



The Holistic Perspective of the INCISIVE Project—Artificial Intelligence in Screening Mammography

 , , ,
, , ,  , , , ,
, , , ,  ,
,  , , ,
, , ,  , and
, and
Abstract
:1. Introduction
2. Relevance and Challenges
2.1. Bring Together AI and Medical Experts
2.2. Legal, Ethics, and Data Sharing
Legal Challenges
- A retrospective study—the model training/development of the INCISIVE AI toolbox.
- A prospective observational study—the validation of the INCISIVE AI toolbox.
- A prospective feasibility study—the evaluation of the INCISIVE AI toolbox.
3. Data Preparation and Integration
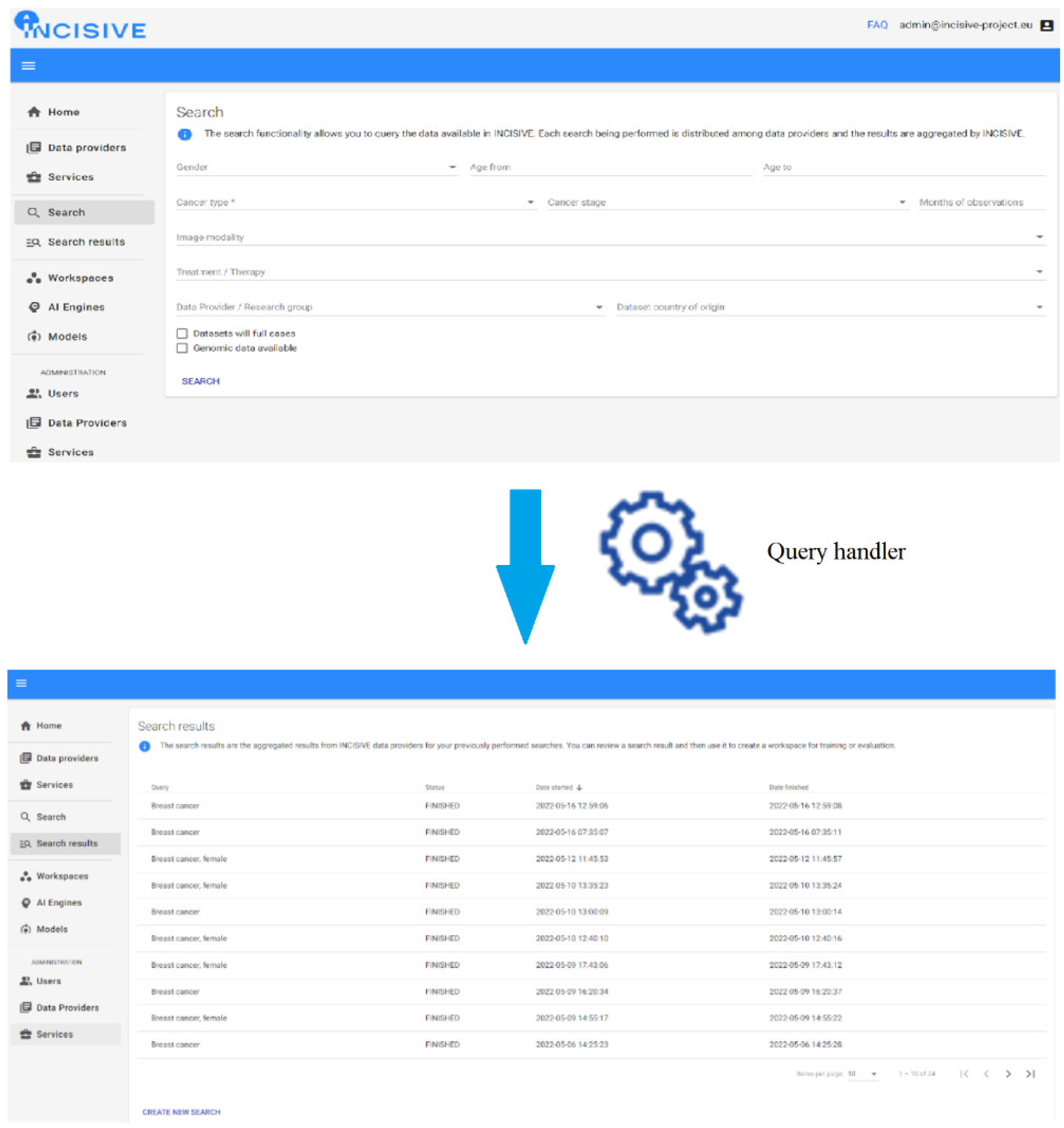
3.1. Data Integration and Quality Check Tool
3.2. Annotation and De-Identification Tools
3.2.1. Annotation
- classification where the whole image is assigned a corresponding label;
- bounding box where a rectangular region of interest is assigned a corresponding label;
- segmentation where each pixel is assigned a corresponding label.
