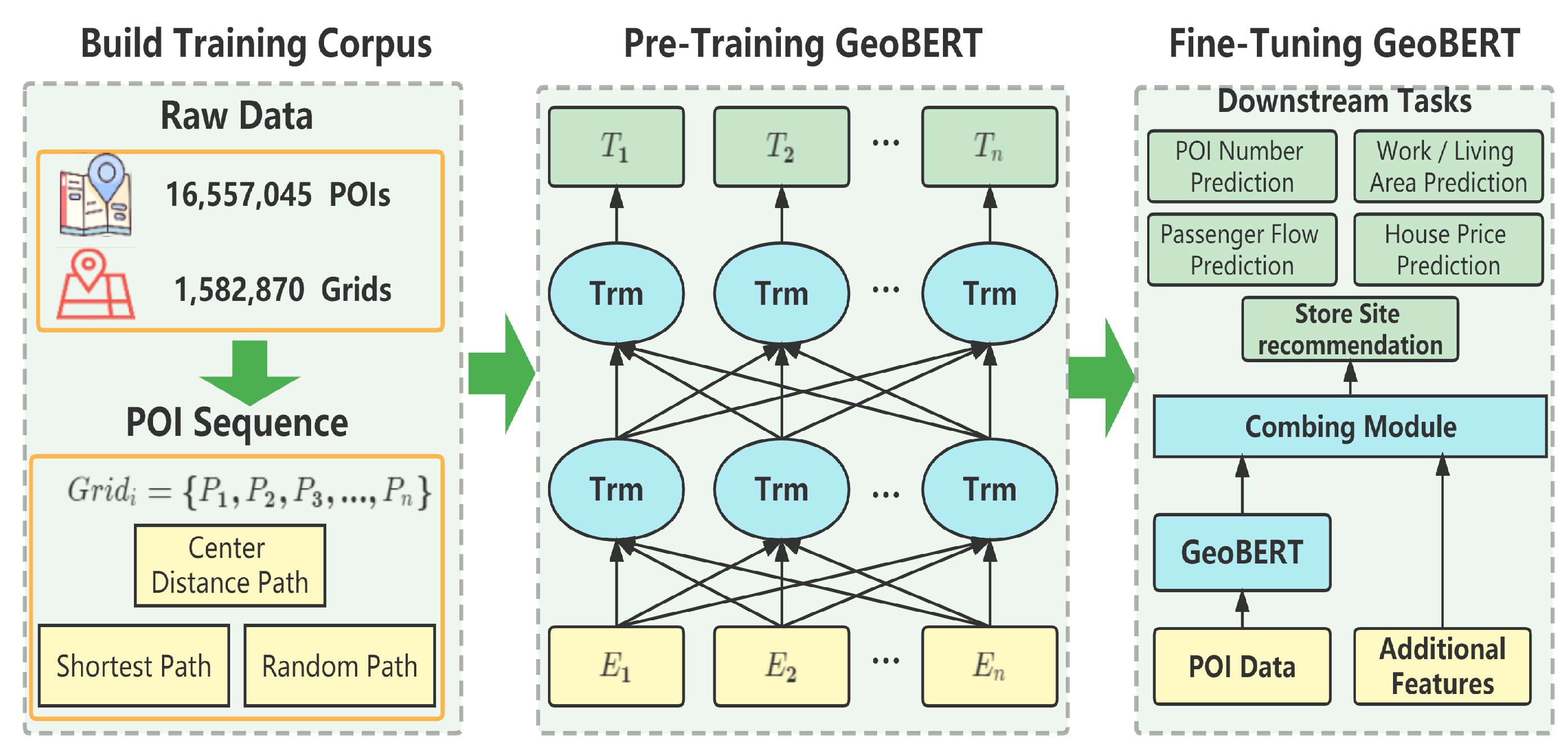
Figure 1.
The overall framework of this study consists of three parts. The part on the left side shows how we construct pre-training corpora based on POIs and Geohash Grids. The middle part shows the model structure, which is based on the BERT structure. E represents the input embedding, Trm refers to a transformer block, and T represents the output token. On the right side is the fine-tuning module. We design five practical downstream tasks. The grid embedding learned from GeoBERT can be directly used for fine-tuning or combined with other features.
Figure 1.
The overall framework of this study consists of three parts. The part on the left side shows how we construct pre-training corpora based on POIs and Geohash Grids. The middle part shows the model structure, which is based on the BERT structure. E represents the input embedding, Trm refers to a transformer block, and T represents the output token. On the right side is the fine-tuning module. We design five practical downstream tasks. The grid embedding learned from GeoBERT can be directly used for fine-tuning or combined with other features.
Figure 2.
