
Learning to Prioritize Test Cases for Computer Aided Design Software via Quantifying Functional Units



Abstract
:1. Introduction
- A new approach for ranking test cases for CAD software. We proposed an automatic approach for converting each functional unit or each test case into a 103-dimensional numeric vector. Then, each functional unit and each test case is combined into a pair, which is converted into a 206-dimensional vector based on the coverage relationship between CAD software functions and test cases. A learnable ranking model of test cases is trained using the data of 206-dimension vectors (Section 3).
- An experimental setup on six ranking models of learning and ranking test cases for CAD software (Section 4).
- Evaluation results of the proposed approach PriorCadTest with six ranking models on a real open-source CAD software, ArtOfIllusion. We find that the random forest classifier is effective in ranking the test case for CAD software (Section 5).
2. Background
2.1. CAD Software
2.2. Software Testing
2.3. Related Work
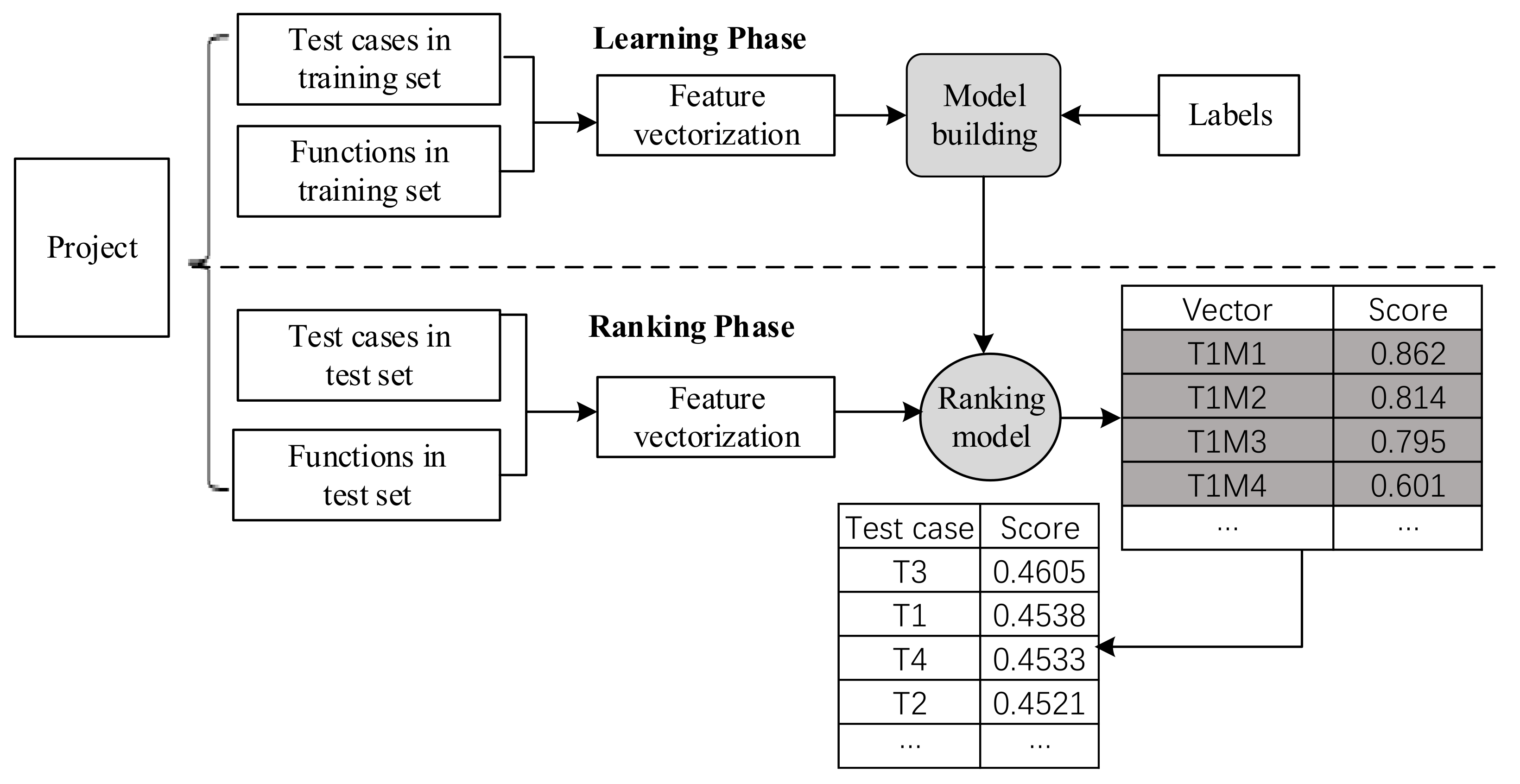
3. Learning to Prioritize Test Cases for CAD Software, PriorCadTest
3.1. Overview
3.2. Feature Extraction
3.3. Learning Phase
3.4. Ranking Phase
4. Experimental Setup
4.1. Research Questions
- RQ1. Can we find a better ranking model to prioritize test cases for CAD software? To save the time cost of defect detection, developers want to find out defects within a limited time. That is, developers need to automatically prioritize test cases before executing them. In this paper, we design RQ1 to explore the effectiveness of machine learning models in the model of test case prioritization.
