



TrojanDetector: A Multi-Layer Hybrid Approach for Trojan Detection in Android Applications




Abstract
:1. Introduction
- This work presents a multi-layer hybrid approach, i.e., TrojanDetector, to detect the Trojan’s misbehaviour in Android applications from three different Android levels based on the selected features and then apply multi-classifiers to train the model.
- This work uses four machine learning classifiers (random forest, support vector machine (SVM), logistic regression and, decision tree) for accurate Trojan detection in Android applications.
2. Related Work
3. TrojanDetector Approach
3.1. Threat Model
- Trojans can come automatically through the ad popups.
- Trojans can come by installing unauthorised applications.
- Trojans can enter the user space by fraud-clicking.
- Trojans can masquerade as legitimate programmes.
3.2. Attacks
- Trojans can exploit the granted permissions to perform actions not intentionally authorised by the OS.
- Trojans can harm user data. It can leak user credentials by exploiting compromised user data.
- Trojans can also steal user data by sending SMS and emails.
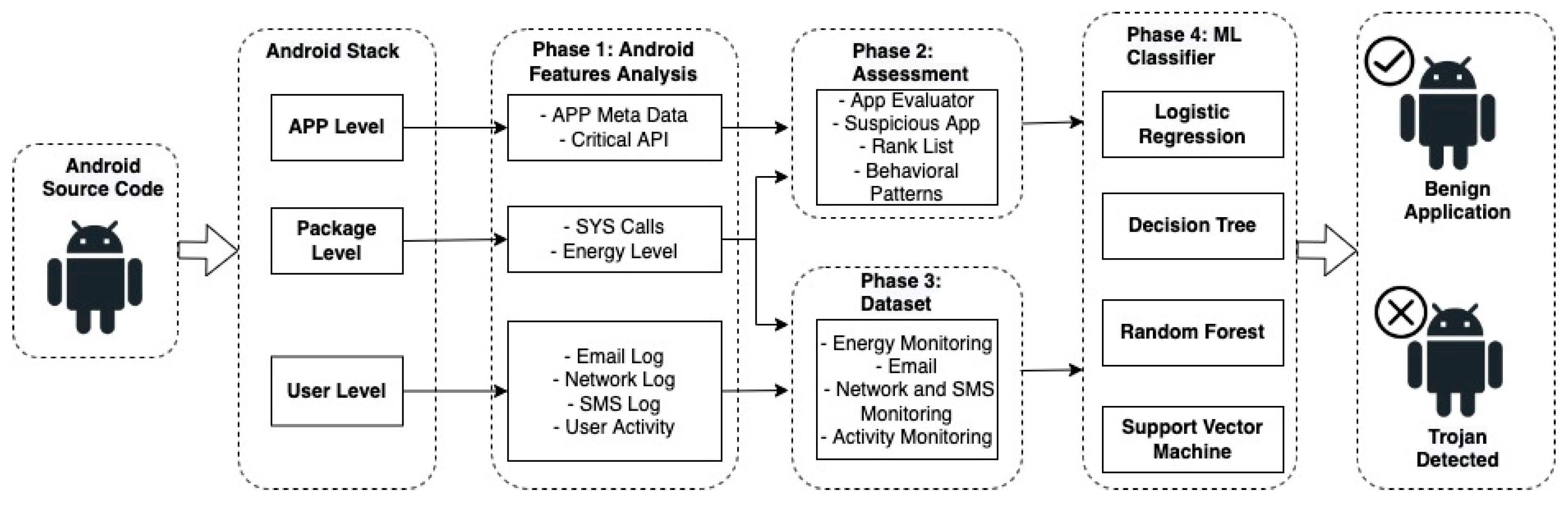
3.3. Trojan Detector
- Phase 1: TrojanDetector performs static analysis at the application level features, e.g., meta-data and critical API, and package level features, e.g., system calls and the energy level.
- Phase 2: TrojanDetector applies dynamic analysis at the user level features (activity/network, emails, SMS logs). Once triggered, it performs app evaluation, ranks lists, and extracts behavioural patterns.
- Phase 3: TrojanDetector extracts energy, email, SMS, and activity features.
