

AI-Based Prediction of Myocardial Infarction Risk as an Element of Preventive Medicine




Abstract
:Featured Application
Abstract
1. Introduction
- derived from damaged heart muscle tissues, including cardiac troponin.
- released from tissues after myocardial infarction as a result of systemic reactions.
- existing in the blood circulation before the MI event [4].
1.1. Literature Review
- rapid assessment of cardiac function.
- the ability to detect small changes in the myocardium.
- the combination of anatomical and functional assessments of coronary artery stenosis using a single method which was previously not possible in a non-invasive manner.
1.2. Aim of the Study
1.3. Main Contributions
2. Materials and Methods
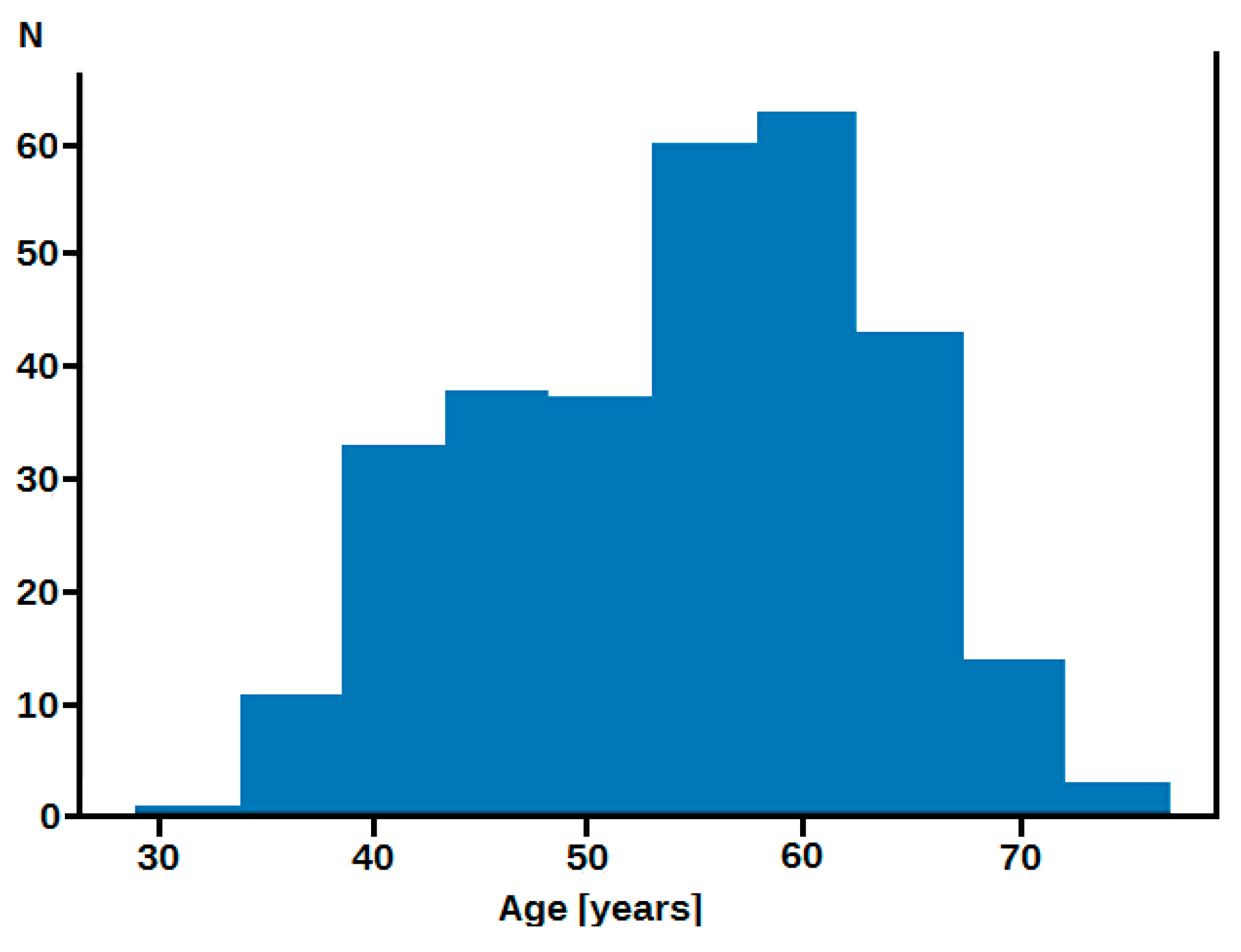
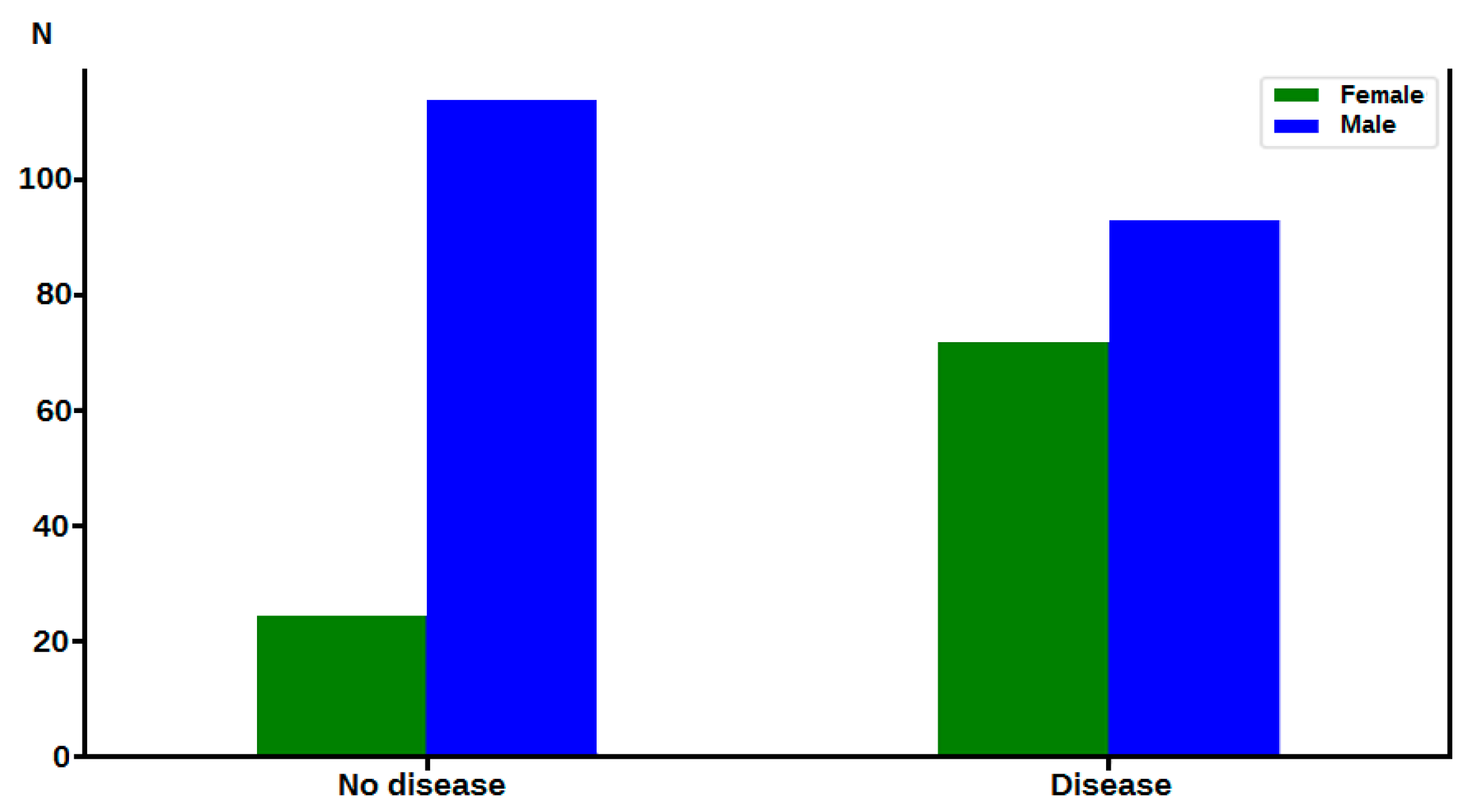
2.1. Material
2.2. Methods
- Pandas: version 1.2.4 (https://pandas.pydata.org, accessed on 1 June 2022), New BSD License [11].