The left part exhibits the area of Shanghai, which covers 404,697 level-7 Geohash grids in total. On the right, is a slice that covers 20 grids. Each level-7 grid can be represented by a unique Geohash string of length 7. All the smaller grids that belong to the same larger grid of the upper level share the same prefix. As shown in the figure, the Geohash of 4 grids in the lower right corner share six characters “wtw3w3” in the prefix since they all belong to a much larger level-6 Geohash grid. The same phenomenon can be observed in all four corners.
Figure 2.
The left part exhibits the area of Shanghai, which covers 404,697 level-7 Geohash grids in total. On the right, is a slice that covers 20 grids. Each level-7 grid can be represented by a unique Geohash string of length 7. All the smaller grids that belong to the same larger grid of the upper level share the same prefix. As shown in the figure, the Geohash of 4 grids in the lower right corner share six characters “wtw3w3” in the prefix since they all belong to a much larger level-6 Geohash grid. The same phenomenon can be observed in all four corners.
Figure 3.
Distribution of POI sequence length of grids. The POI sequence length is the number of POIs in a level-7 Geohash grid. The max length is set to 64, which covers 97.33%.
Figure 3.
Distribution of POI sequence length of grids. The POI sequence length is the number of POIs in a level-7 Geohash grid. The max length is set to 64, which covers 97.33%.
Figure 4.
Construct a POI sequence based on distance ordering from the center point.
Figure 4.
Construct a POI sequence based on distance ordering from the center point.
Figure 5.
The POI number dataset of Shanghai.
Figure 5.
The POI number dataset of Shanghai.
Figure 6.
The working/living area dataset of Shanghai, where yellow refers to living area and red to working area.
Figure 6.
The working/living area dataset of Shanghai, where yellow refers to living area and red to working area.
Figure 7.
The passenger flow dataset of Shanghai, where red refers to high-density areas.
Figure 7.
The passenger flow dataset of Shanghai, where red refers to high-density areas.
Figure 8.
The house price dataset of Shanghai, where red refers to higher house prices.
Figure 8.
The house price dataset of Shanghai, where red refers to higher house prices.
Figure 9.
The process of building a bank recommendation dataset.
Figure 9.
The process of building a bank recommendation dataset.
Figure 10.
Results of classification tasks. Word2vec and GloVe still achieve good results. GeoBERT leads Word2vec by 4.49% in Accuracy for the store site recommendation task and 1.51% for the working∖living area prediction task.
Figure 10.
Results of classification tasks. Word2vec and GloVe still achieve good results. GeoBERT leads Word2vec by 4.49% in Accuracy for the store site recommendation task and 1.51% for the working∖living area prediction task.
Figure 11.
Self-attention mechanism in GeoBERT. GeoBERT consists of 12 layers and 12 heads in each layer. Each row represents a layer (from 0 to 11). Each block represents a head (from 0 to 11). The lines between pairs of tokens in a head show the self-attention weights between them. The darker the color is, the greater the weight between the two tokens. Different layers are represented by different colors, while the same color represents heads in the same layer. These are better viewed in color: (a) GeoBERT-ShortestPath; (b) GeoBERT-CenterDistance; (c) GeoBERT-RandomPath.
Figure 11.
Self-attention mechanism in GeoBERT. GeoBERT consists of 12 layers and 12 heads in each layer. Each row represents a layer (from 0 to 11). Each block represents a head (from 0 to 11). The lines between pairs of tokens in a head show the self-attention weights between them. The darker the color is, the greater the weight between the two tokens. Different layers are represented by different colors, while the same color represents heads in the same layer. These are better viewed in color: (a) GeoBERT-ShortestPath; (b) GeoBERT-CenterDistance; (c) GeoBERT-RandomPath.
Figure 12.
The pattern of attention to the next token. The attention mechanism for shortest Path POI sequence example in
Table 16 is illustrated. Note that the index starts at 0. Most tokens have a heavy attention weight directed to the subsequent tokens. However, this pattern is not absolute since we can see that some tokens are directed to the other tokens. Colors on the top identify the corresponding attention head(s), while the depth of color reflects the attention score: (
a) attention weights for all tokens in Layer 1, Head 10; (
b) attention weights for selected token ’Teahouse’.
Figure 12.
The pattern of attention to the next token. The attention mechanism for shortest Path POI sequence example in
Table 16 is illustrated. Note that the index starts at 0. Most tokens have a heavy attention weight directed to the subsequent tokens. However, this pattern is not absolute since we can see that some tokens are directed to the other tokens. Colors on the top identify the corresponding attention head(s), while the depth of color reflects the attention score: (
a) attention weights for all tokens in Layer 1, Head 10; (
b) attention weights for selected token ’Teahouse’.