- Phase 4: TrojanDetector feeds all the features extracted from all the stages to the chosen classifiers to apply classification.
| Algorithm 1 Detect Trojan |
|
4. Experimental Validation
4.1. Dataset
- CCCS-CIC-AndMal-2020: The dataset includes 200 K benign and 200 K malware samples of Android apps with 14 prominent and 191 eminent malware families. A dataset is generated in collaboration with the Canadian Centre for Cyber Security (CCCS) to capture 200 K android malware apps labelled and characterised into the corresponding family. The benign Android apps (200 K) are collected from the Androzoo dataset to balance the huge dataset. They collected 14 categories of malware, including adware, backdoor, file infector, Potentially Unwanted Apps (PUA), ransomware, scareware, riskware, trojan, trojan-banker, trojan-dropper, trojan-SMS, trojan-spy, and zero-day [25].
- Contagio Mobile: It is a blog-like website that collects malware for several mobile OS. Contagio presents more than 1000 samples for each Trojan family. Contagio has collected Trojans since 2012, including malicious apps found on Google Play, which may affect any Android device regardless of nationality [26].
- VirusShare: It is a website hosting a database of malware for several operating systems, which also includes a good share of Android malware. The database is continuously updated, and it is also possible to retrieve some of the latest threats discovered [27].
4.2. Features Extraction
| Algorithm 2 Calculating Network Stats |
| Input Trojan apps with the APPs Output Bandwidth value
|
- CPU Usage (package level feature: static) This feature describes the use of CPU cycles by the Trojan, as there are three levels of CPU utilization. (i) a high describes the highest level of CPU usage (2) (ii) a Medium means the medium amount of CPU usage (1), and (3) a low means the code is using minimum CPU cycles (1).
- App-Services (application-level feature: static) This feature describes whether the Trojan uses the dangerous services which start in the background or not. The value of this feature is also in Boolean.
- App-Permission (user-level feature: dynamic) This feature describes how the Trojan automatically uses dangerous permission. The value of this feature is also in Boolean.
- App-APIs (application feature: static) This feature describes how the Trojan uses third-party APIs designed to get users’ information without knowing them. It also describes whether these APIs are running in the background or not. The value of this feature is also in Boolean.
- Bandwidth-Consumed (user-level feature: dynamic) This feature describes the bandwidth consumed by a Trojan application for 30 s. It also uses third-party APIs designed to get the users’ information without knowing the use of the bandwidth. These APIs start in the background or not. The value of this feature is in Boolean.
- Is-SMS-Sent (user level feature: dynamic) This feature shows that the Trojan sends the SMS in the background, gets the user’s information without their knowledge, and monitors the sending numbers. The value of this feature is in Boolean.
- SMS-Quantity (user level feature: dynamic) This feature describes the number of sending SMS by the Trojan and its injected applications. It checks whether the Trojan is sending messages or not in the background, which gets the user’s information without their knowledge.
- Email-sent (user-level feature: dynamic) This feature describes that the Trojan sends the email in the background and gets the users’ information without their knowledge. It also monitors the number of sent Emails. The value of this feature is in Boolean.
- Email-Quantity: (user level feature: dynamic) This feature describes the number of sent emails and the injected applications of Trojans. It also checks that the email is sent in the background and gets information without the user’s knowledge. The value of this feature is also in numbers.
- Sys-Call-Invoked (package level feature: dynamic) This feature checks the system and whether the application invokes the system calls, e.g., turning off the ringtone, putting the phone into airplane mode, turning on the user location, etc. It checks whether or not the event in the background is getting the users’ information without their knowledge. The value of this feature is in Boolean.
- Sys-Call (application-level feature: static) This feature describes system calls invoked by the application.
