
Malware Variants Detection Model Based on MFF–HDBA


Abstract
:1. Introduction
- (1)
- A malware preprocessing method was implemented, based on bilinear interpolation algorithm and data augmentation. In preprocessing, malware after visualization is normalized via bilinear interpolation algorithm, and data augmentation technique was utilized to solve the issue of malware data set imbalance.
- (2)
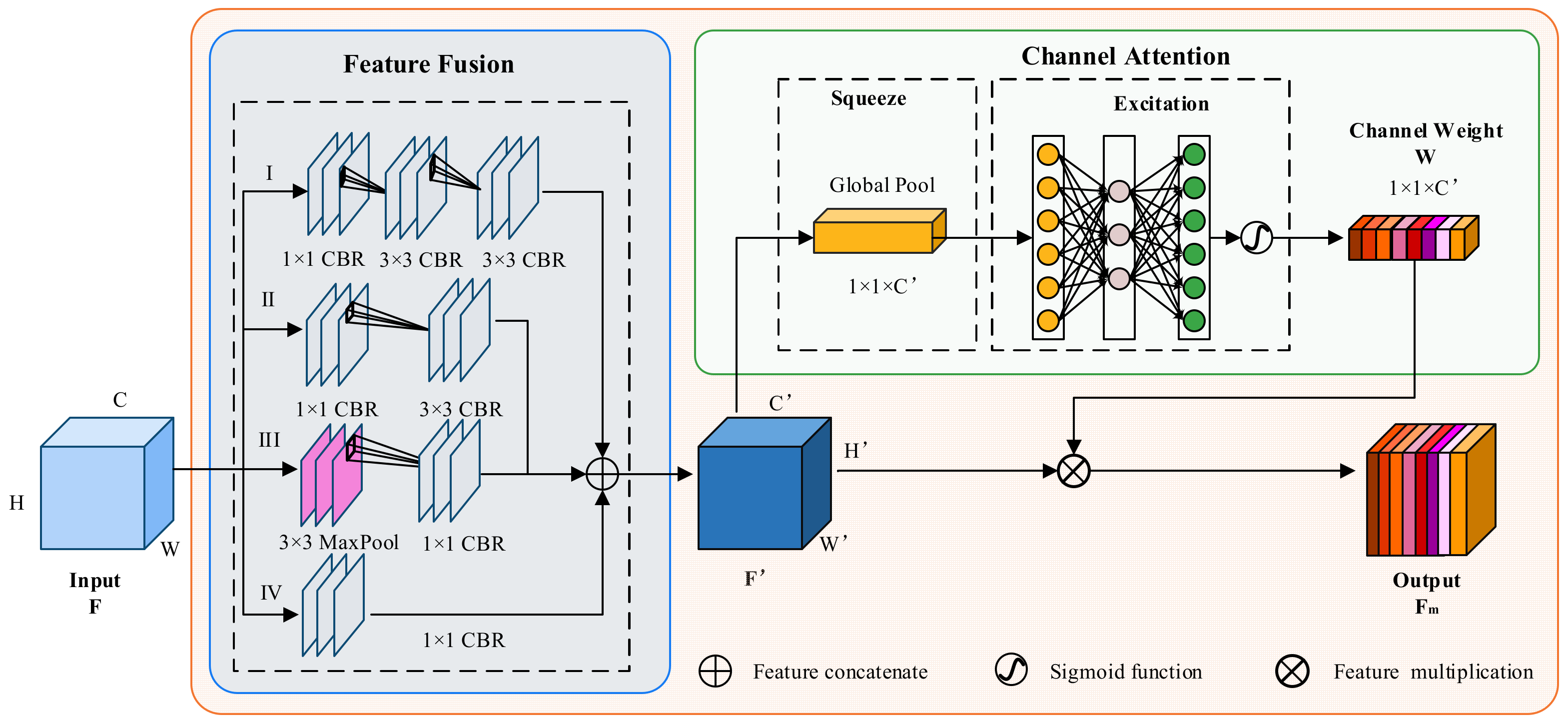
- A novel malware detection method was developed by combining multi-scale feature fusion and channel attention mechanism for more abundant texture information capture and robust feature extraction.
- (3)
- A hyperparameter optimization algorithm was proposed on the basis of the discrete bat algorithm, referred to as HDBA. HDBA was utilized to overcome the disadvantage of the traditional hyperparameter optimization method that lacks a theoretical basis and easily falls into local optima.
- (4)
- The proposed method was evaluated through extensive experimentation. The results indicated that the proposed method not only achieves high classification accuracy, but also a low MTTM (Mean Time to Detect) overhead, which are better than state-of-the-art solutions.