- SiteID is completed from each data provider (e.g., 001 for CERTH, 002 for ICCS, etc.).
- PatientID is created by the de-identification procedure, which took place before annotation (e.g., 000001, 000002).
- Modality is completed from each data provider (e.g., MRI, PETCT, CT, MMG, US, HP).
- Timepoint (BL, TP1, TP2, TP3).
3.2.2. De-Identification
- The real name of the patient (or the alternative identifiable information that each data provider chooses (e.g., a social security number);
- The ID (a variable number of characters for the pilot’s name (e.g., AUTH), followed by a dash, followed by a five-digit incremental number).
3.3. Interoperability Standards and Data Model
3.4. Data Collection and Integration Experiences—Breast Cancer
- a common clinical data schema, i.e., a structural embedding designed to suit all types of information;
- standards of medical terminology to be used, as agreed by a consensus among data providers;
- image de-identification (CTP DICOM anonymizer [38]);
- evaluation of the data quality and compliance (Section 3.1);
4. Results to the Existing Data Repository
4.1. Data Sharing
4.2. Federated Sharing
- The data preparation toolset is a set of tools that operate at each data provider’s site before the data federation stage so that the data becomes GDPR-compliant and appropriately processed (e.g., annotated, where relevant). The main tools that support this process are the data de-identification tool, the data annotation tool, the data curation tool, and the data quality check tool. These tools ensure that the data undergoes a correct pre-process to fulfill the system preconditions before being stored in the INCISIVE platform (see Section 3.1 data integration and 3.2 annotation and de identification).
- The federated node is the node that is hosted by the data provider where the data is stored. The data do not leave the related premises; therefore, the data partners keep full control.
- The federated space is the Cloud environment that contains the centralized services required to offer the federated INCISIVE functionalities.
4.3. INCISIVE Retrospective Data—Breast Cancer Mammograpy Collection
5. Description of AI Toolbox/Breast Cancer Tools
5.1. Federated Learning—Data Exploitation
5.1.1. How It Is Performed
- Orchestrator: in charge of receiving the training requests and deploying the required components in the central node and in the federated nodes.
- Model-as-a-service (MaaS): in charge of storing models and performing inference.
- AI federator: in charge of managing the federated learning process (send training requests, receive weights, and merge models).
- AI engine: in charge of performing the actual training at each federated node. This component is composed of auxiliary components to provide data and retrieve results from a standard machine learning application agnostic of the federated learning and the infrastructure.
- A train request is received in the UI.
- The orchestrator analyzes the request, and a specific AI federator and AI engines of the federated nodes are deployed.
- The AI federator initializes the model or loads a previously trained model from the MaaS, depending on if training from scratch or training from a pretrained model is requested.
- The AI engine receives the model and trains it, using local data available.
- The AI federator receives the trained models and merges them using a merging scheme, e.g., FedAvg [47].
- In case another federated learning round is required, the process restarts from Step 4, sending the new merged model to the AI engines.
