
Deep Neural Network Concept for a Blind Enhancement of Document-Images in the Presence of Multiple Distortions


Abstract
:1. Introduction
2. Related Works
2.1. Deblurring
2.2. Denoising
2.3. Contrast Enhancement and Local Light Adjustment
3. Our Novel Deep Neural Method for Blind Enhancement
- Blur problem(s), e.g., focus blur, Gaussian blur, motions blur, etc.;
- Noise problem(s), e.g., salt noise or pepper noise, depending on image sensor sensitivity;
- Contrast problem(s), e.g., shadows, spotlight, and contrast deficits.
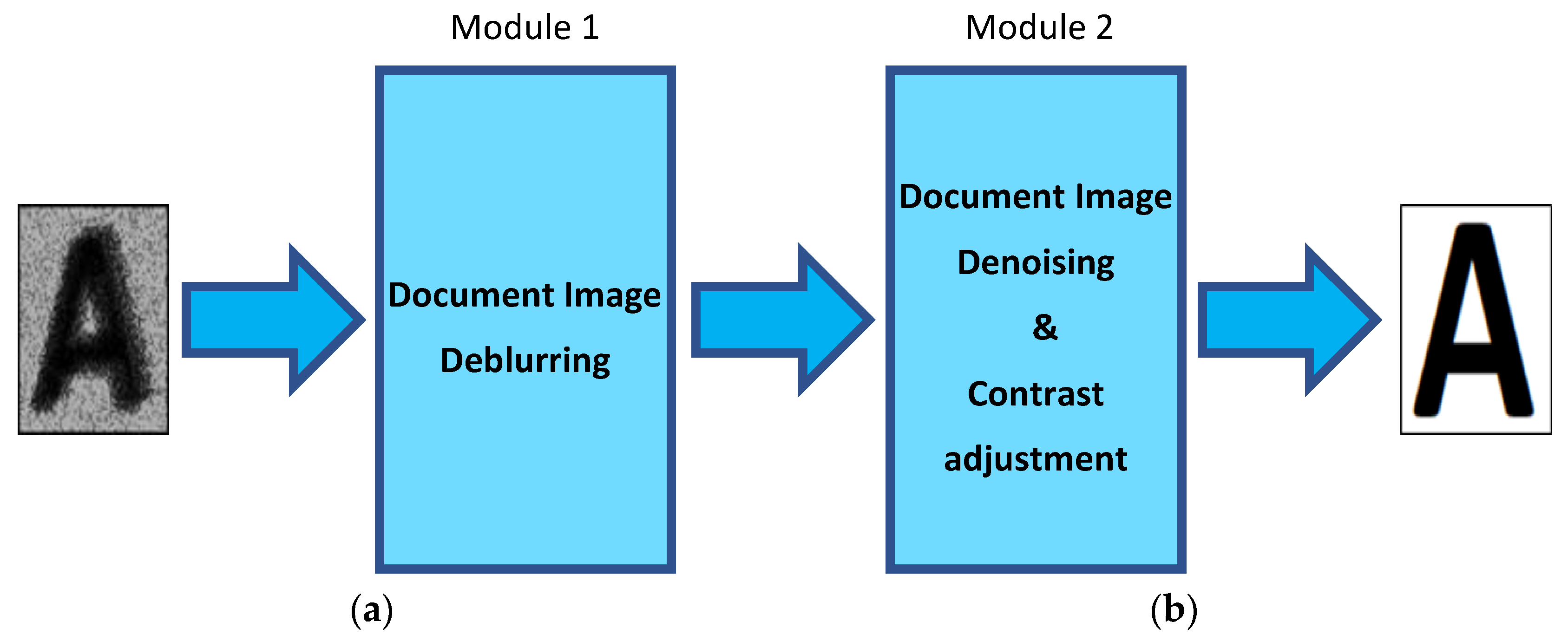
Document-Image Deblurring (Module 1, see Figure 3) and Document-Image Joint Contrast and Noise Enhancement (Module 2, See Figure 3)
4. Model Training and Discussion of the Results Obtained
- (a)
- Blur generator module: this module is responsible for adding blur artifacts to the standard dataset for both training and testing purposes. It contains three types of blurs. These three types are focus, motion, and blur based on the PSF library.
- (b)
- Noise generator module: this module is responsible for adding noise artifacts to the standard dataset. It contains three types of noise. These three types are Gaussian, salt and pepper, and speckle noise types.
