In this section, we apply the previously mentioned algorithms for AC signal analysis to a multisine signal consisting of the sum of 4 sinewaves with arbitrary amplitudes and phases based on matrix measurements of [
33]. The sampling frequency is set to 500 kHz. The properties of the signals are shown in
Table 6. The number of samples is set to a constant 2048.
The analysis follows in five different setups. The first platform is a reference to provide information on the performance of the methods on a generic computer. It consists of a generic Windows personal computer with a CPU Intel Core (TM) i7-7700HQ @ 2.80 GHz and 16 GB RAM. The CPU supports several SIMD instructions, including SSE2 and AVX instructions, which provide hardware acceleration to MATLAB code thanks to Intel Math Kernel Library (MKL) and FFTW-3.3.3-SSE2-AVX library. For a second reference, the codes are reimplemented in C using Visual C++, which uses a compiler optimization for the hardware.
The second platform is the STM32-based evaluation board STM32H743Zi. It features an Arm Cortex-M7 CPU clocked at 480 MHz, which is coupled with 1MB RAM. The built-in ADC is capable of a sampling rate of at 4 MSps, with at least sub GHz-bandwidth [
34]. In this platform, two environments are used: The first one features the computation of algorithms with double-precision floating points. The methods are written in C and compiled in MCU GCC Compiler with no further optimization or hardware acceleration aside from compiler’s. In a second environment, Cortex Microcontroller Software Interface Standard (CMSIS) instructions were used to speed up the computation. The CMSIS-DSP library for Cortex-M7 for single-precision floating points calculations was used to calculate SIMD instructions when possible. The third platform is Teensy 3.6, which is programmed using Teensyduino, a software package for Arduino IDE. It features a Cortex-M4 CPU clocked at 180 MHz and 256 kB RAM. The built-in ADC is capable of a sampling rate of sub-MHz range, with a bandwidth of sub-GHz range. It is worth noting that for both microcontrollers and according to the Nyquist criteria, the maximum frequency should be less than half the sampling rate.
All the decimals are stored and processed as double-precision floating points unless otherwise noted. As CMSIS-DSP only supports single-precision floating-point, the decimals are implemented with single-precision floating-point. In most cases in native STM32 C code, we found that the native double-based trigonometric functions are faster than single float-based trigonometric functions. Further implementation details are discussed in this section.
The FFT is implemented using the FFTW library in MATLAB 2021a, Radix-2 in Visual C++, and STM32/Teensy Native code, and using a mixed-radix based on Radix-8 on CMSIS-DSP implementation. Cross-correlation was implemented with a lookup table (LUT) in all the implementations. Moreover, cross-correlation without LUT was proven to be more efficient only in STM32 native C, as explained in the next sections. The curve fitting was implemented with double precision in generic computing and both single and double precision in STM32 native C. In CMSIS-DSP, only the supported single-precision floating-point was used. DTFT was implemented with a LUT in generic computing and CMSIS-DSP and both with and without it in Native C.
Finally, MATLAB and CMSIS-DSP data are always vectorized, i.e., with lookup tables whenever possible, to enable hardware acceleration through SIMD instructions. In STM32 native C code, the trigonometric functions from the math library were used, while in the DSP-CMSIS library, the Arm-exclusive trigonometric functions were used instead. The methods were run multiple times. A total memory clear and removal of memory cache was ensured between runs by restarting the program/device several times.
4.1. Processing Time
In
Section 3.1, the asymptotic complexity and the expected runtime as a function of the number of samples and frequency components were presented. However, as mentioned before, the actual processing time may differ due to the different optimization on the hardware/software side.
