
Temporal-Guided Label Assignment for Video Object Detection


Abstract
:1. Introduction
- A temporal-guided label assignment framework is proposed. This framework utilizes temporal information to improve the learning task of an RPN.
- We introduce a feature instructing module (FIM) that additionally uses feature information to establish the temporal relation model of labels and enhances the labels. Features contain richer semantic information and can be used to effectively construct the association of labels.
- Experimental results on the ImageNet VID dataset demonstrate that our proposed framework is on par with state-of-the-art works with no extra inference cost compared with our baseline.
2. Related Work
2.1. Object Detection in Still Images
2.2. Video Object Detection
2.3. Label Assignment
3. Methodology
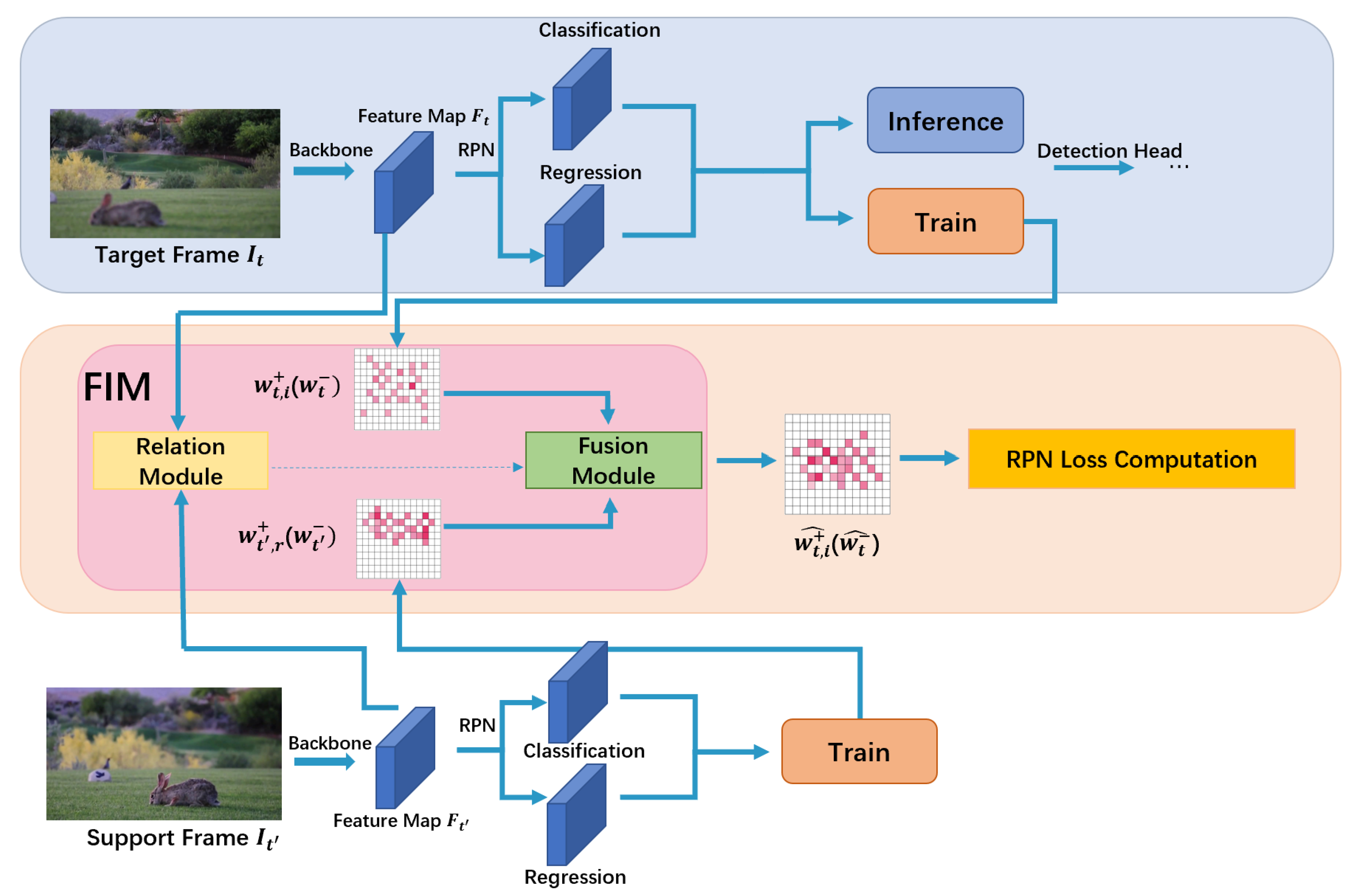
3.1. Overview
3.2. Temporal-Guided Label Assignment Framework
3.2.1. Weight Maps for Label Assignment
3.2.2. Temporal-Guided Label Assignment
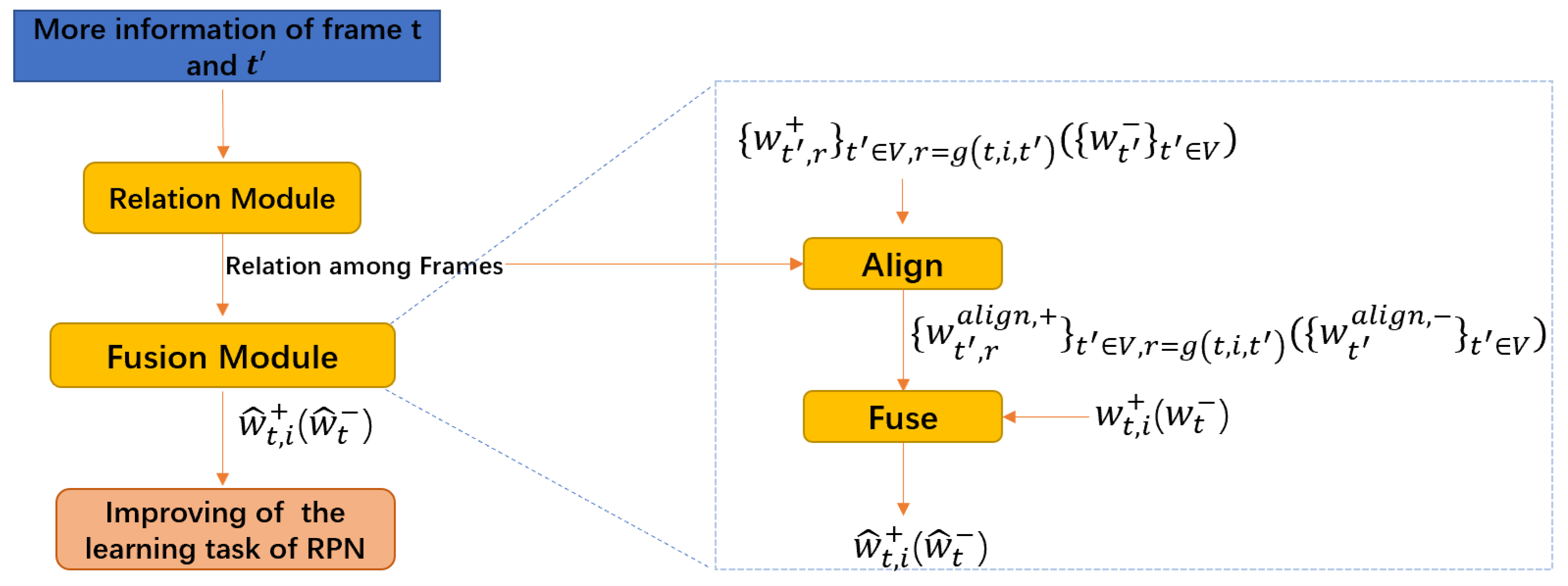
3.3. Feature Instructing Module
3.3.1. Relation Module
3.3.2. Fusion Module
3.3.3. Improving the Learning Task
4. Experiment
4.1. Dataset and Evaluation Setup
4.2. Implementation Details
4.2.1. Architecture
4.2.2. Training Details
4.3. Ablation Study
4.3.1. Effect of Support Frame Number N
4.3.2. The Effectiveness of Temporal-Guided Label Assignment and the Feature Instructing Module (FIM)
4.4. Comparison with State-of-the-Art Methods
4.5. Detection Visualization
5. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhu, X.; Xiong, Y.; Dai, J.; Yuan, L.; Wei, Y. Deep feature flow for video recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2349–2358. [Google Scholar]
- Zhu, X.; Wang, Y.; Dai, J.; Yuan, L.; Wei, Y. Flow-guided feature aggregation for video object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 408–417. [Google Scholar]
- Zhu, X.; Dai, J.; Yuan, L.; Wei, Y. Towards high performance video object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7210–7218. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; van der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Guo, C.; Fan, B.; Gu, J.; Zhang, Q.; Xiang, S.; Prinet, V.; Pan, C. Progressive sparse local attention for video object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019; pp. 3909–3918. [Google Scholar]
