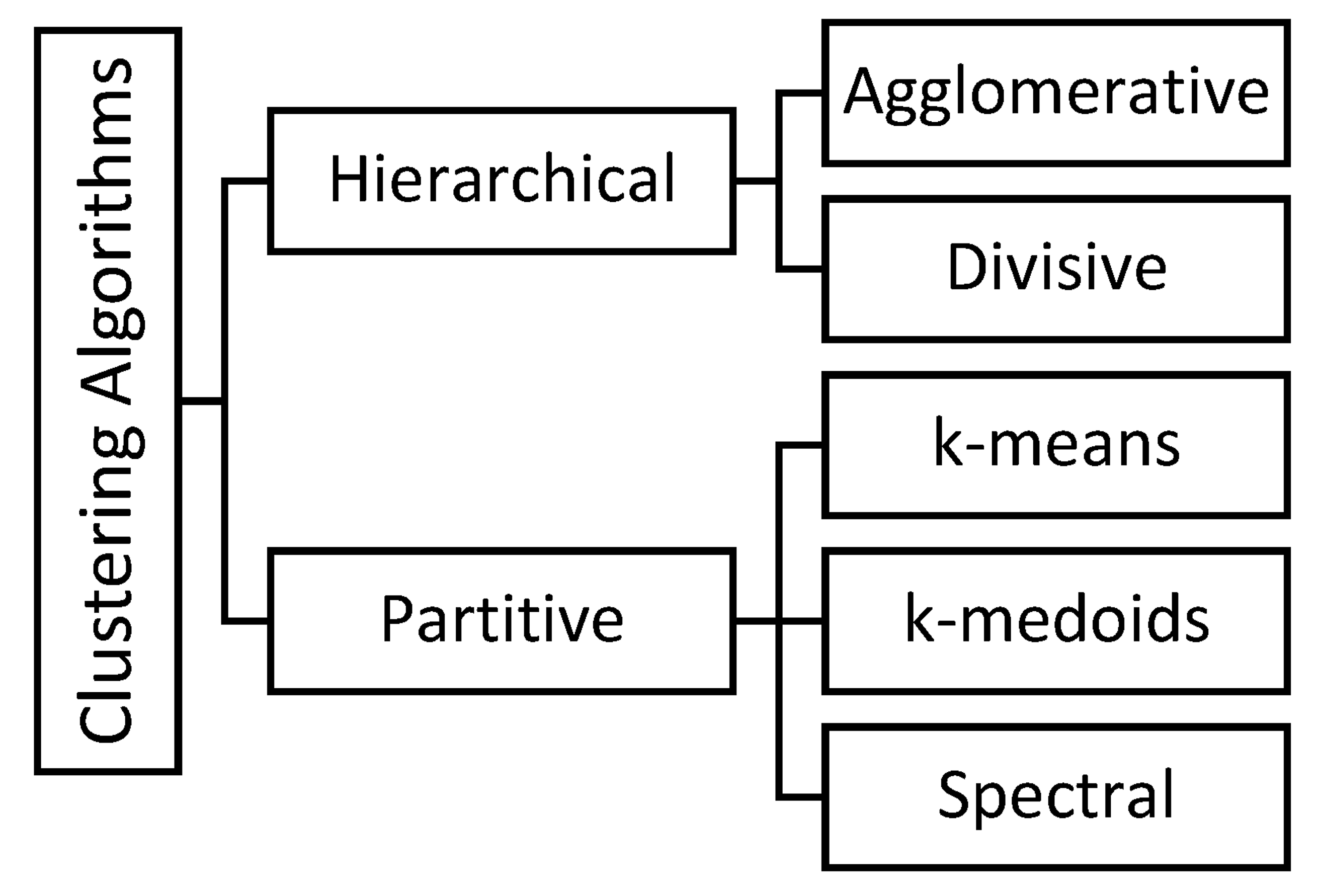
- To implement clustering algorithms such as k-mean, k-medoids, spectral, and hierarchical clustering;
- To compare the clusters obtained by each method with each other and the well-known Köppen classification, characterizing the areas according to climate, solar irradiation, precipitation, and temperatures.
- -
- The objective of the clustering is to improve the efficiency of the forecasting of the solar radiation; the objective was found only in one reference [29];
- -
- The utilization of several parameters to characterize each site;
- -
- The utilization of dynamic parameters to characterize each meteorological station: Hurst exponent already used for other meteorological time series but not for solar irradiances, and mainly the forecastability coefficient, which is a new concept—the utilization of several clustering methods and their comparison between them and with the well-known Köppen classification (upgraded for Spain).
2. Solar Irradiation Time-Series Analysis
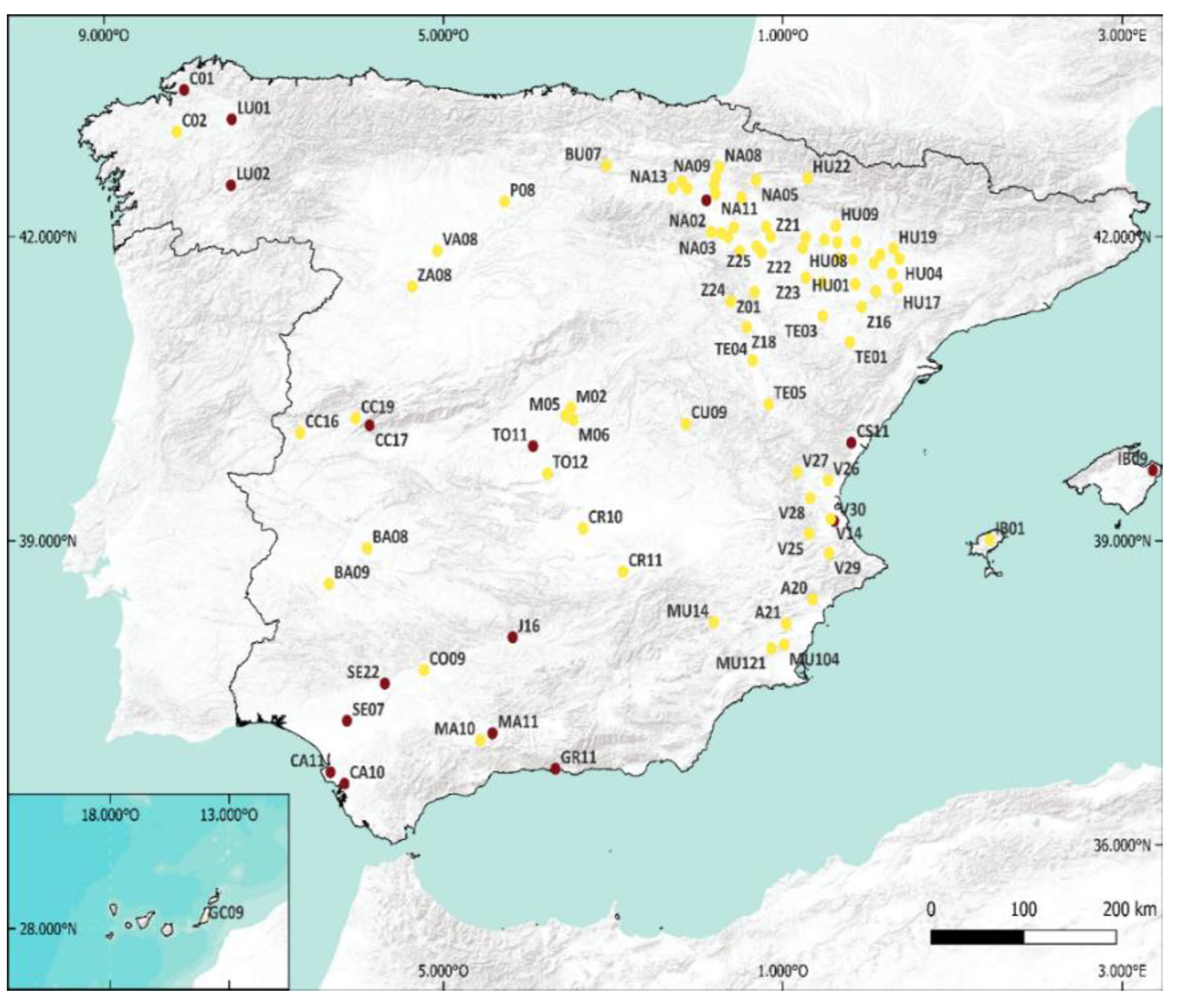
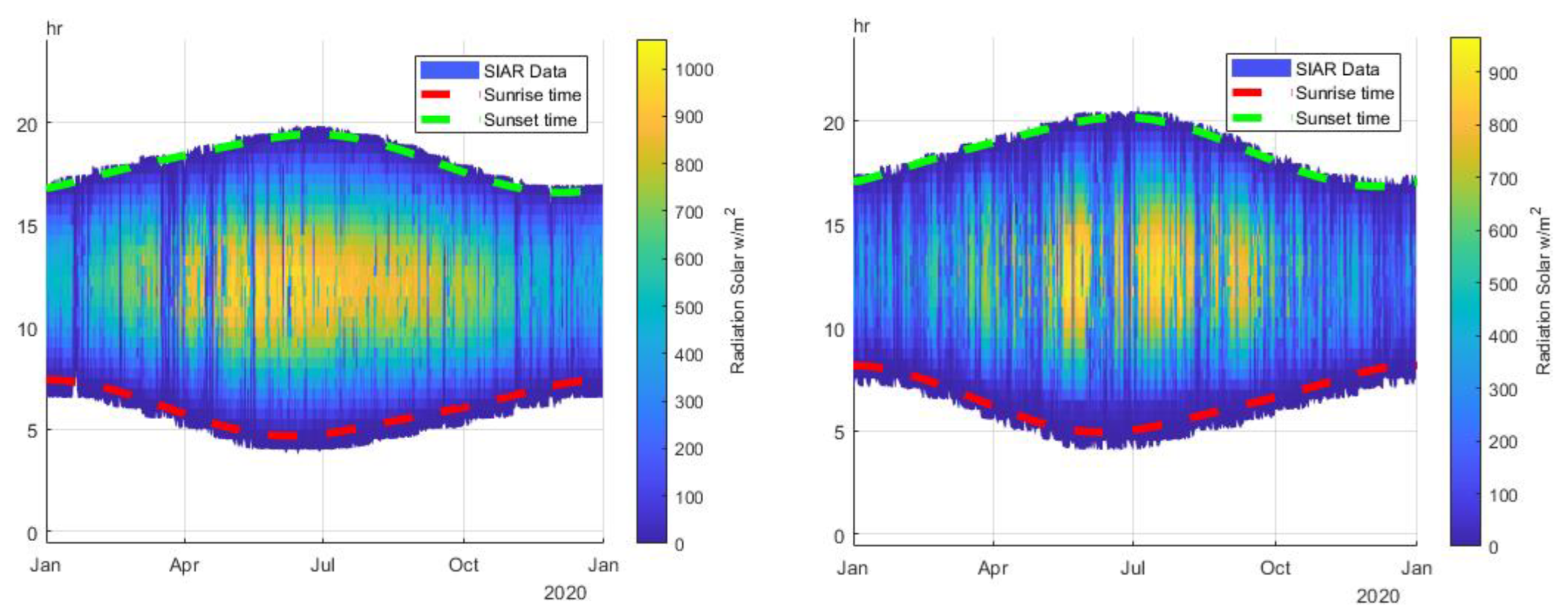
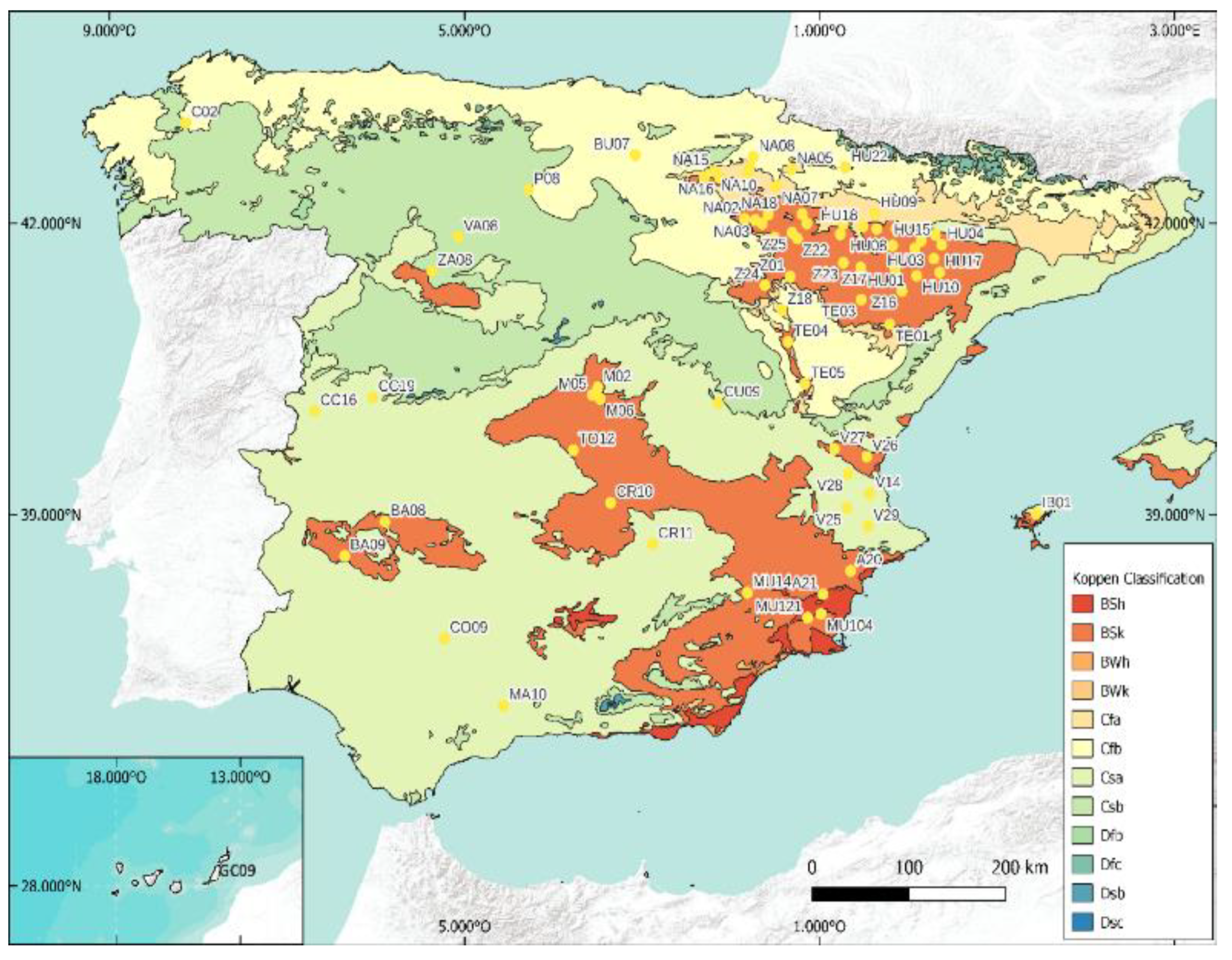
2.1. Data Measures and Stations
2.2. Clear Sky Model