4.3. Classifier Selection
4.4. Experimental Settings
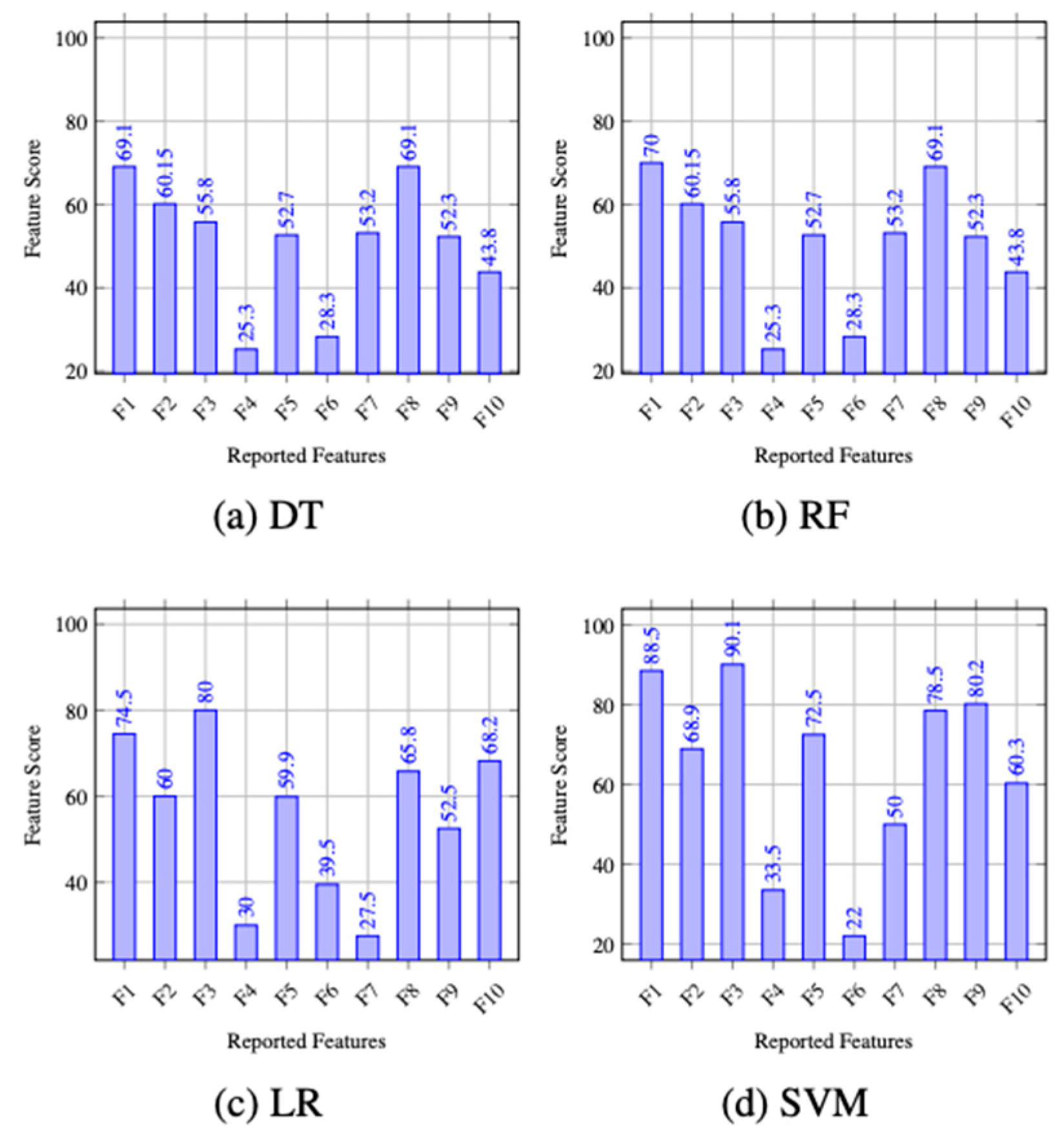
4.5. Feature Selection
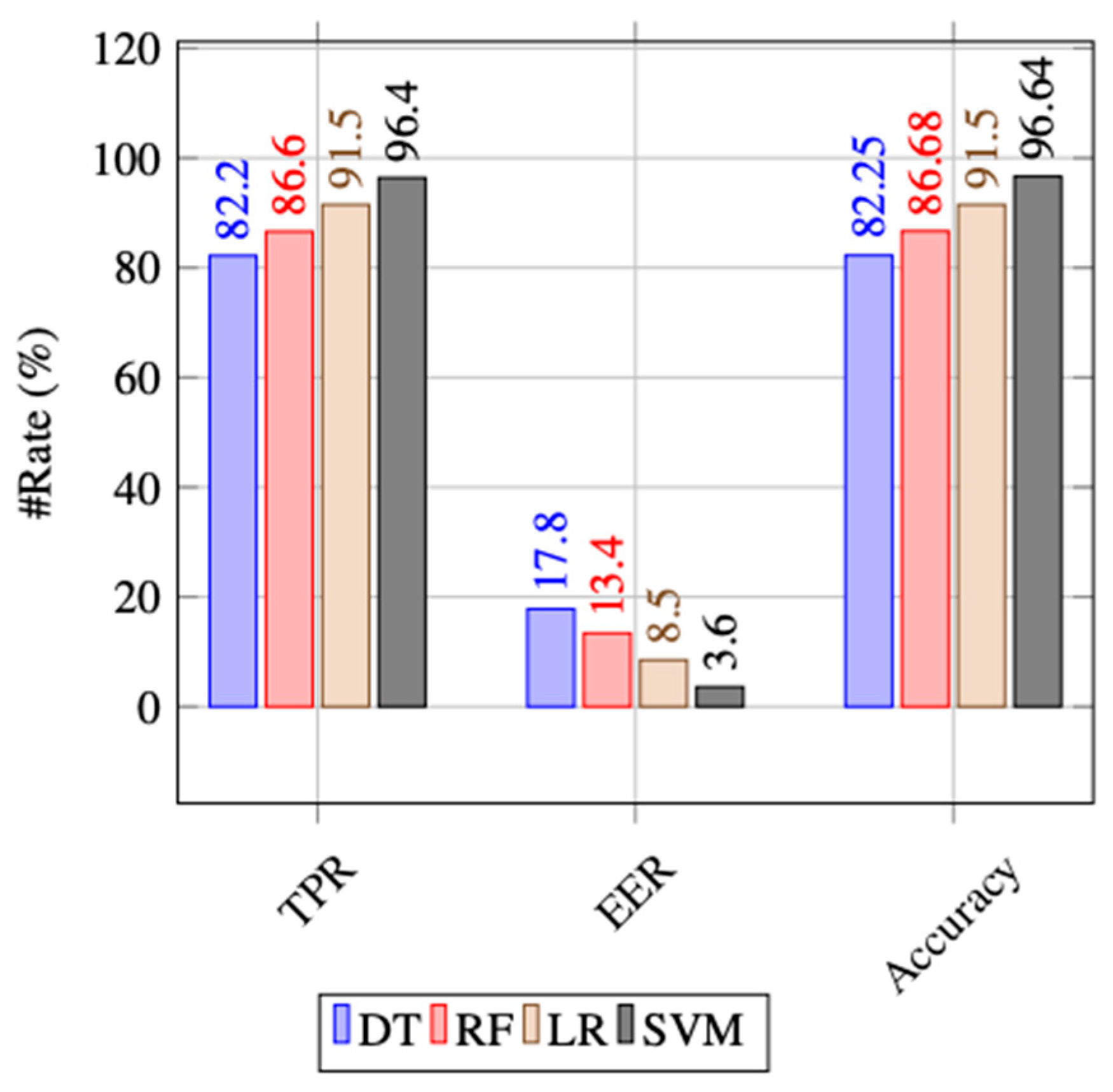
4.6. Experimental Results
4.7. Discussion on Results
4.8. Limitations
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wotring, B.; Potter, B. Host Integrity Monitoring: Using Osiris and Samhain; Books24x7.com: Norwood, MA, USA, 2005. [Google Scholar]
- Sharma, H.; Govindan, K.; Poonia, R.C.; Kumar, S.; Wael, M. Advances in Computing and Intelligent Systems. Springer Nat. 2022. [Google Scholar] [CrossRef]
- Tong, F.; Yan, Z. A hybrid approach of mobile malware detection in Android. J. Parallel Distrib. Comput. 2017, 103, 22–31. [Google Scholar] [CrossRef]
- Cayron, C. ARPGE: A computer program to automatically reconstruct the parent grains from electron backscatter diffraction data. J. Appl. Crystallogr. 2007, 40, 1183–1188. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Edraki, M.; Karim, N.; Rahnavard, N.; Mian, A.; Shah, M. Odyssey: Creation, Analysis and Detection of Trojan Models. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4521–4533. [Google Scholar] [CrossRef]
- Liu, K.; Xu, S.; Xu, G.; Zhang, M.; Sun, D.; Liu, H. A Review of Android Malware Detection Approaches Based on Machine Learning. IEEE Access 2020, 8, 124579–124607. [Google Scholar] [CrossRef]
- Felt, A.P.; Ha, E.; Egelman, S.; Haney, A.; Chin, E.; Wagner, D. Android permissions: User attention, comprehension, and behavior. In Proceedings of the Eighth Symposium on Usable Privacy and Security—SOUPS ’12, Washington, DC, USA, 11–13 July 2012; p. 1. [Google Scholar] [CrossRef]