- Finally, the model is stored in the MaaS.
5.1.2. Hybrid Infrastructure and Federated Learning
5.2. Preliminary Results—Initial Analysis on Mammography
5.2.1. Data Quality and Related Pre-Processing
5.2.2. Annotation Style
6. Conclusions and Next Steps
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bi, W.L.; Hosny, A.; Schabath, M.B.; Giger, M.L.; Birkbak, N.J.; Mehrtash, A.; Allison, T.; Arnaout, O.; Abbosh, C.; Dunn, I.F.; et al. Artificial intelligence in cancer imaging: Clinical challenges and applications. CA Cancer J. Clin. 2019, 69, 127–157. [Google Scholar] [CrossRef] [PubMed]
- Lima, Z.S.; Ebadi, M.R.; Amjad, G.; Younesi, L. Application of Imaging in Breast Cancer Detection: A Review Article. Maced. J. Med. Sci. 2019, 7, 838–848. [Google Scholar] [CrossRef] [PubMed]
- Munir, K.; Elahi, H.; Ayub, A.; Frezza, F.; Rizzi, A. Cancer diagnosis using deep learning: A bibliographic review. Cancers 2019, 11, 1235. [Google Scholar] [CrossRef] [PubMed]
- Michael, E.; Ma, H.; Li, H.; Kulwa, F.; Li, J. Breast cancer segmentation methods: Current status and future potentials. BioMed Res. Int. 2021, 2021, 9962109. [Google Scholar] [CrossRef]
- Immonen, E.; Wong, J.; Nieminen, M.; Kekkonen, L.; Roine, S.; Törnroos, S.; Lanca, L.; Guan, F.; Metsälä, E. The use of deep learning towards dose optimization in low-dose computed tomography: A scoping review. Radiography 2021, 28, 208–214. [Google Scholar] [CrossRef]
- Davenport, T.; Kalakota, R. The potential for artificial intelligence in healthcare. Future Health J. 2019, 6, 94–98. [Google Scholar] [CrossRef]
- Mahadevaiah, G.; Rv, P.; Bermejo, I.; Jaffray, D.; Dekker, A.; Wee, L. Artificial intelligence-based clinical decision support in modern medical physics: Selection, acceptance, commissioning, and quality assurance. Med. Phys. 2020, 47, e228–e235. [Google Scholar] [CrossRef]
- Iqbal, M.J.; Javed, Z.; Sadia, H.; Qureshi, I.A.; Irshad, A.; Ahmed, R.; Malik, K.; Raza, S.; Abbas, A.; Pezzani, R.; et al. Clinical applications of artificial intelligence and machine learning in cancer diagnosis: Looking into the future. Cancer Cell Int. 2021, 21, 270. [Google Scholar] [CrossRef]
- Tarumi, S.; Takeuchi, W.; Chalkidis, G.; Rodriguez-Loya, S.; Kuwata, J.; Flynn, M.; Kawamoto, K. Leveraging artificial intelligence to improve chronic disease care: Methods and application to pharmacotherapy decision support for type-2 diabetes mellitus. Methods Inf. Med. 2021, 60, e32–e43. [Google Scholar] [CrossRef]
- Miller, D.D.; Brown, E.W. Artificial Intelligence in Medical Practice: The Question to the Answer? Am. J. Med. 2018, 131, 129–133. [Google Scholar] [CrossRef]
- Meskó, B.; Görög, M. A short guide for medical professionals in the era of artificial intelligence. NPJ Digit. Med. 2020, 3, 126. [Google Scholar] [CrossRef]
- Bohr, A.; Memarzadeh, K. The rise of artificial intelligence in healthcare applications. Artif. Intell. Healthc. 2020, 25–60. [Google Scholar] [CrossRef]
- Langlotz, C.P.; Allen, B.; Erickson, B.J.; Kalpathy-Cramer, J.; Bigelow, K.; Cook, T.S.; Flanders, A.E.; Lungren, M.P.; Mendelson, D.S.; Rudie, J.D.; et al. A Roadmap for Foundational Research on Artificial Intelligence in Medical Imaging: From the 2018 NIH/RSNA/ACR/The Academy Workshop. Radiology 2019, 291, 781–791. [Google Scholar] [CrossRef] [PubMed]
- Gerke, S.; Minssen, T.; Cohen, G. Ethical and legal challenges of artificial intelligence-driven healthcare. Artif. Intell. Healthc. 2020, 295–336. [Google Scholar] [CrossRef]
- Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the Protection of Natural Persons with Regard to the Processing of Personal Data and on the Free Movement of Such Data, and Repealing Directive 95/46/EC (General Data Protection Regulation, GDPR). Available online: https://eur-lex.europa.eu/eli/reg/2016/679/oj (accessed on 18 August 2022).
