
DHT-Based Blockchain Dual-Sharding Storage Extension Mechanism


Abstract
:1. Introduction
- (1)
- We designed a DHT-based blockchain dual-sharding storage extension mechanism—DBDSM. The transaction data of the whole network are processed by the second fragmentation and stored in nodes across different clusters, providing security and availability of data while reducing transaction data storage requirements at individual nodes, thus realizing the expansion of the blockchain storage capacity.
- (2)
- A hybrid query mechanism for transaction data in the fragmented state is proposed. On the premise of not changing the query of the blockchain state data, the query efficiency of transaction data in the fragmented state has been improved through the master-node caching mechanism and the routing lookup mechanism.
- (3)
- The overlapping storage of fragmented data is allocated to the cluster by nodes within the cluster, guaranteeing the availability of fragmented data even when some of those nodes fail.
2. Related Work
2.1. DHT
2.2. Sharding Storage Protocol
3. Problem Statement
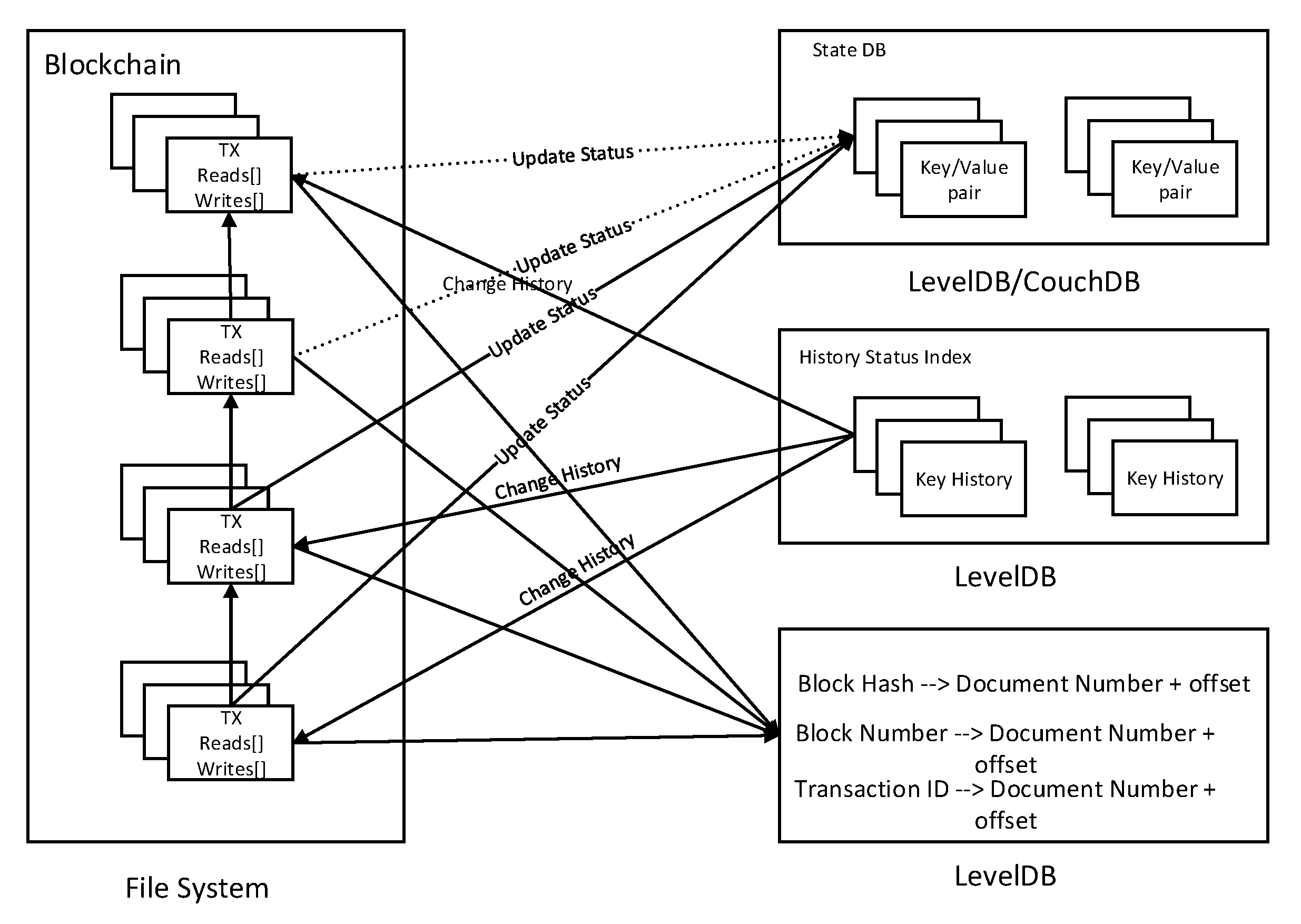
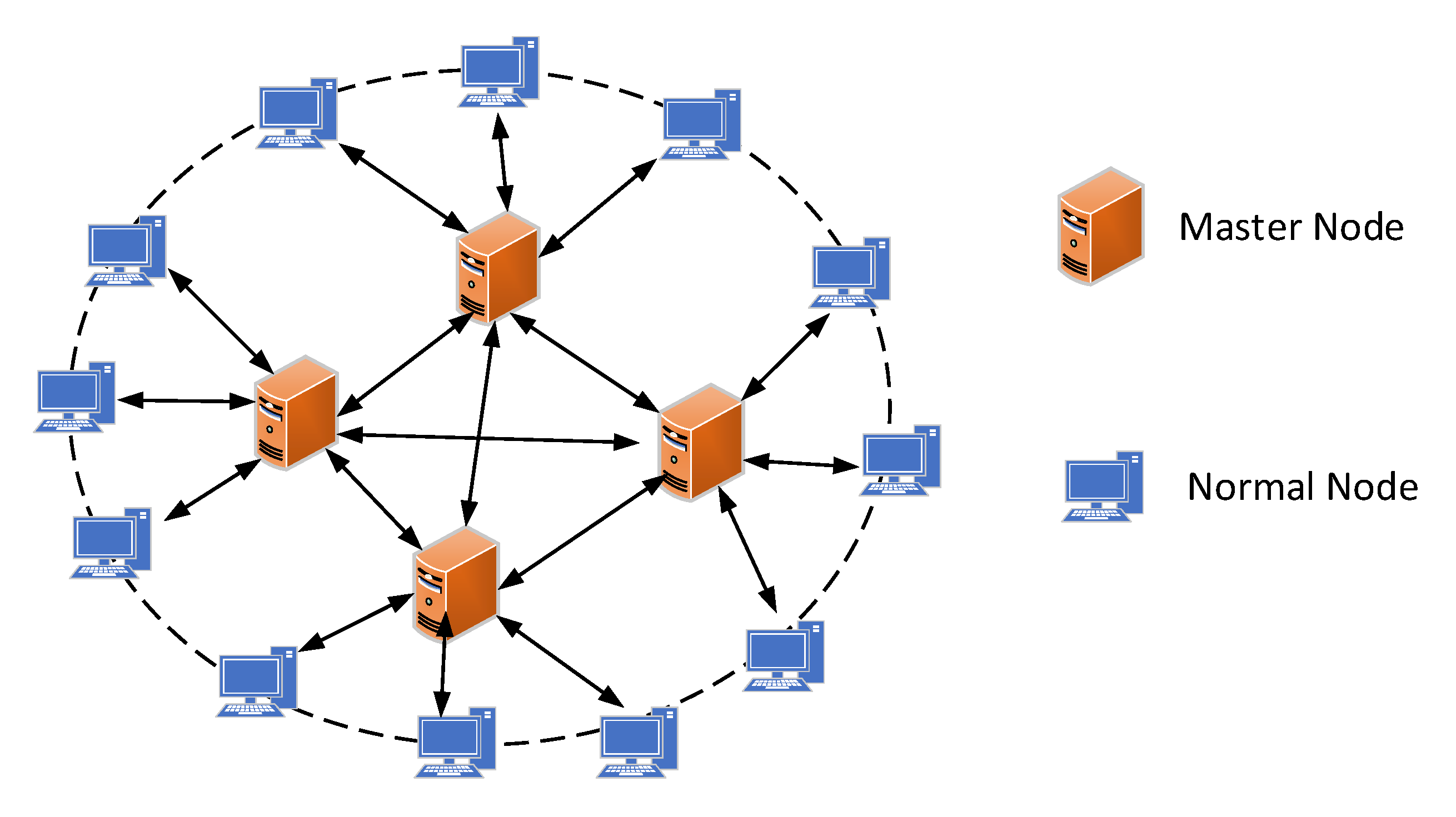
3.1. Storage Model
3.2. Storage Reliability
3.3. Node Performance Evaluation Strategy
4. Dual-Sharding Mechanism
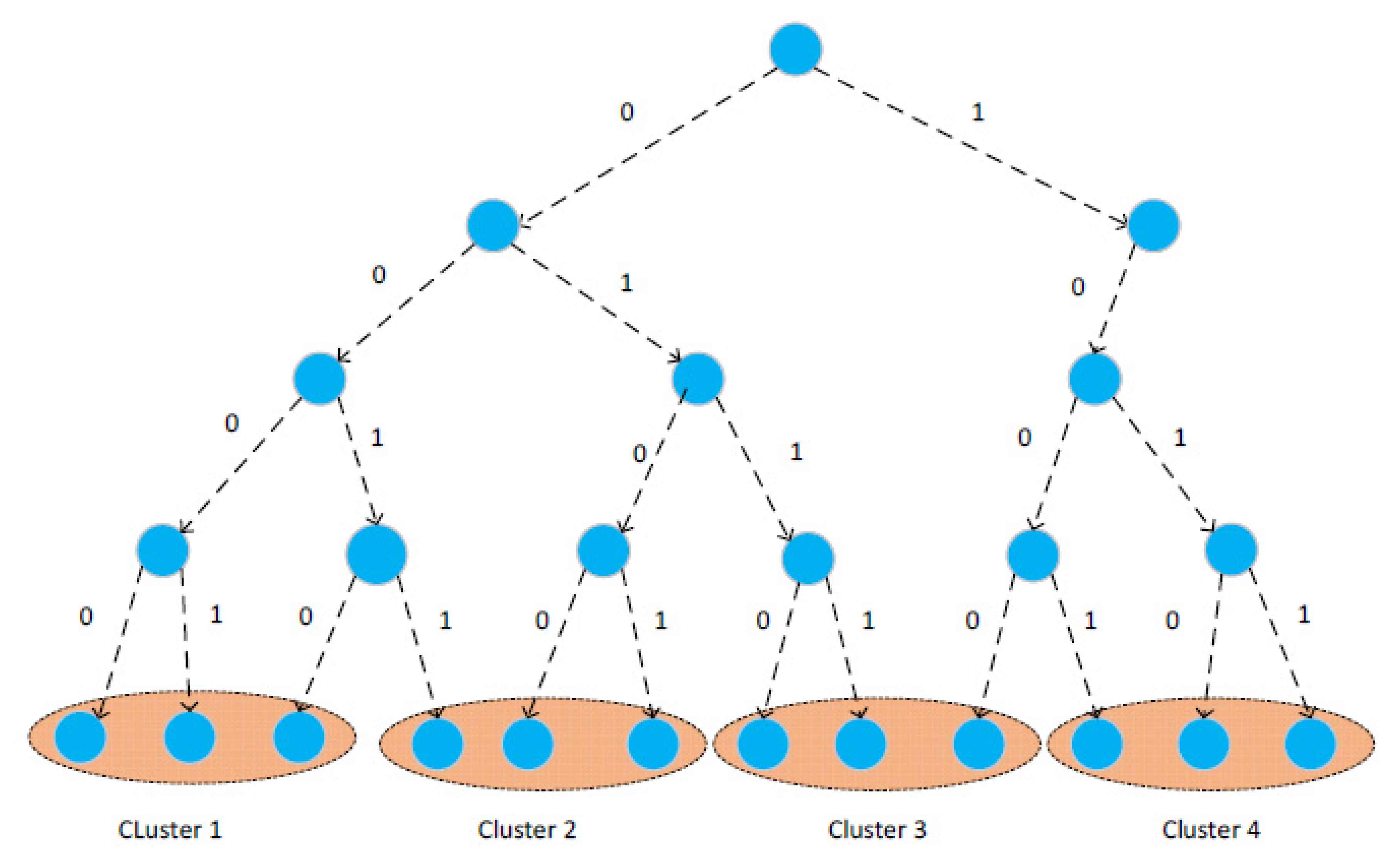
4.1. Cluster Division
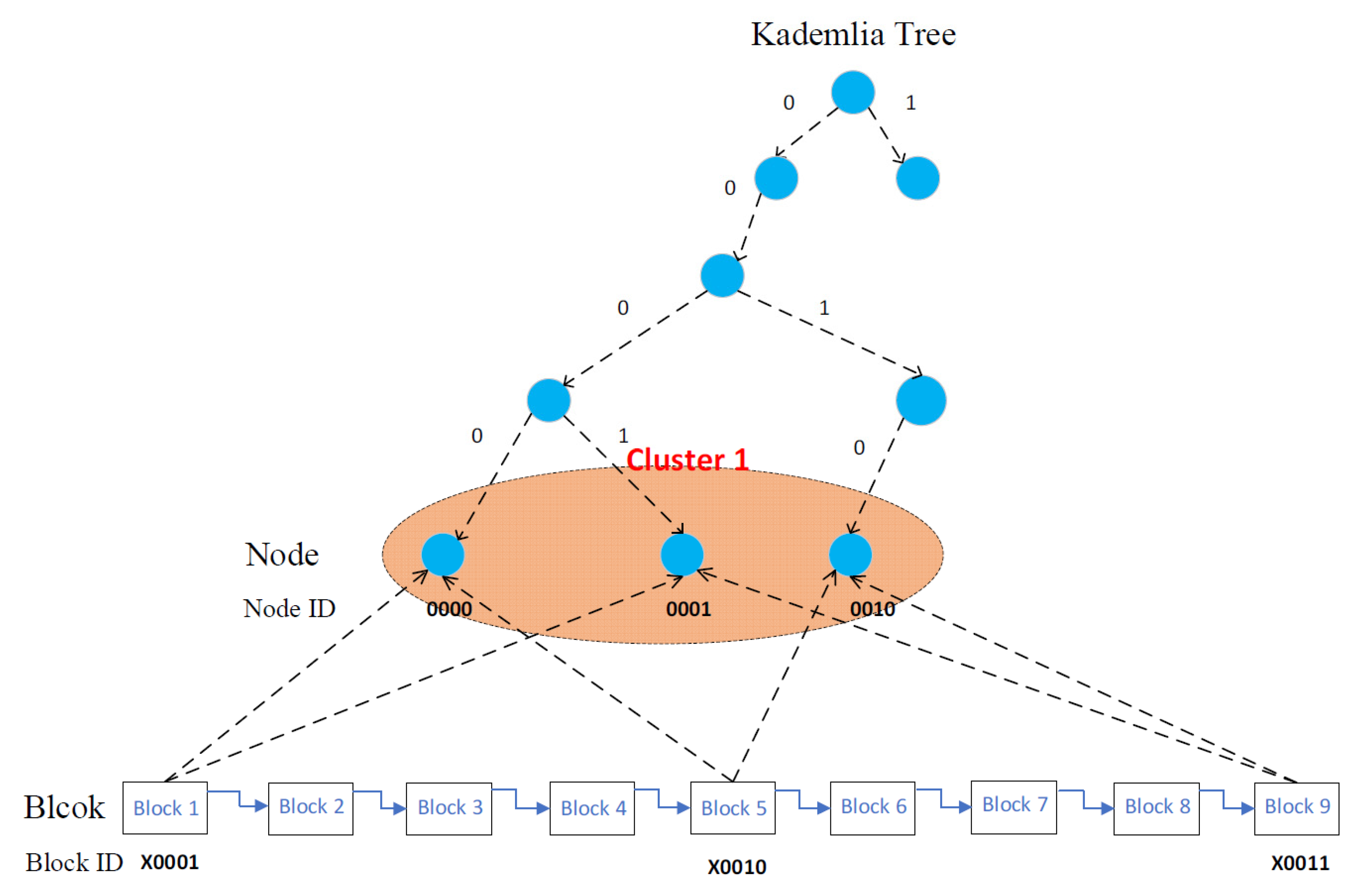
4.2. XOR Mapping Mechanism
- (1)
- The first generated block number is 1. The storage cluster location calculation formula yields 1|4 = 1, determining that the block should be stored in cluster 1. Then, according to the last-bit XOR mapping mechanism, the XOR operation is performed between the ID and the last [log2n] bit of the ID of the node in the cluster. The two nodes with the smaller operation values are selected as the storage nodes, and the final nodes stored in this block are determined to be nodes 0000 and 0001;
- (2)
- The subsequently generated blocks numbered 2, 3, and 4 are calculated and stored in clusters 2, 3 and 4, respectively. The process of mapping blocks to nodes is the same as in (1).
- (3)
- When the block number is 5, the storage location calculation formula yields 5|4 = 1, determining that the block is stored in cluster 1. According to the last-bit XOR mapping mechanism, the final nodes for the block storage are nodes 0000 and 0010.
- (4)
- Continuing the process of (2) above, when the resulting block number is 9, the storage location calculation formula yields 9|4 = 1, determining that the block is stored in cluster 1. Then, according to the last-bit XOR mapping mechanism, the final nodes of the block storage are nodes 0001 and 0010.
