
An End-to-End Mutually Interactive Emotion–Cause Pair Extractor via Soft Sharing



Abstract
:1. Introduction
- Mutual transfer of information in emotion and cause extraction. Soft-sharing is applied between emotion and cause encoders. We add the soft-sharing loss to the total loss function in a multi-task learning style to involve mutual interaction between the two auxiliary tasks. Therefore, the two encoders can learn from each other rather than unidirectional learning in previous methods.
- Efficient pair extractor with weighted representation. We utilize the weighted representation of emotion and cause to filter the clauses which tend to be meaningless. Therefore, only the useful emotion-weighted and cause-weighted clause representations can be reserved to improve the efficiency of emotion–cause paring.
- Novel end-to-end ECPE model. We propose a novel end-to-end method that uses two LSTMs to automatically transfer information between the emotion encoder and cause encoder via soft sharing. Since the end-to-end model considers single emotion and cause extraction along with emotion–cause pairing at the same time, it greatly avoids the cumulative errors in separated steps and significantly improves the performance.
2. Related Work
3. Materials and Methods
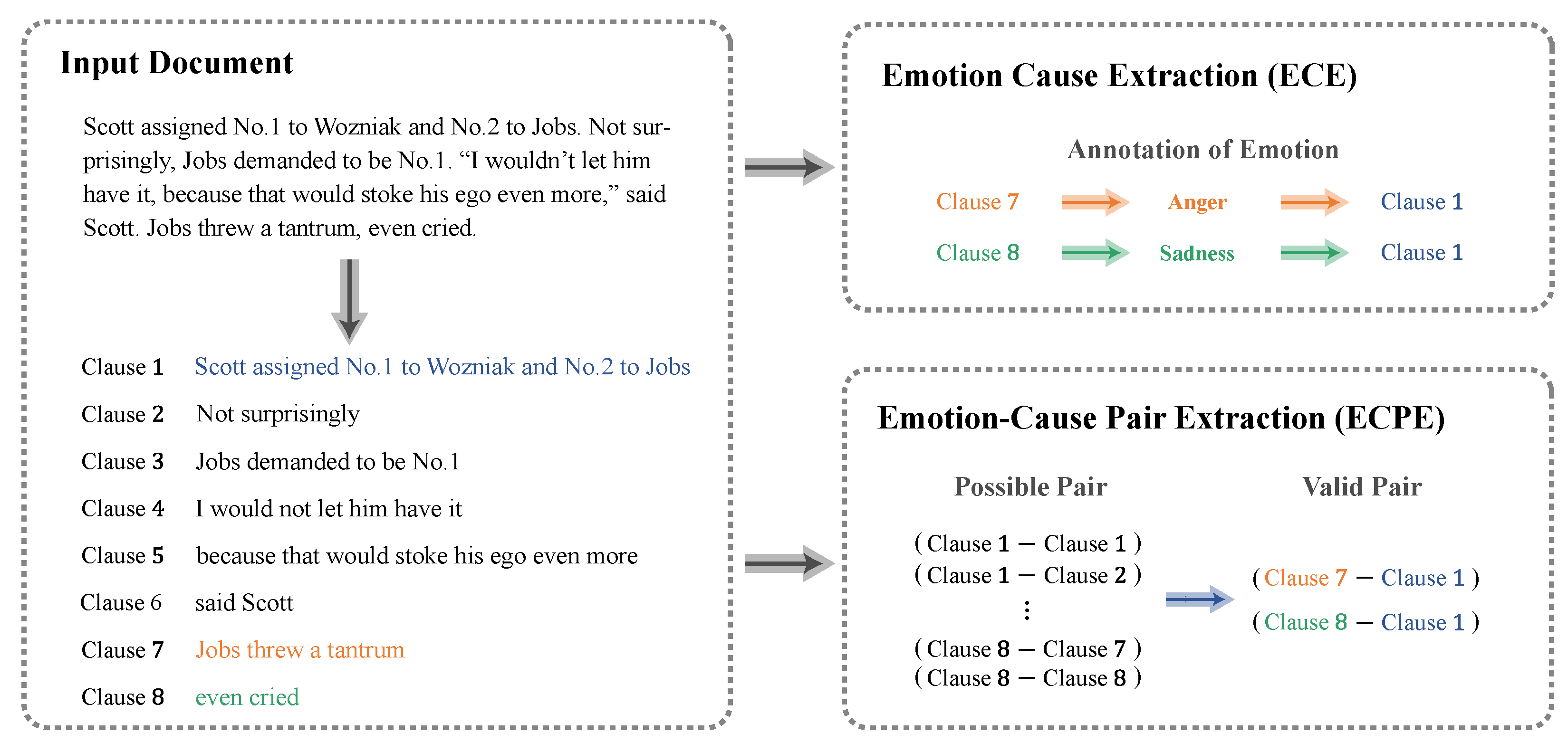
3.1. Task Formalization
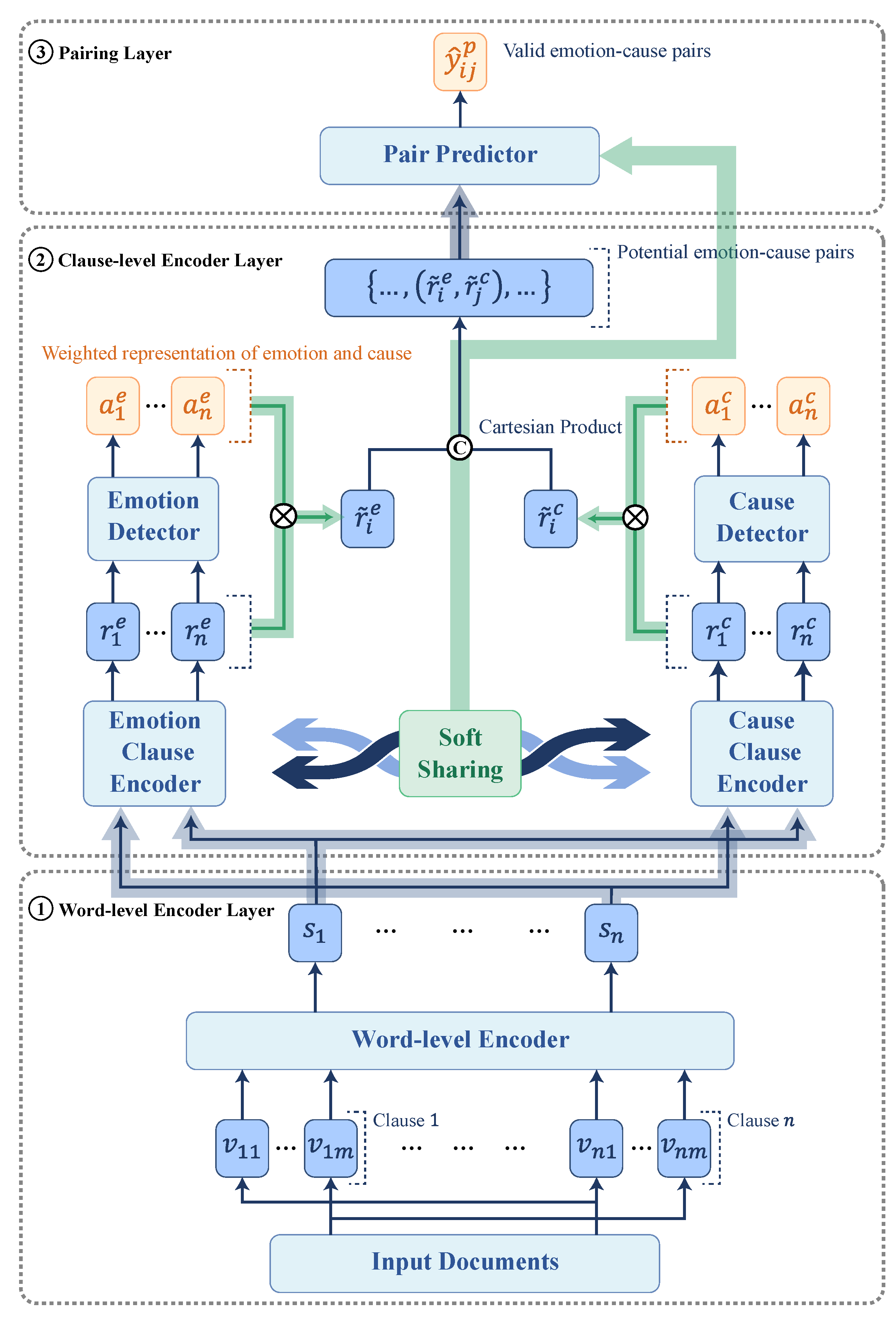
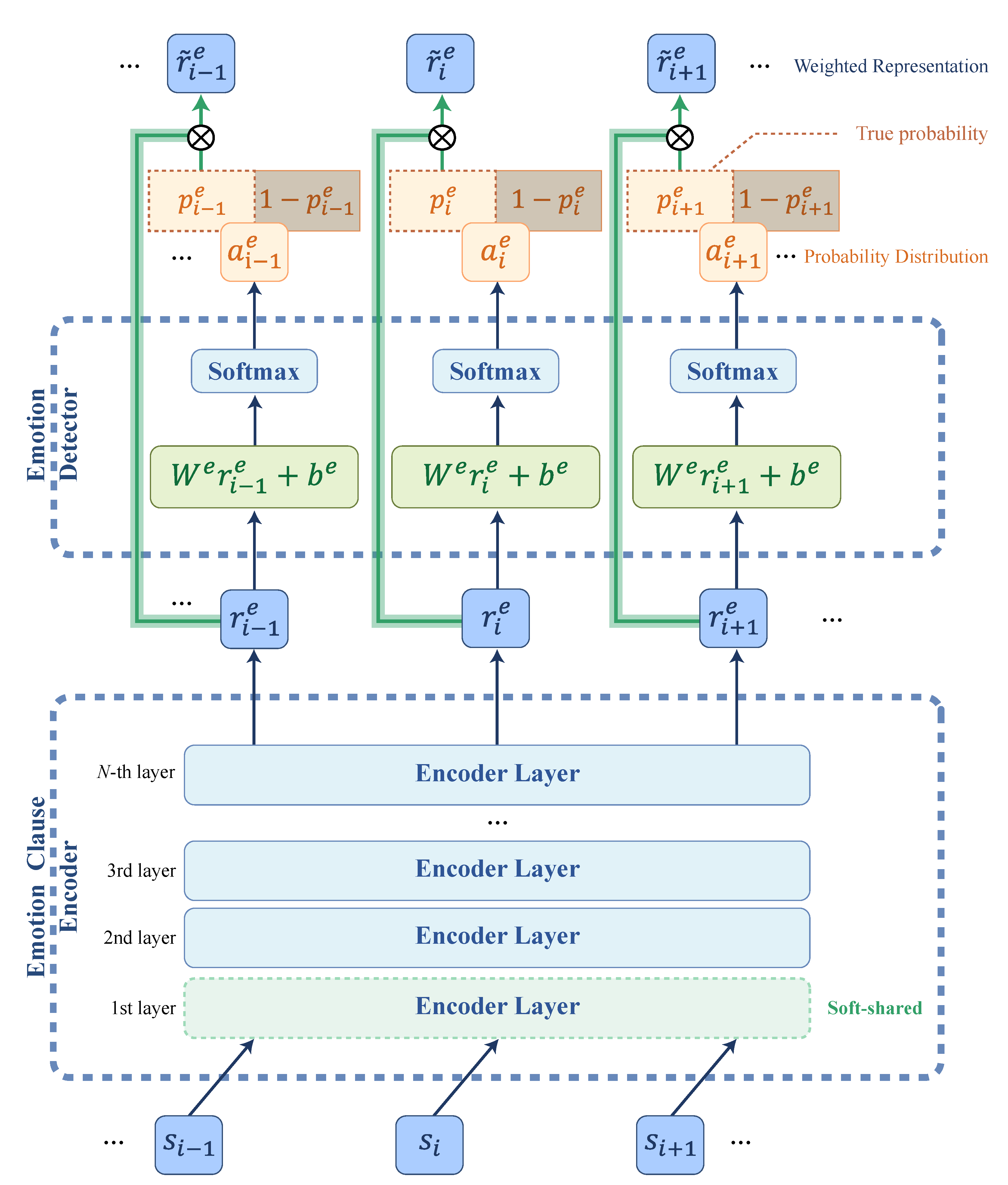
3.2. Architecture
3.3. Learning with Mutual Transfer of Information
3.4. Evaluation Metrics
4. Results
4.1. Dataset
- Emotion–cause pairs (the set of emotion clauses and their corresponding cause clauses);
- Emotion category of each clause;
- Keywords in the emotion clauses.