- (c)
- Contrast generator module: this module is responsible for adding low contrast and brightness effects to the standard dataset. It contains two types of artifacts. The first one is the contrast effect, and the second one is the brightness effect.
4.1. Performance Results of Module 1 (of Figure 3) for Document-Image Deblurring
4.2. Performance Results with Regard to PSNR of Module 2 for Document-Image Noise Reduction and Contrast Improvement
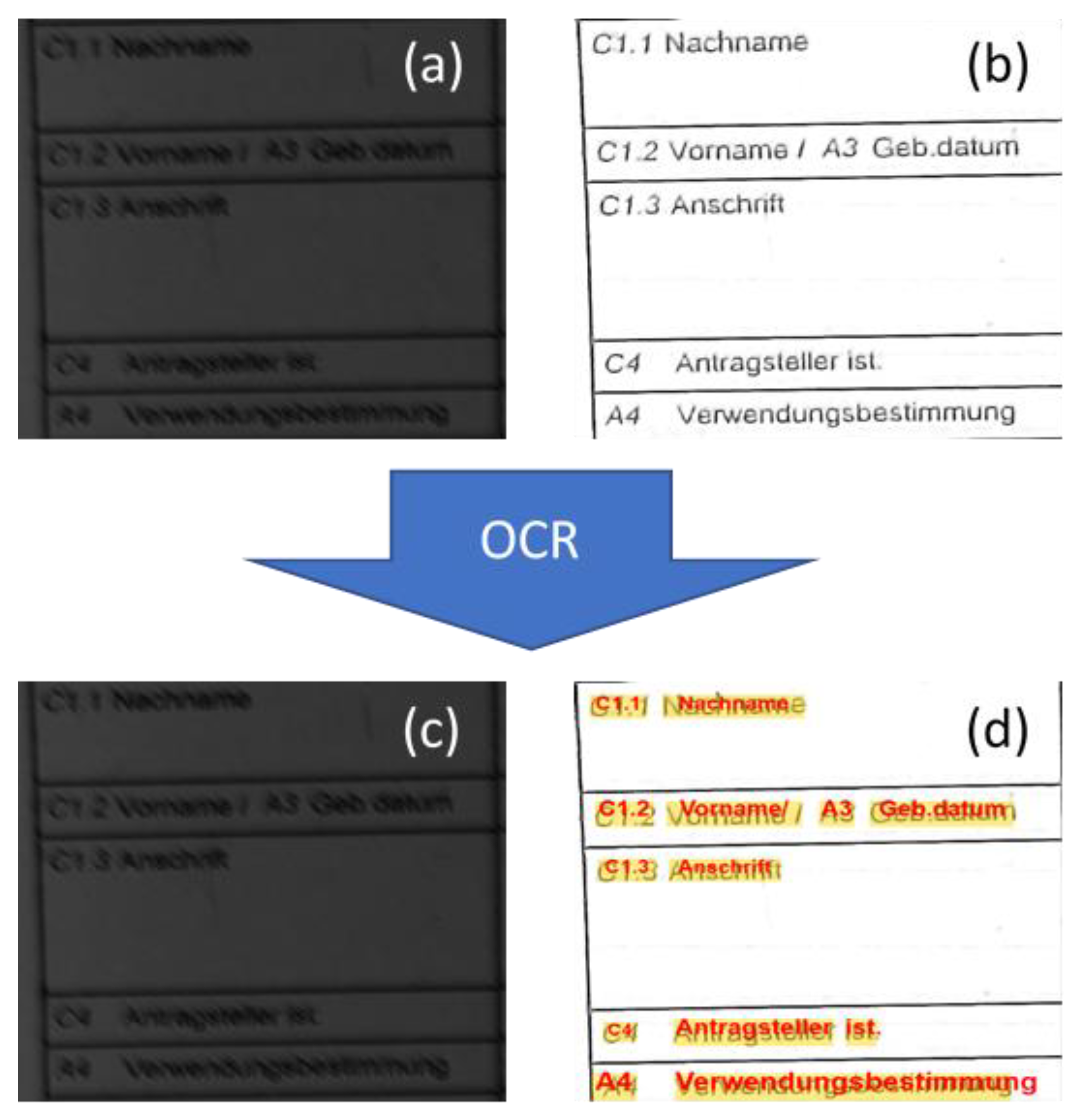
4.3. Performance Results with Respect to the OCR Performance of Module 2 for Document-Image Contrast and Brightness Enhancement
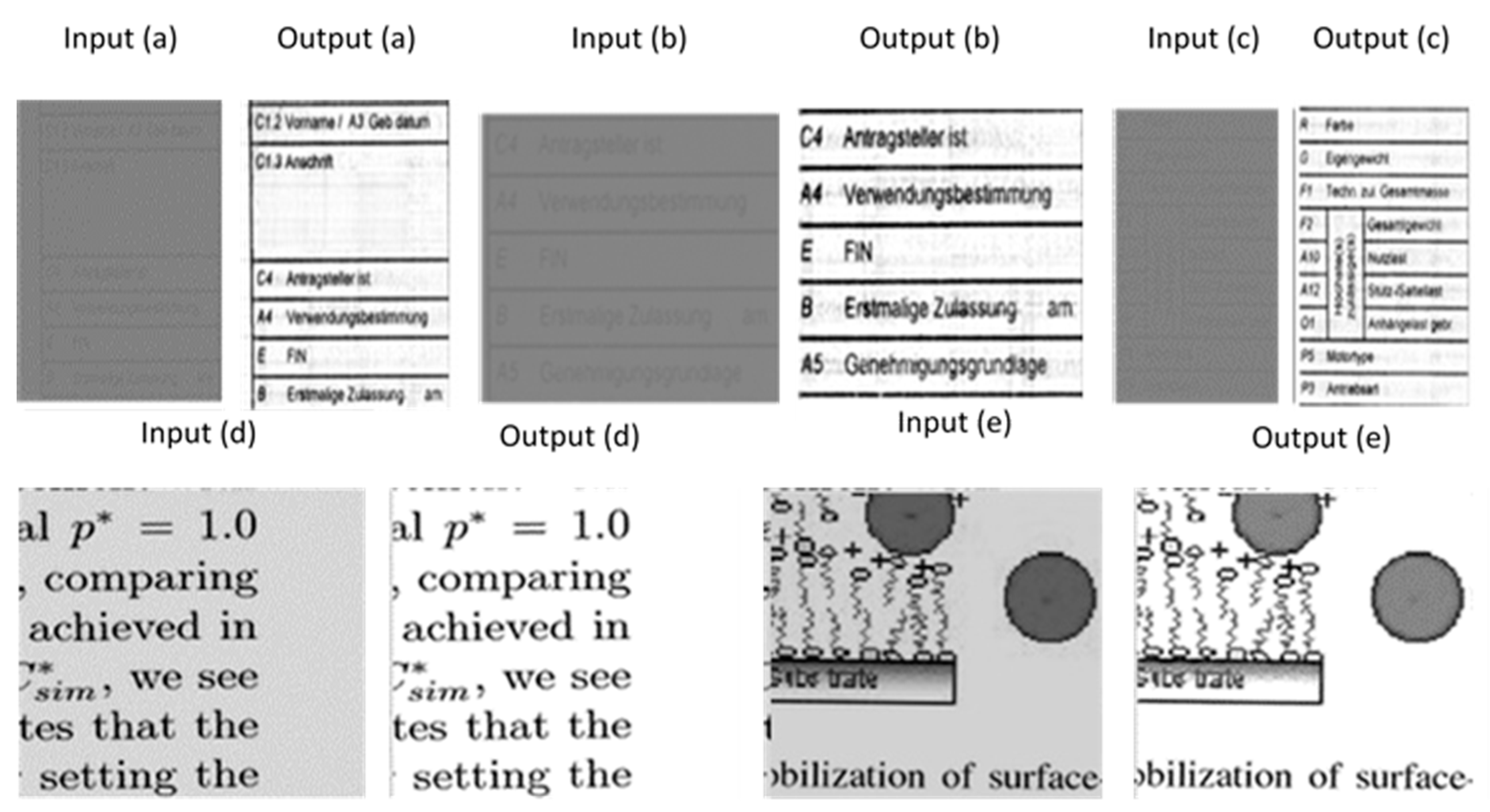
4.4. Performance Evaluation of Our Novel Global Model including “Module 1 + Module 2” (of Figure 3) for Blindly Enhancing Document Images Simultaneously Distorted by Blur + Noise + Contrast
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Chung, Y.; Chi, S.; Bae, K.S.; Kim, K.; Jang, D.; Kim, K.; Choi, Y. Extraction of character areas from digital camera based color document images and OCR system. In Proceedings of the SPIE- Optical Information Systems III, San Diego, CA, USA, 31 July–4 August 2005. [Google Scholar]
- Sharma, P.; Sharma, S. Image processing based degraded camera captured document enhancement for improved OCR accuracy. In Proceedings of the 2016 6th International Conference—Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016. [Google Scholar]
- Visvanathan, T.C.; Bhattacharya, U. Enhancement of camera captured text images with specular reflection. In Proceedings of the 2013 4th National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), Jodhpur, India, 18–21 December 2013. [Google Scholar]
- Tian, D.; Hao, Y.; Ha, M.; Tian, X.; Ha, Y. Algorithm of contrast enhancement for visual document images with underexposure. In Proceedings of the SPIE— International Symposium on Photoelectronic Detection and Imaging, Beijing, China, 7 March 2008. [Google Scholar]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Fan, M.; Huang, R.; Feng, W.; Sun, J. Image blur classification and blur usefulness assessment. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017. [Google Scholar]
- Chan, Z.-M.; Lau, C.-Y.; Thang, K.-F. Visual Speech Recognition of Lips Images Using Convolutional Neural Network in VGG-M Model. J. Inf. Hiding Multimed. Signal Process. 2020, 11, 116–125. [Google Scholar]
- Jaleel, S.; Bhavya, V.; Sree, N.A.; Sajitha, P. Edge Enhancement Using Haar MotherWavelets for Edge Detection in SAR Images. Int. J. Innov. Res. Sci. Eng. Technol. 2014, 3, 5. [Google Scholar]
- Lucas, J.; Calef, B.; Knox, K. Image Enhancement for Astronomical Scenes. Proc. SPIE 2013, 8856, 885603. [Google Scholar]
- Umamaheswari, J.; Radhamani, G. An Enhanced Approach for Medical Brain Image Enhancement. J. Comput. Sci. 2012, 8, 1329–1337. [Google Scholar]