- NumPy: 1.20.3 (https://numpy.org, accessed on 1 June 2022), BSD license [12].
- Matplotlib: version 3.4.2 (https://matplotlib.org, accessed on 1 June 2022), Matplotlib license [13].
- Scikit-Learn: version 0.24.2, New BSD License, containing tools for predictive data analysis [14].
2.3. Computational Models
2.3.1. Logistic Regression
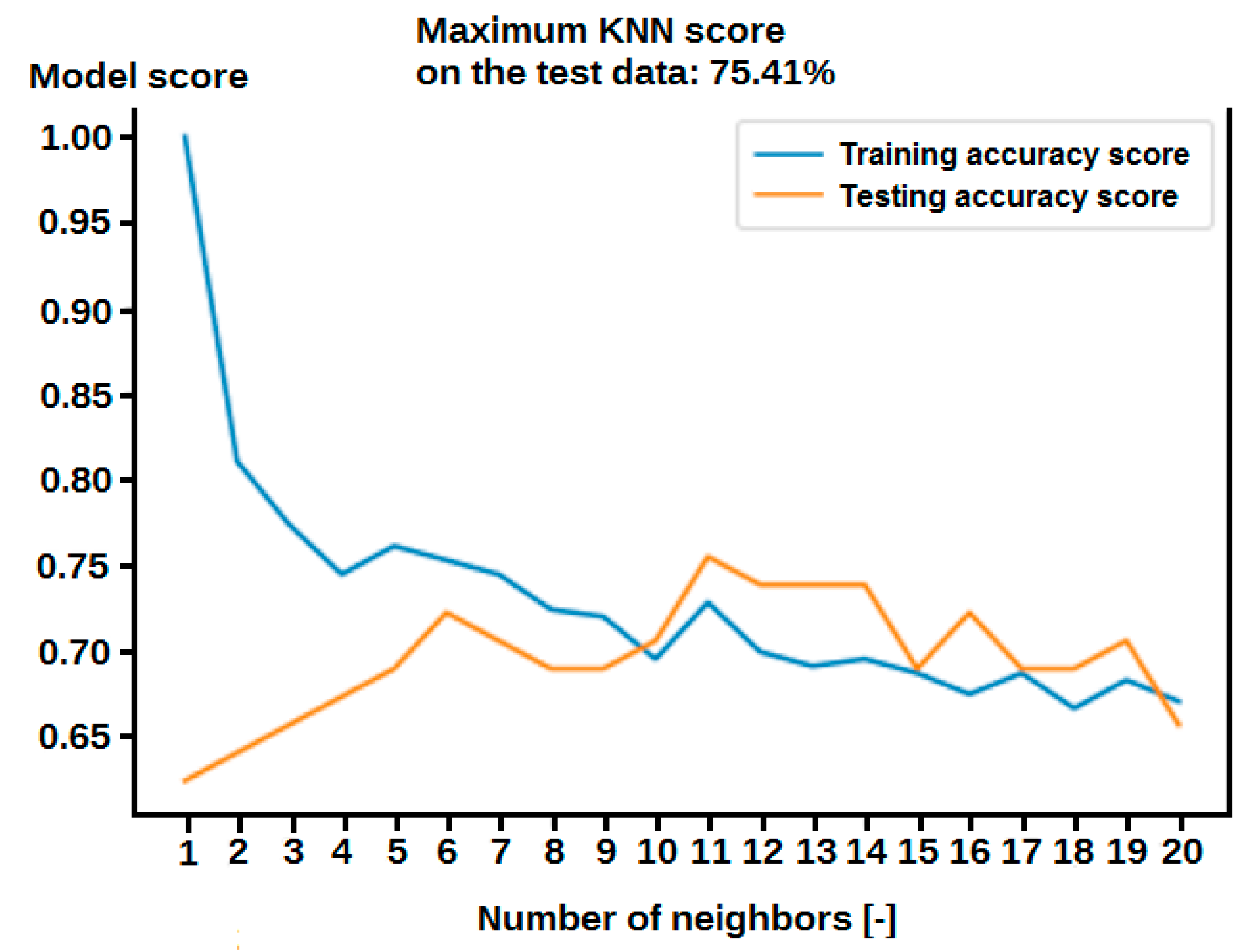
2.3.2. K-Nearest Neighbours
2.3.3. Random Forest Classifiers
2.3.4. Linear SVC
- generates hyperplanes that best segregate the classes.
- selects the hyperplane with the maximum segregation from both nearest data points.
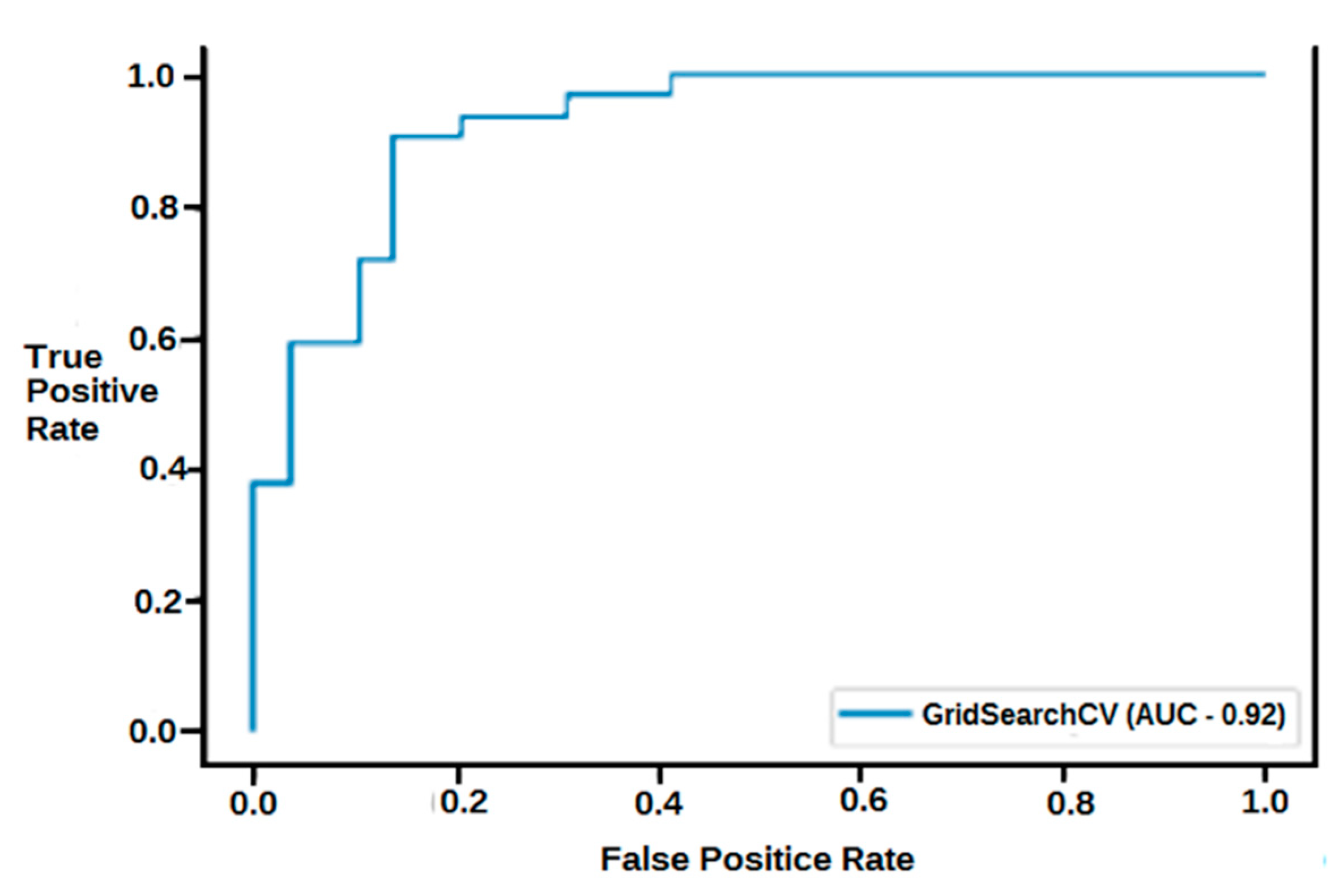
2.3.5. Receiver Operating Characteristic (ROC) Curve
- a false positive test occurs when a person has a positive result but does not actually have the disease.