2. Related Research
2.1. Vision-Based Malware Recognition Using Machine Learning
2.2. Vision-Based Malware Recognition Using Deep Learning
3. Methodology
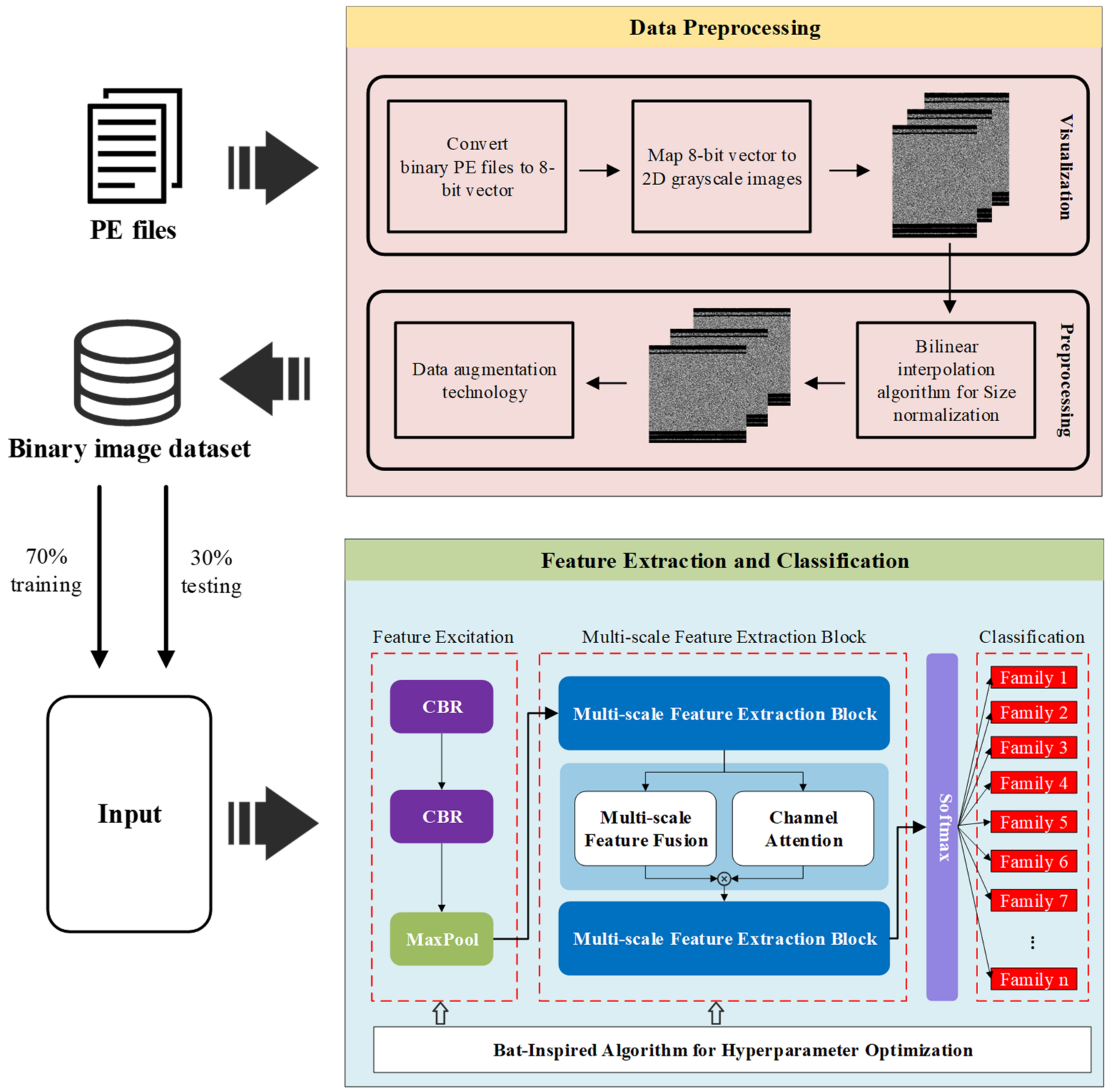
3.1. Data Preprocessing
3.1.1. Malware Visualization
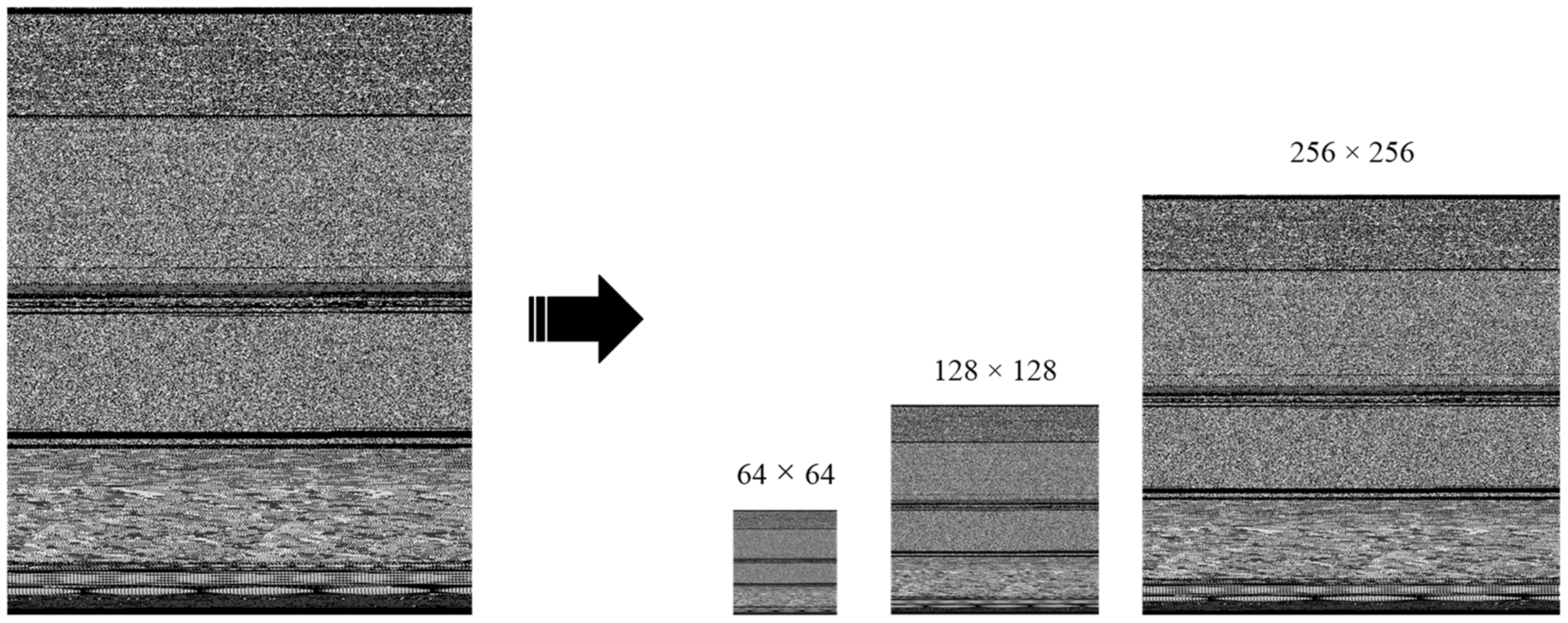
3.1.2. Bilinear Interpolation Algorithm for Size Normalization
3.1.3. Data Augmentation
3.2. Feature Extraction and Classification
3.3. Hyperparameter Optimization Based on Discrete Bat Algorithm
| Algorithm 1: HDBA operation |
| Input: : bat population;