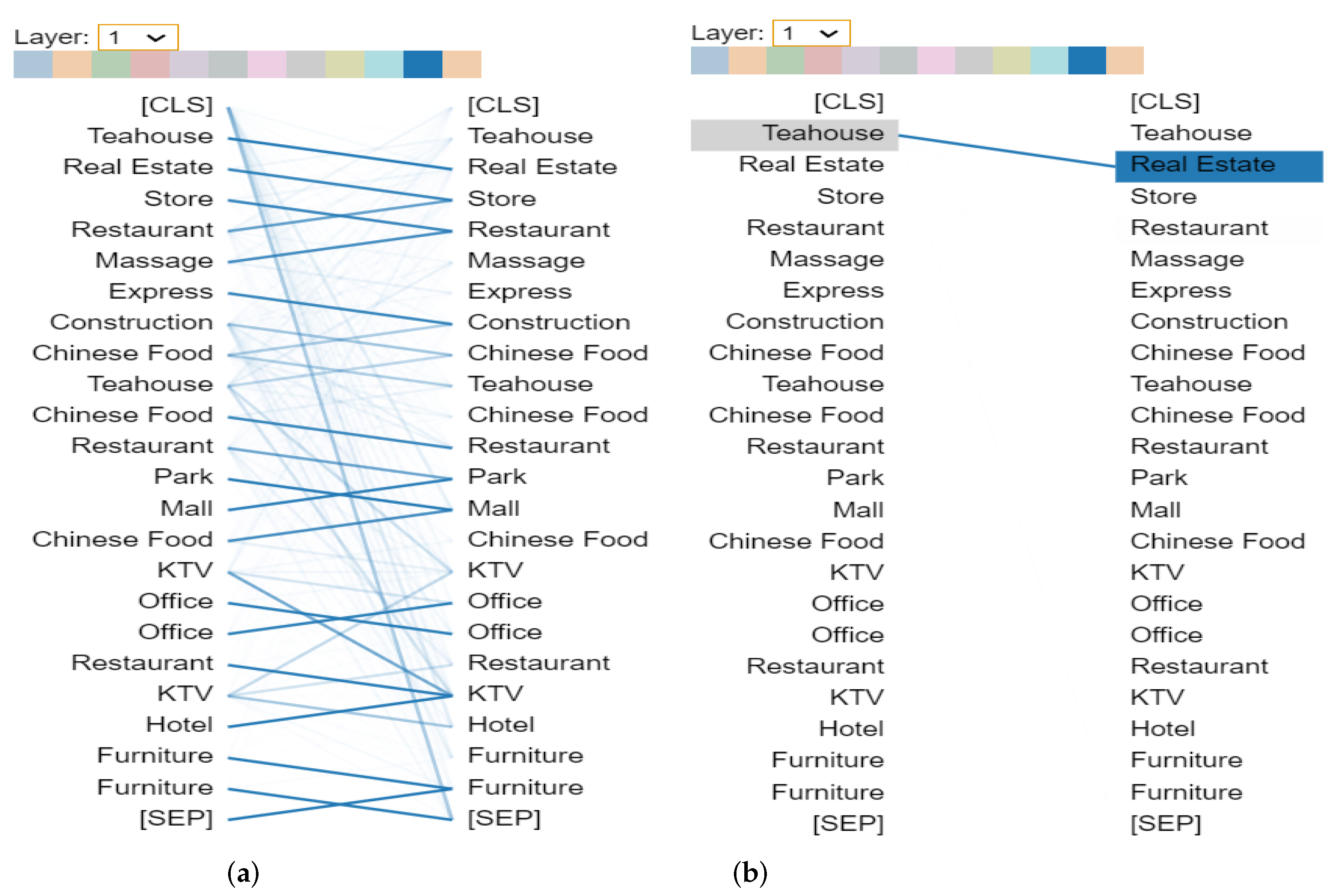
Figure 13.
The pattern of attention to the previous token. In the example of Layer 0, Head 2, most tokens show apparent attention weight directed to the previous tokens. Of course, there are some exceptions, such as the token “Teahouse”, which still has close attention to the next token “Real Estate”: (a) attention weights for all tokens in Layer 0, Head 2; (b) attention weights for selected token ’Store’.
Figure 13.
The pattern of attention to the previous token. In the example of Layer 0, Head 2, most tokens show apparent attention weight directed to the previous tokens. Of course, there are some exceptions, such as the token “Teahouse”, which still has close attention to the next token “Real Estate”: (a) attention weights for all tokens in Layer 0, Head 2; (b) attention weights for selected token ’Store’.