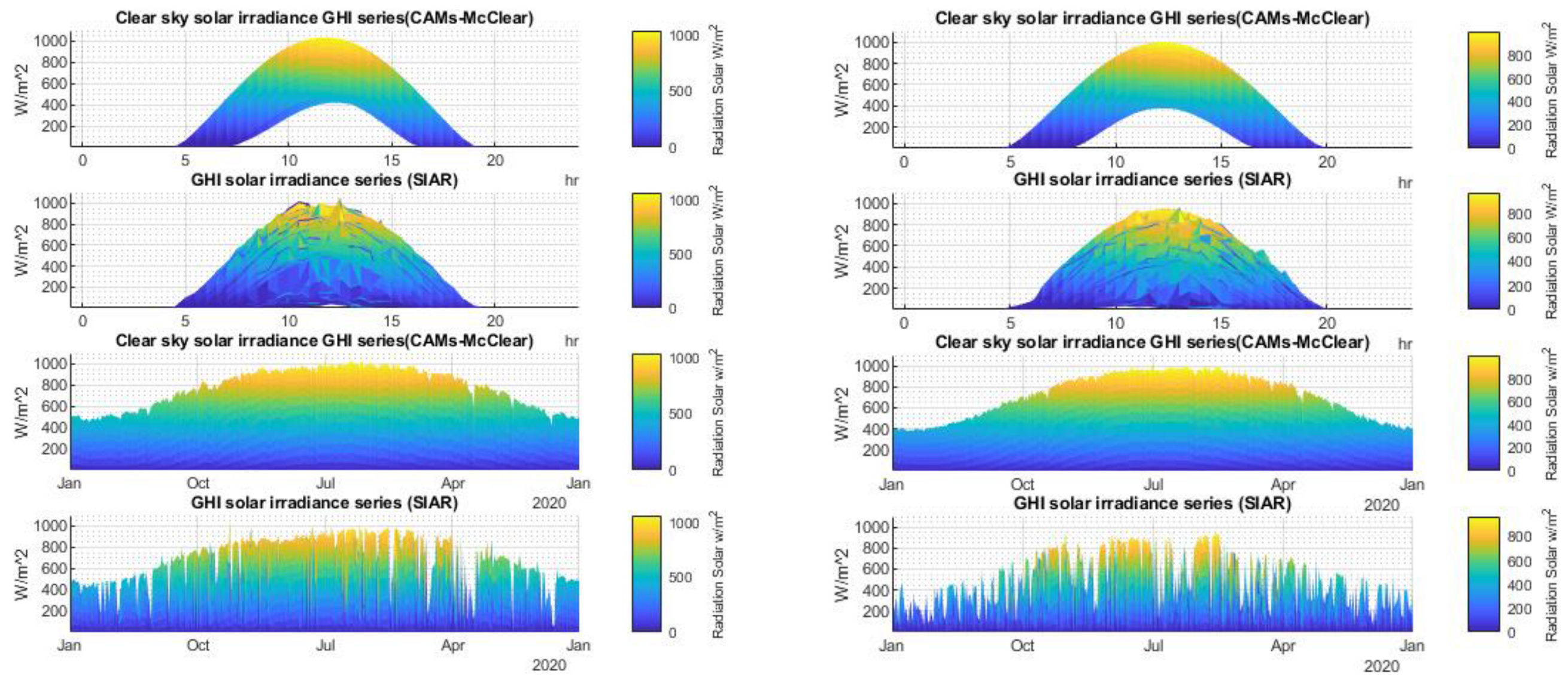
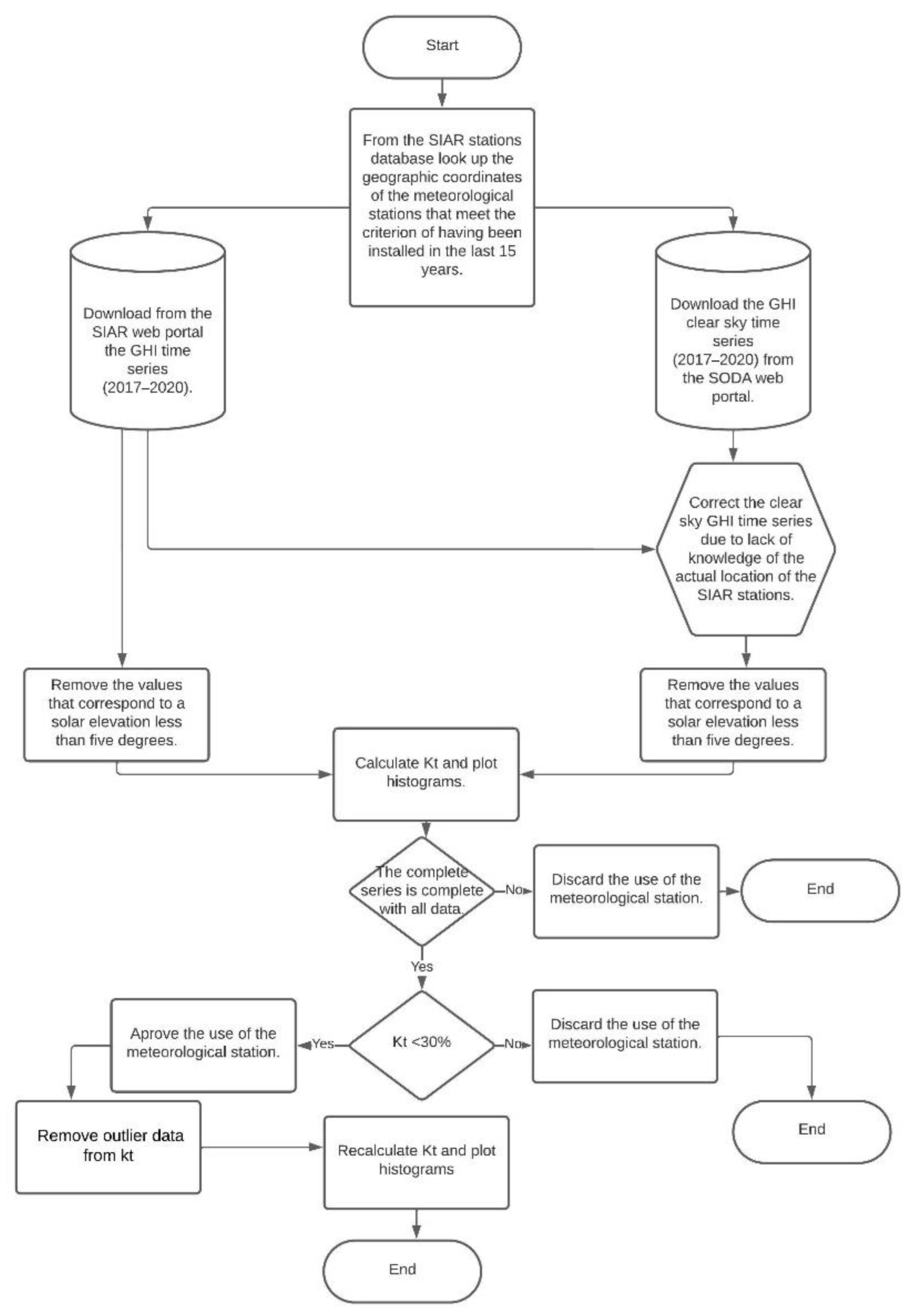
2.3. Data Quality Control
- GHIcs correction related to a possible offset corresponding to an erroneous time stamp: clock issue or stations’ location approximation (see Section 2.3.1);
- Visual validation of kt series to easily identify significant measurement errors (see Section 2.3.2).
- Quality evaluation of data provided by SIAR system and discarding of the stations with more than 30% of over-irradiance data (see Section 2.3.2).
- Detection of the kt outlier. The data that are much larger than 1.2 are removed (see Section 2.3.3).
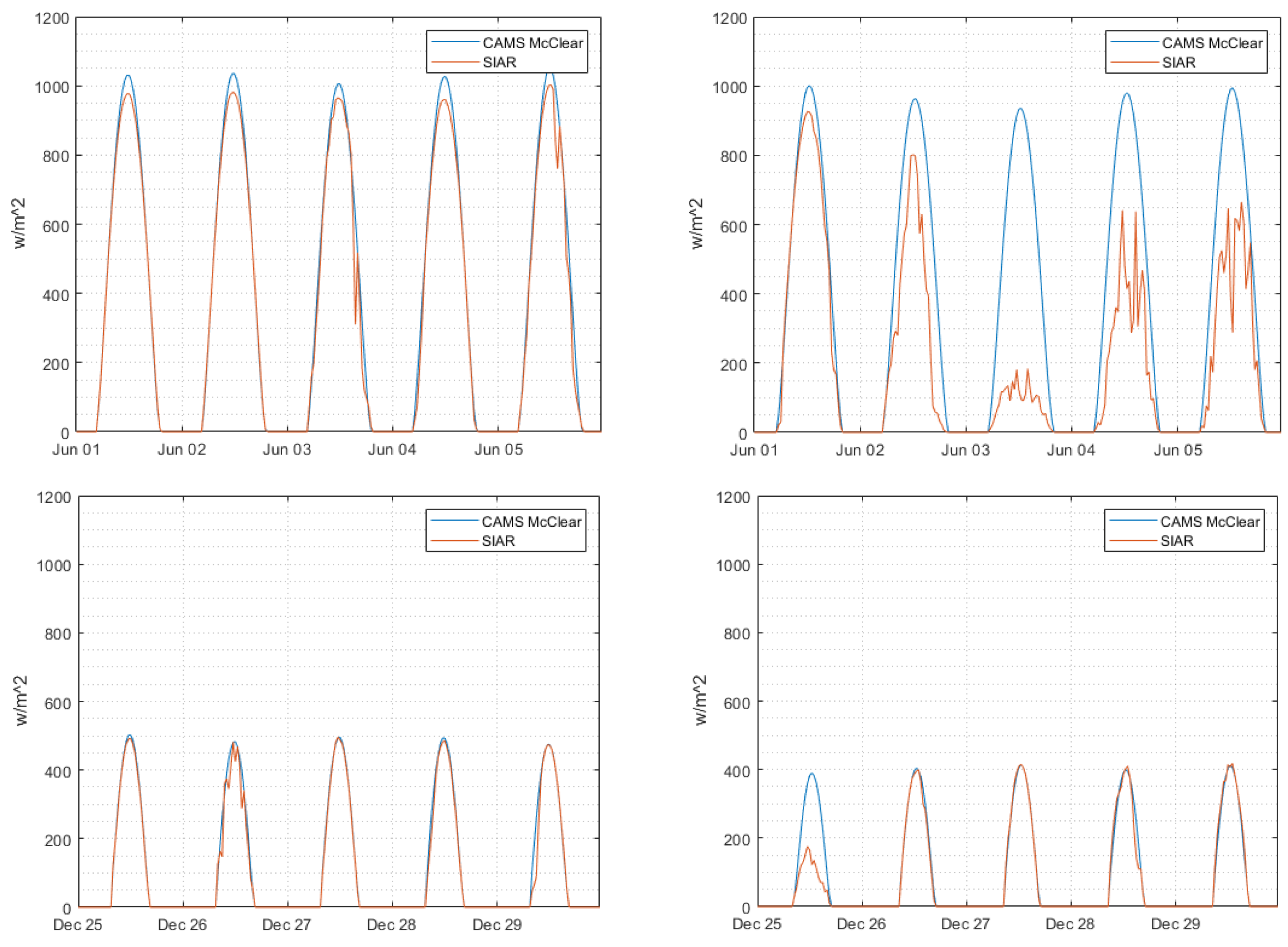
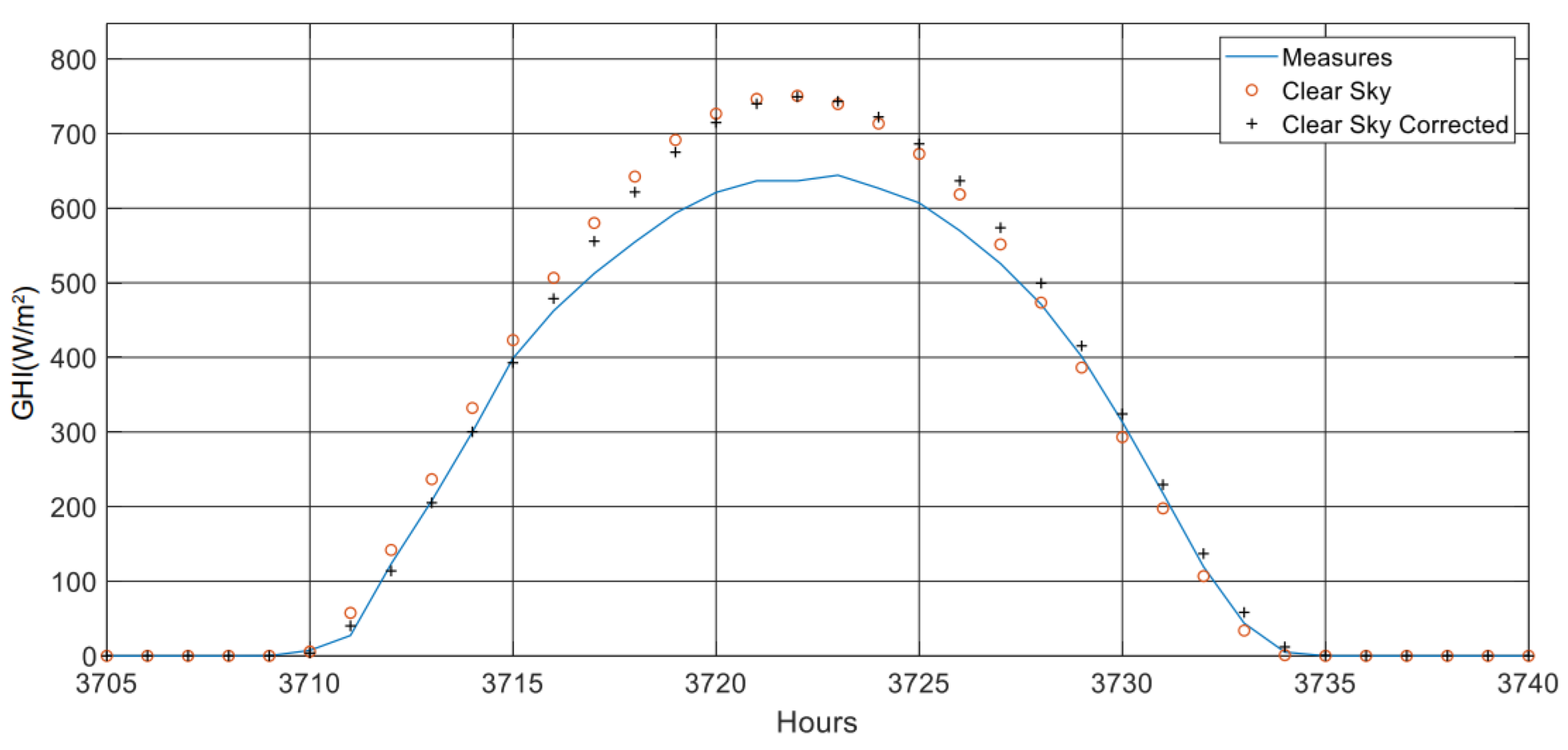
2.3.1. Time-Stamp Correction
- Operate a clear-sky shift (Δt) from −60 min to +60 min (by steps of 1 min), based on a simple linear interpolation (121 time series are obtained).
- Compute for the 121 GHIcs series generated previously the mean square error (MSE) compared to measurement (GHI).
- Retain Δt, the offset that allows us to obtain the minimum MSE.
- Propose the new corrected clear-sky series, which corresponds to the linear interpolation of the series shifted by the offset, Δt ().