Output: : the best Hyperparameter setting;
|
4. Data Sets and Evaluation Metrics
4.1. Data Sets and Experimental Setting
4.2. Evaluation Metrics
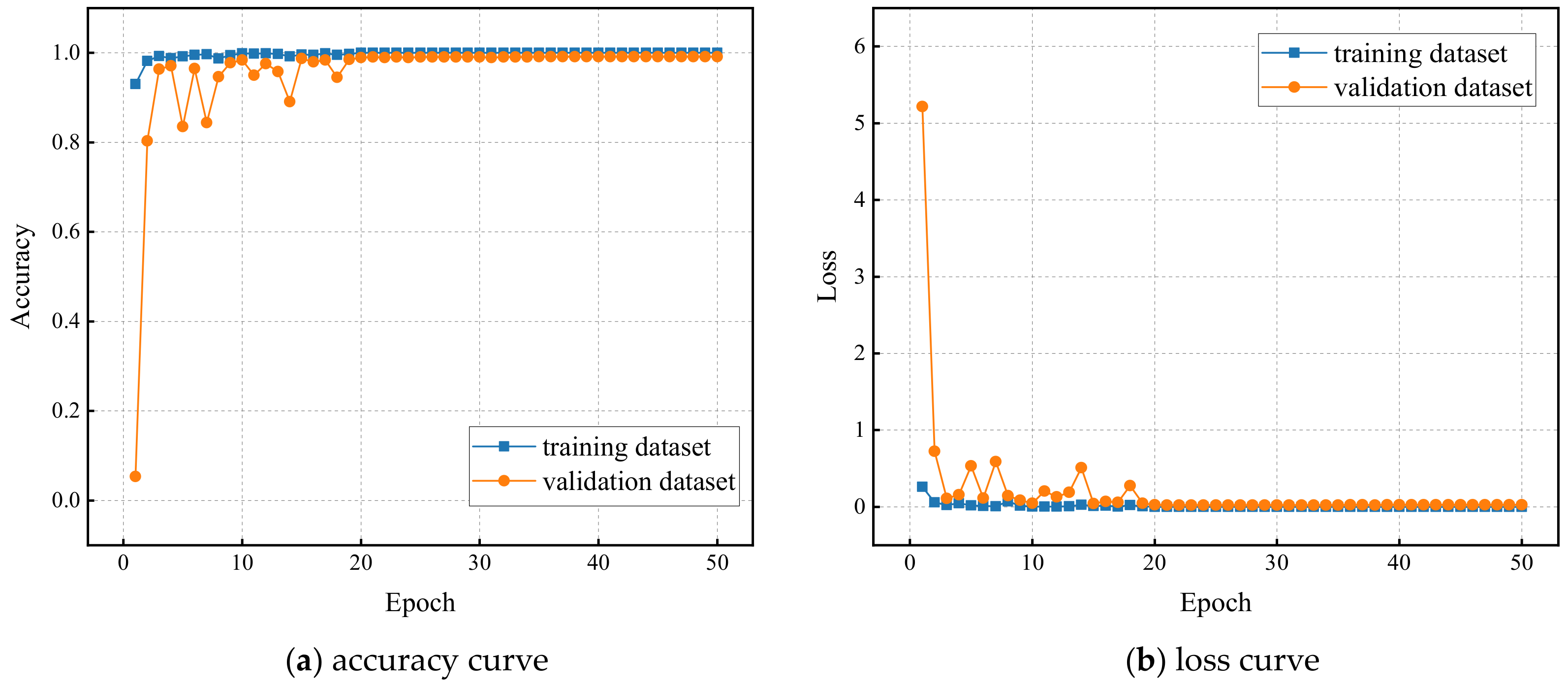
5. Experimental Results and Discussion
- (1)
- Effects of different malware image sizes on model performance;
- (2)
- Comparison of our model performance with advance deep learning frameworks;
- (3)
- Ablation experiments;
- (4)
- Hyperparameter optimization experiment;
- (5)
- Comparative analysis with state-of-the-art solutions;
- (6)
- Validation with the DataCon data set.