- RQ2. How effective is the proposed approach in test case prioritization in testing CAD software? In CAD software, a single test case may cover multiple functions, and a single function may be covered by multiple test cases. Therefore, it is difficult for developers to determine which test case should be executed first. We design RQ2 to evaluate the ability of test case prioritization in testing CAD software.
4.2. Data Preparation and Implementation
4.3. Evaluation Metrics
- TP: # of defective test pairs that are predicted as defective.
- FP: # of undefective test pairs that are predicted as defective.
- FN: # of defective test pairs that are predicted as undefective.
- TN: # of undefective test pairs that are predicted as undefective.
5. Experimental Results
5.1. RQ1. Can We Find a Better Ranking Model to Prioritize Test Cases for CAD Software?
5.2. RQ2. How Effective Is the Proposed Approach in Test Case Prioritization in Testing CAD Software?
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Singh, J.; Perera, V.; Magana, A.J.; Newell, B.; Wei-Kocsis, J.; Seah, Y.Y.; Strimel, G.J.; Xie, C. Using machine learning to predict engineering technology students’ success with computer-aided design. Comput. Appl. Eng. Educ. 2022, 30, 852–862. [Google Scholar] [CrossRef]
- Lane, H.C.; Zvacek, S.; Uhomoibhi, J. (Eds.) Computer Supported Education. In Proceedings of the 11th International Conference on Computer Supported Education, CSEDU 2019, Heraklion, Greece, 2–4 May 2019; SciTePress: Setubal, Portugal, 2019; Volume 2. [Google Scholar]
- Hatton, D. eights: BS 8888: 2011 first angle projection drawings from FreeCAD 3D model. J. Open Source Softw. 2019, 4, 974. [Google Scholar] [CrossRef]
- Agarwal, S.; Sonbhadra, S.K.; Punn, N.S. Software Testing and Quality Assurance for Data Intensive Applications. In Proceedings of the EASE 2022: The International Conference on Evaluation and Assessment in Software Engineering 2022, Gothenburg, Sweden, 13–15 June 2022; pp. 461–462. [Google Scholar] [CrossRef]
- Karadzinov, L.; Cvetkovski, G.; Latkoski, P. (Eds.) Power control in series-resonant bridge inverters. In Proceedings of the IEEE EUROCON 2017—17th International Conference on Smart Technologies, Ohrid, North Macedonia, 6–8 July 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Selvaraj, H.; Chmaj, G.; Zydek, D. (Eds.) FPGA Implementation for Epileptic Seizure Detection Using Amplitude and Frequency Analysis of EEG Signals. In Proceedings of the 25th International Conference on Systems Engineering, ICSEng 2017, Las Vegas, NV, USA, 22–24 August 2017; IEEE Computer Society: New York, NY, USA, 2017. [Google Scholar]
- Chi, Z.; Xuan, J.; Ren, Z.; Xie, X.; Guo, H. Multi-Level Random Walk for Software Test Suite Reduction. IEEE Comput. Intell. Mag. 2017, 12, 24–33. [Google Scholar] [CrossRef]
