
Flow Characteristics of Fibrous Gas Diffusion Layers Using Machine Learning Methods


Abstract
:1. Introduction
2. Methods and Available Data
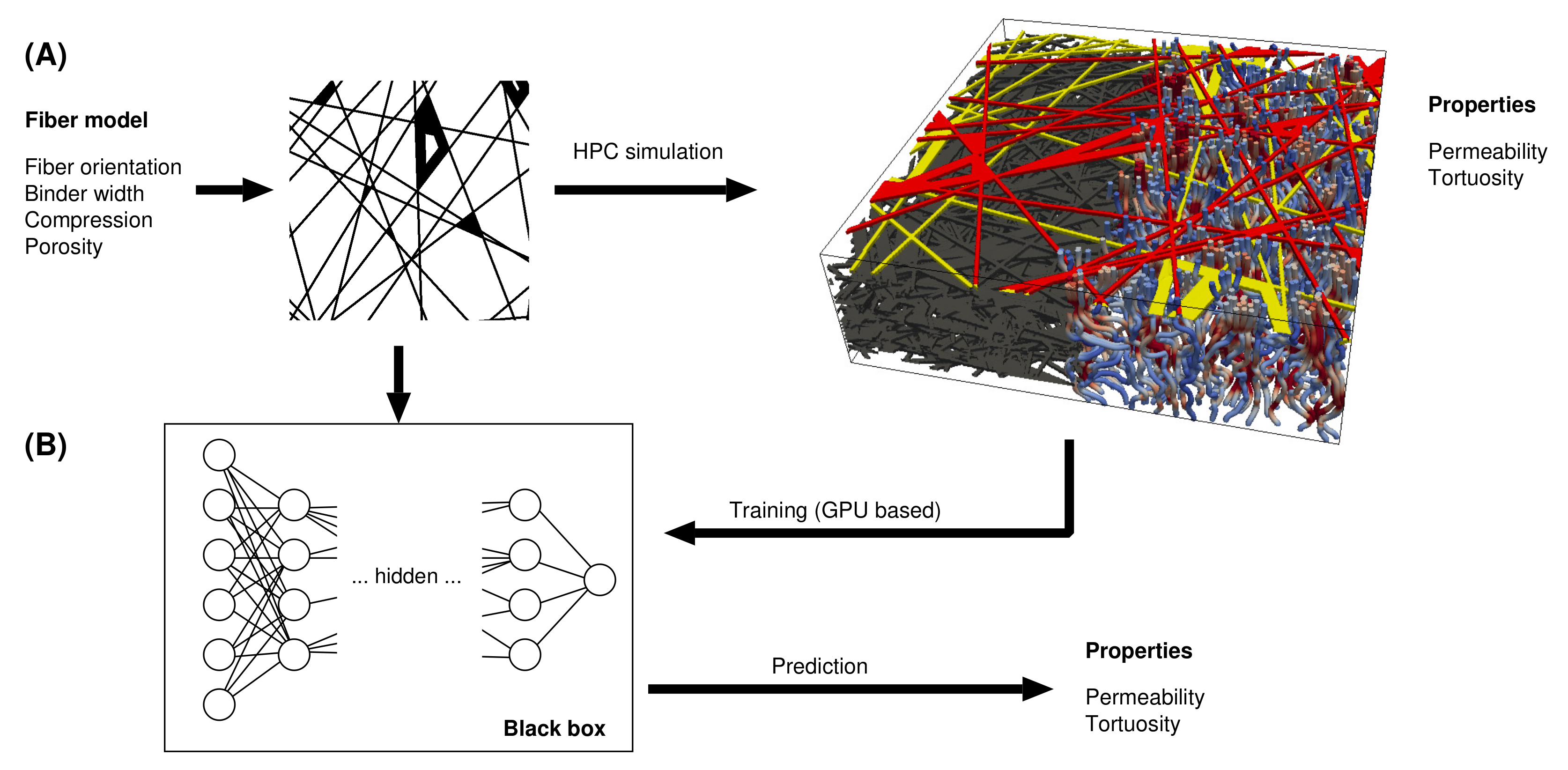
2.1. Machine Learning Model—Overview
2.2. Convolutional Neural Network Model
- Three pairs of three-dimensional convolutional (Conv3D) and average pooling layers;
- Two additional Conv3D layers;
- A flattened layer;
- As a second input, the compression level of the represented material was concatenated with the output of the previous layer;
- Two additional dense layers.
