
An Improved Differentiable Binarization Network for Natural Scene Street Sign Text Detection



Abstract
:1. Introduction
2. Related Work
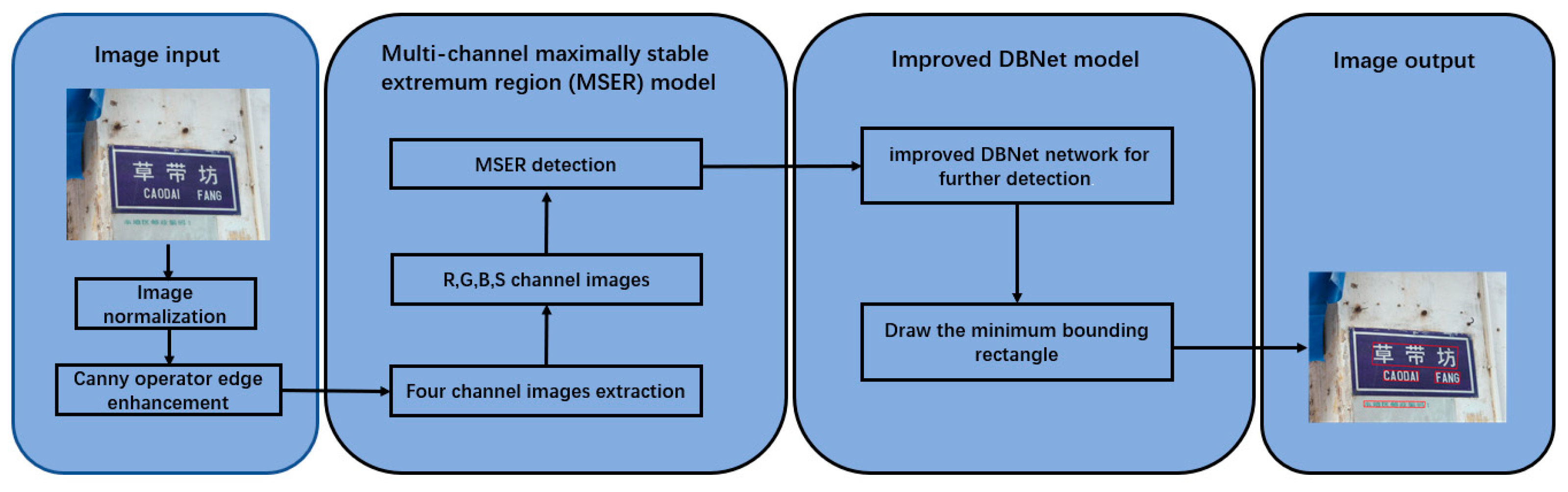
3. Proposed Method
3.1. Multi-Channel Maximally Stable Extremum Region (MSER) Model
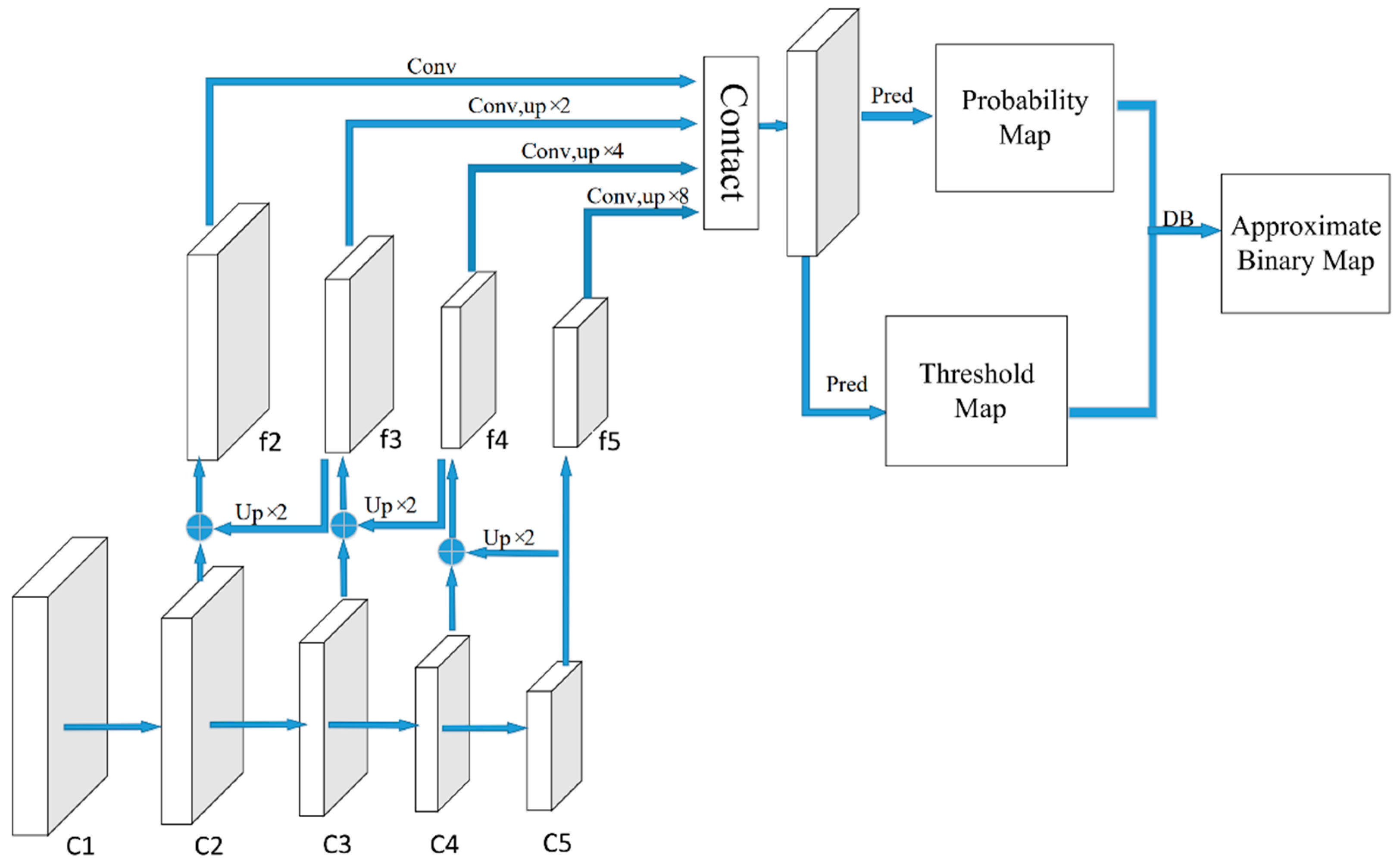
3.2. Improved DBNet for Natural Scene Text Detection
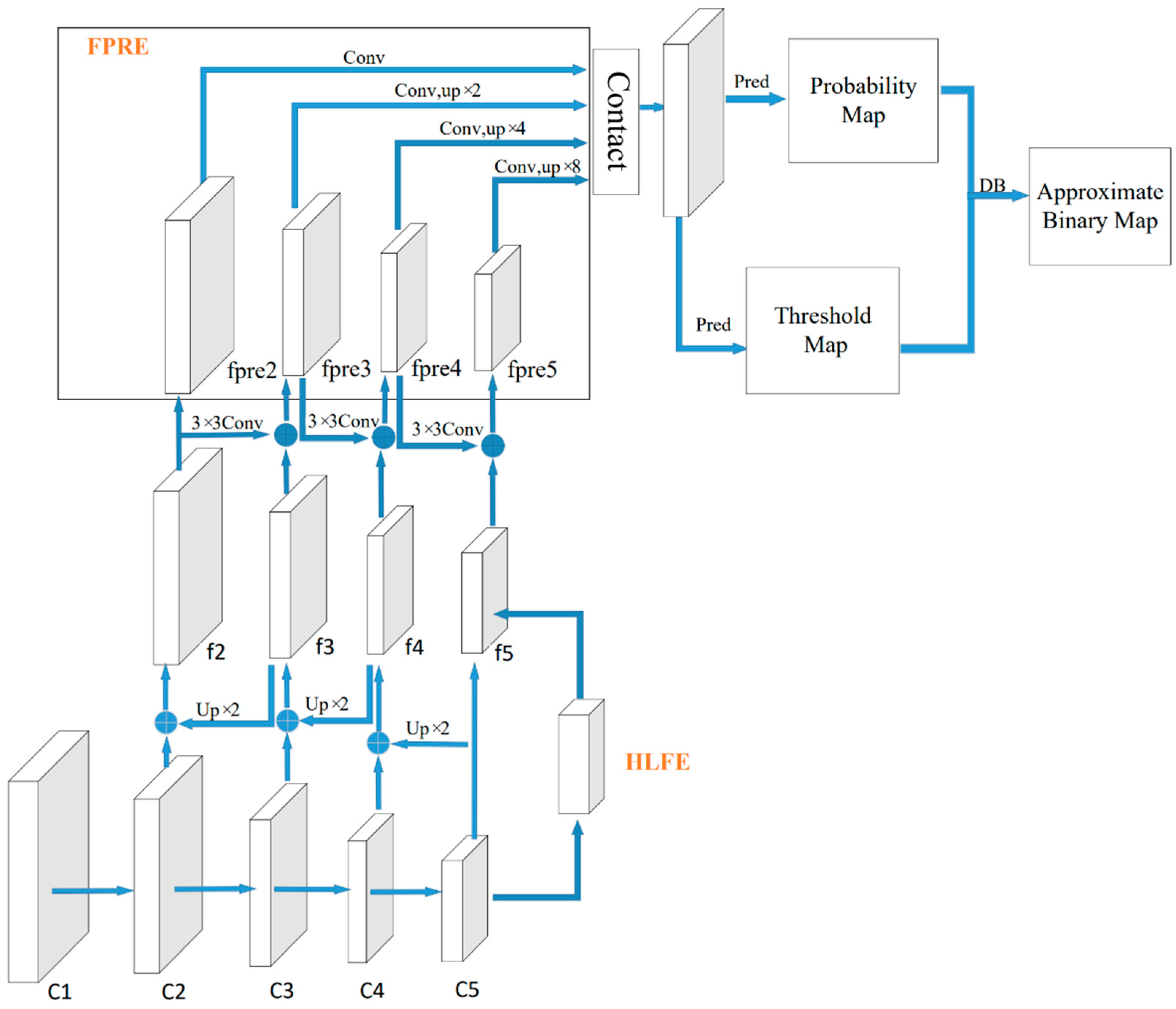
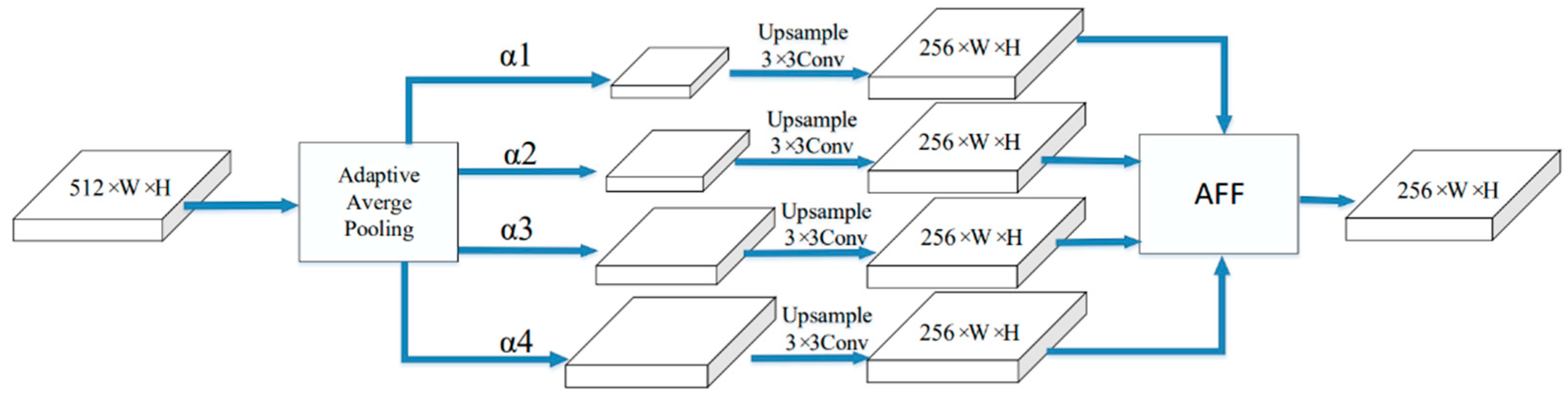
3.2.1. High-Level Feature Enhancement Model
3.2.2. Feature Pyramid Route Enhancement Module
3.3. Loss Function
4. Result and Discussion
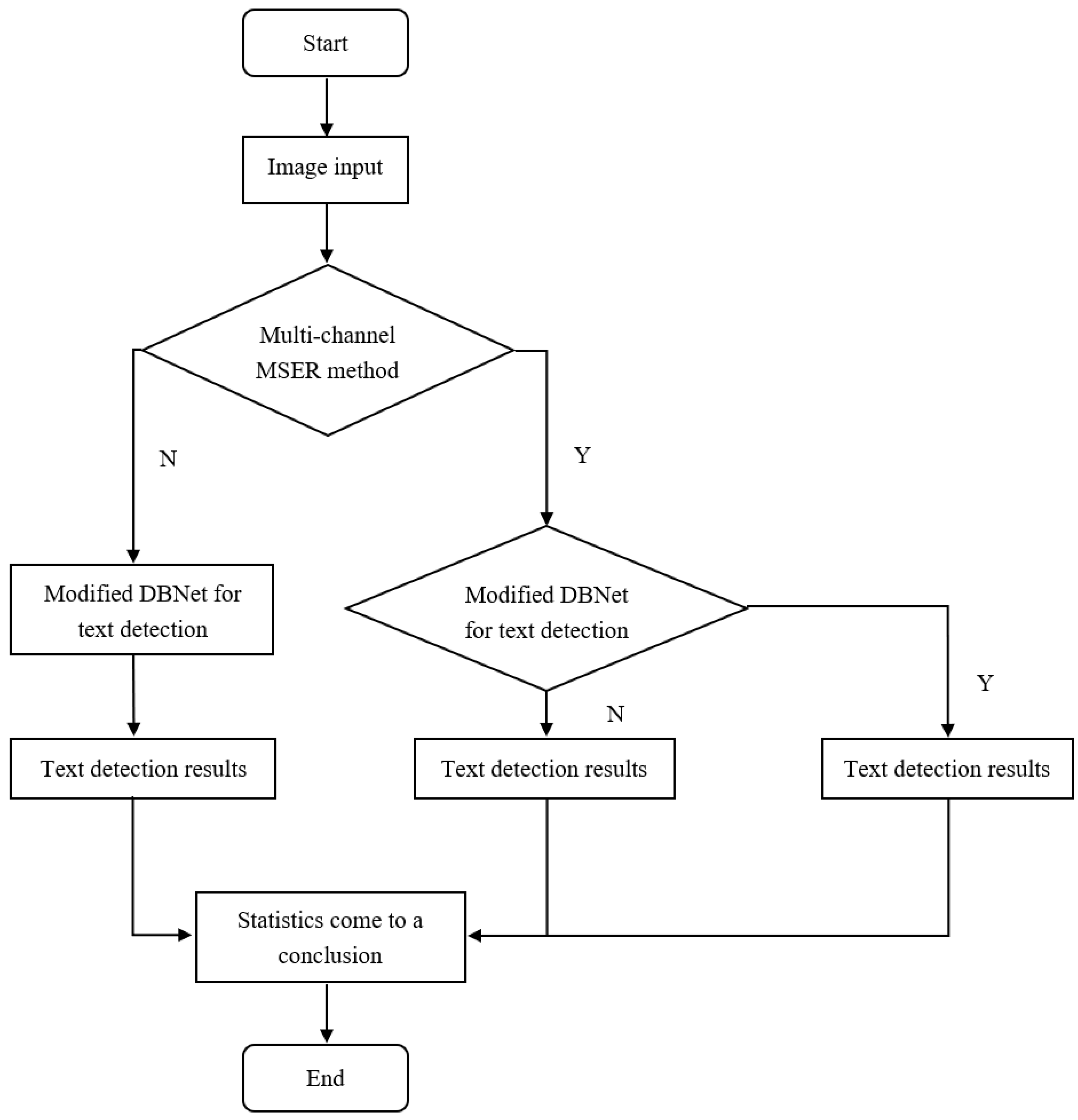
4.1. Experimental Steps
4.2. Experimental Environment
4.3. Experimental Datasets
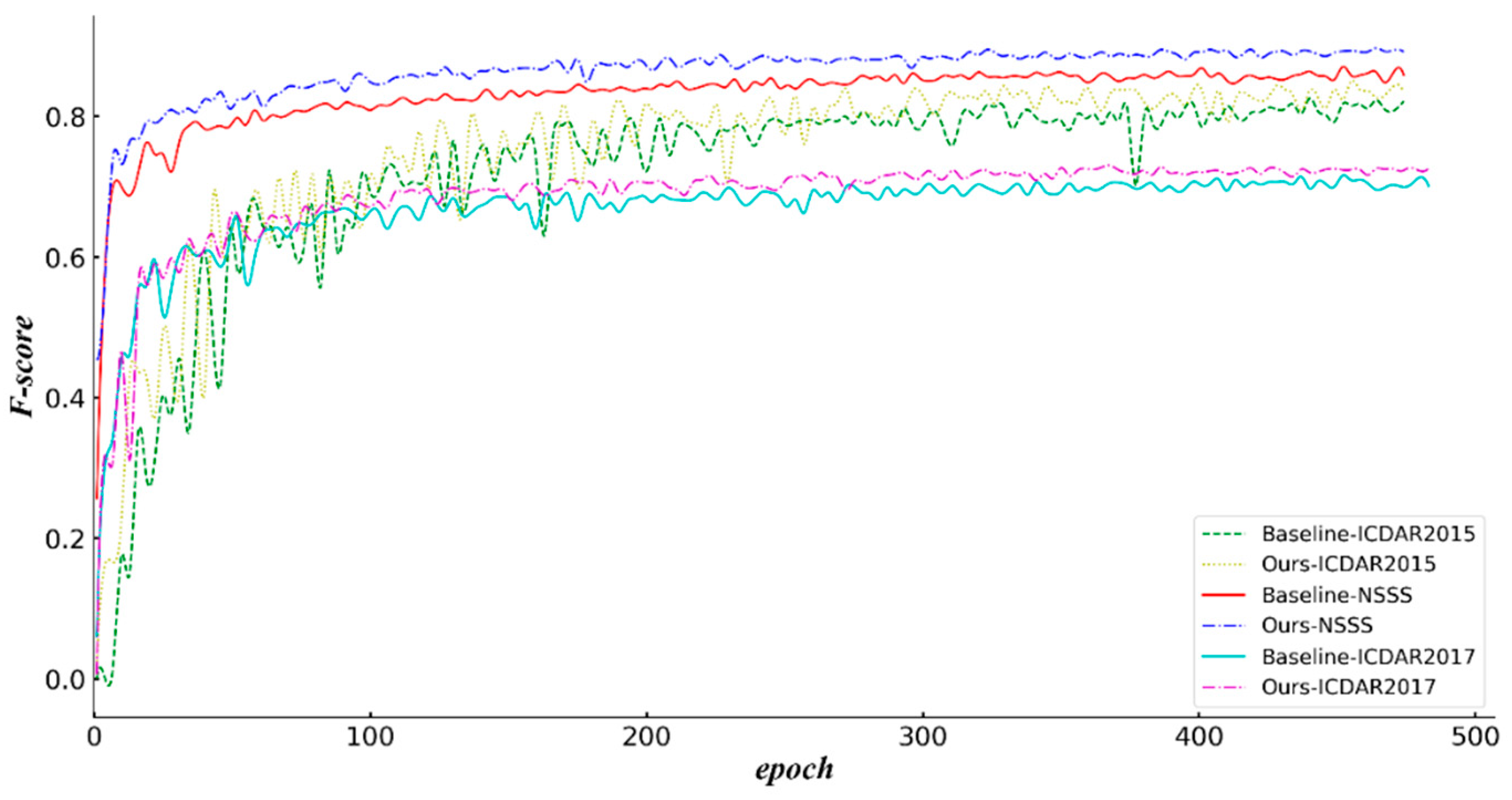
4.4. Experiment Results and Discussion
5. Conclusions and Feature Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Naosekpam, V.; Sahu, N. Text detection, recognition, and script identification in natural scene images: A Review. Int. J. Multimedia Inf. Retrieval 2022, 11, 291–314. [Google Scholar] [CrossRef]
- Yu, Y.; Jiang, T.; Li, Y.; Guan, H.; Li, D.; Chen, L.; Yu, C.; Gao, L.; Gao, S.; Li, J. SignHRNet: Street-level traffic signs recognition with an attentive semi-anchoring guided high-resolution network. ISPRS J. Photogramm. Remote Sens. 2022, 192, 142–160. [Google Scholar] [CrossRef]
