
Synthetic Data and Computer-Vision-Based Automated Quality Inspection System for Reused Scaffolding

 , ,
, , 
Abstract
:1. Introduction
- The lack of a regulatory framework that defines the quantitative indicators of the extent of the deformation and its impact on the quality of the scaffold.
- The lack of technologies that allow the automatic detection of different types of deformations necessary for quality assessment, which can be combined into an overall assessment.
- Improvement of the existing inspection process by reducing the time for quality inspection and independence from human errors.
- Describing an augmentation process of the real dataset by synthetic data prevents over-fitting of the model during the training phase and reduces the time needed for the preparation of the dataset.
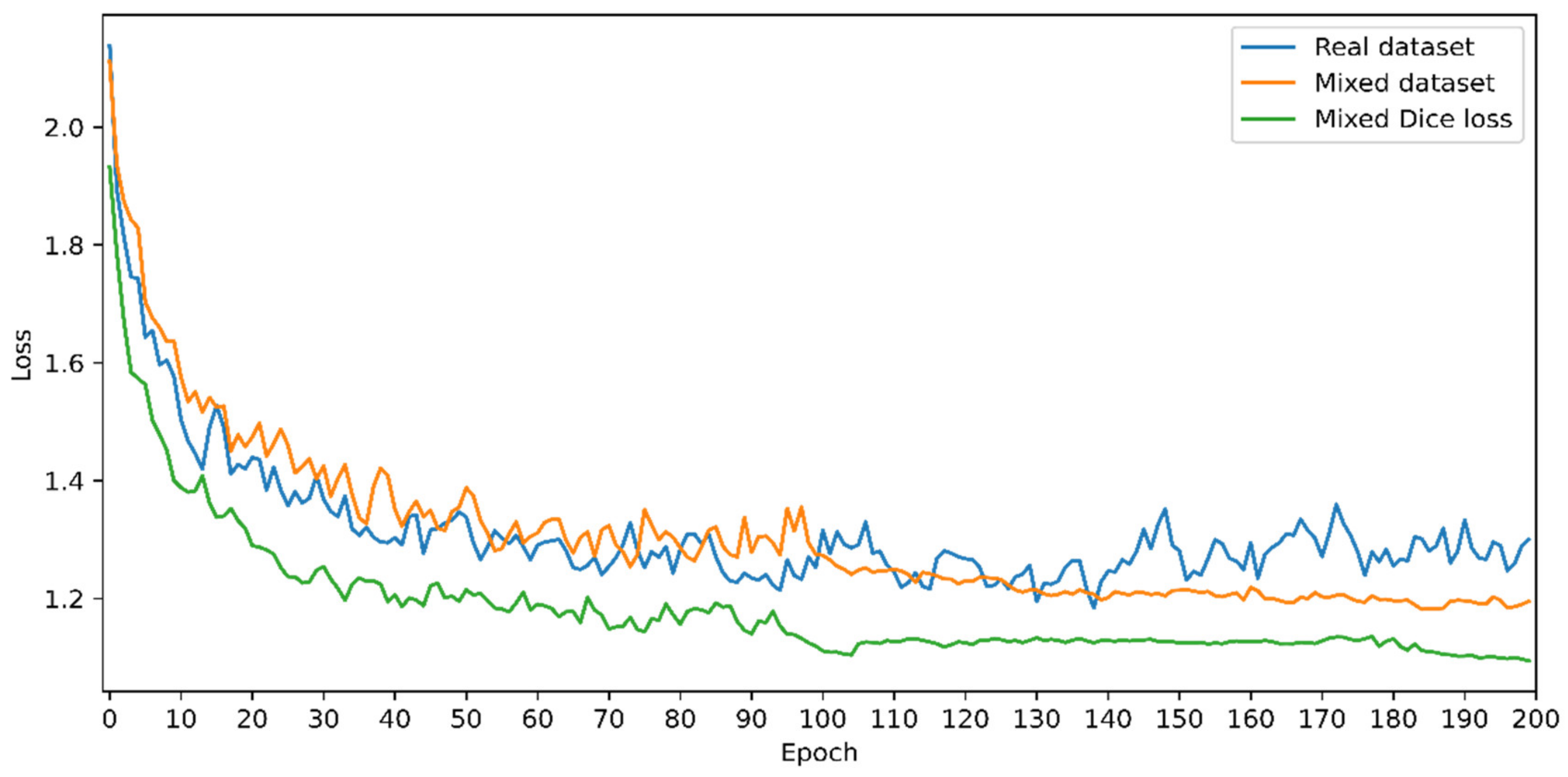
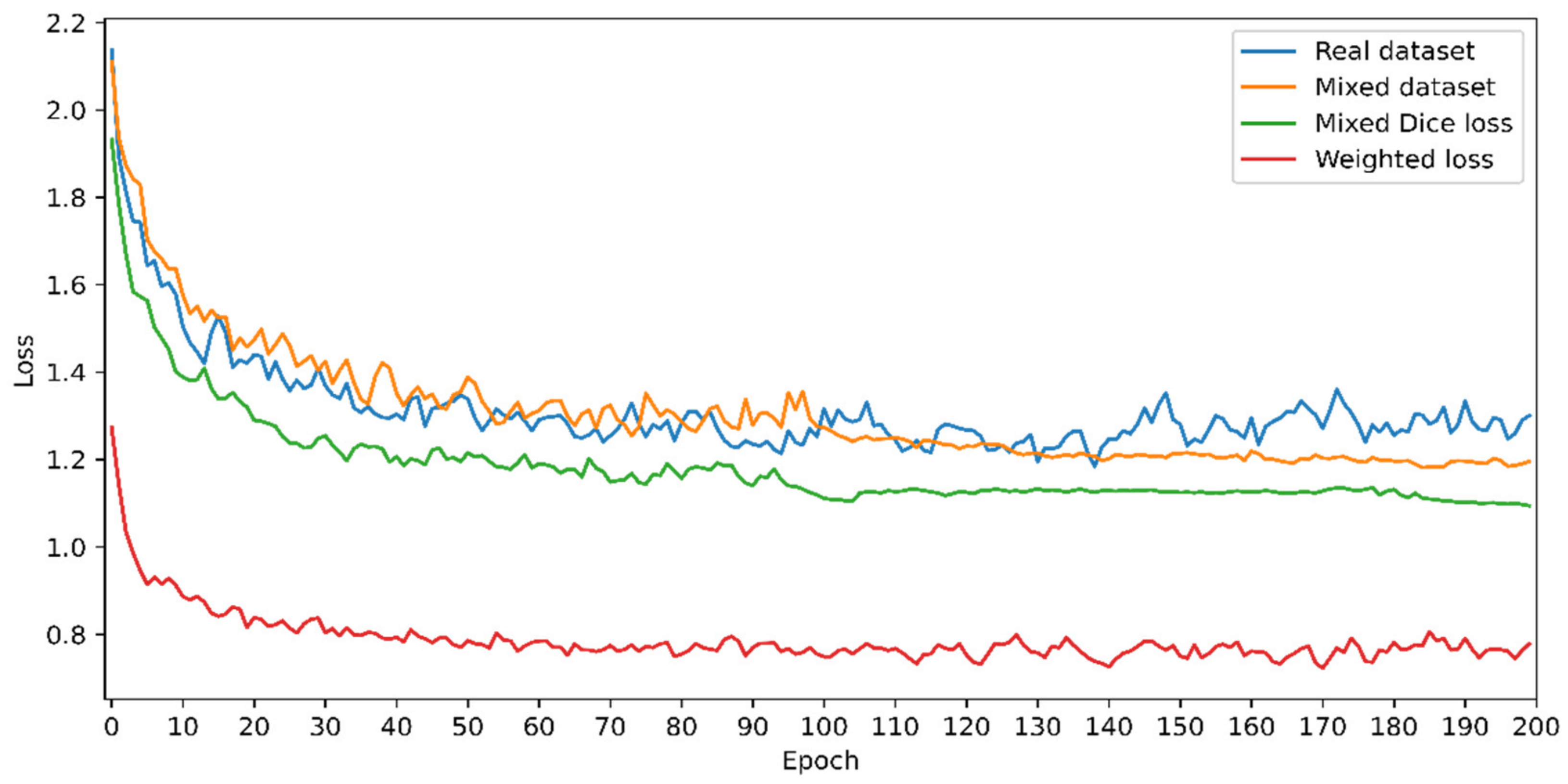
- Describing the advantages of using dice loss for mask branch or mask R-CNN models.