- Jadhav, D.; Patil, P.M. An effective method for satellite image enhancement. In Proceedings of the International Conference on Computing, Communication & Automation, Noida, India, 15–16 May 2015. [Google Scholar]
- Rahman, S.; Rahman, M.M.; Hussain, K.; Khaled, S.M.; Shoyaib, M. Image Enhancement in Spatial Domain: A Comprehensive Study. In Proceedings of the 2014 17th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 22–23 December 2014. [Google Scholar]
- Hou, J.; Zhao, Y.; Lin, C.; Bai, H.; Liu, M. Quality Enhancement of Compressed Video via CNNs. J. Inf. Hiding Multimed. Signal Process. 2017, 8, 200–207. [Google Scholar]
- Huang, R.; Shivakumara, P.; Uchida, S. Scene character detection by an edge-ray filter. In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013. [Google Scholar]
- Almeida, M.; Almeida, L. Blind and Semi-Blind Deblurring of Natural Images. IEEE Trans. Image Process. 2010, 19, 36–52. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; He, X.; Yang, J.; Wu, Q. An effective document image deblurring algorithm. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 2011. [Google Scholar]
- Kuang, X.; Sui, X.; Liu, Y.; Chen, Q.; Gu, G. Single infrared image enhancement using a deep convolutional neural network. Neurocomputing 2019, 332, 119–128. [Google Scholar] [CrossRef]
- Lefkimmiatis, S. Non-local Color Image Denoising with Convolutional Neural Networks. arXiv 2017, arXiv:1611.06757. [Google Scholar]
- Cruz, C.; Foi, A.; Katkovnik, V.; Egiazarian, K. Nonlocality-Reinforced Convolutional Neural Networks for Image Denoising. IEEE Signal Process. Lett. 2018, 25, 1216–1220. [Google Scholar] [CrossRef]
- Sun, J.; Kim, S.W.; Lee, S.W.; Ko, S. A novel contrast enhancement forensics based on convolutional neural networks. Signal Process.-Image Commun. 2018, 63, 149–160. [Google Scholar] [CrossRef]
- Niu, W.; Zhang, K.; Luo, W.; Zhong, Y. Blind motion deblurring super-resolution: When dynamic spatio-temporal learning meets static image understanding. IEEE Trans. Image Process. 2021, 30, 7101–7111. [Google Scholar] [CrossRef] [PubMed]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring. arXiv 2017, arXiv:1612.02177. [Google Scholar]
- Po, L.-M.; Liu, M.; Yuen, W.Y.F.; Li, Y.; Xu, X.; Zhou, C.; Wong, P.H.W.; Lau, K.W.; Luk, H.-T. A Novel Patch Variance Biased Convolutional Neural Network for No-Reference Image Quality Assessment. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 1223–1229. [Google Scholar] [CrossRef]
- Zhang, Y.; Lin, H.; Li, Y.; Ma, H. A Patch Based Denoising Method Using Deep Convolutional Neural Network for Seismic Image. IEEE Access 2019, 7, 156883–156894. [Google Scholar] [CrossRef]
- Yao, H.; Chuyi, L.; Dan, H.; Weiyu, Y. Gabor Feature Based Convolutional Neural Network for Object Recognition in Natural Scene. In Proceedings of the 2016 3rd International Conference on Information Science and Control Engineering (ICISCE), Bejing, China, 8–10 July 2016. [Google Scholar]