- Ali, N.B.; Engström, E.; Taromirad, M.; Mousavi, M.R.; Minhas, N.M.; Helgesson, D.; Kunze, S.; Varshosaz, M. On the search for industry-relevant regression testing research. Empir. Softw. Eng. 2019, 24, 2020–2055. [Google Scholar] [CrossRef] [Green Version]
- Lanchares, J.; Garnica, O.; de Vega, F.F.; Hidalgo, J.I. A review of bioinspired computer-aided design tools for hardware design. Concurr. Comput. Pract. Exp. 2013, 25, 1015–1036. [Google Scholar] [CrossRef]
- Yue, T.; Arcaini, P.; Ali, S. Quantum Software Testing: Challenges, Early Achievements, and Opportunities. ERCIM News 2022, 2022, 128. [Google Scholar]
- Denisov, E.Y.; Voloboy, A.G.; Biryukov, E.D.; Kopylov, M.S.; Kalugina, I.A. Automated Software Testing Technologies for Realistic Computer Graphics. Program. Comput. Softw. 2021, 47, 76–87. [Google Scholar] [CrossRef]
- Xuan, J.; Martinez, M.; Demarco, F.; Clement, M.; Marcote, S.R.L.; Durieux, T.; Berre, D.L.; Monperrus, M. Nopol: Automatic Repair of Conditional Statement Bugs in Java Programs. IEEE Trans. Software Eng. 2017, 43, 34–55. [Google Scholar] [CrossRef] [Green Version]
- IEEE Publisher. In Proceedings of the 5th IEEE/ACM International FME Workshop on Formal Methods in Software Engineering, FormaliSE@ICSE 2017, Buenos Aires, Argentina, 27 May 2017; IEEE: New York, NY, USA, 2017.
- Radhakrishna, S.; Nachamai, M. Performance inquisition of web services using soap UI and JMeter. In Proceedings of the 2017 IEEE International Conference on Current Trends in Advanced Computing (ICCTAC), Bangalore, India, 2–3 March 2017; IEEE: New York, NY, USA, 2017; pp. 1–5. [Google Scholar]
- Ma, P.; Cheng, H.; Zhang, J.; Xuan, J. Can this fault be detected: A study on fault detection via automated test generation. J. Syst. Softw. 2020, 170, 110769. [Google Scholar] [CrossRef]
- Omri, S. Quality-Aware Learning to Prioritize Test Cases. Ph.D. Thesis, Karlsruhe Institute of Technology, Karlsruhe, Germany, 2022. [Google Scholar]
- Frome, F.S. Improving color CAD Systems for Users: Some Suggestions from Human Factors Studies. IEEE Des. Test 1984, 1, 18–27. [Google Scholar] [CrossRef]
- Grinthal, E.T. Software Quality Assurance and CAD User Interfaces. IEEE Des. Test 1986, 3, 39–48. [Google Scholar] [CrossRef]
- Hallenbeck, J.J.; Kanopoulos, N.; Vasanthavada, N.; Watterson, J.W. CAD Tools for Supporting System Design for Testability. In Proceedings of the International Test Conference 1988, Washington, DC, USA, 12–14 September 1988; p. 993. [Google Scholar] [CrossRef]
- Gelsinger, P.; Iyengar, S.; Krauskopf, J.; Nadir, J. Computer aided design and built in self test on the i486TM CPU. In Proceedings of the 1989 IEEE International Conference on Computer Design (ICCD): VLSI in Computers and Processors, Cambridge, MA, USA, 2–4 October 1989; pp. 199–202. [Google Scholar] [CrossRef]
- Sprumont, F.; Xirouchakis, P.C. Towards a Knowledge-Based Model for the Computer Aided Design Process. Concurr. Eng. Res. Appl. 2002, 10, 129–142. [Google Scholar] [CrossRef]