5.1. Effects of Different Malware Image Sizes on Model Performance
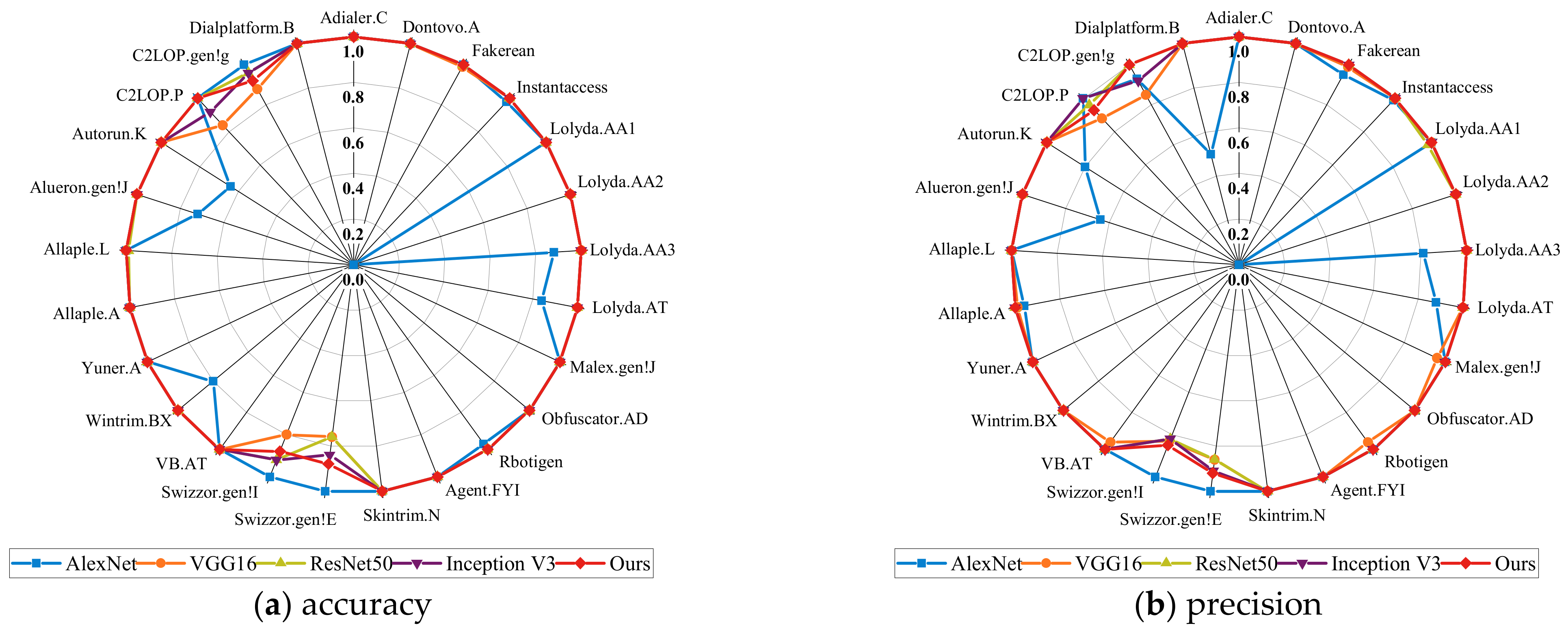
5.2. Comparison of Our Model Performance with Advanced Deep Learning Frameworks
5.3. Ablation Experiments
5.4. Hyperparameter Optimization Experiment
5.5. Comparative Analysis with State-of-the-Art Solutions
5.6. Validation with DataCon Data Set
6. Experimental Results and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Network Security Information and Dynamics Weekly Report. Available online: https://www.cert.org.cn/publish/main/44/index.html (accessed on 13 September 2022).