4.2. Baselines and Settings
- ECPE [12]: As a second step, a Cartesian product is applied to the emotion clauses and causal relationships extracted from the multi-task learning network in the first step in order to compose them into pairs, and a filtering model is trained so that the pair containing the causal relationship is the final output. Bi-LSTM and attention [47,48] is the word-level encoder used in the first extraction step, and Bi-LSTM [48] is used in the emotion and cause extractors as well. Logic regression is used to filter the pairs in the second step.
- ECPE-2D(BERT) [14]: The interactions in the emotion–cause pairs were modeled by a 2D transformer, which in turn represented the pairs in a two-dimensional form, i.e., a square matrix. Two-dimensional representations are integrated with interactions and predictions using a joint framework. The encoding part uses a word-level Bi-LSTM and an attention mechanism [47], while the clause-level emotion extractor and cause extractor leverage BERT [49] to enhance the overall effectiveness of the model.
- ECPE-MLL(ISML-6) [15]: Multi-label learning (MLL) was introduced in the ECPE task. To obtain a representation of the clause, the emotion clause and cause clause are specified as the center of the multi-label learning window. An iterative synchronous multi-task learning (ISML) model with six iterations is used for clause encoding, while the same Bi-LSTM [47] is used for word-level embedding.
- [13]: Using Bi-LSTM plus attention [47], the clause-level representation is obtained based on the word-level one. The clause level representation uses another Bi-LSTM network to further extract contextual information and is used to determine whether the clause is an emotion one or a cause one. Finally, the predicted pair is obtained by a fully connected neural network.
4.3. Overall Performance
5. Ablation Study
5.1. Clause-Level Encoder
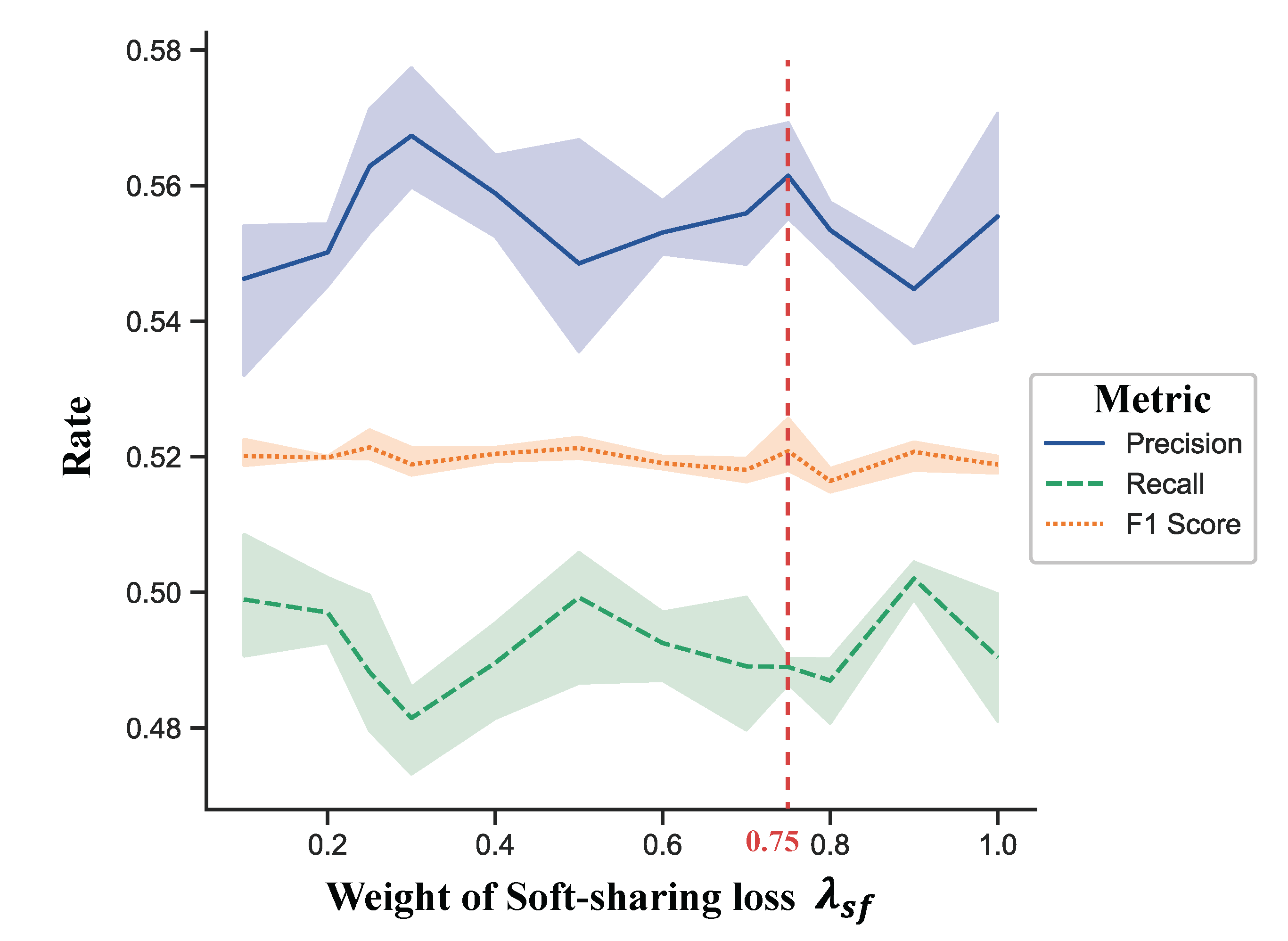
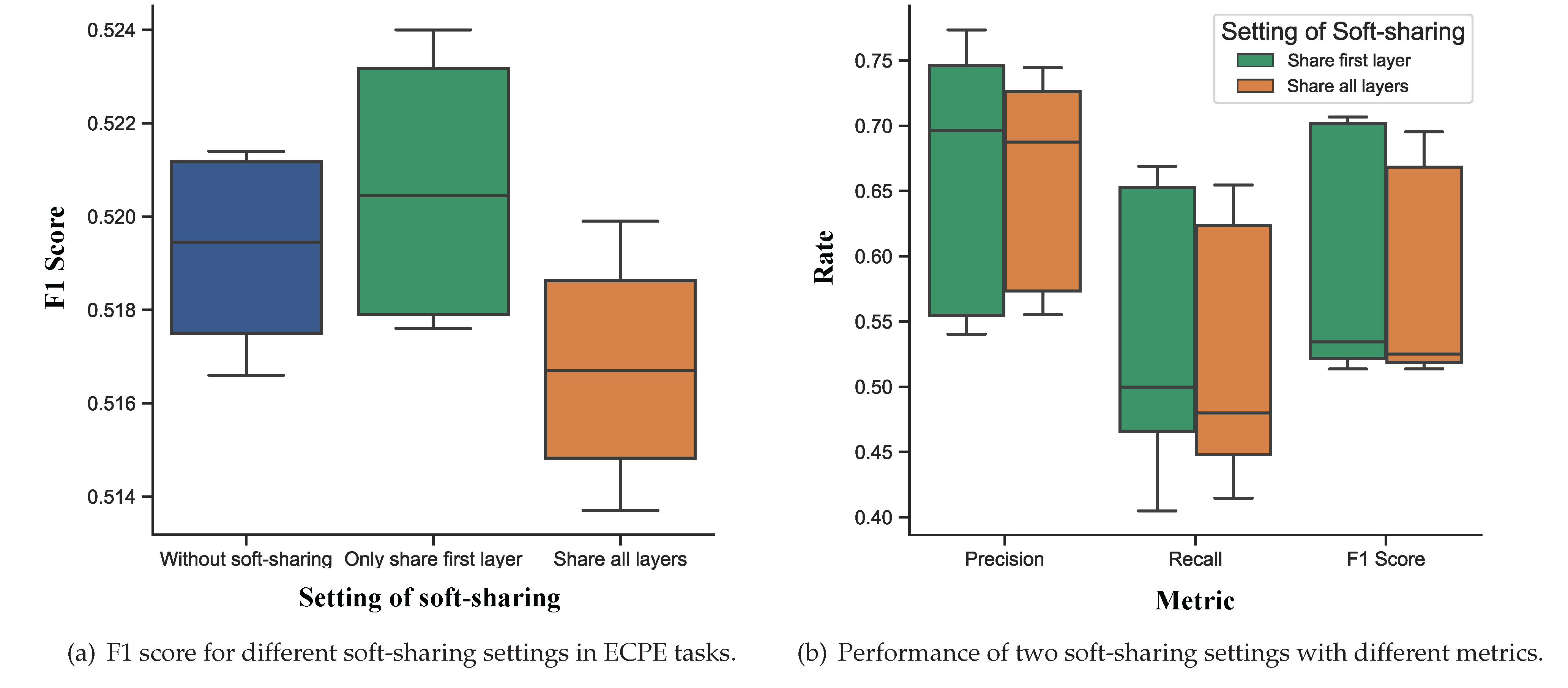
5.2. Mutual Transfer of Information
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, S.Y.M.; Chen, Y.; Huang, C.R. A text-driven rule-based system for emotion cause detection. In Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, Los Angeles, CA, USA, 5 June 2010; pp. 45–53. [Google Scholar]
- Russo, I.; Caselli, T.; Rubino, F.; Boldrini, E.; Martínez-Barco, P. EMOCause: An Easy-adaptable Approach to Extract Emotion Cause Contexts. In Proceedings of the 2nd Workshop on Computational Approaches to Subjectivity and Sentiment Analysis (WASSA 2.011), Portland, OR, USA, 24 June 2011; pp. 153–160. [Google Scholar]
