
ReSTiNet: On Improving the Performance of Tiny-YOLO-Based CNN Architecture for Applications in Human Detection

 ,
,  ,
, 
Abstract
:1. Introduction
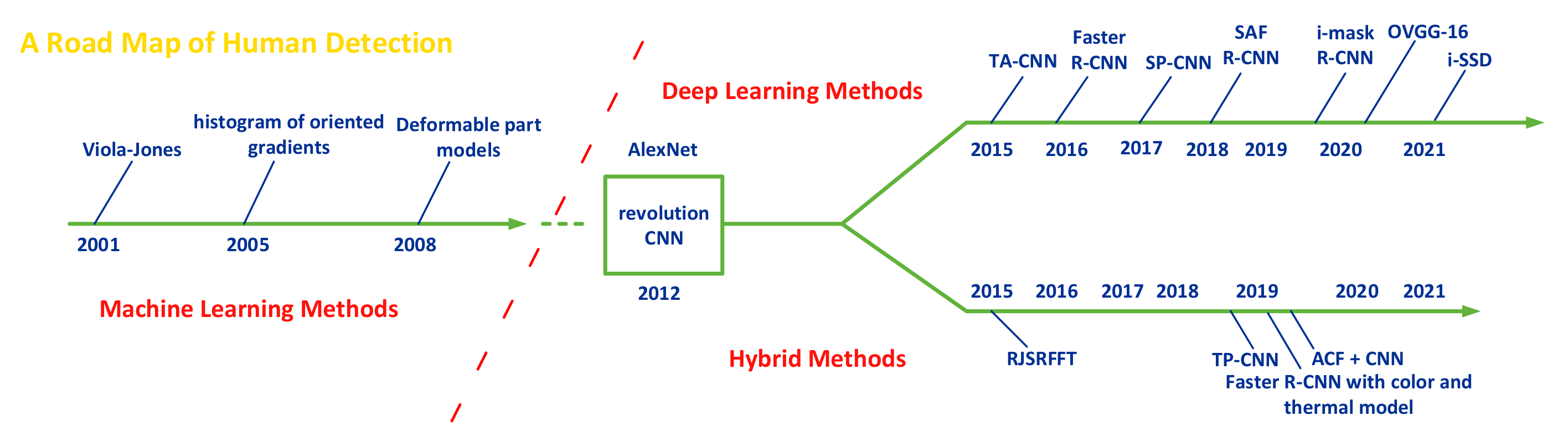
2. Related Literature: State-of-the-Art Methods
3. The Proposed ReSTiNet for Low-Memory Devices
3.1. Motivation
| Algorithm 1 ReSTiNet pseudocode |
Input: Input(shape= (input_size, input_size,3)) Input: learning_ rate, epoch, batch_size Input: iou_ threshold, score_ threshold Output: output_shape, mAP def fire_module(model, fire_id, squeeze, expand) def maxpooling (pool_size, stride) def resnet_block (model, filters, reps, stride) def mAP (model): map = model.evaluate (generator, iou_threshold, score_threshold, average_precisions) return map def layer(conv, batchnorm, activation, maxpooling, dropout) def main (){ create layer1: ([16,3,1], norm_1, leakyReLU[.1], 2, null) x ← layer1 for i in range(2,3,4,5): create layer(i): ([32∗(2∗∗i), 3, 1], norm_ + str(i+2), leakyReLU[.1], 2, [0.20]) x ← (x) (layer(i)) //return x create fire_module1: (x, 2, 16, 64) create fire_module2: (x, 3, 16, 64) create maxpooling1: (3, 2) create resnet_block1: (x, 64, 3, 1) create fire_module3: (x, 4, 32, 128) create fire_module4: (x, 