- Hosseini, S.; Lee, S.; Kwon, H.; Koo, H.; Cho, N. Age and gender classification using wide convolutional neural network and Gabor filter. In Proceedings of the 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018. [Google Scholar]
- Nguyen, V.; Lim, K.; Le, M.; Bui, N. Combination of Gabor Filter and Convolutional Neural Network for Suspicious Mass Classification. In Proceedings of the 2018 22nd International Computer Science and Engineering Conference (ICSEC), Chiang Mai, Thailand, 21–24 November 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Yiren, Z.; Sibo, S.; Cheung, N. On Classification of Distorted Images with Deep Convolutional Neural. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, New Orlean, LA, USA, 5–9 March 2017. [Google Scholar]
- Fergus, R.; Singh, B.; Hertzmann, A.; Roweis, S.T.; Freeman, W.T. Removing camera shake from a single photograph. ACM Trans. Graph. 2006, 25, 787–794. [Google Scholar] [CrossRef]
- Bunyak, Y.; Sofina, O.; Kvetnyy, R. Blind PSF estimation and methods of deconvolution optimization. arXiv 2012, arXiv:1206.3594. [Google Scholar]
- Krishnan, T.T.; Fergus, R. Blind deconvolution using a normalized sparsity measure. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 20–25 June 2011. [Google Scholar]
- Sun, S.; Zhao, H.; Li, B.; Hao, M.; Lv, J. Kernel estimation for robust motion deblurring of noisy and blurry images. J. Electron. Imaging 2016, 25, 033019. [Google Scholar] [CrossRef]
- Levin, A.; Weiss, Y.; Durand, F.; Freeman, W.T. Understanding Blind Deconvolution Algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2354–2367. [Google Scholar] [CrossRef]
- Albluwi, V.K.; Dahyot, R. Image Deblurring and Super-Resolution Using Deep Convolutional Neural Networks. In Proceedings of the IEEE International Workshop on Machine Learning for Signal Processing, AALBORG, Aalborg, Denmark, 17–20 September 2018. [Google Scholar]
- Liu, Z.S.; Siu, W.C.; Chan, Y.L. Reference Based Face Super-Resolution. IEEE Access 2019, 7, 129112–129126. [Google Scholar] [CrossRef]
- Liu, B.; Ait-Boudaoud, D. Effective image super resolution via hierarchical convolutional neural network. Neurocomputing 2020, 374, 109–116. [Google Scholar] [CrossRef]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2599–2613. [Google Scholar] [CrossRef] [PubMed]
- Neji, H.; Halima, M.; Hamdani, T.; Nogueras-Iso, J.; Alimi, A. Blur2Sharp: A GAN-Based Model for Document Image Deblurring. Int. J. Comput. Intell. Syst. 2021, 14, 1315–1321. [Google Scholar] [CrossRef]
- Xu, X.; Sun, D.; Pan, J.; Zhang, Y.; Pfister, H.; Yang, M.H. Learning to super-resolve blurry face and text images. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Khaw, H.Y.; Soon, F.C.; Chuah1, J.H.; Chow, C.-O. Image noise types recognition using. IET Image Process. 2017, 11, 1238–1245. [Google Scholar] [CrossRef]
- Liu, K.; Tan, J.; Su, B. An adaptive image denoising model based on tikhonov and TV regularizations. Adv. Multimed. 2014, 2014, 8. [Google Scholar] [CrossRef]