- Defining the scaffolding quality classes as a function of the deformation values obtained from the expert survey.
2. Research Background
2.1. 3D Scanner-Based Defect Detection
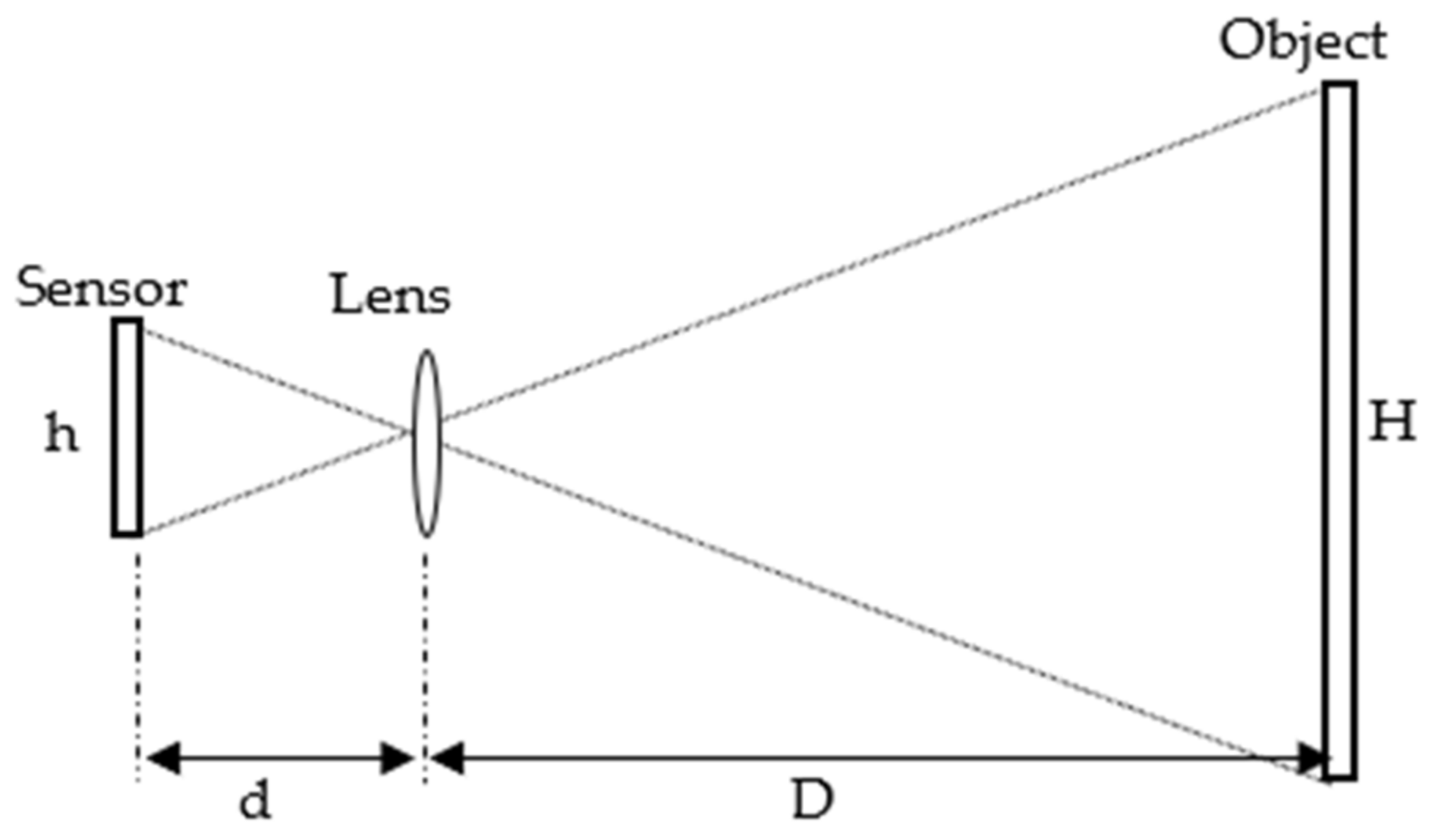