- Baghirov, E. Techniques of Malware Detection: Research Review. In Proceedings of the 2021 IEEE 15th International Conference on Application of Information and Communication Technologies (AICT), Baku, Azerbaijan, 13–15 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Martín, A.; Lara-Cabrera, R.; Camacho, D. Android malware detection through hybrid features fusion and ensemble classifiers: The AndroPyTool framework and the OmniDroid dataset. Inf. Fusion 2018, 52, 128–142. [Google Scholar] [CrossRef]
- Hadiprakoso, R.B.; Kabetta, H.; Buana, I.K.S. Hybrid-Based Malware Analysis for Effective and Efficiency Android Malware Detection. In Proceedings of the 2020 International Conference on Informatics, Multimedia, Cyber and Information System (ICIMCIS), Jakarta, Indonesia, 19–20 November 2020; pp. 8–12. [Google Scholar] [CrossRef]
- Zhao, Y.-l.; Qian, Q. Android malware identification through visual ex-ploration of disassembly files. Int. J. Netw. Secur. 2018, 20, 1061–1073. [Google Scholar]
- Suarez-Tangil, G.; Dash, S.K.; Ahmadi, M.; Kinder, J.; Giacinto, G.; Cavallaro, L. DroidSieve: Fast and Accurate Classification of Obfuscated Android Malware. In Proceedings of the Seventh ACM on Conference on Data and Application Security and Privacy, Scottsdale, AZ, USA, 22–24 March 2017; pp. 309–320. [Google Scholar] [CrossRef]
- Sriyanto; Sahrin, S.B.; Faizal, A.M.; Suryana, N.; Suhendra, A. MiMaLo: Advanced Normalization Method for Mobile Malware Detection. Int. J. Mod. Educ. Comput. Sci. (IJMECS) 2022, 14, 24–33. [Google Scholar] [CrossRef]
- Cai, H.; Meng, N.; Ryder, B.; Yao, D. DroidCat: Effective Android Malware Detection and Categorization via App-Level Profiling. IEEE Trans. Inf. Forensics Secur. 2018, 14, 1455–1470. [Google Scholar] [CrossRef]