- Geis, J.R.; Brady, A.P.; Wu, C.C.; Spencer, J.; Ranschaert, E.; Jaremko, J.L.; Langer, S.G.; Kitts, A.B.; Birch, J.; Shields, W.F.; et al. Ethics of Artificial Intelligence in Radiology: Summary of the Joint European and North American Multisociety Statement. J. Am. Coll. Radiol. 2019, 16, 1516–1521. [Google Scholar] [CrossRef]
- Van Veen, E.; Boeckhout, M.; Schlünder, I.; Boiten, J.W.; Dias, V. Joint controllers in large research consortia: A funnel model to distinguish controllers in the sense of the GDPR from other partners in the consortium [version 1; peer review: Awaiting peer review]. Open Res. Eur. 2022, 2, 80. [Google Scholar] [CrossRef]
- Scheibner, J.; Raisaro, J.L.; Troncoso-Pastoriza, J.R.; Ienca, M.; Fellay, J.; Vayena, E.; Hubaux, J.P. Revolutionizing Medical Data Sharing Using Advanced Privacy-Enhancing Technologies: Technical, Legal, and Ethical Synthesis. J. Med. Internet Res. 2021, 23, e25120. [Google Scholar] [CrossRef]
- Wan, Z.; Hazel, J.W.; Clayton, E.W.; Vorobeychik, Y.; Kantarcioglu, M.; Malin, B.A. Sociotechnical safeguards for genomic data privacy. Nat. Rev. Genet. 2022, 23, 429–445. [Google Scholar] [CrossRef]
- Thorogood, A.; Rehm, H.L.; Goodhand, P.; Page, A.J.H.; Joly, Y.; Baudis, M.; Rambla, J.; Navarro, A.; Nyronen, T.H.; Linden, M.; et al. International federation of genomic medicine databases using GA4GH standards. Cell Genom. 2021, 1, 100032. [Google Scholar] [CrossRef]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [Green Version]
- Regulation (EU) 2022/868 of the European Parliament and of the Council of 30 May 2022 on European Data Governance and Amending Regulation (EU) 2018/1724 (Data Governance Act). 2022. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32022R0868&qid=1660831508274 (accessed on 18 August 2022).
- Proposal for a Regulation of the European Parliament and of the Council on Contestable and Fair Markets in the Digital Sector (Digital Markets Act). Available online: https://eur-lex.europa.eu/legal-content/en/TXT/?uri=COM%3A2020%3A842%3AFIN (accessed on 18 August 2022).
- Proposal for a Regulation of the European Parliament and of the Council laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act, AI Act) and Amending Certain Union Legislative Acts, COM/2021/206 Final. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A52021PC0206 (accessed on 18 August 2022).
- Proposal for a Regulation of the European Parliament and of the Council on the European Health Data Space, COM/2022/197 Final. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A52022PC0197 (accessed on 18 August 2022).