- Wang, Y.; Nnaji, B.O. Solving Interval Constraints by Linearization in Computer-Aided Design. Reliab. Comput. 2007, 13, 211–244. [Google Scholar] [CrossRef]
- Su, F.; Zeng, J. Computer-Aided Design and Test for Digital Microfluidics. IEEE Des. Test Comput. 2007, 24, 60–70. [Google Scholar] [CrossRef]
- Issanchou, S.; Gauchi, J. Computer-aided optimal designs for improving neural network generalization. Neural Netw. 2008, 21, 945–950. [Google Scholar] [CrossRef] [PubMed]
- Veisz, D.; Namouz, E.Z.; Joshi, S.; Summers, J.D. Computer-aided design versus sketching: An exploratory case study. Artif. Intell. Eng. Des. Anal. Manuf. 2012, 26, 317–335. [Google Scholar] [CrossRef]
- Banerjee, S.; Mukhopadhyay, D.; Chowdhury, D.R. Computer Aided Test (CAT) Tool for Mixed Signal SOCs. In Proceedings of the 18th International Conference on VLSI Design (VLSI Design 2005), with the 4th International Conference on Embedded Systems Design, Kolkata, India, 3–7 January 2005; pp. 787–790. [Google Scholar] [CrossRef]
- Bahar, R.I. Conference Reports: Recap of the 37th Edition of the International Conference on Computer-Aided Design (ICCAD 2018). IEEE Des. Test 2019, 36, 98–99. [Google Scholar] [CrossRef]
- Ramanathan, M.K.; Koyutürk, M.; Grama, A.; Jagannathan, S. PHALANX: A graph-theoretic framework for test case prioritization. In Proceedings of the 2008 ACM Symposium on Applied Computing (SAC), Fortaleza, Brazil, 16–20 March 2008; pp. 667–673. [Google Scholar] [CrossRef]
- Chi, J.; Qu, Y.; Zheng, Q.; Yang, Z.; Jin, W.; Cui, D.; Liu, T. Relation-based test case prioritization for regression testing. J. Syst. Softw. 2020, 163, 110539. [Google Scholar] [CrossRef]
- Wong, W.E.; Horgan, J.R.; London, S.; Agrawal, H. A study of effective regression testing in practice. In Proceedings of the Eighth International Symposium on Software Reliability Engineering, ISSRE 1997, Albuquerque, NM, USA, 2–5 November 1997; pp. 264–274. [Google Scholar] [CrossRef]
- Gupta, P.K. K-Step Crossover Method based on Genetic Algorithm for Test Suite Prioritization in Regression Testing. J. Univers. Comput. Sci. 2021, 27, 170–189. [Google Scholar] [CrossRef]
- Chen, J.; Zhu, L.; Chen, T.Y.; Towey, D.; Kuo, F.; Huang, R.; Guo, Y. Test case prioritization for object-oriented software: An adaptive random sequence approach based on clustering. J. Syst. Softw. 2018, 135, 107–125. [Google Scholar] [CrossRef]
- Liu, T. Learning to Rank for Information Retrieval; Springer: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Mirarab, S.; Tahvildari, L. A Prioritization Approach for Software Test Cases Based on Bayesian Networks. In Proceedings of the Fundamental Approaches to Software Engineering, 10th International Conference, FASE 2007, Held as Part of the Joint European Conferences, on Theory and Practice of Software, ETAPS 2007, Braga, Portugal, 24 March–1 April 2007; pp. 276–290. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Yuan, S.; Intasara, J. A Learning-to-Rank Based Approach for Improving Regression Test Case Prioritization. In Proceedings of the 28th Asia-Pacific Software Engineering Conference, APSEC 2021, Taipei, Taiwan, 6–9 December 2021; IEEE: New York, NY, USA, 2021; pp. 576–577. [Google Scholar] [CrossRef]
