1. Introduction
The steel industry is one of the pillar industries supporting the rapid development of economy and has achieved rapid growth [
1]. However, with the advent of the era of intelligence and data, steel manufacturing is facing many difficulties in on-site data management, storage, and application [
2,
3,
4]. Hot strip rolling is an important scene in the field of steel manufacturing. There are a lot of work logs and technical documents in actual production. These field texts contain various professional information such as rolling process, equipment accuracy, and product quality. How to accurately and effectively extract domain information with application value from unstructured data has gradually become a hot spot in the industry [
5,
6]. In 2012, Google proposed the concept of a knowledge graph, which has rapidly fermented in recent years, becoming a hot topic of discussion in many fields, and also pointed out a way for the transformation and the steel industry upgrading.
The construction of a knowledge graph mainly includes knowledge extraction, knowledge update, knowledge processing, and knowledge application. In addition, knowledge extraction is also called information extraction, which aims to make targeted selection of unstructured data, determine the domain entities worthy of attention, and complete the type annotation and relationship binding. Then, Named Entity Recognition (NER) is mainly used to locate important text entities and predict the corresponding labelling entity type. The early NER algorithm is mainly based on rules or statistical machine learning [
7]. The rule-based entity recognition method mainly relies on the artificially constructed rulebase, the recognition accuracy is high, but the execution efficiency is too low and the portability is poor. Later, statistical machine learning gradually replaced rule-based methods. For example, Conditional Random Field (CRF) improved the accuracy of model prediction by training massive data, and got rid of the problem of manual dependence to the greatest extent. However, the defect of the low generalization ability of the model is still not fundamentally solved.
In recent years, with the development of computer technology, NER based on deep learning has gradually become the research hotspot. Compared with statistical machine learning methods, the recognition algorithm based on deep learning has high execution efficiency, high speed, and strong model generalization ability [
8]. Taking advantage of parallel computing, Convolutional Neural Networks (CNN) can quickly complete the task of entity recognition. However, due to the limitation of the model structure, it cannot rely on long-distance text information to improve the labeling effect. The sequential structure of Recurrent Neural Networks (RNN) is similar to text representation, which can effectively capture textual context information, but there is the problem of gradient explosion or gradient disappearance. Then, Bi-directional Long and Short Term Memory Networks (BiLSTM) and Bi-directional Gated Recurrent Unit (BiGRU) are used to improve and optimize RNN. They effectively avoid gradient disappearance and gradient explosion through clever gating design, and mine text dependencies in both directions, becoming the preferred method for information extraction in the era of big data.
In addition, NER is also integrating the information advantages of unsupervised learning, combining Bidirectional Encoder Representation from Transformers [
9] (BERT) or A Lite BERT [
10] (ALBERT) to enhance the semantic understanding of domain texts from a new perspective. The self-attention mechanism is used to mine the associated information in the unstructured data in both directions, which greatly improves the model recognition accuracy and application feasibility.
In this study, NER is regarded as a ‘translation task’ of equal-length sequences, and the seq2seq model is improved and optimized in the way that, under the condition of retaining the original compression information of the encoder, the preliminary prediction information of the encoder is transmitted to the decoding unit, and the prediction result is randomly corrected with the support of Teacher-Forcing and passed to the next sequential unit. Finally, the BERT-ImSeq2seq-CRF model is constructed by combining BERT and CRF to deeply mine the related information in the paper, and it is applied to the process information entity extraction task of hot strip rolling, and obtained a significance domain entity extraction effect. The improved model can provide certain reference value and technical support for the application of complex hot strip professional information management.
2. NER Application Status
Although the research progress of NER algorithm is in full swing, its application in the field is not satisfactory. Due to the background characteristics and historical accumulation of some fields, NER application is mainly concentrated in industries with uniform statistical information, such as agriculture [
11,
12], medicine [
13,
14,
15], news [
16], electricity [
17,
18], and so on.