4.3. Hybrid Query Mechanism
- (1)
- Master node cache mechanism
- (2)
- Route lookup mechanism
| Algorithm 1 Transaction data query algorithm. |
| Initialization:S = 0 Input: node N, condition Ki//Ki means account key. if N is ordinary node then access master node end if while S > 0 for j ⟵ 0 to S if get result then return data update cache data time end if end for end while Iterate through M local file system and M storage routing information, and query other master nodes and common nodes return data if cache < 256 MB then Broadcast data to all master node caches S = S + 1 else Delete data that has not been accessed for a long time Broadcast data to all master node caches S = S + 1 end if Output: transaction data |
5. Theoretical Analysis
5.1. Storage Efficiency Analysis
5.2. Query Efficiency Analysis
5.3. Security Analysis
6. Experiment
6.1. Experiment Setup
6.2. Experimental Results
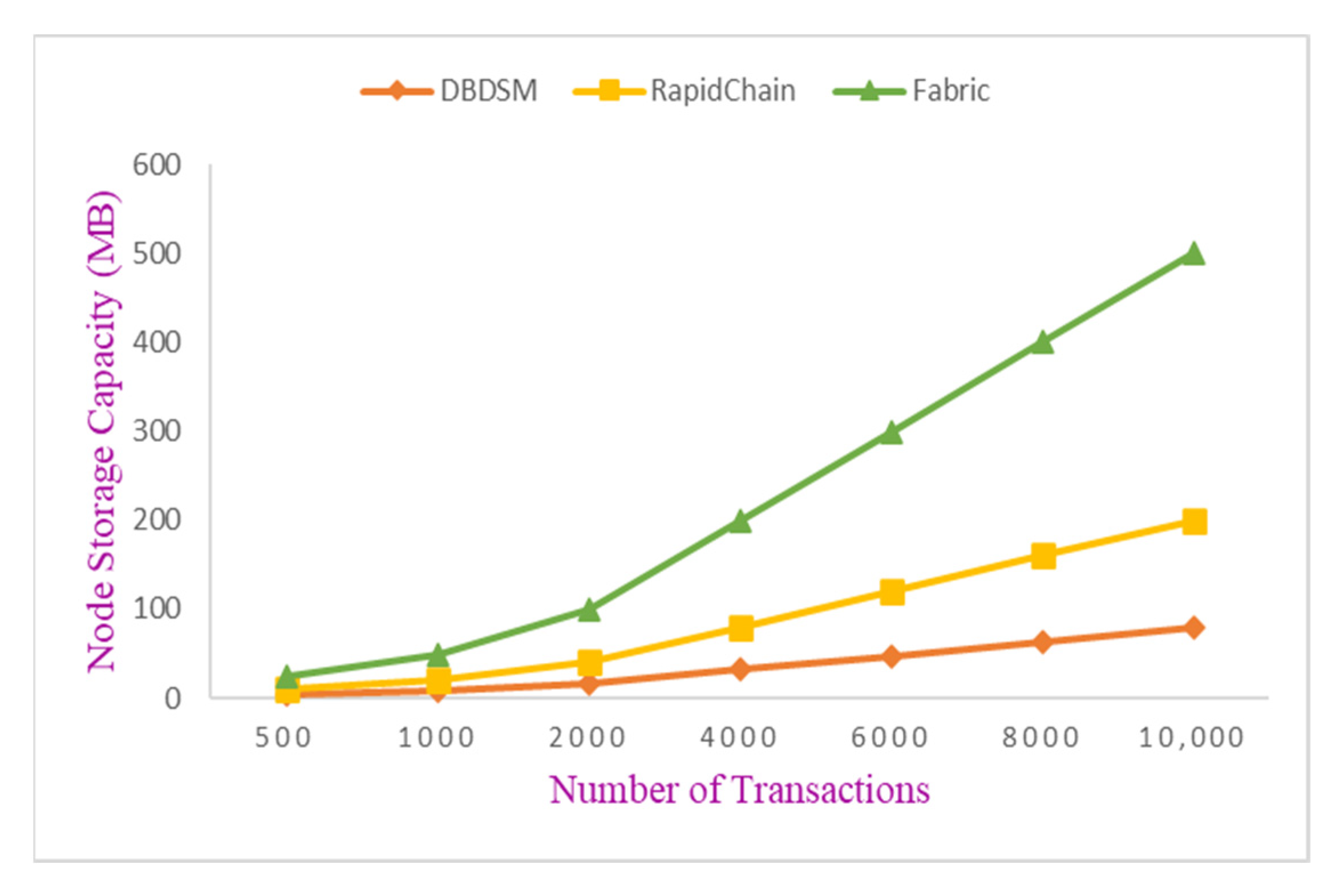
- Experiment 1: Single-node storage consumption.