5, 32, 128) create maxpooling2: (3, 2) create resnet_block1: (x, 128, 4, 2) create fire_module5: (x, 6, 48, 192) create fire_module6: (x, 7, 48, 192) create fire_module7: (x, 8, 64, 256) create fire_module8: (x, 9, 64, 256) dropout ← 0.50 return mAP(x), output_shape(x)} |
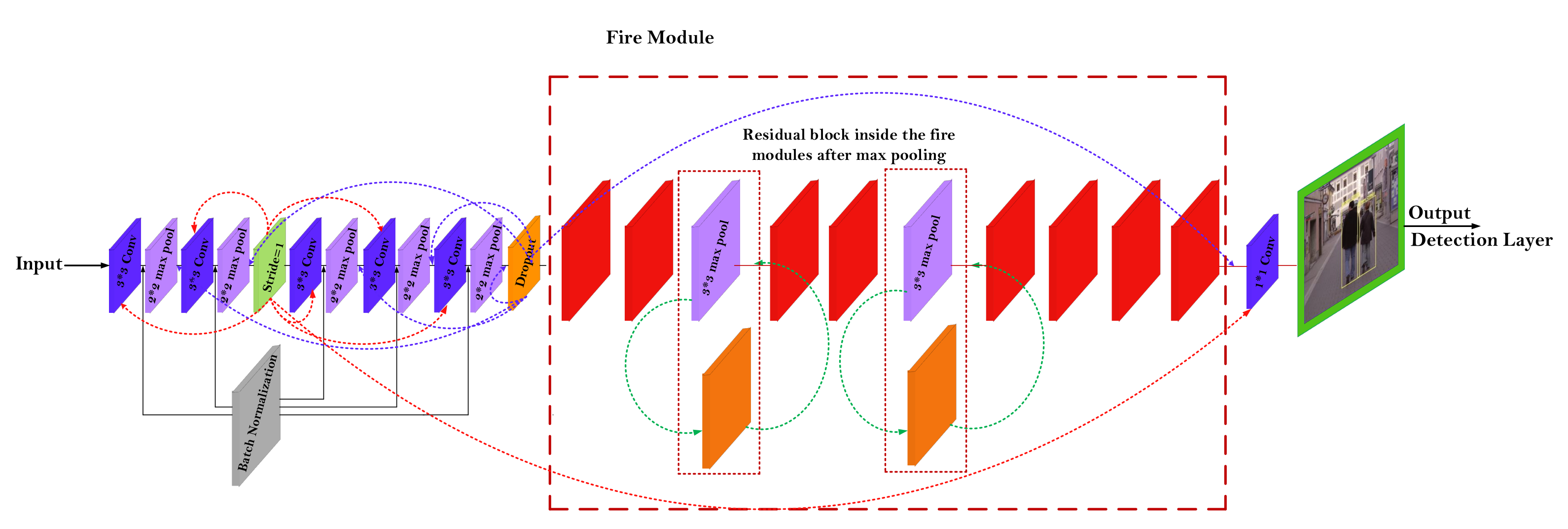
3.2. Construction of ReSTiNet
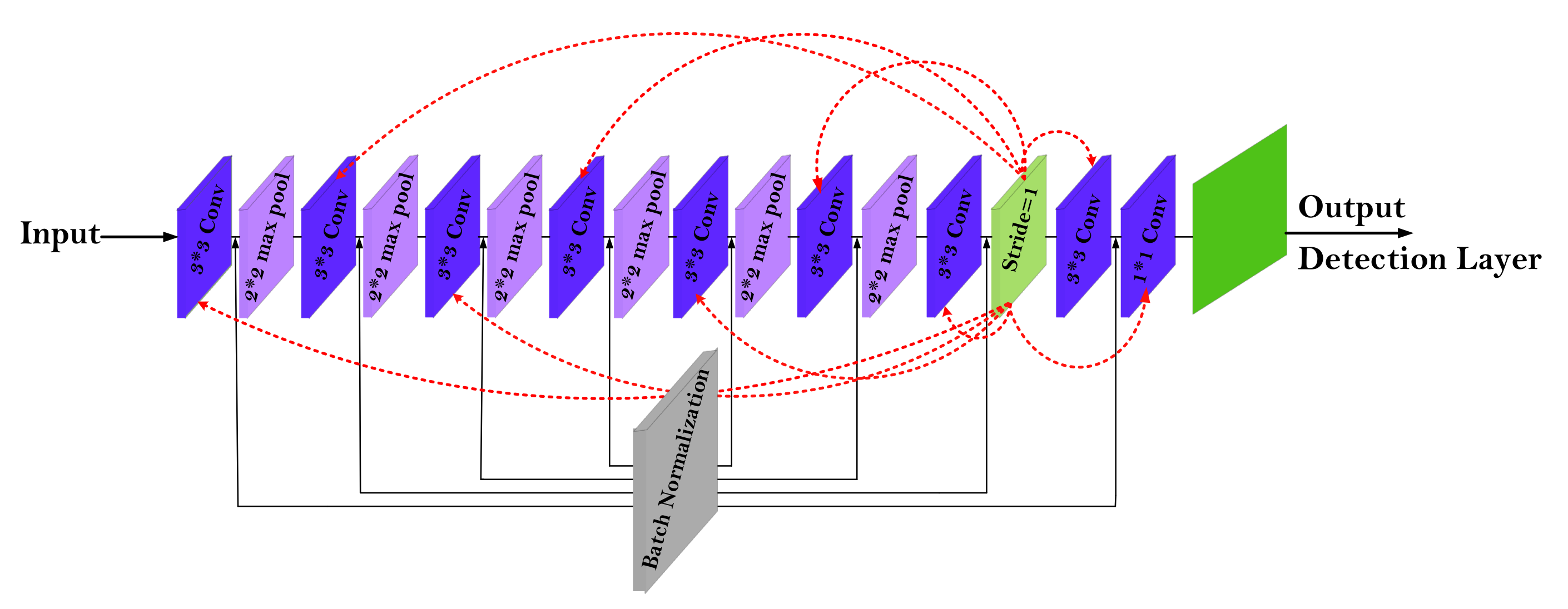
3.2.1. Tiny-YOLO
3.2.2. Fire Module of ReSTiNet
3.2.3. Residual Block between Fire Modules
3.2.4. Dropout in ReSTiNet
3.2.5. Loss Function of ReSTiNet
3.3. Time Complexity, Success, and Challenge of ReSTiNet
3.3.1. Time Complexity
3.3.2. Advantage of the Model
3.3.3. Challenge of the Model
4. Experimental Results
4.1. System Specification
4.2. Data-Set Specification
4.3. Evaluation Criteria (mAP)
4.4. Model Training
4.5. Ablation Experiments of the Proposed ReSTiNet
Detection Time, Parameter, and FLOPs Comparison between Tiny-YOLO and ReSTiNet
4.6. ReSTiNet Performance Comparison with Other Lightweight Methods
5. Performance Analysis of ReSTiNet