- Guo, J.; Lu, J.; Qu, Y.; Li, C. Traffic-Sign Spotting in the Wild via Deep Features. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 120–125. [Google Scholar]
- Jian, M.; Zhang, W.; Yu, H.; Cui, C.; Nie, X.; Zhang, H.; Yin, Y. Saliency detection based on directional patches extraction and principal local color contrast. J. Visual Commun. Image Represent. 2018, 57, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Karatzas, D.; Shafait, F.; Uchida, S.; Iwamura, M.; Bigorda, L.G.; Mestre, S.R.; Mas, J.; Mota, D.F.; Almazan, J.A.; De Las Heras, L.P. ICDAR 2013 Robust Reading Competition. In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1484–1493. [Google Scholar]
- Hassan, E. Scene Text Detection Using Attention with Depthwise Separable Convolutions. Appl. Sci. 2022, 12, 6425. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust wide-baseline stereo from maximally stable extremal regions. Image Vision Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Liao, M.; Wan, Z.; Yao, C.; Chen, K.; Bai, X. Real-Time Scene Text Detection with Differentiable Binarization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; p. 34. [Google Scholar]
- Naiemi, F.; Ghods, V.; Khalesi, H. A novel pipeline framework for multioriented scene text image detection and recognition. Expert Syst. Appl. 2021, 170, 114549. [Google Scholar] [CrossRef]
- Liu, C.; Yang, C.; Hou, J.; Wu, L.; Zhu, X.; Xiao, L. GCCNet: Grouped channel composition network for scene text detection. Neurocomputing 2021, 454, 135–151. [Google Scholar] [CrossRef]
- Lu, M.; Mou, Y.; Chen, C.L.; Tang, Q. An Efficient Text Detection Model for Street Signs. Appl. Sci. 2021, 11, 5962. [Google Scholar] [CrossRef]
- Wan, Q.; Ji, H.; Shen, L. Self-attention based Text Knowledge Mining for Text Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5983–5992. [Google Scholar]
- Deng, D.; Liu, H.; Li, X.; Cai, D. PixelLink: Detecting Scene Text via Instance Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 6773–6780. [Google Scholar]
- Zhu, J.; Wang, G. TransText: Improving scene text detection via transformer. Digital Signal Processing 2022, 130, 103698. [Google Scholar] [CrossRef]
- Zhu, Y.; Chen, J.; Liang, L.; Kuang, Z.; Jin, L.; Zhang, W. Fourier Contour Embedding for Arbitrary-Shaped Text Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3123–3131. [Google Scholar]