- a false negative test occurs when a person has a negative result, suggesting that they are healthy, when in fact they have a disease.
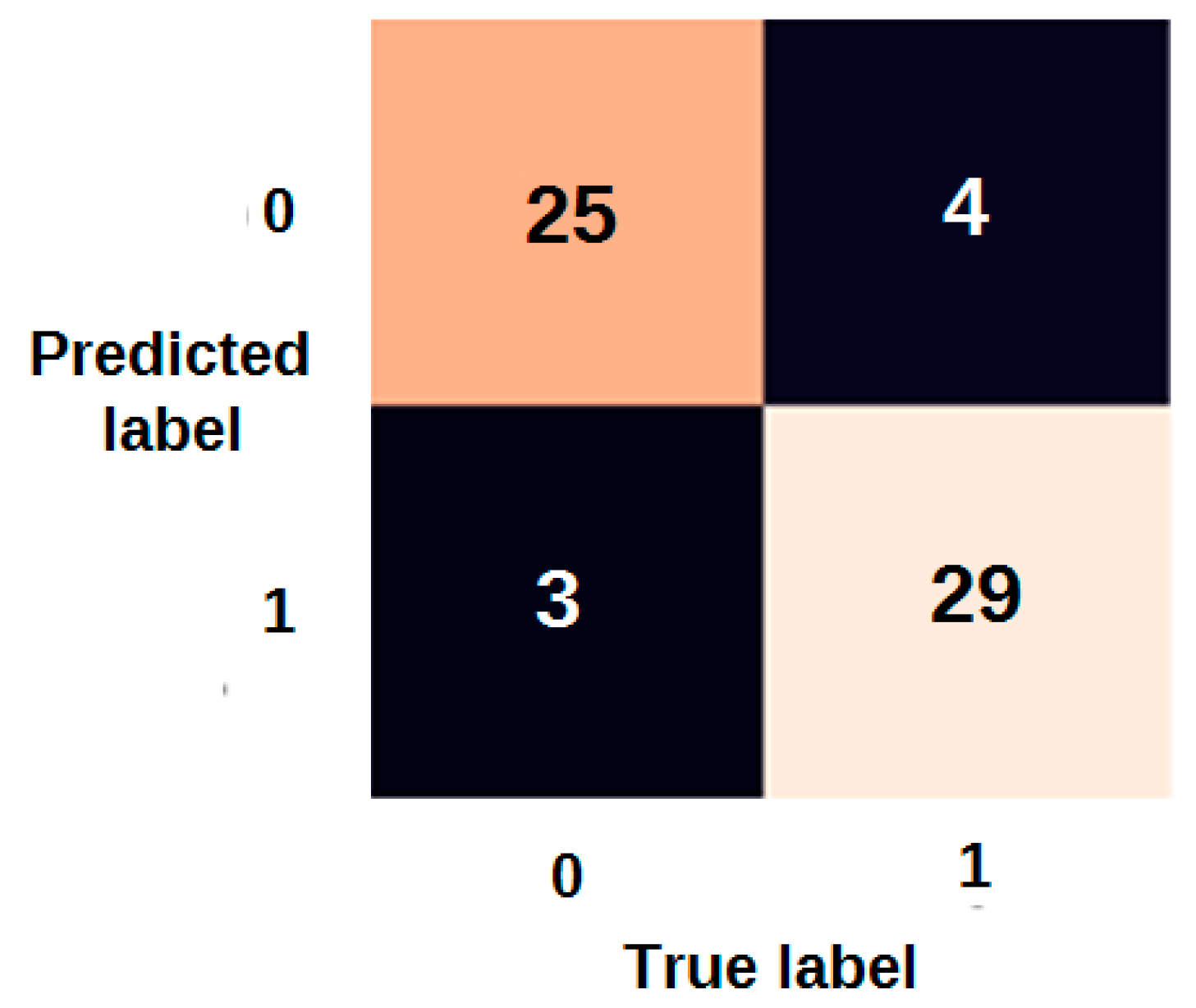
2.3.6. Confusion Matrix
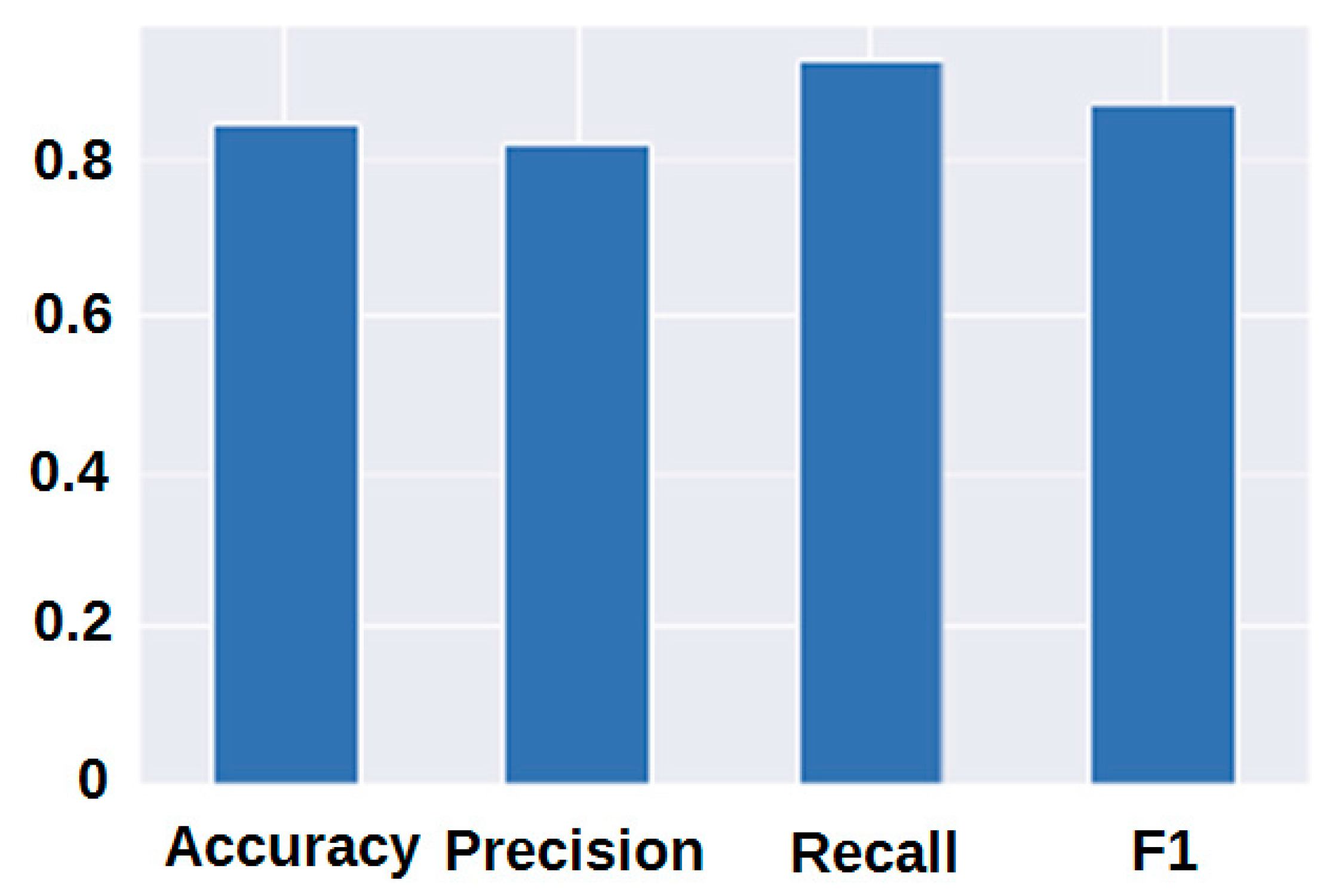
2.3.7. Classification Report
- precision or positive predictive value (PPV): the ratio of true positives in relation to the total number of samples.
- recall or true positive rate (TPR): the ratio of true positives to the total number of true positives and false negatives.
- F1 score: combination of precision and recall.
- Accuracy.