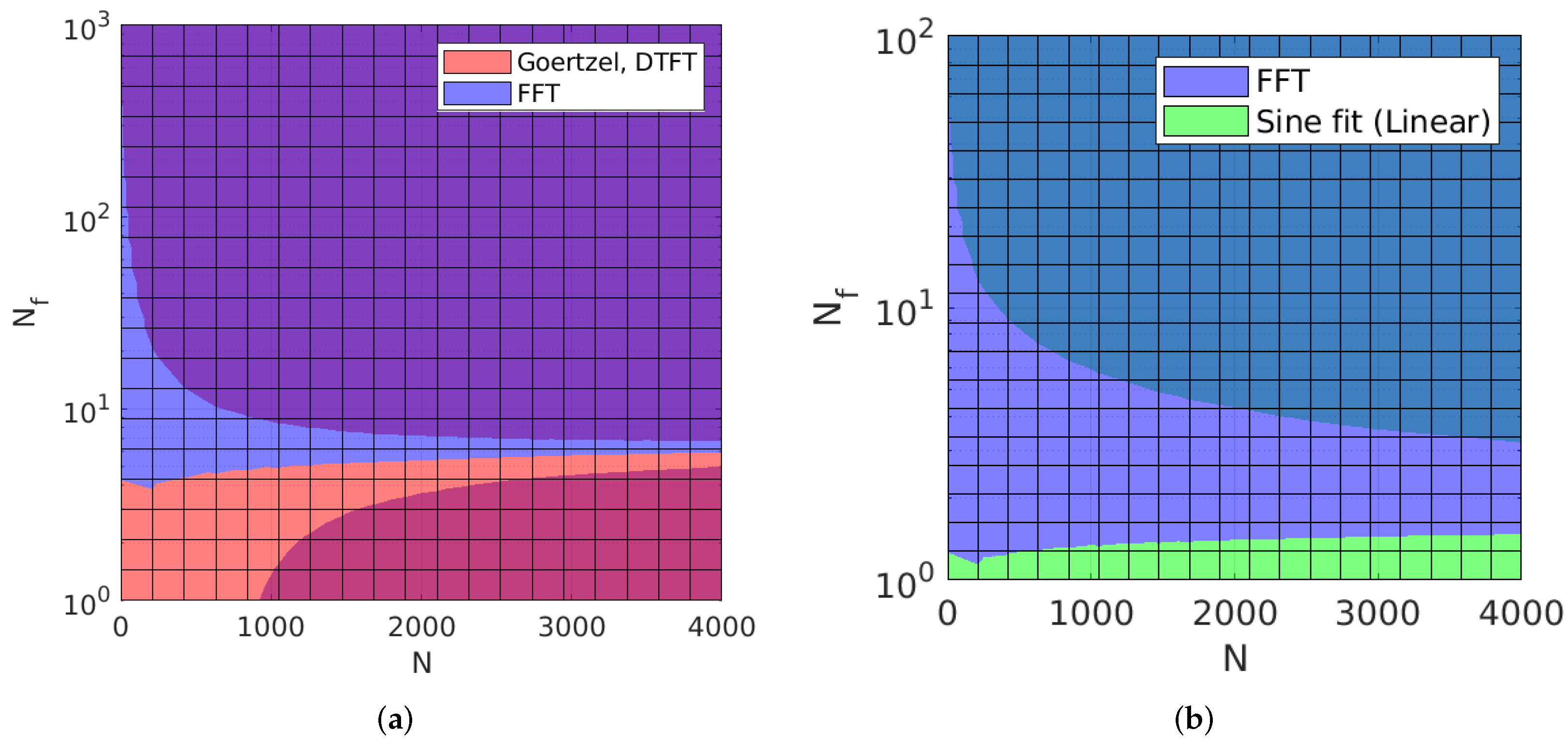
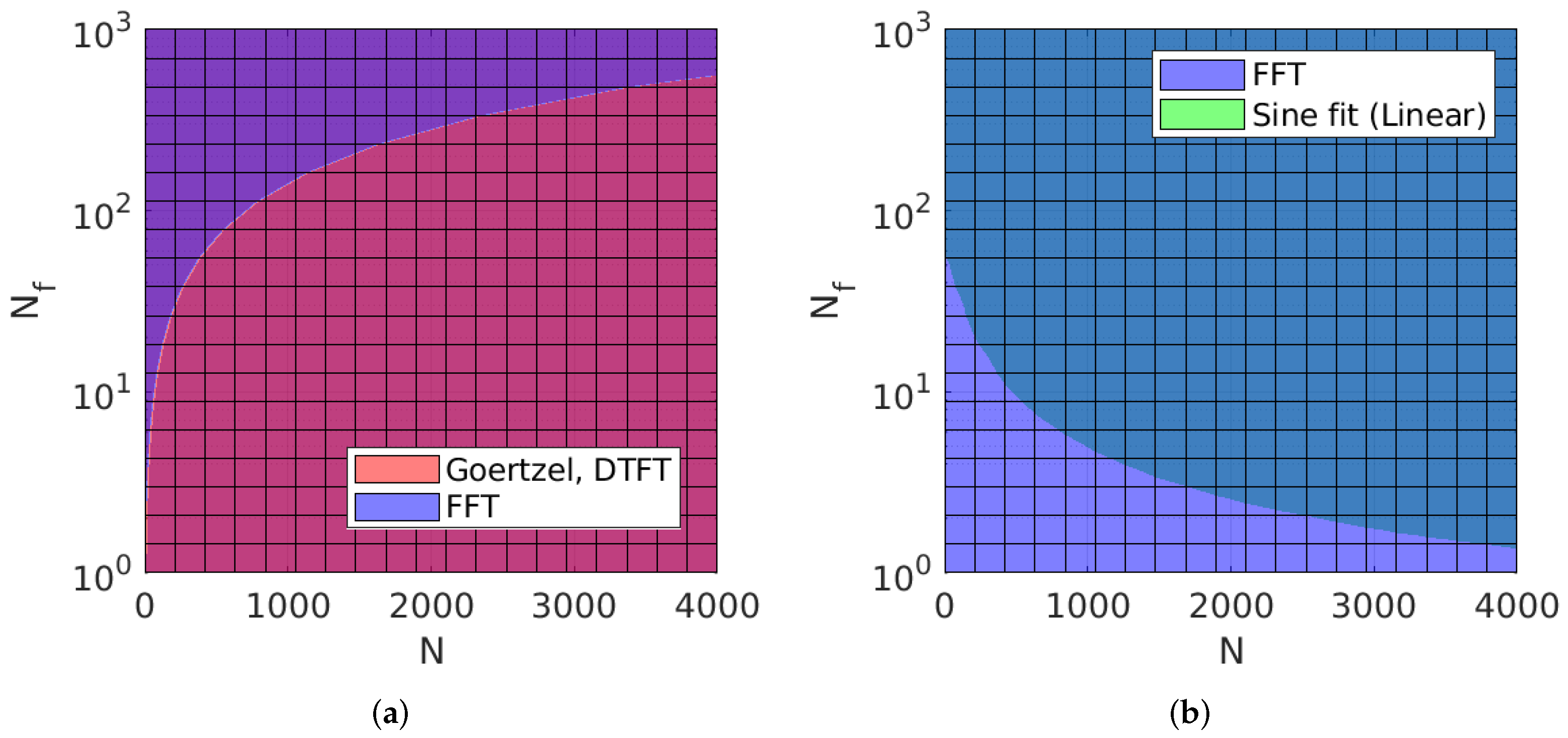
According to
Section 3.1, the proposed scenario falls in the ambiguous region where Goertzel, DTFT, and FFT should have similar asymptotic computations, with an advantage for Goertzel and DTFT. They are then followed by linear sine-fit, nonlinear sine-fit, and cross-correlation ranked according to their ascending computational complexity. Nevertheless, it is important to consider the number of iterations, including overhead operations before or during the calculation process. This includes the computation of look-up tables, twiddle factors, and the computation of in-place coefficients for each algorithm. In fact, DTFT actually requires
up to
per iteration, while FFT Radix 2 only requires
. Therefore, for this test scenario,
operations are required for the FFT and
–
operations for the DTFT. The Goertzel filter requires only
operations per iteration, resulting in
total operations, which should make it the fastest algorithm for this test scenario.
As shown in
Table 7, MATLAB results show that FFT is the fastest owing to the optimized FFTW3 library with a total processing time of 0.51 ms, followed by Goertzel (7.92 ms), then sine-fit linear (8.02 ms), then DTFT (10.98 ms), then cross-correlation (76.64 ms), and finally sine-fit (non-linear) (91.08 ms).
On the other hand, the results of Visual C++ match the expected theoretical results, as Goertzel filter is the fastest with 0.51 ms processing time, followed by FFT (0.81 ms), then DTFT (0.92 ms), then Sine-fit (2.1 ms), then sine-fit non-linear (70.39 ms), and finally cross-correlation (377.95 ms).
Table 8 shows the comparison between the native double-precision code implementation of the algorithm in STM32, native code implementation in Teensy, and STM32 optimized using CMSIS DSP library. In STM32 native implementation, Goertzel is the fastest algorithm with 21 ms runtime, followed by FFT with 99 ms, then DTFT with 132 ms, then sine-fit (linear) with 638 ms, then sine-fit (non-linear) with 58 s, and finally cross-correlation with 67 s. The same rank is seen for Teensy 3.6 implementation. However, this rank changes when the methods are implemented using CMSIS-DSP on STM32: FFT is the fastest with 8 ms runtime, followed by Goertzel with 18 ms, then DTFT with 28 ms, then sine-fit (linear) with 139 ms, then cross-correlation with 4 s, and finally sine-fit (non-linear) with 12 s.