2.2. 2D Image-Based Defect Detection
3. Materials and Methods
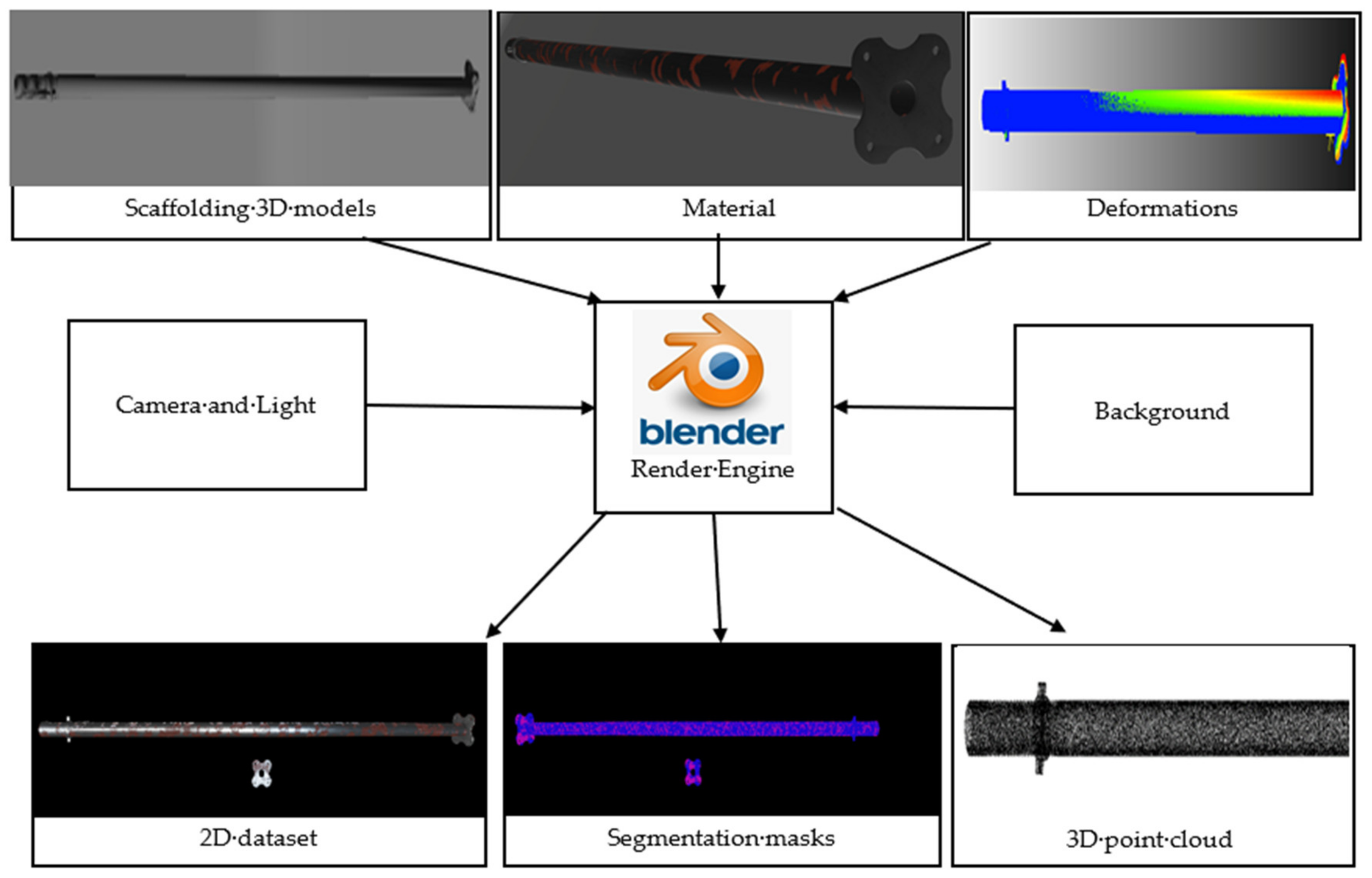
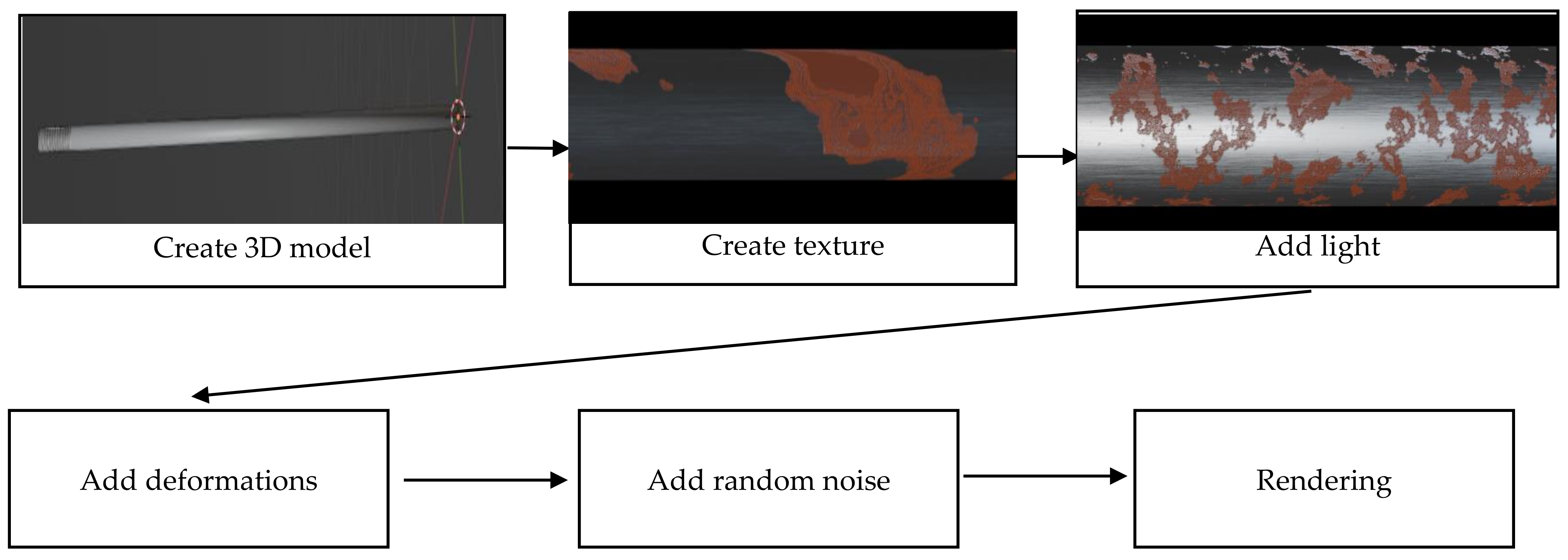
3.1. Datasets
3.2. 2D Image Segmentation
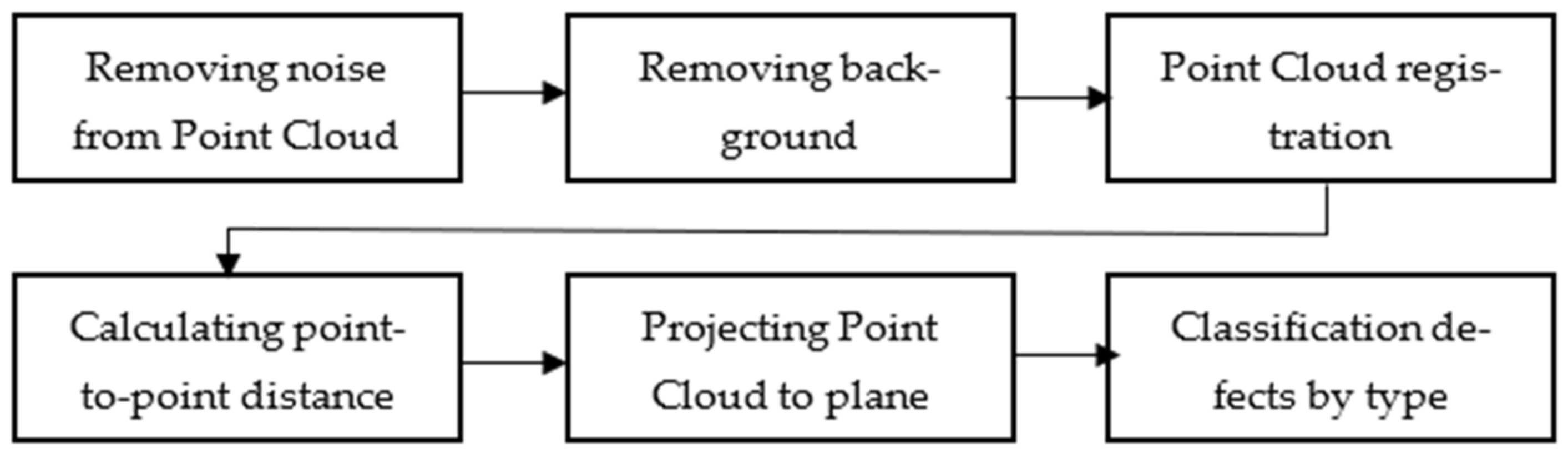