In 2012, Google officially proposed the knowledge graph to improve user search experience and query efficiency [
8]. Subsequently, all walks of life also realized the necessity of knowledge management and application in time, and joined the ranks of domain graph construction. Ref. [
12] proposed an ME+R+BIOES entity labeling method based on the specific field information of crop diseases and insect pests, which can label and classify domain entities and entity relationships at the same time, improve the labeling efficiency, and solve the problem of one-to-many relationship extraction. Then, the cross-validation method was used to train and test 1619 pieces of crop pest data, and the experimental F1-Score was 91.34%. In view of the text form and storage characteristics of power information, Ref. [
19] added the attention mechanism based on the ALBERT-BiGRU-CRF model. The model can fully capture the dependencies and contexts between sentences, and focus on key information. The experimental training effect is 7.3% higher than the original model on average. In view of the low efficiency of some entity recognition models and the inconsistent record characteristics of coal mine case representations, Ref. [
20] presented an entity recognition model applied to the field of coal mine accidents. The ALBERT pre-training model is used to obtain the word vector representation of the text sequence, and four Iterated Dilated Convolutional Neural Networks (IDCNN) with the same structure are used to calculate and label the obtained word vector. Finally, the conditional random field model is used to constrain the predicted labels, which improves the model’s ability to capture long text information, and achieves good results in the entity labeling task of coal mine accident cases.
At present, the research progress of NER with information extraction in some fields is obvious to all, but there is still a gap in the field of steel manufacturing. Aiming at the application requirements and research gaps in steel manufacturing, this paper proposes the NER algorithm for hot strip rolling. The model is preliminarily verified by third-party data sets (Weibo dataset and news dataset). The feasible model is applied to the entity recognition task of hot strip rolling, and provides a cutting-edge technical solution for professional text information processing.
3. Model Design