At this point, it can be stated that the influence of hardware and software should not be underestimated. However, for native PC (Visual C++) and embedded implementations, the rank of each method is the same on each platform, which is consistent with the theoretical values in
Figure 6. For the hardware-accelerated CMSIS implementation, the mixed radix implementation together with hardware acceleration was able to push DTFT behind FFT. Finally, during the experimentation, we noticed that all algorithms showed a slowdown when implemented with single-precision float functions, i.e., cosf and sinf, and that the CMSIS DSP library provides the fastest solutions for trigonometric operations.
As a partial conclusion: For this or a similar scenario, when the number of frequencies is small and when using a hardware-accelerated calculation, FFT is the fastest option for AC signal analysis. Second to FFT is the Goertzel filter, which is relatively fast in both hardware-accelerated generic and embedded computing systems and is slightly faster than DTFT. In a native implementation scenario, i.e., with no to less hardware acceleration, Goertzel performs the fastest, which is confirmed in both PC (Visual C++) and STM32/Teensyduino implementations. While DTFT’s trigonometric solution is accelerated in PCs, its embedded implementation counterpart lags behind. For this reason, DTFT is considered less efficient than FFT for embedded systems with the same or similar specifications for this test scenario.
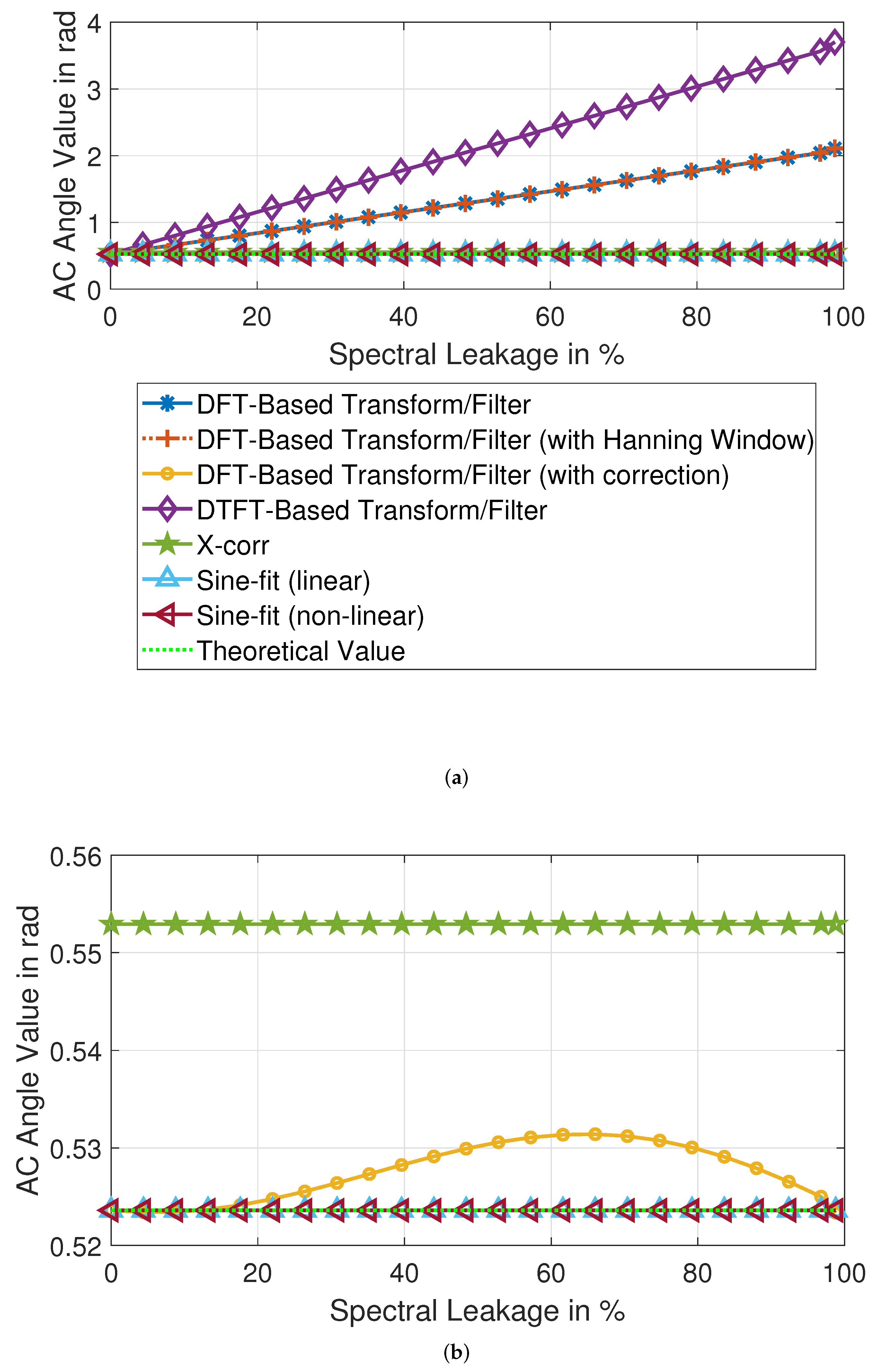
4.3. AC Signal Analysis Precision
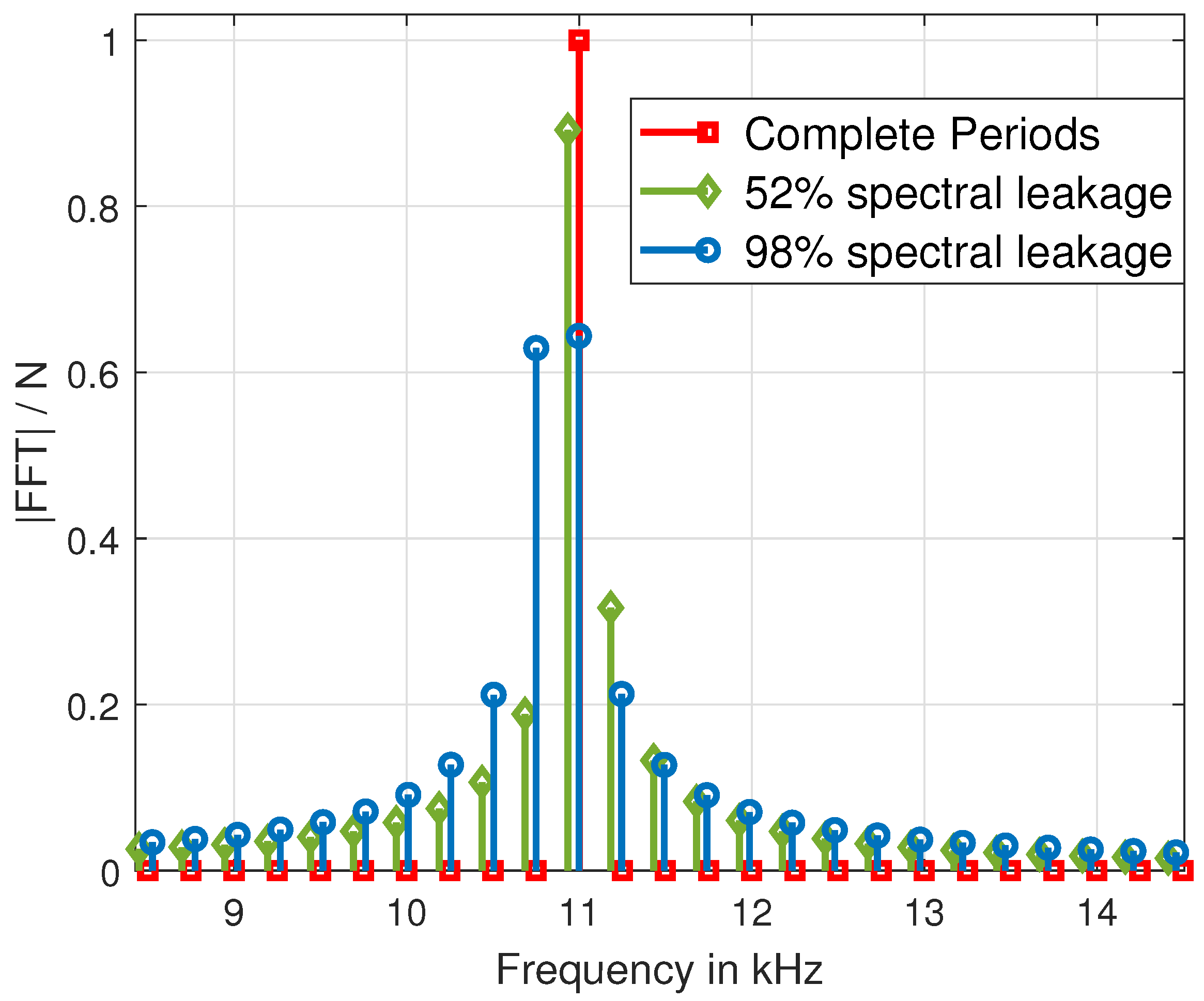
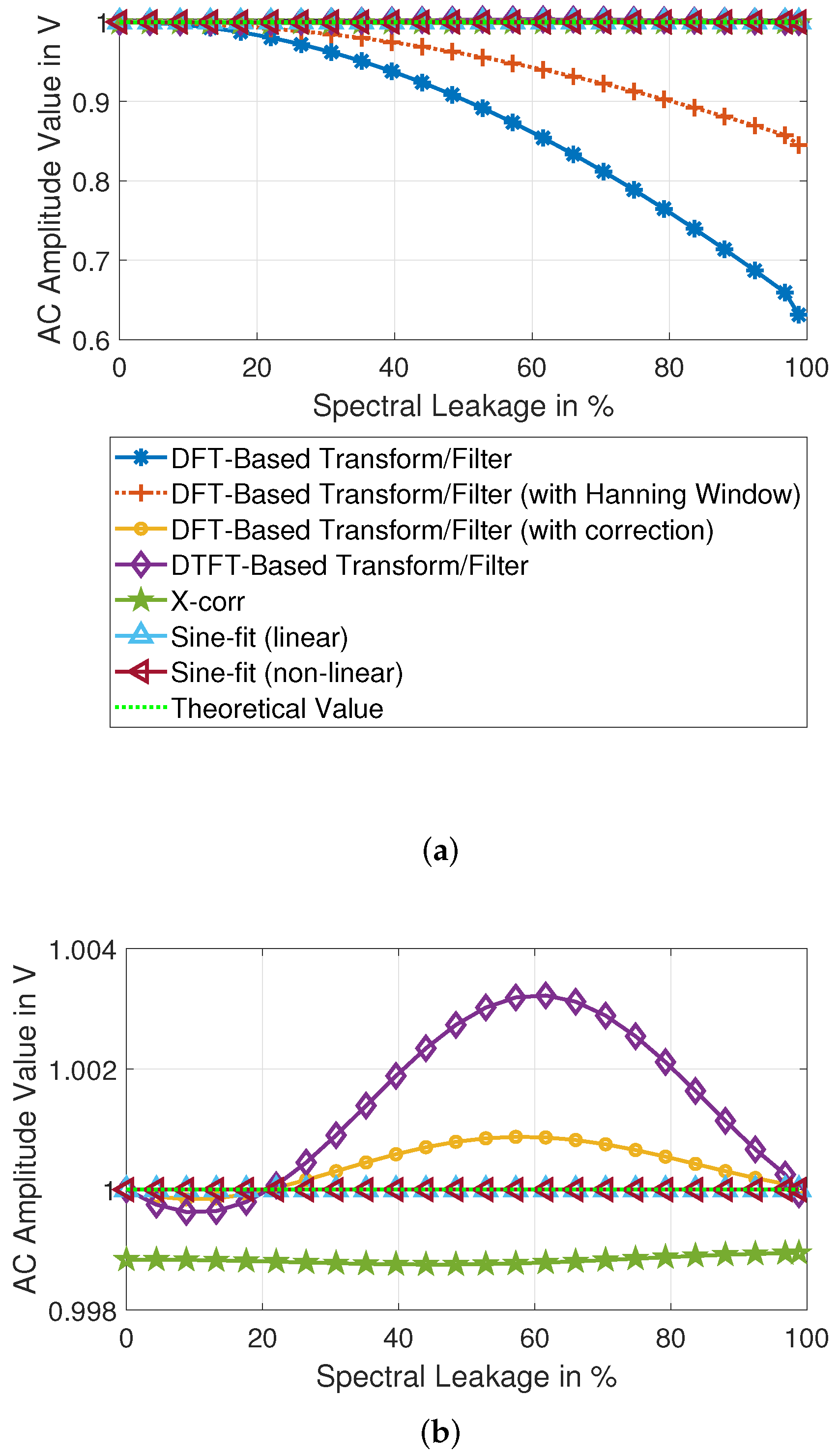
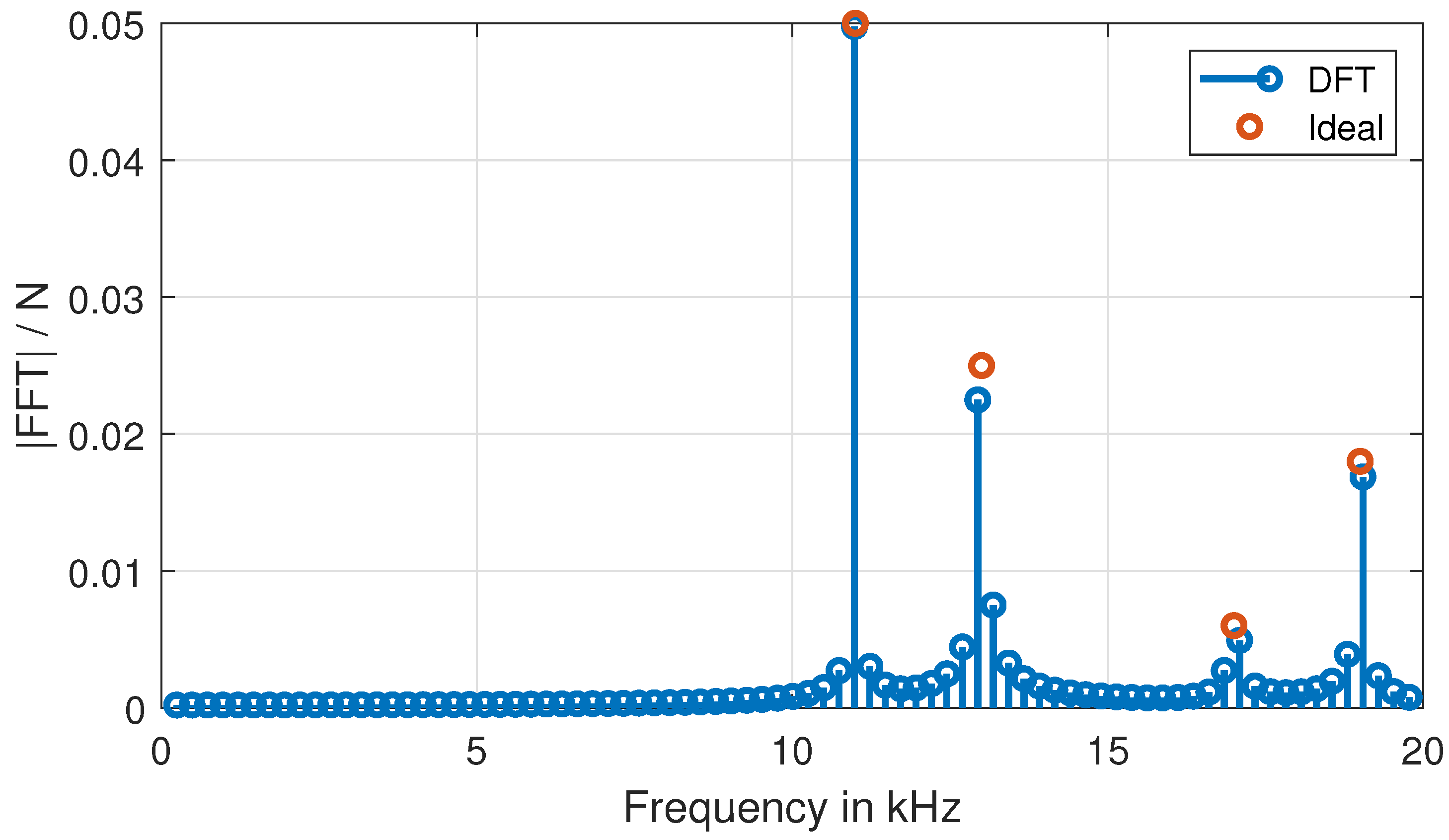
This paragraph examines the results of the analysis of the test scenario. As shown in