- Shahdoosti, H.Z. Edge-preserving image denoising using a deep convolutional neural network. Signal Process. 2019, 159, 20–32. [Google Scholar] [CrossRef]
- Chen, J.L.F. Denoising convolutional neural network with mask for salt and pepper noise. IET Image Process. 2019, 13, 2604–2613. [Google Scholar] [CrossRef]
- Thakur, R.S.; Yadav, R.N.; Gupta, L. State-of-art analysis of image denoising methods using convolutional neural networks. IET Image Process. 2019, 13, 2367–2380. [Google Scholar]
- Alkinani, M.H.; El-Sakka, M.R. Patch-based models and algorithms for image denoising: A comparative review between patch-based images denoising methods for additive noise reduction. Eurasip J. Image Video Process. 2017, 2017, 58. [Google Scholar] [CrossRef]
- Nejati, M.; Samavi, S.; Derksen, H.; Najarian, K. Denoising by low-rank and sparse representations. J. Vis. Commun. Image Represent. 2016, 36, 28–39. [Google Scholar] [CrossRef]
- Zha, Z.; Liu, X.; Zhou, Z.; Huang, X.; Shi, J.; Shang, Z.; Tang, L.; Bai, Y.; Wang, Q.; Zhang, X. Image denoising via group sparsity residual constraint. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Hu, H.; Froment, J.; Liu, Q. A note on patch-based low-rank minimization for fast image denoising. J. Vis. Commun. Image Represent. 2018, 50, 100–110. [Google Scholar] [CrossRef]
- Buades, B.C.; Morel, J.M. Non-Local Means Denoising. Image Process. On Line 2011, 1, 208–212. [Google Scholar] [CrossRef]
- Chatterjee, P.; Milanfar, P. Patch-Based Near-Optimal Image Denoising. IEEE Trans. Image Process. 2012, 21, 1635–1649. [Google Scholar] [CrossRef]
- Zhou, T.; Li, C.; Zeng, X.; Zhao, Y. Sparse representation with enhanced nonlocal self-similarity for image denoising. Mach. Vis. Appl. 2021, 32, 1–11. [Google Scholar] [CrossRef]
- Kishan, H.; Seelamantula, C.S. Patch-based and multiresolution optimum bilateral filters for denoising images corrupted by Gaussian noise. J. Electron. Imaging 2015, 24, 053021. [Google Scholar] [CrossRef]
- Fu, B.; Zhao, X.-Y.; Li, Y.; Wang, X. Patch-based contour prior image denoising for salt and pepper noise. Multimed. Tools Appl. 2019, 78, 30865–30875. [Google Scholar] [CrossRef]
- Lu, S. Good Similar Patches for Image Denoising. arXiv 2019, arXiv:1901.06046. [Google Scholar]
- Jain, P.; Tyagi, V. LAPB: Locally adaptive patch-based wavelet domain edge-preserving image denoising. Inf. Sci. 2015, 294, 164–181. [Google Scholar] [CrossRef]
- Jain, V.; Seung, H.S. Natural Image Denoising with Convolutional Networks. In Proceedings of the Advances in Neural Information Processing Systems 21 (NIPS 2008), Vancouver, BC, Canada, 8–11 December 2008. [Google Scholar]
- Krizhevsky, I.S.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. J. Geotech. Geoenviron. Eng. 2012, 141, 1097–1105. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Fu, B.; Zhao, X.; Li, Y.; Wang, X.; Ren, Y. A convolutional neural networks denoising approach for salt and pepper noise. Multimed. Tools Appl. 2018, 320, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing; Pearson Education, Inc.: Saddle Brook, NJ, USA, 2006. [Google Scholar]