In this study, the process-accurate NER of strip equipment is regarded as a kind of “translation task” of isometric sequences. Considering the task requirements of NER, the original seq2seq model is improved and optimized as the original compression information of the encoder is retained, the preliminary prediction information of the encoder is transmitted to the decoding unit, and the prediction result is randomly corrected with the help of Teacher-Forcing and passed to the next. It is achieved that predictive efficiency of the model is improved. Finally, the BERT-ImSeq2seq-CRF model was constructed by combining BERT and CRF to deeply mine the related information in the text, and it was applied to the process information entity extraction task of strip hot rolling, and obtained a good domain entity extraction effect. The existing model also provides a certain reference value and technical support for the application of complex hot rolling professional information management.
3.1. Seq2seq Model Improved
The seq2seq model belongs to a common Encoder–Decoder structure. The model successfully applies deep learning networks to tasks such as translation or question answering, and achieves impressive performance in conversational robots, machine translation, and speech recognition applications [
21,
22].
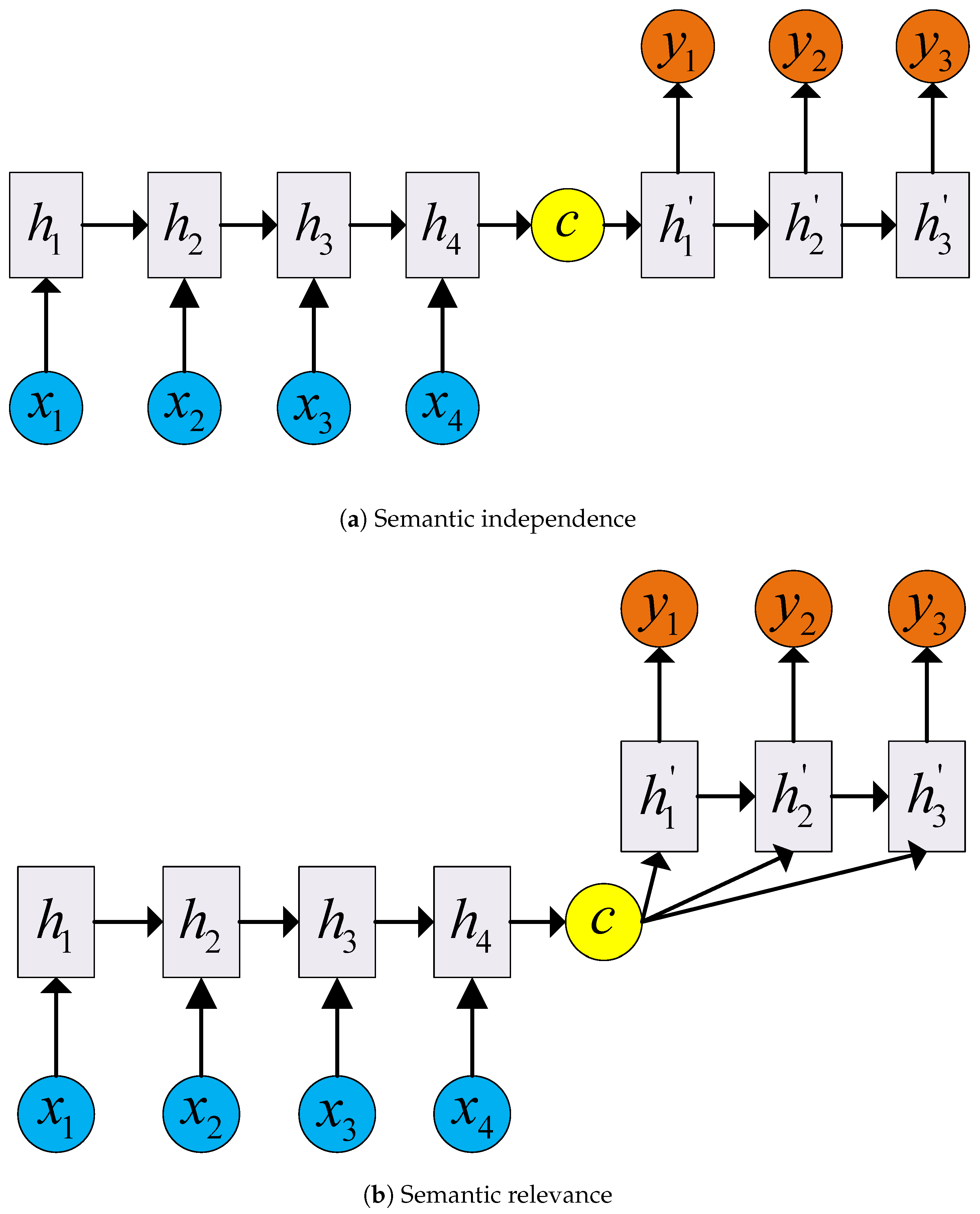
The main idea of the seq2seq model is to use two neural networks as an encoder and a decoder, respectively. The encoder is responsible for converting the input sequence into a vector of a specified length. The vector can be regarded as the semantic information of the input sequence. This process is called encoding. Generally, the hidden state of the last unit is taken as the semantic vector
C. The decoder is responsible for generating an output sequence of a specified length based on the semantic vector
C. This process is called decoding. The decoder input includes two forms: in
Figure 1a, the semantic vector
C obtained by the encoder is added to the decoder network as the initial state, the semantic vector
C only participates in the operation as the initial state, and then the implicit state of the previous unit continues to propagate downward as the implicit state input of the unit.
Figure 1b shows that the semantic vector
C is involved in the operation of the decoder at all times, and the implicit state of the previous unit is still the implicit state input of the current unit.
Inspired by the seq2seq model, NER can be regarded as an equal length sequence to sequence ‘translation’ task. However, the information contained in semantic vector
C is too simple and general. It is far from enough to rely on semantic vector
C to accurately predict sequence labels. In order to give full play to the information obtained by the encoder and the characteristics of the decoder itself, the paper improves the original seq2seq model, recorded as Imseq2seq, and the model structure is shown in
Figure 2.