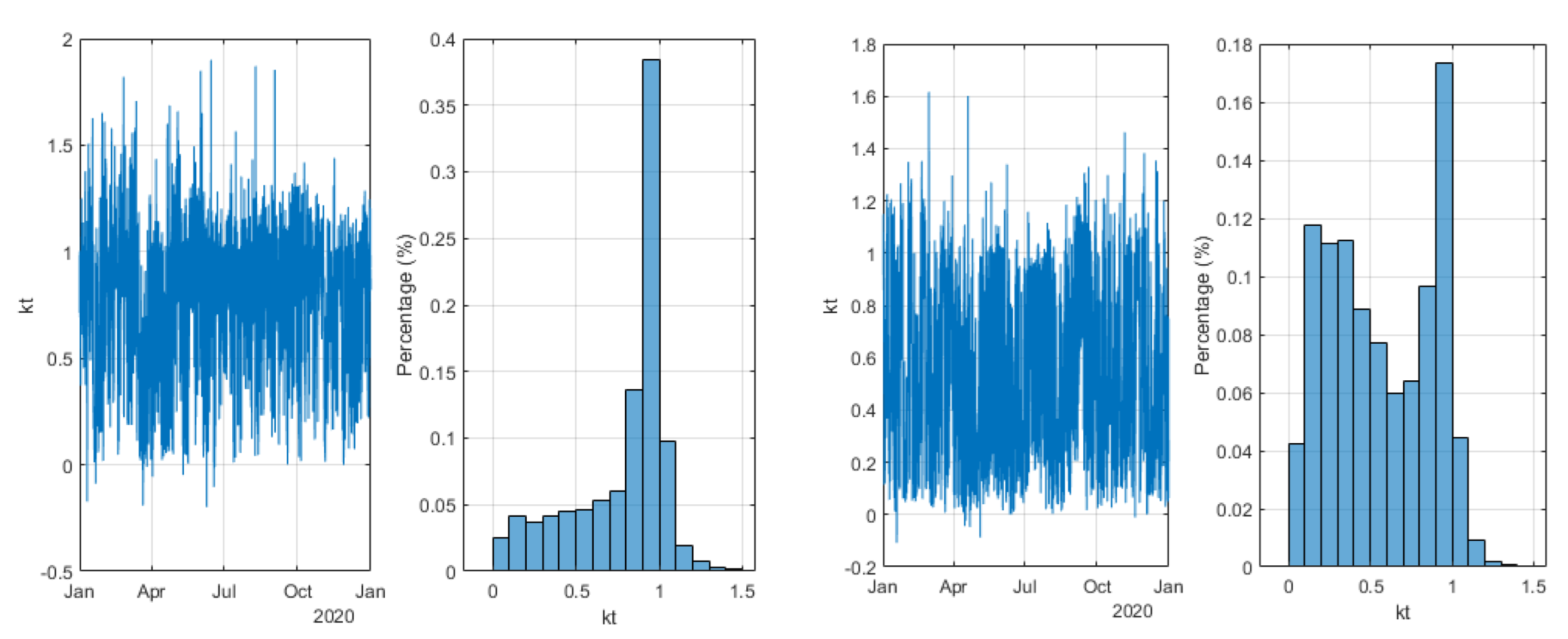
2.3.2. Validation of the SIAR GHI Time Series
2.3.3. Outlier Cleaning Methodology
2.4. Results of the Data Quality Control
3. Characterization of Solar Irradiance Time Series
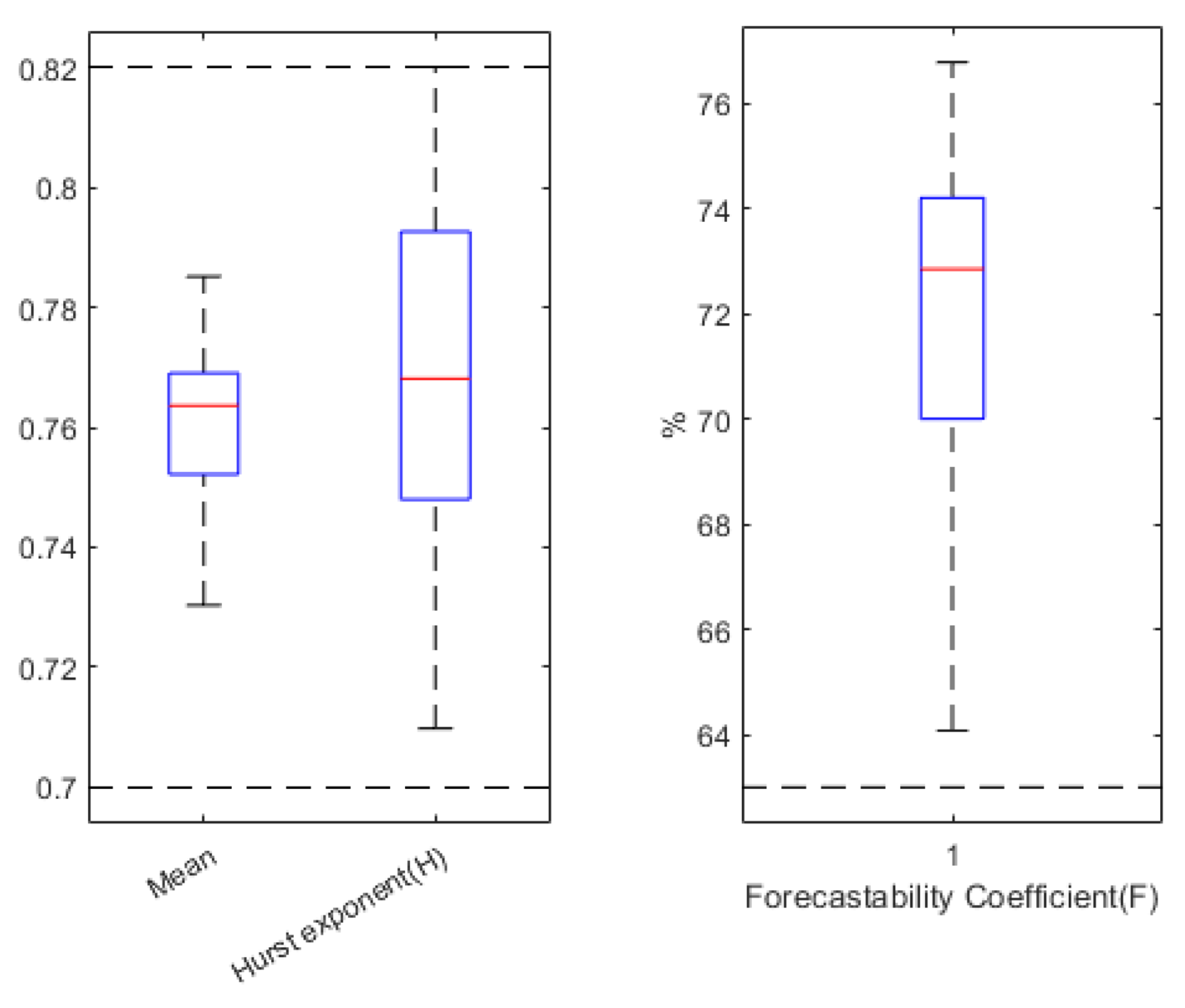
3.1. Static Parameters
3.2. Dynamic Parameters
- If H < 0.5, the series is anti-persistent. The closer the value is to 0, the stronger the mean-reversion process is. In practice, it means that a high value is followed by a low value, and vice versa.
- If H = 0.5, the series is totally random.
- If H > 0.5, the series is persistent. The closer the value is to 1, the stronger the trend.
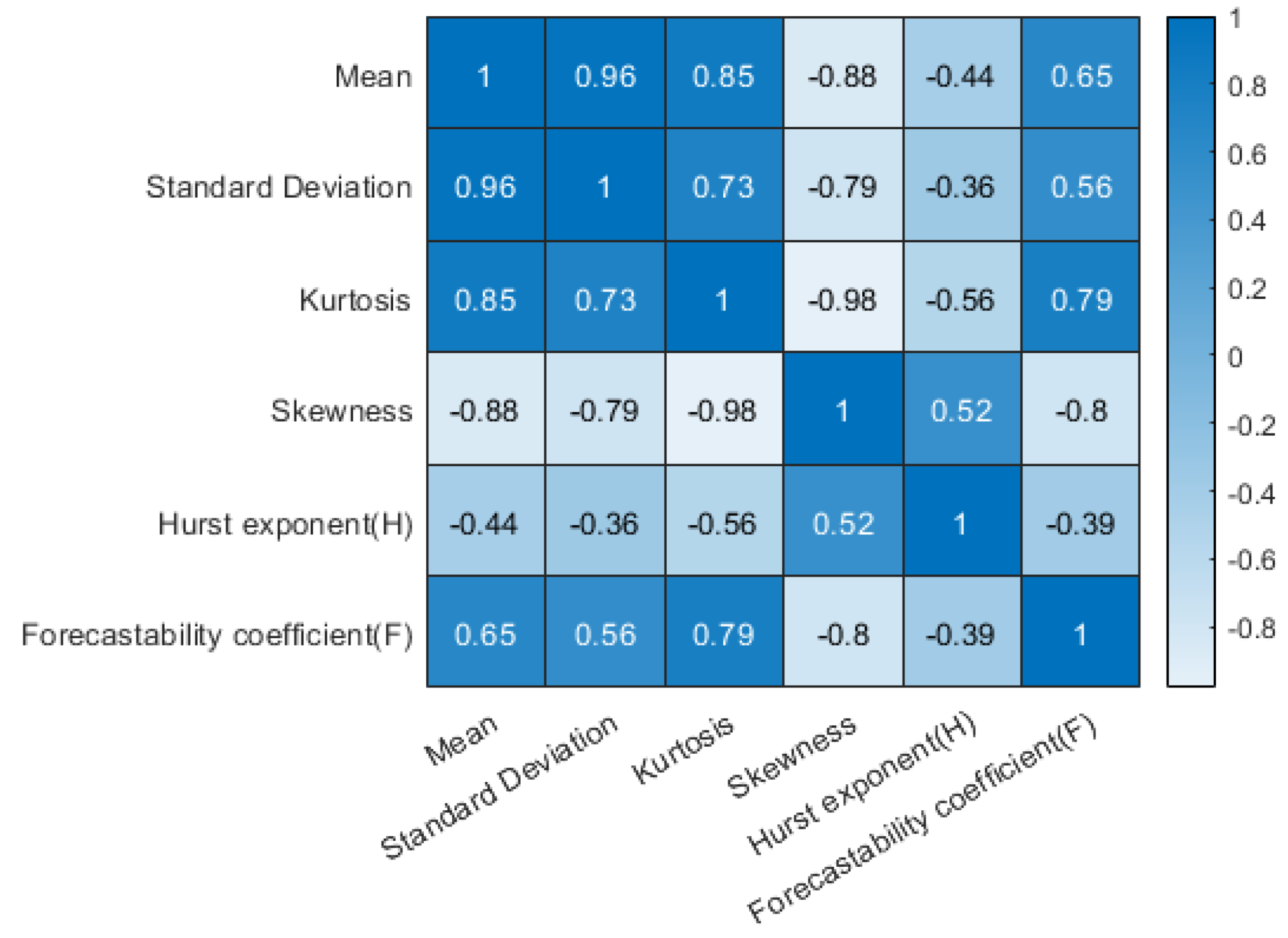
3.3. Correlation between Statistical Parameters—Redundancy
4. Köppen Climatic Classification and Clustering Methods
4.1. Köppen Climatic Classification
4.2. Geographical Clustering Methods
4.2.1. The Available Tools
- -
- Compute the proximity matrix;
- -
- Let each data point be a cluster;
- -
- Repeat: Merge the two closest clusters and update the proximity matrix;
- -
- Until only a single cluster remains.
- According to the Spanish Köppen classification (BSh, BSk, Cfa, Cfb, and Csb), k = 5;
- According to the second letter (precipitation regime) of the Spanish Köppen classification (S, f, and s), k = 3. A strong link exists between GHI and precipitation: when one increases, the other decreases, and vice versa.
4.2.2. Clustering Methods Comparison
- The Rand Index (RI) is a measure of the percentage of correct decisions made by the algorithm: RI = (TP + TN)/(TP + FP + FN + TN), where TP is the number of true positives, TN is the number of true negatives, FP is the number of false positives, and FN is the number of false negatives;
- The Jaccard Index (JI) is a measure that quantifies the degree of similarity between two sets: JI = |A∩B|/|A∪B|, where A and B are two sets or clusters.