- Gui, L.; Xu, R.; Wu, D.; Lu, Q.; Zhou, Y. Event-driven emotion cause extraction with corpus construction. In Social Media Content Analysis: Natural Language Processing and Beyond; World Scientific: Singapore, 2018; pp. 145–160. [Google Scholar]
- Gui, L.; Xu, R.; Lu, Q.; Wu, D.; Zhou, Y. Emotion cause extraction, a challenging task with corpus construction. In Proceedings of the Chinese National Conference on Social Media Processing, Beijing, China, 1–2 November 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 98–109. [Google Scholar]
- Chen, Y.; Lee, S.Y.M.; Li, S.; Huang, C.R. Emotion cause detection with linguistic constructions. In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), Beijing, China, 23–27 August 2010; pp. 179–187. [Google Scholar]
- Gao, K.; Xu, H.; Wang, J. Emotion cause detection for chinese micro-blogs based on ecocc model. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Ho Chi Minh City, Vietnam, 19–22 May 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 3–14. [Google Scholar]
- Li, W.; Xu, H. Text-based emotion classification using emotion cause extraction. Expert Syst. Appl. 2014, 41, 1742–1749. [Google Scholar] [CrossRef]
- Li, X.; Song, K.; Feng, S.; Wang, D.; Zhang, Y. A Co-Attention Neural Network Model for Emotion Cause Analysis with Emotional Context Awareness. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 4752–4757. [Google Scholar]
- Xu, B.; Lin, H.; Lin, Y.; Diao, Y.; Yang, L.; Xu, K. Extracting emotion causes using learning to rank methods from an information retrieval perspective. IEEE Access 2019, 7, 15573–15583. [Google Scholar] [CrossRef]
- Yu, X.; Rong, W.; Zhang, Z.; Ouyang, Y.; Xiong, Z. Multiple Level Hierarchical Network-Based Clause Selection for Emotion Cause Extraction. IEEE Access 2019, 7, 9071–9079. [Google Scholar] [CrossRef]
- Neviarouskaya, A.; Aono, M. Extracting causes of emotions from text. In Proceedings of the Sixth International Joint Conference on Natural Language Processing, Nagoya, Japan, 14–18 October 2013; pp. 932–936. [Google Scholar]
- Xia, R.; Ding, Z. Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1003–1012. [Google Scholar]
- Singh, A.; Hingane, S.; Wani, S.; Modi, A. An End-to-End Network for Emotion-Cause Pair Extraction. In Proceedings of the Eleventh Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Online, 19 April 2021; pp. 84–91. [Google Scholar]
- Ding, Z.; Xia, R.; Yu, J. ECPE-2D: Emotion-cause pair extraction based on joint two-dimensional representation, interaction and prediction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3161–3170. [Google Scholar]
