1. Introduction
The availability of a vast amount of information stored in audio and video repositories worldwide has increased the interest in searching on speech (SoS) [
1]. SoS focuses on retrieving speech content from audio repositories that match user queries, i.e., searching for audio or speech by using any term of interest by text or segment of the audio or voice. Audio data includes everything that can be heard, such as speech, music, animal sounds, bell sounds, laughter, bird chirps, news footage archives, and audio lectures. Pitch is a generally slow-changing periodic signal in spoken speech that corresponds to the frequency of vibration of the vocal cords. Male pitch contribution is often between 50 Hz and 250 Hz, whereas female pitch contribution is typically between 120 Hz and 500 Hz [
2]. Audio files can be generated from different sources such as the internet and social media by individuals and organizations. Moreover, recent technological developments in the storage space of machines and their affordable prices make producing and storing audio files less challenging. Now, audio files can be recorded quickly and shared through many channels or platforms to reach the public immediately. These audio files are played using audio player software and social media such as YouTube. However, there is no way to search for a specific word in a speech on these audio players.
Speech segmentation is the process of decomposing a long speech signal into a shorter length. Speech segmentation can be classified as manual and automatic. Manual segmentation is a traditional approach in which trained phoneticians segment speech manually. However, this approach is uneven and time-consuming because it relies on hearing and visual interpretation of the necessary boundaries [
2]. On the other hand, automatic segmentation segments speech automatically into sentence-like or phrase-like parts. This segmentation is convenient for the design of automatic speech recognition systems systems.
Searching on the speech of an audio file can be done by giving a query term. A query is usually a keyword or a short phrase that is given to the system for retrieving an audio file containing that query. Based on the query type, the searching techniques can be broadly classified into three categories: keyword spotting, spoken term detection (STD), and query-by-example spoken term detection (QbE STD) [
3]. Keyword spotting (word spotting) enables to locate a text query within a speech document or a speech stream [
4]. In literature, the term keyword spotting has been used as STD. However, according to Larson et al. [
4], in keyword spotting, the user query is known in indexing time, whereas in text-based STD the query term is specified at the search time. As a result, STD is more difficult to use since it has no prior knowledge of the queries that are being searched for [
5]. Text-based STD is the process of locating a particular search term from a collection of segmented speech [
6]. With the increased interest in SoS, STD is a type of SoS that helps to retrieve speech data by using text as a query word that represents a particular speech utterance [
7]. The general structure and components of STD systems contain two steps to the STD procedure. The first stage, indexing, creates a database with an intermediate representation of the speech segments stored in a database. Using this intermediate database, the second stage is designed for locating putative occurrences of the query word. The search should be carried out quickly and precisely [
5]. The STD has advantages including the possibility of retrieving any speech file that contains any term from its textual representation, allowing for an efficient search of any term in a large index. This technology can be accessed using any device with text input capabilities [
3,
7]. The state-of-the-art STD systems usually work based on a large vocabulary continuous speech recognition (LVCSR) engine and search for keywords in the results returned by the engine. The search for out-of-vocabulary (OOV) words remains challenging since the LVCSR engine always misrecognizes the OOV words [
8]. The OOV refers to words that are not in the lexicon and is the most common source of error in ASR [
9,
10]. Different approaches are available to minimize the OOV effect on the ASR. One way of achieving high lexical coverage is by building a language model (LM) on the morpheme level [
11]. On the other hand, QbE STD is a technique in which a user presents the system with the desired audio snippets containing queries. The system then searches the database for segments that closely resemble the query [
3].