- Petric, J.; Hall, T.; Bowes, D. How Effectively Is Defective Code Actually Tested?: An Analysis of JUnit Tests in Seven Open Source Systems. In Proceedings of the 14th International Conference on Predictive Models and Data Analytics in Software Engineering, PROMISE 2018, Oulu, Finland, 10 October 2018; pp. 42–51. [Google Scholar] [CrossRef] [Green Version]
- Zou, W.; Xuan, J.; Xie, X.; Chen, Z.; Xu, B. How does code style inconsistency affect pull request integration? An exploratory study on 117 GitHub projects. Empir. Softw. Eng. 2019, 24, 3871–3903. [Google Scholar] [CrossRef]
- Belli, E.; Vantini, S. Measure Inducing Classification and Regression Trees for Functional Data. arXiv, 2020; arXiv:2011.00046v1. [Google Scholar] [CrossRef]
- Samigulina, G.A.; Samigulina, Z.I. Immune Network Technology on the Basis of Random Forest Algorithm for Computer-Aided Drug Design. In Proceedings of the Bioinformatics and Biomedical Engineering—5th International Work-Conference, IWBBIO 2017, Proceedings Part I, Lecture Notes in Computer Science, Granada, Spain, 26–28 April 2017; Rojas, I., Guzman, F.M.O., Eds.; Volume 10208, pp. 50–61. [Google Scholar] [CrossRef]
- Hamid, L.B.A.; Khairuddin, A.S.M.; Khairuddin, U.; Rosli, N.R.; Mokhtar, N. Texture image classification using improved image enhancement and adaptive SVM. Signal Image Video Process. 2022, 16, 1587–1594. [Google Scholar] [CrossRef]
- Atik, I. A New CNN-Based Method for Short-Term Forecasting of Electrical Energy Consumption in the Covid-19 Period: The Case of Turkey. IEEE Access 2022, 10, 22586–22598. [Google Scholar] [CrossRef]
- Xie, B.; Zhang, Q. Deep Filtering with DNN, CNN and RNN. arXiv, 2021; arXiv:2112.12616v1. [Google Scholar] [CrossRef]
- Guidotti, D. Verification and Repair of Machine Learning Models. Ph.D. Thesis, University of Genoa, Genoa, Italy, 2022. [Google Scholar]
- Gu, Y.; Xuan, J.; Zhang, H.; Zhang, L.; Fan, Q.; Xie, X.; Qian, T. Does the fault reside in a stack trace? Assisting crash localization by predicting crashing fault residence. J. Syst. Softw. 2019, 148, 88–104. [Google Scholar] [CrossRef]
- Moraglio, A.; Silva, S.; Krawiec, K.; Machado, P.; Cotta, C. (Eds.) Genetic Programming. In Proceedings of the 15th European Conference, EuroGP 2012, Málaga, Spain, 11–13 April 2012; Lecture Notes in Computer Science. Springer: New York, NY, USA, 2012; Volume 7244. [Google Scholar] [CrossRef]
- Rothermel, G.; Untch, R.H.; Chu, C.; Harrold, M.J. Prioritizing Test Cases For Regression Testing. IEEE Trans. Softw. Eng. 2001, 27, 929–948. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| … | ||||
| 1 | 0 | … | 1 | |