Table 10 and
Table 11, the spectral leakage has a significant impact on the accuracy of the results. DFT-based methods are the most affected by spectral leakage. The influence of the more significant spectral dispersion is still strong despite the corrections. This can be mainly seen in the results of the third and fourth sine signals, as shown in
Figure 7. DTFT and cross-correlation gave very similar results, but it clearly shows that in AC signal analysis with cross-correlation of the third sine, which has the lowest amplitude, is worse than the other sines. On the other hand, sine-fitting methods deliver flawless amplitude results. Overall, sine-fitting and DFT with correction are among the better solutions.
The phase analysis, as shown in
Table 11, shows similar deviation results as the amplitude. The DFT is strongly influenced by spectral leakage, and despite the correction, the deviations of all signals are still to be classified as high. DTFT shows better results, in this case, thanks to the lower influence of the other signals. The phases calculated by cross-correlation show a significant deviation from the expected ones, with all different phases being wrong except for the first and fourth signals. The sine fitting gave perfect results. It can be concluded that sine fitting methods are the best solution, with DTFT and FFT (with correction) being the runners-up.
4.4. Discussion
The choice of the platform and tool comes first. The hardware-accelerated implementation not only speeds up but also enables the application of sophisticated methods such as sine fitting in both linear and non-linear methods. In general, vectorizing the results results in a faster execution but more memory consumption.