- Ding, Z.; Xia, R.; Yu, J. End-to-end emotion-cause pair extraction based on sliding window multi-label learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 3574–3583. [Google Scholar]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Ben-David, S.; Schuller, R. Exploiting task relatedness for multiple task learning. In Learning Theory and Kernel Machines; Springer: Berlin/Heidelberg, Germany, 2003; pp. 567–580. [Google Scholar]
- Evgeniou, T.; Micchelli, C.A.; Pontil, M.; Shawe-Taylor, J. Learning multiple tasks with kernel methods. J. Mach. Learn. Res. 2005, 6, 615–637. [Google Scholar]
- Argyriou, A.; Evgeniou, T.; Pontil, M. Multi-task feature learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; Volume 19. [Google Scholar]
- Kumar, A.; Daume, H., III. Learning task grouping and overlap in multi-task learning. arXiv 2012, arXiv:1206.6417. [Google Scholar]
- Luong, M.T.; Le, Q.V.; Sutskever, I.; Vinyals, O.; Kaiser, L. Multi-task sequence to sequence learning. arXiv 2015, arXiv:1511.06114. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-stitch networks for multi-task learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3994–4003. [Google Scholar]
- Hashimoto, K.; Xiong, C.; Tsuruoka, Y.; Socher, R. A Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 1923–1933. [Google Scholar]
- Pasunuru, R.; Bansal, M. Multi-Task Video Captioning with Video and Entailment Generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 1273–1283. [Google Scholar] [CrossRef]
- Tan, X.; Ma, T.; Su, T. Fast and Privacy-Preserving Federated Joint Estimator of Multi-sUGMs. IEEE Access 2021, 9, 104079–104092. [Google Scholar] [CrossRef]
- Xu, H.; Wang, M.; Wang, B. A Difference Standardization Method for Mutual Transfer Learning. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; Volume 162, pp. 24683–24697. [Google Scholar]
- Zhang, J.; Yan, K.; Mo, Y. Multi-Task Learning for Sentiment Analysis with Hard-Sharing and Task Recognition Mechanisms. Information 2021, 12, 207. [Google Scholar] [CrossRef]
- Fan, C.; Yuan, C.; Gui, L.; Zhang, Y.; Xu, R. Multi-task sequence tagging for emotion-cause pair extraction via tag distribution refinement. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 2339–2350. [Google Scholar] [CrossRef]
- Guo, H.; Pasunuru, R.; Bansal, M. Soft Layer-Specific Multi-Task Summarization with Entailment and Question Generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 687–697. [Google Scholar]
- Gao, Q.; Hu, J.; Xu, R.; Gui, L.; He, Y.; Wong, K.F.; Lu, Q. Overview of NTCIR-13 ECA Task. In Proceedings of the NTCIR-13 Conference, Tokyo, Japan, 5–8 December 2017. [Google Scholar]
- Gao, K.; Xu, H.; Wang, J. A rule-based approach to emotion cause detection for Chinese micro-blogs. Expert Syst. Appl. 2015, 42, 4517–4528. [Google Scholar] [CrossRef]