| 1 | 1 | … | 0 | |
| … | … | … | … | … |
| 0 | 1 | … | 1 |
| Module | #Functions | #Test Cases |
|---|---|---|
| math | 192 | 11 |
| object | 897 | 43 |
| procedural | 577 | 12 |
| animation | 994 | 19 |
| raytracer | 0 † | 2 |
| texture | 459 | 2 |
| util | 65 | 2 |
| Sum | 3184 | 91 |
| Dataset | Module or Fold as Test Set | Functions and Test Cases | Training Set | Test Set |
|---|---|---|---|---|
| math | # Functions | 2992 | 192 | |
| # Defective functions | 1488 | 66 | ||
| # Test Cases | 80 | 11 | ||
| # Defective functions covered by tests | 69 | 8 | ||
| object | # Functions | 2287 | 897 | |
| # Functions with seeding defects | 1160 | 394 | ||
| # Test Cases | 48 | 43 | ||
| # Defective functions covered by tests | 36 | 33 | ||
| Dataset 1 | procedural | #Functions | 2607 | 577 |
| based on | # Functions with seeding defects | 1217 | 337 | |
| modules | # Test Cases | 79 | 12 | |
| # Defective functions covered by tests | 45 | 24 | ||
| # Functions | 2190 | 994 | ||
| animation | # Functions with seeding defects | 1051 | 503 | |
| (not used | # Test Cases | 72 | 19 | |
| in evaluation) | # Defective functions covered by tests | 69 | 0 | |
| Fold 1 | #Functions | 2548 | 636 | |
| # Functions with seeding defects | 1431 | 123 | ||
| # Test Cases | 91 | 91 | ||
| # Defective functions covered by tests | 64 | 5 | ||
| Fold 2 | #Functions | 2548 | 636 | |
| # Functions with seeding defects | 11329 | 1431 | ||
| # Test Cases | 91 | 91 | ||
| # Defective functions covered by tests | 59 | 10 | ||
| Fold 3 | #Functions | 2548 | 636 | |
| Dataset 2 | # Functions with seeding defects | 1267 | 287 | |
| based on | # Test Cases | 91 | 91 | |
| folds | # Defective functions covered by tests | 56 | 13 | |
| Fold 4 | #Functions | 2548 | 636 | |
| # Functions with seeding defects | 1151 | 403 | ||
| # Test Cases | 91 | 91 | ||
| # Defective functions covered by tests | 50 | 19 | ||
| Fold 5 | #Functions | 2544 | 660 | |
| # Functions with seeding defects | 1038 | 516 | ||
| # Test Cases | 91 | 91 | ||
| # Defective functions covered by tests | 47 | 22 |
| Test Set | Ranking Model | Precision | Recall | F-Score | Accuracy | Time (ms) | Memory (MB) |
|---|---|---|---|---|---|---|---|
| math | CART | 87.31% | 88.54% | 87.93% | 87.03% | 37.49 | 200.99 |
| RF | 91.14% | 81.62% | 86.12% | 85.97% | 30.23 | 246.34 | |
| SVM | 53.33% | 100% | 69.56% | 53.33% | 29.17 | 294.53 | |
| BN | 22.86% | 0.51% | 0.99% | 46.03% | 27.96 | 251.96 | |
| CNN | 53.33% | 100% | 69.56% | 53.33% | 41.85 | 353.83 | |
| RNN | 53.33% | 100% | 69.59% | 53.33% | 20.01 | 275.79 | |
| object | CART | 88.12% | 84.50% | 86.28% | 85.66% | 126.66 | 710.58 |
| RF | 89.45% | 79.09% | 83.96% | 83.88% | 202.42 | 826.45 | |
| SVM | N/A | 0% | N/A | 46.67% | 117.87 | 558.3 | |
| BN | 64.01% | 21.82% | 32.55% | 51.76% | 151.64 | 696.19 | |
| CNN | N/A | 0% | N/A | 46.67% | 206.12 | 897.85 | |