The length of the input sequence in
Figure 2 is 4, and the sequence vector is quantized and sent to the encoding layer, and the semantic vector and preliminary prediction results are obtained through the encoder. To solve the problem in which the semantic vector cannot support entity label prediction, this model adds the encoder prediction results to the decoder, and combines a Teacher-Forcing mechanism to randomly correct the labeling results of the previous unit, and then sends them to the current decoding unit. Compared with the original model, the improved seq2seq makes full use of the output information of the encoder, and adds a Teacher-Forcing mechanism to the decoder, which helps to improve the model speed and labeling accuracy. In the actual model design, in order to ensure the consistency of the decoder data input, a ‘START’ vector is inserted at the beginning of each sentence. BiLSTM is used as encoder to perform preliminary prediction and vector compression on input information. The decoder uses a unidirectional LSTM to process and label the input information orderly.
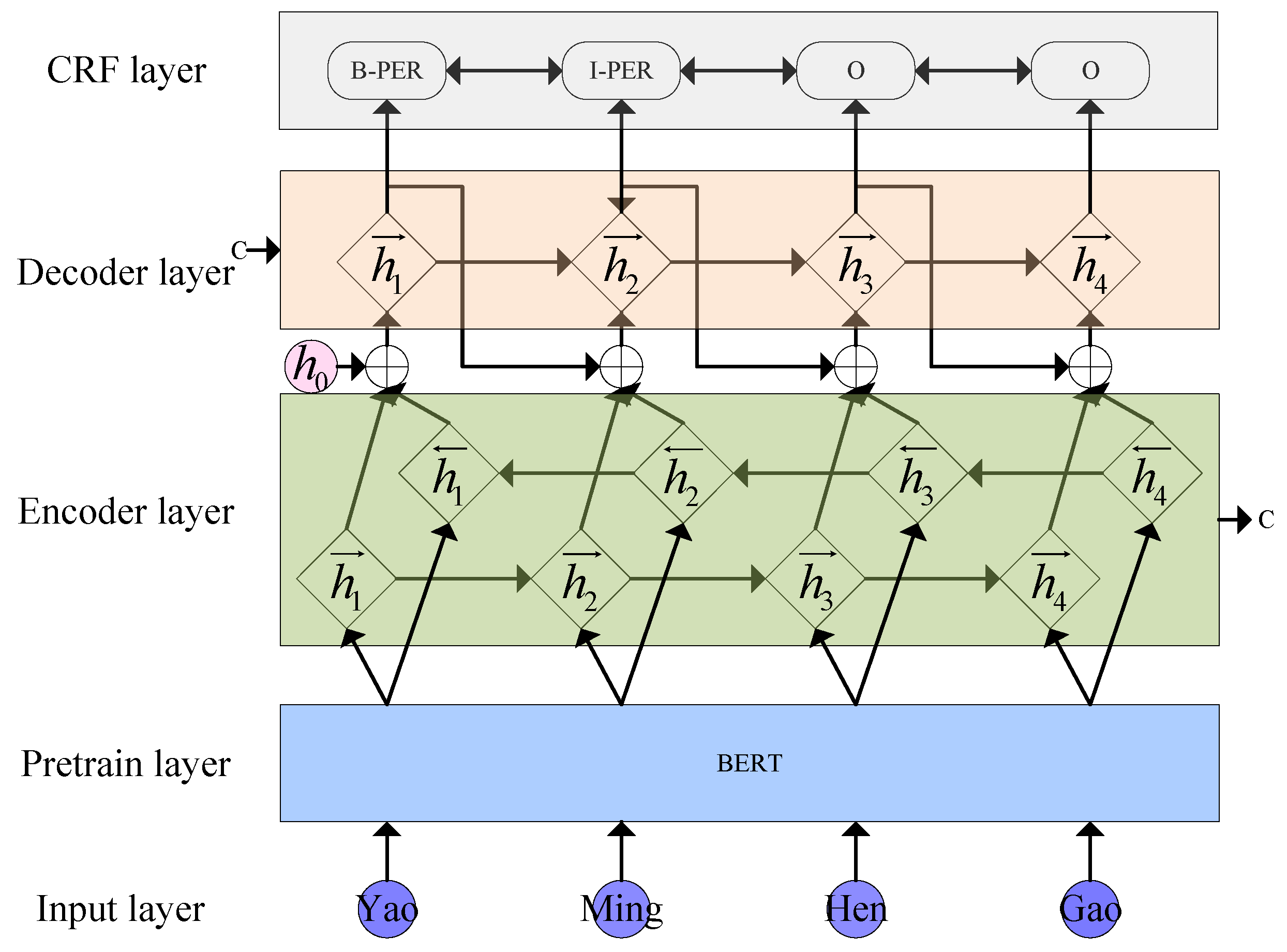
3.2. Model Design
The structure of the overall NER model is shown in
Figure 3, which mainly includes the input layer, preprocessing layer, encoding layer, decoding layer, and CRF layer.