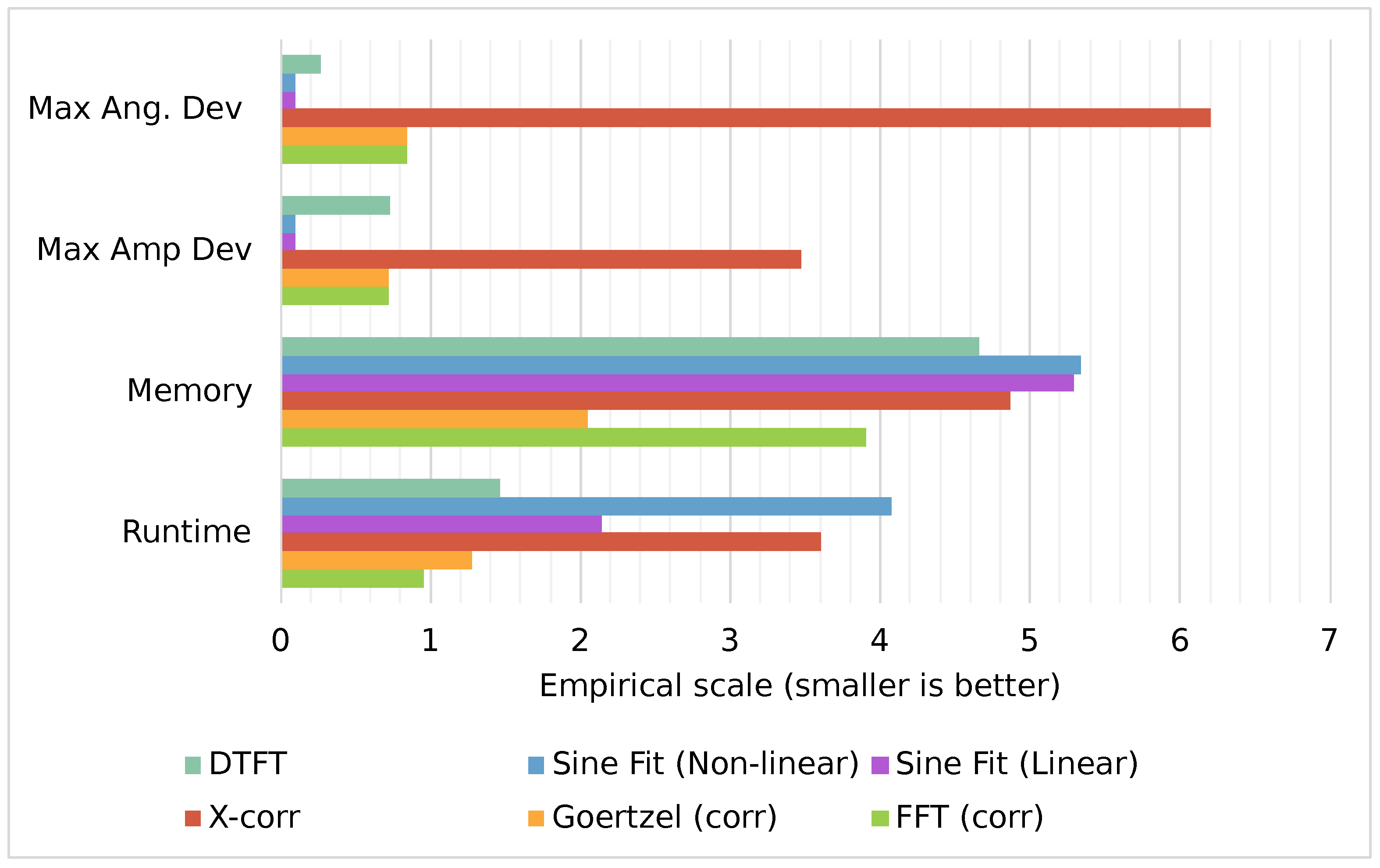
A comparison of the methods on an empirical scale is depicted in
Figure 8. In this graph, the experimental data from the previous section from CMSIS-STM32 hardware acceleration are collected and are scaled with the help of
. In this graph, smaller bars are better. The most accurate solution is sine-fit in both amplitude and phase accuracy. However, they suffer from long runtime. In this study, the linear least-squares sine-fit was deemed sufficient and enough to provide good results in a reasonable runtime. Yet, both sine-fit methods require expansive memory allocation that may not be available in all the microcontrollers. Therefore, FFT or Goerzel, both with correction are all-rounder solutions, could be used as an alternative, as they are both fast and memory-saving and have a good amplitude and phase accuracy. Alternatively, when phase accuracy is the most desired, DTFT could be used instead.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}