3.3. 3D Point Cloud Classification
3.4. Quality Classes
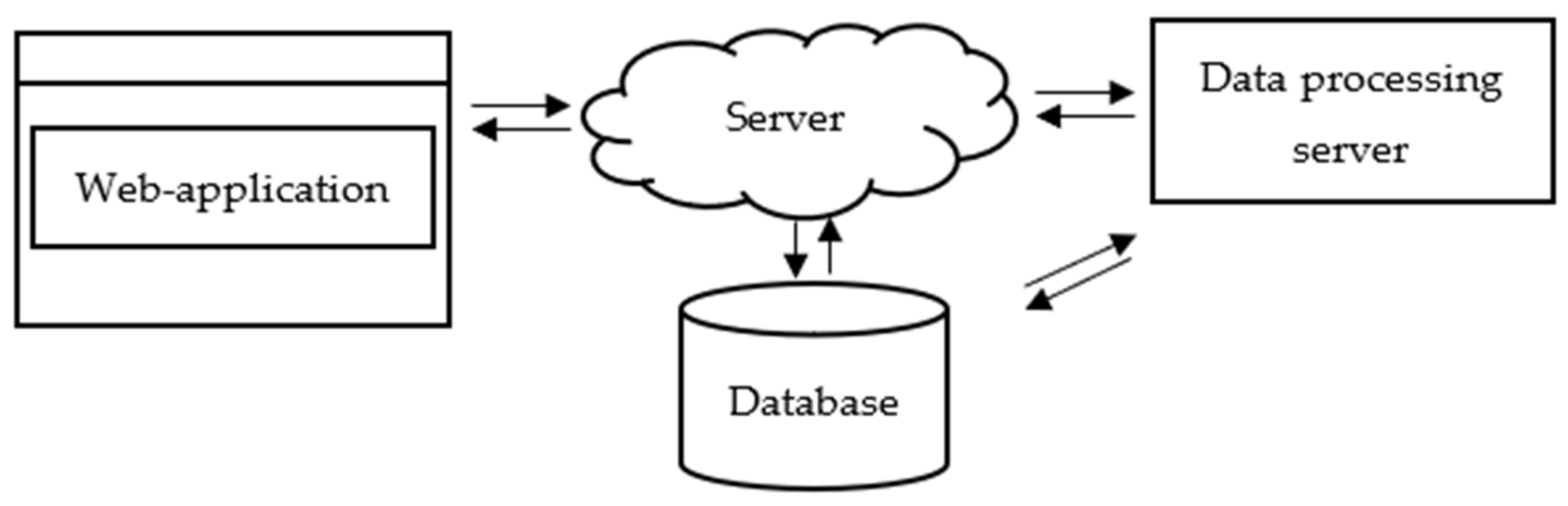
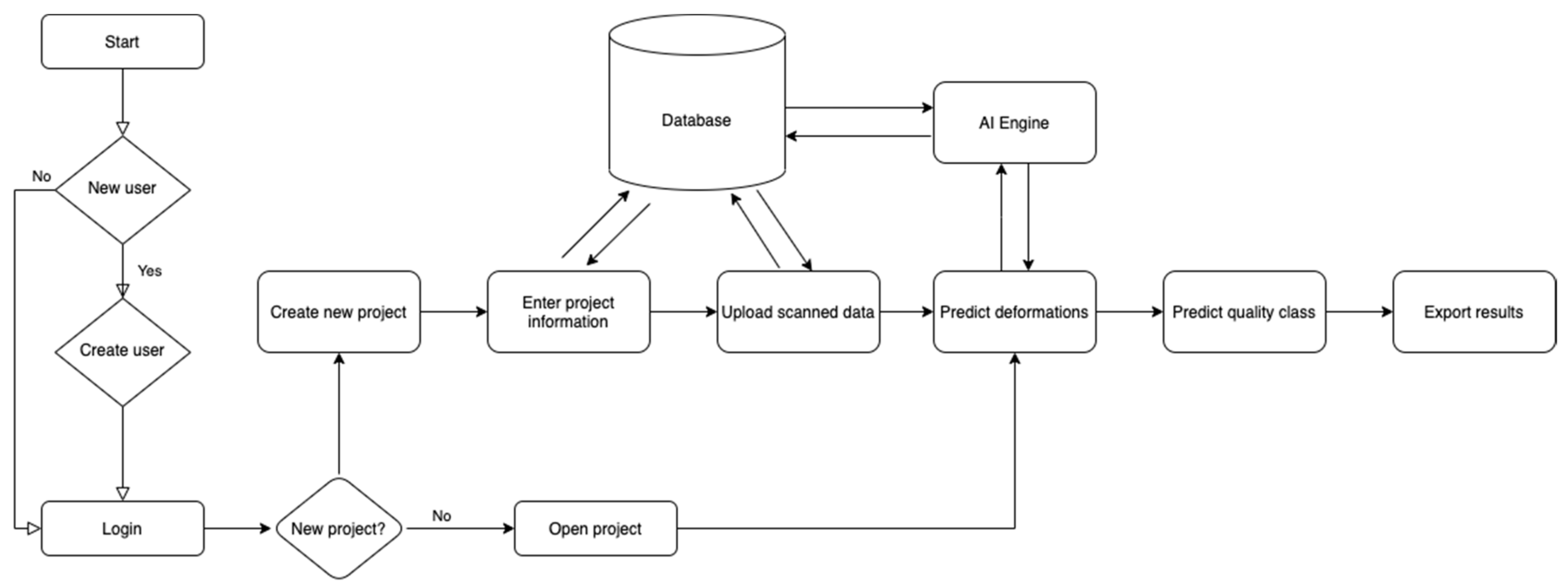
3.5. Quality Inspection System
- ▪
- User authorization flow, which includes creating a new or login user.