When the text is input into the model in batches, the input information is pre-trained with BERT, the context dependencies in the text are fully mined through the Transformer module. The representation vector of Chinese characters is obtained and input into the improved seq2seq model for sequence labeling. In the improved seq2seq model coding layer, BiLSTM is used to compress the input data vector and preliminarily annotate the input data to obtain the semantic vector C and the preliminary labeling result Y of the text, and then the semantic vector C and the labeling result Y are sent to the decoder together. The decoder uses unidirectional LSTM to label the input sequence in sequence, and considers the output result of the previous unit. The Teacher-Forcing mechanism is used to randomly correct the output result to avoid the continuous accumulation of errors and affect the labeling effect. Finally, the prediction results of the decoding layer are sent to the CRF layer. Based on the label constraints, the validity of the labeling results is checked to obtain the best recognition effect. Next, the key links in this model will be introduced gradually.
3.3. Preprocessing Layer
The preprocessing layer uses the BERT pre-trained language model to obtain the text representation vector. Different from the traditional unidirectional language model, BERT innovatively uses a Masked Language Model (MLM) to build a bilateral deep network, which can fully capture textual sentence-level features and perform extremely well in many Natural Language Processing (NLP) tasks [
23,
24].
Bidirectional Transformer is a key module in BERT, mainly including encoder and decoder, both of which have similar structures.
Figure 4 shows the encoder module on the left side of Transformer, in which the multi-head self-attention mechanism plays a crucial role.
Multi-Head Attention is mainly used to mine the dependencies between each word, and trim the weight coefficient matrix to obtain the word representation based on the degree of association between the words:
where
Q indicates Query vector generated from word vector,
K represents Key vector generated from word vector,
V denotes Value vector generated from word vector,
is the input word vector dimension. At the same time, in order to capture the dependencies of multiple dimensions, the Transformer adopts the multi-head attention mechanism, and obtains many pairs of Query, Key and Value through
h linear transformation, performs attention calculation on them respectively, and finally splices the results of
h times to obtain multi-head. The attention result is calculated as follows:
Due to the characteristics of the algorithm, the model is not sensitive to the text order information. In order to distinguish the expression semantics of the same word in different order, the text position vector and segment vector are considered in the BERT model. The model input includes word vector, position vector, and segment vector. Through the multi-layer transformer structure, the text context information is fully mined to obtain the text representation vector, which is applied to different downstream tasks through parameter fine-tuning.
3.4. Encoder–Decoder Layer
The encoder and decoder use LSTM [
25] network, which is an improved model of the RNN network. As shown in
Figure 5, a forget gate
, a memory gate
, and an output gate
are added to the RNN unit, which can effectively capture the context information of the sentence. It is a commonly used network to solve the problem of information dependence in longer sequences.
The forget gate is responsible for deciding whether to discard the information in the unit. The gate reads the output of the previous unit
and the input of this unit
. The output is a value between
, ‘1’ means all are reserved, ‘0’ means all are discarded, and transmitted to the cell state.