2.3. Basic Data
- Fiber orientation;
- Binder width;
- Compression.
- Porosity;
- Permeability;
- Tortuosity.
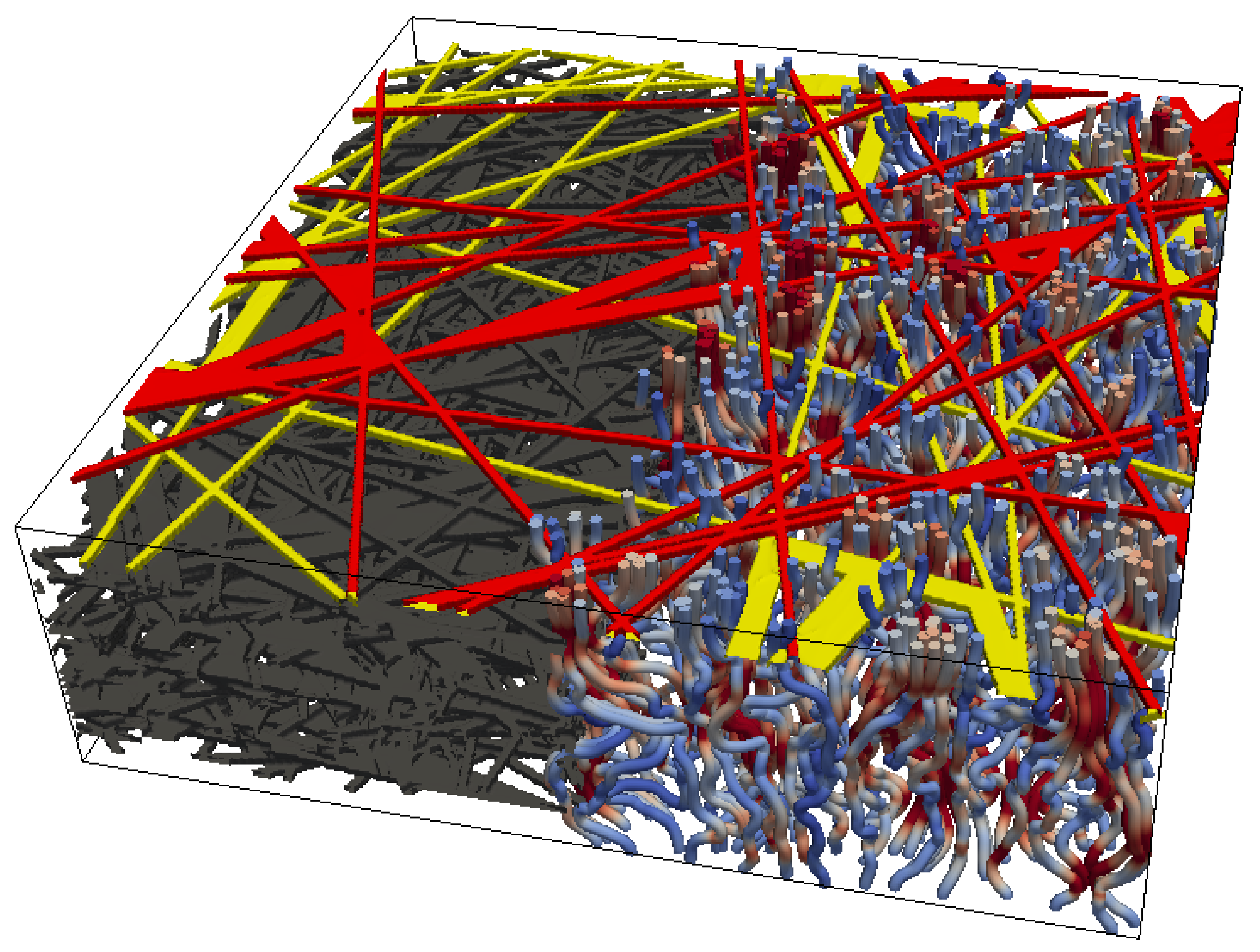
2.4. Lattice Boltzmann Simulations
3. Data Preparation
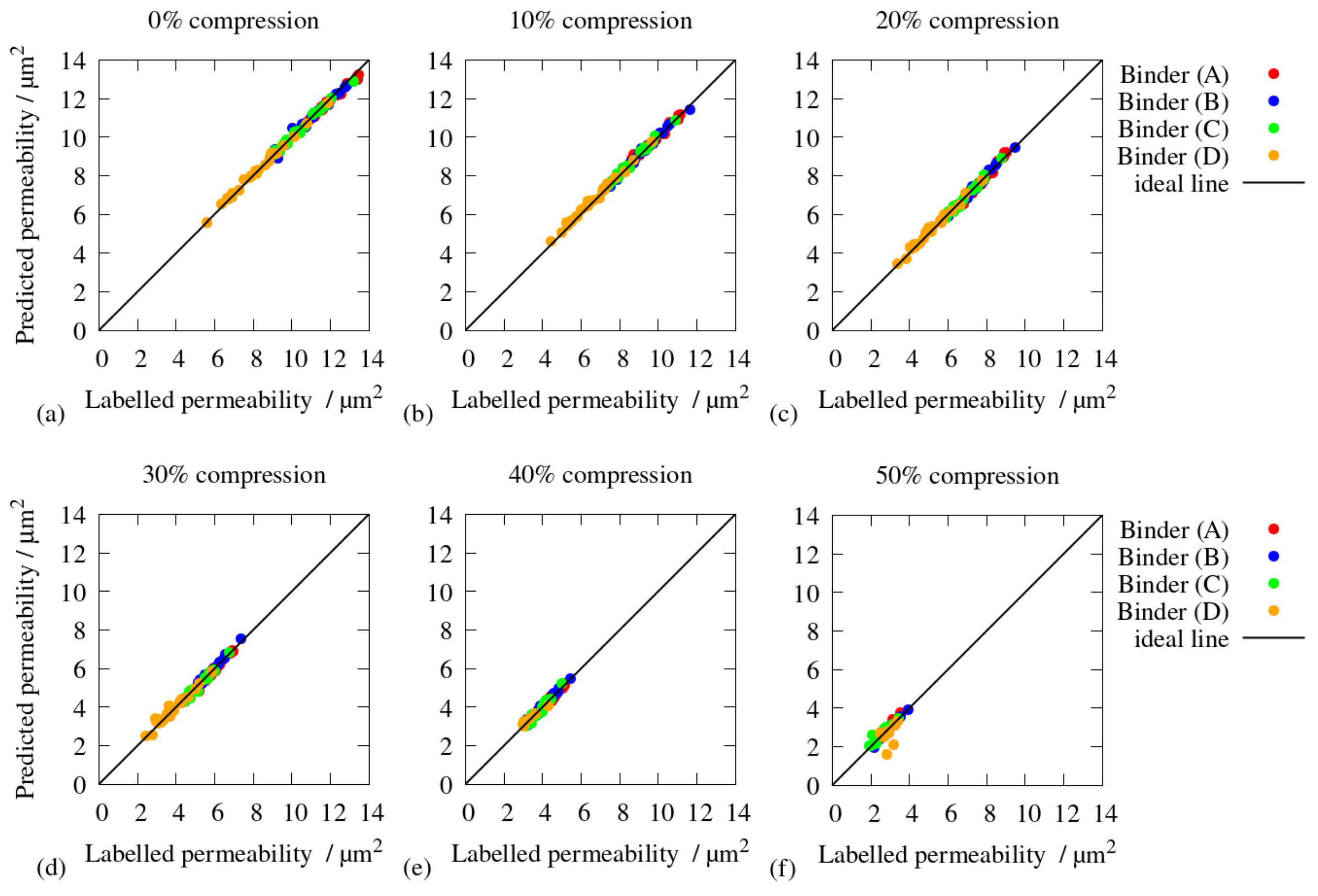
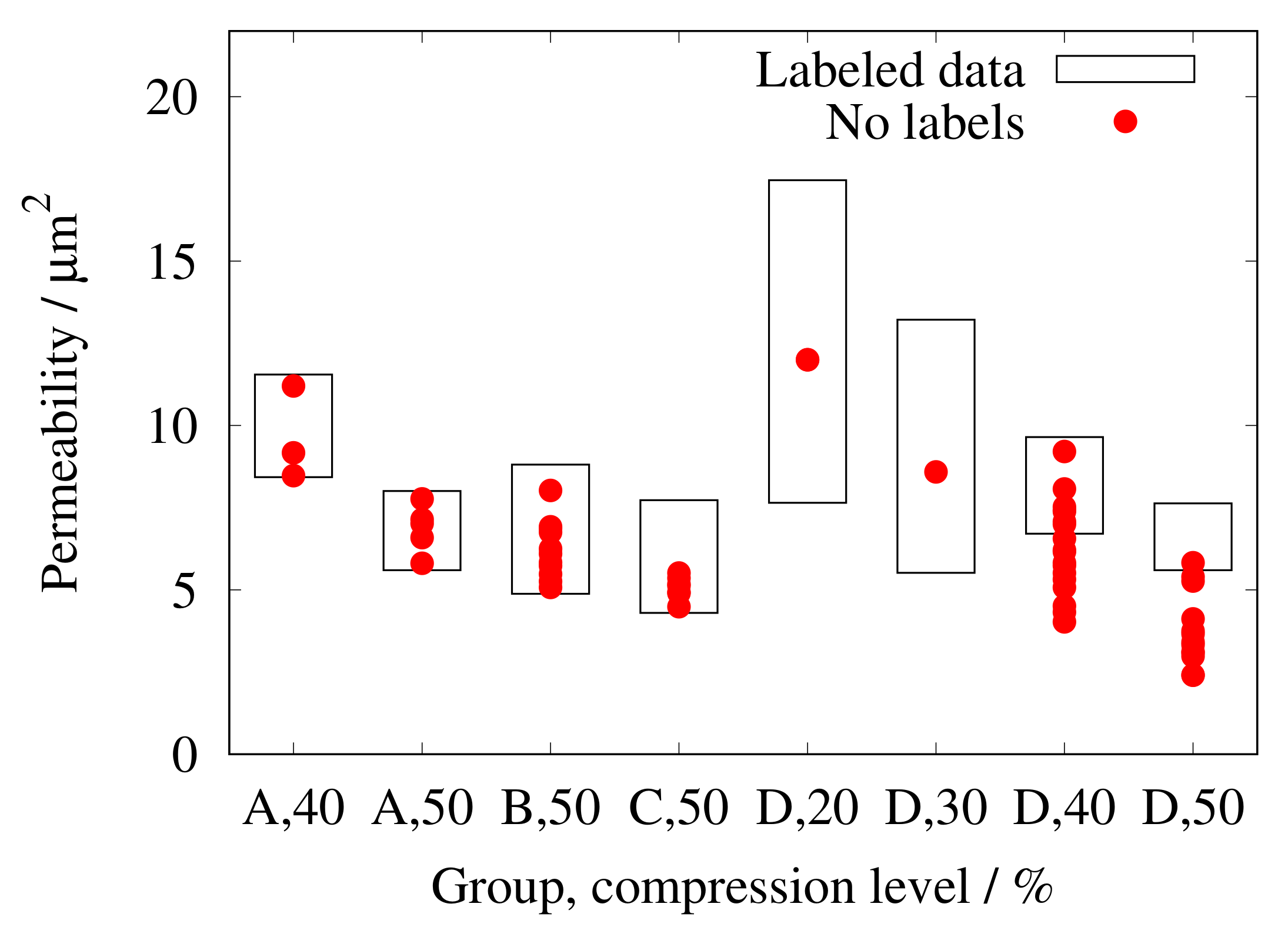
4. Validation
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hoppe, E.; Janßen, H.; Müller, M.; Lehnert, W. The impact of flow field plate misalignment on the gas diffusion layer intrusion and performance of a high-temperature polymer electrolyte fuel cell. J. Power Sources 2021, 501, 230036. [Google Scholar] [CrossRef]
- Kvesić, M.; Reimer, U.; Froning, D.; Lüke, L.; Lehnert, W.; Stolten, D. 3D modeling of a 200 cm2 HT-PEFC short stack. Int. J. Hydrogen Energy 2012, 37, 2430–2439. [Google Scholar] [CrossRef]
- Reimer, U.; Nikitsina, E.; Janßen, H.; Müller, M.; Froning, D.; Beale, S.B.; Lehnert, W. Design and Modeling of Metallic Bipolar Plates for a Fuel Cell Range Extender. Energies 2021, 14, 5484. [Google Scholar] [CrossRef]
- Mukherjee, M.; Bonnet, C.; Lapique, F. Estimation of through-plane and in-plane gas permeability across gas diffusion layers (GDLs): Comparison with equivalent permeability in bipolar plates and relation to fuel cell performance. Int. J. Hydrogen Energy 2020, 45, 13428–13440. [Google Scholar] [CrossRef]
- Yuan, X.Z.; Nayoze-Coynel, C.; Shaigan, N.; Fisher, D.; Zhao, N.; Zamel, N.; Gazdzicki, P.; Ulsh, M.; Friedrich, K.A.; Girard, F.; et al. A review of functions, attributes, properties and measurements for the quality control of proton exchange membrane fuel cell components. J. Power Sources 2021, 491, 229540. [Google Scholar] [CrossRef]
- Yuan, X.Z.; Li, H.; Gu, E.; Qian, W.; Girard, F.; Wang, Q.; Biggs, T.; Jaeggle, M. Measurements of GDL Properties for Quality Control in Fuel Cell Mass Production Line. World Electr. Veh. J. 2016, 8, 422–430. [Google Scholar] [CrossRef] [Green Version]