- Shen, L.; Yue, Z.; Feng, F.; Chen, Q.; Liu, S.; Ma, J. MSR-net: Low-light Image Enhancement Using Deep Convolutional Network. arXiv 2017, arXiv:1711.02488. [Google Scholar]
- Kim, Y.-T. Contrast enhancement using brightness preserving bi-histogram equalization. IEEE Trans. Consum. Electron. 1997, 473, 1–8. [Google Scholar]
- Nakai, K.; Hoshi, Y.; Taguchi, A. Color image contrast enhacement method based on differential intensity/saturation gray-levels histograms. In Proceedings of the International Symposium on Intelligent Signal Processing and Communication Systems, Penang, Malaysia, 22–25 November 2013; pp. 445–449. [Google Scholar]
- Girish, N.; Smitha, P. Survey on Image Equalization Using Gaussian Mixture Modeling with Contrast as an Enhancement Feature. Int. J. Eng. Res. Technol. 2013, 2, 1–4. [Google Scholar]
- Singh, S.; Singh, T.T.; Singh, N.G.; Devi, H.M. Global-Local Contrast Enhancement. Int. J. Comput. Appl. 2012, 54, 7–11. [Google Scholar]
- Yeonan-Kim, J.; Bertalmío, M. Analysis of retinal and cortical components of Retinex algorithms. J. Electron. Imaging 2017, 26, 031208. [Google Scholar] [CrossRef]
- Ahsan, M.; Based, M.A.; Haider, J.; Kowalski, M. An intelligent system for automatic fingerprint identification using feature fusion by Gabor filter and deep learning. Comput. Electr. Eng. 2021, 95, 107387. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Li, F.-F. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Maini, R.; Aggarwal, H. A Comprehensive Review of Image Enhancement Techniques. arXiv 2010, arXiv:1003.4053. [Google Scholar]
- Hradis, M.; Kotera, J.; Zemcík, P.; Sroubek, F. Convolutional Neural Networks for Direct Text Deblurring. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–11 September 2015. [Google Scholar]
- Kingma, D.; Adam, J.B. A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Smith, R. An Overview of the Tesseract OCR Engine. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, 23–26 September 2007. [Google Scholar]
- Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. Aster: An attentional scene text recognizer with flexible rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2035–2048. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Chen, C.; Wong, K.Y.K.; Su, Z.; Han, J. STAR-Net: A spatial attention residue network for scene text recognition. BMVC 2016, 2, 7. [Google Scholar]
- Xu, L.; Ren, J.S.J.; Liu, C.; Jia, J. Deep Convolutional Neural Network for Image Deconvolution. 2014. Available online: http://papers.nips.cc/paper/5485-deep-convolutional-neural-network-for-image-deconvolution (accessed on 22 April 2019).
- Whyte, O.; Sivic, J.; Zisserman, A.; Ponce, J. Non-uniform deblurring for shakenimages. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Pan, J.; Hu, Z.; Su, Z.; Yang, M.-H. L0-Regularized Intensity and Gradient Prior for Deblurring Text Images and Beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39. [Google Scholar]
