

Semi-Direct Point-Line Visual Inertial Odometry for MAVs


Abstract
:1. Introduction
2. Mathematical Formulation
2.1. Notations
2.2. IMU Pre-Integration
2.3. Point Feature Projection
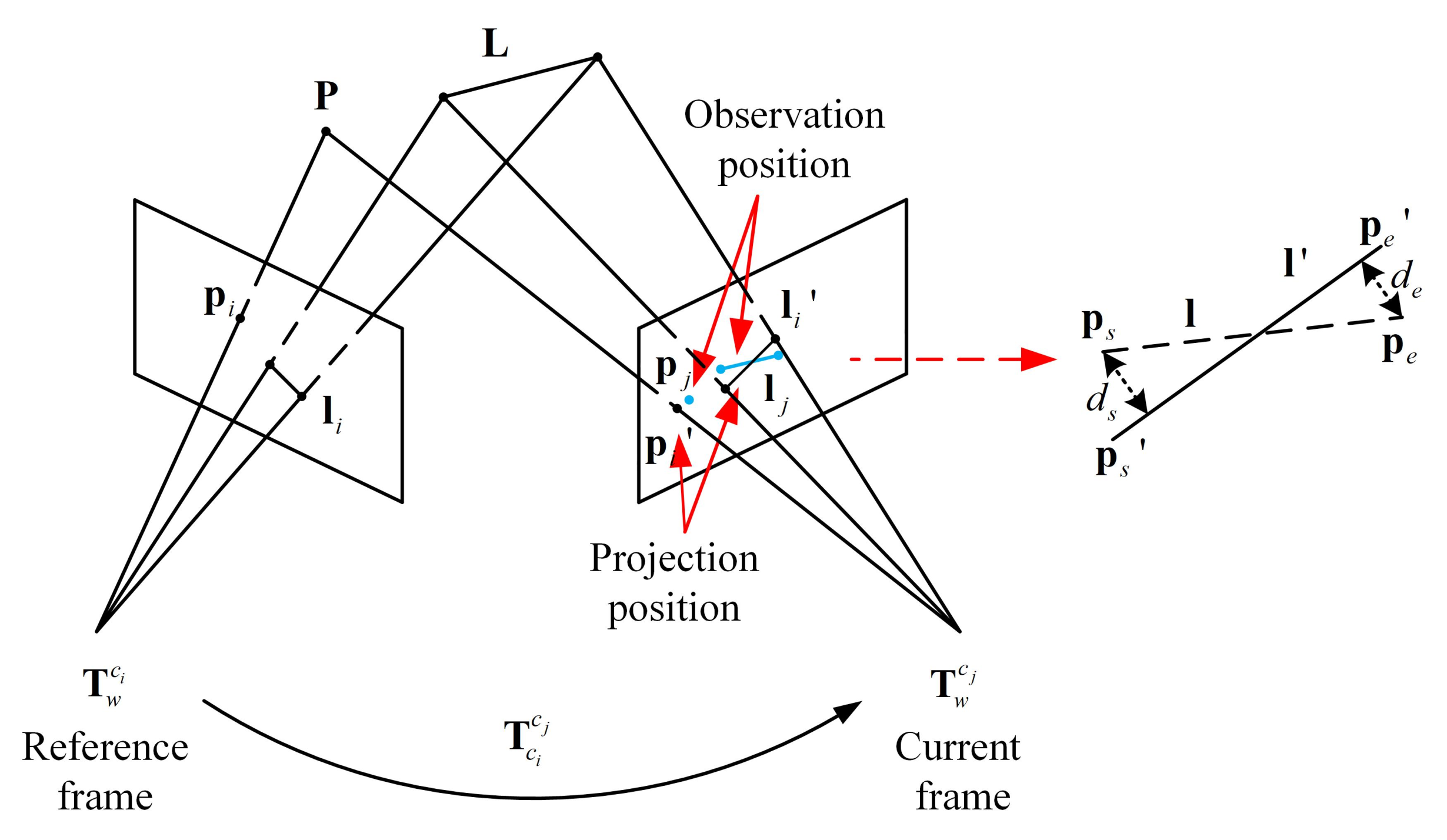
2.4. Line Feature Projection
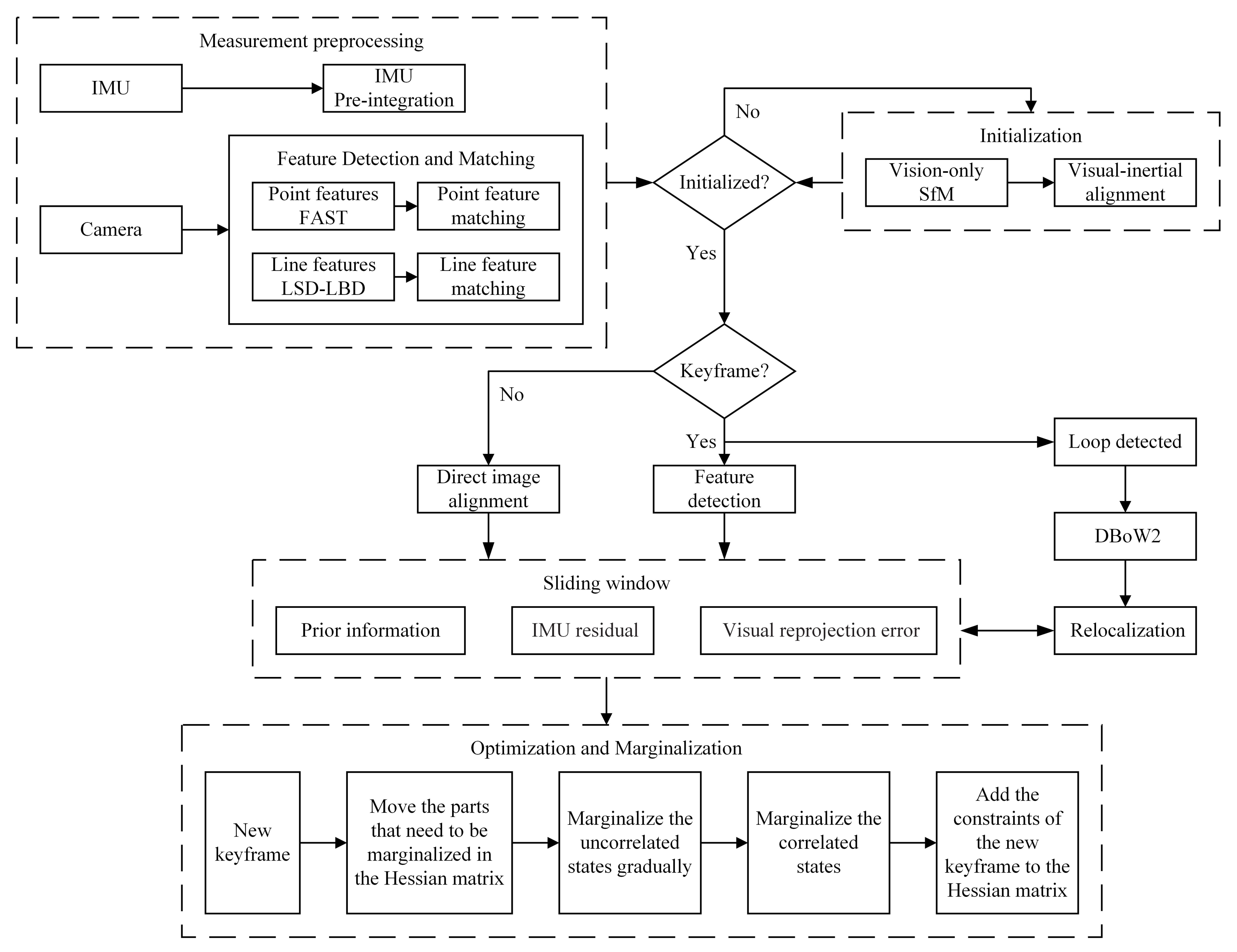
3. Proposed System Implementation
3.1. System Framework
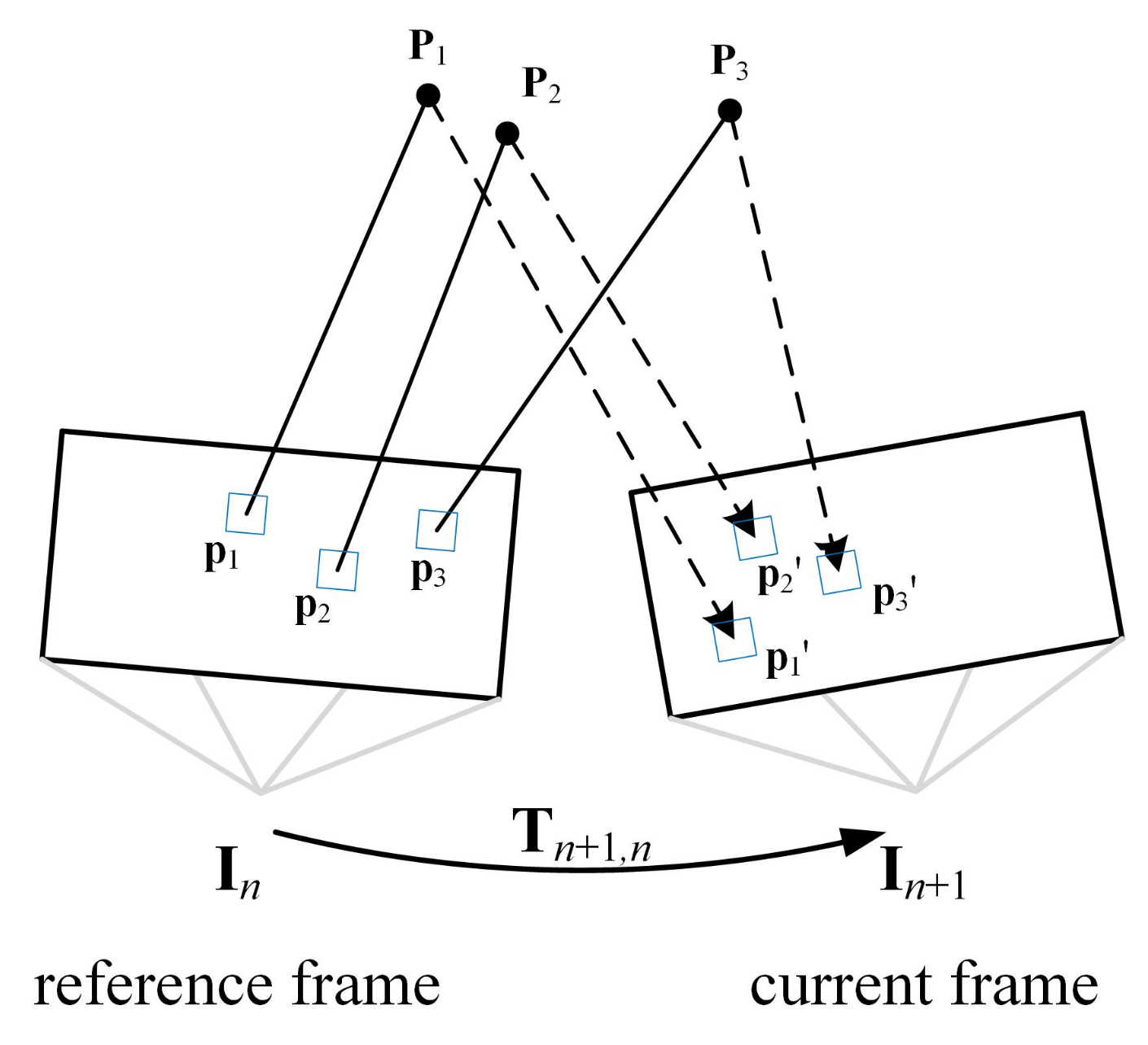
3.2. Front-End Tracking Based on Semi-Direct Methods
3.2.1. Visual-Inertial Initializaiton
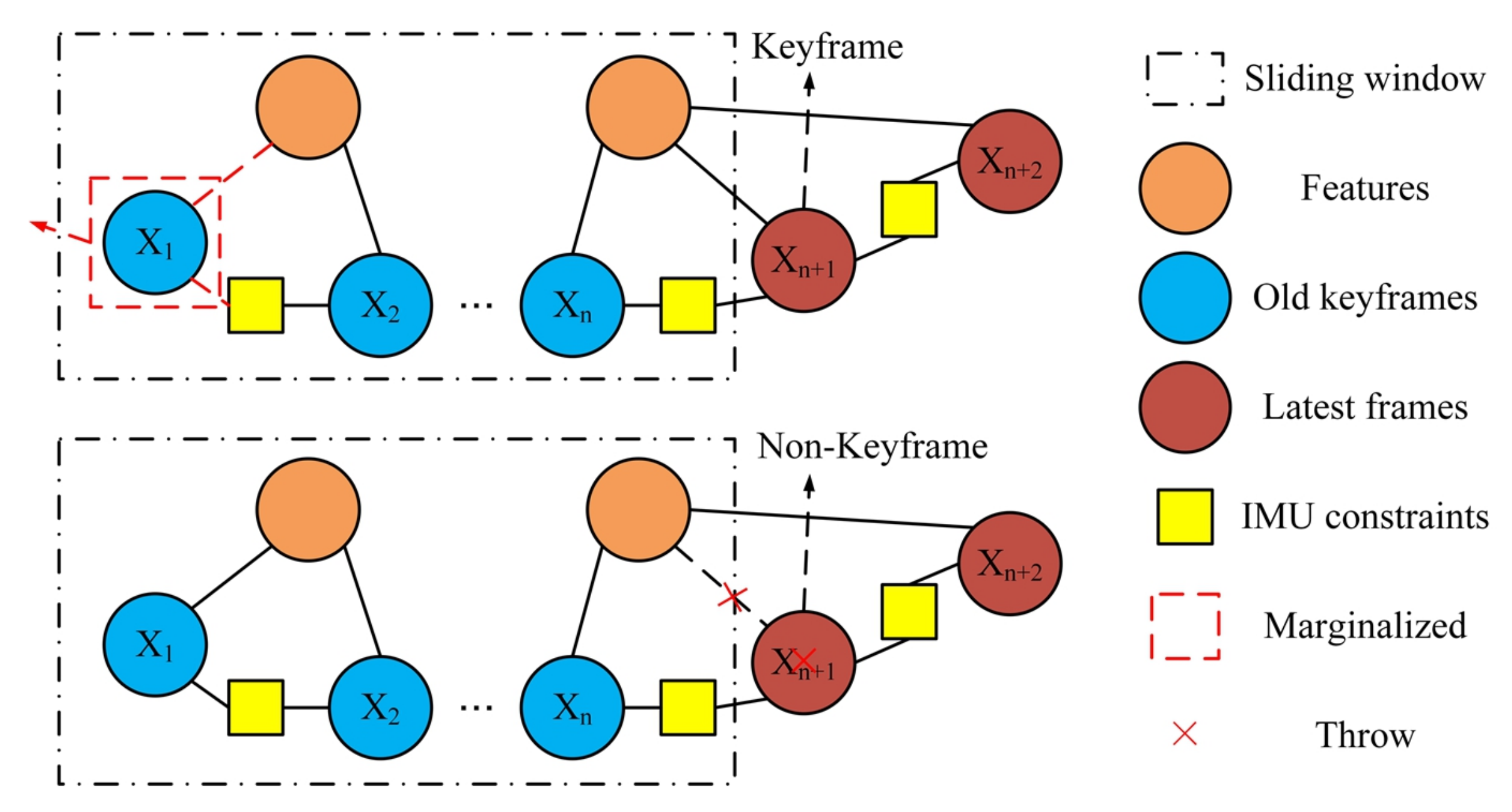
3.2.2. Keyframe Selection
3.2.3. Semi-Direct Method for Tracking
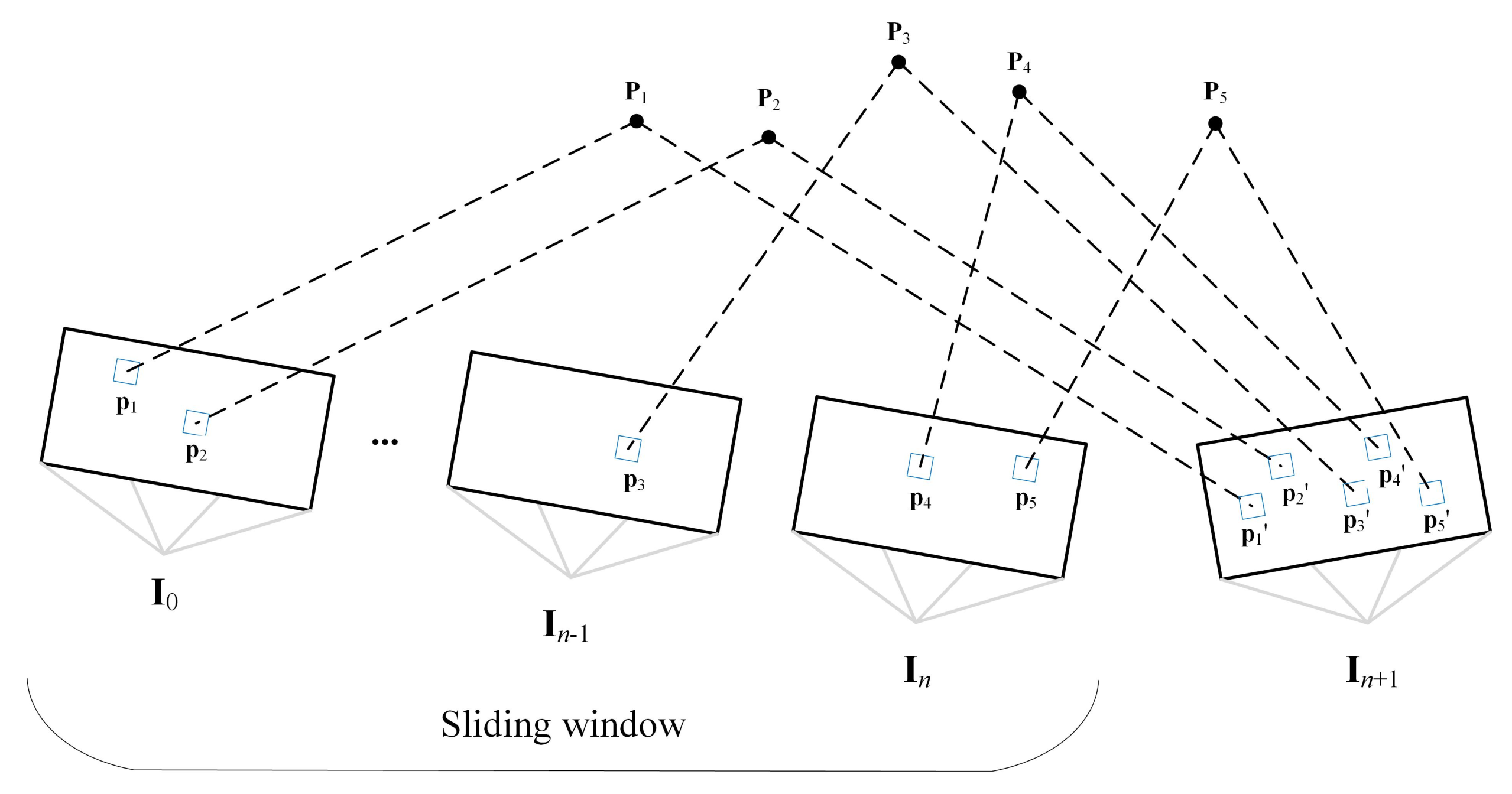
3.3. Back-End Optimization
3.3.1. Sliding Window Formulation
- (a)
- IMU measurement residual
- (b)
- Point feature error term
- (c)
- Line feature error term
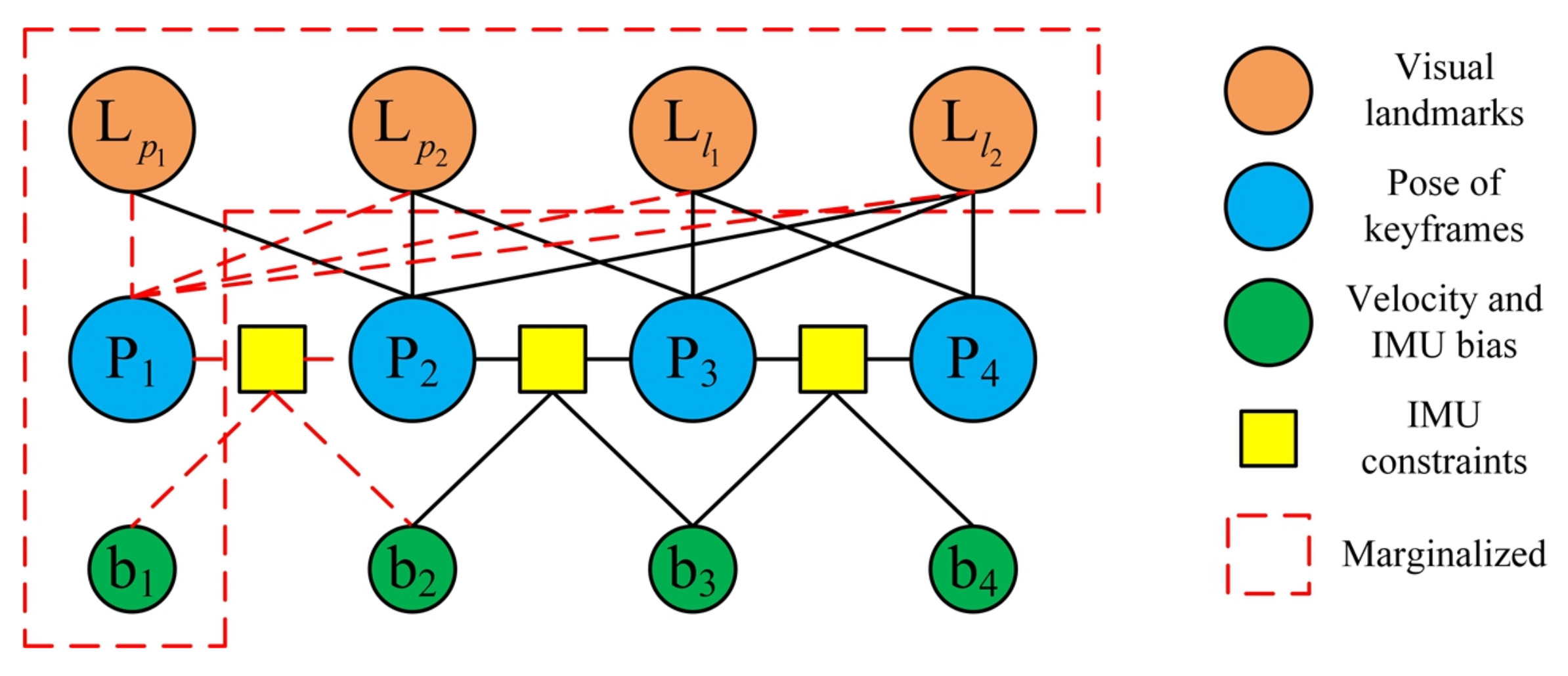
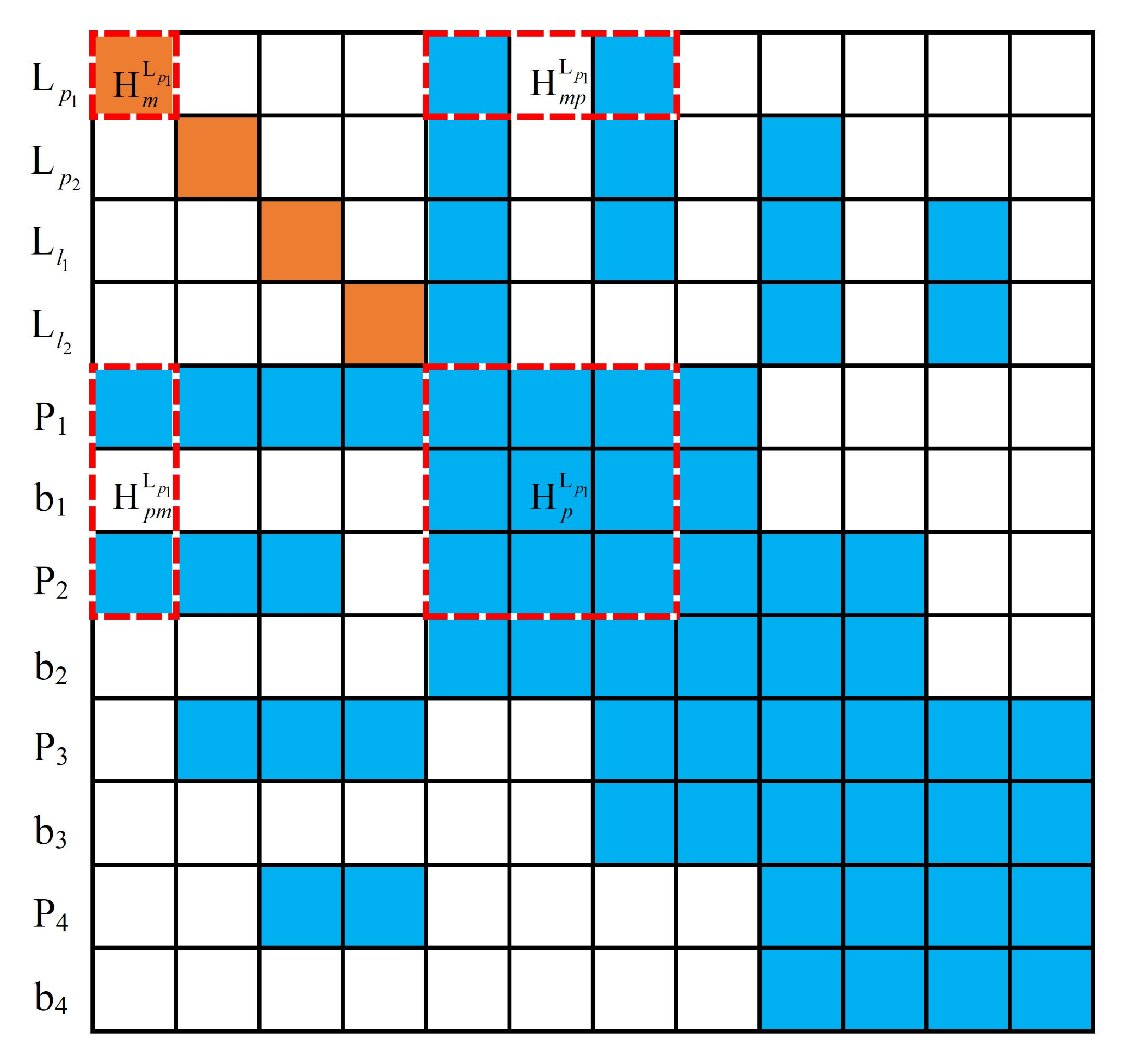
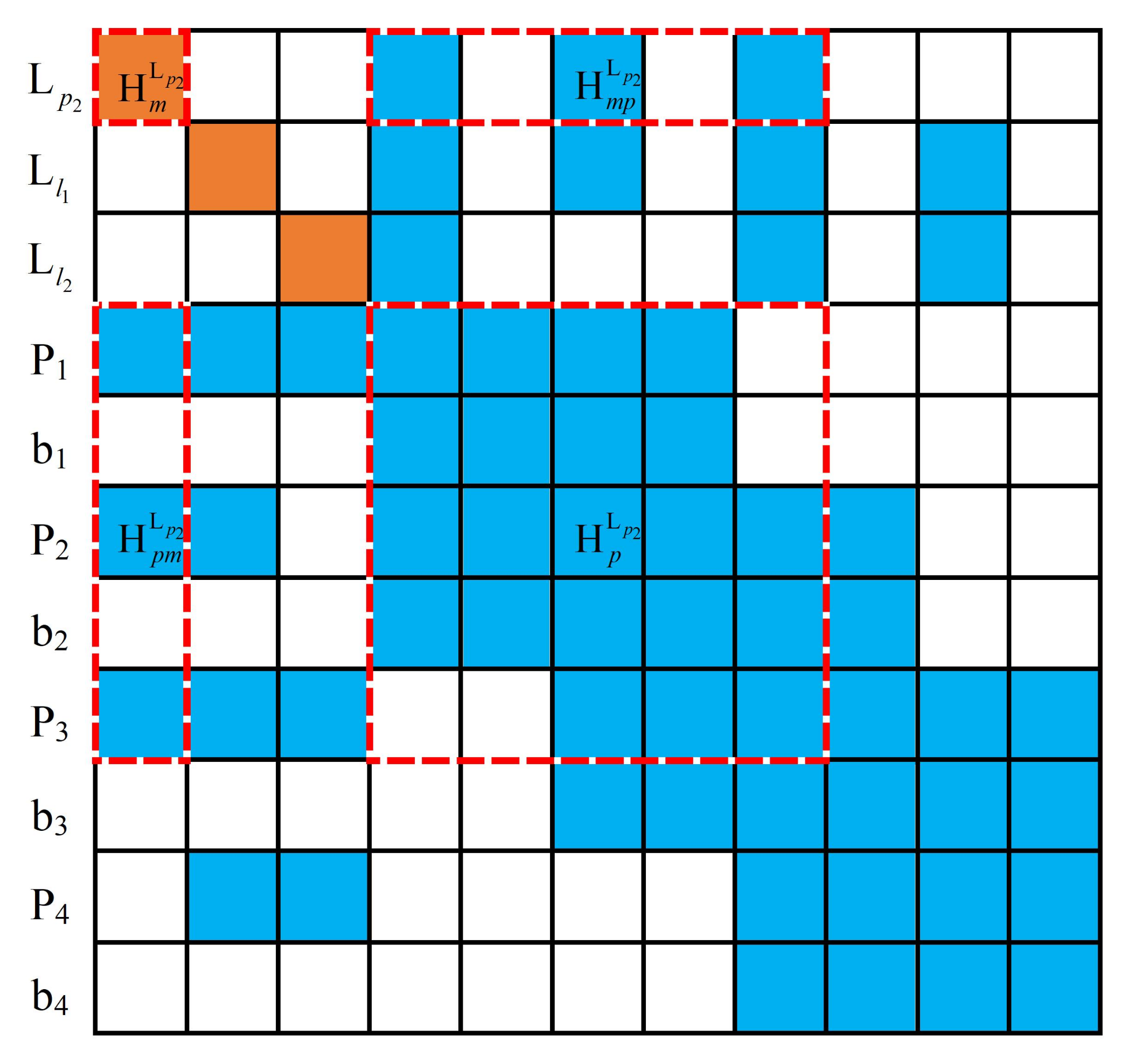
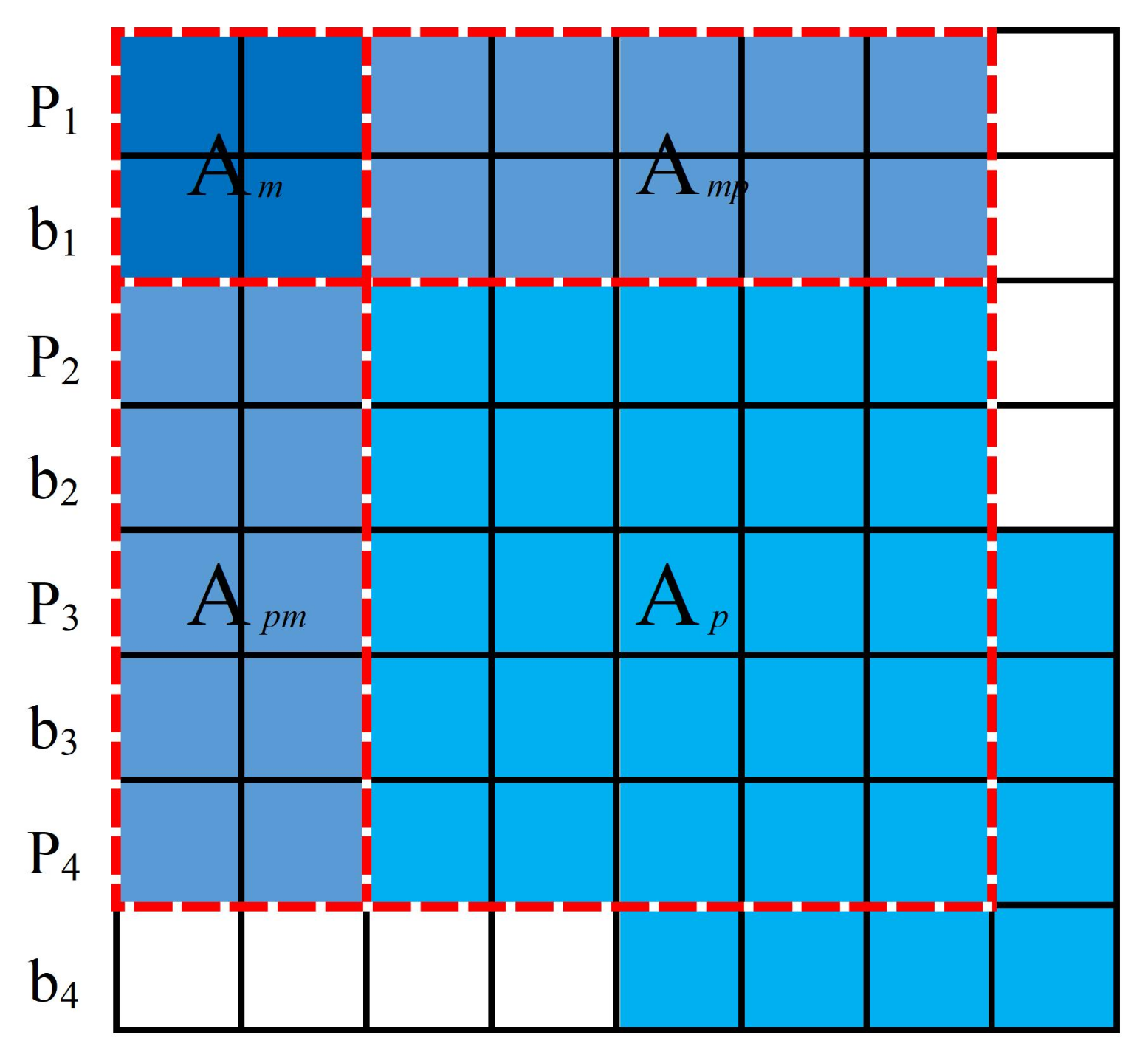
3.3.2. Improved Marginalization
3.3.3. Loop Closure Detection
4. Experimental Results and Analysis
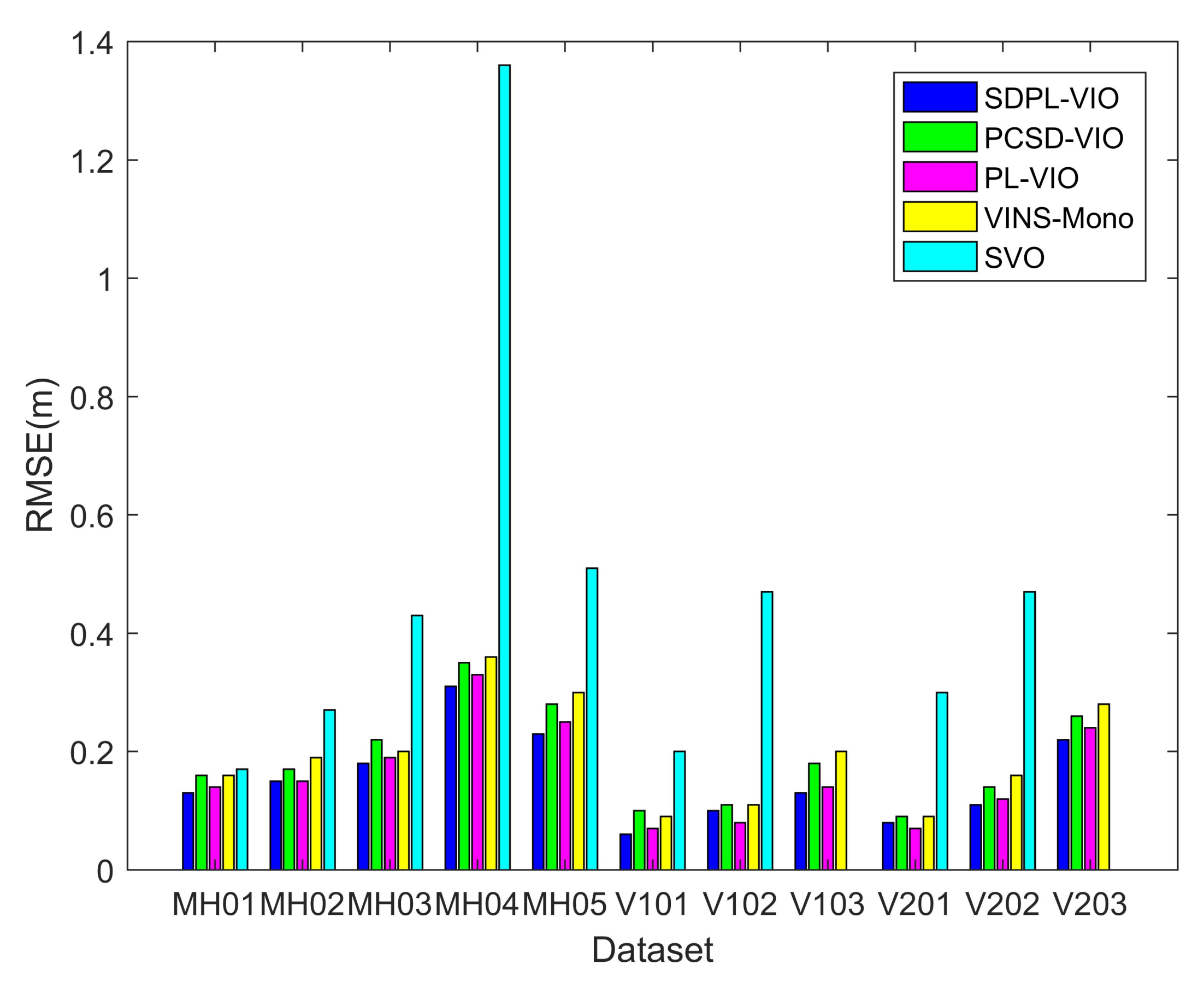
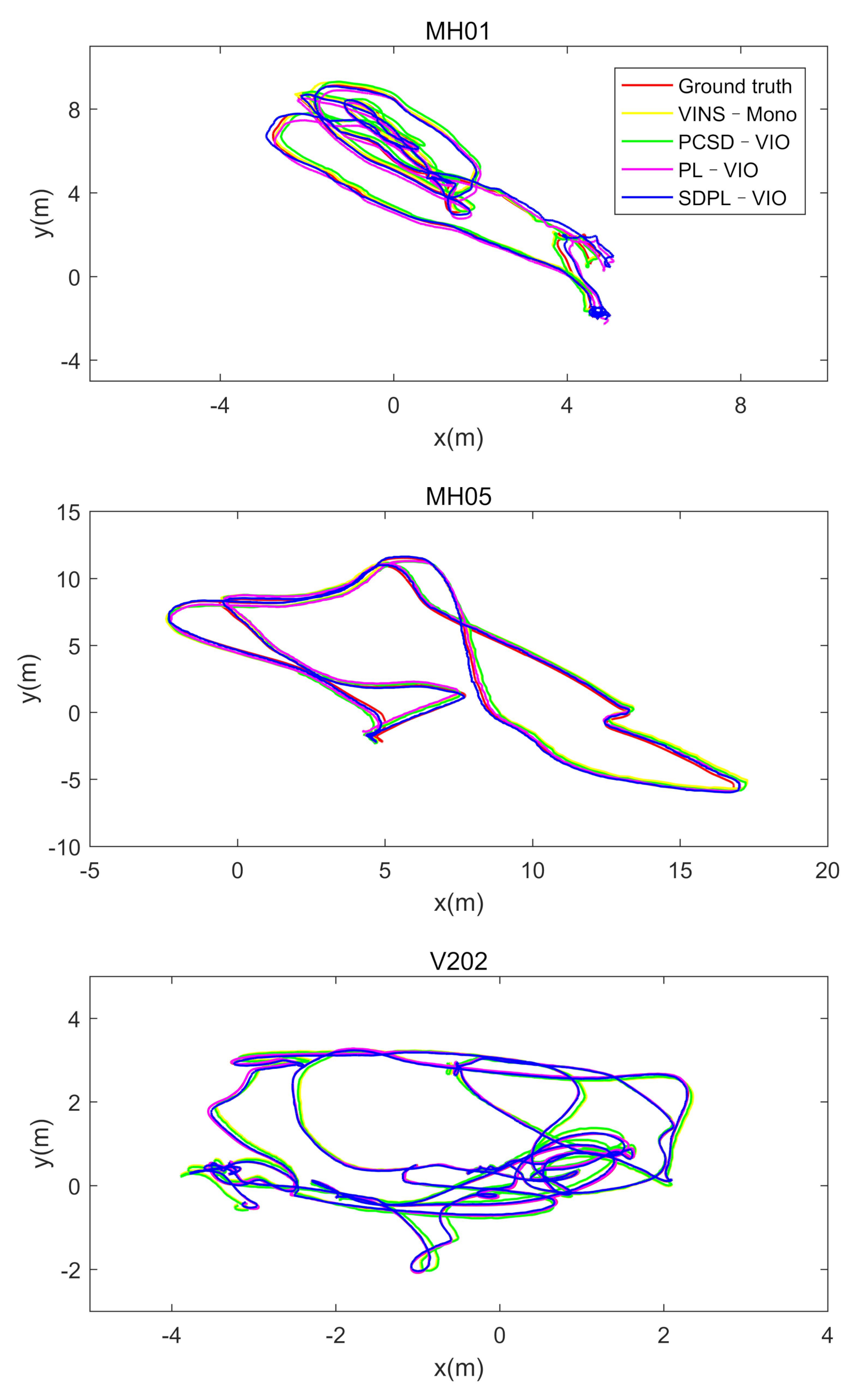
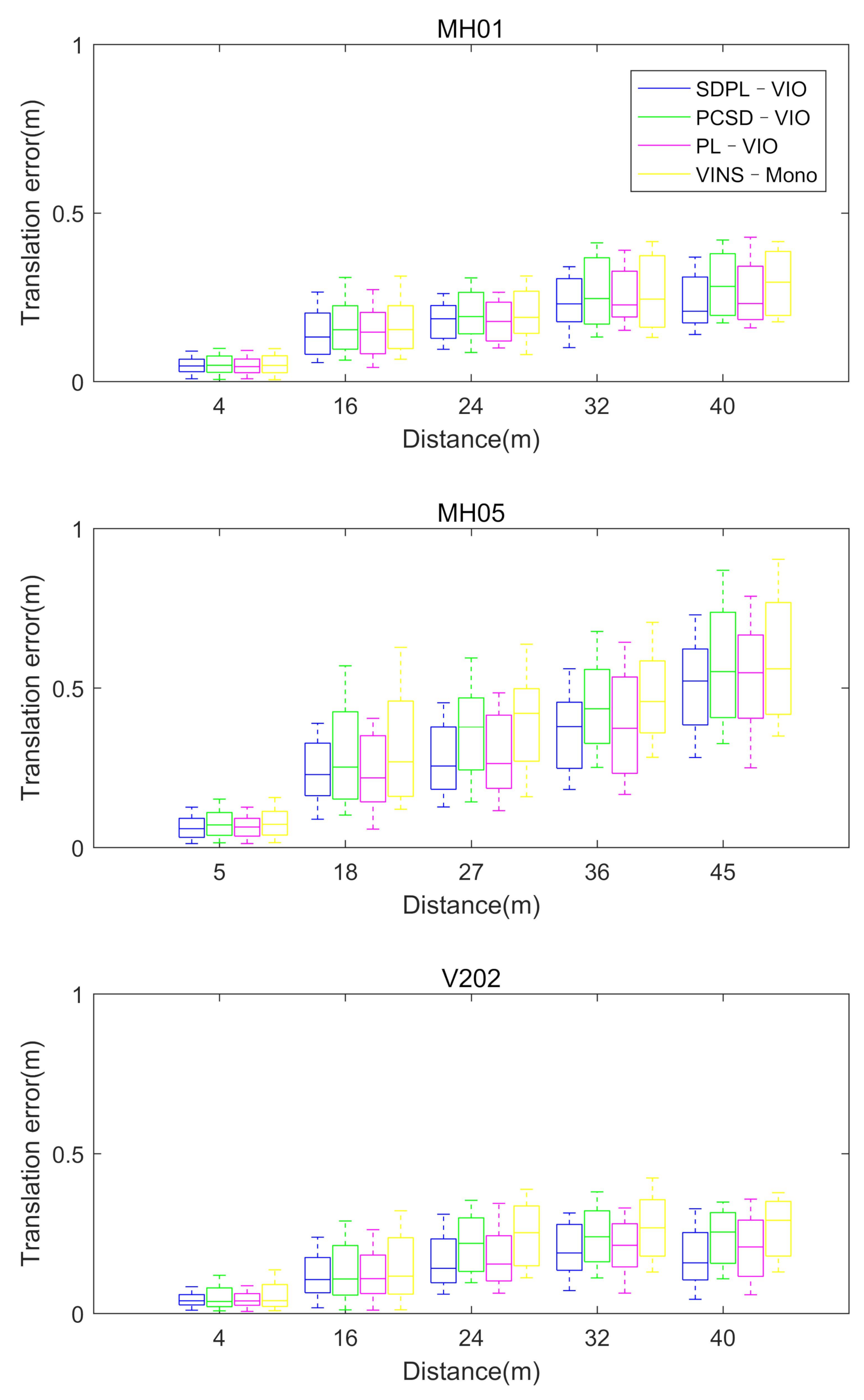
4.1. Accuracy and Robustness Performance
4.2. Computational Performance