- Kaneko, H.; Ohta, K.; Shimuzu, M.; Araki, T. Measurements of Anisotropy of the Effective Diffusivity through PEFC GDL and Mass Transfer Resistance at GDL and Channel Interface. Trans. Jpn. Soc. Mech. Eng. Ser. B 2013, 79, 71–81. [Google Scholar] [CrossRef] [Green Version]
- Syarif, N.; Rohendi, D.; Nanda, A.D.; Sandi, M.T.; Sihombing, D.S.W.B. Gas diffusion layer from Binchotan carbon and its electrochemical properties for supporting electrocatalyst in fuel cell. AIMS Energy 2022, 10, 292–305. [Google Scholar] [CrossRef]
- Froning, D.; Brinkmann, J.; Reimer, U.; Schmidt, V.; Lehnert, W.; Stolten, D. 3D analysis, modeling and simulation of transport processes in compressed fibrous microstructures, using the Lattice Boltzmann method. Electrochim. Acta 2013, 110, 325–334. [Google Scholar] [CrossRef] [Green Version]
- Froning, D.; Yu, J.; Gaiselmann, G.; Reimer, U.; Manke, I.; Schmidt, V.; Lehnert, W. Impact of compression on gas transport in non-woven gas diffusion layers of high temperature polymer electrolyte fuel cells. J. Power Sources 2016, 318, 26–34. [Google Scholar] [CrossRef]
- Zhang, H.; Zhu, L.; Harandi, H.B.; Duan, K.; Zeis, R.; Sui, P.C.; Chuang, P.Y.A. Microstructure reconstruction of the gas diffusion layer and analyses of the anisotropic transport properties. Energy Convers. Manag. 2021, 241, 114293. [Google Scholar] [CrossRef]
- Gao, Y.; Jin, T.; Wu, X. Stochastic 3D Carbon Cloth GDL Reconstruction and Transport Prediction. Energies 2020, 13, 572. [Google Scholar] [CrossRef] [Green Version]
- Tomadakis, M.M.; Robertson, T.J. Viscous Permeability of Random Fiber Structures: Comparison of Electrical and Diffusional Estimates with Experimental and Analytical Results. J. Compos. Mater. 2005, 39, 163–188. [Google Scholar] [CrossRef]
- Lee, S.-H.; Nam, J.H.; Kim, C.J.; Kim, H.M. Effect of fiber orientation on Liquid–Gas flow in the gas diffusion layer of a polymer electrolyte membrane fuel cell. Int. J. Hydrogen Energy 2021, 46, 33957–33968. [Google Scholar] [CrossRef]