The memory gate is responsible for determining whether to store new information in the cell unit. The input is still the output of the previous unit
and the input of this unit
. The Sigmoid activation function generates a value between
to determine the degree of information retention. At the same time, a new tanh layer is created to generate a temporary cell state
to update and replace the original cell state
:
The output gate is responsible for determining the final information and outputting it. Based on the output of the previous unit
, the input
and the cell state of this unit
obtain the final result
with the help of sigmoid and tanh activation functions:
3.5. CRF Layer
CRF is a Markov random field dedicated to word segmentation or part-of-speech tagging tasks. The model is characterized by the global normalization of sequence probability and the free setting of feature functions, which directly avoids the conditional independence assumption of hidden Markov models and solves the problem of label bias in directed graph models [
26,
27]. The CRF model requires a random output variable
Y under the random variable
X, and the conditional probability model satisfies the Markov property, that is:
where
represents all nodes that have edge connections with node
v in the undirected graph,
represents all nodes except node
v, and
represent the random variables corresponding to nodes
.
Because the input and output data are linear sequences in NER task, the learning model is selected as the linear chain conditional random field. Given an input sequence
of length
T, the corresponding labeling sequence is
, and the conditional probability distribution of
Y satisfies Equation (
11). For the linear chain conditional random field, the calculation formula of the conditional profile distribution
is Equation (12):
where
,
indicates the
eigenvalue that the current input sequence position is
t and the input is
X, and the current position dimension and the previous position dimension are
and
.
indicates the corresponding feature weight, and
indicates the normalization factor:
The conditional random field model calculates the conditional probability and feature expectation of different positions through the forward and backward algorithm, and uses the Viterbi algorithm to perform dynamic programming decoding. This study uses the CRF model to learn the dependency between text labels, add constraints to predict labels, avoid illegal labels, and help to obtain better labeling results.
4. Experiment Analysis
4.1. Experimental Dataset
The experimental dataset of this research mainly comes from the project plan, work log and other text materials of the process accuracy of hot strip rolling, which contains a large amount of professional information related to the process accuracy of the equipment. The processed dataset is in the form of Chinese expression, and each Chinese character is used as the smallest unit of text output and entity labeling. At the same time, each complete content ends with a period, so as to facilitate the unified processing of the model. In addition, the source of Weibo dataset and News dataset for model validation is
https://github.com/hspuppy/hugbert/tree/master/ner_dataset (accessed on 9 April 2022). The processed dataset adopts the same expression form as the process accuracy dataset of hot strip rolling.
The text of hot strip rolling includes 1513 process descriptions, which are marked in the form of BIOS. The labeled data are randomly scrambled with each sentence as the smallest unit, and divided into a test set and a training set according to 3:7. The entity types include Position, Index, Parameter, Area, Object, Defect Shape, Evaluation Aspect, and Defect. The marking form is shown in
Table 1.
4.2. Evaluation Metrics and Experimental Configuration
In order to objectively and accurately reflect the performance of the model and avoid the impact of the data’s own characteristics on the model performance, this study uses Precision (%), Recall (%), and F1-Score (%) in the field of information extraction as Model performance evaluation index [
12], and the calculation method of each index is as Equations (
14)–(16):
where
TP represents the positive sample with correct labeling,
FP represents the positive sample with incorrect labeling,
FN represents the negative sample with incorrect labeling, and F1-Score represents the arithmetic average evaluation index.
The experimental environment and parameter configuration of this study are shown in
Table 2.
4.3. Analysis of Experimental Results
In order to verify the considerable feasibility of the model, the paper firstly uses a third-party domain data set (Weibo dataset and news dataset) to conduct preliminary experiments on the model. The data set is divided into training set and test set according to the ratio of 7:3, and several related models are selected as controls. The improved seq2seq model is recorded as Imseq2seq. The experimental results are shown in
Table 3. The original seq2seq model only sends the semantic vector C to the decoder, which covers relatively little text information, and it is difficult to accurately predict labels. The experimental effect is even far worse than the CRF model, and the F1-Score is only about 15%. The improved seq2seq model makes full use of the output information and semantic vector of the encoder. Combined with the CRF model, the comprehensive experimental effect is more impressive than BiLSTM-CRF. After adding the BERT preprocessing model, the F1-Score increases to about 89.5%.
