1. Introduction
The life of many pieces of aircraft equipment is measured by two indexes, namely calendar life (CL) and working life (WL), and this type of equipment is called dual-life equipment (hereinafter referred to as equipment). Similar to aviation-guided munitions, the “power on time” is the working life of aviation-guided munitions.
The specified available calendar life for maintenance is called the stage calendar life, and the specified available working life for maintenance is called the stage working life. The calendar life is gradually consumed over time regardless of whether the task is executed or not, and it is uncontrollable, while the working life is only consumed by the execution of the task, which is controllable. In the actual usage process, the number of tasks for each unit and the number of pieces of equipment rotated between units are uncertain due to the lack of a rotation and echelon usage scheme formulation method. The scheme selection method is random and subjective [
1], resulting in the fact that when the calendar life of the equipment stage is exhausted, its working life only consumes 40~60% of its stage working life [
2], and the working life is seriously wasted and the echelon state is difficult to control. In the case of no rotation, due to the different equipment states and working intensities of different units, the life utilization index and life matching index of equipment are greatly different. Therefore, an effective rotation and echelon usage control method has an important role in solving the problems associated with echelon uniformity, life utilization and the life-matching degree of each unit.
Liu [
3] established a set of comprehensive evaluation indexes, including working life combat-readiness reserves and echelon-uniformity indexes. However, these indexes cannot adapt to the situation of considering calendar life, and cannot control the echelon status. Zhang [
4] proposed an improved echelon usage diagram method, which is concise and intuitive. Zhou et al. [
5] proposed a formation and control method of motorcycle working life echelon reserves using SAA to formulate a usage and repair plan of a motorcycle. For assignment problems, Dorterler [
6] proposed a new genetic algorithm with agent-based crossover for the generalized assignment problem, but it is based on the idea that each task should be assigned to one agent only. Fu et al. [
7] studied the uncertain multi-objective assignment problem, in which the number of tasks each person undertakes is uncertain, but each task can only be undertaken by one person. Xiong [
8] solved the assignment problem of multiple people participating in a task with a new generalized nonlinear integer programming model and verified its effectiveness through an example. Ding [
9,
10] proposed an α-optimistic uncertain assignment model, but this model has the limitations of low efficiency and large storage space requirements.
2. Problem Description and Modeling
2.1. Problem Description
In the case of rotation, the echelon usage problem of equipment belongs to the uncertain assignment problem. The characteristics of this kind of assignment problem are that the amount of equipment in each rotation is uncertain, the quantity of tasks that each equipment can undertake is uncertain and the objective function result is uncertain before the decision matrix is determined.
According to the remaining-life data of equipment and task quantity in different units, the arrangement of the equipment to be rotated is calculated first, followed by the performance of a task of months, where is a positive integer, aiming at maximizing the average working-life echelon-uniformity index, the average calendar-life- and working-life-matching index, the average life-utilization-rate index, and the waste rate-of-rotation-quantity index. The result is the number of pieces of equipment rotated by each unit and the quantity of tasks completed by each piece equipment each month.
The average working-life echelon uniformity refers to the average value of the working-life echelon uniformity of each unit, hereinafter referred to as the average echelon uniformity. The average calendar-life- and working-life-matching-degree index refer to the average value of the calendar-life- and working-life matching-degree index of each unit, hereinafter referred to as the average matching-degree index. The average life-utilization rate refers to the average value of the life-utilization rate of each unit, hereinafter referred to as the average utilization-rate index. The waste rate-of-rotation-quantity index refers to the ratio of the unused rotation equipment quantity to the maximum equipment rotation quantity of all units.
2.2. Problem Assumptions
Assumption 1: There is complete interchangeability between the equipment;
Assumption 2: The quantity of tasks per month of each unit is fixed;
Assumption 3: The quantity of equipment required for each unit is fixed;
Assumption 4: The working-life consumption per task is fixed;
Assumption 5: The calendar life of each piece of equipment is an integer, with the unit of months;
Assumption 6: There is no limit to the number of times each piece of equipment can be used every month;
Assumption 7: Equipment failure is not considered during rotation and usage;
Assumption 8: The upper limit of the amount of equipment in each rotation is determined;
Assumption 9: The calendar life consumption caused by rotation is negligible.
2.3. Problem Inputs
Task quantity sequence every month of each unit ;
Quantity of equipment required for each task ;
Working-life consumption per task ;
Stage working life of equipment ;
Stage calendar life of equipment ;
Task time range ;
Maximum quantity of equipment for each rotation ;
Equipment quantity sequence of each unit ;
Unit quantity .