- Lintermann, A.; Schröder, W. Lattice–Boltzmann simulations for complex geometries on high-performance computers. CEAS Aeronaut. J. 2020, 11, 745–766. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python; Manning: Shelter Island, NJ, USA, 2017; ISBN 9781617294433. [Google Scholar]
- Oliveira, O.N.; Beljonne, D.; Wong, S.S.; Schanze, K.S. Forum on Artificial Intelligence/Machine Learning for Design and Development of Applied Materials. ACS Appl. Mater. Interfaces 2021, 13, 53301–53302. [Google Scholar] [CrossRef]
- Zhao, J.; Qin, F.; Derome, D.; Carmeliet, J. Simulation of quasi-static drainage displacement in porous media on pore-scale: Coupling lattice Boltzmann method and pore network model. J. Hydrol. 2020, 588, 125080. [Google Scholar] [CrossRef]
- Kamrava, S.; Tahmasebi, P.; Sahimi, M. Linking Morphology of Porous Media to Their Macroscopic Permeability by Deep Learning. Transp. Porous Media 2019, 131, 427–448. [Google Scholar] [CrossRef]
- Ishola, O.; Vilcáez, J. Machine learning modeling of permeability in 3D heterogeneous porous media using a novel stochastic pore-scale simulation approach. Fuel 2022, 321, 124044. [Google Scholar] [CrossRef]
- Graczyk, K.M.; Matyka, M. Predicting porosity, permeability, and tortuosity of porous media from images by deep learning. Sci. Rep. 2020, 10, 21488. [Google Scholar] [CrossRef] [PubMed]
- Yasuda, T.; Ookawara, S.; Yoshikawa, S.; Matsumoto, H. Machine learning and data-driven characterization framework for porous materials: Permeability prediction and channeling defect detection. Chem. Eng. J. 2021, 420, 130069. [Google Scholar] [CrossRef]
- Rao, C.; Liu, Y. Three-dimensional convolutional neural network (3D-CNN) for heterogeneous material homogenization. Comput. Mater. Sci. 2020, 184, 109850. [Google Scholar] [CrossRef]
- Wan, S.; Liang, X.; Jiang, H.; Sun, J.; Djilali, N.; Zhao, T. A coupled machine learning and genetic algorithm approach to the design of porous electrodes for redox flow batteries. Appl. Energy 2021, 298, 117177. [Google Scholar] [CrossRef]