- Hu, Z.; Wu, X.; Yang, J. TCATD: Text Contour Attention for Scene Text Detection. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 1083–1088. [Google Scholar]
- Qiao, L.; Tang, S.; Cheng, Z.; Xu, Y.; Niu, Y.; Pu, S.; Wu, F. Text Perceptron: Towards End-to-End Arbitrary-Shaped Text Spotting. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11899–11907. [Google Scholar]
- Cai, Y.; Liu, Y.; Shen, C.; Jin, L.; Li, Y.; Ergu, D. Arbitrarily shaped scene text detection with dynamic convolution. Pattern Recognit. 2022, 127, 108608. [Google Scholar] [CrossRef]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. EAST: An Efficient and Accurate Scene Text Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5551–5560. [Google Scholar]
- Li, X.; Liu, J.; Zhang, G.; Huang, Y.; Zheng, Y.; Zhang, S. Learning to predict more accurate text instances for scene text detection. Neurocomputing 2021, 449, 455–463. [Google Scholar] [CrossRef]
- Liu, J.; Zhong, Q.; Yuan, Y.; Su, H.; Du, B. SemiText: Scene text detection with semi-supervised learning. Neurocomputing 2020, 407, 343–353. [Google Scholar] [CrossRef]
- He, T.; Huang, W.; Qiao, Y.; Yao, J. Text-Attentional Convolutional Neural Network for Scene Text Detection. IEEE Trans. Image Proces. 2016, 25, 2529–2541. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mittal, A.; Shivakumara, P.; Pal, U.; Lu, T.; Blumenstein, M. A new method for detection and prediction of occluded text in natural scene images. Signal Proces. Image Commun. 2022, 100, 116512. [Google Scholar] [CrossRef]
- Xue, M.; Shivakumara, P.; Zhang, C.; Xiao, Y.; Lu, T.; Pal, U.; Lopresti, D.; Yang, Z. Arbitrarily-Oriented Text Detection in Low Light Natural Scene Images. IEEE Trans. Multimedia 2020, 23, 2706–2720. [Google Scholar] [CrossRef]
- Ding, L.; Goshtasby, A. On the Canny edge detector. Pattern Recognit. 2001, 34, 721–725. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets V2: More Deformable, Better Results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 5–20 June 2019; pp. 9308–9316. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Karatzas, D.; Gomez, B.; Nicolaou, A. ICDAR 2015 competition on Robust Reading. In Proceedings of the 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 1156–1160. [Google Scholar]
- Iwamura, M.; Morimoto, N.; Tainaka, K.; Bazazian, D.; Gomez, L.; Karatzas, D. ICDAR2017 Robust Reading Challenge on Omnidirectional Video. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 1448–1453. [Google Scholar]