2.5. Mathematical Model
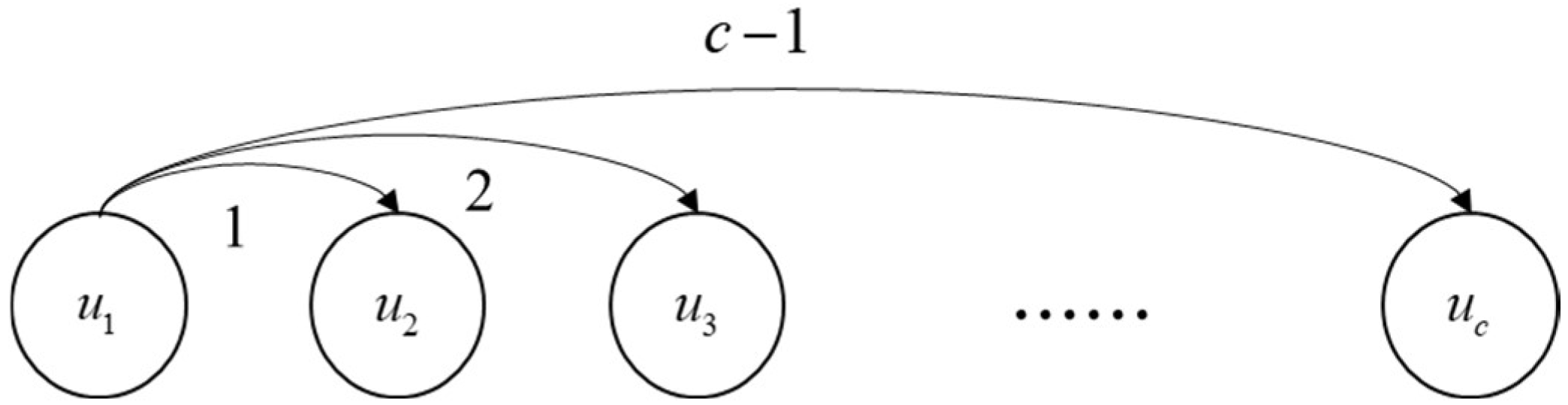
Taking unit
as an example, when rotating from
to other units, the rotation number is
, and the rotation process is shown in
Figure 1.
The decision matrix is divided into two parts.
Let us introduce the 0-1 variable
, where
is the equipment number sequence of
,
is the equipment quantity of
. By analogy, the 0-1 variable is also introduced for other units to build a rotation decision matrix. The selected equipment is moved to the corresponding unit, and the equipment numbers of the current unit and the corresponding unit are updated.
is the updated equipment number sequence of each unit and
is the updated equipment quantity sequence of each unit.
Let us introduce the 0-1 variable
, where
is the task quantity of
. By analogy, the 0-1 variable is also used for other units to construct the task decision matrix and update the working life of the selected equipment.
Next, let us establish the rotation decision matrix,
, and task decision matrix,
, of
, as shown in
Table 1 and
Table 2.
are the remaining usable times of , where and are the updated remaining working life sequence and calendar life sequence. The fitness functions of this problem are the average echelon-uniformity function of each unit, average life-matching function of each unit, average utilization function and rotation-quantity waste function.
- 1.
The average echelon-uniformity function, .
The improved echelon-uniformity function, , of is shown in Formula (1)
This is continued for other units to acquire .
is the sequence of sorted in ascending order according to the of . Its purpose is to increase the working life along the direction of increasing calendar life. is the maximum value in , and is the quantity of equipment of .
- 2.
The average life-matching function, .
The life-matching function,
, of
is shown in Formula (2)
This is continued for other units to acquire .
is the absolute value of the difference between the updated used working life and the used calendar life ratio and the ideal ratio of each equipment. When , the used working life of the equipment is calculated as a ratio.
- 3.
The average utilization function, .
It is defined that the standard for equipment to enter into consumption is that the working life must be less than 3 h or the calendar life must be less than 1 month. When the equipment reaches the consumption standard, it can be considered that the utilization rate is 100%. The process is as follows:
For , define , , , .
Traverse the updated data.
When , ;
When , ;
When , ;
When , , .
The utilization function of
is shown in Formula (3).
is the quantity of equipment with an exhausted calendar life of , is quantity of equipment with an exhausted calendar life of , is the sum of the remaining working life of the equipment with an exhausted calendar life after updating , and is the sum of the remaining calendar life of the equipment with an exhausted working life after updating .
This is continued for other units to acquire .
- 4.
The rotation-quantity waste function, .
The transportation cost and risk level caused by rotation can be replaced by the equipment rotation quantity. In order to reduce the equipment transportation cost and risk caused by rotation, the number of rotating pieces of equipment should be as small as possible.
Let us assume that the number of pieces of equipment rotated from a certain unit at each time cannot exceed
, the rotation phase can be divided into from
to
, from
to
,…, from
to
,…, and from
to
, where the total time of rotations is
, and the maximum quantity of rotations is
. Let us assume that the rotation quantity represented by an individual chromosome is
, the rotation-quantity waste rate function of the individual
is shown in Formula (4).