- Jiang, Z.; Liu, Y.; Yang, C.; Liu, J.; Gao, P.; Zhang, Q.; Xiang, S.; Pan, C. Learning where to focus for efficient video object detection. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 18–34. [Google Scholar]
- Bertasius, G.; Torresani, L.; Shi, J. Object detection in video with spatiotemporal sampling networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 331–346. [Google Scholar]
- Wu, H.; Chen, Y.; Wang, N.; Zhang, Z. Sequence level semantics aggregation for video object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019; pp. 9217–9225. [Google Scholar]
- Deng, J.; Pan, Y.; Yao, T.; Zhou, W.; Li, H.; Mei, T. Relation distillation networks for video object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019; pp. 7023–7032. [Google Scholar]
- Han, M.; Wang, Y.; Chang, X.; Qiao, Y. Mining inter-video proposal relations for video object detection. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 431–446. [Google Scholar]
- Gong, T.; Chen, K.; Wang, X.; Chu, Q.; Zhu, F.; Lin, D.; Yu, N.; Feng, H. Temporal ROI align for video object recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Virtual, 2–9 February 2021; Volume 35, pp. 1442–1450. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Wang, J.; Chen, K.; Yang, S.; Loy, C.C.; Lin, D. Region proposal by guided anchoring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2965–2974. [Google Scholar]
- Yang, T.; Zhang, X.; Li, Z.; Zhang, W.; Sun, J. Metaanchor: Learning to detect objects with customized anchors. In Advances in Neural Information Processing Systems; Curran Associates: New York, NY, USA, 2018; Volume 31. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar]
- Ge, Z.; Liu, S.; Li, Z.; Yoshie, O.; Sun, J. Ota: Optimal transport assignment for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 303–312. [Google Scholar]
- Zhu, B.; Wang, J.; Jiang, Z.; Zong, F.; Liu, S.; Li, Z.; Sun, J. Autoassign: Differentiable label assignment for dense object detection. arXiv 2020, arXiv:2007.03496. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; Curran Associates: New York, NY, USA, 2015; Volume 28. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Advances in Neural Information Processing Systems; Curran Associates: New York, NY, USA, 2016; Volume 29. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates: New York, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Zhu, X.; Li, Z.; Lou, J.; Shen, Q. Video super-resolution based on a spatio-temporal matching network. Pattern Recognit. 2021, 110, 107619. [Google Scholar] [CrossRef]