- Liao, M.; Zhu, Z.; Shi, Z.B. Rotation-Sensitive Regression for Oriented Scene Text Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5909–5918. [Google Scholar]
- Cai, Y.; Wang, W.; Ren, H.; Lu, K. SPN: Short path network for scene text detection. Neural Comput. Appl. 2019, 32, 6075–6087. [Google Scholar] [CrossRef]
- Long, S.; Ruan, J.; Zhang, W.; He, X.; Wu, W.; Yao, C. TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes. In Proceedings of the European Conference on Computer Vision (ECCV), Cham, Switzerland, 9 October 2018; pp. 20–36. [Google Scholar]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8440–8449. [Google Scholar]
- Lyu, P.; Yao, C.; Wu, W.; Yan, S.; Bai, X. Multi-oriented Scene Text Detection via Corner Localization and Region Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7553–7563. [Google Scholar]
- Zhang, S.X.; Zhu, X.; Hou, J.B.; Liu, C.; Yang, C.; Wang, H.; Yin, X.C. Deep Relational Reasoning Graph Network for Arbitrary Shape Text Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9696–9705. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Channel | Precision (%) | Recall (%) | F-Score (%) |
|---|---|---|---|
| RGB | 91.9 | 83.5 | 87.5 |
| RGBI | 91.8 | 83.76 | 87.6 |
| RGBH | 92.1 | 83.7 | 87.7 |
| RGBS | 92.3 | 84.2 | 88.1 |
