Appendix D.1. Cartpole from OpenAI Gym
In this environment, a simple control problem is simulated where a pole on a cart needs to be balanced so it can stand vertically by adjusting the cart in a horizontal direction. The state of this environment consists of the following: cart position(), cart velocity(), pole angle(), and pole angular velocity(). Since the cart is moving horizontally, there are two possible actions that push the cart to the left or right.
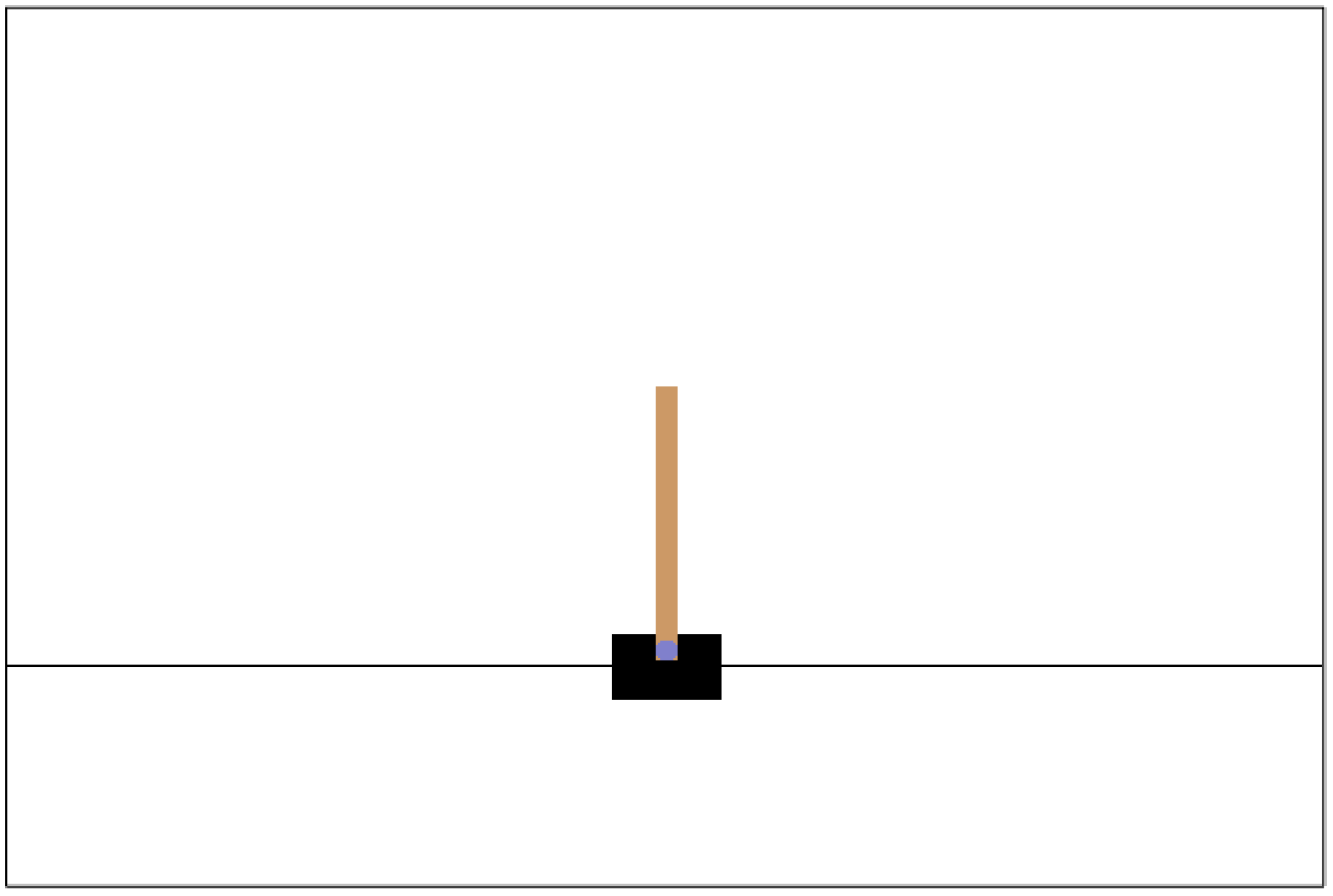
Figure A1.
The illustration of the Cartpole environment from openAI gym.
Figure A1.
The illustration of the Cartpole environment from openAI gym.
The original reward was calculated by giving the reward in each time step when the pole is upright. Otherwise, zero rewards will be given if the pole falls. However, to accommodate the decomposition of the reward, we modify the reward calculation as follows:
Cart position reward: ;
Pole angle reward: ;
Total reward: .
We set the reward weight as 0.2 and 0.8 for the cart position reward () and pole angle reward (), respectively. The higher weight for the pole angle reward is given because it is the main task of this environment. In this manner, the agent is trained not only to keep the pole upright but also to position the cart at the center of the work area.
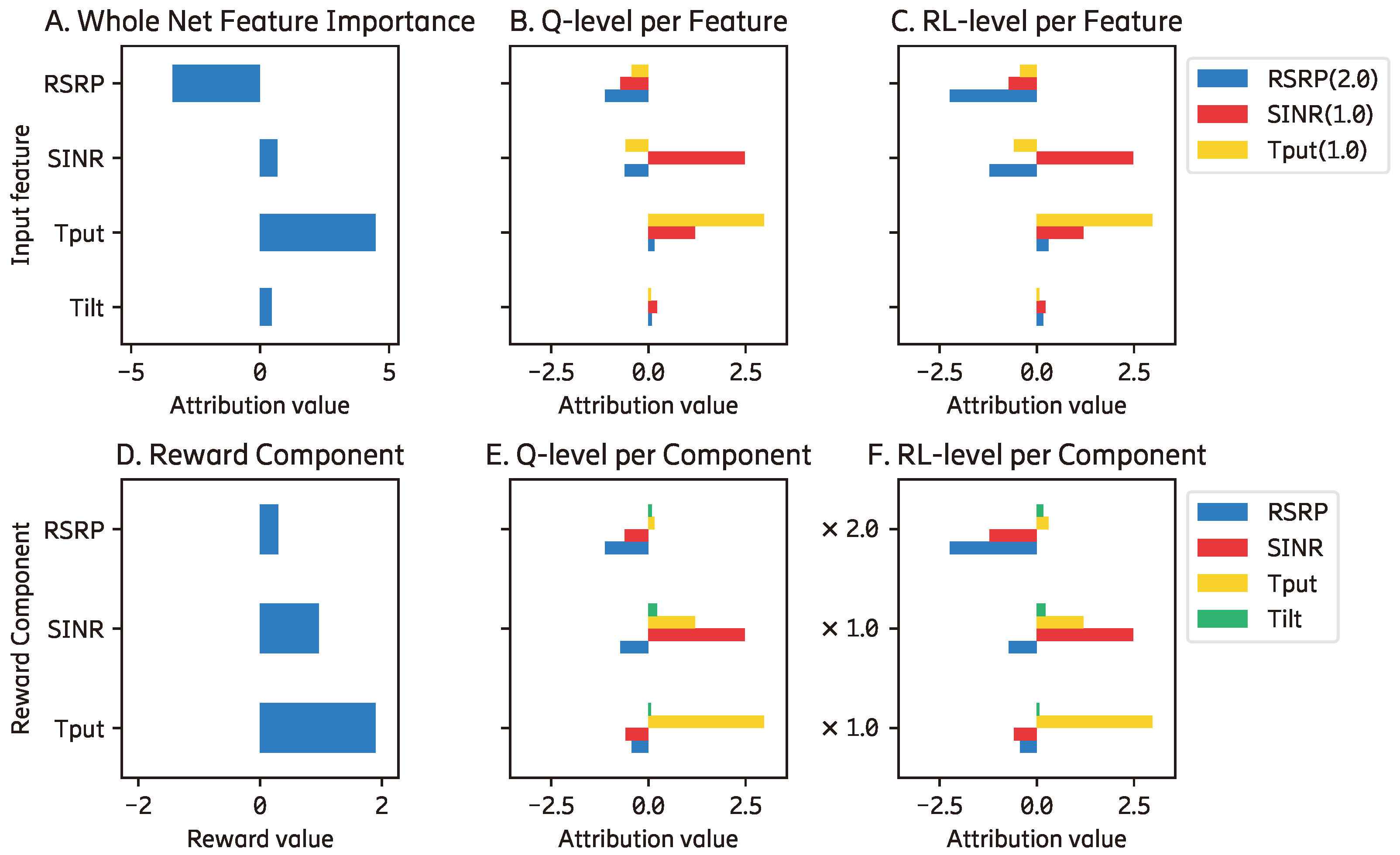
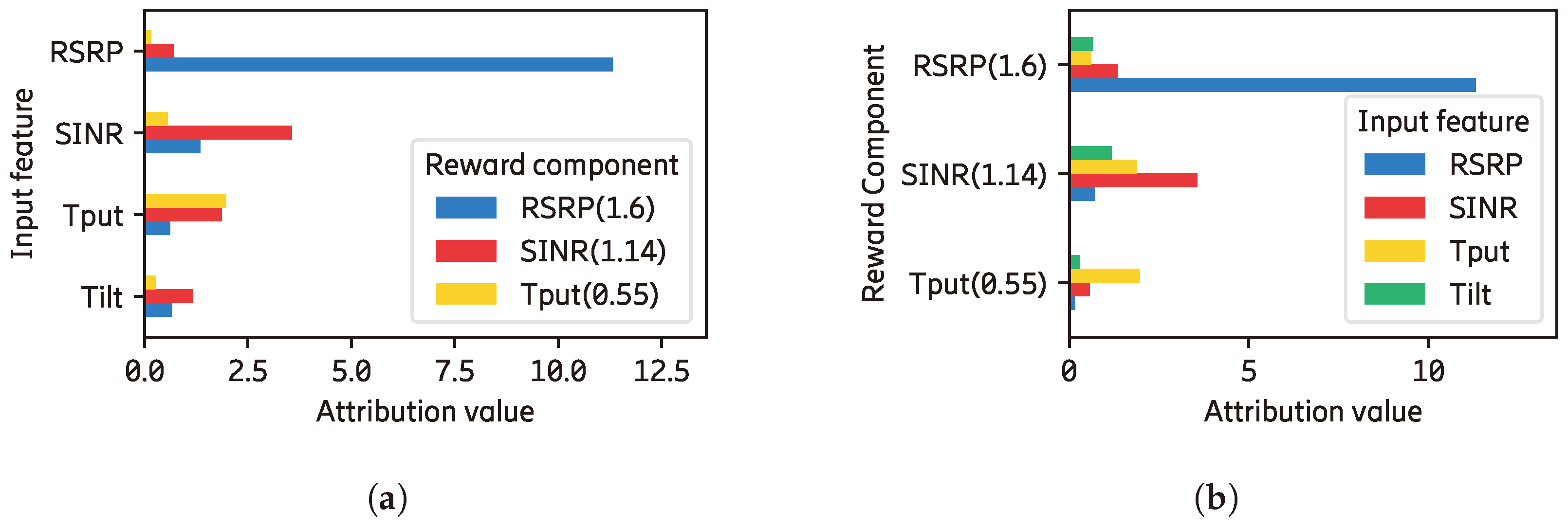
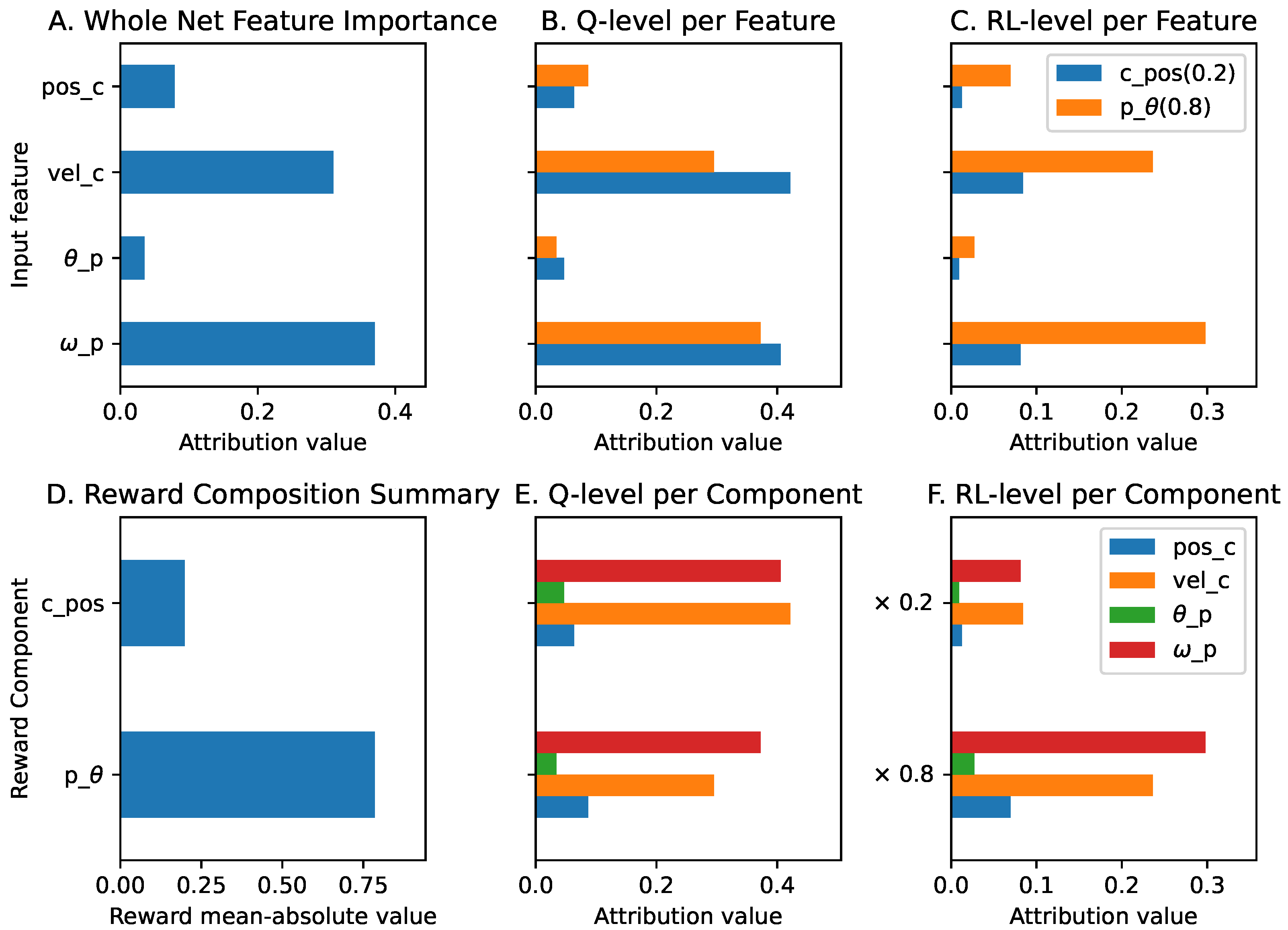
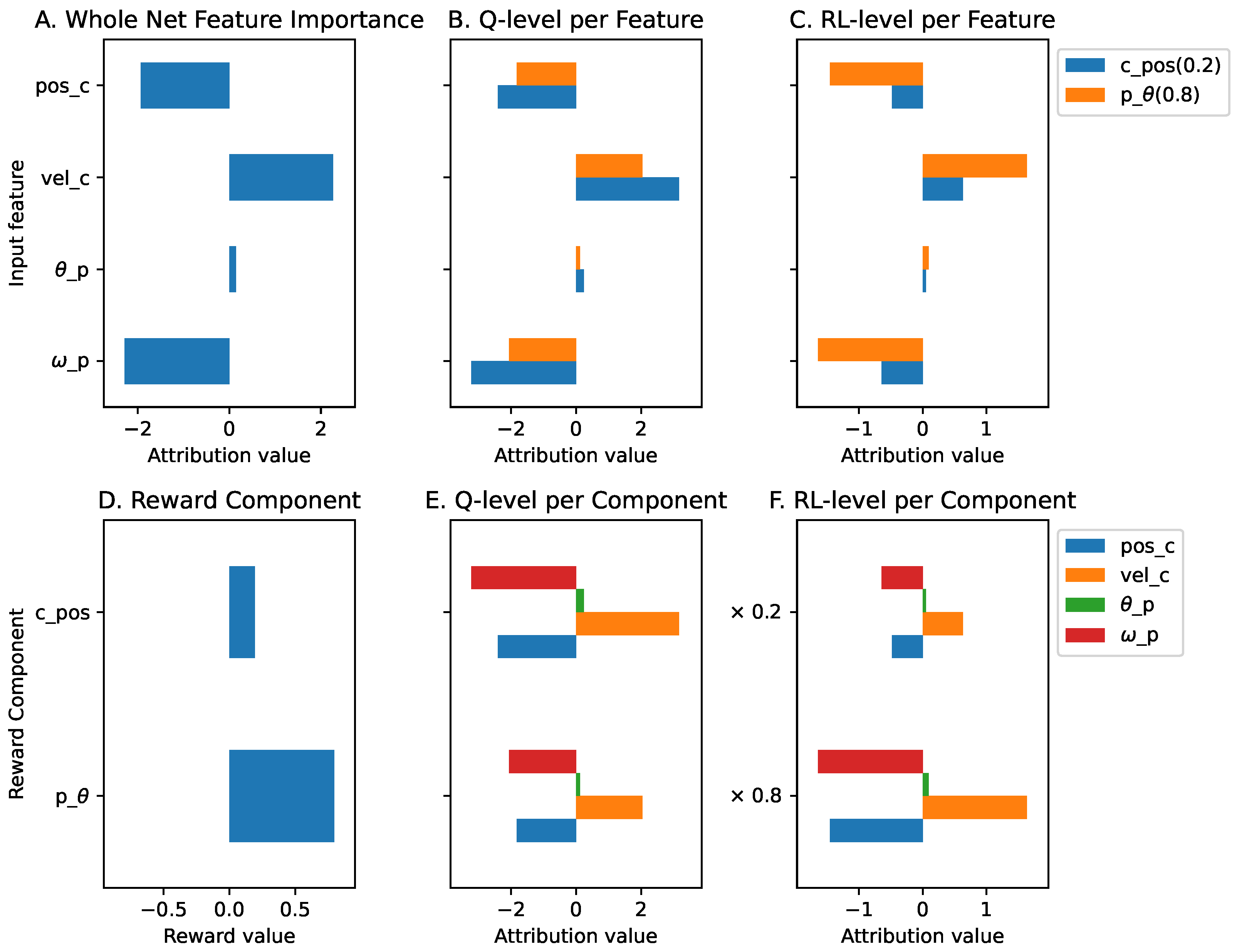
The global explanations of the agent in this environment are shown in
Figure A2. At the Q-function level, all input features other than the position of the cart (