3. Results
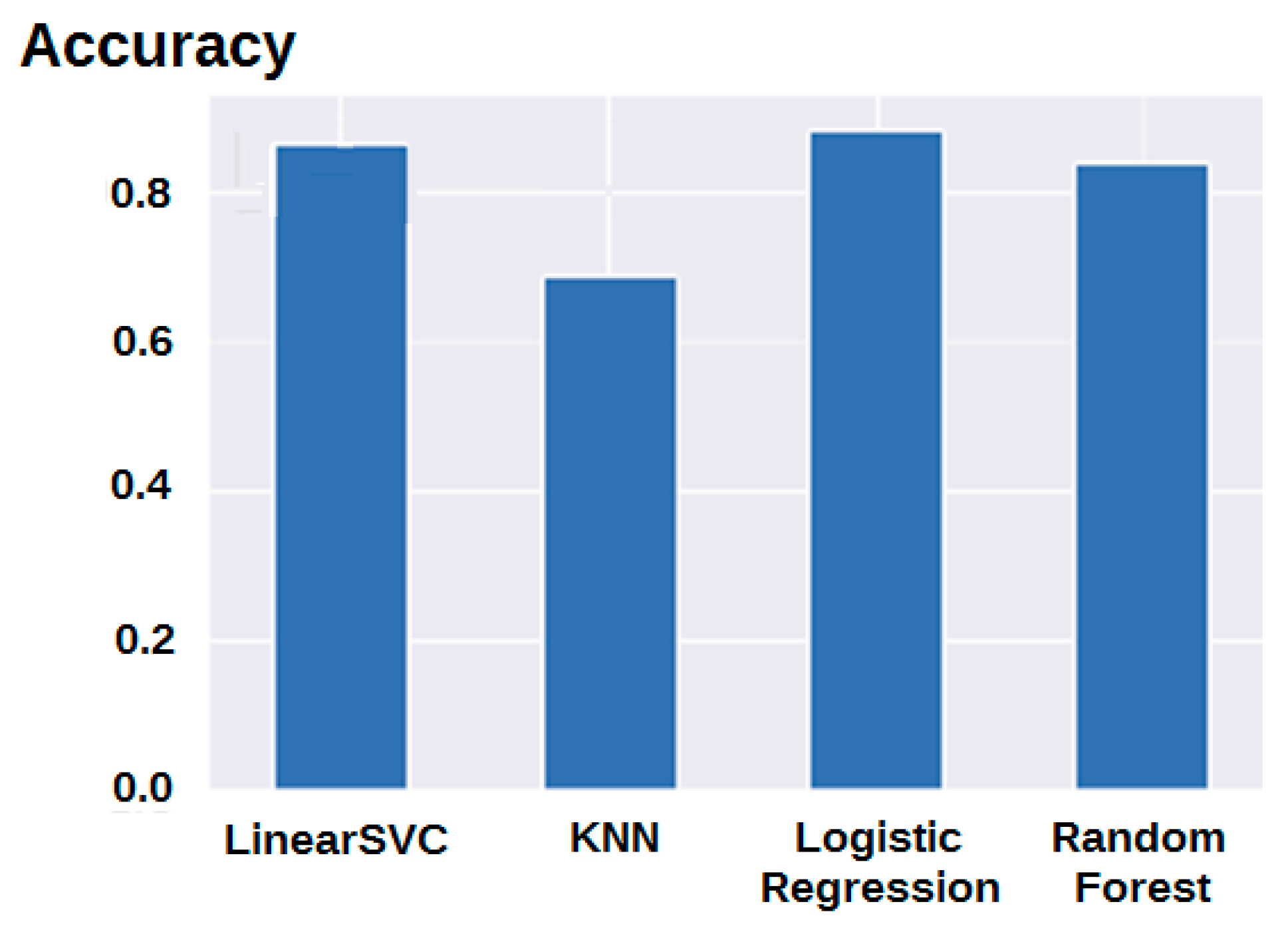
3.1. Modelling Results
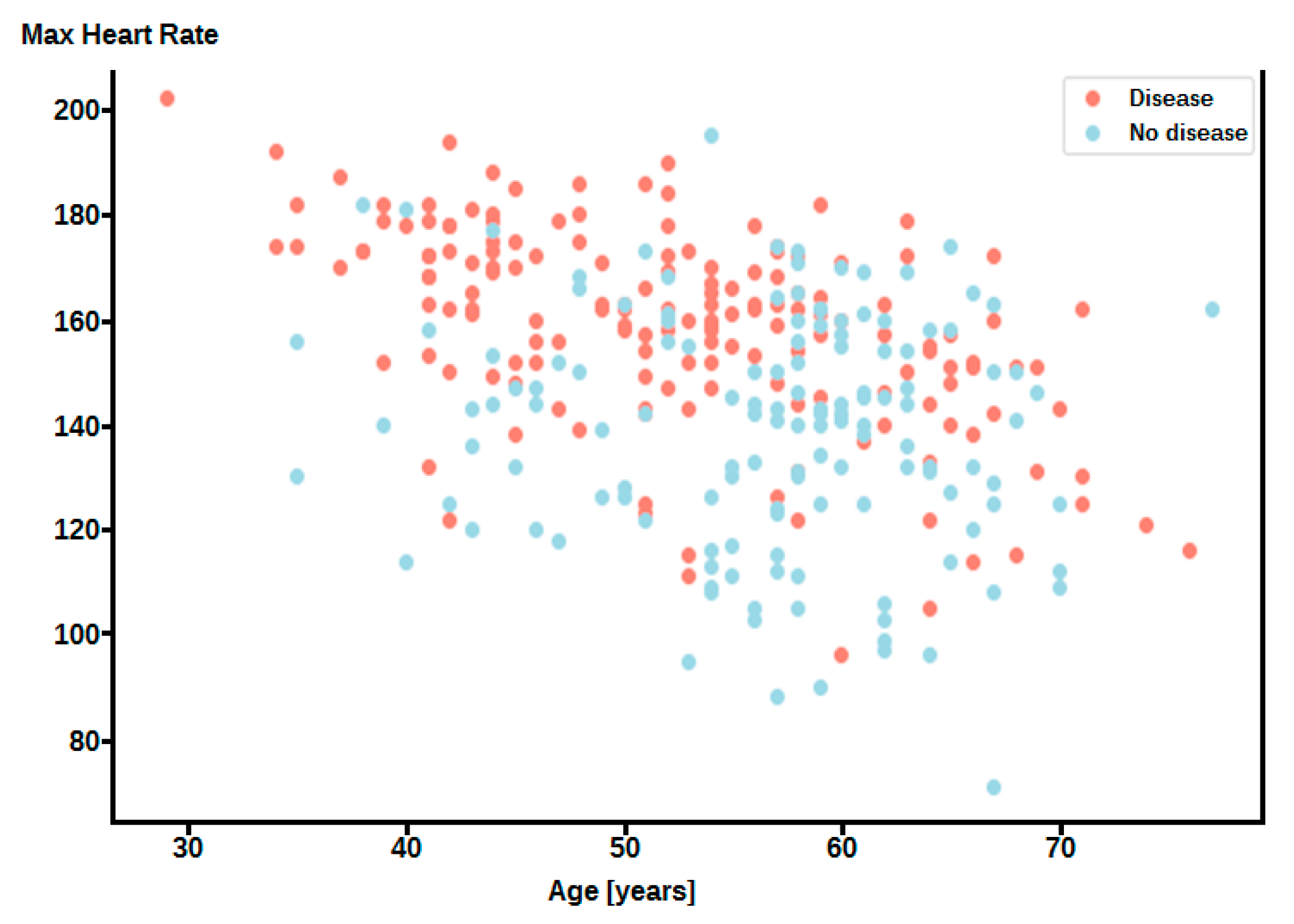
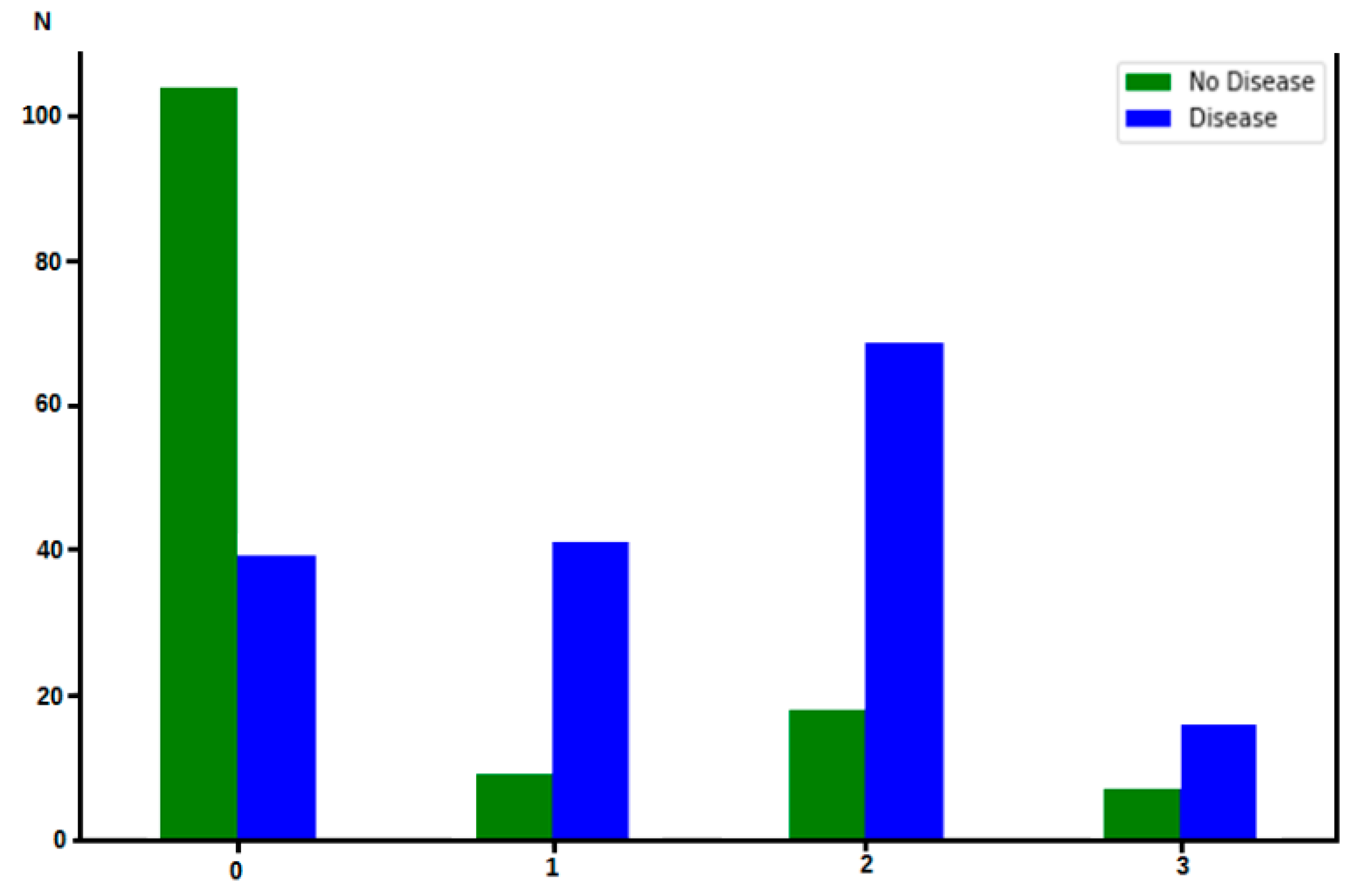
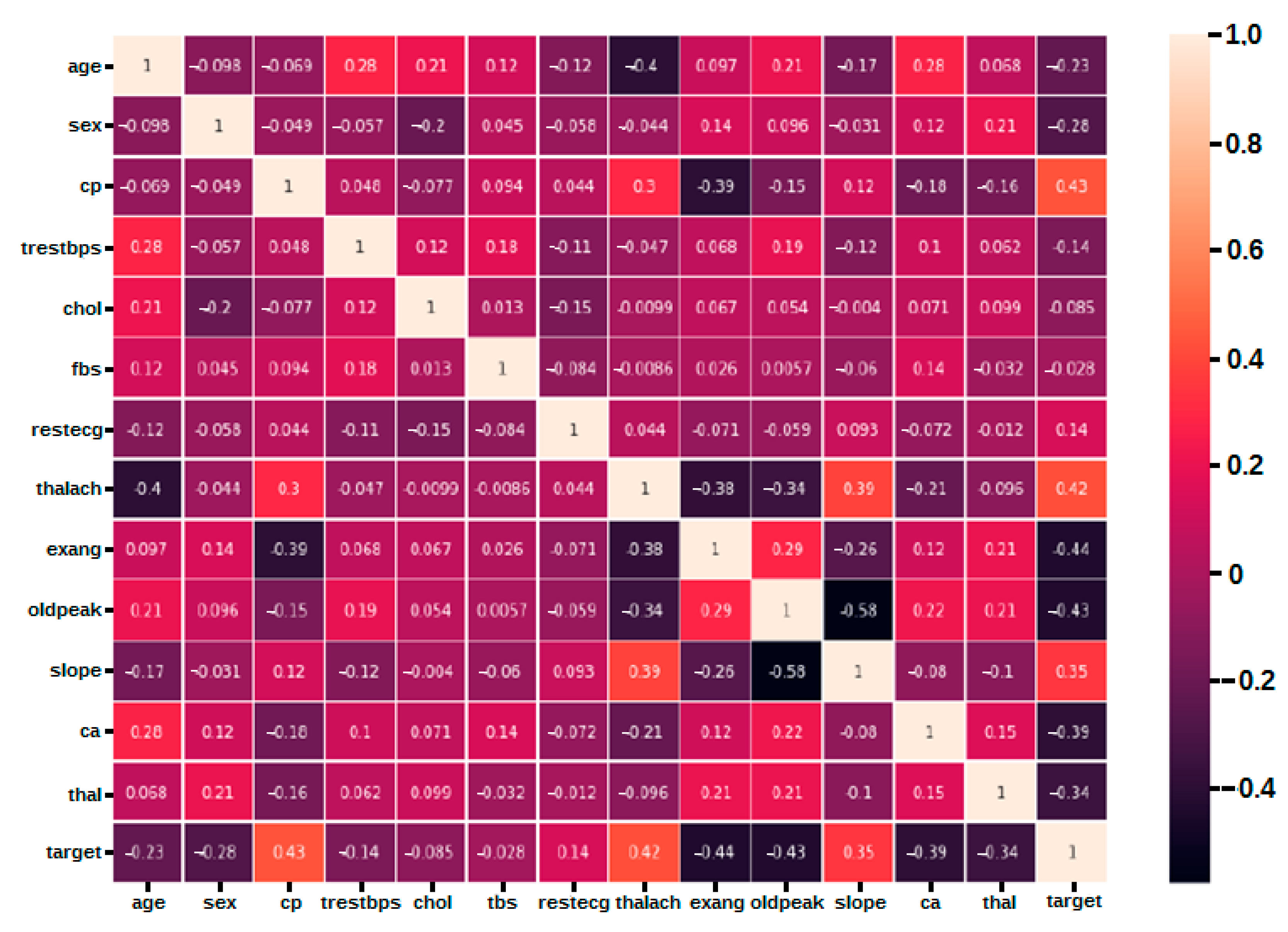
