


Image-Caption Model Based on Fusion Feature

Abstract
:1. Introduction
- (1)
- The grid-level features of an image are extracted by a Res-Net101 with squeeze and excitation operations. The GCN extracts the region-level features. The feature-fusion module weights fusion of the two features of the joint attention mechanism to learn image features and semantic information better.
- (2)
- Fusion-feature vectors are processed by a two-layer LSTM, which adds an attention mechanism to obtain the context information of the heading and dramatically improves the quality of the heading.
- (3)
- The algorithm was trained and tested, and the experimental results show that the algorithm achieved excellent performance.
2. Related Work
2.1. Image Captioning
2.2. Grid-Level Feature
2.3. Region-Level Feature
3. Models and Methods
3.1. Encoder
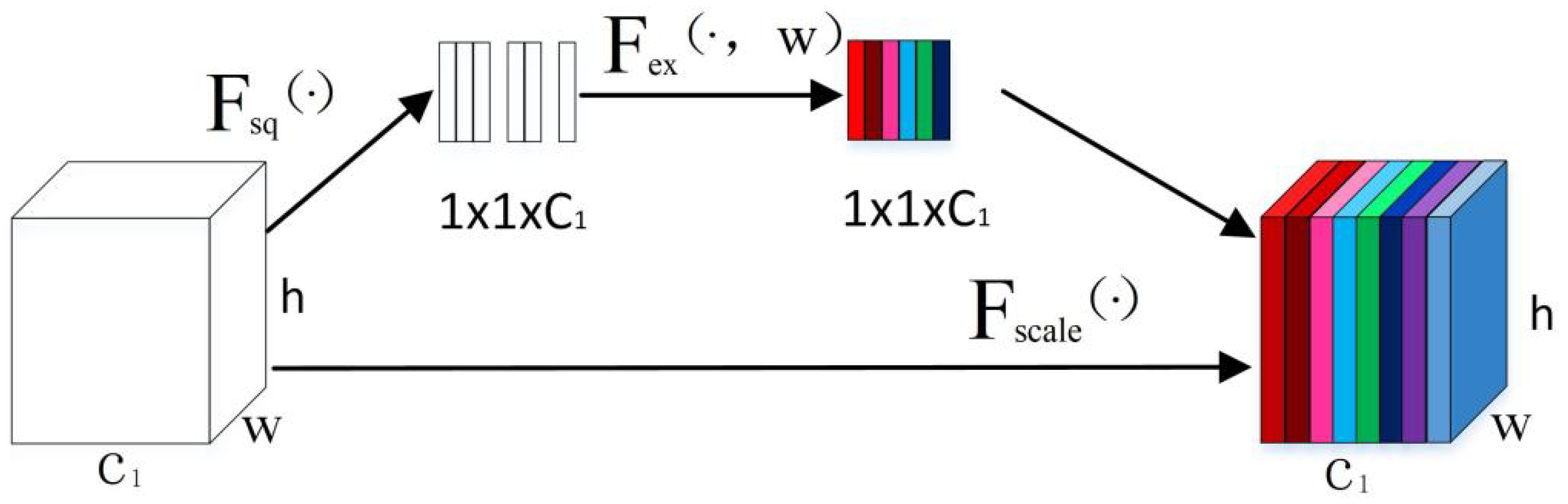
3.1.1. Squeeze and Excitation Module (SE)
3.1.2. Node Embedding (NE) Module
3.1.3. Feature-Fusion Module
3.2. Decoder
3.3. Dataset, Evaluation, and Loss Function
4. Results
4.1. Experimental Environment
4.2. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Farhadi, A.; Hejrati, M.; Sadeghi, M.A.; Young, P.; Rashtchian, C.; Hockenmaier, J.; Forsyth, D. Every picture tells a story: Generating sentences from images. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 15–29. [Google Scholar]
- Kulkarni, G.; Premraj, V.; Ordonez, V.; Dhar, S.; Li, S.; Choi, Y.; Berg, A.C.; Berg, T.L. Babytalk: Understanding and generating simple image descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2891–2903. [Google Scholar] [CrossRef]
- Kuznetsova, P.; Ordonez, V.; Berg, A.; Berg, T.; Choi, Y. Collective generation of natural image descriptions. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Jeju, Korea, 8–14 July 2012; pp. 359–368. [Google Scholar]
- Ordonez, V.; Kulkarni, G.; Berg, T. Im2text: Describing images using 1 million captioned photographs. Adv. Neural Inf. Process. Syst. 2011, 24, 1143–1151. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image caption generationing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 375–383. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image caption generationing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Wu, Q.; Shen, C.; Liu, L.; Dick, A.; Van Den Hengel, A. What value do explicit high level concepts have in vision to language problems? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 203–212. [Google Scholar]
- Tanti, M.; Gatt, A.; Camilleri, K.P. What is the role of recurrent neural networks (rnns) in an image caption generation generator? arXiv 2017, arXiv:1708.02043. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Hierarchy parsing for image caption generationing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 2621–2629. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring visual relationship for image captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 684–699. [Google Scholar]