- ▪
- Creating a new project, adding project information and scanned data.
- ▪
- Predicting deformation by using AI engine in a server.
- ▪
- Predicting quality class based on deformation values.
- ▪
- Visualizing and exporting results.
4. Results
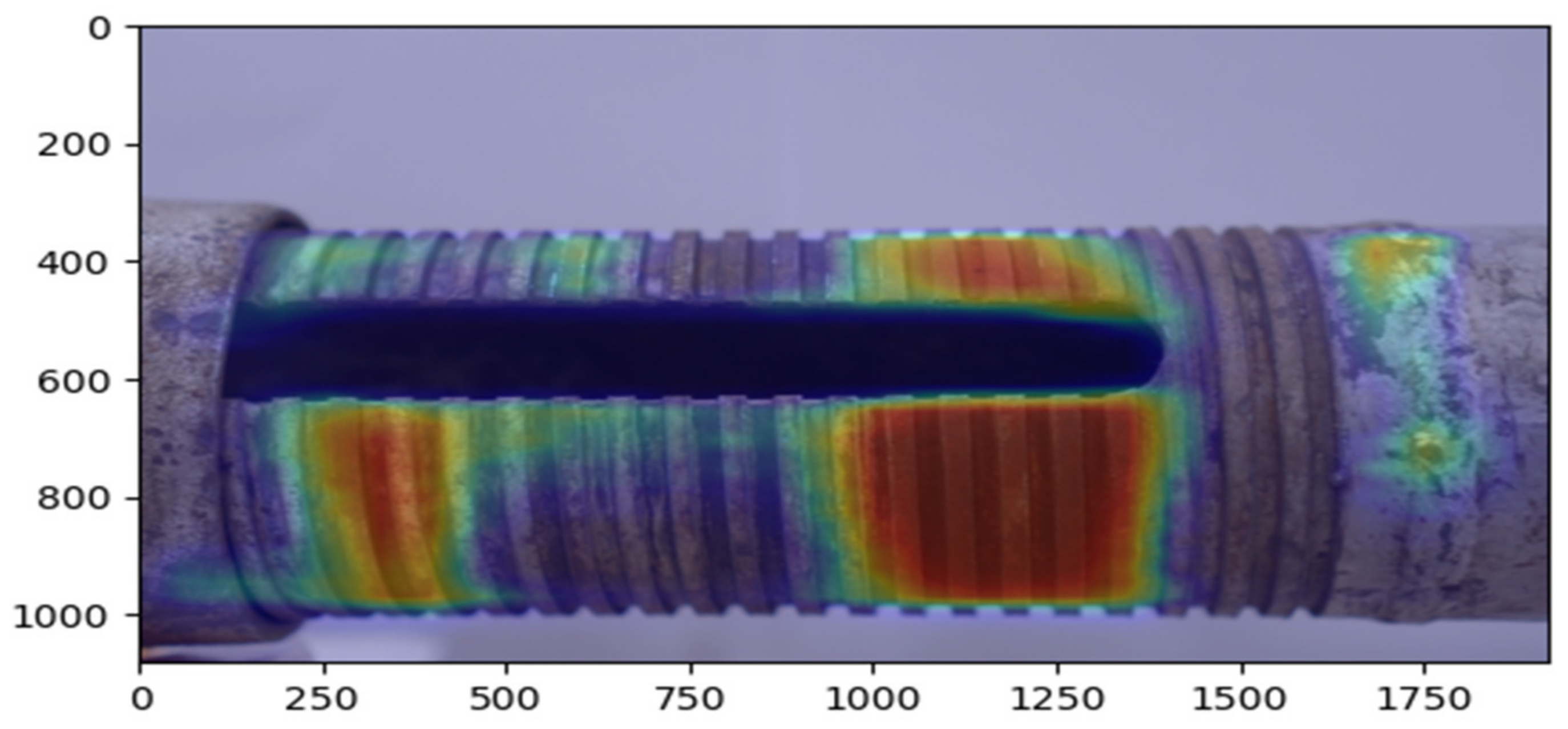
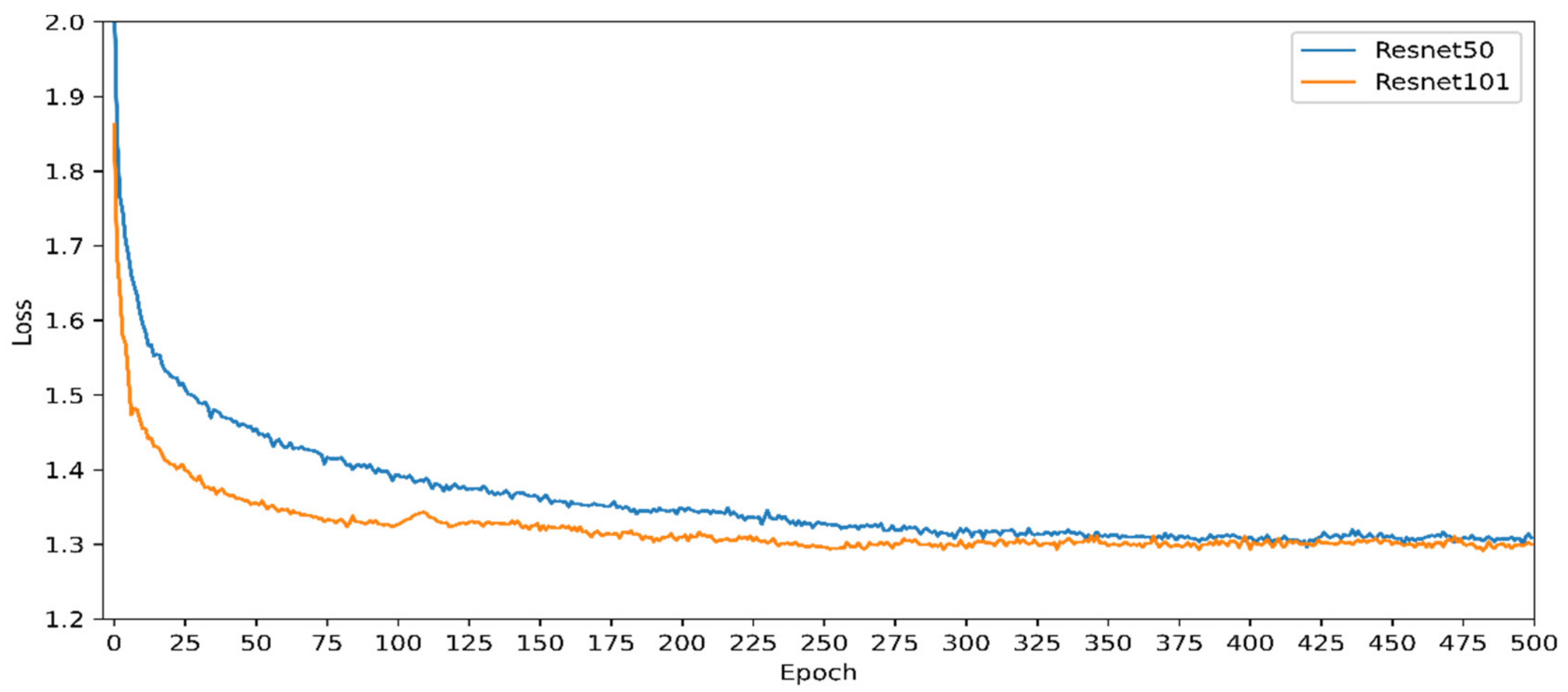
4.1. 2D Image-Based Defect Detection
4.2. 3D Point Cloud-Based Defect Detection
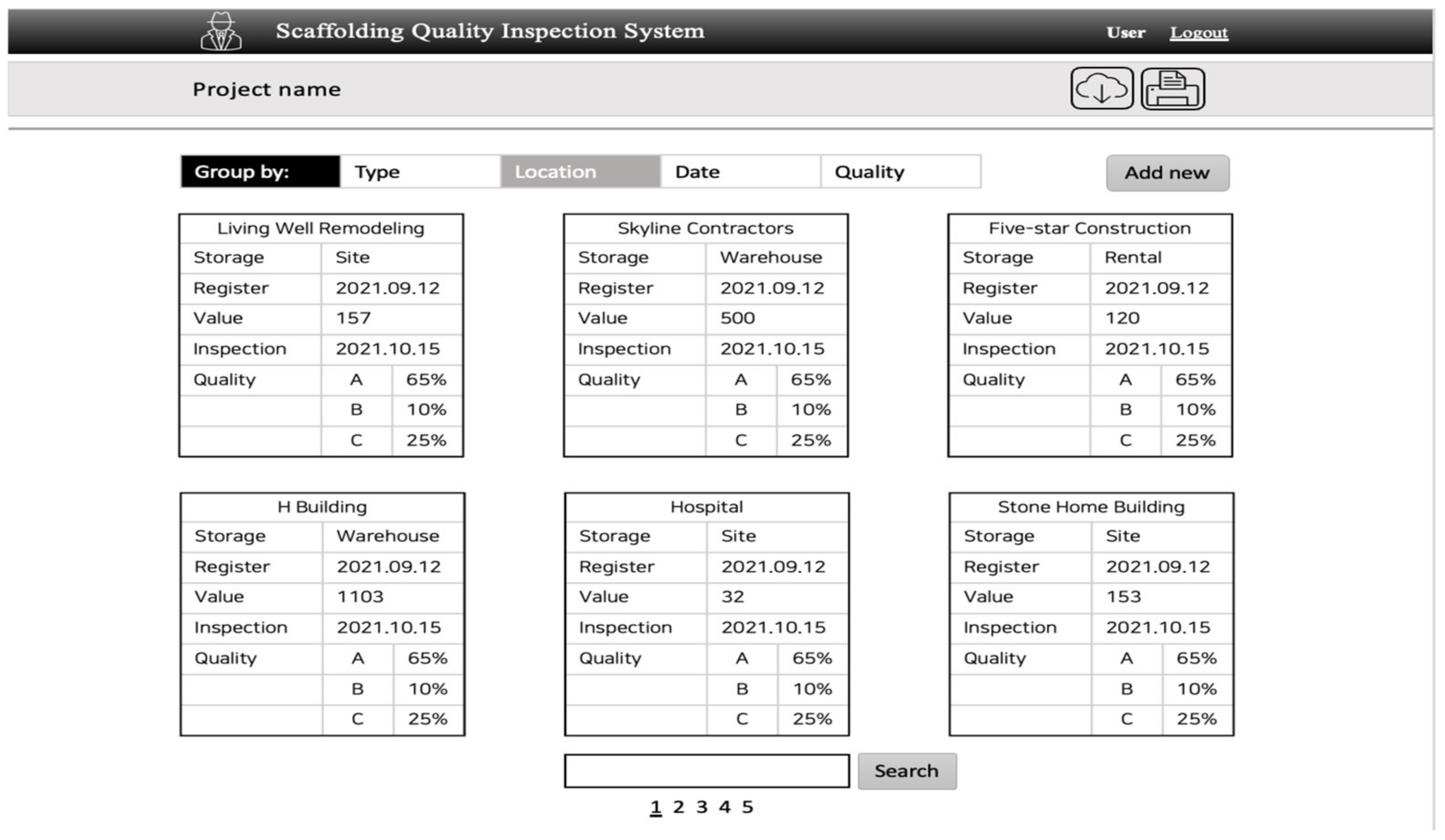
4.3. Quality Inspection System
5. Limitations
- With the same brightness as the background, the object may not have a clear border in the image, or it may be “noisy” with noise, making it impossible to select the contours of deformations.
- Overlapping objects, or the problem of their grouping results in the contour not matching the border of the scaffolding.
- Results vary greatly, depending on image quality, shooting conditions, and scaffolding distance.
- Currently, there are insufficient data on the quantitative indicators of deformations and their effects on the structural integrity of the scaffolding.
- The metrics for model accuracy are based on the assumption that the ground truth in the training dataset with real images is 100% true. However, since deformations have unusual shapes, it is sometimes difficult to determine the exact boundaries of the deformations, which ultimately affects the accuracy of the dataset.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- U.S. Bureau of Labor Statistics. Census of Fatal Occupational Injuries. Available online: https://www.bls.gov/iif/oshcfoi1.htm (accessed on 17 September 2021).