| Methods | Precision (%) | Recall (%) | F-Score (%) |
|---|---|---|---|
| DBNet (baseline) | 91.8 | 82.1 | 86.7 |
| DBNet + HLFE | 91.6 | 83.5 | 87.3 |
| DBNet + FPRE | 92.1 | 83.3 | 87.5 |
| DBNet + HLFE + FPRE | 91.8 | 84.1 | 87.8 |
| DNNet + HLFE + FPRE + MSER (ours) | 92.5 | 86.8 | 89.5 |
| Methods | Precision (%) | Recall (%) | F-Score (%) |
|---|---|---|---|
| DBNet (baseline) | 89.5 | 75.9 | 82.1 |
| DBNet + HLFE | 89.3 | 76.7 | 82.5. |
| DBNet + FPRE | 90.1 | 77.1 | 83.1 |
| DBNet + HLFE + FPRE | 88.2 | 78.1 | 83.3 |
| DNNet + HLFE + FPRE + MSER (ours) | 90.8 | 79.0 | 84.5 |
| Methods | Precision (%) | Recall (%) | F-Score (%) |
|---|---|---|---|
| DBNet (baseline) | 81.9 | 63.8 | 71.7 |
| DBNet + HLFE | 83.1 | 63.7 | 72.2 |
| DBNet + FPRE | 83.6 | 63.2 | 72.0 |
| DBNet + HLFE + FPRE | 83.2 | 63.9 | 72.3 |
| DNNet + HLFE + FPRE + MSER (ours) | 84.1 | 64.9 | 73.3 |
| Methods | Precision (%) | Recall (%) | F-Score (%) |
|---|---|---|---|
| EAST [21] | 83.6 | 73.5 | 78.2 |
| PixelLink [15] | 82.9 | 81.7 | 82.3 |
| RRD [33] | 85.6 | 79.0 | 82.2 |
| SPN [34] | 86.6 | 82.1 | 84.3 |
| TextSnake [35] | 84.9 | 80.4 | 82.6 |
| PANet [36] | 84.0 | 81.9 | 82.9 |
| DBNet [10] | 89.5 | 75.9 | 82.1 |
| Ours | 90.8 | 79.0 | 84.5 |