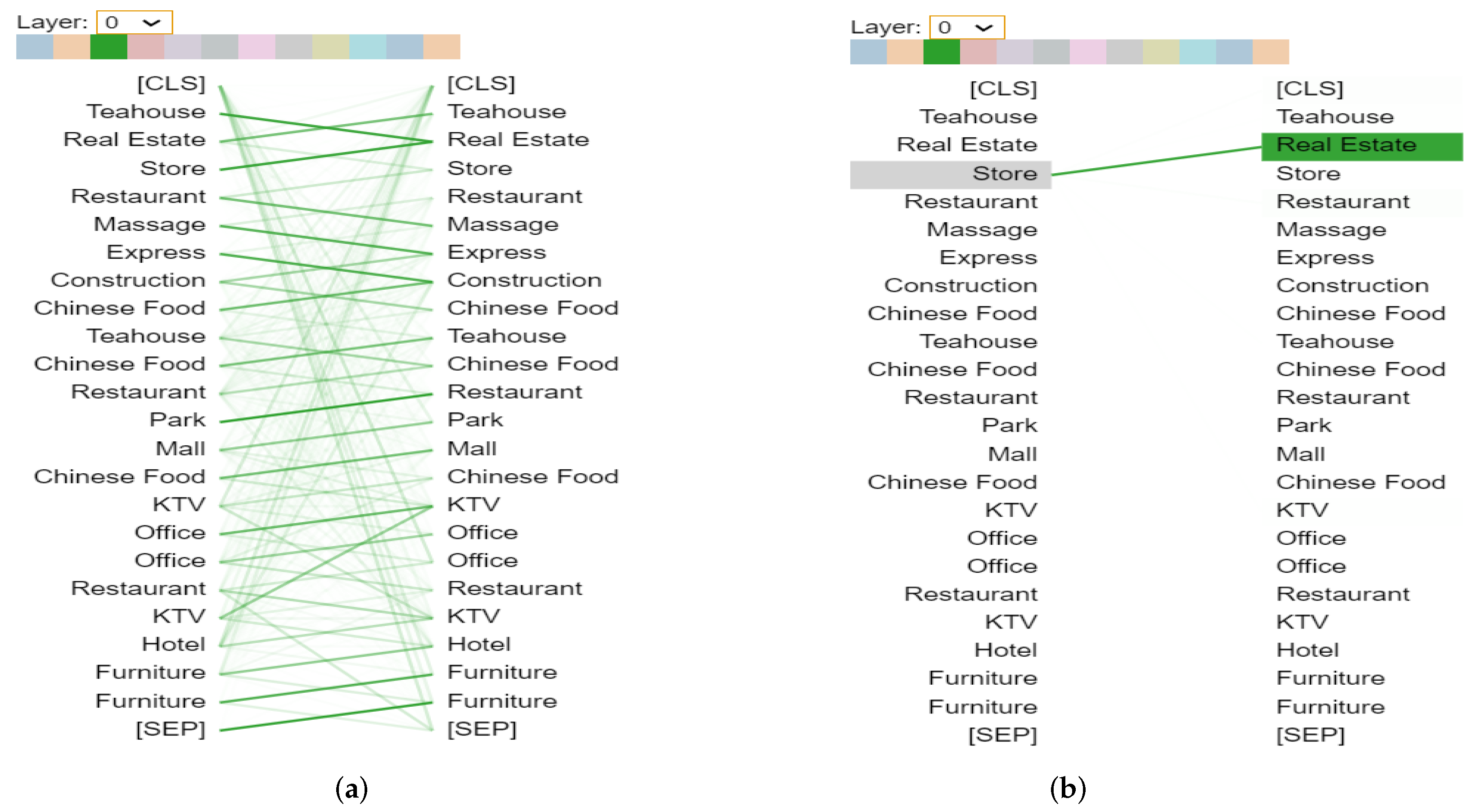
Figure 14.
Pattern of long-distance dependencies. “Real Estate” is directed to itself and “Express” in (a). However, the attention is also dispersed over many different words which can be seen in (b). The color in the right sequence represents its corresponding head with yellow for Head 1 and green for Head 2: (a) attention weights for selected token “Real Estate” in Layer 6, Head 1; (b) attention weights for selected token “Real Estate” in Layer 6, heads 1 (orange) and 2 (green).
Figure 14.
Pattern of long-distance dependencies. “Real Estate” is directed to itself and “Express” in (a). However, the attention is also dispersed over many different words which can be seen in (b). The color in the right sequence represents its corresponding head with yellow for Head 1 and green for Head 2: (a) attention weights for selected token “Real Estate” in Layer 6, Head 1; (b) attention weights for selected token “Real Estate” in Layer 6, heads 1 (orange) and 2 (green).
Figure 15.
Attention Layer 1 and Layer 2 in GeoBERT-ShortestPath. We can see pairs of cross lines between adjacent tokens, which means that GeoBERT has learned the position information between adjacent tokens. (a) Attention Layer 1; (b) Attention Layer 2.
Figure 15.
Attention Layer 1 and Layer 2 in GeoBERT-ShortestPath. We can see pairs of cross lines between adjacent tokens, which means that GeoBERT has learned the position information between adjacent tokens. (a) Attention Layer 1; (b) Attention Layer 2.