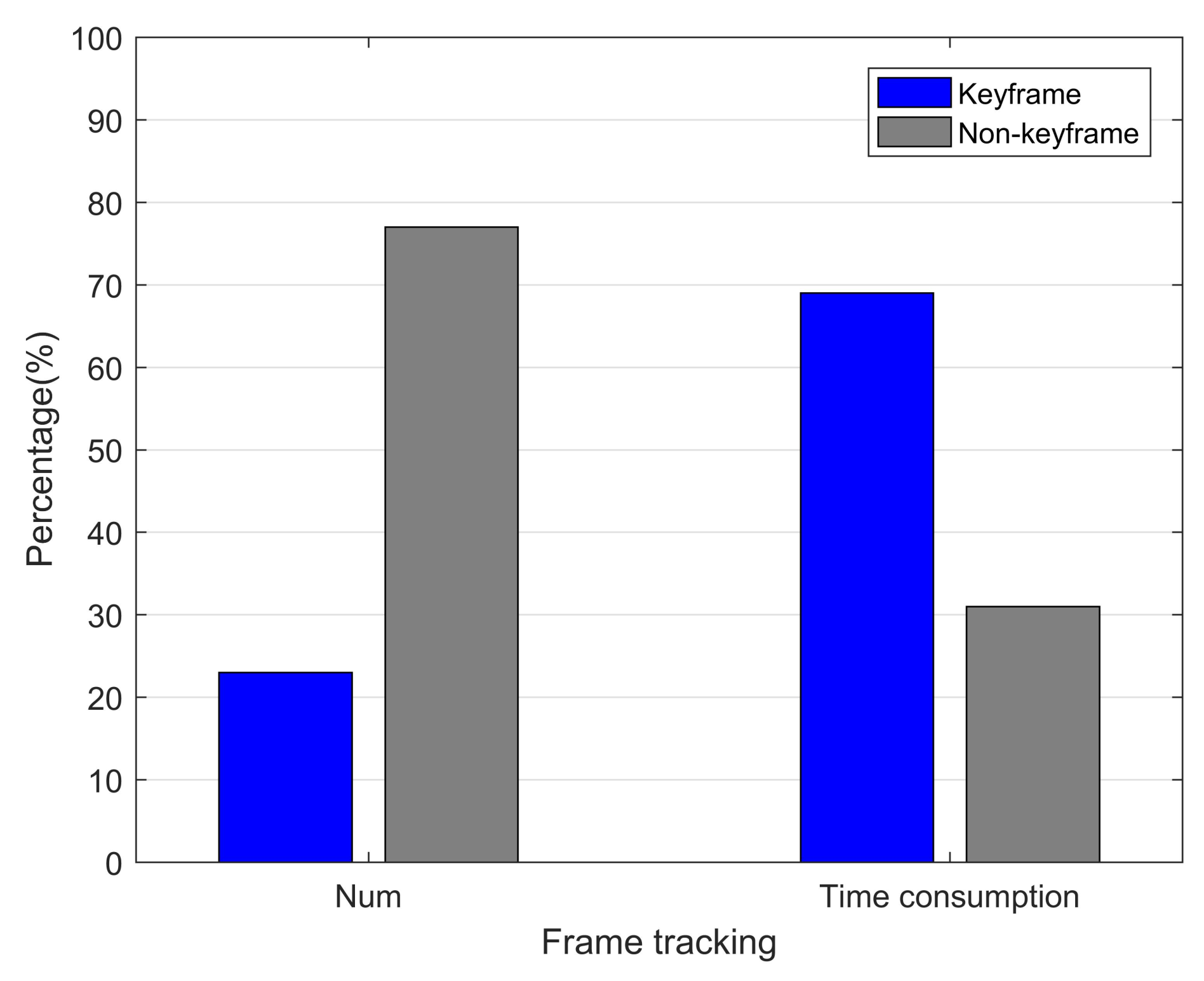
4.2.1. Average Time for Tracking
4.2.2. Average Time for Marginalization
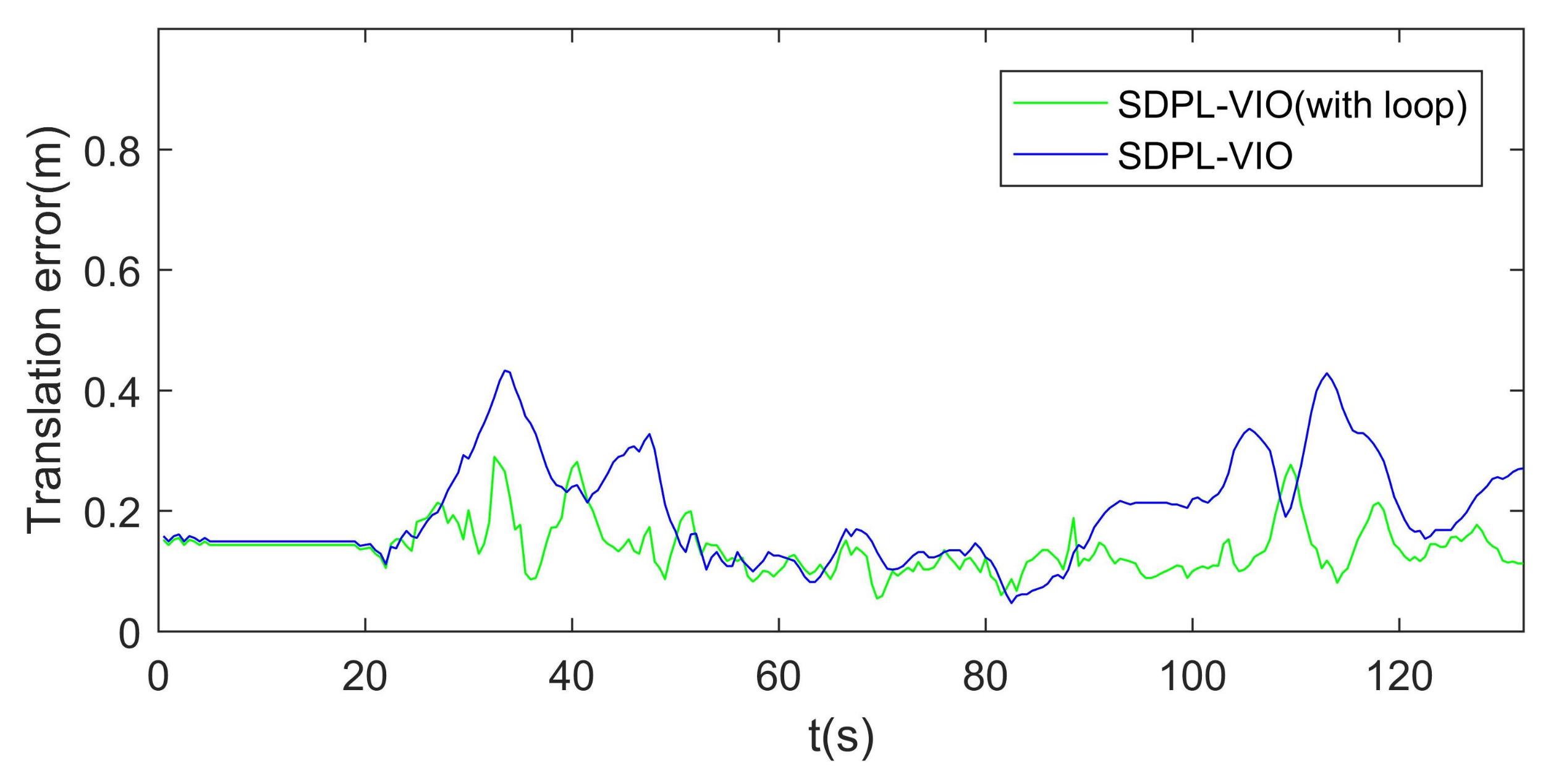
4.3. Loop Closure Detection Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MAVs | Micro Aerial Vehicles |
| IMU | Inertial Measurement Unit |
| VIO | Visual Inertial Odometry |
| VIN | Visual Inertial Navigation |
| OKVIS | Keyframe-based visual-inertial SLAM using nonlinear optimization |
| BRISK | BRISK: Binary robust invariant scalable keypoints |
| ORB | Oriented FAST and Rotated BRIEF |
| ORB-SLAM2 | ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and |
| RGB-D Cameras | |
| PL-SLAM | PL-SLAM: Real-time monocular visual SLAM with points and lines |
| DSO | Direct Sparse Odometry |
| VINS-Mono | VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator |
| PL-VIO | PL-VIO: Tightly-Coupled Monocular Visual–Inertial Odometry Using Point and |
| Line Features | |
| SVO | SVO: Fast semi-direct monocular visual odometry |
| PL-SVO | PL-SVO: Semi-direct Monocular Visual Odometry by combining points and |
| line segments | |
| SVL | Semi-direct monocular visual and visual-inertial SLAM with loop closure detection |
| PCSD-VIO | PC-SD-VIO: A constant intensity semi-direct monocular visual-inertial odometry |