- Yuan, Q.; Longo, M.; Thornton, A.W.; McKeown, N.B.; Comesaña-Gándara, B.; Jansen, J.C.; Jelfs, K.E. Imputation of missing gas permeability data for polymer membranes using machine learning. J. Membr. Sci. 2021, 627, 119207. [Google Scholar] [CrossRef]
- Tahmasebi, P.; Kamrava, S.; Bai, T.; Sahimi, M. Machine learning in geo- and environmental sciences: From small to large scale. Adv. Water Resour. 2020, 142, 103619. [Google Scholar] [CrossRef]
- Kamrava, S.; Sahimi, M.; Tahmasebi, P. Simulating fluid flow in complex porous materials by integrating the governing equations with deep-layered machines. npj Comput. Mater. 2021, 7, 127. [Google Scholar] [CrossRef]
- Wang, Y.; Seo, B.; Wang, B.; Zamel, N.; Jiao, K.; Adroher, X.C. Fundamentals, materials, and machine learning of polymer electrolyte membrane fuel cell technology. Energy AI 2020, 1, 100014. [Google Scholar] [CrossRef]
- Colliard-Granero, A.; Batool, M.; Jankovic, J.; Jitsev, J.; Eikerling, M.H.; Malek, K.; Eslamibidgoli, M.J. Deep learning for the automation of particle analysis in catalyst layers for polymer electrolyte fuel cells. Nanoscale 2022, 14, 10–18. [Google Scholar] [CrossRef] [PubMed]
- Hwang, H.; Ahn, J.; Lee, H.; Oh, J.; Kim, J.; Ahn, J.P.; Kim, H.K.; Lee, J.H.; Yoon, Y.; Hwang, J.H. Deep learning-assisted microstructural analysis of Ni/YSZ anode composites for solid oxide fuel cells. Mater. Charact. 2021, 172, 110906. [Google Scholar] [CrossRef]
- Bührer, M.; Xu, H.; Hendriksen, A.A.; Büchi, F.N.; Eller, J.; Stampanoni, M.; Marone, F. Deep learning based classification of dynamic processes in time-resolved X-ray tomographic microscopy. Sci. Rep. 2021, 11, 24174. [Google Scholar] [CrossRef] [PubMed]
- Cawte, T.; Bazylak, A. A 3D convolutional neural network accurately predicts the permeability of gas diffusion layer materials directly from image data. Curr. Opin. Electrochem. 2022, 35, 101101. [Google Scholar] [CrossRef]