- Zhong, L.; Cho, S.; Metaxas, D.; Paris, S.; Wang, J. Handling noise in single image deblurring using directional filters. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Cho, H.; Wang, J.; Lee, S. Text Image Deblurring Using Text-Specific Properties. In Proceedings of the Computer Vision—ECCV, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Zhou, Y.; Ye, Z.; Huang, J. Improved decision-based detail-preserving variational method for removal of random-valued impulse noise. Image Process. IET 2012, 6, 976–985. [Google Scholar] [CrossRef]
- Varghese, J.; Tairan, N.; Subash, S. Adaptive switching non-local filter for the restoration of salt and pepper impulse-corrupted digital images. Arab. J. Sci. Eng. 2015, 40, 3233–3246. [Google Scholar] [CrossRef]
- Delon, J.; Desolneux, A.; Guillemot, T. PARIGI: A patch-based approach to remove impulse-Gaussian noise from images. Image Process. On Line 2016, 5, 130–154. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Artifact | Generator Parameters | Description |
|---|---|---|
| Gaussian Noise | Norm is a Gaussian random generator with mean value μ and standard deviation . | |
| Speckle Noise | Norm is a Gaussian random generator with mean value . | |
| Salt and Pepper Noise | S and P are two matrices in which the elements can have either 0 or 1. The matrix S defines white pixels in the image, and the matrix P represents black pixels in the image. They participate together in generating salt and pepper noise: s is an element of matrix S; p is an element of matrix P; m is number of rows in matrix either S or P; n is the number of columns in matrix S or P; f and t are random numbers in the defined range which define noise level in percent and both salt and pepper ratios. | |
| Contrast | R is a real value from the given set of values | |
| Brightness | R is a real value from the given set of values | |
| Focus Blur | The Kernel matrix is defined for convolution with the original image | |
| Motion Blur | The motion blur kernel has one direction of 45 degrees |
| Considered Deblurring Models | Character Recognition Accuracy (CRA) by the Tesseract OCR | Average PSNR |
|---|---|---|
| Blurred reference images | 0 | 14.15 |
| Our model without blur and Gabor filters | 70.23 | 32.32 |
| Our model without Gabor filters | 81.32 | 32.76 |
| Our model without blur filters | 91.12 | 33.32 |
| Our model, Module 1 | 94.55 | 33.85 |
| Considered Deblurring Models | Type of Deblurring Model | Character Recognition Accuracy (CRA) by the Tesseract OCR | Average PSNR |
|---|---|---|---|
| Blurred reference Images | - | 0 | 14.15 |
| Xu and Jia [76] | Analytical | 0 | 20.12 |
| L0 deblur [77] | Analytical | 0 | 18.14 |
| Cho and Lee [78] | Analytical | 0 | 25.10 |
| Zhong et al. [79] | Analytical | 0 | 27.3 |