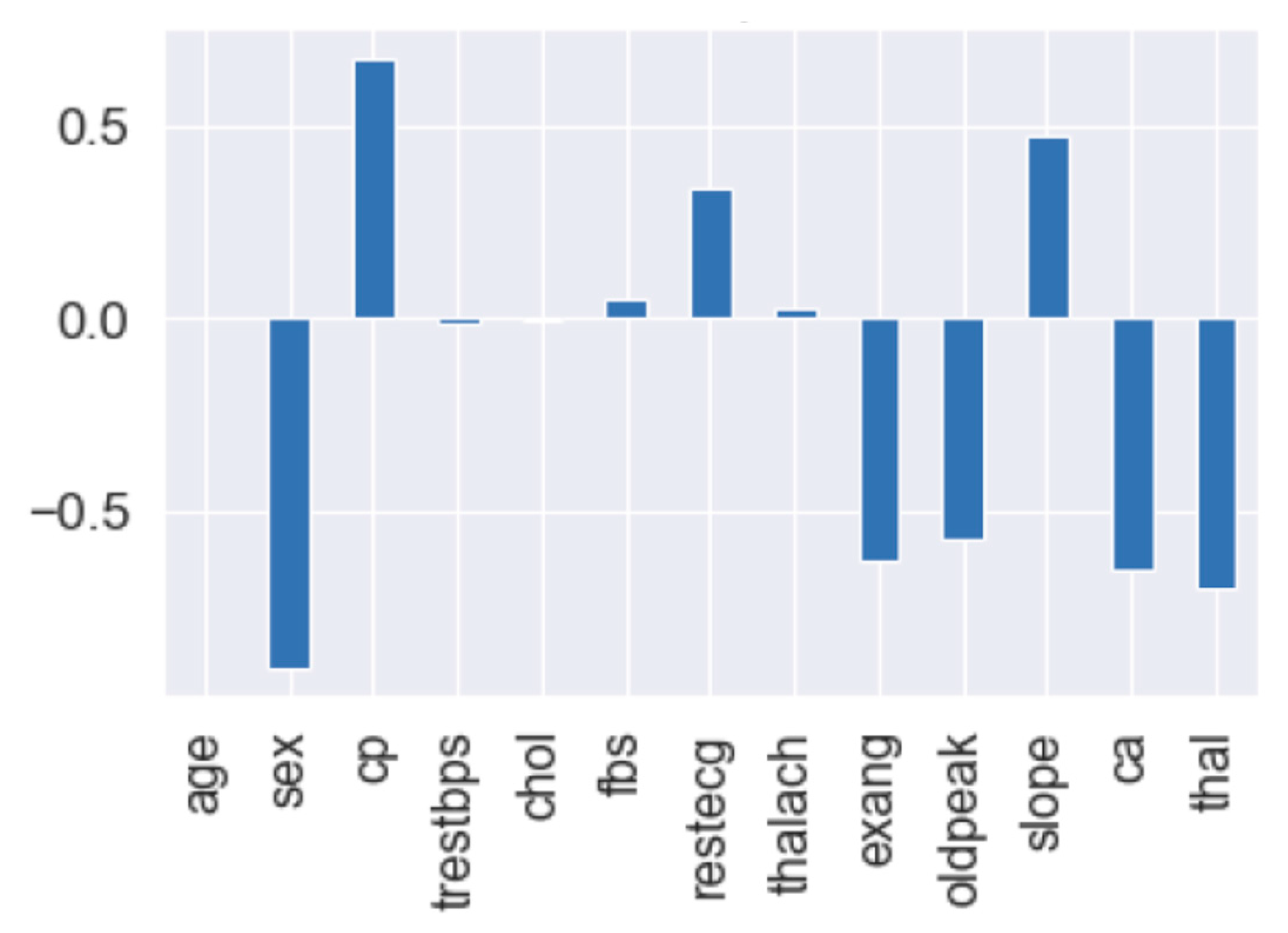
3.2. Feature Importance
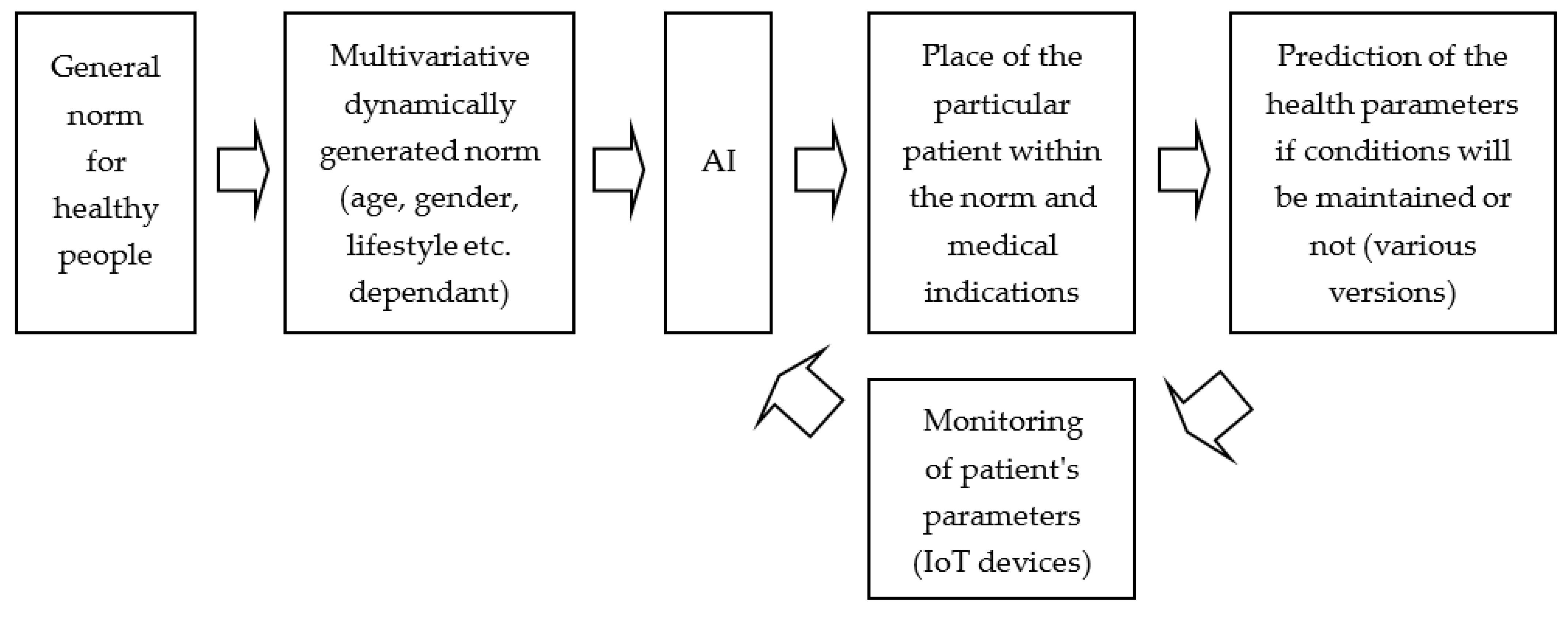
3.3. Predictive Medicine Application
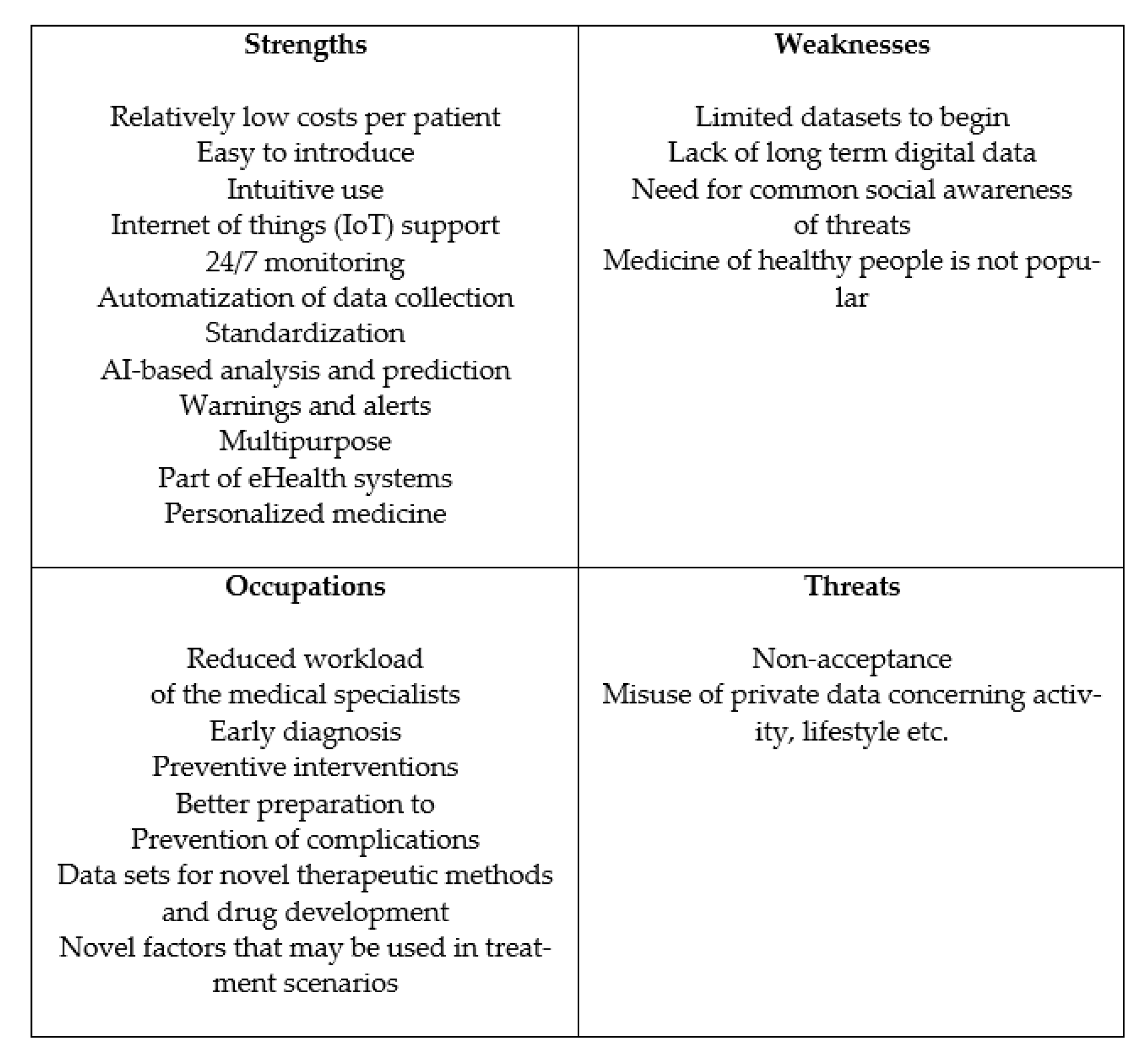
4. Discussion
- identification of knowledge gaps [15]
- methods for standardizing diagnostic imaging results through reference image exchange between observers and artificial intelligence thus enabling accurate measurements [16].