| with online photometric calibration | |
| EuRoC | the European Robotics Challenge |
| SFM | Structure from Motion |
| FAST | the Accelerated Segment Test |
| KLT | Kanade-Lucas-Tomasi |
| RANSAC | Random Sample Consensus |
| LSD | Line Segment Detector |
| LBD | Line Band Descriptors |
| DBoW2 | Bags of Words |
| RMSE | root-mean-square error |
References
- Citroni, R.; Di Paolo, F.; Livreri, P. A Novel Energy Harvester for Powering Small UAVs: Performance Analysis, Model Validation and Flight Results. Sensors 2019, 19, 1771. [Google Scholar] [CrossRef]
- Delmerico, J.; Scaramuzza, D. A Benchmark Comparison of Monocular Visual-Inertial Odometry Algorithms for Flying Robots. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2502–2509. [Google Scholar]
- Cheng, J.; Zhang, L.; Chen, Q.; Hu, X.; Cai, J. A review of visual SLAM methods for autonomous driving vehicles. Eng. Appl. Artif. Intell. 2022, 114, 104992. [Google Scholar] [CrossRef]
- Mourikis, A.I.; Roumeliotis, S.I. A Multi-State Constraint Kalman Filter for Vision-aided Inertial Navigation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Rome, Italy, 10–14 April 2007; pp. 3565–3572. [Google Scholar]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-based visual-inertial odometry using nonlinear optimization. Int. J. Robot. Res. 2014, 34, 314–334. [Google Scholar] [CrossRef]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 298–304. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Pumarola, A.; Vakhitov, A.; Agudo, A.; Sanfeliu, A.; Moreno-Noguer, F. PL-SLAM: Real-time monocular visual SLAM with points and lines. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4503–4508. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. Visual-Inertial Monocular SLAM With Map Reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- He, Y.; Zhao, J.; Guo, Y.; He, W.; Yuan, K. PL-VIO: Tightly-Coupled Monocular Visual–Inertial Odometry Using Point and Line Features. Sensors 2019, 18, 1159. [Google Scholar] [CrossRef]
- Duan, R.; Paudel, D.P.; Fu, C.; Lu, P. Stereo Orientation Prior for UAV Robust and Accurate Visual Odometry. IEEE/ASME Trans. Mechatronics 2022, 1–11. [Google Scholar] [CrossRef]
- Engel, J.; Schps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Gomez-Ojeda, R.; Briales, J.; Gonzalez-Jimenez, J. PL-SVO: Semi-direct Monocular Visual Odometry by combining points and line segments. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4211–4216. [Google Scholar]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect Visual Odometry for Monocular and Multicamera Systems. IEEE Trans. Robot. 2017, 33, 249–265. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Zhang, T.; Gao, X.; Wang, D.; Xian, Y. Semi-direct monocular visual and visual-inertial SLAM with loop closure detection. Robot. Auton. Syst. 2019, 112, 201–210. [Google Scholar] [CrossRef]
- Lee, S.H.; Civera, J. Loosely-Coupled Semi-Direct Monocular SLAM. IEEE Robot. Autom. Lett. 2019, 4, 399–406. [Google Scholar] [CrossRef]
- Dong, X.; Cheng, L.; Peng, H.; Li, T. FSD-SLAM: A fast semi-direct SLAM algorithm. Complex Intell. Syst. 2021, 8, 1823–1834. [Google Scholar] [CrossRef]
- Luo, H.; Pape, C.; Reithmeier, E. Hybrid Monocular SLAM Using Double Window Optimization. IEEE Robot. Autom. Lett. 2021, 6, 4899–4906. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, Z.; Wang, H. PC-SD-VIO: A constant intensity semi-direct monocular visual-inertial odometry with online photometric calibration. Robot. Auton. Syst. 2021, 146, 103877. [Google Scholar] [CrossRef]
- Usenko, V.; Demmel, N.; Schubert, D.; Stueckler, J.; Cremers, D. Visual-Inertial Mapping with Non-Linear Factor Recovery. IEEE Robot. Autom. Lett. (RA-L) Int. Intell. Robot. Autom. (ICRA) 2020, 5, 422–429. [Google Scholar] [CrossRef]