Aiming at the multi-objective assignment problem with an uncertain rotation quantity, with the task quantity completed by each equipment under the conditions of rotation, this paper constructed a decision-making model for the rotation and echelon usage of dual-life equipment and proposed an improved NSGA-III method with a variable length chromosome (I-NSGA-III-VLC) to solve it. This method can obtain a variety of optimization schemes in a relatively short time. Through scheme screening, the problem of poor working-life echelon status, low matching between calendar life and working life and the low utilization of the working life of equipment in different units can be solved to a certain extent with as few rotations as possible.
3. Principle of I-NSGA-III-VLC Method
Optimizing the equipment echelon uniformity, life-matching degree, life utilization and rotation-quantity waste rate at the same time is a high-dimensional multi-objective optimization problem. Deb proposed a fast, non-dominated-sorting genetic algorithm based on reference points (NSGA-III) [
11], which replaced the congestion by associating the reference points, and solved the problem of high-dimensional objective optimization. Many scholars have solved high-dimensional multi-objective optimization problems based on the above algorithms, including the multi-objective classification problem [
12], reservoir flood-control-operation problem [
13], resource-allocation problem [
14,
15,
16], location-routing problem [
17,
18,
19,
20], high-dimensional target power-flow-optimization problem of a power system [
21,
22], etc.
The feasible region of many problems is uncertain in real life. Many scholars [
23,
24,
25,
26,
27,
28,
29] have improved the NSGA-III-VLC according to the characteristics of the problem. In the formulation of the equipment usage plan considering rotation, because the quantity of rotation will affect the rotation cost and risk, the length of the chromosome also affects the decision-making. In this paper, the chromosome-coding method, crossover operator, mutation operator and repetitive individual control operator were improved according to the characteristics of the problem. The specific improvement contents are shown from
Section 3.1,
Section 3.2,
Section 3.3,
Section 3.4 and
Section 3.5.
3.1. Variable Length Cegment Hybrid Coding Method
Due to the need for considering the rotation between different units, the chromosome-coding method needs to be changed to distinguish different units. The rotation stage is placed before the task stage. This paper adopted the variable length and hybrid segmented-coding methods. Let us add a number “prefix” before each rotation, such as 1, 2, …, . Therefore, the shortest chromosome length at the rotation stage is , and the maximum quantity of equipment for each rotation is . Therefore, the longest chromosome length is .