- Wang, H.; Yang, G.; Li, S.; Shen, Q.; Liao, J.; Jiang, Z.; Zhang, G.; Zhang, H.; Su, F. Effect of Binder and Compression on the Transport Parameters of a Multilayer Gas Diffusion Layer. Energy Fuels 2021, 35, 15058–15073. [Google Scholar] [CrossRef]
- Froning, D.; Gaiselmann, G.; Reimer, U.; Brinkmann, J.; Schmidt, V.; Lehnert, W. Stochastic Aspects of Mass Transport in Gas Diffusion Layers. Transp. Porous Media 2014, 103, 469–495. [Google Scholar] [CrossRef]
- El-Amir, H.; Hamdy, M. Deep Learning Pipeline; Apress: Berkeley, CA, USA, 2020. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow. Concepts, Tools, and Techniques to Build Intelligent Systems, 2nd ed.; O’Reilly: Sebastopol, CA, USA, 2019; ISBN 978-1-49203264-9. [Google Scholar]
- Thiedmann, R.; Fleischer, F.; Hartnig, C.; Lehnert, W.; Schmidt, V. Stochastic 3D Modeling of the GDL Structure in PEMFCs Based on Thin Section Detection. J. Electrochem. Soc. 2008, 155, B391–B399. [Google Scholar] [CrossRef]
- Thiedmann, R.; Hartnig, C.; Manke, I.; Schmidt, V.; Lehnert, W. Local Structural Characteristics of Pore Space in GDLs of PEM Fuel Cells Based on Geometric 3D Graphs. J. Electrochem. Soc. 2009, 156, B1339. [Google Scholar] [CrossRef]
- Wirtz, J. Untersuchung von Neuronalen Architekturen für ein Prediktives Modell der Eigenschaften von Faserbasierten Gasdiffusionsschichten. Bachelor’s Thesis, University of Applied Sciences, Aachen, Germany, 2021. [Google Scholar]
- Centre, J.S. JURECA: Modular supercomputer at Jülich Supercomputing Centre. J. Large-Scale Res. Facil. 2018, 4, A132. [Google Scholar]
- Pillonetto, G.; Dinuzzo, F.; Chen, T.; Nicolao, G.D.; Ljung, L. Kernel methods in system identification, machine learning and function estimation: A survey. Automatica 2014, 50, 657–682. [Google Scholar] [CrossRef] [Green Version]
- Hussaini, I.S.; Wang, C.Y. Measurement of relative permeability of fuel cell diffusion media. J. Power Sources 2010, 195, 3830–3840. [Google Scholar] [CrossRef]