- Zhang, J.; Qin, Z.; Yin, H.; Ou, L.; Zhang, K. A feature-hybrid malware variants detection using CNN based opcode embedding and BPNN based API embedding. Comput. Secur. 2019, 84, 376–392. [Google Scholar] [CrossRef]
- Zhang, J.; Gao, C.; Gong, L.; Gu, Z.; Man, D.; Yang, W.; Li, W. Malware Detection Based on Multi-level and Dynamic Multi-feature Using Ensemble Learning at Hypervisor. Mob. Networks Appl. 2020, 26, 1668–1685. [Google Scholar] [CrossRef]
- Dai, Y.; Li, H.; Qian, Y.; Lu, X. A malware classification method based on memory dump grayscale image. Digit. Investig. 2018, 27, 30–37. [Google Scholar] [CrossRef]
- Souri, A.; Hosseini, R. A state-of-the-art survey of malware detection approaches using data mining techniques. Hum.-Cent. Comput. Inf. Sci. 2018, 8, 3. [Google Scholar] [CrossRef]
- Aslan, O.; Samet, R. A Comprehensive Review on Malware Detection Approaches. IEEE Access 2020, 8, 6249–6271. [Google Scholar] [CrossRef]
- Daniel, G.; Carles, M.; Jordi, P. The Rise of Machine Learning for Detection and Classification of Malware. J. Netw. Comput. Appl. 2020, 153, 102526. [Google Scholar]
- Le, Q.; Boydell, O.; Mac Namee, B.; Scanlon, M. Deep learning at the shallow end: Malware classification for non-domain experts. Digit. Investig. 2018, 26, S118–S126. [Google Scholar] [CrossRef]
- Samaneh, M.; Ali, A.G. Application of Deep Learning to Cybersecurity: A Survey. Neurocomputing 2019, 347, 149–176. [Google Scholar]
- Ucci, D.; Aniello, L.; Baldoni, R. Survey of machine learning techniques for malware analysis. Comput. Secur. 2019, 81, 123–147. [Google Scholar] [CrossRef]
- Conti, G.; Bratus, S.; Shubina, A.; Sangster, B.; Ragsdale, R.; Supan, M.; Lichtenberg, A.; Perez-Alemany, R. Automated mapping of large binary objects using primitive fragment type classification. Digit. Investig. 2010, 7, S3–S12. [Google Scholar] [CrossRef]
- Nataraj, L.; Yegneswaran, V.; Porras, P.; Zhang, J. A comparative assessment of malware classification using binary texture analysis and dynamic analysis. In Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence, Chicago, IL, USA, 21 October 2011; pp. 21–30. [Google Scholar] [CrossRef]
- Yu, J.; He, Y.; Yan, Q.; Kang, X. SpecView: Malware Spectrum Visualization Framework with Singular Spectrum Transformation. IEEE Trans. Inf. Forensics Secur. 2021, 16, 5093–5107. [Google Scholar] [CrossRef]
- Xiao, M.; Guo, C.; Shen, G.; Cui, Y.; Jiang, C. Image-based malware classification using section distribution information. Comput. Secur. 2021, 110, 102420. [Google Scholar] [CrossRef]
- Wang, S.; Wang, J.; Song, Y.; Li, S. Malicious Code Variant Identification Based on Multiscale Feature Fusion CNNs. Comput. Intell. Neurosci. 2021, 2021, 1070586. [Google Scholar] [CrossRef] [PubMed]
- Nataraj, L.; Karthikeyan, S.; Jacob, G.; Manjunath, B. Malware images: Visualization and automatic classification. In Proceedings of the VizSec ‘11: 2011 International Symposium on Visualization for Cyber Security, Pittsburgh, PA, USA, 20 July 2011; pp. 1–7. [Google Scholar]
- Kabanga, E.K.; Kim, C.H. Malware Images Classification Using Convolutional Neural Network. J. Comput. Commun. 2018, 6, 153–158. [Google Scholar] [CrossRef]
- Liu, Y.-S.; Lai, Y.-K.; Wang, Z.-H.; Yan, H.-B. A New Learning Approach to Malware Classification Using Discriminative Feature Extraction. IEEE Access 2019, 7, 13015–13023. [Google Scholar] [CrossRef]
- Naeem, H.; Guo, B.; Naeem, M.R.; Ullah, F.; Aldabbas, H.; Javed, M.S. Identification of malicious code variants based on image visualization. Comput. Electr. Eng. 2019, 76, 225–237. [Google Scholar] [CrossRef]
- Nataraj, L.; Manjunath, B. SPAM: Signal Processing to Analyze Malware. IEEE Signal Process. Mag. 2016, 33, 105–117. [Google Scholar] [CrossRef]