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ansari, M.; Singh, D.K. Human detection techniques for real time surveillance: A comprehensive survey. Multimed. Tools Appl. 2021, 80, 8759–8808. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Mahmmod, B.M.; Abdul-Hadi, A.M.; Abdulhussain, S.H.; Hussien, A. On computational aspects of Krawtchouk polynomials for high orders. J. Imaging 2020, 6, 81. [Google Scholar] [CrossRef] [PubMed]
- Haq, E.U.; Jianjun, H.; Li, K.; Haq, H.U. Human detection and tracking with deep convolutional neural networks under the constrained of noise and occluded scenes. Multimed. Tools Appl. 2020, 79, 30685–30708. [Google Scholar] [CrossRef]
- Kim, K.; Oh, C.; Sohn, K. Personness estimation for real-time human detection on mobile devices. Expert Syst. Appl. 2017, 72, 130–138. [Google Scholar] [CrossRef]
- Sumit, S.S.; Rambli, D.R.A.; Mirjalili, S. Vision-Based Human Detection Techniques: A Descriptive Review. IEEE Access 2021, 9, 42724–42761. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Shao, Y.; Zhang, X.; Chu, H.; Zhang, X.; Zhang, D.; Rao, Y. AIR-YOLOv3: Aerial Infrared Pedestrian Detection via an Improved YOLOv3 with Network Pruning. Appl. Sci. 2022, 12, 3627. [Google Scholar] [CrossRef]
- Road Traffic Injuries. 2022. Available online: https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries (accessed on 2 March 2022).