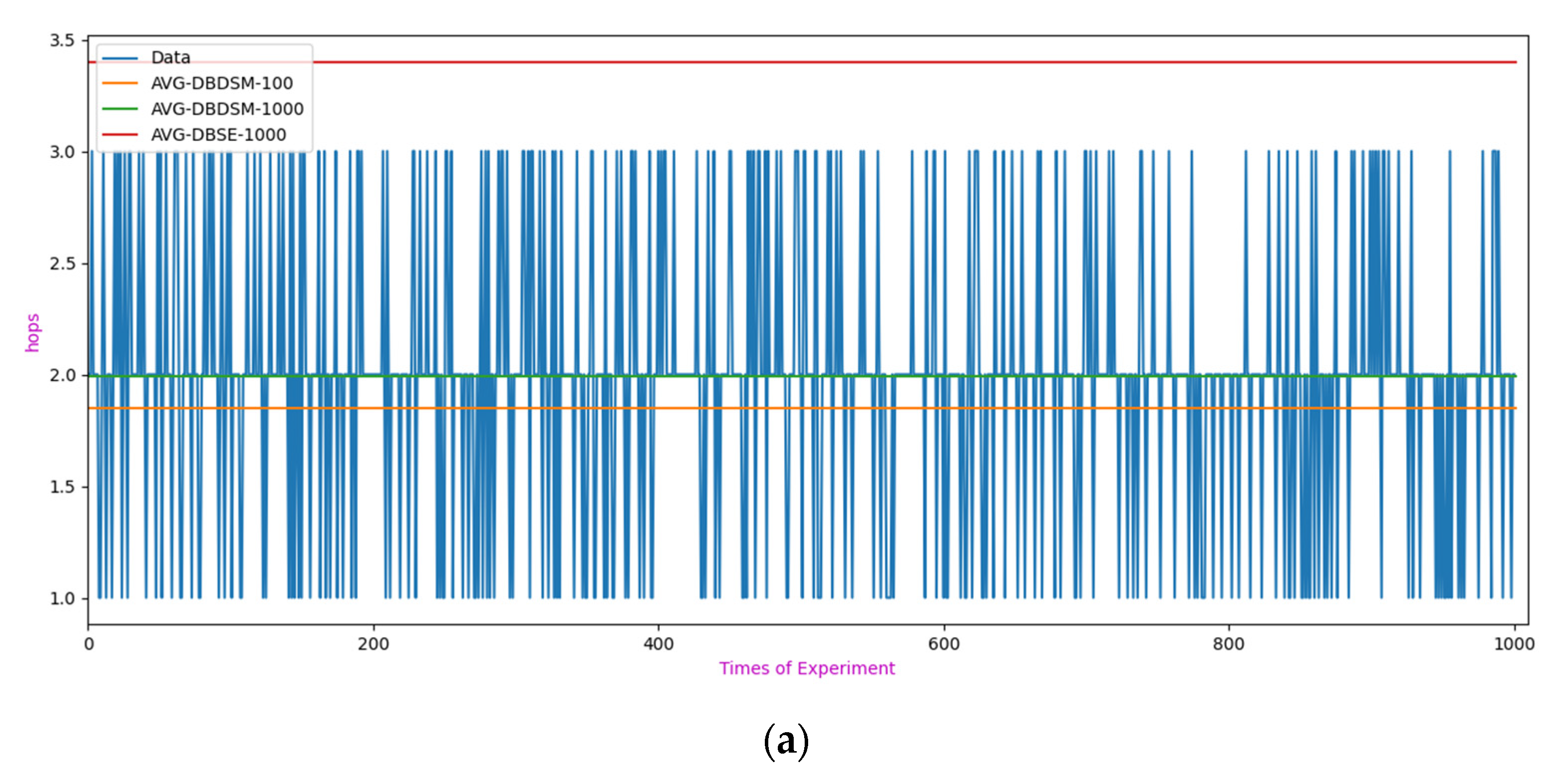
- Experiment 2: Query efficiency.
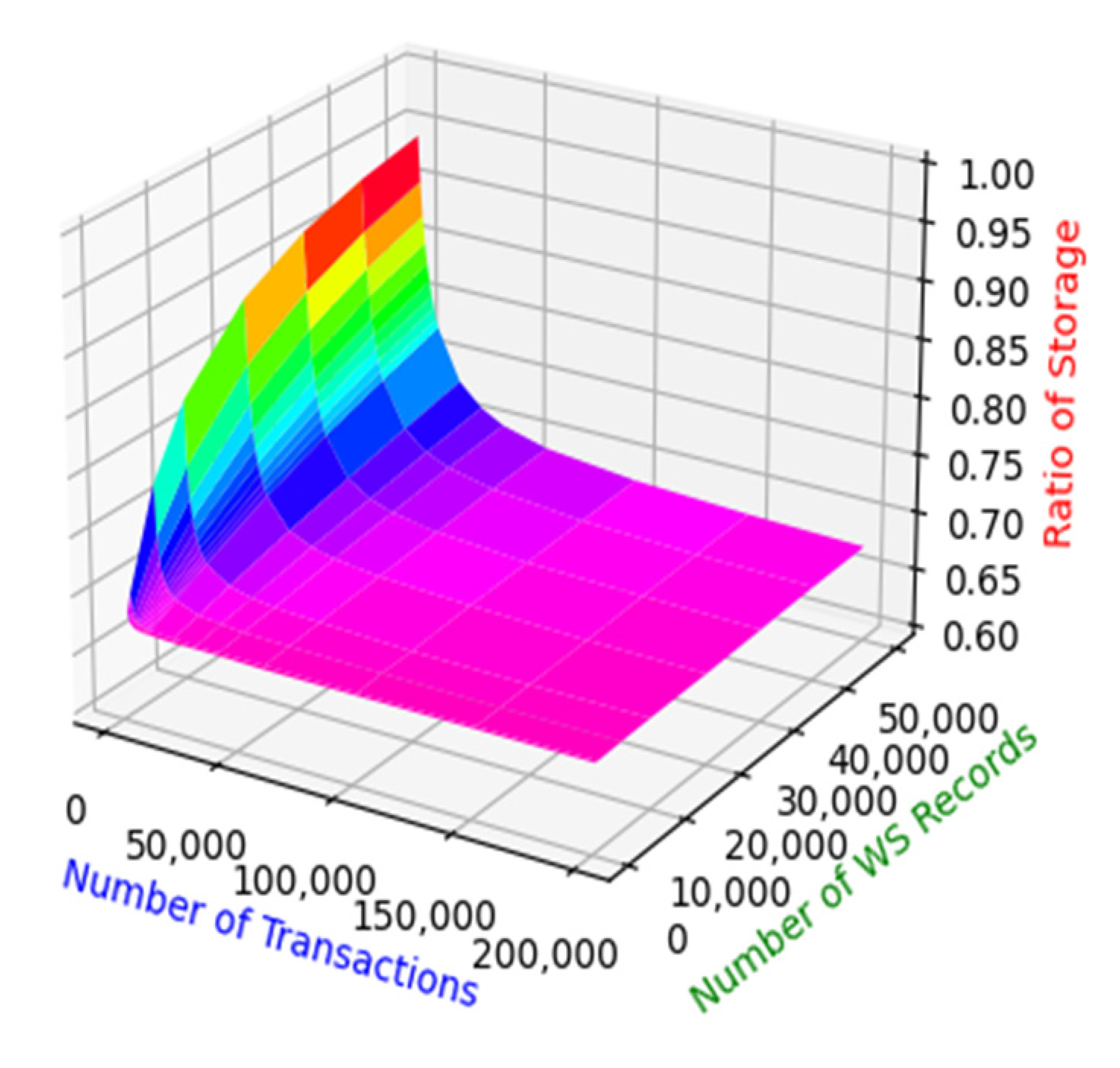
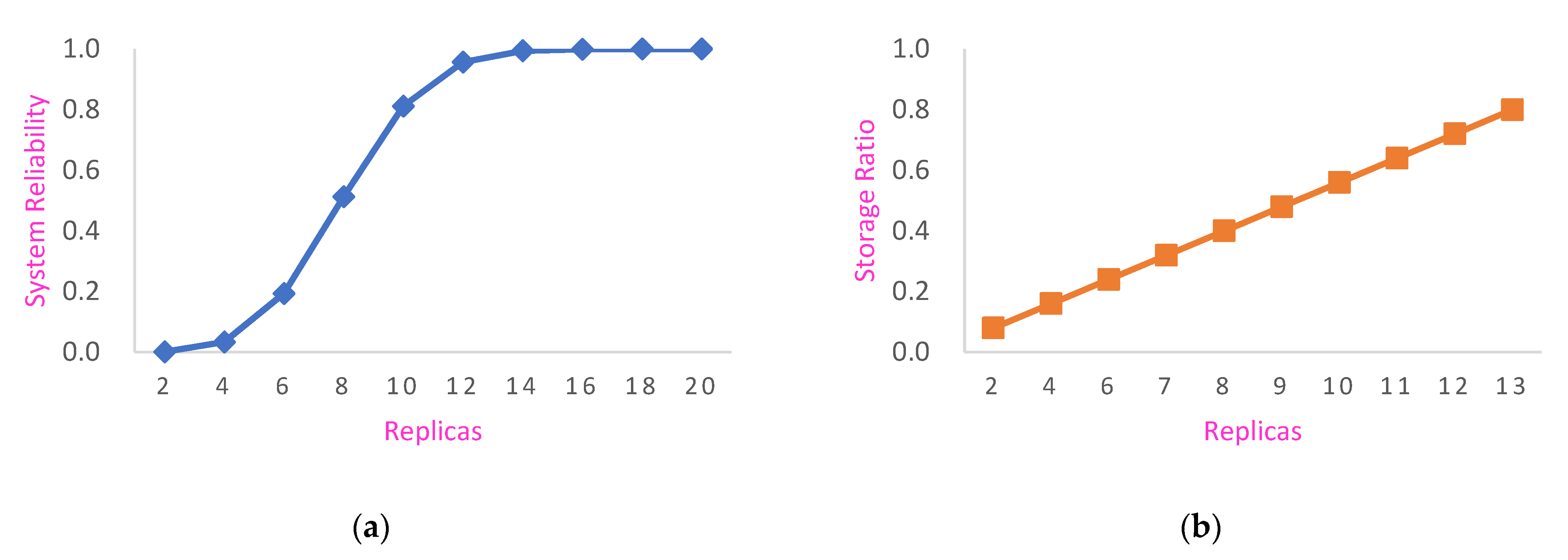
- Experiment 3: System reliability and node storage rate analysis.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Technical Report. 2019. Available online: https://bitcoin.org/en/bitcoin-paper (accessed on 6 May 2022).
- Labazova, O.; Dehling, T.; Sunyaev, A. From hype to reality: A taxonomy of blockchain applications. In Proceedings of the 52nd Hawaii International Conference on System Sciences (HICSS 2019), Grand Wailea, HI, USA, 8 January 2019. [Google Scholar]
- Wang, G.; Shi, Z.; Nixon, M.; Han, S. Chainsplitter: Towards blockchain-based industrial iot architecture for supporting hierarchical storage. In Proceedings of the 2019 IEEE International Conference on Blockchain (Blockchain), Atlanta, GA, USA, 14 July 2019; pp. 166–175. [Google Scholar]
- Zhang, Z.; Wang, G.; Xu, J.; Du, X. Survey on data management in blockchain systems. J. Softw. 2022, 31, 2903–2925. [Google Scholar]
- Banker, K.; Garrett, D.; Bakkum, P.; Verch, S. MongoDB in Action: Covers MongoDB Version 3.0. Simon and Schuster; Manning Publications: Greenwich, CT, USA, 2016. [Google Scholar]
- Yang, W.; Aghasian, E.; Garg, S.; Herbert, D.; Kang, B. A survey on blockchain-based internet service architecture: Requirements, challenges, trends, and future. IEEE Access 2019, 7, 75845–75872. [Google Scholar] [CrossRef]