- Roseline, S.A.; Geetha, S.; Kadry, S.; Nam, Y. Intelligent Vision-Based Malware Detection and Classification Using Deep Random Forest Paradigm. IEEE Access 2020, 8, 206303–206324. [Google Scholar] [CrossRef]
- Yue, S. Imbalanced Malware Images Classification: A CNN based Approach. arXiv 2017, arXiv:1708.08042. [Google Scholar]
- Catal, C.; Gunduz, H.; Ozcan, A. Malware Detection Based on Graph Attention Networks for Intelligent Transportation Systems. Electronics 2021, 10, 2534. [Google Scholar] [CrossRef]
- Gibert, D.; Mateu, C.; Planes, J.; Vicens, R. Using convolutional neural networks for classification of malware represented as images. J. Comput. Virol. Hacking Tech. 2019, 15, 15–28. [Google Scholar] [CrossRef]
- Venkatraman, S.; Alazab, M.; Vinayakumar, R. A hybrid deep learning image-based analysis for effective malware detection. J. Inf. Secur. Appl. 2019, 47, 377–389. [Google Scholar] [CrossRef]
- Zhihua, C.; Lei, D.; Penghong, W.; Xingjuan, C.; Wensheng, Z. Malicious code detection based on CNNs and multi-objective algorithm. J. Parallel Distr. Com. 2019, 129, 50–58. [Google Scholar]
- Danish, V.; Mamoun, A.; Sobia, W.; Babak, S.; Qin, Z. Image-Based malware classification using ensemble of CNN architectures (IMCEC). Comput. Secur. 2020, 92, 101748. [Google Scholar]
- Danish, V.; Mamoun, A.; Sobia, W.; Hamad, N.; Babak, S.; Qin, Z. IMCFN: Image-based malware classification using fine-tuned convolutional neural network architecture. Comput. Netw. 2020, 171, 107138. [Google Scholar]
- Catal, C.; Giray, G.; Tekinerdogan, B. Applications of deep learning for mobile malware detection: A systematic literature review. Neural Comput. Appl. 2022, 34, 1007–1032. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, A.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Wang, C.; Zhao, Z.; Wang, F.; Li, Q. A Novel Malware Detection and Family Classification Scheme for IoT Based on DEAM and DenseNet. Secur. Commun. Networks 2021, 2021, 6658842. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 2261–2269. [Google Scholar]
- Li, Q.; Mi, J.; Li, W.; Wang, J.; Cheng, M. CNN-Based Malware Variants Detection Method for Internet of Things. IEEE Internet Things J. 2021, 8, 16946–16962. [Google Scholar] [CrossRef]
- Cui, Z.; Xue, F.; Cai, X.; Cao, Y.; Wang, G.-G.; Chen, J. Detection of Malicious Code Variants Based on Deep Learning. IEEE Trans. Ind. Inform. 2018, 14, 3187–3196. [Google Scholar] [CrossRef]
- Hemalatha, J.; Roseline, S.; Geetha, S.; Kadry, S.; Damaševičius, R. An Efficient DenseNet-Based Deep Learning Model for Malware Detection. Entropy 2021, 23, 344. [Google Scholar] [CrossRef]
- Bansal, M.; Kumar, M.; Sachdeva, M.; Mittal, A. Transfer learning for image classification using VGG19: Caltech-101 image data set. J. Ambient Intell. Humaniz. Comput. 2021, 1–12. [Google Scholar] [CrossRef]
- Kumar, S.; Janet, B. DTMIC: Deep transfer learning for malware image classification. J. Inf. Secur. Appl. 2022, 64, 103063. [Google Scholar] [CrossRef]
- El-Shafai, W.; Almomani, I.; AlKhayer, A. Visualized Malware Multi-Classification Framework Using Fine-Tuned CNN-Based Transfer Learning Models. Appl. Sci. 2021, 11, 6446. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Xie, J.; Ma, Z.; Lei, J.; Zhang, G.; Xue, J.H.; Tan, Z.H.; Guo, J. Advanced Dropout: A Model-free Methodology for Bayesian Dropout Optimization. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1, 4605–4625. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn Res. 2014, 15, 1929–1958. [Google Scholar]
- DataCon: Multi-Domain Large-Scale Competition Open Data for Security Research. Available online: https://datacon.qianxin.com/opendata (accessed on 13 September 2022).