| RNN | N/A | 0% | N/A | 46.67% | 285.83 | 768.95 | |
| procedural | CART | 92.89% | 83.25% | 87.80% | 87.67% | 40.91 | 218.17 |
| RF | 92.43% | 80.22% | 85.89% | 85.95% | 35.94 | 280.97 | |
| SVM | 53.33% | 100% | 69.56% | 53.33% | 60.62 | 219.94 | |
| BN | 22.58% | 0.5% | 0.97% | 46.03% | 63.37 | 288.06 | |
| CNN | 53.33% | 100% | 69.56% | 53.33% | 46.21 | 338.44 | |
| RNN | 53.33% | 100% | 69.59% | 53.33% | 74.97 | 193.84 | |
| Fold 1 | CART | 29.78% | 43.56% | 35.38% | 43.71% | 65.31 | 273.88 |
| RF | 50.99% | 92% | 65.61% | 65.88% | 75.31 | 335.16 | |
| SVM | 35.38% | 100% | 52.26% | 35.38% | 72.88 | 301.46 | |
| BN | 65.04% | 71.11% | 67.94% | 76.26% | 30.17 | 189.84 | |
| CNN | 35.38% | 100% | 52.26% | 35.38% | 41.64 | 257.77 | |
| RNN | 35.38% | 100% | 52.26% | 35.38% | 36.03 | 331.65 | |
| Fold 2 | CART | 42.06% | 79.67% | 55.06% | 74.84% | 78.34 | 320.61 |
| RF | 47.27% | 63.41% | 54.17% | 79.25% | 62.81 | 169.62 | |
| SVM | 19.34% | 100% | 32.41% | 19.34% | 69.69 | 284.75 | |
| BN | 16.92% | 17.89% | 17.39% | 67.19% | 35.03 | 178.8 | |
| CNN | 19.34% | 100% | 32.41% | 19.34% | 75.26 | 249.2 | |
| RNN | 19.34% | 100% | 32.41% | 19.34% | 41.59 | 226.92 | |
| Fold 3 | CART | 55.56% | 60.98% | 58.14% | 60.38% | 77.24 | 275.33 |
| RF | 59.75% | 84.32% | 69.94% | 67.3% | 38.26 | 338.93 | |
| SVM | 45.13% | 100% | 62.19% | 45.13% | 35.02 | 175.69 | |
| BN | 20.97% | 18.19% | 19.44% | 32.23% | 72.33 | 389.09 | |
| CNN | 45.13% | 100% | 62.19% | 45.13% | 72.9 | 336.95 | |
| RNN | 45.13% | 100% | 62.19% | 45.13% | 59.32 | 189.21 | |
| Fold 4 | CART | 41.04% | 21.59% | 28.29% | 30.66% | 48.16 | 278.7 |
| RF | 58.96% | 44.91% | 50.99% | 45.28% | 51.04 | 282.38 | |
| SVM | N/A | 0 | N/A | 36.64% | 32.36 | 380.15 | |
| BN | 7.27% | 2.98% | 4.23% | 14.47% | 60.11 | 226.24 | |
| CNN | N/A | 0 | N/A | 36.64% | 35.28 | 185.58 | |
| RNN | N/A | 0 | N/A | 36.64% | 63.32 | 217.7 | |
| Fold 5 | CART | 73.53% | 38.99% | 50.96% | 39.84% | 42.56 | 221.22 |
| RF | 87% | 80.9% | 83.84% | 75% | 32.09 | 248.61 | |
| SVM | 80.63% | 100% | 89.27% | 80.63% | 70.12 | 249.8 | |
| BN | 53.06% | 15.2% | 23.64% | 21.25% | 44.91 | 353.38 | |
| CNN | 80.63% | 100% | 89.27% | 80.63% | 33.8 | 294.55 | |
| RNN | 80.63% | 100% | 89.27% | 80.63% | 65.31 | 253.19 |
| Data Set | Test Set | Ranking Model | Top-10 | Top-20 | Top-30 | APFD |
|---|---|---|---|---|---|---|
| Dataset 1 | math | CART | 8 | 8 | 8 | 59.09% |
| RF | 8 | 8 | 8 | 85.23% | ||
| SVM | 8 | 8 | 8 | 61.36% | ||
| BN | 5 | 8 | 8 | 71.59% | ||
| CNN | 8 | 8 | 8 | 61.36% | ||
| RNN | 8 | 8 | 8 | 61.36% | ||
| RR | 7 | 8 | 8 | 48.86% | ||
| object | CART | 14 | 19 | 27 | 65.29% | |
| RF | 17 | 29 | 33 | 72.83% | ||
| SVM | 16 | 23 | 27 | 69.10% | ||
| BN | 13 | 21 | 30 | 65.57% | ||
| CNN | 16 | 23 | 27 | 69.10% | ||
| RNN | 16 | 23 | 27 | 69.10% | ||
| RR | 15 | 16 | 16 | 53.66% | ||
| procedural | CART | 24 | 24 | 24 | 70.49% | |
| RF | 24 | 24 | 24 | 80.21% | ||