- Bokolo, B.; Sur, G.; Liu, Q.; Yuan, F.; Liang, F. Hybrid Analysis Based Cross Inspection Framework for Android Malware Detection. In Proceedings of the 2022 IEEE/ACIS 20th International Conference on Software Engineering Research, Management and Applications (SERA), Las Vegas, NV, USA, 25–27 May 2022; pp. 99–105. [Google Scholar]
- Gan, Y.; Qian, H.; Gao, Y. Combining traditional machine learning and anomaly detection for several imbalanced Android malware dataset’s classification. In Proceedings of the 2022 7th International Conference on Machine Learning Technologies (ICMLT), Rome, Italy, 11–13 March 2022; pp. 74–80. [Google Scholar]
- Qamar, A.; Karim, A.; Chang, V. Mobile malware attacks: Review, taxonomy & future directions. Futur. Gener. Comput. Syst. 2019, 97, 887–909. [Google Scholar] [CrossRef]
- Yuan, Z.; Lu, Y.; Xue, Y. Droiddetector: Android malware characterization and detection using deep learning. Tsinghua Sci. Technol. 2016, 21, 114–123. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, M.F.; Biash, Z.T.; Shakil, A.R.; Ryen, A.A.N.; Hossain, A.; Ashraf, F.B.; Hossain, M.I. ShielDroid: A Hybrid Approach Integrating Machine and Deep Learning for Android Malware Detection. In Proceedings of the 2022 International Conference on Decision Aid Sciences and Applications (DASA), Chiangrai, Thailand, 23–25 March 2022; pp. 911–916. [Google Scholar]
- Aminuddin, N.I.; Abdullah, Z. Android Trojan Detection Based on Dynamic Analysis. 2019. Available online: https://fazpublishing.com/acis/index.php/acis/article/view/4 (accessed on 21 August 2022).