- Xiao, J.; Xiong, D.; Yu, Q.; Huang, K.; Lu, H.; Zeng, Z. A Real-Time Sliding Window based Visual-Inertial Odometry for MAVs. IEEE Trans. Ind. Inform. 2020, 16, 4049–4058. [Google Scholar] [CrossRef]
- Guan, Q.; Wei, G.; Wang, L.; Song, Y. A Novel Feature Points Tracking Algorithm in Terms of IMU-Aided Information Fusion. IEEE Trans. Ind. Inform. 2021, 17, 5304–5313. [Google Scholar] [CrossRef]
- Xu, C.; Liu, Z.; Li, Z. Robust Visual-Inertial Navigation System for Low Precision Sensors under Indoor and Outdoor Environments. Remote Sens. 2021, 13, 772. [Google Scholar] [CrossRef]
- Stumberg, L.v.; Cremers, D. DM-VIO: Delayed Marginalization Visual-Inertial Odometry. IEEE Robot. Autom. Lett. 2022, 7, 1408–1415. [Google Scholar] [CrossRef]
- Sibley, G.; Matthies, L.; Sukhatme, G. Sliding window filter with application to planetary landing. J. Field Robot. 2010, 27, 587–608. [Google Scholar] [CrossRef]
- Bartoli, A.; Sturm, P. The 3D line motion matrix and alignment of line reconstructions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; pp. 287–292. [Google Scholar]
- Bartoli, A.; Sturm, P. Structure-From-Motion Using Lines: Representation, Triangulation and Bundle Adjustment. Comput. Vis. Image Underst. 2005, 100, 416–441. [Google Scholar] [CrossRef]