Figure 16.
Attention Layer 1 and Layer 2 in GeoBERT-CenterDistance. Pairs of cross lines between adjacent tokens can be clearly observed, and the conclusion is similar to the shortest Path. Moreover, most of these signs occur at shallow attention layers, basically from Layer 0 to Layer 2. Thus, we believe that in the shallow attention layers, GeoBERT learns the position information among POIs: (a) Attention Layer 1; (b) Attention Layer 2.
Figure 16.
Attention Layer 1 and Layer 2 in GeoBERT-CenterDistance. Pairs of cross lines between adjacent tokens can be clearly observed, and the conclusion is similar to the shortest Path. Moreover, most of these signs occur at shallow attention layers, basically from Layer 0 to Layer 2. Thus, we believe that in the shallow attention layers, GeoBERT learns the position information among POIs: (a) Attention Layer 1; (b) Attention Layer 2.
Figure 17.
Attention Layer 1 and Layer 2 in GeoBERT-RandomPath. Unlike the above two methods, there were no obvious signs observed. Therefore, we think that no position information has been acquired by GeoBERT-RandomPath. This phenomenon is reasonable since all POIs are ordered randomly: (a) Attention Layer 1: (b) Attention Layer 2.
Figure 17.
Attention Layer 1 and Layer 2 in GeoBERT-RandomPath. Unlike the above two methods, there were no obvious signs observed. Therefore, we think that no position information has been acquired by GeoBERT-RandomPath. This phenomenon is reasonable since all POIs are ordered randomly: (a) Attention Layer 1: (b) Attention Layer 2.
Figure 18.
Two specific attention heads in GeoBERT-ShortestPath. In both figures, tokens “Mall” and “Hotel” strongly connect with all other tokens. We define this kind of token as the “Anchor POIs” in a grid. Anchor POIs play essential roles in a grid and to some extent can represent certain attributes of the whole grid: (a) Layer 9, Head 9; (b) Layer 10, Head 8.
Figure 18.
Two specific attention heads in GeoBERT-ShortestPath. In both figures, tokens “Mall” and “Hotel” strongly connect with all other tokens. We define this kind of token as the “Anchor POIs” in a grid. Anchor POIs play essential roles in a grid and to some extent can represent certain attributes of the whole grid: (a) Layer 9, Head 9; (b) Layer 10, Head 8.
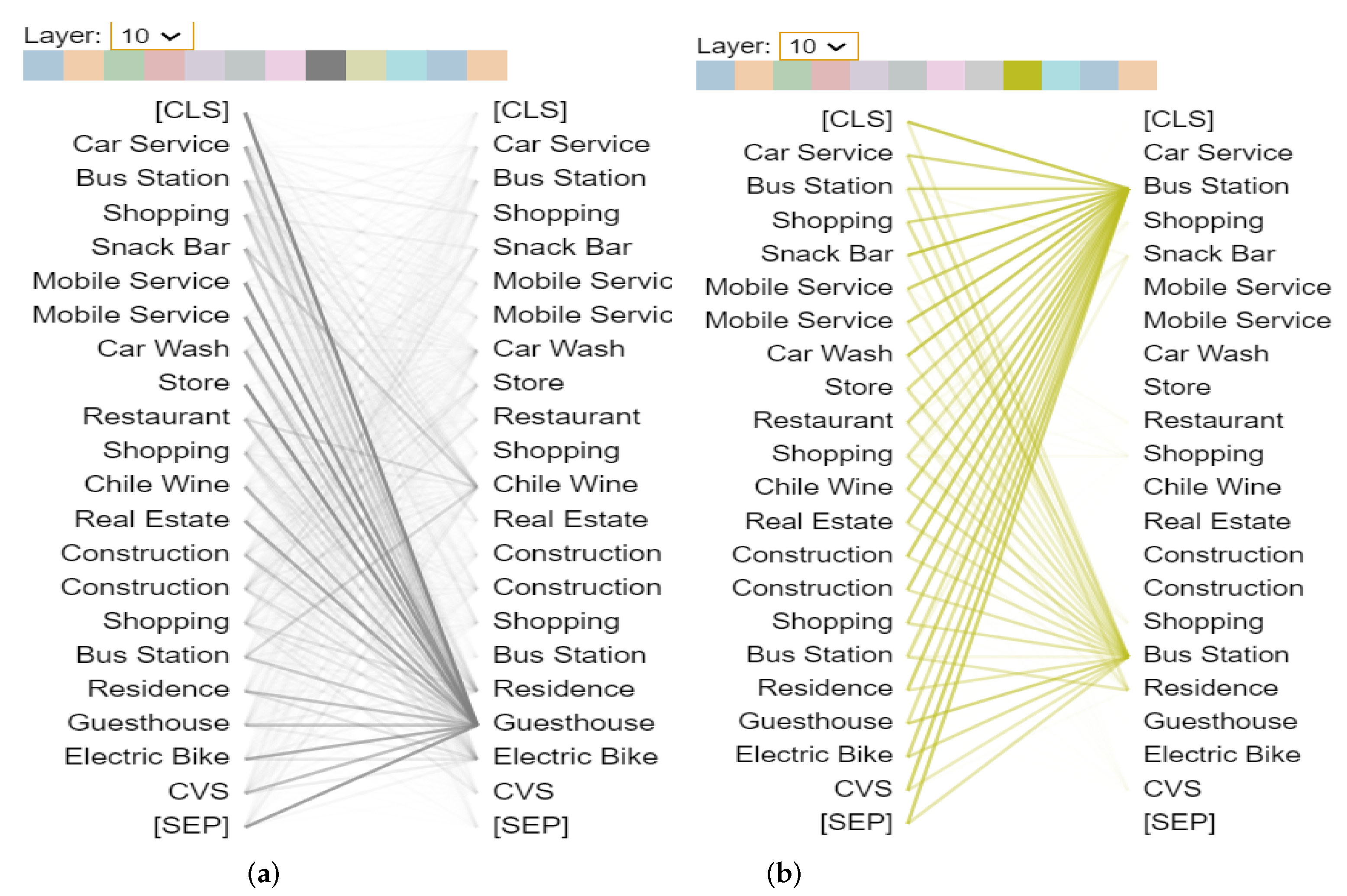
Figure 19.
Attention Layer 10 (with all heads) of three models. Although “Mall’ and “Hotel” are in different positions in different corpora, they are successfully recognized by the models. As we have mentioned, the core ability of GeoBERT is to identify the most significant tokens in a grid and capture co-occurrence. These phenomena only appear in the deep attention layers, basically from Layer 9 to Layer 11 (layer index starts at 0).