- Luu, L.; Narayanan, V.; Zheng, C.; Baweja, K.; Saxena, P. A secure sharding protocol for open blockchains. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 17–30. [Google Scholar]
- Corbett, J.; Dean, J.; Epstein, M.; Andrew, F.; Christopher, F.; Furman, J.J.; Ghemavat, S.; Gubarev, A.; Heiser, C.; Hochschild, P.; et al. Spanner: Google’s globally distributed database. ACM Trans. Comput. Syst. (TOCS) 2013, 31, 1–22. [Google Scholar] [CrossRef]
- Glendenning, L.; Beschastnikh, I.; Krishnamurthy, A.; Anderson, T. Scalable consistency in scatter. In Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles, Cascais, Portugal, 23–26 October 2011; pp. 15–28. [Google Scholar]
- Danezis, G.; Meiklejohn, S. Centrally banked cryptocurr encies. arXiv 2015, arXiv:1505.06895. [Google Scholar]
- Huang, H.; Kong, W.; Peng, X.; Zheng, Z. A Survey on blockchain sharding. Comput. Eng. 2022, 8, 14155–14181. [Google Scholar]
- Jia, D.; Xin, J.; Wang, Z.; Wang, G. Optimized data storage method for sharding-based blockchain. IEEE Access 2021, 9, 67890–67900. [Google Scholar] [CrossRef]
- Stoica, I. Chord: A scalable peer-to-peer lookup protocol for Internet applications. IEEE/ACM Trans. Netw. 2003, 11, 17–32. [Google Scholar] [CrossRef]
- Corbett, J.C.; Dean, J.; Epstein, M.; Fikes, A.; Woodford, D. Spanner: Google’s globally-distributed database. ACM Trans. Comput. Syst. (TOCS) 2012, 31, 261–264. [Google Scholar]
- Fusion. Fusion: An Inclusive Cryptofinance Platform Based on Blockchains. Available online: http://docs.wixstatic.com/ugd/76b9ac_6919c49798d84a65bfb2e421cefbfbd3.pdf (accessed on 8 May 2022).