- the use of ML to accelerate diagnostic and therapeutic procedures allowing an earlier discharge of the patient from the ward or an early start of rehabilitation [1].
- new approaches in cardiac anaesthesia [15].
- creation and clinical application of hybrid approaches [1].
4.1. Limitations of Our Own Study
4.2. Directions for Further Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Iannattone, P.A.; Zhao, X.; VanHouten, J.; Garg, A.; Huynh, T. Artificial Intelligence for Diagnosis of Acute Coronary Syndromes: A Meta-analysis of Machine Learning Approaches. Can. J. Cardiol. 2020, 36, 577–583. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Pan, N.; An, Y.; Xu, M.; Tan, L.; Zhang, L. Diagnostic and Prognostic Biomarkers for Myocardial Infarction. Front. Cardiovasc. Med. 2021, 7, 617277. [Google Scholar] [CrossRef]
- Khosravi, F.; Ahmadvand, N.; Bellusci, S.; Sauer, H. The Multifunctional Contribution of FGF Signaling to Cardiac Development, Homeostasis, Disease and Repair. Front. Cell Dev. Biol. 2021, 9, 672935. [Google Scholar] [CrossRef] [PubMed]
- Giallauria, F. Editorial to the effect of high-intensity interval training on exercise capacity in post-myocardial infarction patients: A systematic review and meta-analysis. Eur. J. Prev. Cardiol. 2021, 29, 475–484. [Google Scholar] [CrossRef] [PubMed]
- Thosar, S.S.; Shea, S.A. Circadian control of human cardiovascular function. Curr. Opin. Pharmacol. 2021, 57, 89–97. [Google Scholar] [CrossRef]
- Portaluppi, F.; Tiseo, R.; Smolensky, M.H.; Hermida, R.C.; Ayala, D.E.; Fabbian, F. Circadian rhythms and cardiovascular health. Sleep Med. Rev. 2012, 16, 151–166. [Google Scholar] [CrossRef]
- Scheer, F.A.; Hu, K.; Evoniuk, H.; Kelly, E.E.; Malhotra, A.; Hilton, M.F.; Shea, S.A. Impact of the human circadian system, exercise, and their interaction on cardiovascular function. Proc. Natl. Acad. Sci. USA 2010, 107, 20541–20546. [Google Scholar] [CrossRef]
- Santos, P. The Role of Cardiovascular Risk Assessme nt in Preventive Medicine: A Perspective from Portugal Primary Health-Care Cardiovascular Risk Assessment. J. Environ. Public Health 2020, 2020, 1639634. [Google Scholar] [CrossRef]
- Frenz, W. Handbook Industry 4.0: Law, Technology, Society; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Thuemmler, C.; Bai, C. Health 4.0: How Virtualization and Big Data Are Revolutionizing Healthcare; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- McKinney, W. Pandas: A Foundational Python Library for Data Analysis and Statistics. Available online: https://www.researchgate.net/publication/265194455_pandas_a_Foundational_Python_Library_for_Data_Analysis_and_Statistics (accessed on 2 July 2022).
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- McGregor, D.M. Mastering Matplotlib; Packt Publishing: Birmingham, UK, 2015. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Spence, J.; Mazer, C.D. The Future Directions of Research in Cardiac Anesthesiology. Adv. Anesth. 2019, 37, 801–813. [Google Scholar] [CrossRef]
- Kusunose, K.; Zheng, R.; Yamada, H.; Sata, M. How to standardize the measurement of left ventricular ejection fraction. J. Med. Ultrason. 2021, 49, 35–43. [Google Scholar] [CrossRef]
- Saenz-Pipaon, G.; Martinez-Aguilar, E.; Orbe, J.; González Miqueo, A.; Fernandez-Alonso, L.; Paramo, J.A.; Roncal, C. The Role of Circulating Biomarkers in Peripheral Arterial Disease. Int. J. Mol. Sci. 2021, 22, 3601. [Google Scholar] [CrossRef]
- Cho, S.M.; Austin, P.C.; Ross, H.J.; Abdel-Qadir, H.; Chicco, D.; Tomlinson, G.; Taheri, C.; Foroutan, F.; Lawler, P.R.; Billia, F.; et al. Machine Learning Compared with Conventional Statistical Models for Predicting Myocardial Infarction Readmission and Mortality: A Systematic Review. Can. J. Cardiol. 2021, 37, 1207–1214. [Google Scholar] [CrossRef]
- Rubel, P.; Fayn, J.; Nollo, G.; Assanelli, D.; Li, B.; Restier, L.; Adami, S.; Arod, S.; Atoui, H.; Ohlsson, M.; et al. Toward personal eHealth in cardiology. Results from the EPI-MEDICS telemedicine project. J. Electrocardiol. 2005, 38 (Suppl. S4), 100–106. [Google Scholar] [CrossRef]
- Body, R. Acute coronary syndromes diagnosis, version 2.0: Tomorrow’s approach to diagnosing acute coronary syndromes? Turk. J. Emerg. Med. 2018, 18, 94–99. [Google Scholar] [CrossRef]
- Kerneis, M.; Nafee, T.; Yee, M.K.; Kazmi, H.A.; Datta, S.; Zeitoun, M.; Afzal, M.K.; Jafarizade, M.; Walia, S.S.; Qamar, I.; et al. Most Promising Therapies in Interventional Cardiology. Curr. Cardiol. Rep. 2019, 21, 26. [Google Scholar] [CrossRef]
- Jamthikar, A.; Gupta, D.; Khanna, N.N.; Araki, T.; Saba, L.; Nicolaides, A.; Sharma, A.; Omerzu, T.; Suri, H.S.; Gupta, A.; et al. A Special Report on Changing Trends in Preventive Stroke/Cardiovascular Risk Assessment Via B-Mode Ultrasonography. Curr. Atheroscler. Rep. 2019, 21, 25. [Google Scholar] [CrossRef]
- Goto, S.; Goto, S. Application of Neural Networks to 12-Lead Electrocardiography—Current Status and Future Directions. Circ. Rep. 2019, 1, 481–486. [Google Scholar] [CrossRef]
- Hayıroğlu, M.İ.; Lakhani, I.; Tse, G.; Çınar, T.; Çinier, G.; Tekkeşin, A.İ. In-Hospital Prognostic Value of Electrocardiographic Parameters Other Than ST-Segment Changes in Acute Myocardial Infarction: Literature Review and Future Perspectives. Heart Lung Circ. 2020, 29, 1603–1612. [Google Scholar] [CrossRef]
- Kusunose, K. Radiomics in Echocardiography: Deep Learning and Echocardiographic Analysis. Curr. Cardiol. Rep. 2020, 22, 89. [Google Scholar] [CrossRef]
- Willemink, M.J.; Varga-Szemes, A.; Schoepf, U.J.; Codari, M.; Nieman, K.; Fleischmann, D.; Mastrodicasa, D. Emerging methods for the characterization of ischemic heart disease: Ultrafast Doppler angiography, micro-CT, photon-counting CT, novel MRI and PET techniques, and artificial intelligence. Eur. Radiol. Exp. 2021, 5, 12. [Google Scholar] [CrossRef]
- Duncker, D.; Ding, W.Y.; Etheridge, S.; Noseworthy, P.A.; Veltmann, C.; Yao, X.; Bunch, T.J.; Gupta, D. Smart Wearables for Cardiac Monitoring-Real-World Use beyond Atrial Fibrillation. Sensors 2021, 21, 2539. [Google Scholar] [CrossRef]
- Biswas, M.; Saba, L.; Omerzu, T.; Johri, A.M.; Khanna, N.N.; Viskovic, K.; Mavrogeni, S.; Laird, J.R.; Pareek, G.; Miner, M.; et al. A Review on Joint Carotid Intima-Media Thickness and Plaque Area Measurement in Ultrasound for Cardiovascular/Stroke Risk Monitoring: Artificial Intelligence Framework. J. Digit. Imaging. 2021, 34, 581–604. [Google Scholar] [CrossRef]