- Yada, S.; Ikeda, K.; Hoashi, K.; Kageura, K. A bootstrap method for automatic rule acquisition on emotion cause extraction. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 414–421. [Google Scholar]
- Ghazi, D.; Inkpen, D.; Szpakowicz, S. Detecting emotion stimuli in emotion-bearing sentences. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Cairo, Egypt, 14–20 April 2015; pp. 152–165. [Google Scholar]
- Cheng, X.; Chen, Y.; Cheng, B.; Li, S.; Zhou, G. An emotion cause corpus for chinese microblogs with multiple-user structures. In ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP); Association for Computing Machinery: New York, NY, USA, 2017; Volume 17, pp. 1–19. [Google Scholar]
- Serban, I.V.; Sordoni, A.; Lowe, R.; Charlin, L.; Pineau, J.; Courville, A.; Bengio, Y. A hierarchical latent variable encoder-decoder model for generating dialogues. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 3295–3301. [Google Scholar]
- Tang, H.; Ji, D.; Zhou, Q. Joint multi-level attentional model for emotion detection and emotion-cause pair extraction. Neurocomputing 2020, 409, 329–340. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Fan, W.; Zhu, Y.; Wei, Z.; Yang, T.; Ip, W.; Zhang, Y. Order-guided deep neural network for emotion-cause pair prediction. Appl. Soft Comput. 2021, 112, 107818. [Google Scholar] [CrossRef]
- Jia, X.; Chen, X.; Wan, Q.; Liu, J. A Novel Interactive Recurrent Attention Network for Emotion-Cause Pair Extraction. In Proceedings of the 2020 3rd International Conference on Algorithms, Computing and Artificial Intelligence, Sanya, China, 24–26 December 2020; pp. 1–9. [Google Scholar]
- Chen, F.; Shi, Z.; Yang, Z.; Huang, Y. Recurrent synchronization network for emotion-cause pair extraction. Knowl.-Based Syst. 2022, 238, 107965. [Google Scholar] [CrossRef]
- Yu, J.; Liu, W.; He, Y.; Zhang, C. A mutually auxiliary multitask model with self-distillation for emotion-cause pair extraction. IEEE Access 2021, 9, 26811–26821. [Google Scholar] [CrossRef]
- Li, C.; Hu, J.; Li, T.; Du, S.; Teng, F. An effective multi-task learning model for end-to-end emotion-cause pair extraction. Appl. Intell. 2022, 1–11. [Google Scholar] [CrossRef]
- Fan, C.; Yuan, C.; Du, J.; Gui, L.; Yang, M.; Xu, R. Transition-based directed graph construction for emotion-cause pair extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3707–3717. [Google Scholar]
- Wei, P.; Zhao, J.; Mao, W. Effective inter-clause modeling for end-to-end emotion-cause pair extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3171–3181. [Google Scholar]