- Sun, Z.; Zhang, X.; Xiang, F.; Chen, L. Survey of storage scalability on blockchain. J. Softw. 2021, 32, 1–20. [Google Scholar]
- Kokoris-Kogias, E.; Jovanovic, P.; Gasser, L.; Gailly, N.; Syta, E.; Ford, B. OmniLedger: A secure, scale-out, decentralized ledger via sharding. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–23 May 2018; pp. 583–598. [Google Scholar]
- Chen, H.; Wang, Y. SSChain: A full sharding protocol for public blockchain without data migration overhead. Pervasive Mob. Comput. 2019, 59, 101055. [Google Scholar] [CrossRef]
- Jia, D.; Xin, J.; Wang, Z.; Guo, W.; Wang, G. ElasticChain: Support Very Large Blockchain by Reducing Data Redundancy; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Zamani, M.; Movahedi, M.; Raykova, M. RapidChain: Scaling Blockchain via Full Sharding. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security (CCS ’18), Toronto, ON, Canada, 15–19 October 2018; ACM: New York, NY, USA, 2019. 18p. [Google Scholar]
- Wang, J.; Wang, H. Monoxide: Scale out blockchains with asyn-chronous consensus zones. In Proceedings of the 16th Usenix Symposium on Networked Systems Design and Implementation (NSDI), Boston, MA, USA, 26–28 February 2019; pp. 95–112. [Google Scholar]
- Xie, J.; Li, Z.; Jin, J.; Zhang, B.; Hua, Y. Research on blockchain storage extension based on DHT. In Proceedings of the 2021 4th International Conference on Big Data Technologies (ICBDT) (ICBDT 2021), Zibo, China, 24–26 September 2021; ACM: New York, NY, USA, 2021; pp. 79–85. [Google Scholar]
- Fan, X.; Niu, B.; Liu, Z. Scalable blockchain storage systems: Research progress and models. Computing 2022, 104, 1497–1524. [Google Scholar] [CrossRef]
- Buterin, V. Thoughts on UTXOs. Available online: https://medium.com/@ConsenSys/thoughts-on-utxo-by-vitalik-buterin-2bb782c67e53. (accessed on 6 May 2022).
- Zheng, P.; Xu, Q.; Zheng, Z.; Zhou, Z.; Zhang, H. Meepo: Sharded Consortium Blockchain. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021. [Google Scholar]
- Hong, L.; Huang, T.P.; Zou, W.X.; Li, S.R.; Zhou, Z. Research of AODV routing protocol based on link availability prediction. J. Commun. 2008, 2008, 118–123. [Google Scholar]
- Handurukande, S.B.; Kermarrec, A.M.; Fessant, F.L.; Massoulié, L.; Patarin, S. Peer sharing behaviour in the eDonkey network, and implications for the design of server-less file sharing systems. In Proceedings of the 1st ACM SIGOPS/EuroSys European Conference on Computer Systems, Leuven, Belgium, 18–21 April 2006; Volume 40, pp. 359–371. [Google Scholar]
- Xu, J. Research on Data Reliability in Peer-to-Peer Networks Storage System; Harbin Engineering University: Harbin, China, 2011. [Google Scholar]