Because the entity names contained in the third-party dataset are only person name (PER), local name (LOC) and organization (ORG), the entity types are relatively rare and the sentence structure is simple. The recognition difficulty is not high, and it is difficult to reflect the advantages of the model. Next, the model is applied to the task of entity recognition in hot strip rolling. The text expression of hot strip rolling is specialized, including entity types and entity names in many fields. At the same time, there are some entities with long names or nested entities, such as ‘spindle main motor torque’, ‘steel shifting impact fluctuation’, ‘outlet anti arching roll set pressure’, and ‘measured flow deviation of rack cooling water’, which undoubtedly increases the difficulty of entity identification.
Similarly, in order to verify the feasibility and advantages of the model, relevant models are selected as the control experiment. The model identification results for the hot strip rolling data set are shown in
Table 4. Combining WeiBo dataset, news dataset, and the hot strip rolling process accuracy dataset, it is not difficult to draw the following conclusions: CRF is a classic machine learning model, which realizes the information labelling by adding constraints. The angle of processing information is relatively single, and the F1-Score is only 77.30%; the seq2seq model only transmits the paragraph compression information obtained by the encoder to the decoding layer, and the amount of information is greatly reduced, which is far from satisfying the labeling task of a single Chinese character, and the recognition effect is extremely poor; in addition, the encoder part of the Imseq2seq model adopts BiLSTM. The decoding layer adopts unidirectional LSTM and combines the Teacher-Forcing mechanism to randomly correct the prediction results, and performs secondary prediction based on various information. Compared with the BiLSTM model, the model in this paper considers information from multiple angles, the overall recognition effect of the model is also better than other models of the same level, and the F1-Score reaches 94.47%.
The specific recognition results of this model are shown in
Table 5. The mixed expression of Chinese characters, letters, and numbers in some sentences does not affect the prediction performance of the model, and almost all entity tags are accurately predicted as a whole. At the same time, the prediction results of the specific entity types of the hot strip rolling text by this model are shown in
Figure 6. There is a phenomenon that the prediction results of individual entity types are lower than the average value. Through the verification text, it is found that the number of entity types of ‘defect type DEF’ is relatively small. Different statements express the entity type differently, which affects the prediction level of the model to a certain extent.
Inspired by the seq2seq model, this paper constructs the NER model applied to the hot strip rolling field. Except for some entity types, the F1-Score is more than 85%, and some experimental indexes are close to 100%. It improves the efficiency and quality of entity recognition and labeling, and provides solutions and technical support for information extraction and atlas construction of hot strip rolling.
5. Conclusions
Aiming at the blank research on information extraction of hot strip rolling and the needs of industry development, this paper proposes a text NER algorithm for hot strip rolling based on BERT-Imseq2seq-CRF:
(1) Based on the seq2seq model concept, this paper regards NER as a ‘translation’ task of equal-length sequences. In addition, the existing model is improved and optimized. Make full use of the encoder to achieve text information compression and preliminary prediction, and integrate the Teacher-Forcing mechanism into the decoder unit to improve the model recognition efficiency. Compared with the existing models, Imseq2seq outperforms the task of NER. Combined with the CRF model, the F1-Score increased from 13.72% to 87.38%; adding the preprocessing model BERT, the F1-Score increased to 91.47%, and the recognition performance was the best among all models.
(2) In this study, the text form and process development requirements of technological accuracy of hot strip rolling are considered. A professional domain NER model is provided for massive professional domain information management, which can efficiently and accurately locate and label the domain information in the text. To a certain extent, it fills the application gap of knowledge extraction in the field of hot strip rolling, and improves the information management and application level of strip manufacturing industry.
(3) Although this paper has made some progress in text recognition of hot strip rolling, there is still room for progress in recognition performance and scale. In the future, we will continue to experiment on model application, improve the generalization ability of model application, and pay attention to knowledge fusion, knowledge update, and knowledge reasoning, so as to speed up the construction process of steel manufacturing knowledge graph.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}