| Chen et al. [16] | Analytical | 0 | 28.4 |
| Cho et al. [80] | Analytical | 66.35 | 30.10 |
| Pan et al. [16] | Analytical | 92.48 | 33.50 |
| Hradis et al. [78] | ConvNet | 68.3 | 32.20 |
| Neji et al. [39] | GAN | 69.55 | 32.12 |
| Our model, Module 1 | ConvNet | 94.55 | 33.85 |
| Test Image | Noise Levels in the Test Image | PSNR for DBA [81] | PSNR for NASNLM [82] | PSNR for PARIGI [83] | PSNR for NLSF [60] | PSNR for NLSF MLP [60] | PSNR for NLSF CNN [60] | PSNR for Our Model (Module 2) |
|---|---|---|---|---|---|---|---|---|
| Pepper | 30 50 70 | 26.85 25.27 22.11 | 22.38 21.82 21.58 | 28.88 25.44 21.46 | 32.27 27.99 23.04 | 30.01 28.57 27.04 | 32.99 30.23 27.70 | 34.66 32.57 30.01 |
| Lena | 30 50 70 | 34.35 30.13 25.21 | 28.18 26.15 25.88 | 33.88 29.44 25.46 | 34.21 30.14 25.04 | 30.01 29.30 27.34 | 35.19 32.23 30.70 | 35.66 32.57 30.81 |
| Average Over 11 Images from the Standard Test Images | 30 50 70 | 31.79 28.27 24.38 | 27.07 26.38 26.98 | 30.86 27.47 23.87 | 32.28 29.28 25.09 | 29.77 28.09 26.36 | 33.35 31.34 29.15 | 33.76 32.57 29.80 |
| Average Over 100 Images from Hradis et al. [78] Test Images | 30 50 70 | 31.37 27.36 23.37 | 26.69 25.32 26.74 | 29.92 27.35 23.84 | 31.45 28.84 24.12 | 28.89 27.08 25.42 | 32.45 30.35 28.53 | 32.91 31.70 29.65 |
| Considered Image Enhancement Models | CRA in Different Image Quality (By the Tesseract OCR) | ||||
|---|---|---|---|---|---|
| Very Good | Good | Middle | Bad | Very Bad | |
| Mix distorted (blur + noise + contrast) reference images | 95.23 | 85.32 | 57.21 | 33.26 | 13.56 |
| Pan et al. [16] | 94.78 | 85.48 | 66.71 | 56.12 | 46.88 |
| Neji et al. [39] | 93.10 | 86.34 | 67.23 | 57.36 | 57.64 |
| Pan et al. [16] + NLSF CNN [60] | 95.40 | 87.83 | 82.53 | 80.73 | 77.53 |
| Neji et al. [39] + NLSF CNN [60] | 95.35 | 88.25 | 84.45 | 81.65 | 75.45 |
| Our global model (Module 1 + Model 2, seeFigure 3) | 97.12 | 98.52 | 95.15 | 92.13 | 91.51 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohsenzadegan, K.; Tavakkoli, V.; Kyamakya, K. Deep Neural Network Concept for a Blind Enhancement of Document-Images in the Presence of Multiple Distortions. Appl. Sci. 2022, 12, 9601. https://doi.org/10.3390/app12199601
Mohsenzadegan K, Tavakkoli V, Kyamakya K. Deep Neural Network Concept for a Blind Enhancement of Document-Images in the Presence of Multiple Distortions. Applied Sciences. 2022; 12(19):9601. https://doi.org/10.3390/app12199601
Chicago/Turabian StyleMohsenzadegan, Kabeh, Vahid Tavakkoli, and Kyandoghere Kyamakya. 2022. "Deep Neural Network Concept for a Blind Enhancement of Document-Images in the Presence of Multiple Distortions" Applied Sciences 12, no. 19: 9601. https://doi.org/10.3390/app12199601
APA StyleMohsenzadegan, K., Tavakkoli, V., & Kyamakya, K. (2022). Deep Neural Network Concept for a Blind Enhancement of Document-Images in the Presence of Multiple Distortions. Applied Sciences, 12(19), 9601. https://doi.org/10.3390/app12199601