- García, F.; García, J.; Ponz, A.; De La Escalera, A.; Armingol, J.M. Context aided pedestrian detection for danger estimation based on laser scanner and computer vision. Expert Syst. Appl. 2014, 41, 6646–6661. [Google Scholar] [CrossRef]
- Ritchie, H.; Hasell, J.; Mathieu, E.; Appel, C.; Roser, M. Terrorism. Our World in Data. 2019. Available online: https://ourworldindata.org/terrorism (accessed on 2 March 2022).
- Idrees, H.; Soomro, K.; Shah, M. Detecting humans in dense crowds using locally-consistent scale prior and global occlusion reasoning. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1986–1998. [Google Scholar] [CrossRef]
- Kalayeh, M.M.; Basaran, E.; Gökmen, M.; Kamasak, M.E.; Shah, M. Human semantic parsing for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1062–1071. [Google Scholar]
- Sumit, S.S.; Watada, J.; Roy, A.; Rambli, D. In object detection deep learning methods, YOLO shows supremum to Mask R-CNN. J. Phys. Conf. Ser. 2020, 1529, 042086. [Google Scholar] [CrossRef]
- Luna, C.A.; Losada-Gutiérrez, C.; Fuentes-Jiménez, D.; Mazo, M. Fast heuristic method to detect people in frontal depth images. Expert Syst. Appl. 2021, 168, 114483. [Google Scholar] [CrossRef]
- Fuentes-Jimenez, D.; Martin-Lopez, R.; Losada-Gutierrez, C.; Casillas-Perez, D.; Macias-Guarasa, J.; Luna, C.A.; Pizarro, D. DPDnet: A robust people detector using deep learning with an overhead depth camera. Expert Syst. Appl. 2020, 146, 113168. [Google Scholar] [CrossRef]
- Kim, D.; Kim, H.; Mok, Y.; Paik, J. Real-Time Surveillance System for Analyzing Abnormal Behavior of Pedestrians. Appl. Sci. 2021, 11, 6153. [Google Scholar] [CrossRef]
- Wang, W.; Li, Y.; Zou, T.; Wang, X.; You, J.; Luo, Y. A novel image classification approach via dense-MobileNet models. Mob. Inf. Syst. 2020, 2020, 7602384. [Google Scholar] [CrossRef]
- Fang, W.; Wang, L.; Ren, P. Tinier-YOLO: A real-time object detection method for constrained environments. IEEE Access 2019, 8, 1935–1944. [Google Scholar] [CrossRef]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4133–4141. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Quantized neural networks: Training neural networks with low precision weights and activations. J. Mach. Learn. Res. 2017, 18, 6869–6898. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Nguyen, D.T.; Li, W.; Ogunbona, P.O. Human detection from images and videos: A survey. Pattern Recognit. 2016, 51, 148–175. [Google Scholar] [CrossRef]
- Sabzmeydani, P.; Mori, G. Detecting pedestrians by learning shapelet features. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the International Conference on Computer Vision & Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; IEEE Computer Society: Washington, DC, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Mu, Y.; Yan, S.; Liu, Y.; Huang, T.; Zhou, B. Discriminative local binary patterns for human detection in personal album. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Viola, P.; Jones, M.J.; Snow, D. Detecting pedestrians using patterns of motion and appearance. Int. J. Comput. Vis. 2005, 63, 153–161. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B.; Schmid, C. Human detection using oriented histograms of flow and appearance. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 428–441. [Google Scholar]
- Xu, Y.; Xu, D.; Lin, S.; Han, T.X.; Cao, X.; Li, X. Detection of sudden pedestrian crossings for driving assistance systems. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2011, 42, 729–739. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision And Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Ouyang, W.; Wang, X. Joint deep learning for pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2056–2063. [Google Scholar]