ASR allows the machine to understand the user’s speech and convert it into a series of words through a computer program; thereby creating a kind of natural communication between human and machine [
12]. The ASR components include acoustic front-end, acoustic model, lexicon, LM, and decoder. The acoustic front-end converts the speech signal into appropriate features used by the recognizer. The process of converting the audio wave form into a sequence of fixed-size acoustic vectors is called feature extraction. Feature vectors are generally generated every 10 milliseconds using a 25 millisecond overlapping analysis frame. The decoder searches through all possible word sequences to find the sequence of words most likely to generate. The LM is generally an n-gram model where each
n word’s likelihood is solely dependent on its
predecessors [
13]. Moreover, smoothing is a technique essential in constructing the n-gram LM, a main part of speech recognition. It is a set of procedures for fine-tuning the maximum likelihood estimation (MLE) by counting events in the training corpus to produce more accurate probabilities. Some of the smoothing techniques, such as Laplace Smoothing, Add
Smoothing, Natural Discounting, Good-Turing Smoothing, Interpolation, and Backoff can solve the problem of data sparsity based on the raw frequency of n-grams. The details of each smoothing technique are clearly elaborated by Tachbelie [
14]. The author used interpolation as a smoothing technique and solved the problem of data sparsity through n-gram hierarchy. Furthermore, the probability estimates of all n-gram orders were combined based on the assumption that, if there is not enough data to estimate a probability in the higher-order n-gram, the lower-order n-gram can frequently give relevant information [
14].
To date, around 7000 languages are spoken in the world [
15]. Amharic is the official working language of the government of Ethiopia, an East African country with a population of over 100 million. It is one of the Ethio-Semitic languages, which belongs to the Semitic branch of the Afro-Asiatic family and has the second largest number of speakers in the world after Arabic [
16] and is the most widely spoken Semitic language in Ethiopia [
17]. The majority of the speakers of Amharic can be found in Ethiopia; however, there are some speakers in other nations, such as Israel, Eritrea, Canada, the USA, and Sweden [
9,
18]. Audio data are abundantly found in Amharic language via the various private, social, and government media platforms. The high prevalence of social media and multimedia in our interconnected global society today has created the need to access different audio files. Individuals and organizations use this audio file to satisfy their information needs. Locating a spoken word in an audio file, however, is a challenge, because users may know that the speaker spoke a word but may not know in which part of the audio file that the word was spoken. For instance, to find a spoken word
ኢትዮጵያ (Ethiopia) that was spoken in a given audio file having a length
n in time, users might listen to the whole audio file or guess for the location of spoken word
ኢትዮጵያ within that audio file. Therefore, automatically locating a particular spoken word from a given audio file is a challenge for languages that are spoken in Ethiopia: particularly Amharic, which has distinguishing characteristics or properties. The existence of glottal, palatal, and labialized consonants makes the Amharic language different from other languages. In addition, Amharic is one of the inflated languages [
19]. Consequently, it is not possible to directly use models implemented for other languages. Currently, the different tools are available to search text; however, they are not applicable for speech or audio search [
20]. Although some online web applications allow users to convert a given audio file to an English text, the resources, technology, and research on speech searching remain in their infancy [
6]. In addition, Chaudhary et al. [
21] studied keyword-based indexing of a multimedia file in the English language to allow users to search for a particular spoken speech using text and display the time frame and the utterance. However, research has not been done for searching or locating the spoken word (utterance) time frame interval from the audio file in any Ethiopian language. Therefore, the result of this research will enhance and add additional features to audio information retrievals.