Figure 19.
Attention Layer 10 (with all heads) of three models. Although “Mall’ and “Hotel” are in different positions in different corpora, they are successfully recognized by the models. As we have mentioned, the core ability of GeoBERT is to identify the most significant tokens in a grid and capture co-occurrence. These phenomena only appear in the deep attention layers, basically from Layer 9 to Layer 11 (layer index starts at 0).
Figure 20.
Attention mechanism for addition Case 1 in GeoBERT-ShortestPath. "CVS" is the abbreviation for convenience store. In (a), “Guesthouse” obtains attention weights from all other tokens. In (b), there are two “Bus Stations” in a grid, and both attract the most attention. Moreover, the weights for the first “Bus Station” are higher. This difference validates that the sequence order plays a role to some extent: (a) Layer 10, Head 7; (b) Layer 10, Head 8.
Figure 20.
Attention mechanism for addition Case 1 in GeoBERT-ShortestPath. "CVS" is the abbreviation for convenience store. In (a), “Guesthouse” obtains attention weights from all other tokens. In (b), there are two “Bus Stations” in a grid, and both attract the most attention. Moreover, the weights for the first “Bus Station” are higher. This difference validates that the sequence order plays a role to some extent: (a) Layer 10, Head 7; (b) Layer 10, Head 8.
Figure 21.
Attention mechanism for addition Case 2 in GeoBERT-ShortestPath. The phenomenon is evident, and the above two heads each identify an anchor POI, namely “Supermarket” and “Industry Park”: (a) Layer 9, Head 9; (b) Layer 10, Head 3.
Figure 21.
Attention mechanism for addition Case 2 in GeoBERT-ShortestPath. The phenomenon is evident, and the above two heads each identify an anchor POI, namely “Supermarket” and “Industry Park”: (a) Layer 9, Head 9; (b) Layer 10, Head 3.
Table 1.
Quantitative proportion of each first-level POI type in the dataset.
Table 1.
Quantitative proportion of each first-level POI type in the dataset.
| POI Type | Number | Proportions |
|---|
| accommodation | 930,307 | 5.62% |
| enterprise and business | 2,513,793 | 15.18% |
| restaurant | 2,498,107 | 15.09% |
| shopping | 3,603,615 | 21.76% |
| transportation | 1,385,916 | 8.37% |
| life services | 2,515,165 | 15.19% |
| sport and leisure | 865,208 | 5.23% |
| science and education | 725,916 | 4.38% |
| health and medical | 683,560 | 4.13% |
| government | 664,317 | 4.01% |
| public facilities | 171,141 | 1.03% |
| total | 16,557,045 | 100.00% |
Table 2.
Area of each level Geohash cell.
Table 2.