- Zeng, X.; Ouyang, W.; Wang, X. Multi-stage contextual deep learning for pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 121–128. [Google Scholar]
- Luo, P.; Tian, Y.; Wang, X.; Tang, X. Switchable deep network for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 899–906. [Google Scholar]
- Cai, Z.; Saberian, M.; Vasconcelos, N. Learning complexity-aware cascades for deep pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3361–3369. [Google Scholar]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Pedestrian detection aided by deep learning semantic tasks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5079–5087. [Google Scholar]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware fast R-CNN for pedestrian detection. IEEE Trans. Multimed. 2017, 20, 985–996. [Google Scholar] [CrossRef]
- Zhang, L.; Lin, L.; Liang, X.; He, K. Is faster R-CNN doing well for pedestrian detection? In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2016; pp. 443–457. [Google Scholar]
- Liu, J.; Gao, X.; Bao, N.; Tang, J.; Wu, G. Deep convolutional neural networks for pedestrian detection with skip pooling. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2056–2063. [Google Scholar]
- Xu, C.; Wang, G.; Yan, S.; Yu, J.; Zhang, B.; Dai, S.; Li, Y.; Xu, L. Fast Vehicle and Pedestrian Detection Using Improved Mask R-CNN. Math. Probl. Eng. 2020, 2020, 5761414. [Google Scholar] [CrossRef]
- Kim, B.; Yuvaraj, N.; Sri Preethaa, K.; Santhosh, R.; Sabari, A. Enhanced pedestrian detection using optimized deep convolution neural network for smart building surveillance. Soft Comput. 2020, 24, 17081–17092. [Google Scholar] [CrossRef]
- Brunetti, A.; Buongiorno, D.; Trotta, G.F.; Bevilacqua, V. Computer vision and deep learning techniques for pedestrian detection and tracking: A survey. Neurocomputing 2018, 300, 17–33. [Google Scholar] [CrossRef]
- Lan, X.; Ma, A.J.; Yuen, P.C.; Chellappa, R. Joint sparse representation and robust feature-level fusion for multi-cue visual tracking. IEEE Trans. Image Process. 2015, 24, 5826–5841. [Google Scholar] [CrossRef]
- Jeon, H.M.; Nguyen, V.D.; Jeon, J.W. Pedestrian detection based on deep learning. In Proceedings of the IECON 2019-45th Annual Conference of the IEEE Industrial Electronics Society, Lisbon, Portugal, 14–17 October 2019; Volume 1, pp. 144–151. [Google Scholar]
- Chebrolu, K.N.R.; Kumar, P. Deep learning based pedestrian detection at all light conditions. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 4–6 April 2019; pp. 0838–0842. [Google Scholar]
- Mateus, A.; Ribeiro, D.; Miraldo, P.; Nascimento, J.C. Efficient and robust pedestrian detection using deep learning for human-aware navigation. Robot. Auton. Syst. 2019, 113, 23–37. [Google Scholar]
- Liu, S.a.; Lv, S.; Zhang, H.; Gong, J. Pedestrian detection algorithm based on the improved ssd. In Proceedings of the 2019 Chinese Control And Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 3559–3563. [Google Scholar]
- Zhou, T.; Wang, W.; Qi, S.; Ling, H.; Shen, J. Cascaded human-object interaction recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4263–4272. [Google Scholar]
- Zhou, T.; Wang, W.; Liu, S.; Yang, Y.; Van Gool, L. Differentiable multi-granularity human representation learning for instance-aware human semantic parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1622–1631. [Google Scholar]