- Rosten, E.; Porter, R.; Drummond, T. Faster and Better: A Machine Learning Approach to Corner Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 105–119. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the Imaging Understanding Workshop, Vancouver, BC, Canada, 24–28 August 1981; pp. 121–130. [Google Scholar]
- Gioi, R.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: A Fast Line Segment Detector with a False Detection Control. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 722–732. [Google Scholar] [CrossRef]
- Zhang, L.; Koch, R. An efficient and robust line segment matching approach based on LBD descriptor and pairwise geometric consistency. J. Vis. Commun. Image Represent. 2013, 24, 794–805. [Google Scholar] [CrossRef]
- Galvez-Lopez, D.; Tardos, J.D. Bags of Binary Words for Fast Place Recognition in Image Sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | SDPL-VIO | PCSD-VIO | PL-VIO | VINS-Mono | SVO |
|---|---|---|---|---|---|
| MH01 | 0.13 | 0.16 | 0.14 | 0.16 | 0.17 |
| MH02 | 0.15 | 0.17 | 0.15 | 0.19 | 0.27 |
| MH03 | 0.18 | 0.22 | 0.19 | 0.20 | 0.43 |
| MH04 | 0.31 | 0.35 | 0.33 | 0.36 | 1.36 |
| MH05 | 0.23 | 0.28 | 0.25 | 0.30 | 0.51 |
| V101 | 0.06 | 0.10 | 0.07 | 0.09 | 0.20 |