) have higher contributions to the position of the cart (
) than the pole angle’s (
) reward component. However, after applying the reward prioritization, the pole angle reward component dominates the contribution at the RL level. We can also see that the cart and pole angular velocity’s (
and
) input features are the two most important features. Both have significant contributions to both the cart position (
) and pole angle (
) reward components. When we compare the contribution of all input features and the reward components, as shown in
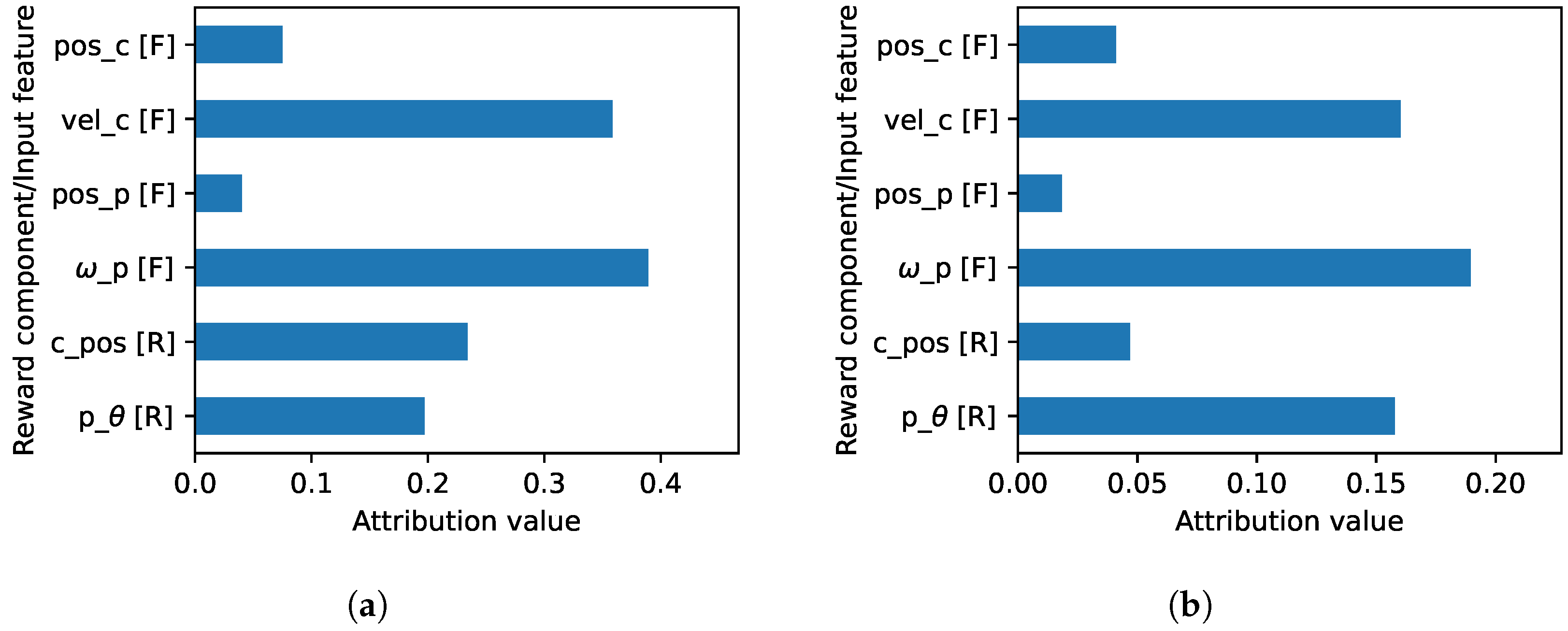
Figure A3b, both the velocity input features (
and
) and the
reward component are the most contributing elements in the trained agent.
Figure A2.
The global explanations of the cartpole agent.