5. Results
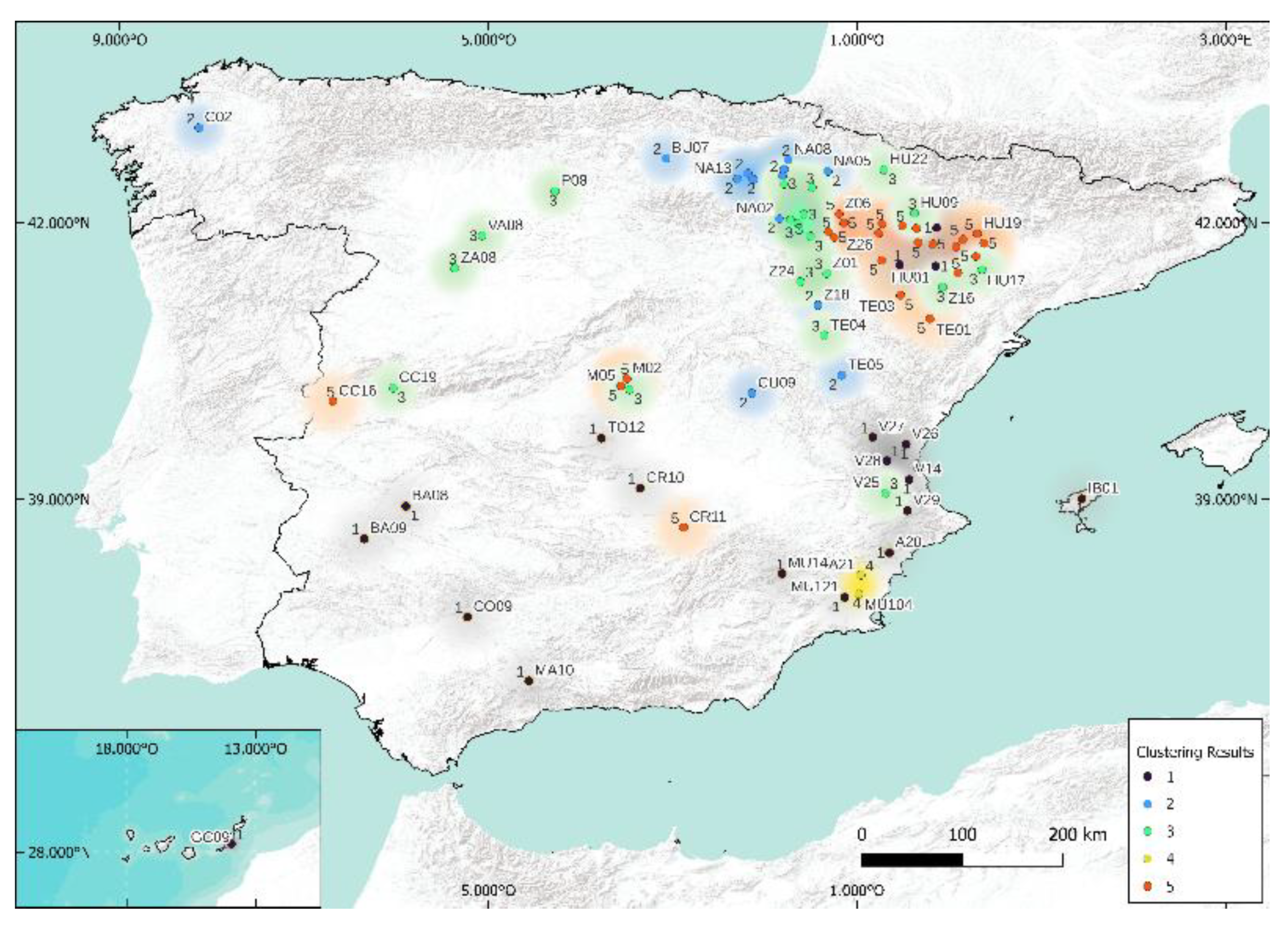
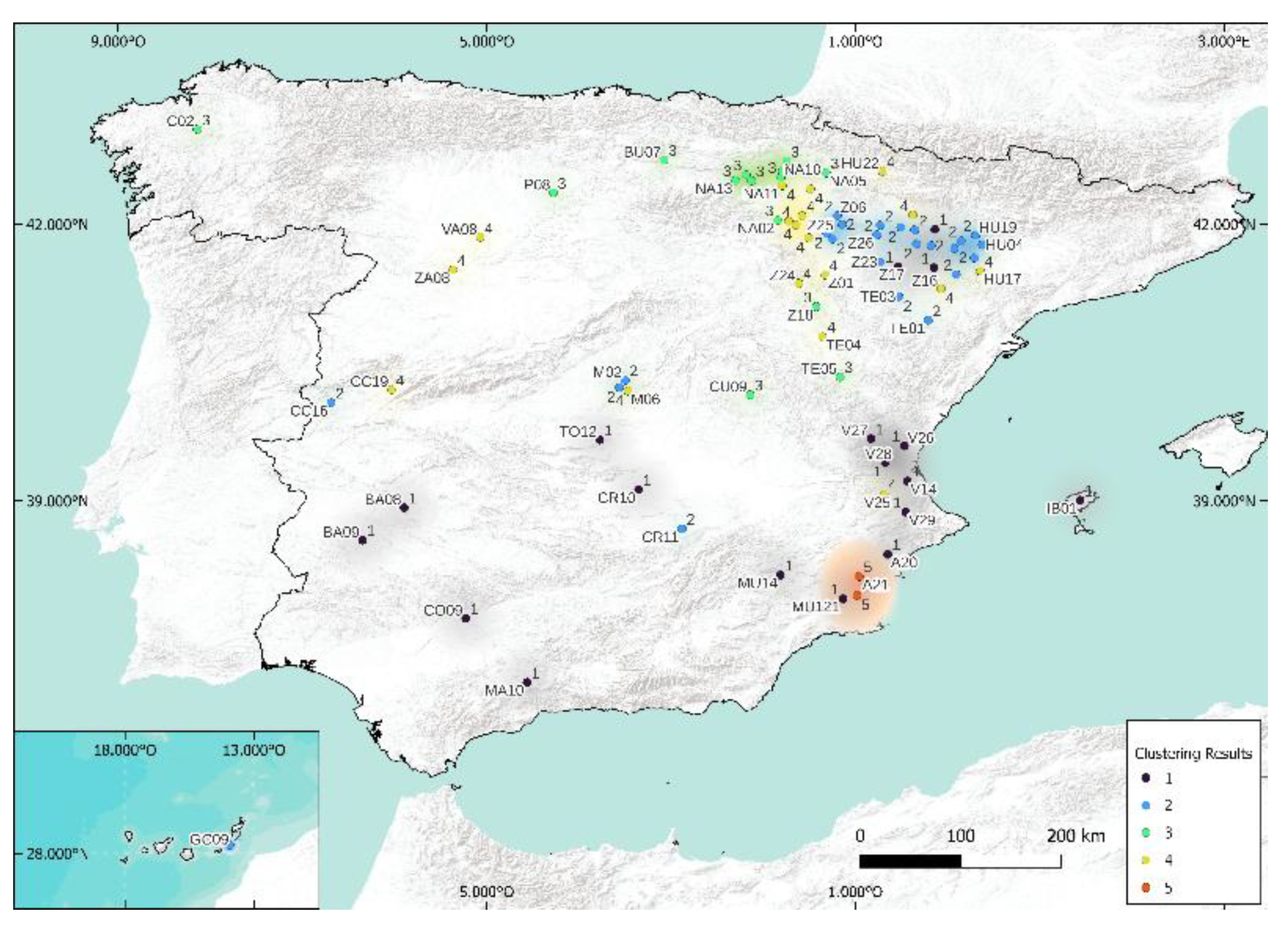
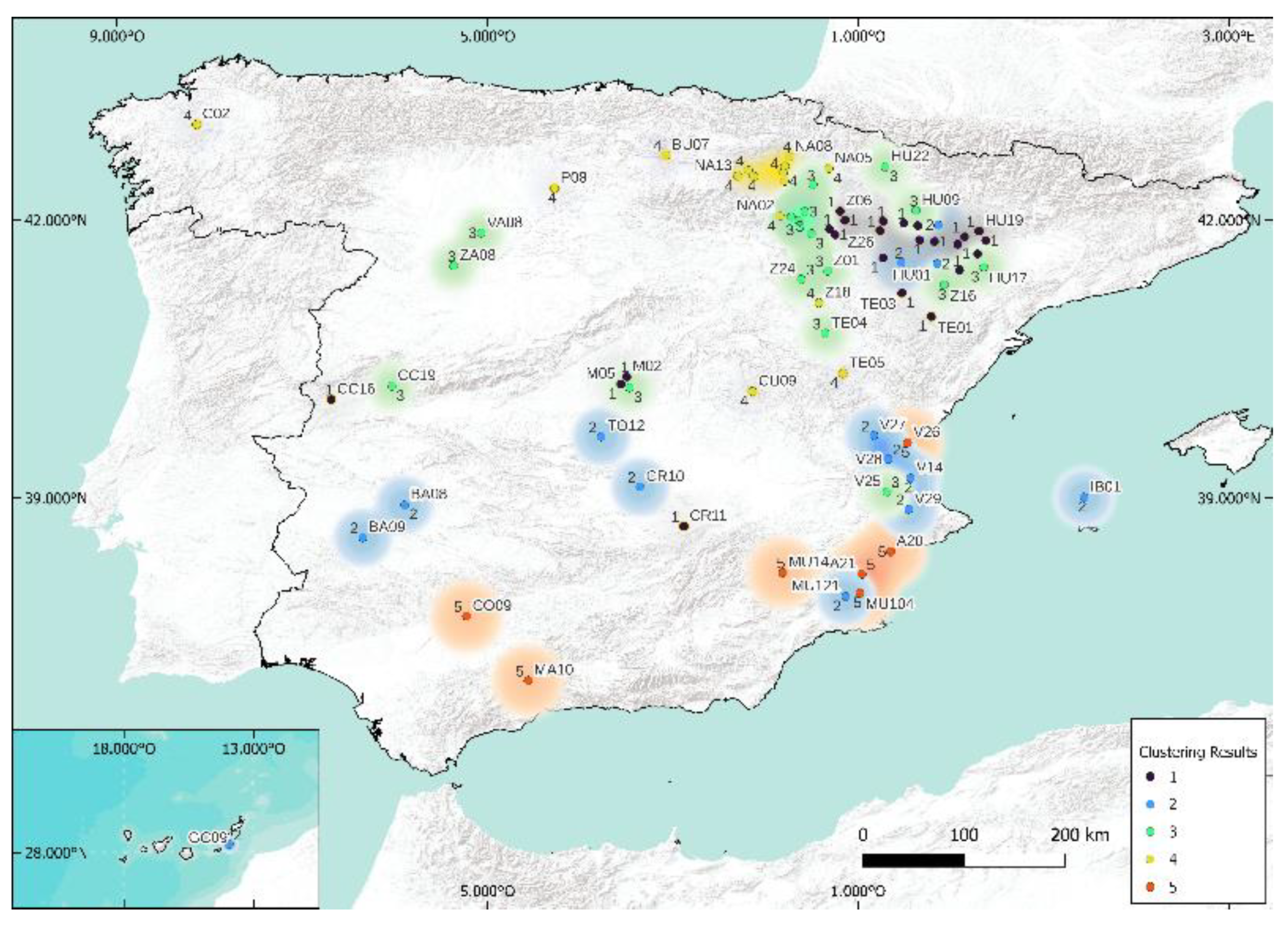
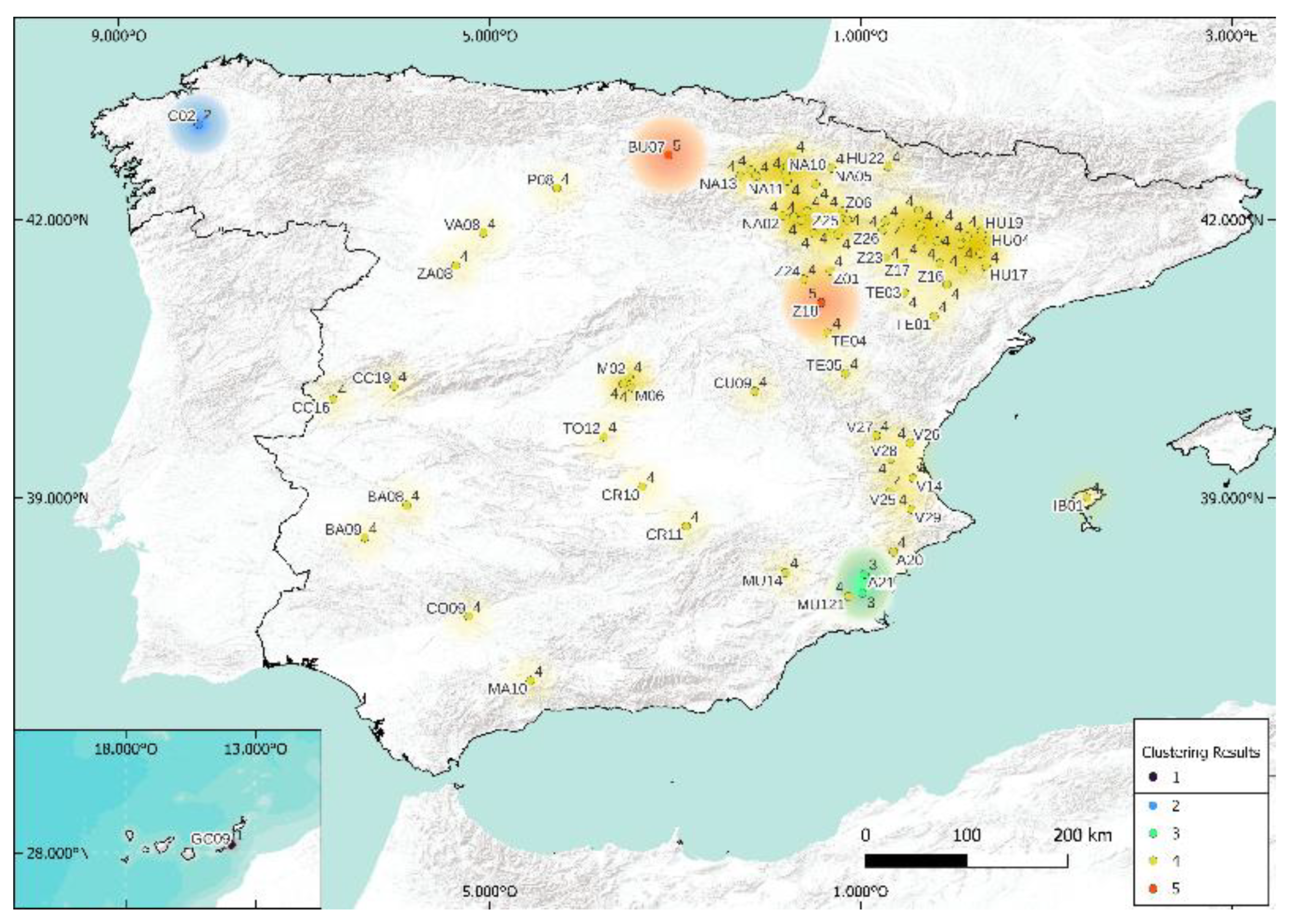
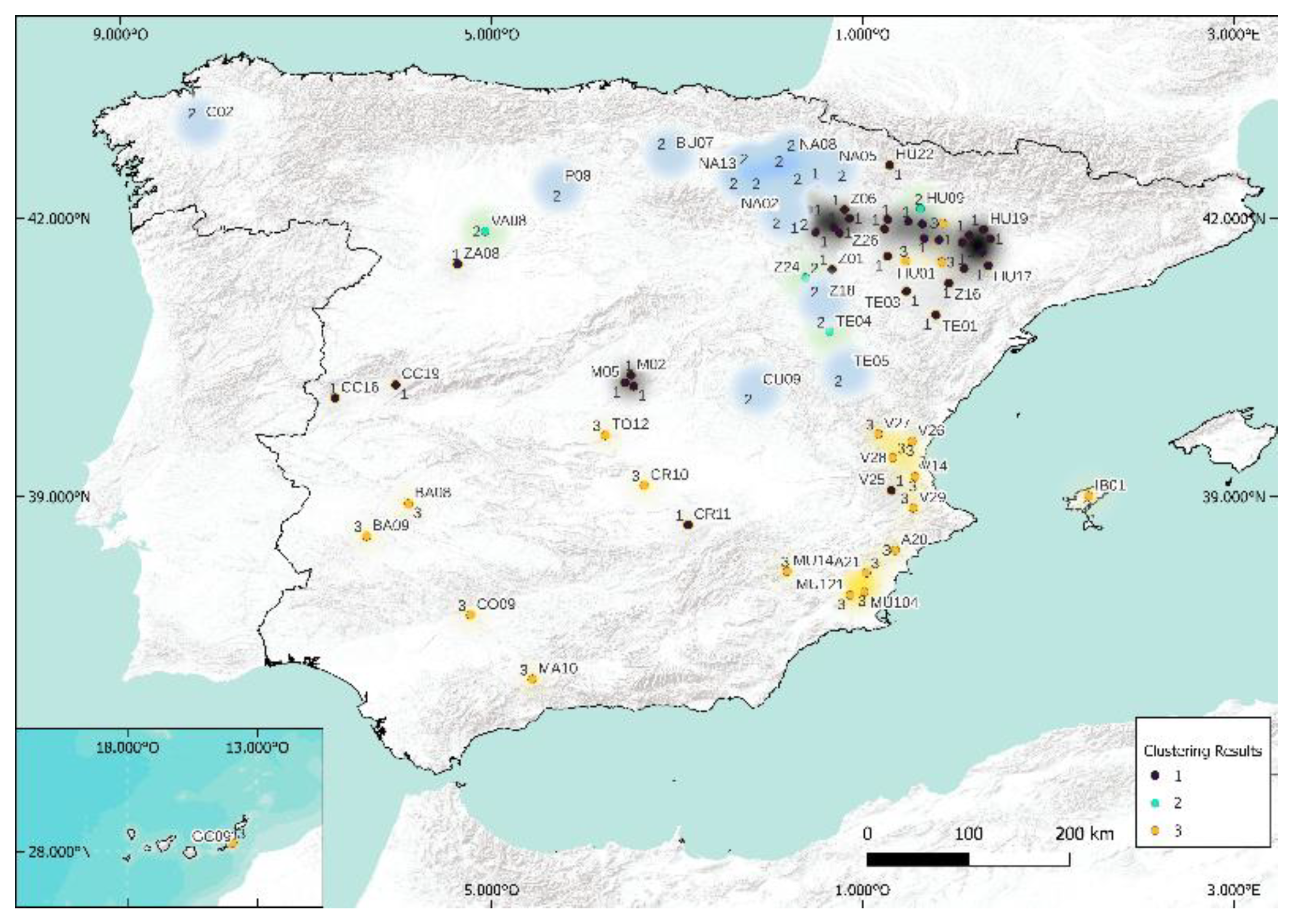
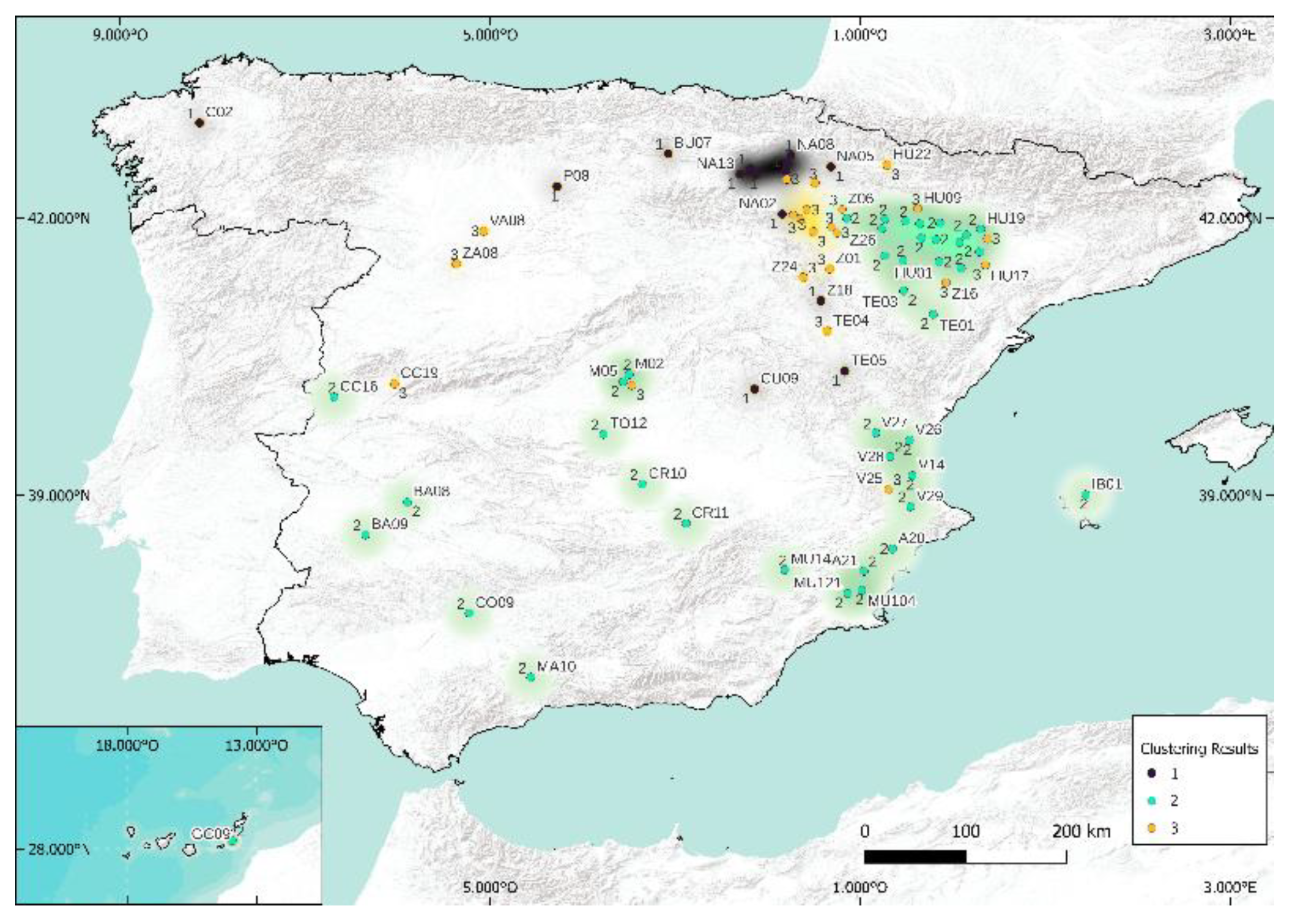
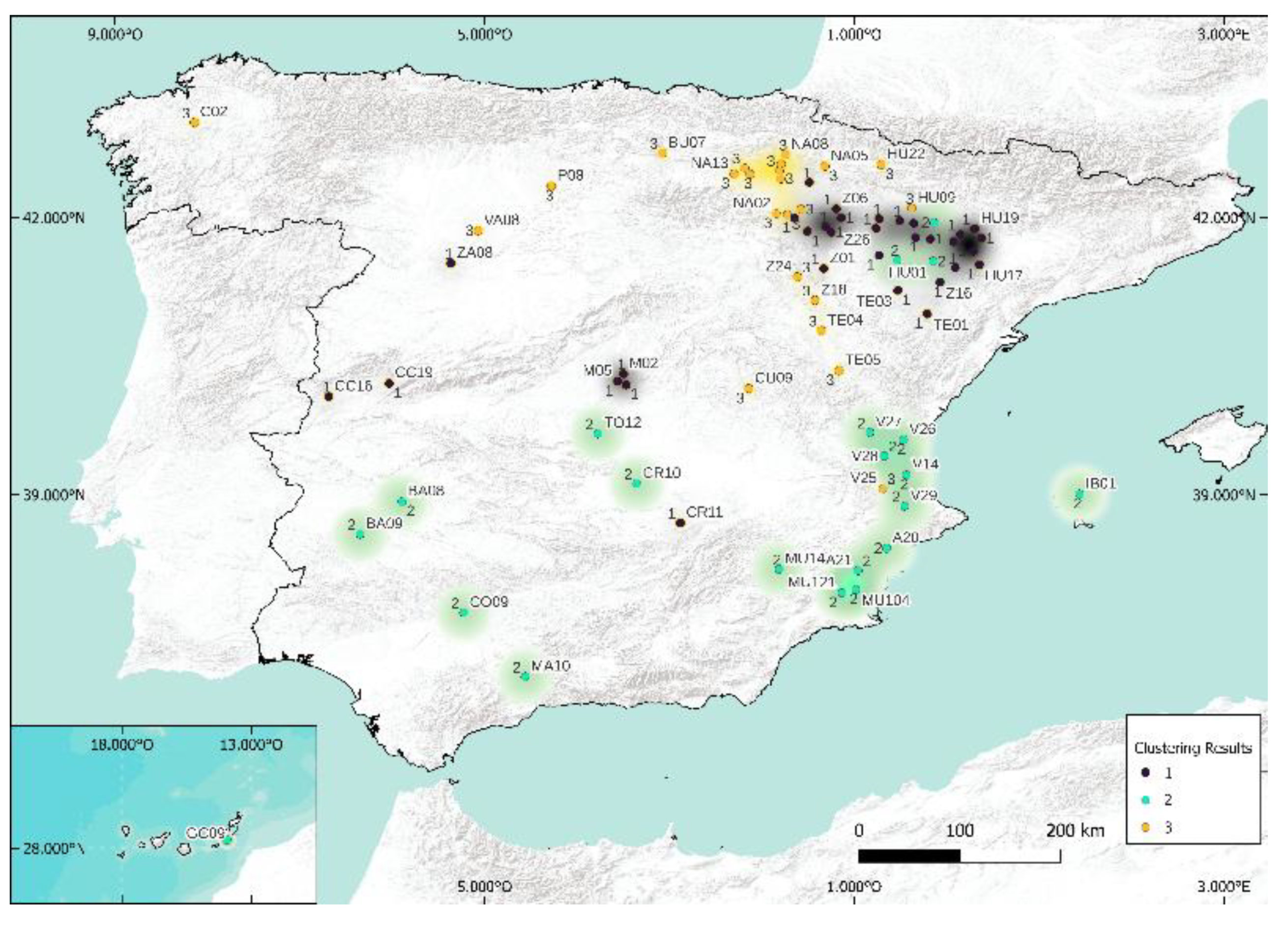
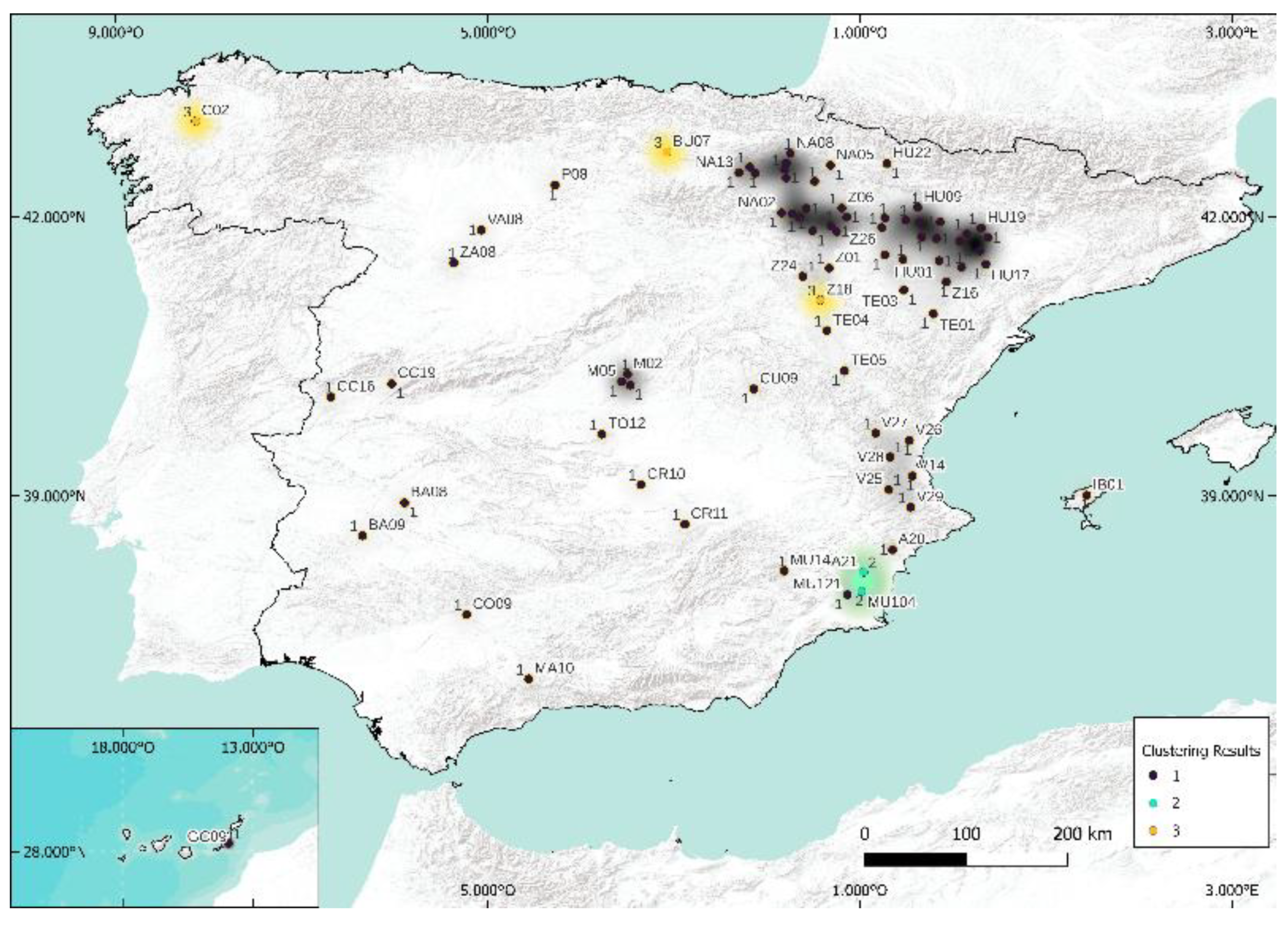
5.1. Case of 5 Clusters
5.2. Case of 3 Clusters
6. Summary of Some Important Milestones of This Work
- (a)
- The methodology used for analysis, correction, and validation of solar irradiance time series was presented