- Shi, Z.; Zhou, X.; Qiu, X. Improving image caption generationing with Better Use of Captions. arXiv 2020, arXiv:2006.11807. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Ding, S.; Qu, S.; Xi, Y.; Sangaiah, A.K.; Wan, S. image caption generation generation with high-level image features. Pattern Recognit. Lett. 2019, 123, 89–95. [Google Scholar] [CrossRef]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-memory transformer for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10578–10587. [Google Scholar]
- Ke, L.; Pei, W.; Li, R. Reflective decoding network for image caption generationing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 8888–8897. [Google Scholar]
- Li, G.; Zhu, L.; Liu, P.; Yang, Y. Entangled transformer for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 8928–8937. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar]
- Luo, Y.; Ji, J.; Sun, X.; Cao, L.; Wu, Y.; Huang, F.; Lin, C.W.; Ji, R. Dual-level collaborative transformer for image captioning. arXiv 2021, arXiv:2101.06462. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BLEU-1 | BLEU-4 | CIDEr | METEOR | ROUGE-L | |
|---|---|---|---|---|---|
| High-Level Attention, 2019 [20] | 0.746 | 0.317 | 1.103 | 0.265 | 0.535 |
| CGVRG, 2020 [15] | 0.814 | 0.386 | 1.267 | 0.286 | 0.588 |
| M2-Transformer, 2020 [21] | 0.816 | 0.397 | 1.293 | 0.294 | 0.592 |
| RDN, 2019 [22] | 0.775 | 0.368 | 1.153 | 0.272 | 0.568 |
| Entangle-Transformer, 2019 [23] | 0.776 | 0.378 | 1.193 | 0.284 | 0.574 |
| DLCT, 2021 [24] | 0.816 | 0.392 | 1.297 | 0.298 | 0.598 |
| Ours | 0.821 | 0.399 | 1.311 | 0.297 | 0.601 |
| BLEU-1 | BLEU-4 | CIDEr | METEOR | ROUGE-L | |
|---|---|---|---|---|---|
| CNN–LSTM | 0.666 | 0.246 | 0.862 | 0.201 | - |
| CNN–LSTM–Attention | 0.726 | 0.310 | 0.920 | 0.235 | - |
| GCN–LSTM | 0.808 | 0.387 | 1.253 | 0.285 | 0.585 |
| GCN–LSTM–Attention | 0.816 | 0.393 | 1.279 | 0.288 | 0.590 |
| Grid + Regionadd | 0.801 | 0.344 | 1.237 | 0.273 | 0.577 |
| Grid + Regionmul | 0.811 | 0.389 | 1.271 | 0.280 | 0.591 |
| Grid + Regionconcat | 0.821 | 0.399 | 1.311 | 0.297 | 0.601 |
| BLEU-4 | CIDEr | |
|---|---|---|
| Baseline | 0.792 | 1.183 |
| Grid + Region + SE | 0.797 | 1.199 |
| Grid + Region + NE | 0.802 | 1.217 |
| Grid + Region + Att | 0.811 | 1.233 |
| Grid + Region + SE + NE | 0.807 | 1.229 |
| Grid + Region + SE + Att | 0.818 | 1.253 |
| Grid + Region + NE + Att | 0.816 | 1.267 |
| Grid + Region + SE + NE + Att | 0.821 | 1.311 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Geng, Y.; Mei, H.; Xue, X.; Zhang, X. Image-Caption Model Based on Fusion Feature. Appl. Sci. 2022, 12, 9861. https://doi.org/10.3390/app12199861
Geng Y, Mei H, Xue X, Zhang X. Image-Caption Model Based on Fusion Feature. Applied Sciences. 2022; 12(19):9861. https://doi.org/10.3390/app12199861
Chicago/Turabian StyleGeng, Yaogang, Hongyan Mei, Xiaorong Xue, and Xing Zhang. 2022. "Image-Caption Model Based on Fusion Feature" Applied Sciences 12, no. 19: 9861. https://doi.org/10.3390/app12199861
APA StyleGeng, Y., Mei, H., Xue, X., & Zhang, X. (2022). Image-Caption Model Based on Fusion Feature. Applied Sciences, 12(19), 9861. https://doi.org/10.3390/app12199861