| V102 | 0.10 | 0.11 | 0.08 | 0.11 | 0.47 |
| V103 | 0.13 | 0.18 | 0.14 | 0.20 | N/A |
| V201 | 0.08 | 0.09 | 0.07 | 0.09 | 0.30 |
| V202 | 0.11 | 0.14 | 0.12 | 0.16 | 0.47 |
| V203 | 0.22 | 0.26 | 0.24 | 0.28 | N/A |
| Sequence | SDPL-VIO | PL-VIO |
|---|---|---|
| MH01 | 28.54 | 84.40 |
| MH02 | 33.55 | 88.05 |
| MH03 | 27.51 | 85.73 |
| MH04 | 30.45 | 83.18 |
| MH05 | 30.10 | 83.10 |
| V101 | 29.65 | 82.52 |
| V102 | 29.48 | 83.35 |
| V103 | 32.81 | 87.61 |
| V201 | 30.15 | 81.24 |
| V202 | 31.65 | 89.76 |
| V203 | 33.56 | 90.40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, B.; Lian, B.; Tang, C. Semi-Direct Point-Line Visual Inertial Odometry for MAVs. Appl. Sci. 2022, 12, 9265. https://doi.org/10.3390/app12189265
Gao B, Lian B, Tang C. Semi-Direct Point-Line Visual Inertial Odometry for MAVs. Applied Sciences. 2022; 12(18):9265. https://doi.org/10.3390/app12189265
Chicago/Turabian StyleGao, Bo, Baowang Lian, and Chengkai Tang. 2022. "Semi-Direct Point-Line Visual Inertial Odometry for MAVs" Applied Sciences 12, no. 18: 9265. https://doi.org/10.3390/app12189265
APA StyleGao, B., Lian, B., & Tang, C. (2022). Semi-Direct Point-Line Visual Inertial Odometry for MAVs. Applied Sciences, 12(18), 9265. https://doi.org/10.3390/app12189265