in Figure 4. This part of the methodology was developed in Section 2.3, and the results obtained were presented in Section 2.4.
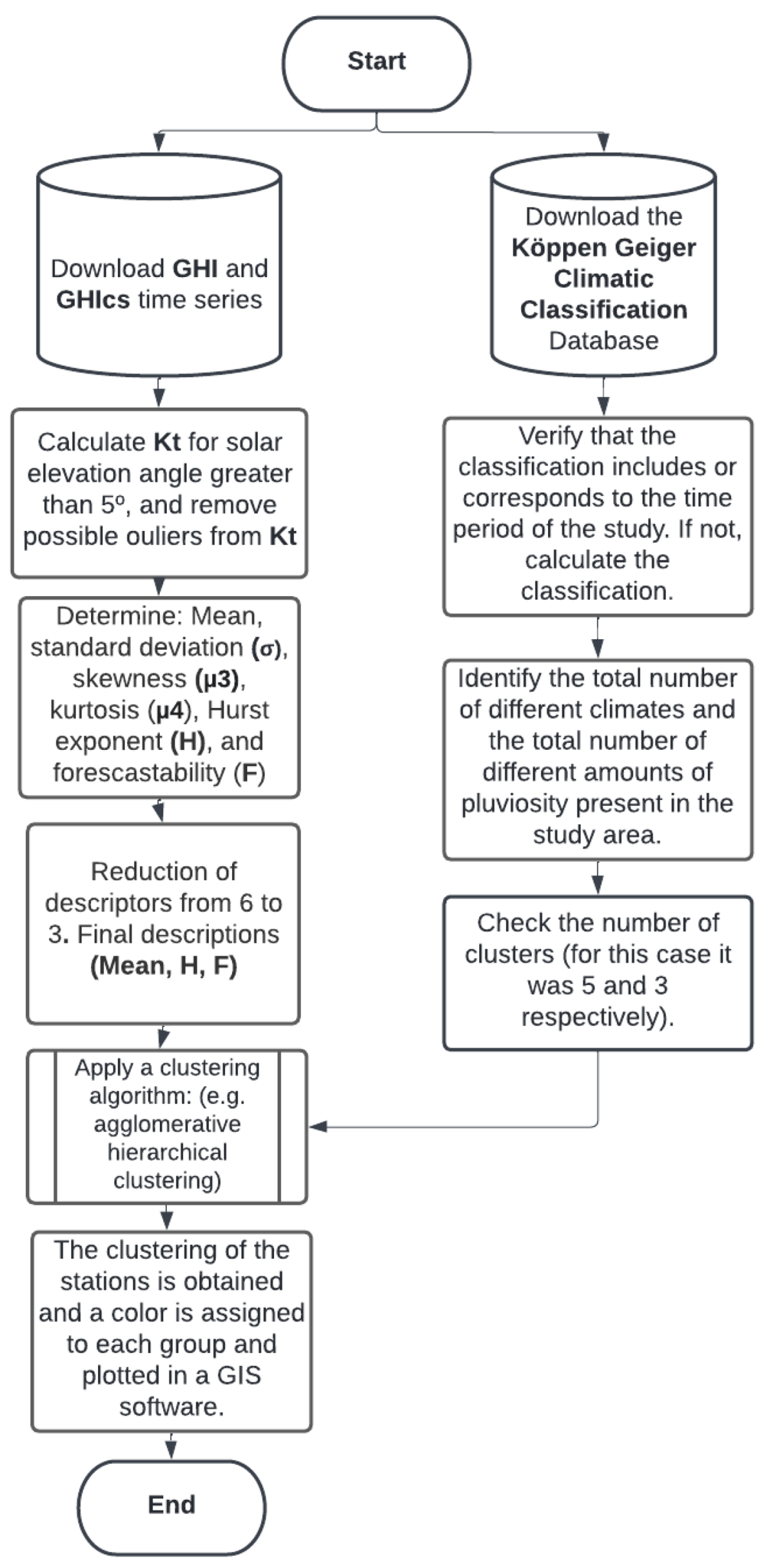
- (b)
- The methodology used for characterization, clustering, and decision of the number of clusters from Köppen–Geiger classification is presented in Figure 20. This part of the methodology was developed in Section 3 (characterization); in Section 4, we presented the Köppen climatic classification and clustering methods; and finally, in Section 5, we presented the maps and results.