Figure A2.
The global explanations of the cartpole agent.
Figure A3.
The normalized explanations of the cartpole agent where the importance of the input features and the reward components are compared in the same plot. (a) Normalized explanation at the Q-function level. (b) Normalized explanation when the reward weight is applied (at RL-level).
Figure A3.
The normalized explanations of the cartpole agent where the importance of the input features and the reward components are compared in the same plot. (a) Normalized explanation at the Q-function level. (b) Normalized explanation when the reward weight is applied (at RL-level).
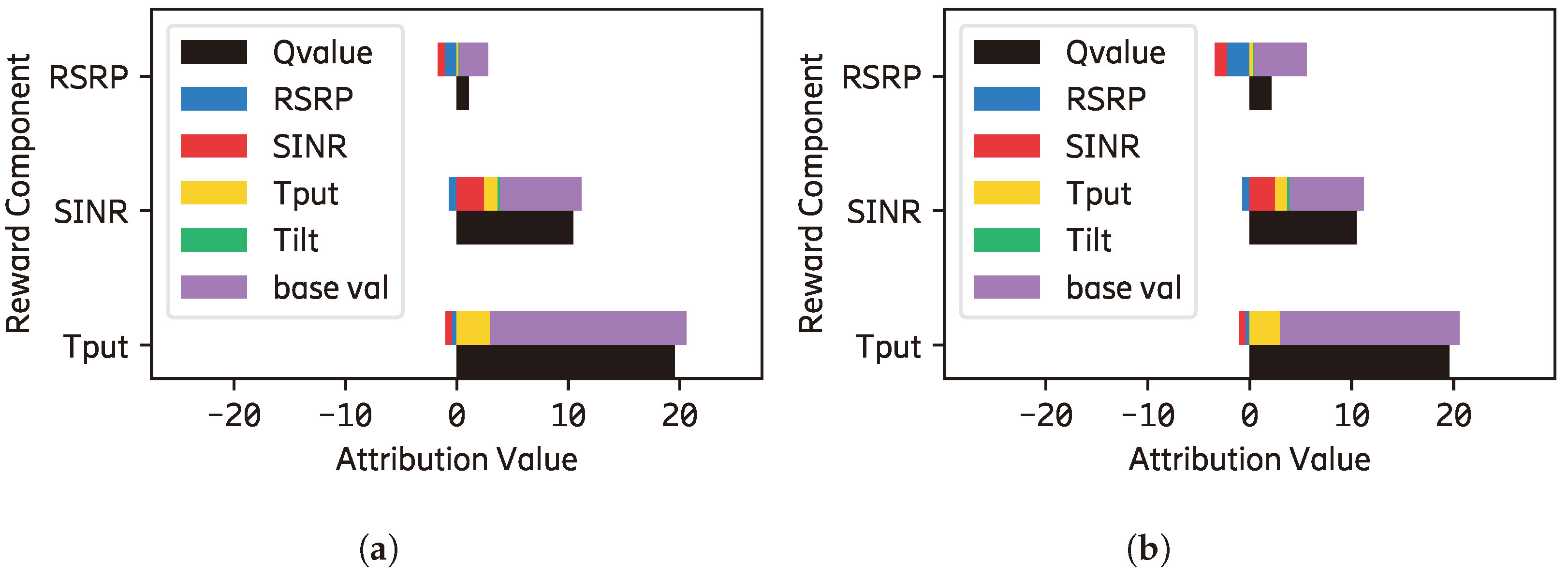
For local explanations, we can see from
Figure A4 that, in that particular situation, opposing contributions are made by the cart position (
) and velocity (
) input features to both reward components. This information may not be obtained if we use the existing method (feature importance and reward decomposition) exclusively.
Figure A5 presents the contrastive explanation in which the agent chooses the push-right action instead of push-left. The sum contribution of ‘
[I] to [R]’ and ‘
[I] to ’ is enough to outweigh the disadvantage of not choosing the push-left action. This explanation is further compressed by Algorithm 1 to present that only the contribution of
input feature is enough to outweigh the disadvantage of the same situation.
Figure A4.
The local explanations of the cartpole when the agent chooses the push-right action.
Figure A4.
The local explanations of the cartpole when the agent chooses the push-right action.
Figure A5.
The contrastive explanation showing why the agent chooses push-right instead of push-left action.
Figure A5.
The contrastive explanation showing why the agent chooses push-right instead of push-left action.
Table A3 presents the base values of each action and reward component for both in normalized and weighted values. In contrast to the antenna tilt use case, we want this agent to prioritize the angle of the pole more than the position of the cart. Thus, after applying the reward weight, we can see that the pole angle has higher base values than the cart position reward component. We want the cart position and velocity input feature to contribute more to the cart position reward component. Additionally, all input features other than cart position should have a significant impact on the pole angle reward component. These desired properties are set in
Table A4 which will be used to generate the focus values as presented in
Table A5. We can see that the focus value of the cart position is lower than the pole angle because there is a significant contribution from the pole velocity input feature to this reward component. The unweighted mean shows the mean of focus values without applying the reward prioritization, while the weighted mean quantifies the fulfillment of the desired properties of the global explanation.
Table A3.
Base values of the cartpole agent.
Table A3.
Base values of the cartpole agent.
| | Unweighted | Weighted |
|---|
| Action | Cart_position | Pole_angle | Cart_position | Pole_angle |
| push_Left | 91.209076 | 85.066811 | 18.241844 | 68.053467 |
| push_right | 90.984283 | 85.097321 | 18.196852 | 68.077972 |
| mean | 91.096680 | 85.082062 | 18.219349 | 68.065720 |
| range | 0.124793 | 0.030510 | 0.044992 | 0.024505 |
Table A4.
Relevance table for the cartpole agent.
Table A4.
Relevance table for the cartpole agent.
| Reward | Input Feature |
|---|
| Component | Cart_position | Cart_velocity | Pole_angle | Pole_velocity |
| cart_position | 1.0 | 1.0 | 0.5 | 0.5 |
| pole_angle | 0.5 | 1.0 | 1.0 | 1.0 |
Table A5.
Focus value of the cartpole agent.
Table A5.
Focus value of the cartpole agent.