- Kristensen, F.B.; Husereau, D.; Huić, M.; Drummond, M.; Berger, M.L.; Bond, K.; Augustovski, F.; Booth, A.; Bridges, J.F.P.; Grimshaw, J.; et al. Identifying the Need for Good Practices in Health Technology Assessment: Summary of the ISPOR HTA Council Working Group Report on Good Practices in HTA. Value Health 2019, 22, 13–20. [Google Scholar] [CrossRef] [PubMed]
- Kosvyra, A.; Filos, D.; Fotopoulos, D.; Olga, T.; Chouvarda, I. Towards Data Integration for AI in Cancer Research. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Mexico City, Mexico, 1–5 November 2021; IEEE: New York, NY, USA, 2021. [Google Scholar]
- ITK-Snap Version 3.8.0. Available online: http://www.itksnap.org/pmwiki/pmwiki.php?n=Downloads.SNAP3 (accessed on 24 August 2022).
- Kosvyra, A.; Filos, D.; Fotopoulos, D.; Olga, T.; Chouvarda, I. Data Quality Check in Cancer Imaging Research: Deploying and Evaluating the DIQCT Tool. In Proceedings of the 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, UK, 11–15 July 2022. [Google Scholar]
- DICOM Security and System Management Profiles. Available online: https://dicom.nema.org/medical/dicom/current/output/chtml/part15/chapter_e.html (accessed on 24 August 2022).
- MIRC CTP-MircWiki. Available online: https://mircwiki.rsna.org/index.php?title=MIRC_CTP (accessed on 24 August 2022).
- Graham, R.N.; Perriss, R.W.; Scarsbrook, A.F. DICOM demystified: A review of digital file formats and their use in radiological practice. Clin. Radiol. 2005, 60, 1133–1140. [Google Scholar] [CrossRef] [PubMed]
- DICOM Standard PS 3.15 Digital Imaging and Communications in Medicine (DICOM), Part 15: Security and System Management Profiles. Available online: http://dicom.nema.org/dicom/2013/output/chtml/part15/PS3.15.html (accessed on 24 August 2022).
- McDonald, C.J.; Huff, S.M.; Suico, J.G.; Hill, G.; Leavelle, D.; Aller, R.; Forrey, A.; Mercer, K.; DeMoor, G.; Hook, J.; et al. LOINC, a universal standard for identifying laboratory observations: A 5-year update. Clin. Chem. 2003, 49, 624–633. [Google Scholar] [CrossRef] [PubMed]
- SNOMED. Available online: https://www.snomed.org/ (accessed on 24 August 2022).
- Esthesis Platform. Available online: https://www.eurodyn.com/rnd-product/esthesis/ (accessed on 24 August 2022).
- OMOP Common Data Model. Available online: https://www.ohdsi.org/data-standardization/the-common-data-model/ (accessed on 24 August 2022).
- The CTP DICOM Anonymizer. Available online: https://mircwiki.rsna.org/index.php?title=The_CTP_DICOM_Anonymizer (accessed on 24 August 2022).