Area of each level Geohash cell.
| Geohash Length (Level) | Cell Length | Cell Width |
|---|
| 1 | ≤5000 km | ≤5000 km |
| 2 | ≤1250 km | ≤625 km |
| 3 | ≤156 km | ≤156 km |
| 4 | ≤39.1 km | ≤19.5 km |
| 5 | ≤4.89 km | ≤4.89 km |
| 6 | ≤1.22 km | ≤0.61 km |
| 7 | ≤153 m | ≤153 m |
| 8 | ≤19.1 m | ≤19.1 m |
Table 3.
Statistics of POI number dataset.
Table 3.
Statistics of POI number dataset.
| Count | Mean | Std | Min | 25% | 50% | 75% | Max |
|---|
| 61,521 | 21.97 | 35.15 | 3 | 4 | 9 | 25 | 883 |
Table 4.
Statistics of working/living area dataset.
Table 4.
Statistics of working/living area dataset.
| Living Area | Working Area | Total |
|---|
| 34,049 | 28,156 | 62,205 |
Table 5.
Statistics of passenger flow dataset.
Table 5.
Statistics of passenger flow dataset.
| Count | Mean | Std | Min | 25% | 50% | 75% | Max |
|---|
| 1,262,380 | 955.16 | 2951.65 | 1 | 13 | 88 | 580 | 649,795 |
Table 6.
Statistics of house price dataset.
Table 6.
Statistics of house price dataset.
| Count | Mean | Std | Min | 25% | 50% | 75% | Max |
|---|
| 412,662 | 624,873 | 54,706 | 3742 | 29,415 | 48,574 | 84,546 | 361,633 |
Table 7.
Statistic of store site recommendation dataset.
Table 7.
Statistic of store site recommendation dataset.
| Positive Samples | Negative Samples | Total |
|---|
| (Suitable for Opening a Store) | (Unsuitable) | |
|---|
| 701 | 1249 | 1950 |
Table 8.
Summary of primary notations.
Table 8.
Summary of primary notations.
| Notations | Description |
|---|
| a level-7 geohash grid |
| 9 (3*3) adjacent grids with in center |
| the number of POI in a grid |
| the final embedding after the merge of GeoBERT and addition features |
| h | the output of the last transformer layer in GeoBERT |
| x | additional features |
| W | a weight matrix for additional features |
| abbreviation for Multilayer Perceptron |
| concate operation |
| R | activation function |
| additional parameters only used in Gating method |
Table 9.
Evaluation on POI number prediction.
Table 9.
Evaluation on POI number prediction.
| Model | MSE | MAE |
|---|
| GeoBERT-CenterDistance | 0.1932 | 0.1492 |
| GeoBERT-ShortestPath | 0.1790 | 0.1343 |
| GeoBERT-RandomPath | 0.1994 | 0.1383 |
| Word2Vec-CenterDistance | 0.2503 | 0.2354 |
| Word2Vec-ShortestPath | 0.2474 | 0.2330 |
| Word2Vec-RandomPath | 0.2659 | 0.2385 |
| GloVe-CenterDistance | 0.3824 | 0.3150 |
| GloVe-ShortestPath | 0.3958 | 0.3147 |
| GloVe-RandomPath | 0.4082 | 0.3225 |
Table 10.
Evaluation on working∖living area prediction.
Table 10.
Evaluation on working∖living area prediction.
| Model | Accuracy | F1-Score |
|---|
| GeoBERT-CenterDistance | 0.7736 | 0.7712 |
| GeoBERT-ShortestPath | 0.7729 | 0.7677 |
| GeoBERT-RandomPath | 0.7739 | 0.7719 |
| Word2Vec-CenterDistance | 0.7642 | 0.7359 |
| Word2Vec-ShortestPath | 0.7626 | 0.7337 |
| Word2Vec-RandomPath | 0.7638 | 0.7344 |
| GloVe-CenterDistance | 0.7398 | 0.7093 |
| GloVe-ShortestPath | 0.7454 | 0.7144 |
| GloVe-RandomPath | 0.7377 | 0.7101 |
Table 11.
Evaluation on passenger flow prediction.
Table 11.
Evaluation on passenger flow prediction.
| Model | MSE | MAE |
|---|
| GeoBERT-CenterDistance | 0.1491 | 0.1825 |
| GeoBERT-ShortestPath | 0.1446 | 0.1809 |
| GeoBERT-RandomPath | 0.1557 | 0.1901 |
| Word2Vec-CenterDistance | 0.2563 | 0.2916 |
| Word2Vec-ShortestPath | 0.2567 | 0.2920 |
| Word2Vec-RandomPath | 0.2569 | 0.2913 |
| GloVe-CenterDistance | 0.3825 | 0.3703 |
| GloVe-ShortestPath | 0.3772 | 0.3651 |
| GloVe-RandomPath | 0.3865 | 0.3700 |
Table 12.
Evaluation on house price prediction.