- Analysis of Industrial Accident Status 2019. Available online: http://www.moel.go.kr/index.do (accessed on 17 September 2021).
- Darko, A.; Chan, A.P.C.; Adabre, M.A.; Edwards, D.J.; Hosseini, M.R.; Ameyaw, E.E. Artificial Intelligence in the AEC Industry: Scientometric Analysis and Visualization of Research Activities. Autom. Constr. 2020, 112, 103081. [Google Scholar] [CrossRef]
- Li, H.; Lu, M.; Hsu, S.-C.; Gray, M.; Huang, T. Proactive Behavior-Based Safety Management for Construction Safety Improvement. Saf. Sci. 2015, 75, 107–117. [Google Scholar] [CrossRef]
- Kim, H.; Kim, K.; Kim, H. Vision-Based Object-Centric Safety Assessment Using Fuzzy Inference: Monitoring Struck-By Accidents with Moving Objects. J. Comput. Civ. Eng. 2016, 30, 04015075. [Google Scholar] [CrossRef]
- Xu, S.; Wang, J.; Shou, W.; Ngo, T.; Sadick, A.-M.; Wang, X. Computer Vision Techniques in Construction: A Critical Review. Arch. Comput. Methods Eng. 2021, 28, 3383–3397. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D. Autonomous Concrete Crack Detection Using Deep Fully Convolutional Neural Network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Hashimoto, S. Fast Crack Detection Method for Large-Size Concrete Surface Images Using Percolation-Based Image Processing. Mach. Vis. Appl. 2010, 21, 797–809. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer Vision-Based Concrete Crack Detection Using U-Net Fully Convolutional Networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.P.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-Learning Network. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.P.; Fei, Y.; Liu, Y.; Tao, S.; Chen, C.; Li, J.Q.; Li, B. Deep Learning–Based Fully Automated Pavement Crack Detection on 3D Asphalt Surfaces with an Improved CrackNet. J. Comput. Civ. Eng. 2018, 32, 04018041. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Wu, S.; Zou, S. Automatic Detection Technology of Surface Defects on Plastic Products Based on Machine Vision. In Proceedings of the 2010 International Conference on Mechanic Automation and Control Engineering, Wuhan, China, 26–28 June 2010; pp. 2213–2216. [Google Scholar]
- Tao, X.; Zhang, D.; Ma, W.; Liu, X.; Xu, D. Automatic Metallic Surface Defect Detection and Recognition with Convolutional Neural Networks. Appl. Sci. 2018, 8, 1575. [Google Scholar] [CrossRef]
- Xiong, Z.; Li, Q.; Mao, Q.; Zou, Q. A 3D Laser Profiling System for Rail Surface Defect Detection. Sensors 2017, 17, 1791. [Google Scholar] [CrossRef] [Green Version]
- Aubreton, O.; Bajard, A.; Verney, B.; Truchetet, F. Infrared System for 3D Scanning of Metallic Surfaces. Mach. Vis. Appl. 2013, 24, 1513–1524. [Google Scholar] [CrossRef] [Green Version]
- Hong-Seok, P.; Mani, T.U. Development of an Inspection System for Defect Detection in Pressed Parts Using Laser Scanned Data. Procedia Eng. 2014, 69, 931–936. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Zou, Q.; Lin, H.; Xu, X.; He, L.; Gui, R.; Li, Q. Automatic Pavement Defect Detection Using 3D Laser Profiling Technology. Autom. Constr. 2018, 96, 350–365. [Google Scholar] [CrossRef]
- Madrigal, C.; Branch, J.; Restrepo, A.; Mery, D. A Method for Automatic Surface Inspection Using a Model-Based 3D Descriptor. Sensors 2017, 17, 2262. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Su, Z.; Geng, J.; Yin, Y. Real-Time Detection of Steel Strip Surface Defects Based on Improved YOLO Detection Network. IFAC-PapersOnLine 2018, 51, 76–81. [Google Scholar] [CrossRef]
- Wang, W.; Su, C. Semi-Supervised Semantic Segmentation Network for Surface Crack Detection. Autom. Constr. 2021, 128, 103786. [Google Scholar] [CrossRef]
- Pan, G.; Zheng, Y.; Guo, S.; Lv, Y. Automatic Sewer Pipe Defect Semantic Segmentation Based on Improved U-Net. Autom. Constr. 2020, 119, 103383. [Google Scholar] [CrossRef]
- Feng, W.; Liu, H.; Zhao, D.; Xu, X. Research on Defect Detection Method for High-Reflective-Metal Surface Based on High Dynamic Range Imaging. Optik 2020, 206, 164349. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. jair 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Goyal, M.; Rajpura, P.; Bojinov, H.; Hegde, R. Dataset Augmentation with Synthetic Images Improves Semantic Segmentation. In Proceedings of the Computer Vision, Pattern Recognition, Image Processing, and Graphics, Mandi, India, 16–19 December 2018; Rameshan, R., Arora, C., Dutta Roy, S., Eds.; Springer: Singapore, 2018; pp. 348–359. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2015, arXiv:1411.4038. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Xu, Y.; Li, D.; Xie, Q.; Wu, Q.; Wang, J. Automatic Defect Detection and Segmentation of Tunnel Surface Using Modified Mask R-CNN. Measurement 2021, 178, 109316. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2018, arXiv:1703.06870. [Google Scholar]
- Jadon, S. A Survey of Loss Functions for Semantic Segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Online, 27–29 October 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- KOSHA GUIDE H-36–2011. Technical Guidelines for Safety of Installation and Use of Mobile Scaffold. 2018. Available online: https://www.kosha.or.kr/kosha/data/guidanceDetail.do (accessed on 14 September 2021). (In Korean).