- Anandhi, V.; Vinod, P.; Menon, V.G. Malware visualization and detection using DenseNets. Pers. Ubiquitous Comput. 2021, 1–17. [Google Scholar] [CrossRef]
- Naeem, H.; Ullah, F.; Naeem, M.R.; Khalid, S.; Vasan, D.; Jabbar, S.; Saeed, S. Malware detection in industrial internet of things based on hybrid image visualization and deep learning model. Ad Hoc Netw. 2020, 105, 102154. [Google Scholar] [CrossRef]
- Xiao, G.; Li, J.; Chen, Y.; Li, K. MalFCS: An effective malware classification framework with automated feature extraction based on deep convolutional neural networks. J. Parallel Distrib. Comput. 2020, 141, 49–58. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual Attention Network for Image Classification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6450–6458. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Vinayakumar, R.; Alazab, M.; Soman, K.P.; Poornachandran, P.; Venkatraman, S. Robust Intelligent Malware Detection Using Deep Learning. IEEE Access 2019, 7, 46717–46738. [Google Scholar] [CrossRef]
- Naeem, H.; Guo, B.; Ullah, F.; Naeem, M.R. A Cross-Platform Malware Variant Classification based on Image Representation. KSII Trans. Internet Inf. Syst. 2019, 13, 3756–3777. [Google Scholar]
- Vinita, V.; Sunil, K.M.; Singh, V.B. Multiclass Malware Classification via First- and Second-Order Texture Statistics. Comput. Secur. 2020, 97, 101895. [Google Scholar]
- Moussas, V.; Andreatos, A. Malware Detection Based on Code Visualization and Two-Level Classification. Information 2021, 12, 118. [Google Scholar] [CrossRef]
- Sudhakar; Kumar, S. MCFT-CNN: Malware classification with fine-tune convolution neural networks using traditional and transfer learning in Internet of Things. Futur. Gener. Comput. Syst. 2021, 125, 334–351. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Approach | Contribution | Description | Disadvantage |
|---|---|---|---|---|
| [18] | Machine learning | Proposed a multi-layer learning framework based on a bag-of-visual-words (BoVW) model to obtain feature descriptors of malware images. | Multi-layer LBP+SIFT+BoVW | Long prediction time |
| [19] | Machine learning | Proposed a malware identification model for characterizing malicious variants, both locally and globally, to achieve a useful classification. | LGMP | Long prediction time (4.27 s) |
| [20] | Machine learning | Explored orthogonal yet complementary methods to analyze malware, motivated by signal and image processing. | SPAM | Low detection accuracy |
| [21] | Machine learning | Proposed a diverse deep forest model for effective malware detection and classification. | CRF+RF+Deep Forest | Poor generalization ability and high memory cost |
| [22] | Deep learning | Proposed a weighted softmax loss for convolutional neural networks on unbalanced malware images classification. | Weighted softmax loss+Vgg-verydeep-19 | Poor feature extraction ability |
| [23] | Deep learning | Proposed a graph attention network (GAN)-based framework to improve the performance of malware detection models. | Node2Vec+GAN | Low detection accuracy |
| [24] | Deep learning | Proposed a novel file, agnostic deep learning system, for classification of malware based on its visualization as grayscale images. | CNN | Poor feature extraction ability |
| [25] | Deep learning | Proposed a new hybrid model for image-based analysis using similarity mining and deep learning architectures to identify and classify obfuscated malware accurately. | CNN+LSTM | High computational overhead |
| [26] | Deep learning | Proposed a method to advance the detection of malicious code using convolutional neural networks and intelligence algorithm. | NSGA-II+CNN | Long training time and high computational overhead |
| [27] | Deep learning | Proposed a novel ensemble convolutional neural networks-based architecture for effective detection of both packed and unpacked malware. | IMCEC | Long prediction time (4.27 s) |
| [28] | Deep learning | Proposed a novel classifier to detect variants of malware families and improve malware detection using CNN-based deep learning architecture. | IMCFN | High computational overhead |
| Method | Setting | Method | Setting |
|---|---|---|---|
| rescale | 1/255 | shear range | 0.0 |
| width shift | 0.0 | zoom range | 0.0 |
| height shift | 0.0 | horizontal flip | false |
| rotation range | 0.0 | fill mode | none |
| Family | Samples |