Table 12.
Evaluation on house price prediction.
| Model | MSE | MAE |
|---|
| GeoBERT-CenterDistance | 0.0574 | 0.1578 |
| GeoBERT-ShortestPath | 0.0556 | 0.1559 |
| GeoBERT-RandomPath | 0.0674 | 0.1724 |
| Word2Vec-CenterDistance | 0.3192 | 0.4177 |
| Word2Vec-ShortestPath | 0.3190 | 0.4182 |
| Word2Vec-RandomPath | 0.3227 | 0.4188 |
| GloVe-CenterDistance | 0.4889 | 0.5079 |
| GloVe-ShortestPath | 0.4935 | 0.5101 |
| GloVe-RandomPath | 0.4945 | 0.5098 |
Table 13.
Evaluation on store site recommendation (POIs only).
Table 13.
Evaluation on store site recommendation (POIs only).
| Model | Accuracy | F1-Score |
|---|
| GeoBERT-CenterDistance | 0.8359 | 0.7922 |
| GeoBERT-ShortestPath | 0.8256 | 0.7777 |
| GeoBERT-RandomPath | 0.8358 | 0.7908 |
| Word2Vec-CenterDistance | 0.7846 | 0.7042 |
| Word2Vec-ShortestPath | 0.8000 | 0.7254 |
| Word2Vec-RandomPath | 0.7821 | 0.6931 |
| GloVe-CenterDistance | 0.6744 | 0.5171 |
| GloVe-ShortestPath | 0.6923 | 0.5455 |
| GloVe-RandomPath | 0.6799 | 0.5039 |
Table 14.
Evaluation on store site recommendation (with additional features).
Table 14.
Evaluation on store site recommendation (with additional features).
| Concat Method | Accuracy | F1-Score |
|---|
| MLP | 0.8564 (+2.45%) | 0.8163 (+3.04%) |
| Gating | 0.8538 (+2.14%) | 0.8119 (+2.49%) |
| Weighted | 0.8436 (+0.92%) | 0.8103 (+2.28%) |
| Concat | 0.8435 (+0.91%) | 0.8000 (+0.98%) |
| POIs Only | 0.8359 (+0.00%) | 0.7922 (+0.00%) |
Table 15.
Ablation over different masking strategies.
Table 15.
Ablation over different masking strategies.
| | Center Distance | Shortest Path | Random Sequence |
|---|
| Mask Ratio | MSE | MAE | MSE | MAE | MSE | MAE |
| 15% | 0.1677 | 0.2065 | 0.1697 | 0.2109 | 0.1713 | 0.2090 |
| 30% | 0.1665 | 0.2066 | 0.1652 | 0.2045 | 0.1718 | 0.2114 |
| 50% | 0.1726 | 0.2108 | 0.1715 | 0.2095 | 0.1716 | 0.2111 |
| 70% | 0.1754 | 0.2132 | 0.1653 | 0.2015 | 0.1763 | 0.2166 |
Table 16.
Example POI sequence for attention visualization.
Table 16.
Example POI sequence for attention visualization.
| Shortest Path |
|---|
| ‘[CLS]’,
‘Teahouse’,
‘Real Estate’,
‘Store’,
‘Restaurant’,
‘Massage’,
‘Express’,
‘Construction’,
‘Chinese Food’,
‘teahouse’,
‘Chinese Food’,
‘Restaurant’,
‘Park’,
‘Mall Store’,
‘Chinese Food’,
‘KTV’,
‘Office’,
‘Office’,
‘Restaurant’,
‘KTV’,
‘Hotel’,
‘Furniture’,
‘Furniture’,
‘[SEP]’ |
| Center Distance Path |
| ‘[CLS]’,
‘Furniture’,
‘Hotel’,
‘Furniture’,
‘KTV’,
‘KTV’,
‘Restaurant’,
‘Teahouse’,
‘Chinese Food’,
‘Chinese Food’,
‘Restaurant’,
‘Chinese Food’,
‘Mall’,
‘Office’,
‘Park’,
‘Construction’,
‘Office’,
‘Express’,
‘Massage’,
‘Restaurant’,
‘Store’,
‘Real Estate’,
‘Teahouse’,
‘[SEP]’ |
| Random Path |
| ‘[CLS]’,
‘Real Estate’,
‘teahouse’,
‘Office’,
‘Hotel’,
‘Teahouse’,
‘Restaurant’,
‘Express’,
‘Massage’,
‘Store’,
‘Office’,
‘Chinese Food’,
‘Furniture’,
‘Park’,
‘Chinese Food’,
‘Chinese Food’,
‘Construction’,
‘Restaurant’,
‘Restaurant’,
‘KTV’,
‘Mall’,
‘Furniture’,
‘KTV’,
‘[SEP]’ |


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}