| | Cart_position | Pole_angle | Weighted_mean | Unweighted_mean |
|---|
| focus value | 0.758693 | 0.944922 | 0.907676 | 0.851807 |
Appendix D.2. LunarLander from OpenAI Gym
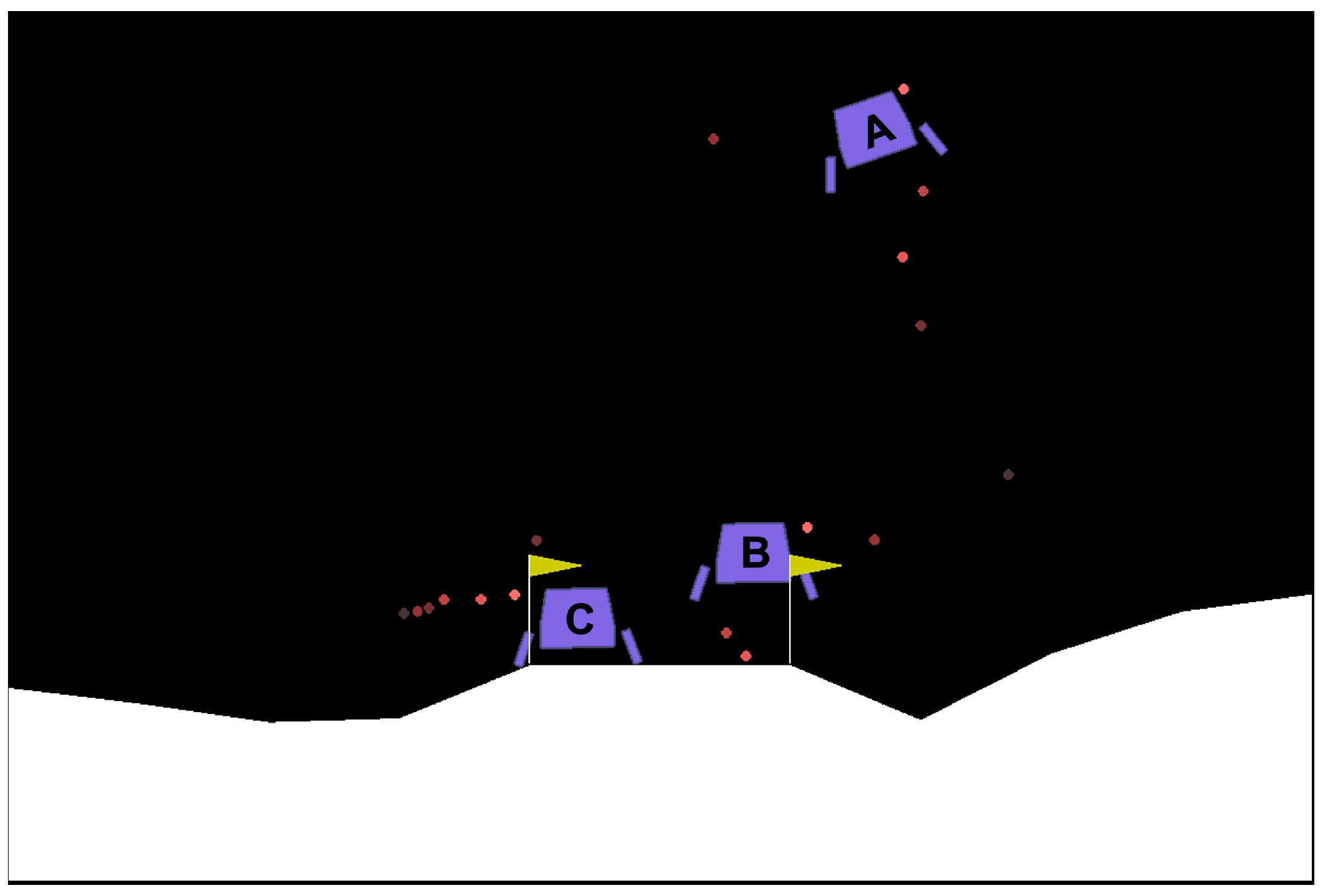
In this environment, the agent controls the engine to land the lunar lander at the origin
, which is illustrated as a point in the middle of the two flags in
Figure A6. Despite being a simple simulator, it formulates a complex problem where more input features are involved and affect differently to different reward components. There are four discrete actions available, which are no operation, fire left, fire up, or fire right. The inputs (state variables) of the RL agent consist of the horizontal coordinate (
), vertical coordinate (
), horizontal velocity (
), vertical velocity (
), angle (
), angular speed (
), and its legs (left,
and right,
) contact status, i.e., touching the moon or not.
Figure A6.
The illustration of the Lunarlander environment from openAI gym where the lunar lander (purple) has to land in the middle of yellow flag. A, B, and C are the three states showing the initial, middle, and final phase of the landing process, respectively.
Figure A6.
The illustration of the Lunarlander environment from openAI gym where the lunar lander (purple) has to land in the middle of yellow flag. A, B, and C are the three states showing the initial, middle, and final phase of the landing process, respectively.
By default, the reward of the lunar lander environment is given as a single value considering the total improvement of all combined factors which are position, velocity, angle, legs contact status, main and side engine activity. To apply our solution, we expose the reward calculation by assigning each factor to the respective reward component () function and the reward prioritization. The reward component functions are configured to generate a normalized value, as implemented in the following formulas:
Position reward:
Velocity reward:
Angle reward:
reward:
reward:
Main engine reward:
Side engine reward:
For the first five components, we follow the same mechanism as the original implementation to calculate the improvement of each reward component, i.e.,
where
t denotes the time step.
and
are modified by adding the
calculation (
) while the others remain the same as the original implementation. This is performed to guide the
leg component to approach the moon surface, which is also performed in [
8].
Reward prioritization is implemented as a linear function (
) where
is the weight or multiplication factor of the respective component. In this way, the exact reward weight/prioritization can be presented in a ratio format, i.e.,
for
, respectively.
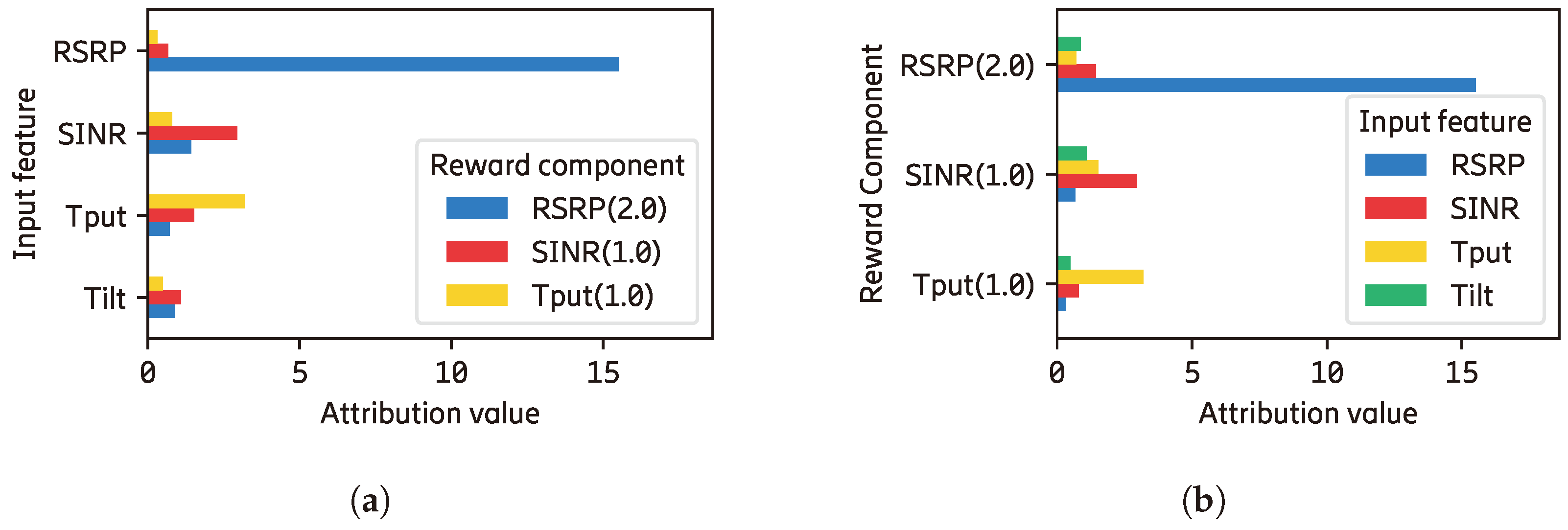
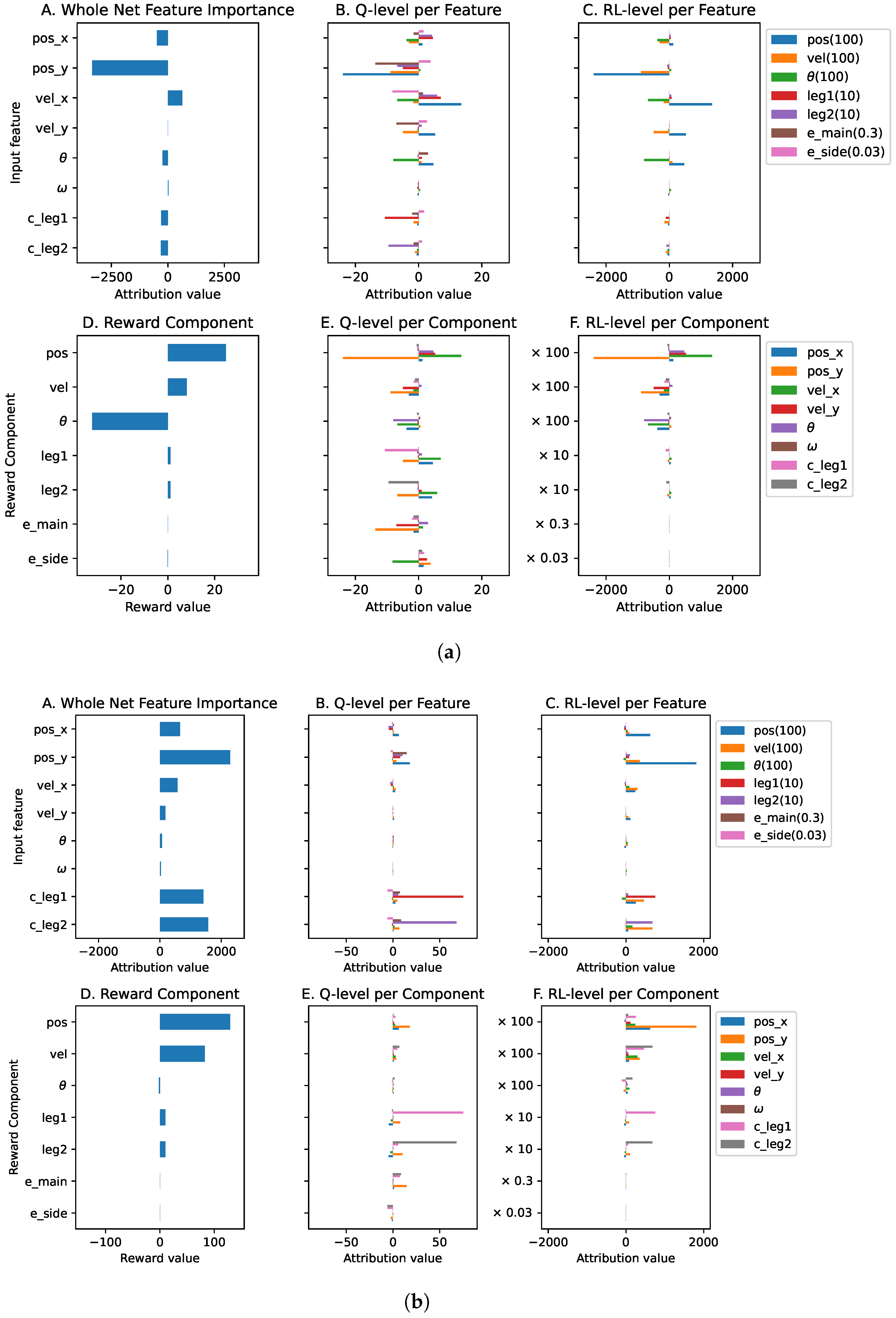
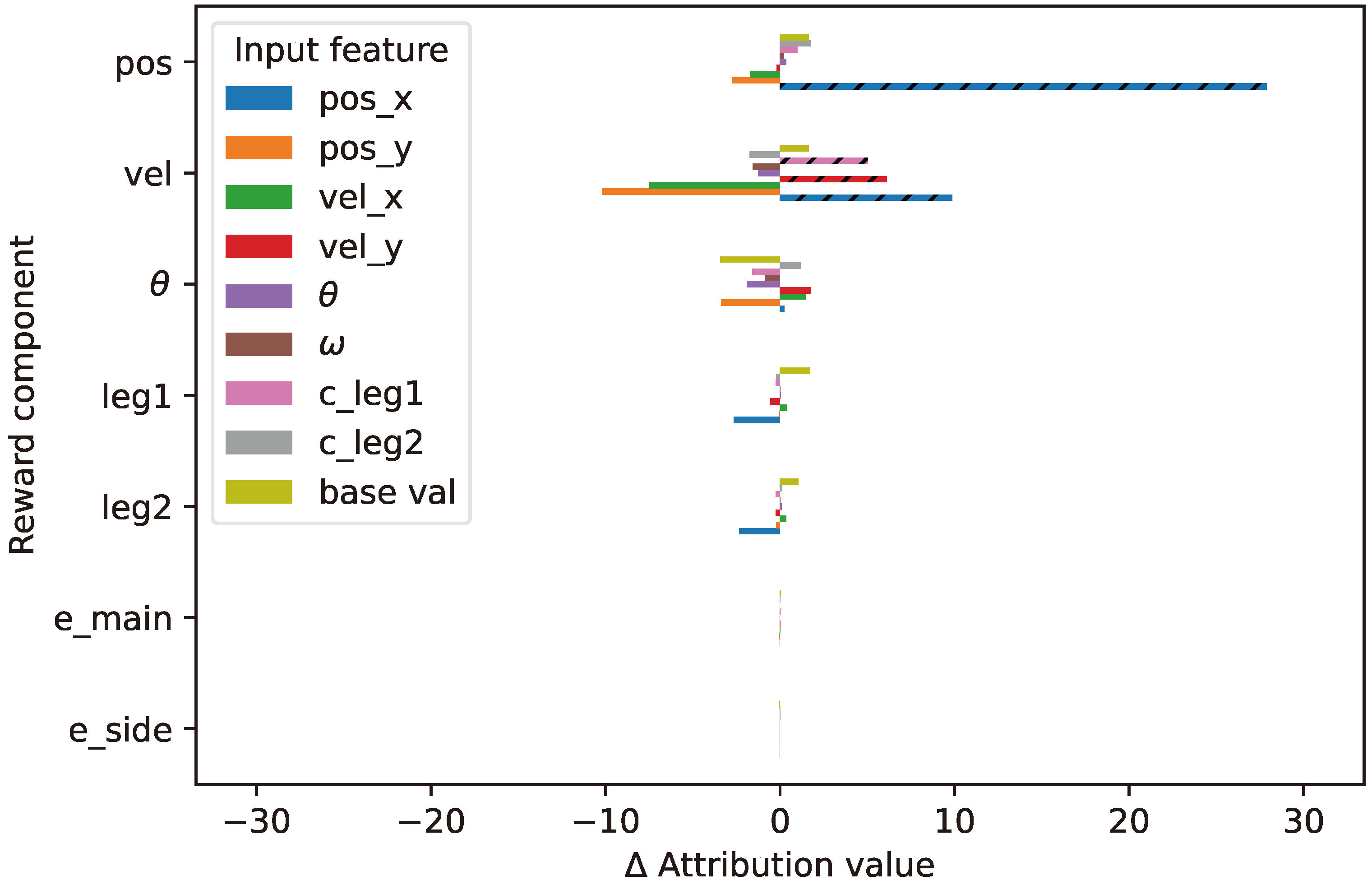
Figure A7 shows two different levels of explanation where we observe that each reward component has input features that contribute to it at the Q-level. However, due to the high difference in reward priority (100 and 0.03), the contributions of input features to the main and side engine reward components are barely visible at the RL-level. Without decoupling the reward priority from the reward function, the NN of the Q-function can generate a high value (up to 2000), which is susceptible to gradient explosion. In contrast, when the NN output is too low, it is susceptible to a vanishing gradient problem.