- Nitta, I.; Hottinen, T.; Himanen, O.; Mikkola, M. Inhomogeneous compression of PEMFC gas diffusion layer. J. Power Sources 2007, 171, 26–36. [Google Scholar] [CrossRef]
- Feser, J.; Prasad, A.; Advani, S. Experimental characterization of in-plane permeability of gas diffusion layers. J. Power Sources 2006, 162, 1226–1231. [Google Scholar] [CrossRef]
- Hoppe, E. Kompressionseigenschaften der Gasdiffusionslage einer Hochtemperatur-Polymerelektrolyt-Brennstoffzelle. Ph.D. Thesis, RWTH Aachen University, Aachen, Germany, 2021. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set 80%, Test Set 20% | ||||||
|---|---|---|---|---|---|---|
| Fold | Out of Sample = X | MSE | ||||
| 1 | X | 0.0676 | ||||
| 2 | X | 0.1128 | ||||
| 3 | X | 0.0389 | ||||
| 4 | X | 0.0446 | ||||
| 5 | X | 0.0578 | ||||
| Average | 0.0643 | |||||
| Comp. | No. | Quantiles of Predicted Permeability/ | MPE/% | MSE/ | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| / | /% | min | 25% | 50% | 75% | Max | Training | Validation | Training | Validation | |
| 6 | 0 | 25 | 10.42 | 11.04 | 11.55 | 12.17 | 13.23 | 0.88 | 0.92 | 0.024 | 0.016 |
| 10 | 25 | 8.62 | 9.20 | 9.56 | 10.14 | 11.19 | 0.73 | 2.77 | 0.007 | 0.077 | |
| 20 | 25 | 6.56 | 7.22 | 7.60 | 8.16 | 9.22 | 1.10 | 1.58 | 0.012 | 0.023 | |
| 30 | 25 | 4.81 | 5.39 | 5.72 | 6.21 | 6.94 | 1.09 | 2.66 | 0.007 | 0.038 | |
| 40 | 22 | 3.60 | 3.95 | 4.30 | 4.53 | 5.25 | 2.08 | 1.81 | 0.010 | 0.009 | |
| 50 | 20 | 2.38 | 2.73 | 2.85 | 3.18 | 3.78 | 2.15 | 5.37 | 0.007 | 0.033 | |
| 18 | 0 | 25 | 8.91 | 10.52 | 11.10 | 11.70 | 13.38 | 0.85 | 2.43 | 0.013 | 0.115 |
| 10 | 25 | 7.46 | 8.71 | 9.15 | 9.65 | 11.44 | 0.90 | 1.99 | 0.010 | 0.036 | |
| 20 | 25 | 5.87 | 6.85 | 7.14 | 7.66 | 9.44 | 1.05 | 1.76 | 0.008 | 0.017 | |
| 30 | 25 | 4.32 | 5.25 | 5.42 | 5.84 | 7.53 | 1.34 | 1.83 | 0.010 | 0.011 | |
| 40 | 25 | 3.08 | 3.71 | 4.01 | 4.31 | 5.47 | 1.73 | 2.96 | 0.007 | 0.016 | |