7. Conclusions and Perspectives
- To select to predictor considering that a method efficient on a meteorological site can be applied with the same efficiency of all the sites of the same cluster (i.e., with the same solar radiation variability or evolution);
- To make a forecast on a site where a GHI measurement device has just been installed. Clustering allows us to perform learning on data measured on one or several sites with similar characteristics and then to perform transfer learning to be able to make a forecast on the new site;
- To make GHI predictions on a site where few historical measurements are available. Clustering allows us to increase the number of training data (and thus the quality of the training by avoiding overfitting) by integrating data from other sites of the same cluster;
- To make prediction on a site where no measurement device is available. Clustering coupled with Kriging could allow for making a forecast from measurements obtained on nearby sites with similar meteorological characteristics;
- To improve a forecast by integrating during the learning process time-delayed data from other sites in the same cluster.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | Station | Lat (°) | Long (°) | Altitude (m) | Köp Class 1981–2010 | Köp Class 2017–2020 | Mean | Standard Deviation | Kurtosis | Skewness | H | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A20 | Agost | 38.422 | −0.650 | 941 | BSk | BSk | 0.81 | 0.44 | 3.39 | −1.15 | 0.73 | 71.91 |
| A21 | Orihuela | 38.180 | −0.959 | 96 | BSh | BSk | 0.82 | 0.44 | 3.87 | −1.30 | 0.73 | 74.25 |
| BA08 | Don Benito | 38.927 | −5.896 | 268 | BSk | BSk | 0.79 | 0.43 | 3.13 | −1.07 | 0.76 | 75.35 |
| BA09 | Vil. los Barros | 38.575 | −6.348 | 406 | BSk | BSk | 0.79 | 0.43 | 3.18 | −1.09 | 0.76 | 73.11 |
| BU07 | S. Gadea del Cid | 42.701 | −3.075 | 525 | Cfb | BSk | 0.67 | 0.37 | 1.79 | −0.36 | 0.75 | 51.96 |
| C02 | Boimorto | 43.032 | −8.141 | 429 | Csb | BSk | 0.61 | 0.37 | 1.68 | −0.20 | 0.76 | 50.28 |
| CC16 | Moraleja | 40.066 | −6.688 | 272 | Csa | BSk | 0.75 | 0.42 | 2.88 | −0.99 | 0.78 | 73.74 |
| CC19 | Zarza de Granadilla | 40.207 | −6.033 | 354 | Csa | BSk | 0.75 | 0.42 | 2.57 | −0.85 | 0.77 | 72.02 |
| CO09 | Palma del Río | 37.725 | −5.227 | 57 | Csa | BSk | 0.79 | 0.43 | 3.48 | −1.19 | 0.75 | 76.79 |
| CR10 | Manzanares | 39.122 | −3.354 | 645 | BSk | BSk | 0.80 | 0.44 | 3.15 | −1.12 | 0.76 | 74.59 |
| CR11 | Montiel | 38.696 | −2.881 | 887 | Csa | BSk | 0.79 | 0.44 | 2.86 | −1.01 | 0.76 | 72.42 |
| CU09 | Mariana | 40.152 | −2.142 | 941 | Csa | BSk | 0.73 | 0.42 | 2.16 | −0.69 | 0.77 | 67.25 |
| GC09 | Antigua | 28.320 | −13.942 | 72 | BWh | BSk | 0.81 | 0.43 | 3.13 | −1.01 | 0.66 | 73.83 |
| HU01 | Valfarta | 41.531 | −0.148 | 359 | BSk | BSk | 0.79 | 0.43 | 3.14 | −1.11 | 0.75 | 74.65 |
| HU02 | Zaidín | 41.636 | 0.289 | 182 | BSk | BSk | 0.78 | 0.43 | 2.89 | −1.04 | 0.77 | 76.32 |
| HU03 | Alcolea de Cinca | 41.740 | 0.073 | 225 | BSk | BSk | 0.80 | 0.44 | 2.86 | −1.05 | 0.77 | 75.72 |
| HU04 | Tamarite de Litera | 41.780 | 0.377 | 218 | BSk | BSk | 0.75 | 0.42 | 2.71 | −0.96 | 0.77 | 75.41 |
| HU05 | Lanaja | 41.786 | −0.338 | 361 | BSk | BSk | 0.79 | 0.43 | 2.93 | −1.01 | 0.76 | 74.02 |
| HU08 | Sariñena | 41.771 | −0.177 | 291 | BSk | BSk | 0.76 | 0.42 | 2.90 | −1.00 | 0.76 | 74.90 |
| HU09 | Huesca | 42.105 | −0.378 | 432 | Cfa | BSk | 0.74 | 0.42 | 2.42 | −0.78 | 0.77 | 74.17 |
| HU10 | Candasnos | 41.459 | 0.094 | 307 | BSk | BSk | 0.78 | 0.43 | 2.90 | −1.02 | 0.76 | 75.48 |
| HU11 | Grañén | 41.942 | −0.356 | 323 | BSk | BSk | 0.75 | 0.41 | 2.86 | −0.96 | 0.77 | 74.71 |
| HU12 | Huerto | 41.947 | −0.138 | 415 | BSk | BSk | 0.82 | 0.45 | 3.09 | −1.12 | 0.76 | 75.65 |
| Z06 | Ejea de los Caballeros | 42.097 | −1.196 | 316 | BSk | Cfa | 0.76 | 0.43 | 2.81 | −0.97 | 0.77 | 73.04 |
| HU13 | Gurrea de Gállego | 41.992 | −0.731 | 364 | BSk | BSk | 0.79 | 0.44 | 2.84 | −1.01 | 0.76 | 73.83 |
| HU15 | Alfántega | 41.821 | 0.148 | 249 | BSk | BSk | 0.77 | 0.43 | 2.86 | −1.02 | 0.77 | 75.33 |
| HU17 | Fraga | 41.494 | 0.354 | 98 | BSk | BSk | 0.75 | 0.42 | 2.52 | −0.88 | 0.78 | 73.75 |
| HU18 | Tardienta | 41.969 | −0.508 | 366 | BSk | BSk | 0.79 | 0.44 | 2.93 | −1.05 | 0.76 | 74.69 |
| HU19 | San Esteban de Litera | 41.882 | 0.304 | 316 | BSk | BSk | 0.81 | 0.45 | 2.82 | −1.04 | 0.77 | 76.01 |
| HU22 | Santa Cilia | 42.576 | −0.708 | 733 | Cfb | Csa | 0.76 | 0.43 | 2.47 | −0.87 | 0.77 | 71.23 |
| IB01 | Santa Eulalia del Río | 39.009 | 1.440 | 122 | Csa | BSk | 0.78 | 0.43 | 3.10 | −1.04 | 0.74 | 70.25 |
| M02 | Arganda del Rey | 40.310 | −3.498 | 531 | BSk | BSk | 0.80 | 0.44 | 2.91 | −1.07 | 0.76 | 73.43 |
| M05 | San Martín de la Vega | 40.233 | −3.560 | 516 | BSk | BSk | 0.78 | 0.43 | 2.83 | −1.01 | 0.77 | 73.65 |
| M06 | Chinchón | 40.192 | −3.469 | 534 | BSk | BSk | 0.78 | 0.43 | 2.63 | −0.94 | 0.77 | 72.70 |
| MA10 | Antequera | 37.034 | −4.563 | 457 | Csa | BSk | 0.79 | 0.43 | 3.39 | −1.18 | 0.75 | 73.46 |
| MU104 | Murcia | 37.977 | −0.984 | 128 | BSh | BSh | 0.85 | 0.46 | 3.84 | −1.33 | 0.73 | 74.75 |
| MU121 | Murcia | 37.939 | −1.135 | 54 | BSh | BSh | 0.83 | 0.45 | 3.21 | −1.13 | 0.73 | 73.97 |
| MU14 | Moratalla | 38.196 | −1.813 | 458 | BSk | BSk | 0.81 | 0.44 | 3.32 | −1.15 | 0.73 | 73.22 |
| NA02 | Fitero | 42.045 | −1.843 | 436 | BSk | Csa | 0.74 | 0.42 | 2.22 | −0.69 | 0.76 | 68.78 |
| NA03 | Cascante | 42.034 | −1.724 | 346 | BSk | BSk | 0.75 | 0.42 | 2.39 | −0.78 | 0.76 | 69.68 |
| NA04 | Ablitas | 41.996 | −1.645 | 338 | BSk | BSk | 0.77 | 0.43 | 2.49 | −0.88 | 0.76 | 70.05 |
| NA05 | Aibar/Oibar | 42.558 | −1.316 | 420 | Cfa | Csa | 0.75 | 0.42 | 2.22 | −0.71 | 0.78 | 69.71 |
| NA07 | Murillo el Fruto | 42.384 | −1.487 | 348 | Cfa | Csa | 0.75 | 0.42 | 2.57 | −0.89 | 0.77 | 70.52 |
| NA08 | Adiós | 42.686 | −1.747 | 443 | Cfb | Csa | 0.74 | 0.43 | 1.99 | −0.60 | 0.78 | 68.79 |
| NA09 | Artajona | 42.583 | −1.791 | 360 | Cfa | Cfa | 0.73 | 0.42 | 2.16 | −0.67 | 0.77 | 68.89 |
| NA10 | Miranda de Arga | 42.510 | −1.809 | 345 | Cfa | Csa | 0.73 | 0.41 | 2.17 | −0.65 | 0.78 | 69.05 |
| NA11 | Falces | 42.422 | −1.792 | 292 | Cfa | Csa | 0.75 | 0.42 | 2.30 | −0.74 | 0.77 | 69.31 |
| NA13 | Bargota | 42.477 | −2.299 | 382 | BSk | Cfa | 0.71 | 0.41 | 2.04 | −0.62 | 0.77 | 67.41 |
| NA15 | Arcos, Los | 42.539 | −2.185 | 421 | Cfa | Cfa | 0.72 | 0.41 | 2.03 | −0.59 | 0.77 | 67.10 |
| NA16 | Sesma | 42.473 | −2.127 | 456 | Cfa | Csa | 0.73 | 0.42 | 2.08 | −0.62 | 0.77 | 67.75 |
| NA18 | Tudela | 42.093 | −1.577 | 243 | BSk | BSk | 0.76 | 0.43 | 2.50 | −0.83 | 0.77 | 71.60 |
| P08 | Lantadilla | 42.345 | −4.278 | 793 | Csb | Csb | 0.75 | 0.42 | 2.24 | −0.74 | 0.79 | 69.95 |
| TE01 | Calanda | 40.960 | −0.210 | 439 | BSk | BSk | 0.79 | 0.44 | 2.91 | −1.05 | 0.75 | 71.79 |
| TE03 | Híjar | 41.215 | −0.530 | 306 | BSk | BSk | 0.81 | 0.45 | 2.97 | −1.07 | 0.75 | 73.90 |
| TE04 | Monreal del Campo | 40.780 | −1.355 | 950 | BSk | BSk | 0.74 | 0.42 | 2.38 | −0.78 | 0.75 | 68.26 |
| TE05 | Teruel | 40.347 | −1.166 | 914 | BSk | BSk | 0.71 | 0.41 | 2.07 | −0.62 | 0.75 | 67.18 |
| TO12 | Mora | 39.664 | −3.773 | 735 | BSk | BSk | 0.81 | 0.44 | 3.15 | −1.13 | 0.76 | 72.49 |
| V14 | Algemesí | 39.216 | −0.436 | 19 | Csa | Csa | 0.79 | 0.44 | 3.10 | −1.06 | 0.74 | 73.92 |
| V25 | Bolbaite | 39.068 | −0.690 | 267 | Csa | Csa | 0.68 | 0.39 | 2.46 | −0.85 | 0.74 | 69.96 |
| V26 | Bétera | 39.598 | −0.468 | 97 | BSk | BSk | 0.78 | 0.43 | 3.48 | −1.18 | 0.74 | 73.82 |
| V27 | Chulilla | 39.676 | −0.832 | 378 | BSk | BSk | 0.80 | 0.44 | 3.18 | −1.13 | 0.73 | 73.14 |
| V28 | Godelleta | 39.421 | −0.677 | 270 | Csa | Csa | 0.77 | 0.43 | 3.20 | −1.11 | 0.74 | 71.87 |
| V29 | Bèlgida | 38.879 | −0.454 | 281 | Csa | Csa | 0.76 | 0.42 | 3.22 | −1.09 | 0.74 | 73.01 |
| VA08 | Medina de Rioseco | 41.860 | −5.071 | 727 | Csb | Csb | 0.77 | 0.43 | 2.44 | −0.81 | 0.78 | 71.24 |
| Z01 | Almonacid de la Sierra | 41.451 | −1.330 | 384 | BSk | BSk | 0.76 | 0.43 | 2.55 | −0.90 | 0.76 | 70.62 |
| Z14 | Borja | 41.854 | −1.508 | 378 | BSk | Csa | 0.77 | 0.43 | 2.50 | −0.87 | 0.76 | 70.33 |
| Z16 | Caspe | 41.303 | −0.071 | 175 | BSk | BSk | 0.75 | 0.42 | 2.67 | −0.86 | 0.77 | 74.69 |
| Z17 | Osera de Ebro | 41.544 | −0.537 | 251 | BSk | BSk | 0.80 | 0.44 | 3.04 | −1.11 | 0.76 | 74.63 |
| Z18 | Daroca | 41.107 | −1.425 | 748 | BSk | BSk | 0.68 | 0.40 | 1.77 | −0.40 | 0.74 | 64.08 |
| Z21 | Tauste | 41.999 | −1.143 | 353 | BSk | BSk | 0.78 | 0.43 | 2.88 | −1.01 | 0.77 | 72.31 |
| Z22 | Boquiñeni | 41.842 | −1.250 | 227 | BSk | BSk | 0.76 | 0.42 | 2.76 | −0.95 | 0.76 | 71.32 |
| Z23 | Pastriz | 41.593 | −0.731 | 182 | BSk | BSk | 0.81 | 0.45 | 2.90 | −1.03 | 0.76 | 74.29 |
| Z24 | Calatayud | 41.362 | −1.615 | 523 | BSk | BSk | 0.74 | 0.42 | 2.39 | −0.79 | 0.77 | 69.08 |
| Z25 | Tauste | 41.905 | −1.310 | 237 | BSk | BSk | 0.77 | 0.42 | 2.80 | −0.95 | 0.76 | 72.36 |
| Z26 | Zuera | 41.888 | −0.766 | 288 | BSk | BSk | 0.78 | 0.43 | 2.92 | −1.02 | 0.77 | 73.66 |
| ZA08 | Toro | 41.507 | −5.366 | 652 | Csb | Csa | 0.77 | 0.43 | 2.52 | −0.86 | 0.78 | 71.39 |
| 5 Classes | 3 Classes | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Code | Station | k-Means | Spectral | k-Medoids | Hierarchical | k-Means | Spectral | k-Medoids | Hierarchical |
| A20 | Agost | 1 | 5 | 1 | 4 | 3 | 2 | 2 | 1 |
| A21 | Orihuela | 4 | 5 | 5 | 3 | 3 | 2 | 2 | 2 |
| BA08 | Don Benito | 1 | 2 | 1 | 4 | 3 | 2 | 2 | 1 |
| BA09 | Villafranca de los Barros | 1 | 2 | 1 | 4 | 3 | 2 | 2 | 1 |
| BU07 | Santa Gadea del Cid | 2 | 4 | 3 | 5 | 2 | 3 | 1 | 3 |
| C02 | Boimorto | 2 | 4 | 3 | 2 | 2 | 3 | 1 | 3 |
| CC16 | Moraleja | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| CC19 | Zarza de Granadilla | 3 | 3 | 4 | 4 | 1 | 1 | 3 | 1 |
| CO09 | Palma del Río | 1 | 5 | 1 | 4 | 3 | 2 | 2 | 1 |
| CR10 | Manzanares | 1 | 2 | 1 | 4 | 3 | 2 | 2 | 1 |
| CR11 | Montiel | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| CU09 | Mariana | 2 | 4 | 3 | 4 | 2 | 3 | 1 | 1 |
| GC09 | Antigua | 1 | 2 | 1 | 1 | 3 | 2 | 2 | 1 |
| HU01 | Valfarta | 1 | 2 | 1 | 4 | 3 | 2 | 2 | 1 |
| HU02 | Zaidín | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| HU03 | Alcolea de Cinca | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| HU04 | Tamarite de Litera | 5 | 1 | 2 | 4 | 1 | 1 | 3 | 1 |
| HU05 | Lanaja | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| HU08 | Sariñena | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| HU09 | Huesca | 3 | 3 | 4 | 4 | 2 | 3 | 3 | 1 |
| HU10 | Candasnos | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| HU11 | Grañén | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| HU12 | Huerto | 1 | 2 | 1 | 4 | 3 | 2 | 2 | 1 |
| Z06 | Ejea de los Caballeros | 5 | 1 | 2 | 4 | 1 | 1 | 3 | 1 |
| HU13 | Gurrea de Gállego | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| HU15 | Alfántega | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| HU17 | Fraga | 3 | 3 | 4 | 4 | 1 | 1 | 3 | 1 |
| HU18 | Tardienta | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| HU19 | San Esteban de Litera | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| HU22 | Santa Cilia | 3 | 3 | 4 | 4 | 1 | 3 | 3 | 1 |
| IB01 | Santa Eulalia del Río | 1 | 2 | 1 | 4 | 3 | 2 | 2 | 1 |