| Methods | Precision (%) | Recall (%) | F-Score (%) |
|---|---|---|---|
| SCUT_DLVlab1 [37] | 80.3 | 54.5 | 65.0 |
| ete_ctc01_multi_scale [37] | 79.8 | 61.2 | 69.3 |
| Corner [37] | 83.8 | 55.6 | 66.8 |
| Zhang et al. [38] | 74.9 | 61.0 | 67.3 |
| PSENet [6] | 77.0 | 68.4 | 72.5 |
| DBNet [10] | 81.9 | 63.8 | 71.7 |
| Ours | 84.1 | 64.9 | 73.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, M.; Leng, Y.; Chen, C.-L.; Tang, Q. An Improved Differentiable Binarization Network for Natural Scene Street Sign Text Detection. Appl. Sci. 2022, 12, 12120. https://doi.org/10.3390/app122312120
Lu M, Leng Y, Chen C-L, Tang Q. An Improved Differentiable Binarization Network for Natural Scene Street Sign Text Detection. Applied Sciences. 2022; 12(23):12120. https://doi.org/10.3390/app122312120
Chicago/Turabian StyleLu, Manhuai, Yi Leng, Chin-Ling Chen, and Qiting Tang. 2022. "An Improved Differentiable Binarization Network for Natural Scene Street Sign Text Detection" Applied Sciences 12, no. 23: 12120. https://doi.org/10.3390/app122312120
APA StyleLu, M., Leng, Y., Chen, C. -L., & Tang, Q. (2022). An Improved Differentiable Binarization Network for Natural Scene Street Sign Text Detection. Applied Sciences, 12(23), 12120. https://doi.org/10.3390/app122312120