After the rotation phase, according to the task intensity sequence and of each unit, according to the unit quantity, let us add a number “prefix” before each unit task, such as ,,…,. Therefore, the total length of chromosomes in the task phase is .
Each coding segment is divided by a digital “prefix”. With this coding method, we can not only distinguish each unit but also cross and mutate under the same “prefix”. The range of crossover and mutation is reduced, and it is easy to control the chromosome length. The chromosome initialization process is shown below.
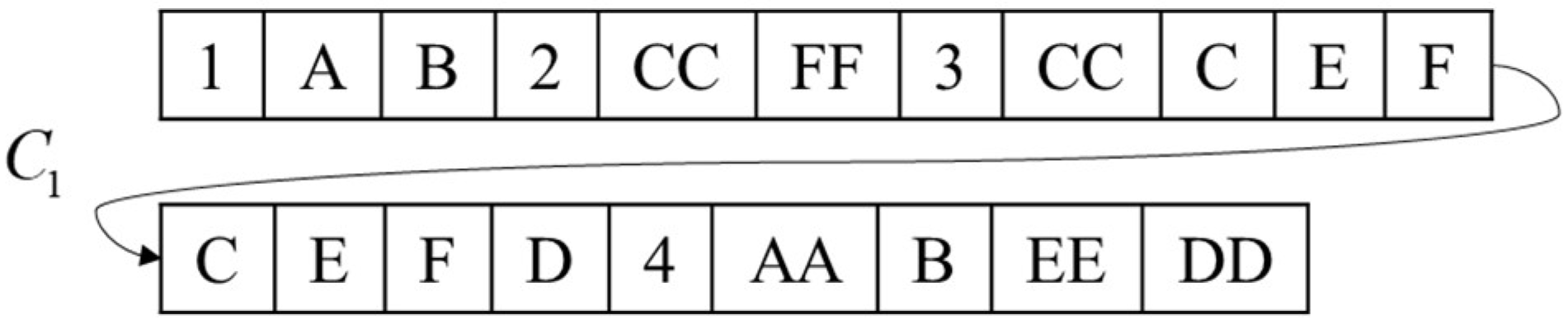
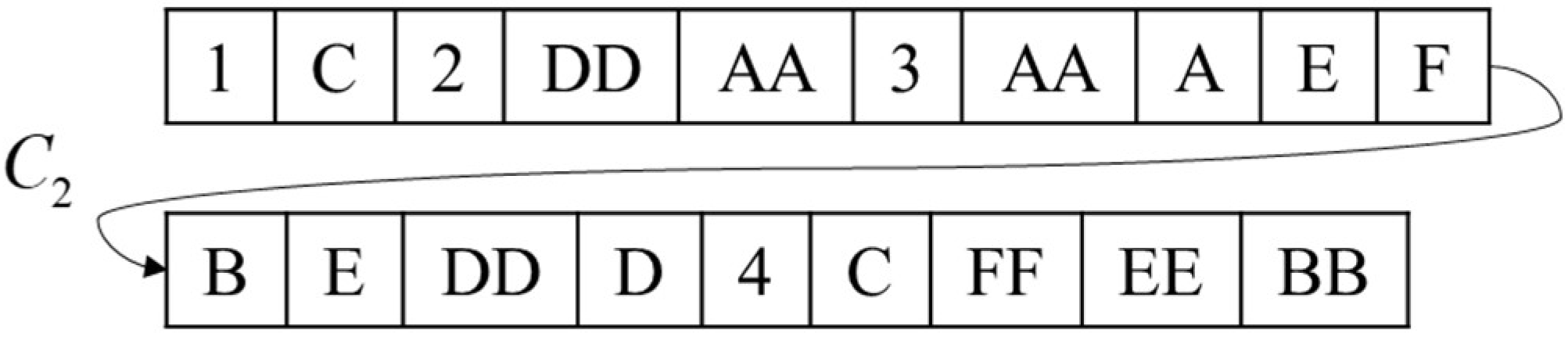
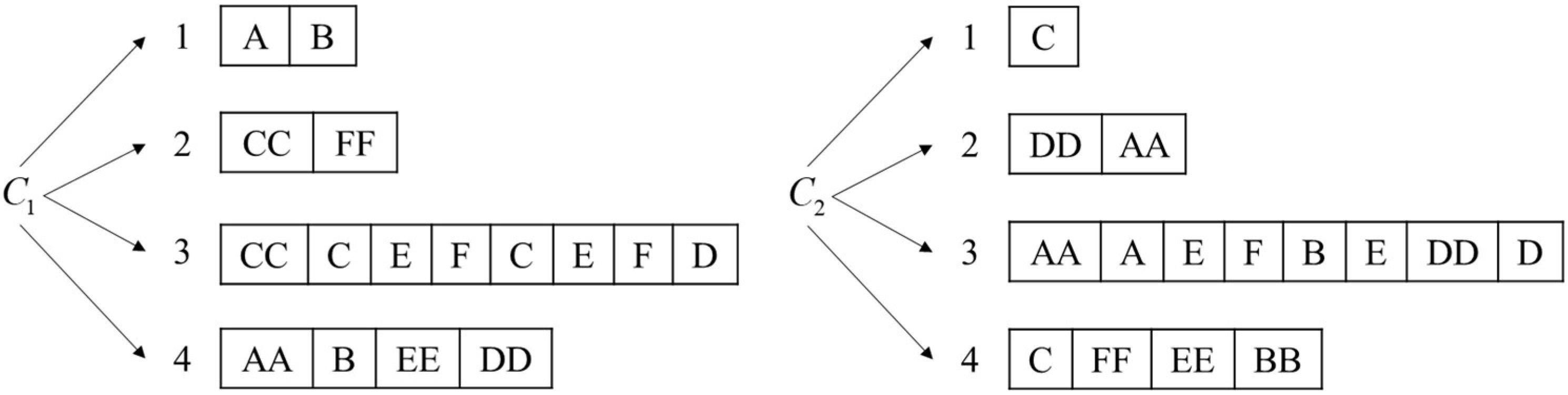
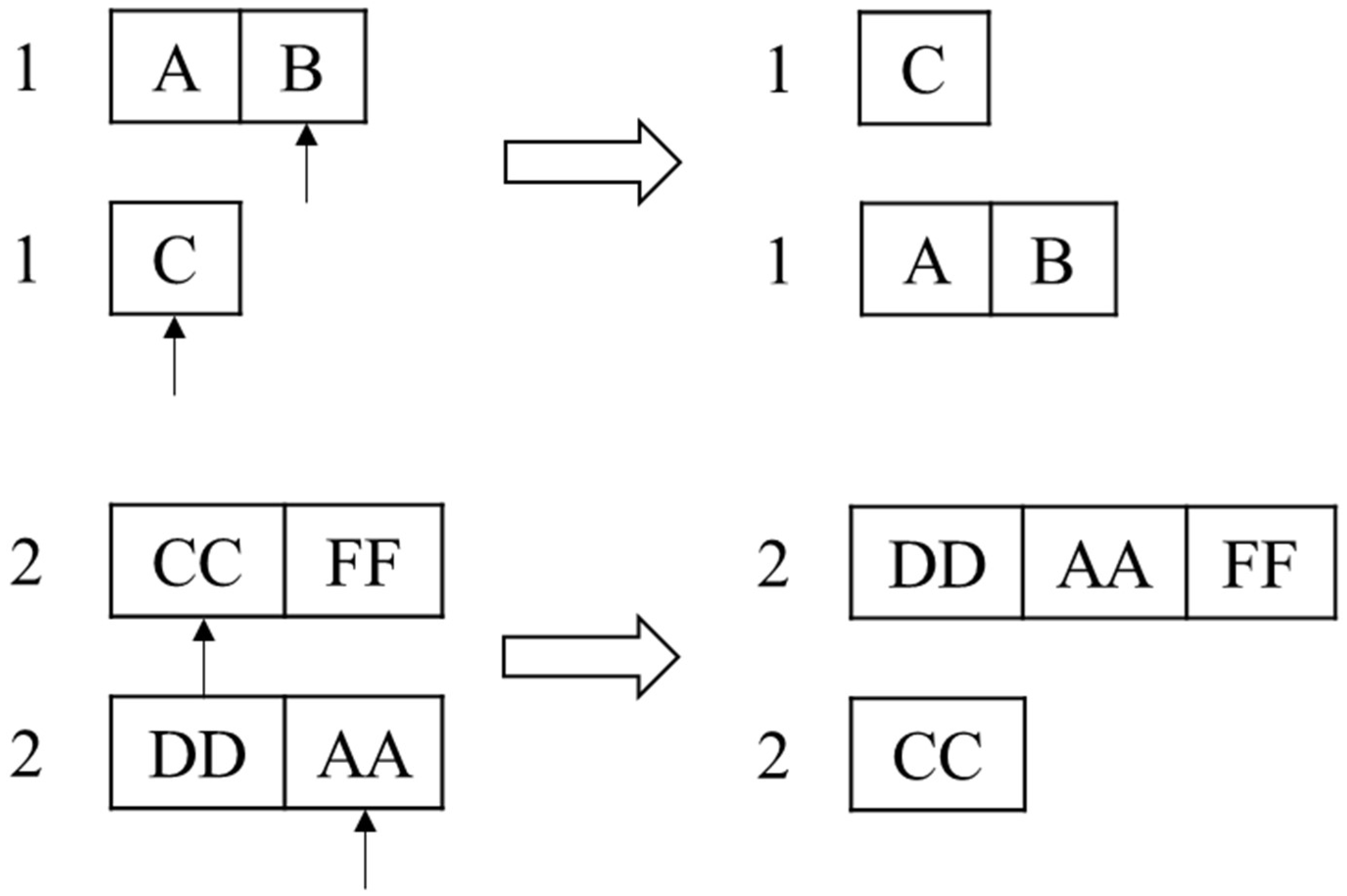
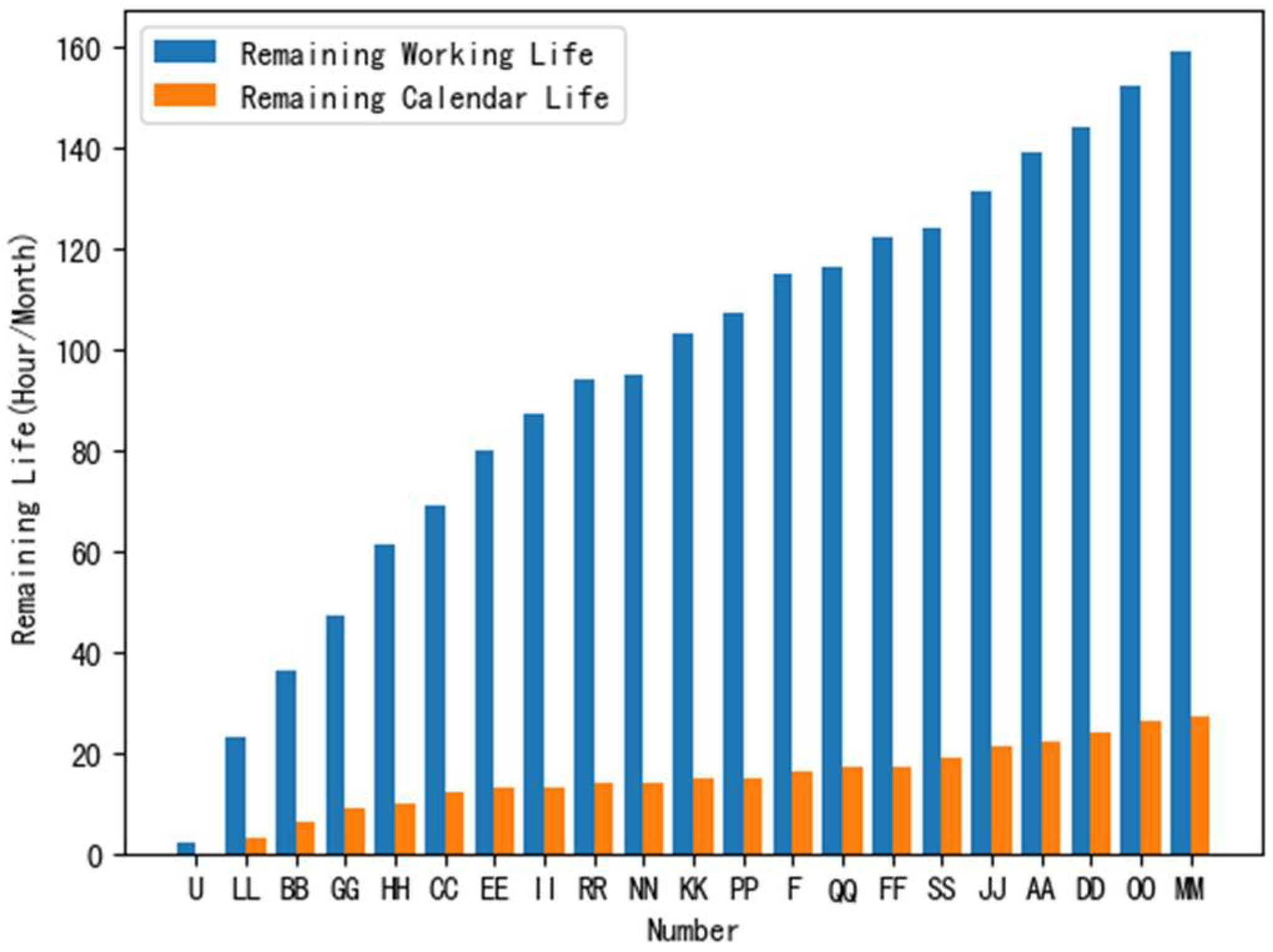
Step 1: Arrange all equipment numbers and remaining usable times in each unit to form a sequence in in the format of “Number: Remaining Usable Times”. Like all equipment numbers, of is [‘A’: 4, ‘C’: 5, ‘E’: 5, ‘F’: 6, ‘B’: 6, ‘D’: 7], and like all equipment numbers, of is [‘AA’: 3, ‘CC’: 6, ‘EE’: 7, ‘BB’: 7, ‘FF’: 8, ‘DD’: 9].
Step 2: Adopt a segmental coding method where there are coding segments in the rotation phase, and the shortest length of each coding segment is 1 and the longest is . Assume , . Randomly select equipment from and randomly select equipment from ,, where the equipment number and “prefix” together constitute the code segment, i.e., [1, ‘A’, ‘B’, 2, ‘CC’, ‘FF’]. This indicates that the first rotation is to rotate the equipment numbered ‘A’ and ‘B’ in to , and the second rotation is to rotate the equipment numbered ‘CC’ and ‘FF’ in to .
Add ‘A’ and ‘B’ to according to the remaining usable times, delete them in , add ‘CC’ and ‘FF’ to according to the remaining usable times, delete them in , update and , and obtain [‘C’: 5, ‘E’: 5, ‘F’: 6, ‘CC’: 6, ‘D’: 7, ‘FF’: 8] and [‘AA’: 3, ‘A’: 4, ‘B’: 6, ‘EE’: 7, ‘BB’: 7, ‘DD’: 9].
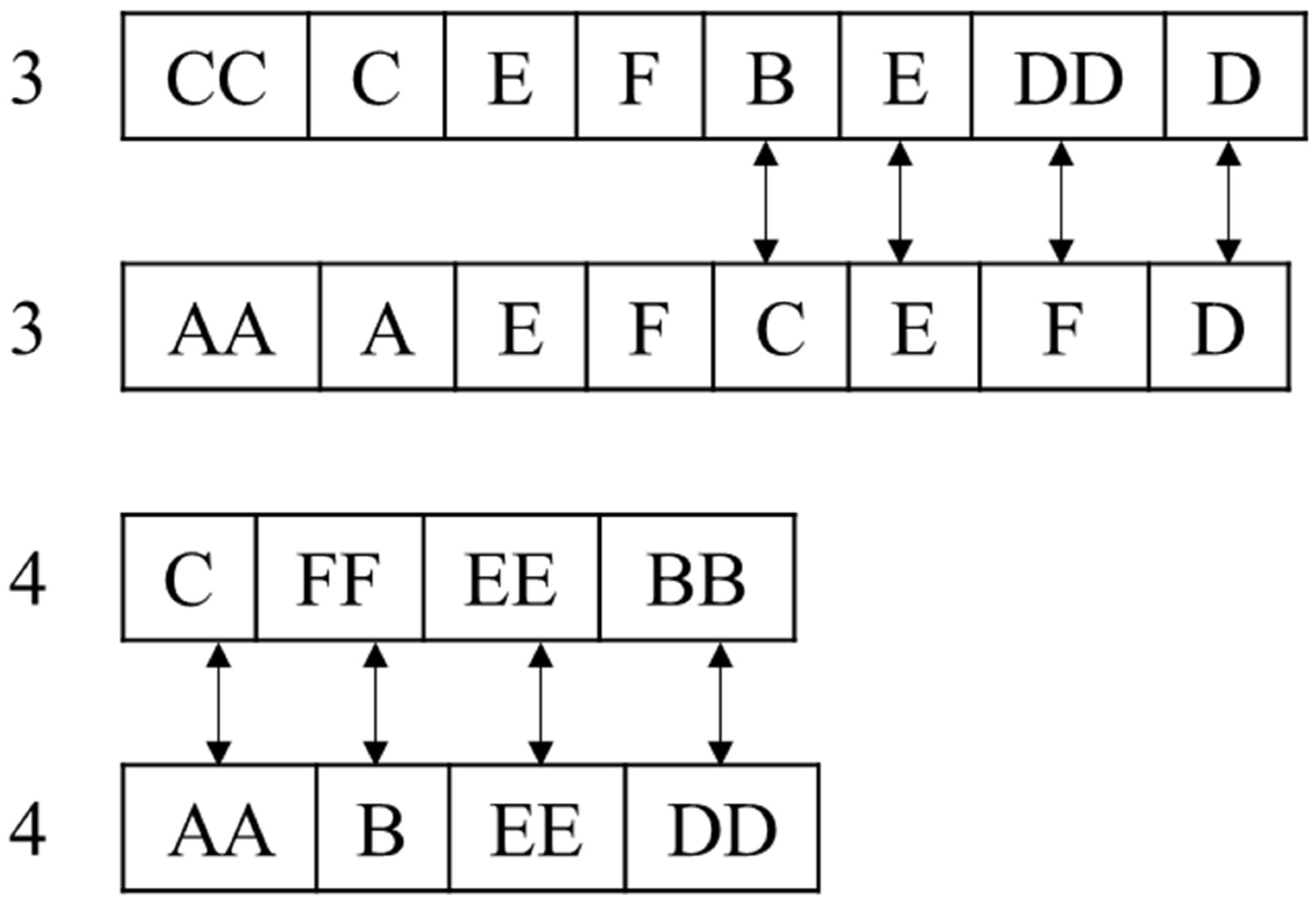
Step 3: In the task phase, the order of executing the task of the equipment is not considered in the same coding segment, but it cannot be reused. Gene can be reused in different coding segments, but the number of repetitions cannot exceed the corresponding remaining usable times. The total length of code in a task stage is . Assume , , , initialize the chromosome, select equipment from as a group, repeat times and select equipment from as a group, repeat times, such as [3, [‘CC’, ‘C’, ‘E’, ‘F’], [‘C’, ‘E’, ‘FF’, ‘D’], 4, [‘AA’, ‘B’, ‘EE’, ‘DD’]]. This coding method can be directly interpreted as selecting the equipment to complete the task. The segmented real-number coding conforms to the practical significance, and it is easy to control the upper limit of usage times.