The contributions of this research work include:
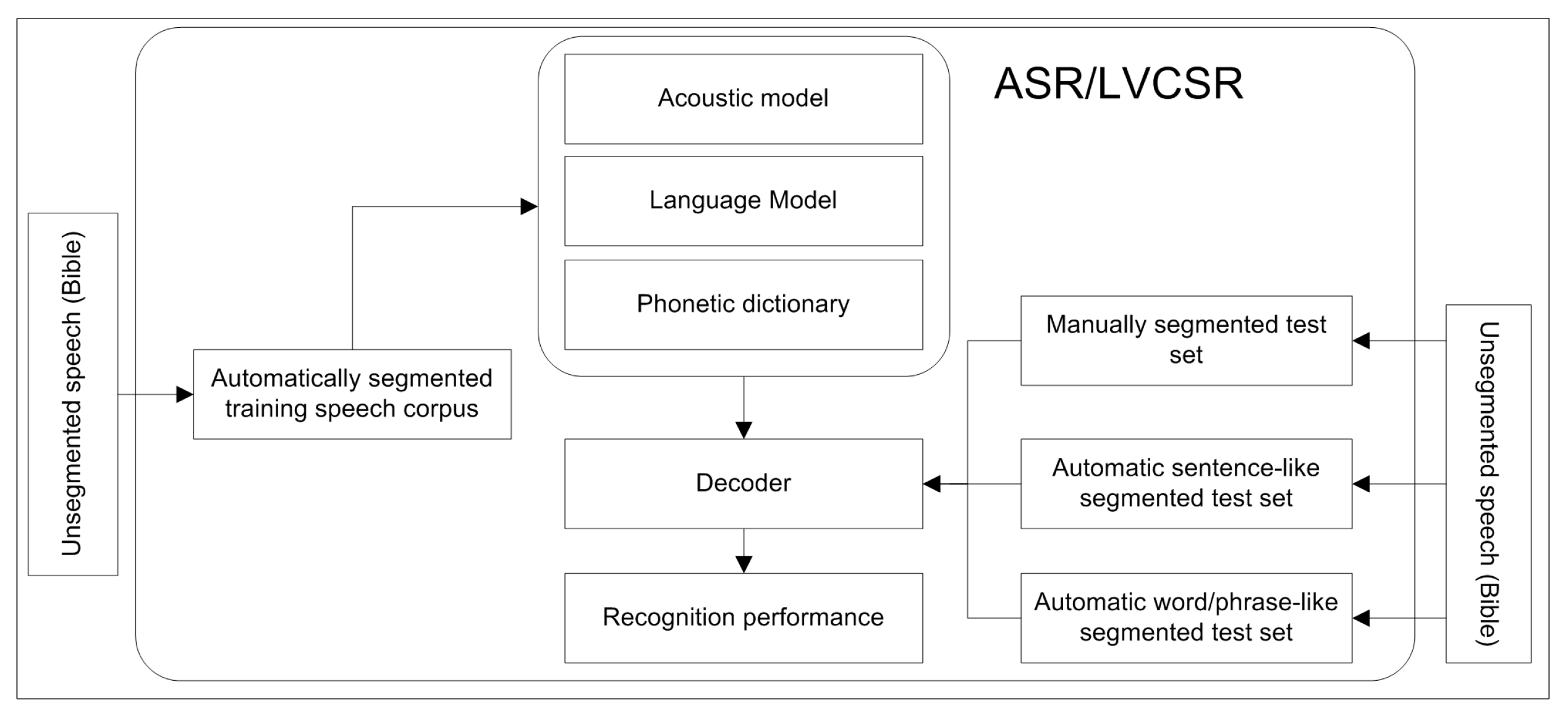
Since there is no prior research made on the effect of automatically and manual segmented speech on Amharic ASR, we compared the performance of ASR using automatically and manually segmented test speeches;
We propose Amharic speech search using text word query (ASSTWQ) based on automatically sentence-like segmentation and using a previously developed speech corpus, which is in a broadcast LVCSR domain, together with the in-domain using the Bible domain speech corpus;
We showed the effect of ASR recognition errors on searching the recognized text and the effect of ASR recognition errors on searching using different domains;
We prepared the speech corpus and conducted an extensive experimental evaluation to check the performance of the proposed work.
The rest of the paper is described as follows:
Section 2 presents a discussion of the Amharic language and
Section 3 elaborates the related works.
Section 4 describes the materials and methods. The experiments are provided in
Section 5. The results and discussion are provided in
Section 6. Finally, the conclusions are summarized in
Section 7.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