| 50 | 14 | 1.97 | 2.49 | 2.70 | 3.02 | 3.93 | 1.69 | 4.06 | 0.005 | 0.015 | |
| 30 | 0 | 25 | 9.10 | 9.66 | 10.24 | 11.32 | 12.87 | 0.89 | 0.82 | 0.015 | 0.009 |
| 10 | 25 | 7.48 | 7.91 | 8.38 | 9.35 | 10.85 | 0.93 | 1.37 | 0.010 | 0.016 | |
| 20 | 25 | 5.84 | 6.24 | 6.49 | 7.39 | 8.92 | 1.02 | 1.50 | 0.008 | 0.013 | |
| 30 | 25 | 4.28 | 4.72 | 4.85 | 5.51 | 6.84 | 1.62 | 2.70 | 0.010 | 0.028 | |
| 40 | 25 | 3.02 | 3.39 | 3.61 | 4.09 | 5.21 | 2.07 | 4.05 | 0.008 | 0.032 | |
| 50 | 18 | 2.06 | 2.35 | 2.60 | 2.89 | 3.47 | 3.68 | 9.58 | 0.014 | 0.077 | |
| ∞ | 0 | 25 | 5.57 | 7.23 | 8.11 | 9.12 | 11.78 | 1.17 | 1.41 | 0.012 | 0.021 |
| 10 | 25 | 4.60 | 5.86 | 6.67 | 7.35 | 9.73 | 1.92 | 4.10 | 0.019 | 0.052 | |
| 20 | 24 | 3.48 | 4.46 | 5.15 | 5.75 | 7.76 | 2.50 | 1.63 | 0.022 | 0.011 | |
| 30 | 24 | 2.49 | 3.33 | 3.90 | 4.28 | 5.85 | 3.90 | 4.26 | 0.032 | 0.048 | |
| 40 | 7 | 3.02 | 3.16 | 3.28 | 3.52 | 4.05 | 3.36 | 3.69 | 0.018 | 0.031 | |
| 50 | 12 | 1.61 | 2.56 | 2.71 | 2.76 | 3.33 | 5.11 | 38.35 | 0.025 | 1.319 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Froning, D.; Wirtz, J.; Hoppe, E.; Lehnert, W. Flow Characteristics of Fibrous Gas Diffusion Layers Using Machine Learning Methods. Appl. Sci. 2022, 12, 12193. https://doi.org/10.3390/app122312193
Froning D, Wirtz J, Hoppe E, Lehnert W. Flow Characteristics of Fibrous Gas Diffusion Layers Using Machine Learning Methods. Applied Sciences. 2022; 12(23):12193. https://doi.org/10.3390/app122312193
Chicago/Turabian StyleFroning, Dieter, Jannik Wirtz, Eugen Hoppe, and Werner Lehnert. 2022. "Flow Characteristics of Fibrous Gas Diffusion Layers Using Machine Learning Methods" Applied Sciences 12, no. 23: 12193. https://doi.org/10.3390/app122312193
APA StyleFroning, D., Wirtz, J., Hoppe, E., & Lehnert, W. (2022). Flow Characteristics of Fibrous Gas Diffusion Layers Using Machine Learning Methods. Applied Sciences, 12(23), 12193. https://doi.org/10.3390/app122312193