Step 4: Combine the chromosomes of the two stages to acquire
[1, ‘A’, ‘B’, 2, ‘CC’, ‘FF’, 3, [‘CC’, ‘C’, ‘E’, ‘F’], [‘C’, ‘E’, ‘FF’, ‘D’], 4, [‘AA’, ‘B’, ‘EE’, ‘DD’]]. By the same token,
[1, ‘C’, 2, ‘DD’, ‘AA’, 3, [‘AA’, ‘A’, ‘E’, ‘F’], [‘B’, ‘E’, ‘DD’, ‘D’], 4, [‘C’, ‘FF’, ‘EE’, ‘BB’]].
is shown in
Figure 2, and
is shown in
Figure 3.
3.2. Population Initialization
Step 1: Population size , , , equipment numbers , such as [‘A’: 4, ‘C’: 5, ‘E’: 5, ‘F’: 6, ‘B’: 6, ‘D’: 7] and [‘AA’: 3, ‘CC’: 6, ‘EE’: 7, ‘BB’: 7, ‘FF’: 8, ‘DD’: 9];
Step 2: Initialize chromosome , acquire and and calculate the usage time of each equipment number in the chromosome in the format of “Number: Usage Times”. For example, of is [‘C’: 2, ‘E’: 2, ‘F’: 1, ‘CC’: 1, ‘D’: 1, ‘FF’: 1] and of is [‘AA’: 1, ‘B’: 1, ‘EE’: 1, ‘DD’: 1];
Step 3: Traverse the number in . If the usage time of the number is greater than the remaining usable time of the corresponding number in , return to Step 2. Otherwise, enter Step 4.
Step 4: Add to the , where . If return to Step 2. Otherwise, the population initialization is completed.
3.3. Crossover Operator
For different coding stages, the ectopic single point crossover method was adopted in the rotation stage, and the two-point crossover method was adopted in the task stage. The crossover operator steps are as follows.
Step 1: Given the crossover rate , , the new population size is , where , and .