- Yushkevich, P.A.; Piven, J.; Hazlett, H.C.; Smith, R.G.; Ho, S.; Gee, J.C.; Gerig, G. User-guided 3D active contour segmentation of anatomical structures: Significantly improved efficiency and reliability. Neuroimage 2006, 31, 1116–1128. [Google Scholar] [CrossRef]
- Schünemann, H.J.; Lerda, D.; Quinn, C.; Follmann, M.; Alonso-Coello, P.; Rossi, P.G.; Lebeau, A.; Nyström, L.; Broeders, M.; Ioannidou-Mouzaka, L.; et al. Breast Cancer Screening and Diagnosis: A Synopsis of the European Breast Guidelines. Ann. Intern. Med. 2019, 172, 46–56. [Google Scholar] [CrossRef]
- Runowicz, C.D.; Leach, C.R.; Henry, N.L.; Henry, K.S.; Mackey, H.T.; Cowens-Alvarado, R.L.; Ganz, P.A. American cancer society/American society of clinical oncology breast cancer survivorship care guideline. CA A Cancer J. Clin. 2016, 66, 43–73. [Google Scholar] [CrossRef]
- Lazic, I.; Jakovljevic, N.; Boban, J.; Nosek, I.; Loncar-Turukalo, T. Information extraction from clinical records: An example for breast cancer. In Proceedings of the 21st IEEE Mediterranean Electrotechnical Conference, Palermo, Italy, 14–16 June 2022. [Google Scholar]
- Symvoulidis, C.; Marinos, G.; Kiourtis, A.; Mavrogiorgou, A.; Kyriazis, D. HealthFetch: An Influence-Based, Context-Aware Prefetch Scheme in Citizen-Centered Health Storage Clouds. Future Internet 2022, 14, 112. [Google Scholar] [CrossRef]
- Symvoulidis, C.; Kiourtis, A.; Mavrogiorgou, A.; Kyriazis, D. Healthcare Provision in the Cloud: An EHR Object Store-based Cloud Used for Emergency. Healthinf 2021, 1, 435–442. [Google Scholar]
- NextCloud. Available online: https://nextcloud.com/ (accessed on 24 August 2022).
- Intel Software Guard Extensions. Available online: https://www.intel.com/content/www/us/en/developer/tools/software-guard-extensions/overview.html (accessed on 24 August 2022).
- McMahan, H.B.; Moore, E.; Ramage, D.; Arcas, B.A. Federated learning of deep networks using model averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Linardos, A.; Kushibar, K.; Walsh, S.; Gkontra, P.; Lekadir, K. Federated Learning for Multi-Center Imaging Diagnostics: A Study in Cardiovascular Disease. arXiv 2021, arXiv:2107.03901. [Google Scholar] [CrossRef]
- Izmailov, P.; Podoprikhin, D.; Garipov, T.; Vetrov, D.; Wilson, A.G. Averaging weights leads to wider optima and better generalization. arXiv 2018, arXiv:1803.05407. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23 June–28 June 2014. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, K.; Shen, Y.; Wu, N.; Chłędowski, J.; Fernandez-Granda, C.; Geras, K.J. Weakly-supervised high-resolution segmentation of mammography images for breast cancer diagnosis. Proc. Mach. Learn. Res. 2021, 143, 268. [Google Scholar] [PubMed]
- Shen, Y.; Wu, N.; Phang, J.; Park, J.; Liu, K.; Tyagi, S.; Heacock, L.; Kim, S.G.; Moy, L.; Cho, K.; et al. An interpretable classifier for high-resolution breast cancer screening images utilizing weakly supervised localization. Med. Image Anal. 2021, 68, 101908. [Google Scholar] [CrossRef] [PubMed]
- Wei, J.; Chan, H.-P.; Wu, Y.-T.; Zhou, C.; Helvie, M.A.; Tsodikov, A.; Hadjiiski, L.M.; Sahiner, B. Association of computerized mammographic parenchymal pat- tern measure with breast cancer risk: A pilot case-control study. Radiology 2011, 260, 42–49. [Google Scholar] [CrossRef] [PubMed]