| M02 | Arganda del Rey | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| M05 | San Martín de la Vega | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| M06 | Chinchón | 3 | 3 | 4 | 4 | 1 | 1 | 3 | 1 |
| MA10 | Antequera | 1 | 5 | 1 | 4 | 3 | 2 | 2 | 1 |
| MU104 | Murcia | 4 | 5 | 5 | 3 | 3 | 2 | 2 | 2 |
| MU121 | Murcia | 1 | 2 | 1 | 4 | 3 | 2 | 2 | 1 |
| MU14 | Moratalla | 1 | 5 | 1 | 4 | 3 | 2 | 2 | 1 |
| NA02 | Fitero | 2 | 4 | 3 | 4 | 2 | 3 | 1 | 1 |
| NA03 | Cascante | 3 | 3 | 4 | 4 | 2 | 3 | 3 | 1 |
| NA04 | Ablitas | 3 | 3 | 4 | 4 | 1 | 1 | 3 | 1 |
| NA05 | Aibar/Oibar | 2 | 4 | 3 | 4 | 2 | 3 | 1 | 1 |
| NA07 | Murillo el Fruto | 3 | 3 | 4 | 4 | 1 | 1 | 3 | 1 |
| NA08 | Adiós | 2 | 4 | 3 | 4 | 2 | 3 | 1 | 1 |
| NA09 | Artajona | 2 | 4 | 3 | 4 | 2 | 3 | 1 | 1 |
| NA10 | Miranda de Arga | 2 | 4 | 3 | 4 | 2 | 3 | 1 | 1 |
| NA11 | Falces | 3 | 4 | 4 | 4 | 2 | 3 | 3 | 1 |
| NA13 | Bargota | 2 | 4 | 3 | 4 | 2 | 3 | 1 | 1 |
| NA15 | Arcos, Los | 2 | 4 | 3 | 4 | 2 | 3 | 1 | 1 |
| NA16 | Sesma | 2 | 4 | 3 | 4 | 2 | 3 | 1 | 1 |
| NA18 | Tudela | 3 | 3 | 4 | 4 | 1 | 3 | 3 | 1 |
| P08 | Lantadilla | 3 | 4 | 3 | 4 | 2 | 3 | 1 | 1 |
| TE01 | Calanda | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| TE03 | Híjar | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| TE04 | Monreal del Campo | 3 | 3 | 4 | 4 | 2 | 3 | 3 | 1 |
| TE05 | Teruel | 2 | 4 | 3 | 4 | 2 | 3 | 1 | 1 |
| TO12 | Mora | 1 | 2 | 1 | 4 | 3 | 2 | 2 | 1 |
| V14 | Algemesí | 1 | 2 | 1 | 4 | 3 | 2 | 2 | 1 |
| V25 | Bolbaite | 3 | 3 | 4 | 4 | 1 | 3 | 3 | 1 |
| V26 | Bétera | 1 | 5 | 1 | 4 | 3 | 2 | 2 | 1 |
| V27 | Chulilla | 1 | 2 | 1 | 4 | 3 | 2 | 2 | 1 |
| V28 | Godelleta | 1 | 2 | 1 | 4 | 3 | 2 | 2 | 1 |
| V29 | Bèlgida | 1 | 2 | 1 | 4 | 3 | 2 | 2 | 1 |
| VA08 | Medina de Rioseco | 3 | 3 | 4 | 4 | 2 | 3 | 3 | 1 |
| Z01 | Almonacid de la Sierra | 3 | 3 | 4 | 4 | 1 | 1 | 3 | 1 |
| Z14 | Borja | 3 | 3 | 4 | 4 | 1 | 1 | 3 | 1 |
| Z16 | Caspe | 3 | 3 | 4 | 4 | 1 | 1 | 3 | 1 |
| Z17 | Osera de Ebro | 1 | 2 | 1 | 4 | 3 | 2 | 2 | 1 |
| Z18 | Daroca | 2 | 4 | 3 | 5 | 2 | 3 | 1 | 3 |
| Z21 | Tauste | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| Z22 | Boquiñeni | 5 | 1 | 2 | 4 | 1 | 1 | 3 | 1 |
| Z23 | Pastriz | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| Z24 | Calatayud | 3 | 3 | 4 | 4 | 2 | 3 | 3 | 1 |
| Z25 | Tauste | 5 | 1 | 2 | 4 | 1 | 1 | 3 | 1 |
| Z26 | Zuera | 5 | 1 | 2 | 4 | 1 | 1 | 2 | 1 |
| ZA08 | Toro | 3 | 3 | 4 | 4 | 1 | 1 | 3 | 1 |
References
- Viera da Rosa, A.; Ordoñez, J.C. Fundamentals of Renewable Energy Processes; Academic Press: Cambridge, MA, USA, 2022. [Google Scholar] [CrossRef]
- Moukhtar, I.; El Dein, A.Z.; Elbaset, A.A.; Mitani, Y. Economic Study of Solar Energy Systems. In Solar Energy Power Systems; Springer: Cham, Switzerland, 2021. [Google Scholar] [CrossRef]
- Kabir, E.; Kumar, P.; Kumar, S.; Adelodun, A.A.; Kim, K.H. Solar energy: Potential and future prospects. Renew. Sustain. Energy Rev. 2018, 82, 894–900. [Google Scholar] [CrossRef]
- Kannan, N.; Vakeesan, D. Solar energy for future world: A review. Renew. Sustain. Energy Rev. 2016, 62, 1092–1105. [Google Scholar] [CrossRef]
- Zheng, J.; Zhang, H.; Dai, Y.; Wang, B.; Zheng, T.; Liao, Q.; Liang, Y.; Zhang, F.; Song, X. Time series prediction for output of multi-region solar power plants. Appl. Energy 2020, 257, 114001. [Google Scholar] [CrossRef]
- Sørensen, B. Solar Energy Storage; Academic Press: Copenhagen, Denmark, 2015. [Google Scholar] [CrossRef]
- Stoustrup, J.; Annaswamy, A.; Chakrabortty, A.; Qu, Z. Smart Grid Control; Springer International Publishing: Berlin, Germany, 2019. [Google Scholar] [CrossRef]
- Blaga, R.; Sabadus, A.; Stefu, N.; Dughir, C.; Paulescu, M.; Badescu, V. A current perspective on the accuracy of incoming solar energy forecasting. Prog. Energy Combust. Sci. 2019, 70, 119–144. [Google Scholar] [CrossRef]
- Notton, G.; Nivet, M.L.; Voyant, C.; Paoli, C.; Darras, C.; Motte, F.; Fouillot, A. Intermittent and stochastic character of renewable energy sources: Consequences, cost of intermittence and benefit of forecasting. Renew. Sustain. Energy Rev. 2018, 87, 96–105. [Google Scholar] [CrossRef]
- Perez, R. Wind Field and Solar Radiation Characterization and Forecasting: A Numerical Approach for Complex Terrain; Springer: Berlin, Germany, 2018. [Google Scholar] [CrossRef]
- Doorga, J.R.S.; Rughooputh, S.D.D.V.; Boojhawon, R. Modelling the global solar radiation climate of Mauritius using regression techniques. Renew. Energy 2019, 131, 861–878. [Google Scholar] [CrossRef]
- Fouilloy, A.; Voyant, C.; Notton, G.; Motte, F.; Paoli, C.; Nivet, M.L.; Guillot, E.; Duchaud, J.L. Solar irradiation prediction with machine learning: Forecasting models selection method depending on weather variability. Energy 2018, 165, 620–629. [Google Scholar] [CrossRef]
- Wang, L.; Kisi, O.; Zounemat-Kermani, M.; Salazar, G.A.; Zhu, Z.; Gong, W. Solar radiation prediction using different techniques: Model evaluation and comparison. Renew. Sustain. Energy Rev. 2016, 61, 384–397. [Google Scholar] [CrossRef]
- Zebari, R.; Abdulazeez, A.; Zeebaree, D.; Zebari, D.; Saeed, J.A. Comprehensive Review of Dimensionality Reduction Techniques for Feature Selection and Feature Extraction. J. Appl. Sci. Technol. Trends 2020, 1, 56–70. [Google Scholar] [CrossRef]
- Borra, S.; Thanki, R.; Dey, N. Satellite Image Analysis: Clustering and Classification; Springer Briefs in Applied Sciences and Technology; Springer: Singapore, 2019. [Google Scholar] [CrossRef]
- Warren Liao, T. Clustering of time series data A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Wang, X.; Smith, K.; Hyndman, R. Characteristic-based clustering for time series data. Data Min. Knowl. Discov. 2006, 13, 335–364. [Google Scholar] [CrossRef]
- Aghabozorgi, S.; Seyed Shirkhorshidi, A.; Ying Wah, Y. Time-series clustering-A decade review. Inf. Syst. 2015, 53, 16–38. [Google Scholar] [CrossRef]
- Maharaj, E.A.; D’Urso, P.; Caiado, J. Time Series Clustering and Classification, 1st ed.Chapman and Hall/CRC Press: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Tripathi, S.L.; Rishiwal, M.K.D.V.; Padmanaban, S. Introduction to AI Techniques for Renewable Energy Systems, 1st ed.; CRC Press: New York, NY, USA, 2021; ISBN 978-0367610920. [Google Scholar]
- Hartmann, B. Comparing various solar irradiance categorization methods—A critique on robustness. Renew. Energy 2020, 154, 661–671. [Google Scholar] [CrossRef]
- Jiménez-Pérez, P.F.; Mora-López, L. Modeling and forecasting hourly global solar radiation using clustering and classification techniques. Sol. Energy 2016, 135, 682–691. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, Y.; Wang, D.; Wang, Y.; Li, Y.; Zhu, Y. Classification of solar radiation zones and general models for estimating the daily global solar radiation on horizontal surfaces in China. Energy Convers. Manag. 2017, 154, 168–179. [Google Scholar] [CrossRef]
- Hassan, M.A.; Abubakr, M.; Khalil, A. A profile-free non-parametric approach towards generation of synthetic hourly global solar irradiation data from daily totals. Renew. Energy 2021, 167, 613–628. [Google Scholar] [CrossRef]
- Laguarda, A.; Alonso-Suárez, R.; Terra, R. Solar irradiation regionalization in Uruguay: Understanding the interannual variability and its relation to El Niño climatic phenomena. Renew. Energy 2020, 158, 444–452. [Google Scholar] [CrossRef]
- Pham, T.T.N.; Pham, T.H.; Vu, T.H. Satellite-Based Regionalization of Solar Irradiation in Vietnam by k-Means Clustering. J. Appl. Meteorol. Climatol. 2021, 60, 391–402. [Google Scholar] [CrossRef]
- Maldonado-Salguero, P.; Bueso-Sanchez, M.C.; Molina-Garcia, A.; Sanchez-Lozano, J.M. Spatio-Temporal Dynamic Clustering Modeling for Solar Irradiance Resource Assessment. 2022. Available online: https://ssrn.com/abstract=4121126 (accessed on 1 August 2022). [CrossRef]
- Feng, C.; Cui, M.; Hodge, B.M.; Lu, S.; Hamann, H.F.; Zhang, J. Unsupervised Clustering-Based Short-Term Solar Forecasting. IEEE Trans. Sustain. Energy 2019, 10, 2174–2185. [Google Scholar] [CrossRef]
- Malakar, S.; Goswami, S.; Ganguli, B.; Chakrabarti, A.; Roy, S.S.; Boopathi, K.; Rangaraj, A.G. Deep-Learning-Based Adaptive Model for Solar Forecasting Using Clustering. Energies 2022, 15, 3568. [Google Scholar] [CrossRef]
- Nasraoui, O.; Ben N’Cir, C.E. Clustering Methods for Big Data Analytics; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Ministerio de Agricultura, Pesca y Alimentación. 2018. Available online: https://www.mapa.gob.es/en/ (accessed on 12 August 2021).
- Beck, H.E.; Zimmermann, N.E.; McVicar, T.R.; Vergopolan, N.; Berg, A.; Wood, E.F. Present and future köppen-geiger climate classification maps at 1-km resolution. Sci. Data 2018, 5, 180214. [Google Scholar] [CrossRef] [Green Version]
- Trapletti, A.; Leisch, F.; Hornik, K. Stationary and Integrated Autoregressive Neural Network Processes. Neural Comput. 2000, 12, 2427–2450. [Google Scholar] [CrossRef]
- Badescu, V.; Gueymard, C.A.; Cheval, S.; Oprea, C.; Baciu, M.; Dumetrescu, A.; Iacobescu, F.; Milos, I.; Rada, C. Computing global and diffuse solar hourly irradiation on clear sky. Review and testing of 54 models. Renew. Sustain. Energy Rev. 2012, 16, 1636–1656. [Google Scholar] [CrossRef]
- Ineichen, P. Validation of models that estimate the clear sky global and beam solar irradiance. Sol. Energy 2016, 132, 332–344. [Google Scholar] [CrossRef]
- Mueller, R.W.; Dagestad, K.F.; Ineichen, P.; Schroedler Homscheidt, M.; Cros, S.; Dumortier, D.; Kuhlemann, R.; Olseth, J.; Piernavieja, G.; Reise, C.; et al. Rethinking satellite-based solar irradiance modelling: The SOLIS clear-sky module. Remote Sens. Environ. 2004, 91, 160–174. [Google Scholar] [CrossRef]
- Ineichen, P. A broadband simplified version of the Solis clear sky model. Sol. Energy 2008, 82, 758–762. [Google Scholar] [CrossRef]
- Rigollier, C.; Bauer, O.; Wald, L. Radiation atlas with respect to the heliosat method. Sol. Energy 2000, 68, 33–48. [Google Scholar] [CrossRef]
- Gueymard, C.A. REST2: High-performance solar radiation model for cloudless-sky irradiance, illuminance, and photosynthetically active radiation-Validation with a benchmark dataset. Sol. Energy 2008, 82, 272–285. [Google Scholar] [CrossRef]
- Qu, Z.; Oumbe, A.; Blanc, P.; Espinar, B.; Gesell, G.; Gschwind, B.; Klüser, L.; Lefèvre, M.; Saboret, L.; Schroedter-Homscheidt, M.; et al. Fast radiative transfer parameterisation for assessing the surface solar irradiance: The Heliosat-4 method. Meteorol. Z. 2017, 26, 33–57. [Google Scholar] [CrossRef]
- Lefèvre, M.; Oumbe, A.; Blanc, P.; Espinar, B.; Gschwind, B.; Qu, Z.; Wald, L.; Schroedter-Homscheidt, M.; Hoyer-Klick, C.; Arola, A.; et al. McClear: A new model estimating downwelling solar radiation at ground level in clear-sky conditions. Atmos. Meas. Tech. 2013, 6, 2403–2418. [Google Scholar] [CrossRef]
- Gschwind, B.; Wald, L.; Blanc, P.; Lefèvre, M.; Schroedter-Homscheidt, M.; Arola, A. Improving the McClear model estimating the downwelling solar radiation at ground level in cloud-free conditions-McClear-v3. Meteorol. Z. 2019, 28, 147–163. [Google Scholar] [CrossRef]
- Monitoring Atmospheric Composition and Climate|Copernicus. 2021. Available online: https://www.copernicus.eu/en/monitoring-atmospheric-composition-and-climate (accessed on 7 October 2021).