| SVM | 24 | 24 | 24 | 84.38% | ||
| BN | 7 | 24 | 24 | 90.63% | ||
| CNN | 24 | 24 | 24 | 84.38% | ||
| RNN | 24 | 24 | 24 | 84.38% | ||
| RR | 23 | 24 | 24 | 48.96% | ||
| Dataset 2 | Fold 1 | CART | 8 | 8 | 10 | 66.5% |
| RF | 9 | 10 | 10 | 73.03% | ||
| SVM | 8 | 9 | 10 | 63.66% | ||
| BN | 8 | 8 | 9 | 67.54% | ||
| CNN | 8 | 9 | 10 | 63.66% | ||
| RNN | 8 | 9 | 10 | 63.66% | ||
| RR | 7 | 8 | 8 | 58.11% | ||
| Fold 2 | CART | 5 | 5 | 5 | 72.9% | |
| RF | 5 | 5 | 5 | 73.38% | ||
| SVM | 5 | 5 | 5 | 73.5% | ||
| BN | 3 | 5 | 5 | 62.07% | ||
| CNN | 5 | 5 | 5 | 73.5% | ||
| RNN | 5 | 5 | 5 | 73.5% | ||
| RR | 4 | 5 | 5 | 69.72% | ||
| Fold 3 | CART | 6 | 9 | 12 | 66.14% | |
| RF | 8 | 12 | 13 | 73.51% | ||
| SVM | 6 | 10 | 13 | 67.12% | ||
| BN | 7 | 11 | 13 | 68.94% | ||
| CNN | 6 | 10 | 13 | 67.12% | ||
| RNN | 6 | 10 | 13 | 67.12% | ||
| RR | 5 | 8 | 11 | 58.39% | ||
| Fold 4 | CART | 9 | 15 | 18 | 69.23% | |
| RF | 11 | 17 | 19 | 71.37% | ||
| SVM | 8 | 14 | 17 | 63.25% | ||
| BN | 8 | 13 | 16 | 61.51% | ||
| CNN | 8 | 14 | 17 | 63.25% | ||
| RNN | 8 | 14 | 17 | 63.25% | ||
| RR | 9 | 13 | 16 | 65.78% | ||
| Fold 5 | CART | 11 | 15 | 19 | 67.83% | |
| RF | 13 | 18 | 22 | 80.21% | ||
| SVM | 11 | 16 | 20 | 73.22% | ||
| BN | 9 | 12 | 16 | 64.44% | ||
| CNN | 11 | 16 | 20 | 73.22% | ||
| RNN | 11 | 16 | 20 | 73.22% | ||
| RR | 7 | 11 | 13 | 57.64% |
| Rank | Function | Score |
|---|---|---|
| 1 | point_outside_influence_radius_is_0 | 0.4605 |
| 2 | point_inside_radius_is_greater_than_1 | 0.4605 |
| 3 | gradient_estimate_within_delta | 0.4538 |
| 4 | point_between_radius_and_influence_is_between_0_and_1 | 0.4533 |
| 5 | gradient_estimate_at_influence_edge | 0.4521 |
| 6 | testDuplicateAll | 0.4476 |
| 7 | testDuplicateWithTracks | 0.4467 |
| 8 | testCopyInfo | 0.4434 |
| 9 | setObjectInfoMaterial | 0.4432 |
| 10 | testDuplicateWithNewGeometryAndTracks | 0.4426 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, F.; Liu, S.; Yang, F.; Xu, Y.; Zhou, G.; Xuan, J. Learning to Prioritize Test Cases for Computer Aided Design Software via Quantifying Functional Units. Appl. Sci. 2022, 12, 10414. https://doi.org/10.3390/app122010414
Zeng F, Liu S, Yang F, Xu Y, Zhou G, Xuan J. Learning to Prioritize Test Cases for Computer Aided Design Software via Quantifying Functional Units. Applied Sciences. 2022; 12(20):10414. https://doi.org/10.3390/app122010414
Chicago/Turabian StyleZeng, Fenfang, Shaoting Liu, Feng Yang, Yisen Xu, Guofu Zhou, and Jifeng Xuan. 2022. "Learning to Prioritize Test Cases for Computer Aided Design Software via Quantifying Functional Units" Applied Sciences 12, no. 20: 10414. https://doi.org/10.3390/app122010414
APA StyleZeng, F., Liu, S., Yang, F., Xu, Y., Zhou, G., & Xuan, J. (2022). Learning to Prioritize Test Cases for Computer Aided Design Software via Quantifying Functional Units. Applied Sciences, 12(20), 10414. https://doi.org/10.3390/app122010414