- Deepa, N.; Pham, Q.V.; Nguyen, D.C.; Bhattacharya, S.; Prabadevi, B.; Gadekallu, T.R.; Maddikunta, P.K.; Fang, F.; Pathirana, P.N. A survey on blockchain for big data: Approaches, opportunities, and future directions. Future Gener. Comput. Syst. 2022, 131, 209–226. [Google Scholar] [CrossRef]
- Hashim, F.; Shuaib, K.; Sallabi, F. Medshard: Electronic health record sharing using blockchain sharding. Sustainability 2021, 13, 5889. [Google Scholar] [CrossRef]
- Cai, X.; Geng, S.; Zhang, J.; Wu, D.; Cui, Z.; Zhang, W.; Chen, J. A sharding scheme-based many-objective optimization al-gorithm for enhancing security in blockchain-enabled industrial internet of things. IEEE Trans. Ind. Inform. 2021, 17, 7650–7658. [Google Scholar] [CrossRef]
- Asheralieva, A.; Niyato, D. Reputation-based coalition formation for secure self-organized and scalable sharding in iot blockchains with mobile-edge computing. IEEE Internet Things J. 2020, 7, 11830–11850. [Google Scholar] [CrossRef]
- Tao, L.; Lu, Y.; Ding, X.; Fan, Y.; Kim, J.Y. Throughput-oriented associated transaction assignment in sharding blockchains for IoT social data storage. Digit. Commun. Netw. 2022; in press. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, R.; Yu, F.R.; Li, M.; Zhang, Y.; Teng, Y. Sharded Blockchain for Collaborative Computing in the Internet of Things: Combined of Dynamic Clustering and Deep Reinforcement Learning Approach. IEEE Internet Things J. 2022, 9, 16494–16509. [Google Scholar] [CrossRef]
- Aiyar, K.; Halgamuge, M.N.; Mohammad, A. Probability distribution model to analyze the trade-off between scalability and security of sharding-based blockchain networks. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications & Net-working Conference (CCNC), Las Vegas, NV, USA, 9 January 2021; pp. 1–6. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
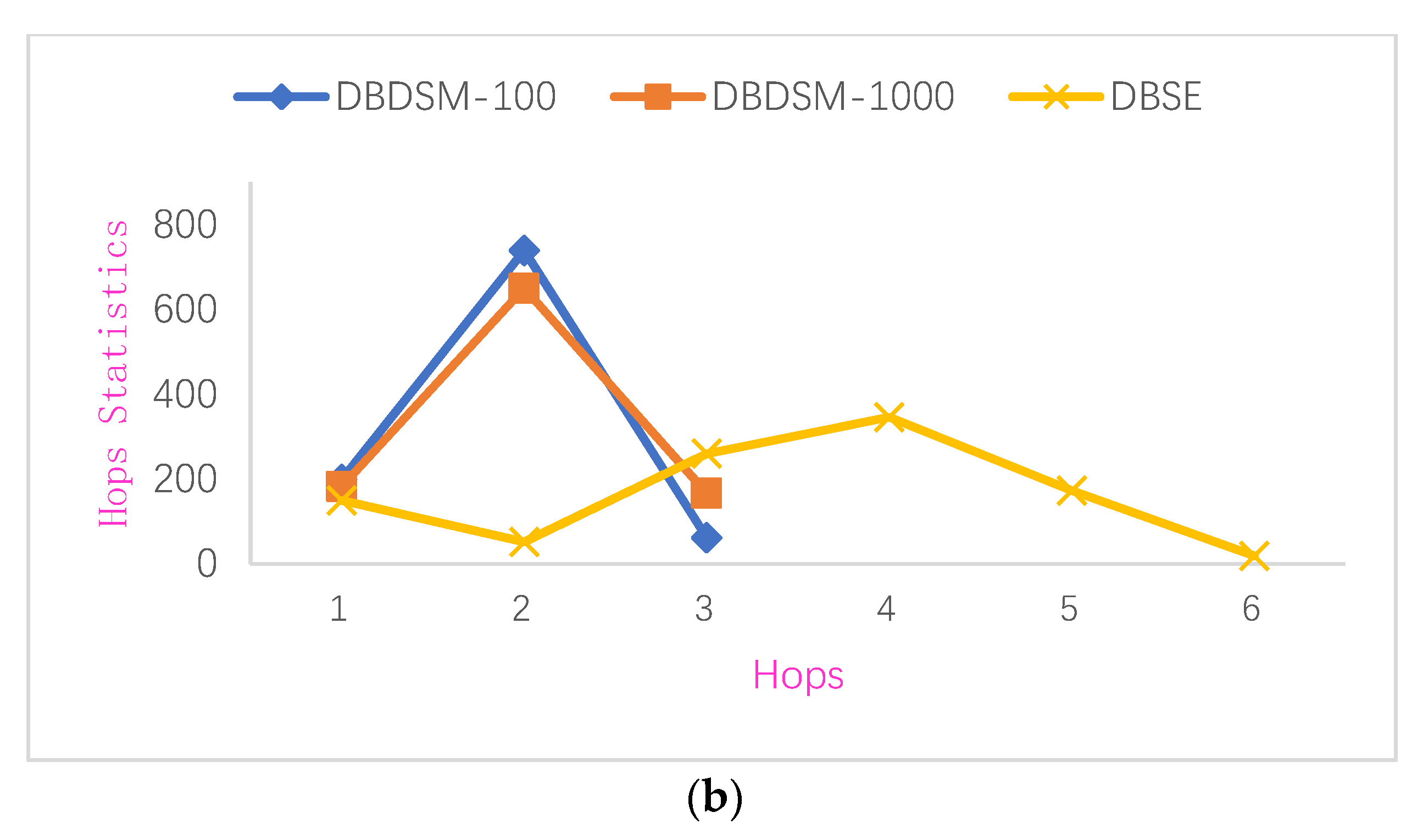
| Hops | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| Model Frequency | |||||||
| DBSE | 150 | 52 | 260 | 346 | 173 | 19 | |
| DBDSM-100 | 199 | 739 | 62 | 0 | 0 | 0 | |
| DBDSM-1000 | 183 | 650 | 167 | 0 | 0 | 0 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Zhang, D.; Liu, W.; Qiu, X.; Brusic, V. DHT-Based Blockchain Dual-Sharding Storage Extension Mechanism. Appl. Sci. 2022, 12, 9635. https://doi.org/10.3390/app12199635
Zhao J, Zhang D, Liu W, Qiu X, Brusic V. DHT-Based Blockchain Dual-Sharding Storage Extension Mechanism. Applied Sciences. 2022; 12(19):9635. https://doi.org/10.3390/app12199635
Chicago/Turabian StyleZhao, Jindong, Donghong Zhang, Wenxuan Liu, Xiuqin Qiu, and Vladimir Brusic. 2022. "DHT-Based Blockchain Dual-Sharding Storage Extension Mechanism" Applied Sciences 12, no. 19: 9635. https://doi.org/10.3390/app12199635
APA StyleZhao, J., Zhang, D., Liu, W., Qiu, X., & Brusic, V. (2022). DHT-Based Blockchain Dual-Sharding Storage Extension Mechanism. Applied Sciences, 12(19), 9635. https://doi.org/10.3390/app12199635