Figure A7B shows the detailed explanations on how each input feature contributes to every reward component. Input feature
contributes significantly to the position and the main engine reward components, which is desirable. We can also see that both the leg-contact input features (
and
) contribute significantly to the respective leg reward components.
Figure A8 shows the comparison of the input feature and the reward component at two different levels. We can see that when reward prioritization is not applied (
Figure A8a), several elements have significant contributions in generating the Q-values prediction. On the other hand, when reward prioritization is applied (
Figure A8b), the input feature
and the position reward component contribute the highest compared to others.
Figure A7.
The global explanations of the Lunarlander agent.
Figure A7.
The global explanations of the Lunarlander agent.
Figure A8.
The normalized explanations of the Lunarlander agent where the importance of the input features and the reward components are compared in the same plot. (a) Normalized explanation at the Q-function level. (b) Normalized explanation when the reward weight is applied (at RL-level).
Figure A8.
The normalized explanations of the Lunarlander agent where the importance of the input features and the reward components are compared in the same plot. (a) Normalized explanation at the Q-function level. (b) Normalized explanation when the reward weight is applied (at RL-level).
In a local scope,
Figure A9 shows the explanations of two different states of the lunar lander.
Figure A9a show the explanations for choosing the fire_right action in the initial phase of the landing process. We can see that pos_y input feature contributes negatively to several reward components and at the RL level it significantly contributes to the position and velocity reward component. This explanation makes sense because the lander is still far from the moon’s surface. Furthermore, we can also see that the angle (
) input feature contributes negatively to the angle (
) reward component because the lander is rotated. The explanation of when the lander has landed on the moon (
Figure A6 position C) is shown in
Figure A9b. At the Q-level explanation, we can see that the contributions of the leg contact input features that contribute to the respective leg reward components are significant compared to others. However, at the RL-level, the contribution of pos_y input feature to the position reward component is the highest due to reward prioritization, while the contributions of the respective legs elements become the second and third.
Figure A9.
The local explanations of the Lunarlander of three different states as shown in
Figure A6. (
a) The local explanations of the Lunarlander when the agent chooses fire_right action on position A in
Figure A6. (
b) The local explanations of the Lunarlander when the agent chooses fire_left action on position C in
Figure A6.
Figure A9.
The local explanations of the Lunarlander of three different states as shown in
Figure A6. (
a) The local explanations of the Lunarlander when the agent chooses fire_right action on position A in
Figure A6. (
b) The local explanations of the Lunarlander when the agent chooses fire_left action on position C in
Figure A6.
When comparing two actions, the contrastive explanation shows the benefit of choosing an action over the other, as shown in
Figure A10. By applying the MSX concept, the contributions of
“pos_x[I] to pos[R]”,
“pos_x[I] to vel[R]”,
“vel_y[I] to vel[R]”, and
“c_leg1[I] to vel[R]” are enough to choose fire_right action and outweigh the disadvantage of not choosing no_fire action. Furthermore, our automatic MSX compression (Algorithm 1) reduces the length of the explanation to only present the contributions of position and velocity reward components to be presented to the user.
Figure A10.
The contrastive explanation showing why the agent chooses fire_right instead of no_fire action on position B in
Figure A6.
Figure A10.
The contrastive explanation showing why the agent chooses fire_right instead of no_fire action on position B in
Figure A6.
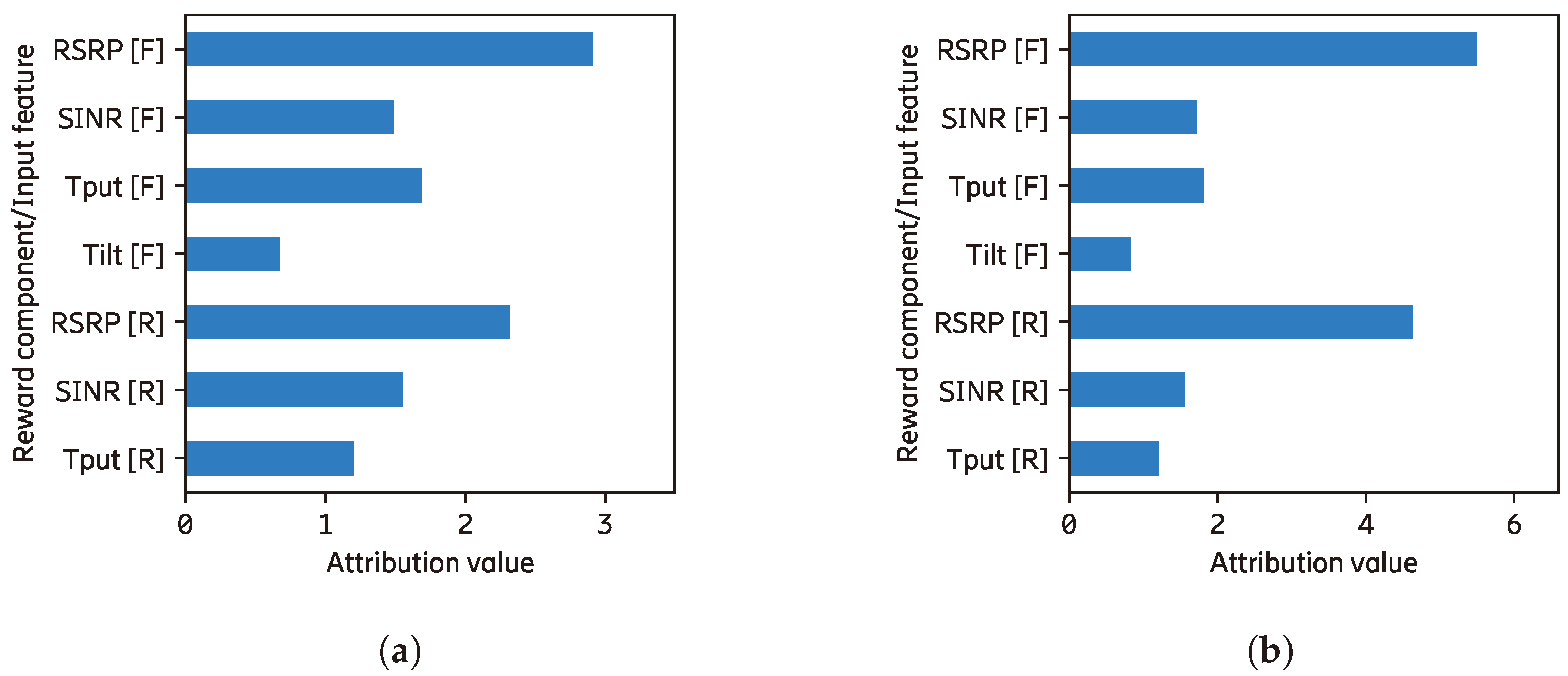
The base value of each pair of action and reward components is shown in
Table A6 and
Table A7, where the former is calculated at the Q-level while the latter is at the RL-level. We can see that the range at the RL-level is significantly larger than the Q-level because of the reward prioritization. The base value of the position reward component has the highest value, which is relevant to this environment where the main goal is to position the lander to the origin.
Table A6.
Base values of the Lunarlander agent without reward prioritization.
Table A6.