- Wu, N.; Phang, J.; Park, J.; Shen, Y.; Kim, S.G.; Heacock, L.; Moy, L.; Cho, K.; Geras, K.J. The NYU Breast Cancer Screening Dataset V1.0; New York University: New York, NY, USA, 2019. [Google Scholar]
- Shen, Y.; Wu, N.; Phang, J.; Park, J.; Kim, G.; Moy, L.; Cho, K.; Geras, K.J. Globally-aware multiple instance classifier for breast cancer screening. In International Workshop on Machine Learning in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2019; pp. 18–26. [Google Scholar]
- Diba, A.; Sharma, V.; Pazandeh, A.; Pirsiavash, H.; Van Gool, L. Weakly supervised cascaded convolutional networks. arXiv 2017, arXiv:1611.08258. [Google Scholar]
- Valanarasu, J.M.J.; Oza, P.; Hacihaliloglu, I.; Patel, V.M. Medical transformer: Gated axial-attention for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 36–46. [Google Scholar]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef]
- Amendoeira, I.; Perry, N.; Broeders, M.; de Wolf, C.; Törnberg, S.; Holland, R.; von Karsa, L. European Guidelines for Quality Assurance in Breast Cancer Screening and Diagnosis; European Commission: Brussels, Belgium, 2013. [Google Scholar]
- Williams, M.B.; Raghunathan, P.; More, M.J.; Seibert, J.A.; Kwan, A.; Lo, J.; Samei, E.; Ranger, N.T.; Fajardo, L.L.; McGruder, A.; et al. Optimization of exposure parameters in full field digital mammography. Med. Phys. 2008, 35, 2414–2423. [Google Scholar] [CrossRef]
- Audelan, B.; Delingette, H. Unsupervised quality control of segmentations based on a smoothness and intensity probabilistic model. Med. Image Anal. 2020, 68, 101895. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ultrasound | Mammography | MRI | CT Scan | PET/CT Scan | |
|---|---|---|---|---|---|
| Data requirements | Healthy and non-healthy images |
|
| MST: 5 mm | MST: 5 mm |
| Annotation procedure | Bounding box | Contouring | Contouring | Bounding box | Bounding box |
| Labels |
|
|
|
|
|
| Partner | No of Patients | No of Studies | No of Annotated Studies | No of Images |
|---|---|---|---|---|
| AUTH | 25 | 85 | 71 | 36,345 |
| DISBA | 11 | 26 | 19 | 14,886 |
| GOC | 67 | 297 | - | 43,391 |
| HCS | 1950 | 2326 | 1309 | 10,326 |
| UNITOV | 11 | 615 | - | 30,331 |
| UNS | 1392 | 4704 | 666 | 908,580 |
| DP | MG Studies | MG Images | MG Annotated Images | DBT Studies | DBT Images | DBT Annotated Images |
|---|---|---|---|---|---|---|
| AUTH | 41 | 160 | 109 | 0 | 0 | 0 |
| GOC | 49 | 190 | 0 | 4 | 599 | 0 |
| HCS | 1950 | 7282 | 1214 | 3 | 5 | 0 |
| UNS | 4119 | 15,278 | 655 | 1618 | 131,653 | 26 |
| Manufacturer | Bits Allocated | Bits Stored | Image Size | Service–Object Pair Class |
|---|---|---|---|---|
| CARESTREAM Rochester, NY, USA | 16 | 12 | 6000 × 4735 | Computed Radiography Image Storage |
| FUJIFILM corporation Midtown West, Tokyo Midtown Akasaka, Minato, Tokyo, Japan | 16 | 12, 14 | 5928 × 4728, 2370 × 1770, 4740 × 3540, 2964 × 2364 | Breast Tomosynthesis Image Storage, Computed Radiography Image Storage, Digital Mammography X-ray Image Storage—For Presentation |
| HOLOGIC Inc. Marlboough, MA, USA | 16 | 10,12 | 2457 × 1892, 425 × 268, 4096 × 3328, 2457 × 1996, 3328 × 2560, 2457 × 1890 | Secondary Capture Image Storage, Breast Tomosynthesis Image Storage, Digital Mammography X-ray Image Storage—For Presentation |