- Qassim, H.; Verma, A.; Feinzimer, D. Compressed residual-VGG16 CNN model for big data places image recognition. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018; pp. 169–175. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Rennie, S.J.; Goel, V.; Thomas, S. Annealed dropout training of deep networks. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, NV, USA, 7–10 December 2014; pp. 159–164. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Dauphin, Y.N.; Bengio, Y. Big neural networks waste capacity. arXiv 2013, arXiv:1301.3583. [Google Scholar]
- Ba, L.J.; Caruana, R. Do deep nets really need to be deep? arXiv 2013, arXiv:1312.6184. [Google Scholar]
- Poole, B.; Lahiri, S.; Raghu, M.; Sohl-Dickstein, J.; Ganguli, S. Exponential expressivity in deep neural networks through transient chaos. Adv. Neural Inf. Process. Syst. 2016, 29, 3360–3368. [Google Scholar]
- Dean, J.; Corrado, G.; Monga, R.; Chen, K.; Devin, M.; Mao, M.; Ranzato, M.; Senior, A.; Tucker, P.; Yang, K.; et al. Large scale distributed deep networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1223–1231. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Computing Platform | Graphics Processor | Memory |
|---|---|---|
| Tesla K80 | GK210 × 2, 2496 × 2 shading units, 208 × 2 TUMs, 48 × 2 ROPs | 12 GB × 2, 384 bit × 2, GDDR5, 240.6 GB/s × 2 |
| Hyperparameter | Range |
|---|---|
| input size | 416 × 416 |
| learning rate | 0.001 |
| activation | Leaky ReLU (), ReLU |
| batchsize | 16 |
| no. of epoch | 50 |
| optimizer | adam (, , ) |
| loss function | custom loss |
| dropout | 0.2, 0.5 |
| iou_threshold | 0.5 |
| score_threshold | 0.5 |
| Tiny-YOLO | ReSTiNet | ||
|---|---|---|---|
| fire module | ✓ | ✓ | |
| residual learning | ✓ | ||
| dropout | ✓ | ✓ | |
| MS COCO mAP(%) | 19.0 | 24.37 | 27.31 |
| Pascal VOC mAP(%) | 42.21 | 55.67 | 63.79 |
| Tiny-YOLO | ReSTiNet | Dataset | |
|---|---|---|---|
| Avg. test time | 74.486 (s) | 37.514 (s) | INRIA |
| Model parameters | 11.043 (m) | 2.109 (m) | - |
| FLOPs | 11.552 (bn) | 7.570 (bn) | - |
| Network | mAP (%) | Model Size (MB) |
|---|---|---|
| MobileNet | 47.12 | 13.5 |
| SqueezeNet | 41.51 | 3.0 |
| Tiny-YOLO | 42.21 | 60.50 |
| ReSTiNet | 63.79 | 10.7 |
| Conv. Layer | Input Channel | Output Channel | Kernel Size | Conv. Layer (Parameters) | Fire Module (Parameters) |
|---|---|---|---|---|---|
| 1 | 3 | 16 | 3 | 448 | 184 |
| 2 | 16 | 32 | 3 | 4680 | 740 |
| 3 | 32 | 64 | 3 | 18,496 | 2888 |
| 4 | 64 | 128 | 3 | 73,856 | 11,408 |
| 5 | 128 | 256 | 3 | 295,168 | 45,344 |
| 6 | 256 | 512 | 3 | 1,180,160 | 180,800 |
| 7 | 512 | 1024 | 3 | 4,719,616 | 722,048 |
| 8 | 1024 | 512 | 3 | 4,719,616 | 722,048 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sumit, S.S.; Awang Rambli, D.R.; Mirjalili, S.; Ejaz, M.M.; Miah, M.S.U. ReSTiNet: On Improving the Performance of Tiny-YOLO-Based CNN Architecture for Applications in Human Detection. Appl. Sci. 2022, 12, 9331. https://doi.org/10.3390/app12189331
Sumit SS, Awang Rambli DR, Mirjalili S, Ejaz MM, Miah MSU. ReSTiNet: On Improving the Performance of Tiny-YOLO-Based CNN Architecture for Applications in Human Detection. Applied Sciences. 2022; 12(18):9331. https://doi.org/10.3390/app12189331
Chicago/Turabian StyleSumit, Shahriar Shakir, Dayang Rohaya Awang Rambli, Seyedali Mirjalili, Muhammad Mudassir Ejaz, and M. Saef Ullah Miah. 2022. "ReSTiNet: On Improving the Performance of Tiny-YOLO-Based CNN Architecture for Applications in Human Detection" Applied Sciences 12, no. 18: 9331. https://doi.org/10.3390/app12189331
APA StyleSumit, S. S., Awang Rambli, D. R., Mirjalili, S., Ejaz, M. M., & Miah, M. S. U. (2022). ReSTiNet: On Improving the Performance of Tiny-YOLO-Based CNN Architecture for Applications in Human Detection. Applied Sciences, 12(18), 9331. https://doi.org/10.3390/app12189331