- Bharati, S.; Podder, P.; Thanh, D.N.H.; Surya Prasath, V.B. Dementia classification using MR imaging and clinical data with voting based machine learning models. Multimed. Tools Appl. 2022, 81, 25971–25992. [Google Scholar] [CrossRef]
- Raj, S.; Masood, S. Analysis and Detection of Autism Spectrum Disorder Using Machine Learning Techniques. Procedia Comput. Sci. 2020, 167, 994–1004. [Google Scholar] [CrossRef]
- Xie, L.; Li, Z.; Zhou, Y.; He, Y.; Zhu, J. Computational Diagnostic Techniques for Electrocardiogram Signal Analysis. Sensors 2020, 20, 6318. [Google Scholar] [CrossRef]
- Nudi, R.; Campagna, M.; Parma, A.; Nudi, A.; Biondi Zoccai, G. Breakthrough healthcare technologies in the COVID-19 era: A unique opportunity for cardiovascular practitioners and patients. Panminerva Med. 2021, 63, 62–74. [Google Scholar] [CrossRef]
- Caie, P.D.; Dimitriou, N.; Arandjelović, O. Precision medicine in digital pathology via image analysis and machine learning. Artif. Intell. Deep. Learn. Pathol. 2021, 149–173. [Google Scholar] [CrossRef]
- Rojek, I. Neural networks as performance improvement models in intelligent CAPP systems. Control Cybern. 2010, 39, 55–68. [Google Scholar]
- Rojek, I.; Jagodziński, M. Hybrid Artificial Intelligence System in Constraint Based Scheduling of Integrated Manufacturing ERP Systems. In Proceedings of the 7th International Conference on Hybrid Artificial Intelligent Systems (HAIS), Salamanca, Spain, 28–30 March 2012; pp. 229–240. [Google Scholar]
- Rojek, I.; Mikołajewski, D.; Dostatni, E. Digital twins in product lifecycle for sustainability in manufacturing and maintenance. Appl. Sci. 2021, 11, 31. [Google Scholar] [CrossRef]
- Rojek, I.; Mikołajewski, D.; Kotlarz, P.; Macko, M.; Kopowski, J. Intelligent System Supporting Technological Process Planning for Machining and 3D Printing. Bull. Pol. Acad. Sci. Tech. Sci. 2021, 69, e136722. [Google Scholar]
- Rojek, I.; Kowal, M.; Stoic, A. Predictive compensation of thermal deformations of ball screws in cnc machines using neural networks. Teh.-Tech. Gaz. 2017, 24, 1697–1703. [Google Scholar] [CrossRef]
- Mikołajewski, D.; Prokopowicz, P. Effect of COVID-19 on Selected Characteristics of Life Satisfaction Reflected in a Fuzzy Model. Appl. Sci. 2022, 12, 7376. [Google Scholar] [CrossRef]
- Prokopowicz, P.; Mikołajewski, D. Fuzzy Approach to Computational Classification of Burnout—Preliminary Findings. Appl. Sci. 2022, 12, 3767. [Google Scholar] [CrossRef]
- Konieczny, M.; Pakosz, P.; Domaszewski, P.; Błaszczyszyn, M.; Kawala-Sterniuk, A. Analysis of Upper Limbs Target-Reaching Movement and Muscle Co-Activation in Patients with First Time Stroke for Rehabilitation Progress Monitoring. Appl. Sci. 2022, 12, 1551. [Google Scholar] [CrossRef]
- Podpora, M.; Gardecki, A.; Beniak, R.; Klin, B.; Vicario, J.L.; Kawala-Sterniuk, A. Human Interaction Smart Subsystem—Extending Speech-Based Human-Robot Interaction Systems with an Implementation of External Smart Sensors. Sensors 2020, 20, 2376. [Google Scholar] [CrossRef]
- Zolubak, M.; Grochowicz, B.; Pelc, M.; Kawala-Sterniuk, A. Stress analysis recorded in the EEG signal based on mathematical markers. In Proceedings of the 2019 24th International Conference on Methods and Models in Automation and Robotics (MMAR), Międzyzdroje, Poland, 26–29 August 2019; pp. 625–628. [Google Scholar]
- Lee, S.; Chu, Y.; Ryu, J.; Park, Y.J.; Yang, S.; Koh, S.B. Artificial Intelligence for Detection of Cardiovascular-Related Diseases from Wearable Devices: A Systematic Review and Meta-Analysis. Yonsei Med. J. 2022, 63, S93–S107. [Google Scholar] [CrossRef]
- Kim, A.; Jung, J.; Hong, J.; Yoon, S.J. Time series analysis of meteorological factors and air pollutants and their association with hospital admissions for acute myocardial infarction in Korea. Int. J. Cardiol. 2021, 322, 220–226. [Google Scholar] [CrossRef]
- Kim, D.W.; Byeon, K.H.; Kim, J.; Cho, K.D.; Lee, N. The Correlation of Comorbidities on the Mortality in Patients with COVID-19: An Observational Study Based on the Korean National Health Insurance Big Data. J. Korean Med. Sci. 2020, 35, e243. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Feature Name | Description |
|---|---|---|
| 1. | age | Age in years |
| 2. | sex | 1 = male 0 = female |
| 3. | cp | Chest pain type:
|
| 4. | trestbps | Resting blood pressure (in mm Hg on admission to the hospital)
|
| 5. | chol | Serum cholesterol in mg/dl
|
| 6. | fbs | Fasting blood sugar > 120 mg/dl (1 = true; 0 = false)
|
| 7. | restecg | Resting electrocardiographic results
|
| 8. | thalach | Maximum heart rate achieved |
| 9. | exang | Exercise induced angina (1 = yes; 0 = no) |
| 10. | oldpeak | ST depression induced by exercise relative to rest
|
| 11. | slope | The slope of the peak exercise ST segment
|
| 12. | ca | Number of major vessels (0–3) coloured in fluoroscopy
|
| 13. | thal | Thallium stress result
|
| 14. | target | Have disease or not (1 = yes, 0 = no) (= the predicted attribute) |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| accuracy | 0.89 | 61 | ||
| macro avg | 0.89 | 0.88 | 0.88 | 61 |
| weighted avg | 0.89 | 0.89 | 0.89 | 61 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rojek, I.; Kozielski, M.; Dorożyński, J.; Mikołajewski, D. AI-Based Prediction of Myocardial Infarction Risk as an Element of Preventive Medicine. Appl. Sci. 2022, 12, 9596. https://doi.org/10.3390/app12199596
Rojek I, Kozielski M, Dorożyński J, Mikołajewski D. AI-Based Prediction of Myocardial Infarction Risk as an Element of Preventive Medicine. Applied Sciences. 2022; 12(19):9596. https://doi.org/10.3390/app12199596
Chicago/Turabian StyleRojek, Izabela, Mirosław Kozielski, Janusz Dorożyński, and Dariusz Mikołajewski. 2022. "AI-Based Prediction of Myocardial Infarction Risk as an Element of Preventive Medicine" Applied Sciences 12, no. 19: 9596. https://doi.org/10.3390/app12199596
APA StyleRojek, I., Kozielski, M., Dorożyński, J., & Mikołajewski, D. (2022). AI-Based Prediction of Myocardial Infarction Risk as an Element of Preventive Medicine. Applied Sciences, 12(19), 9596. https://doi.org/10.3390/app12199596