| IMS GIOTTO S.P.A. Sasso Marconi (BO), Italy | 16 | 14 | 2149 × 1198, 3580 × 2663, 2295 × 1120, 3580 × 2603, 1691 × 896, 3580 × 2717, 3580 × 2597, 1794 × 826, 3580 × 2812, 1817 × 876, 3580 × 2730, 3580 × 2591, 3580 × 2585, 3580 × 2657, 3580 × 2687, 1864 × 998, 3580 × 2669, 2164 × 1374, 3580 × 2675, 2287 × 1231 | Breast Tomosynthesis Image Storage, Digital Mammography X-ray Image Storage—For Presentation |
| IMS S.R.L. | 16 | 14 | 3584 × 2784, 3584 × 2736, 3584 × 2720, 3584 × 2704, 3580 × 2812, 3584 × 2768, 3584 × 2752, 3584 × 2816, 3584 × 2800 | Digital Mammography X-ray Image Storage—For Presentation |
| LORAD, Hologic company Bedford, MA, USA | 16 | 16 | 512 × 512, 1024 × 1024 | Digital Mammography X-ray Image Storage—For Presentation |
| PHILIPS digital mammography Sweden, AB Solna, Stockholms Lan, Sweden | 16 | 16 | 5355 × 4915 | Digital Mammography X-ray Image Storage—For Presentation |
| SIEMENS Munich, Germany | 16 | 12 | 1882 × 1325, 3164 × 2364, 3241 × 2203, 2577 × 1006, 3518 × 2800 | Secondary Capture Image Storage, Digital Mammography X-ray Image Storage—For Presentation |
| SIEMENS Healthineers Erlangen, Germany | 16 | 12, 14 | 2850 × 2394, 3223 × 2842, 3798 × 3328, 3359 × 2776, 2786 × 2027, 4017 × 3328, 4083 × 3328, 4092 × 3328, 3986 × 3328, 2298 × 2118, 3647 × 3328, 3867 × 2195, 3842 × 3328, 4096 × 3328, 3328 × 2560, 2665 × 2394 | Secondary Capture Image Storage |
| Annotation Label | |||||||
|---|---|---|---|---|---|---|---|
| Provider | Suspicious/Indeterminate | Malign | Calcification | Surgical Clip | Axial Lymph Node | Benign | No Findings |
| AUTH | 5 | 28 | 85 | 28 | 15 | 15 | 12 |
| HCS | 160 | 299 | 558 | 50 | 249 | 300 | 7 |
| UNS | 213 | 53 | 87 | 86 | 87 | 52 | 216 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lazic, I.; Agullo, F.; Ausso, S.; Alves, B.; Barelle, C.; Berral, J.L.; Bizopoulos, P.; Bunduc, O.; Chouvarda, I.; Dominguez, D.; et al. The Holistic Perspective of the INCISIVE Project—Artificial Intelligence in Screening Mammography. Appl. Sci. 2022, 12, 8755. https://doi.org/10.3390/app12178755
Lazic I, Agullo F, Ausso S, Alves B, Barelle C, Berral JL, Bizopoulos P, Bunduc O, Chouvarda I, Dominguez D, et al. The Holistic Perspective of the INCISIVE Project—Artificial Intelligence in Screening Mammography. Applied Sciences. 2022; 12(17):8755. https://doi.org/10.3390/app12178755
Chicago/Turabian StyleLazic, Ivan, Ferran Agullo, Susanna Ausso, Bruno Alves, Caroline Barelle, Josep Ll. Berral, Paschalis Bizopoulos, Oana Bunduc, Ioanna Chouvarda, Didier Dominguez, and et al. 2022. "The Holistic Perspective of the INCISIVE Project—Artificial Intelligence in Screening Mammography" Applied Sciences 12, no. 17: 8755. https://doi.org/10.3390/app12178755
APA StyleLazic, I., Agullo, F., Ausso, S., Alves, B., Barelle, C., Berral, J. L., Bizopoulos, P., Bunduc, O., Chouvarda, I., Dominguez, D., Filos, D., Gutierrez-Torre, A., Hesso, I., Jakovljević, N., Kayyali, R., Kogut-Czarkowska, M., Kosvyra, A., Lalas, A., Lavdaniti, M., ... Charalambous, A. (2022). The Holistic Perspective of the INCISIVE Project—Artificial Intelligence in Screening Mammography. Applied Sciences, 12(17), 8755. https://doi.org/10.3390/app12178755