- Espinar, B.; Blanc, P.; Wald, L.; Hoyer-Klick, C.; Schroedter-Homscheidt, M.; Wanderer, T. On Quality Control Procedures for Solar Radiation and Meteorological Measures, from Subhourly to Monthly Average Time Periods; EGU General Assembly: Vienna, Austria, 2012; Available online: http://elib.dlr.de/80168/ (accessed on 23 March 2021).
- El Alani, O.; Ghennioui, H.; Ghennioui, G.; Saint-Drenan, Y.M.; Blanc, P.; Hanrieder, N.; Dahr, F.E. A visual support of standard procedures for solar radiation quality control. Int. J. Renew. Energy Dev. 2021, 10, 401–414. [Google Scholar] [CrossRef]
- Yesilbudak, M.; Colak, M.; Bayindir, R. A review of data mining and solar power prediction. In Proceedings of the 2016 IEEE International Conference on Renewable Energy Research and Applications (ICRERA), Birmingham, UK, 20–23 November 2016; pp. 1117–1121. [Google Scholar] [CrossRef]
- Forstinger, A.; Wilbert, S.; Driesse, A.; Hanrieder, N.; Affolter, R.; Kumar, S.; Goswami, N.; Geuder, N.; Vignola, F.; Zarzalejo, L.; et al. Physically based correction of systematic errors of Rotating Shadowband Irradiometers. Meteorol. Z. 2020, 29, 19–39. [Google Scholar] [CrossRef]
- Yang, D. Solar radiation on inclined surfaces: Corrections and benchmarks. Sol. Energy 2016, 136, 288–302. [Google Scholar] [CrossRef]
- Kosmopoulos, P.G.; Kazadzis, S.; Taylor, M.; Raptis, P.L.; Keramitsoglou, I.; Kiranoudis, C.; Bais, A.F. Assessment of surface solar irradiance derived from real-time modelling techniques and verification with ground-based measurements. Atmos. Meas. Tech. 2018, 11, 907–924. [Google Scholar] [CrossRef]
- Walpole, R.; Myers, R.; Myers, S.; Ye, K. Probability & Statistics for Engineers & Scientists; Pearson Ed.: Edinburgh Gate, UK, 2016. [Google Scholar]
- Bojanowski, J.S.; Vrieling, A.; Skidmore, A.K. A comparison of data sources for creating a long-term time series of daily gridded solar radiation for Europe. Sol. Energy 2014, 99, 152–171. [Google Scholar] [CrossRef]
- David, D.P.; Seward, L.E. Measuring Skewness: A Forgotten Statistic? J. Stat. Educ. 2011, 19, 1–18. [Google Scholar] [CrossRef]
- Brys, G.; Hubert, M.; Struyf, A. A Robust Measure of Skewness. J. Comput. Graph. Stat. 2004, 13, 996–1017. [Google Scholar] [CrossRef]
- Mohammed, M.B.; Adam, M.B.; Ali, N.; Zulkafli, H.S. Improved frequency table’s measures of skewness and kurtosis with application to weather data. Commun. Stat. Theory Methods Commun. Stat. Theory Methods 2022, 51, 581–598. [Google Scholar] [CrossRef]
- Groeneveld, R.A.; Meeden, G. Measuring Skewness and Kurtosis. J. R. Stat. Soc. Ser. D (Stat.) 1984, 33, 391–399. [Google Scholar] [CrossRef]
- Ruppert, D. What is Kurtosis? An Influence Function Approach. Am. Stat. 1987, 41, 1–5. [Google Scholar] [CrossRef]
- Girone, G.; Massari, A.; Campobasso, F.; D’Uggento, A.M.; Marin, C.; Manca, F. A proposal of new disnormality indexes. Commun. Stat.-Theory Methods 2021, 1–17. [Google Scholar] [CrossRef]
- Yang, D.; Dong, Z.; Lim, L.H.I.; Liu, L. Analyzing big time series data in solar engineering using features and PCA. Sol. Energy 2017, 153, 317–328. [Google Scholar] [CrossRef]
- Mandelbrot, B.B. Self-affine fractals and fractal dimension. Phys. Scr. 1985, 32, 257–260. [Google Scholar] [CrossRef]
- Cadenas, E.; Campos-Amezcua, R.; Rivera, W.; Espinosa-Medina, M.A.; Méndez-Gordillo, A.R.; Rangel, E.; Tena, J. Wind speed variability study based on the Hurst coefficient and fractal dimensional analysis. Energy Sci Eng. 2019, 7, 361–378. [Google Scholar] [CrossRef]
- Barbulescu, A.; Serban, C.; Maftei, C. Statistical analysis and evaluation of Hurst coefficient for annual and monthly precipitation time series. WSEAS Trans. Math. 2010, 10, 791–800. [Google Scholar]
- Shesh, S.R.; Koirala, R.; Gentry, R.; Perfect, E.; Mulholland, P.J.; Schwartz, J.S. Hurst Analysis of Hydrologic and Water Quality Time Series. J. Hydrol. Eng. 2011, 16, 717–724. [Google Scholar] [CrossRef]
- Mielniczuk, J.; Wojdyłło, P. Estimation of Hurst exponent revisited. Comput. Stat. Data Anal. 2007, 51, 4510–4525. [Google Scholar] [CrossRef]
- López-Lambraño, A.; Carrillo-Yee, E.; Fuentes, C.; López-Ramos, A.; López-Lambraño, M. Una revisión de los métodos para estimar el exponente de Hurst y la dimensión fractal en series de precipitación y temperatura. Rev. Mex. Fis. 2017, 63, 244–267. [Google Scholar]
- Notton, G.; Voyant, C. Chapter 3: Forecasting of Intermittent Solar Energy Resource. In Advances in Renewable Energies and Power Technologies, 1st ed.; Yahyaoui, I., Ed.; Elsevier Inc.: Amsterdam, The Netherlands, 2018; pp. 77–114. [Google Scholar] [CrossRef]
- Voyant, C.; Lauret, P.; Notton, G.; Duchaud, J.L.; Fouilloy, A.; David, M.; Mundher Yaseen, Z.; Soubdhan, T. A Monte Carlo based solar radiation forecastability estimation. J. Renew. Sustain. Energy 2021, 13, 1–13. [Google Scholar] [CrossRef]
- Wang, Z.; Lv, J.; Tan, Y.; Guo, M.; Gu, Y.; Xu, S.; Zhou, Y. Temporospatial variations and Spearman correlation analysis of ozone concentrations to nitrogen dioxide, sulfur dioxide, particulate matters and carbon monoxide in ambient air, China. Atmos. Pollut. Res. 2019, 10, 1203–1210. [Google Scholar] [CrossRef]
- Welcome to the QGIS Project! 2021. Available online: https://qgis.org/en/site/ (accessed on 25 November 2021).
- Agencia Estatal de Meteorología; Ministerio de Medio Ambiente y Rural y Marino; Instituto de Meteorologia de Portugal. Atlas Climático Ibérico/Iberian Climate Atlas; Agencia Estatal de Meteorología: Madrid, Spain, 2011; ISBN 978-84-7837-079-5. [CrossRef]
- Fortuna, L.; Nunnari, G.; Nunnari, S. Nonlinear Modeling of Solar Radiation and Wind Speed Time Series, 1st ed.; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Wu, J.; Chan, C.K.; Zhang, Y.; Xiong, B.Y.; Zhang, Q.H. Prediction of solar radiation with genetic approach combing multi-model framework. Renew. Energy 2014, 66, 132–139. [Google Scholar] [CrossRef]
- Prasad, J.C.; Prasad, M.V.N.K.; Nickolas, S.; Gangadharan, G.R. Trendlets: A novel probabilistic representational structures for clustering the time series data. Expert Syst. Appl. 2020, 145, 113119. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning Data Mining, Inference and Prediction, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef]
- Park, H.S.; Jun, C.H. A simple and fast algorithm for K-medoids clustering. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar] [CrossRef]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Bradley, P.S.; Fayyad, U.M. Refining initial points for k-means clustering. In Proceedings of the 15th International Conference on Machine Learning, Madison, WI, USA, 24–27 July 1998; pp. 91–99. [Google Scholar]
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. On clustering validation techniques. J. Intell. Inf. Syst. (JIIS) 2001, 17, 107–145. [Google Scholar] [CrossRef]
- Keogh, E.; Lin, J.; Truppel, W. Clustering of time series subsequences is meaningless: Implications for past and future research. In Proceedings of the Third IEEE International Conference on Data Mining, Melbourne, FL, USA, 22 November 2003; pp. 115–122. [Google Scholar]
- Ezugwu, E.; Ikotun, M.; Oyelade, O.; Abualigah, L.; Agushaka, O.; Eke, I.; Akinyelu, A. A comprehensive survey of clustering algorithms: State-of-the-art machine learning applications, taxonomy, challenges, and future research prospects. Eng. Appl. Artif. Intell. 2022, 110, 104743. [Google Scholar] [CrossRef]
- Scitovski, R.; Sabo, K.; Martínez-Álvarez, F.; Ungar, S. Cluster analysis and Applications, 1st ed.; Springer: Cham, Switzerland, 2021. [Google Scholar] [CrossRef]
- Estivill-Castro, V. Why so many clustering algorithms: A position paper. ACM SIGKDD Explor. Newsl. 2002, 4, 65–75. [Google Scholar] [CrossRef]
- Wierzchoń, S.T.; Kłopotek, M.A. Modern Algorithms of Cluster Analysis, 1st ed.; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Xiong, H.; Gao, X.; Wu, J. Understanding of internal clustering validation measures. In Proceedings of the 2010 IEEE International Conference on Data Mining, ICDM, Sydney, NSW, Australia, 14–17 December 2010; pp. 911–916. [Google Scholar] [CrossRef]
- Maulik, U.; Bandyopadhyay, S. Performance evaluation of some clustering algorithms and validity indices. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1650–1654. [Google Scholar] [CrossRef]
- Amigó, E.; Gonzalo, J.; Artiles, J.; Verdejo, F. A comparison of extrinsic clustering evaluation metrics based on formal constraints. Inf. Retr. Boston 2009, 12, 461–486. [Google Scholar] [CrossRef]
- Rand, W.M. Objective Criteria for the Evaluation of Clustering Methods. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar] [CrossRef]
- Wagner, S.; Wagner, D. Comparing Clusterings—An Overview. 2007. Available online: https://publikationen.bibliothek.kit.edu/1000011477 (accessed on 3 March 2021). [CrossRef]




















| 2020 | 2019 | 2018 | 2017 | |
|---|---|---|---|---|
| Total SIAR station | 542 | |||
| Active SIAR Stations | 448 | |||
| Selected * SIAR Stations | 94 | 84 | 82 | 78 |
| Discarded ** SIAR stations | 10 | 2 | 4 | 2 |
| Subtotal | 84 | 82 | 78 | 76 |
| Clustering Method | Basis of Algorithm | Input to Algorithm | Requires Specified Number of Clusters | Cluster Shapes Identified |
|---|---|---|---|---|
| Hierarchical | Distance between objects | Pairwise distances between observations | No | Arbitrarily shaped clusters, depending on the specified “Linkage” algorithm |
| k-Means k-Medoids | Distance between objects and centroids | Actual observations | Yes | Spheroidal clusters with equal diagonal covariance |
| Spectral | Graph representing connections between data points | Actual observations or similarity matrix | Yes, but the algorithm also provides a way to estimate the number of clusters | Arbitrarily shaped clusters |
| k-Means (%) | Spectral (%) | k-Medoids (%) | Hierarchical (%) | Köppen (%) | |
|---|---|---|---|---|---|
| k-means | 100 | 95 | 99 | 35 | 53 |
| Spectral | 95 | 100 | 96 | 32 | 52 |
| k-medoids | 99 | 96 | 100 | 35 | 53 |
| Hierarchical | 35 | 32 | 35 | 100 | 51 |
| Köppen | 53 | 52 | 53 | 51 | 100 |
| k-Means (%) | Spectral (%) | k-Medoids (%) | Hierarchical (%) | Köppen (%) | |
|---|---|---|---|---|---|
| k-means | 100 | 91 | 99 | 37 | 49 |
| Spectral | 91 | 100 | 92 | 37 | 47 |
| k-medoids | 99 | 92 | 100 | 37 | 49 |
| Hierarchical | 37 | 37 | 37 | 100 | 64 |
| Köppen | 49 | 47 | 49 | 64 | 100 |
| k-Means (%) | Spectral (%) | k-Medoids (%) | Hierarchical (%) | Köppen (%) | |
|---|---|---|---|---|---|
| k-means | 100 | 95 | 70 | 41 | 51 |
| Spectral | 95 | 100 | 69 | 40 | 52 |
| k-medoids | 70 | 69 | 100 | 44 | 60 |
| Hierarchical | 41 | 40 | 44 | 100 | 53 |
| Köppen | 51 | 52 | 60 | 53 | 100 |
| k-Means (%) | Spectral (%) | k-Medoids (%) | Hierarchical (%) | Köppen (%) | |
|---|---|---|---|---|---|
| k-means | 100 | 96 | 67 | 53 | 58 |
| Spectral | 96 | 100 | 63 | 49 | 58 |
| k-medoids | 67 | 63 | 100 | 54 | 55 |
| Hierarchical | 53 | 49 | 54 | 100 | 62 |
| Köppen | 58 | 58 | 55 | 62 | 100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garcia-Gutierrez, L.; Voyant, C.; Notton, G.; Almorox, J. Evaluation and Comparison of Spatial Clustering for Solar Irradiance Time Series. Appl. Sci. 2022, 12, 8529. https://doi.org/10.3390/app12178529
Garcia-Gutierrez L, Voyant C, Notton G, Almorox J. Evaluation and Comparison of Spatial Clustering for Solar Irradiance Time Series. Applied Sciences. 2022; 12(17):8529. https://doi.org/10.3390/app12178529
Chicago/Turabian StyleGarcia-Gutierrez, Luis, Cyril Voyant, Gilles Notton, and Javier Almorox. 2022. "Evaluation and Comparison of Spatial Clustering for Solar Irradiance Time Series" Applied Sciences 12, no. 17: 8529. https://doi.org/10.3390/app12178529
APA StyleGarcia-Gutierrez, L., Voyant, C., Notton, G., & Almorox, J. (2022). Evaluation and Comparison of Spatial Clustering for Solar Irradiance Time Series. Applied Sciences, 12(17), 8529. https://doi.org/10.3390/app12178529