Base values of the Lunarlander agent without reward prioritization.
| Reward | Action |
|---|
| Component | No_fire | Fire_right | Fire_up | Fire_left |
| position | 99.954918 | 99.971298 | 99.855209 | 100.127533 |
| velocity | 24.920115 | 24.936441 | 25.133207 | 24.831766 |
| angle | −3.527749 | −3.562116 | −3.443951 | −3.553954 |
| leg1 | 23.622988 | 23.793665 | 23.522532 | 23.526903 |
| leg2 | 22.642960 | 22.748714 | 22.536240 | 22.465919 |
| main_engine | −36.977737 | −36.853558 | −37.329254 | −36.843079 |
| side_engine | −50.239410 | −51.475277 | −50.376621 | −51.710163 |
All above explanations are detailed and the focus value can be used to summarize whether the explanations fulfill the desired properties. For this environment, the relevance table is set as shown in
Table A8 which generates the focus value shown in
Table A9. The position component (
) is highly correlated with the position input features (
). Similarly, other pairs are also highly correlated where we set the relevance value as 1 such as: velocity component (
) with speed (
); angle component (
) with angular speed (
) and angle input feature; and leg components (
and
) with leg input feature (
and
, respectively), etc. On the other hand, the main engine (
) should not consider the angular speed (
) because changes in the angular speed cannot be corrected by the action of the main engine; therefore, it has zero relevance value.
Table A7.
Base values of the Lunarlander agent when reward prioritization is applied.
Table A7.
Base values of the Lunarlander agent when reward prioritization is applied.
| Reward | Action |
|---|
| Component | No_fire | Fire_right | Fire_up | Fire_left |
| position | 9995.485352 | 9997.129883 | 9985.517578 | 10012.757812 |
| velocity | 2492.011719 | 2493.641357 | 2513.325684 | 2483.169189 |
| angle | −352.775330 | −356.211731 | −344.395172 | −355.395264 |
| leg1 | 236.229767 | 237.936707 | 235.225174 | 235.268982 |
| leg2 | 226.429245 | 227.487045 | 225.362274 | 224.659210 |
| main_engine | −11.093332 | −11.056075 | −11.198791 | −11.052940 |
| side_engine | −1.507182 | −1.544255 | −1.511300 | −1.551306 |
Table A8.
Relevance table for the Lunarlander agent.
Table A8.
Relevance table for the Lunarlander agent.
| Reward | Input Feature |
|---|
| Comp. | Pos_x | Pos_y | Vel_x | Vel_y | | | c_leg1 | c_leg2 |
| position | 1.0 | 1.0 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 |
| velocity | 0.5 | 0.5 | 1.0 | 1.0 | 0.5 | 1.0 | 0.5 | 0.5 |
| angle() | 0.5 | 0.5 | 0.5 | 0.5 | 1.0 | 1.0 | 0.5 | 0.5 |
| leg1 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 1.0 | 0.5 |
| leg2 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 1.0 |
| main_eng | 0.5 | 1.0 | 0.5 | 1.0 | 0.5 | 0.0 | 0.5 | 0.5 |
| side_eng | 1.0 | 0.5 | 1.0 | 0.5 | 1.0 | 1.0 | 1.0 | 1.0 |
Table A9.
Focus value of the Lunarlander agent.
Table A9.
Focus value of the Lunarlander agent.
| Reward Component | Focus Value |
|---|
| position | 0.847708 |
| velocity | 0.690510 |
| angle | 0.698298 |
| leg1 | 0.826667 |
| leg2 | 0.787410 |
| main_engine | 0.804658 |
| side_engine | 0.784765 |
| weighted_mean | 0.749406 |
| unweighted_mean | 0.777145 |
We can see that the position reward component has the highest focus value, and contributes significantly higher than the others. The velocity () reward component has a low value because has a higher contribution than , or the angular velocity (), which ideally is the focus of this component. Similarly, the angle reward component has a low value because and are the second and third most contributing feature instead of the angular velocity (). Overall, the weighted mean has a lower value than the unweighted mean focus value, which means that high priority components (i.e., velocity and angle) do not focus on the desired input features.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
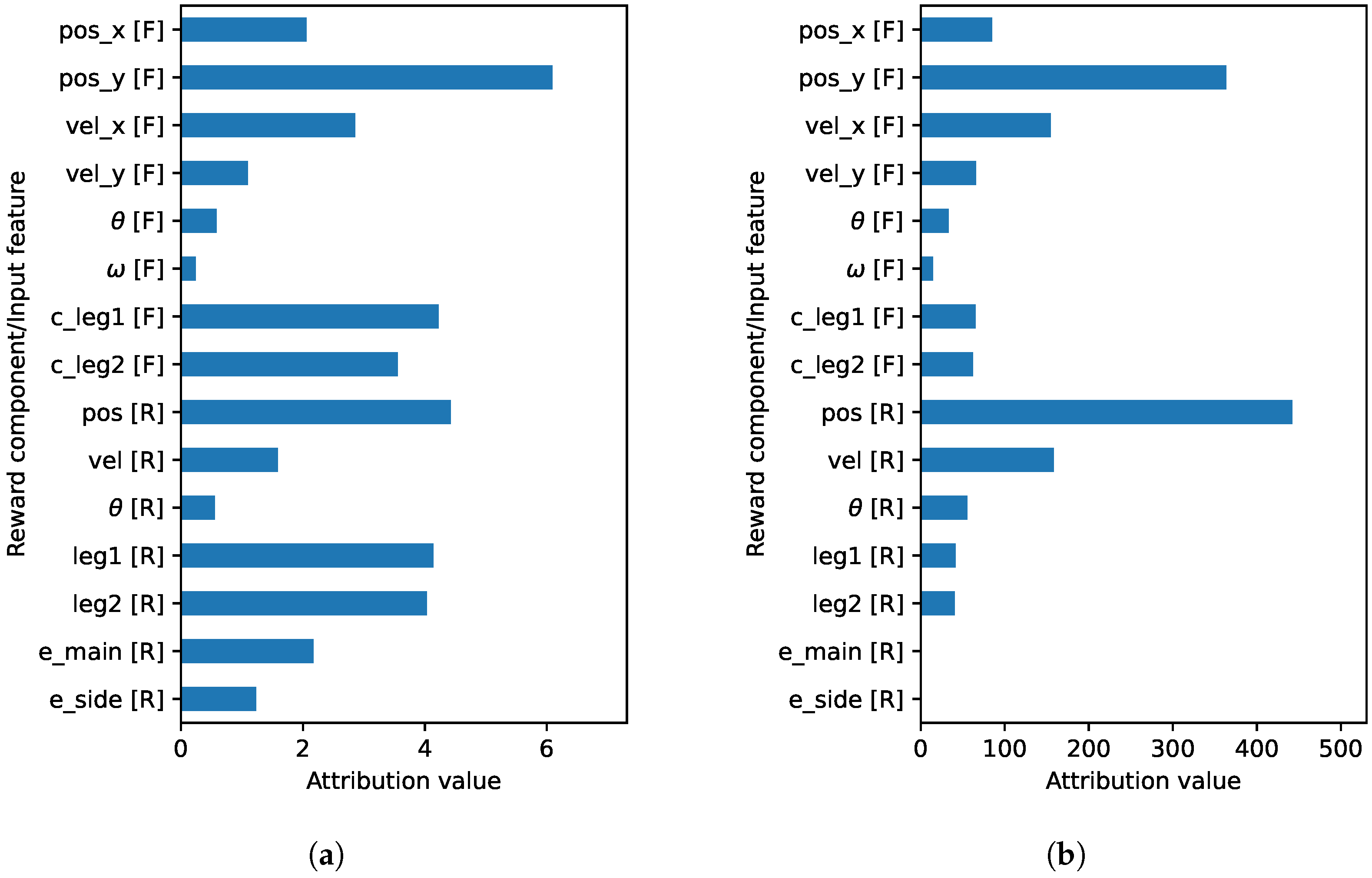{kind=link}
{kind=link}
{kind=link}




