- Yang, X.; Yang, Y. Emotion-Type-Based Global Attention Neural Network for Emotion-Cause Pair Extraction. In Proceedings of the International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery, Guiyang, China, 24–26 July 2021; pp. 546–557. [Google Scholar]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Graves, A.; Mohamed, A.-r.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, USA, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-Attention with Relative Position Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 464–468. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 328–339. [Google Scholar]
- Belinkov, Y.; Durrani, N.; Dalvi, F.; Sajjad, H.; Glass, J.R. What do Neural Machine Translation Models Learn about Morphology? In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 861–872. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the ICLR (Poster), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # Document | # Clause () | # Emotion-Cause Pair () | # Annotated Emotion Type |
|---|---|---|---|
| 2843 | 21,802 | 3272 | 6 |
| Annotated Emotion | # Corresponding Emotion Clause |
|---|---|
| happiness | 741 |
| surprise | 388 |
| sadness | 638 |
| fear | 622 |
| anger | 269 |
| disgust | 214 |
| Emotion Extraction | Cause Extraction | Pair Extraction | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | Precision | Recall | F1 Score | Precision | Recall | F1 Score | |
| ECPE [12] | |||||||||
| ECPE-2D(BERT) [14] | |||||||||
| ECPE-MLL(ISML-6) [15] | |||||||||
| [13] | |||||||||
| Emiece-LSTM (Ours) | |||||||||
| Emiece-BERT (Ours) | |||||||||
| Clause-Level Encoder | Emotion Extraction | Cause Extraction | Pair Extraction | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | Precision | Recall | F1 Score | Precision | Recall | F1 Score | |
| stacked Bi-LSTM [47] | |||||||||
| BERT [49] | |||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, B.; Ma, T.; Lu, Z.; Xu, H. An End-to-End Mutually Interactive Emotion–Cause Pair Extractor via Soft Sharing. Appl. Sci. 2022, 12, 8998. https://doi.org/10.3390/app12188998
Wang B, Ma T, Lu Z, Xu H. An End-to-End Mutually Interactive Emotion–Cause Pair Extractor via Soft Sharing. Applied Sciences. 2022; 12(18):8998. https://doi.org/10.3390/app12188998
Chicago/Turabian StyleWang, Beilun, Tianyi Ma, Zhengxuan Lu, and Haoqing Xu. 2022. "An End-to-End Mutually Interactive Emotion–Cause Pair Extractor via Soft Sharing" Applied Sciences 12, no. 18: 8998. https://doi.org/10.3390/app12188998
APA StyleWang, B., Ma, T., Lu, Z., & Xu, H. (2022). An End-to-End Mutually Interactive Emotion–Cause Pair Extractor via Soft Sharing. Applied Sciences, 12(18), 8998. https://doi.org/10.3390/app12188998