Step 2: Select two parent individuals and define
and
. The paternal chromosomes are segmented according to the number “prefix”, as shown in
Figure 4.
Step 3: Combine the split parent individuals according to the same “prefix”. Because the first combinations belong to the rotation stage, the length of coding segments may be different, so the heterotopic single point crossover method is adopted.
For the code segment combination in the rotation stage:
Step 4: Randomly select two points and , where is the point selected from the coding segment with “prefix” of the parent . In addition, , , , and , where is the length of the coding segment of the parent with “prefix” .
Step 5: Generate a random number
between 0 and 1. If
and
, crossover the first
genes of the coding segment with
as the “prefix” in parent1 and the first
genes of the coding segment with
as the “prefix” in parent2.
, generate crossover results, as shown in
Figure 5, and enter Step 6. If
, do not crossover, return Step 4. If
, the parent individuals will be preserved in the new population.
The specific steps of modifying operator 1 are as follows.
Step 6: Calculate the repetitions of each number after crossover in the format “Number: Repetitions”. Iterate through the numbers in . If the repetitions of the number are 1 and the set of numbers is a subset of the number , acquire and enter Step 7. Otherwise, return to Step 10.
For the code segment combination in the task stage:
Step 7: Adopt the method of two-point crossing and randomly select two points, and , where , and .
Step 8: Generate a random number
between 0 and 1. If
and
, exchange genes between two points, and if
, generate crossover results, as shown in
Figure 6, and enter Step 9. If
and
do not cross, return to Step 7. If
, the parent individuals are added to the new population, with
.
The specific steps of modifying operator 2 are as follows.
Step 9: Calculate the number of repetitions of each character in each unit after crossover, where represents the individual number of the offspring after crossover, and represents the unit number in the format “Number: Quantity of Repetitions”. According to the different units, traverse the number in . If the number of repetitions is less than the number of repetitions of the corresponding number in of the corresponding unit and the number of is a subset of , enter Step 10. Otherwise, return to Step 7.
Step 10: Merge the cross results according to the “prefix” and add the results to the new population , where . If , return to Step 2. If , the crossover operator ends.
3.4. Mutation Operator
For different coding stages, the methods of gene mutation and gene length mutation are used, respectively. The steps of the mutation operator are as follows.
Step 1: Define the mutation rate , .
Step 2: Select the parent individuals, define , , and divide the chromosome according to the number “prefix”.
For the combination of rotation stage:
Step 3: Randomly select two points and , where and .
Step 4: Generate a random number
between 0 and 1. If
, delete the number except
in
to get
, and randomly select
numbers from
to replace it. Similarly, delete the number except
in
to get
, and randomly select
numbers from
to replace it. Generate the mutation results, as shown in
Figure 7, and enter Step 5. If
, do not generate the mutation, and return to Step 3.
Step 5: After obtaining the mutation results in the rotation stage, can be obtained according to the mutation results, such as [‘AA’: 3, ‘E’: 5, ‘F’: 6, ‘B’: 6, ‘D’: 7] and [‘A’: 4, ‘C’: 5, ‘CC’: 6, ‘EE’: 7, ‘BB’: 7, ‘FF’: 8, ‘DD’: 9].
For the code segment in the task phase:
Step 6: Traverse the code segment. If there is a number that does not belong to , it will be replaced with the number in according to the number of the remaining usage time.
Step 7: Randomly select the code segment of the parent to generate a random number between 0 and 1.
Step 8: If , enter Step 9, otherwise, return to Step 7.
Step 9: Calculate the number of gene repetitions excluding coding segment , and subtract from to acquire .
Step 10: This coding segment is mutated into a gene segment generated by the set , and no repeat genes are allowed.
This mutation operator ensures that the number repetitions of the chromosome gene after mutation is lower than the limit of the number repetitions, without using a new modifying operator, and improves the efficiency of the algorithm.
3.5. Population-Diversity-Preserving Operator
Step 1: Initialize the population, with the iteration number and the diversity-keeping parameter .
Step 2: Conduct the crossover, mutation and selection operators to generate a new generation of population, where .
Step 3: Judge whether is equal to 0. If the result is 0, enter Step 4; if the result is not 0, enter Step 5.
Step 4: Traverse all the individuals in the population, sequence the genes in the rotation phase of the individuals and count the number of gene repeats in the task phase. If there are individuals with the same rotation gene and the same number of repeats, the repeats will be replaced by a new, randomly generated individual.
3.6. Selection Operator
The selection operator of I-NSGA-III-VLC is used to select the population of the
iteration from the mixed population consisting of the population of the
iteration (the number is
) and the new offspring obtained by the genetic operator (the number is
). The individuals are sorted from largest to the smallest according to the non-dominated level [
30], and the individuals in the same non-dominated set are selected according to the reference point [
31,
32,
33,
34,
35,
36,
37]. A total of
individuals are obtained, which will be used as the next generation for the next iteration.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