- Kumar, R.; Kumar, P.; Tripathi, R.; Gupta, G.P.; Islam, A.K.M.N.; Shorfuzzaman, M. Permissioned Blockchain and Deep Learning for Secure and Efficient Data Sharing in Industrial Healthcare Systems. IEEE Trans. Ind. Inform. 2022, 18, 8065–8073. [Google Scholar] [CrossRef]
- Kumar, P.; Kumar, R.; Gupta, G.P.; Tripathi, R.; Srivastava, G. P2TIF: A Blockchain and Deep Learning Framework for Privacy-Preserved Threat Intelligence in Industrial IoT. Trans. Ind. Inform. 2022, 18, 6358–6367. [Google Scholar] [CrossRef]
- Kumar, P.; Kumar, R.; Gupta, G.P.; Tripathi, R. BDEdge: Blockchain and Deep-Learning for Secure Edge-Envisioned Green CAVs. IEEE Trans. Green Commun. Netw. 2022, 6, 1330–1339. [Google Scholar] [CrossRef]
- Kumar, R.; Kumar, P.; Tripathi, R.; Gupta, G.P.; Garg, S.; Hassan, M.M. BDTwin: An Integrated Framework for Enhancing Security and Privacy in Cybertwin-Driven Automotive Industrial Internet of Things. IEEE Internet Things J. 2022, 9, 17110–17119. [Google Scholar] [CrossRef]
- Rahali, A.; Lashkari, A.H.; Kaur, G.; Taheri, L.; Gagnon, F.; Massicotte, F. DIDroid: Android Malware Classification and Characterization Using Deep Image Learning. In Proceedings of the 2020 the 10th International Conference on Communication and Network Security, Tokyo, Japan, 27–29 November 2020; pp. 70–82. [Google Scholar] [CrossRef]
- Mila, P. Contagiodump. Available online: http://contagiodump.blogspot.com/ (accessed on 21 August 2022).
- Virusshare. Available online: https://virusshare.com/ (accessed on 21 August 2022).
- Alpaydin, E. Machine Learning; MIT Press: Cambridge, UK, 2021. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Trojan Detectors | Dataset Used | Intrusion Detection and Classification Techniques | Feature Selection on Layers for Intrusion Detection | Analysis Approach | Accuracy of Malware Detection |
|---|---|---|---|---|---|
| MiMaLo [13] | MiMaLo technique | Neural Network Algorithm | Application | Static | 88.5% |
| DroidSieve [12] | exploited obfuscation-invariant features | Obfuscation | 99.82% | ||
| Bokolo et al. [15] | Tested on emulators | STAMINA approach based on DL | Application | Dynamic | Nil |
| Yuan et al. [18] | Apps: Google play store and Malware: from Contagio community and Gnome project | DBN-based DL | 96.76% | ||
| Gan et al. [16] | CICAndMal2017 | ML-based random forest model | 98% | ||
| DroidCat [14] | Drebin and Gnome along with virus total and virus share databases | Supervised ML | 97% | ||
| Aminuddin et al. [20] | Trojan dataset from Drebin and google play store | Random forest, Naive Bayes, and J48 | 81.2% | ||
| Martin et al. [17] | OmniDroid | AndroPyTool | Application | Hybrid | 89.7% |
| Hadiprakoso et al. [18] | Genome & CICMalDroid | ML & DL | |||
| Tong and Yan [3] | Own data set created by comparing the patterns of malware and benign apps | Offline comparisons of dynamic patterns set to judge the unknown app. | 88% | ||
| ShielDroid [19] | CICMalDroid | Random forest, and Multilayer perceptron | 97% | ||
| TrojanDetector | CCCS-CIC-AndMal-2020, Cantagio-Mobile and Virusshare with 13,559 Trojan samples | Random forest, decision tree, Linear Regression, and SVM | (MultiLayer) Application, user and package layers | Hybrid | 86.68% with an EER of 0.1346 and 96.64%, with an EER of 0.036 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ullah, S.; Ahmad, T.; Buriro, A.; Zara, N.; Saha, S. TrojanDetector: A Multi-Layer Hybrid Approach for Trojan Detection in Android Applications. Appl. Sci. 2022, 12, 10755. https://doi.org/10.3390/app122110755
Ullah S, Ahmad T, Buriro A, Zara N, Saha S. TrojanDetector: A Multi-Layer Hybrid Approach for Trojan Detection in Android Applications. Applied Sciences. 2022; 12(21):10755. https://doi.org/10.3390/app122110755
Chicago/Turabian StyleUllah, Subhan, Tahir Ahmad, Attaullah Buriro, Nudrat Zara, and Sudipan Saha. 2022. "TrojanDetector: A Multi-Layer Hybrid Approach for Trojan Detection in Android Applications" Applied Sciences 12, no. 21: 10755. https://doi.org/10.3390/app122110755
APA StyleUllah, S., Ahmad, T., Buriro, A., Zara, N., & Saha, S. (2022). TrojanDetector: A Multi-Layer Hybrid Approach for Trojan Detection in Android Applications. Applied Sciences, 12(21), 10755. https://doi.org/10.3390/app122110755