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research | Data Type | Rust | Deformation | Crack | Limitation | |
|---|---|---|---|---|---|---|
| 1 | Park (2014) [17] | Point cloud | X | O | X | Does not detect rust and crack |
| 2 | Xiong (2017) [15] | Point cloud | X | O | O | Does not detect rust |
| 3 | Zhang (2018) [18] | Point cloud | X | O | O | Does not detect rust |
| 4 | Madrigal (2017) [19] | Point cloud | X | O | O | Does not detect rust |
| 5 | Li (2018) [20] | Image | O | X | O | Does not detect deformation and defect size |
| 6 | Wang (2021) [21] | Image | X | X | O | Does not detect deformation and rust |
| 7 | Pan (2020) [22] | Video | X | O | O | Does not detect defects size and rust |
| 8 | Feng (2020) [23] | Image | X | O | O | Does not detect rust and defect size |
| 9 | The proposed methods | Image +Point cloud | O | O | O |
| Model | Layers | |||||
|---|---|---|---|---|---|---|
| ResNet-50 | 7 × 7, 64, stride 2 | 3 × 3 max pool, stride 2 | ||||
| ResNet-101 | ||||||
| Backbone | Train Settings | Dataset | Validation |
|---|---|---|---|
| ResNet-50 | Original | Real images | Real images |
| ResNet-101 | Original | Real images Mixed dataset (real + synthetic images) | |
| ResNet-101 | Dice mask loss | ||
| ResNet-101 | Weighted + Dice loss functions |
| Defect | Quality Classes | ||
|---|---|---|---|
| A | B | C | |
| Deformation | None or slightly | Repairable | Non-repairable |
| Corrosion | None or slightly | Repairable | Non-repairable |
| Crack | None or slightly | Repairable | Non-repairable |
| Defect | Quality Classes | ||||
|---|---|---|---|---|---|
| A | B | C | D | E | |
| Deformation mm2 | <25 | 25–100 | >100 | ||
| Corrosion mm2 | <25 | 25–100 | >100 | ||
| Crack mm | <5 | 5–10 | >10 | ||
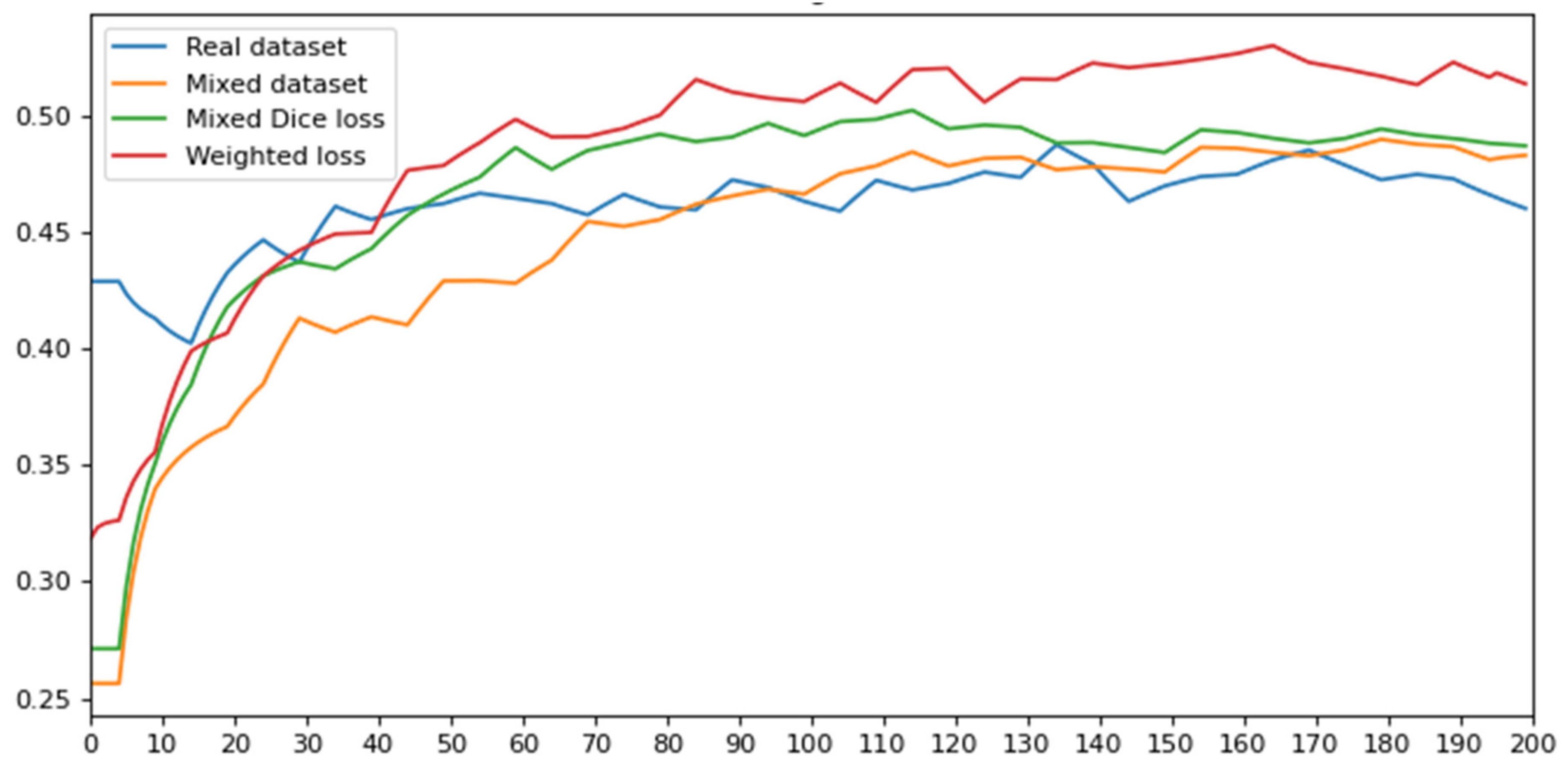
| Mask R-CNN | Mixed Dataset mAP | Real Dataset mAP |
|---|---|---|
| ResNet-50 | 0.46 | 0.45 |
| ResNet-101 | 0.50 | 0.48 |
| ResNet-101 + Dice loss | 0.52 | 0.50 |
| ResNet-101 + Dice loss + Weighted loss functions | 0.59 | 0.55 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, A.; Lee, K.; Lee, S.; Song, J.; Kwon, S.; Chung, S. Synthetic Data and Computer-Vision-Based Automated Quality Inspection System for Reused Scaffolding. Appl. Sci. 2022, 12, 10097. https://doi.org/10.3390/app121910097
Kim A, Lee K, Lee S, Song J, Kwon S, Chung S. Synthetic Data and Computer-Vision-Based Automated Quality Inspection System for Reused Scaffolding. Applied Sciences. 2022; 12(19):10097. https://doi.org/10.3390/app121910097
Chicago/Turabian StyleKim, Alexander, Kyuhyup Lee, Seojoon Lee, Jinwoo Song, Soonwook Kwon, and Suwan Chung. 2022. "Synthetic Data and Computer-Vision-Based Automated Quality Inspection System for Reused Scaffolding" Applied Sciences 12, no. 19: 10097. https://doi.org/10.3390/app121910097
APA StyleKim, A., Lee, K., Lee, S., Song, J., Kwon, S., & Chung, S. (2022). Synthetic Data and Computer-Vision-Based Automated Quality Inspection System for Reused Scaffolding. Applied Sciences, 12(19), 10097. https://doi.org/10.3390/app121910097