|---|---|
| Mining | 15,759 |
| Non-mining | 7896 |
| Malware Type | Family Name | No. | Samples |
|---|---|---|---|
| Worm | Allaple.A | 3 | 2824 |
| Allaple.L | 4 | 1491 | |
| VB.AT | 23 | 383 | |
| Yuner.A | 25 | 775 | |
| Worm: AutoIT | Autorun.K | 6 | 81 |
| Trojan | Alueron.gen!J | 5 | 173 |
| C2LOP.gen!g | 7 | 175 | |
| C2LOP.P | 8 | 121 | |
| Malex.gen!J | 17 | 111 | |
| Skintrim.N | 20 | 55 | |
| Dialer | Adialer.C | 1 | 97 |
| Dialplatform.B | 9 | 152 | |
| Instantaccess | 12 | 356 | |
| PWS | Lolyda.AA1 | 13 | 153 |
| Lolyda.AA2 | 14 | 159 | |
| Lolyda.AA3 | 15 | 98 | |
| Lolyda.AT | 16 | 134 | |
| Trojan Downloader | Dontovo.A | 10 | 137 |
| Obfuscator.AD | 18 | 117 | |
| Swizzor.gen!E | 21 | 103 | |
| Swizzor.gen!I | 22 | 107 | |
| Wintrim.BX | 24 | 72 | |
| Rogue | Fakerean | 11 | 306 |
| Backdoor | Agent.FYI | 2 | 91 |
| Rbot!gen | 19 | 133 |
| Input Size | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | Parameters (M) |
|---|---|---|---|---|---|
| 32 × 32 | 84.28 | 83.44 | 84.27 | 82.82 | 0.31 |
| 64 × 64 | 94.22 | 93.08 | 94.22 | 93.26 | 0.35 |
| 128 × 128 | 98.61 | 98.61 | 98.60 | 98.60 | 0.50 |
| 256 × 256 | 99.36 | 99.39 | 99.36 | 99.36 | 1.11 |
| 512 × 512 | 99.04 | 99.18 | 99.04 | 99.06 | 3.58 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| AlexNet8 | 94.12 | 92.77 | 94.11 | 93.19 |
| VGG16 | 97.11 | 97.00 | 97.11 | 97.03 |
| ResNet50 | 97.54 | 97.57 | 97.54 | 97.53 |
| Inception V3 | 98.71 | 98.72 | 98.71 | 98.71 |
| Our model | 99.36 | 99.39 | 99.36 | 99.36 |
| Model | AlexNet | VGG16 | ResNet50 | Inception V3 | Our Model |
|---|---|---|---|---|---|
| Parameters (M) | 362.0 | 134.4 | 23.6 | 21.9 | 1.11 |
| MTTD | 28.28 | 20.84 | 19.61 | 29.18 | 9.63 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| CNN | 96.47 | 96.53 | 96.47 | 96.46 |
| CNN + Channel Attention | 97.86 | 97.85 | 97.86 | 97.77 |
| Multi-scale Feature Fusion | 98.72 | 98.86 | 98.72 | 98.73 |
| Multi-scale Feature Fusion + Channel Attention | 99.36 | 99.39 | 99.36 | 99.36 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| No optimization | 98.82 | 98.86 | 98.82 | 98.84 |
| Manual optimization | 99.04 | 99.18 | 99.04 | 99.05 |
| HDBA | 99.36 | 99.39 | 99.36 | 99.36 |
| Methods | Year | Description | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|---|
| Ref [16] | 2011 | GIST + KNN | 97.18 | - | - | - |
| Ref [20] | 2016 | SPAM | 97.40 | - | - | - |
| Ref [36] | 2018 | DRBA + CNN | 94.50 | 96.60 | 88.40 | - |
| Ref [19] | 2019 | LGMP + KNN | 98.40 | - | 98.20 | 97.1 |
| Ref [26] | 2019 | NSGAII + CNN | 97.60 | 97.60 | 88.40 | - |
| Ref [52] | 2019 | CNN + LSTM | 96.30 | 96.30 | 96.20 | 96.20 |
| Ref [25] | 2019 | CNN + BiGRU | 96.30 | 91.80 | 91.50 | 91.60 |
| Ref [53] | 2019 | CSGM + KNN | 98.40 | - | 98.20 | 97.10 |
| Ref [54] | 2020 | MxN + GLCM | 98.58 | 98.04 | 98.06 | 98.05 |
| Ref [21] | 2020 | Sliding Window Scanning + RF | 98.65 | 98.86 | 98.63 | 98.74 |
| Ref [46] | 2020 | DCNN | 98.79 | 98.79 | 98.47 | 98.46 |
| Ref [28] | 2020 | IMCFN | 98.82 | 98.85 | 98.81 | 98.75 |
| Ref [45] | 2021 | DenseNet201 | 98.97 | - | - | 98.88 |
| Ref [33] | 2021 | DEAM + Densenet | 98.50 | 96.90 | 96.60 | 96.70 |
| Ref [55] | 2021 | Two-level ANN | 99.13 | - | - | - |
| Ref [56] | 2021 | MCFT-CNN | 99.19 | 97.72 | 97.76 | 97.68 |
| Ref [39] | 2022 | DTMIC | 98.93 | 99.00 | 99.00 | 99.00 |
| Ours | 2022 | Multi-scale Feature Fusion + Channel Attention + HDBA | 99.36 | 99.39 | 99.36 | 99.36 |
| Dataset | Our Model | No HDBA | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | |
| DataCon dataset | 96.64 | 96.63 | 96.64 | 96.62 | 95.20 | 95.23 | 95.20 | 95.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Wang, J.; Song, Y.; Li, S.; Huang, W. Malware Variants Detection Model Based on MFF–HDBA. Appl. Sci. 2022, 12, 9593. https://doi.org/10.3390/app12199593
Wang S, Wang J, Song Y, Li S, Huang W. Malware Variants Detection Model Based on MFF–HDBA. Applied Sciences. 2022; 12(19):9593. https://doi.org/10.3390/app12199593
Chicago/Turabian StyleWang, Shuo, Jian Wang, Yafei Song, Sicong Li, and Wei Huang. 2022. "Malware Variants Detection Model Based on MFF–HDBA" Applied Sciences 12, no. 19: 9593. https://doi.org/10.3390/app12199593
APA StyleWang, S., Wang, J., Song, Y., Li, S., & Huang, W. (2022). Malware Variants Detection Model Based on MFF–HDBA. Applied Sciences, 12(19), 9593. https://doi.org/10.3390/app12199593