- Zhu, X.; Li, Z.; Li, X.; Li, S.; Dai, F. Attention-aware perceptual enhancement nets for low-resolution image classification. Inf. Sci. 2020, 515, 233–247. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Kang, K.; Li, H.; Yan, J.; Zeng, X.; Yang, B.; Xiao, T.; Zhang, C.; Wang, Z.; Wang, R.; Wang, X.; et al. T-cnn: Tubelets with convolutional neural networks for object detection from videos. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2896–2907. [Google Scholar] [CrossRef]
- Lee, B.; Erdenee, E.; Jin, S.; Nam, M.Y.; Jung, Y.G.; Rhee, P.K. Multi-class multi-object tracking using changing point detection. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 68–83. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems; Curran Associates: New York, NY, USA, 2019; Volume 32. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Detect to track and track to detect. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3038–3046. [Google Scholar]
- Shvets, M.; Liu, W.; Berg, A.C. Leveraging Long-Range Temporal Relationships Between Proposals for Video Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019; pp. 9756–9764. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| #N | 2 | 4 | 6 | 8 |
|---|---|---|---|---|
| mAP(%) | 81.0 | 81.4 | 81.7 | 82.0 |
| Method | Temporal-Guided Label Assignment | FIM | mAP(%) |
|---|---|---|---|
| TROI-Var | - | - | 81.2 |
| Our TGLA | ✓ | - | 81.5 |
| Our TGLA | ✓ | ✓ | 82.0 |
| Method | Backbone | mAP(%) |
|---|---|---|
| FGFA [2] | R101 | 78.4 |
| D&T [32] | R101 | 80.0 |
| PLSA [5] | R101+DCN | 80.0 |
| SELSA [8] | R101 | 80.25 |
| Leveraging [33] | R101-FPN | 81.0 |
| RDN [9] | R101 | 81.8 |
| TGLA | R101 | 82.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, S.; Xia, M.; Yang, C. Temporal-Guided Label Assignment for Video Object Detection. Appl. Sci. 2022, 12, 12314. https://doi.org/10.3390/app122312314
Tian S, Xia M, Yang C. Temporal-Guided Label Assignment for Video Object Detection. Applied Sciences. 2022; 12(23):12314. https://doi.org/10.3390/app122312314
Chicago/Turabian StyleTian, Shu, Meng Xia, and Chun Yang. 2022. "Temporal-Guided Label Assignment for Video Object Detection" Applied Sciences 12, no. 23: 12314. https://doi.org/10.3390/app122312314
APA StyleTian, S., Xia, M., & Yang, C. (2022). Temporal-Guided Label Assignment for Video Object Detection. Applied Sciences, 12(23), 12314. https://doi.org/10.3390/app122312314