
Normality in the Distribution of Revealed Comparative Advantage Index for International Trade and Economic Complexity



Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials
2.2. Methods
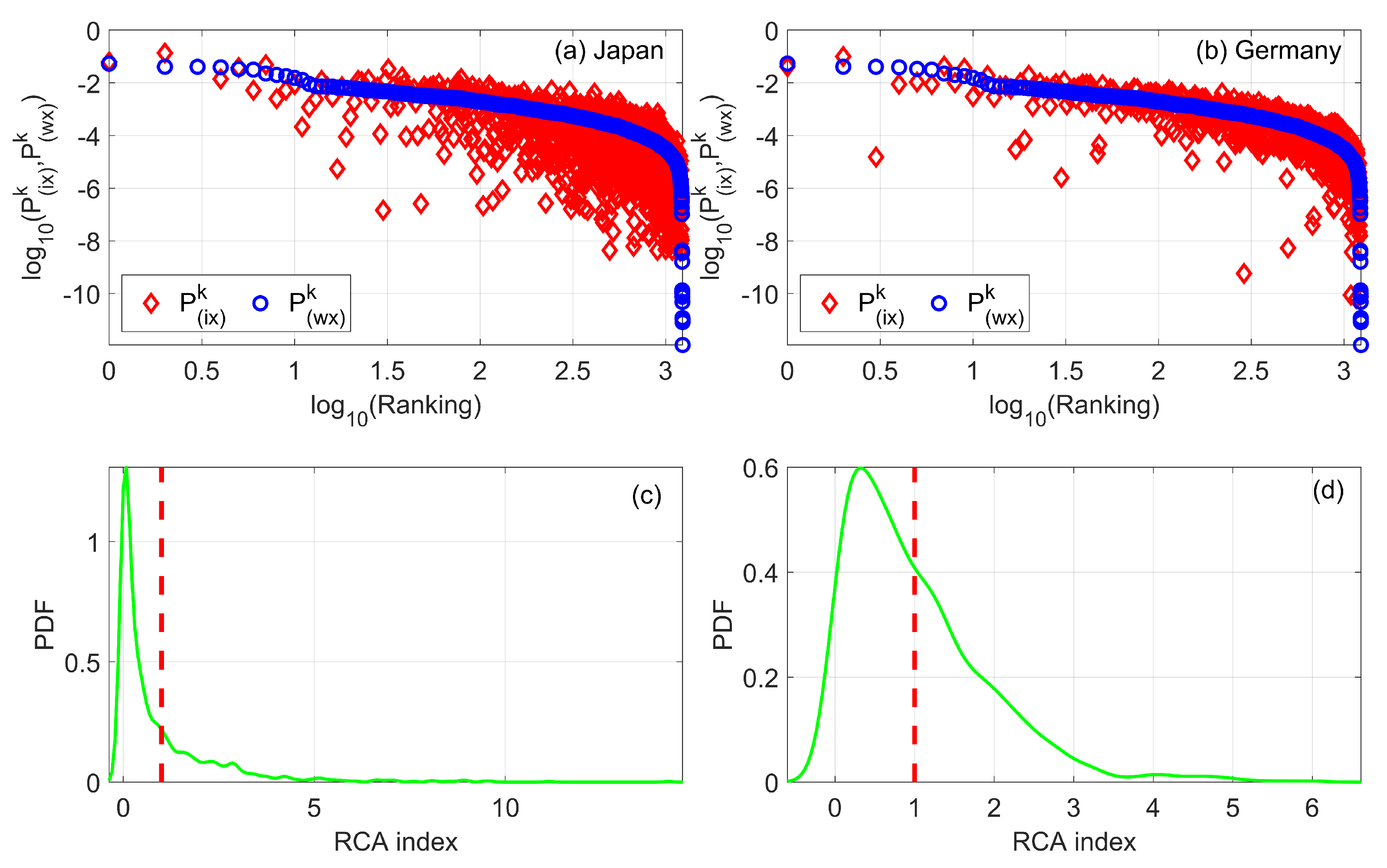
2.2.1. RCA Index
2.2.2. Economic Complexity Index
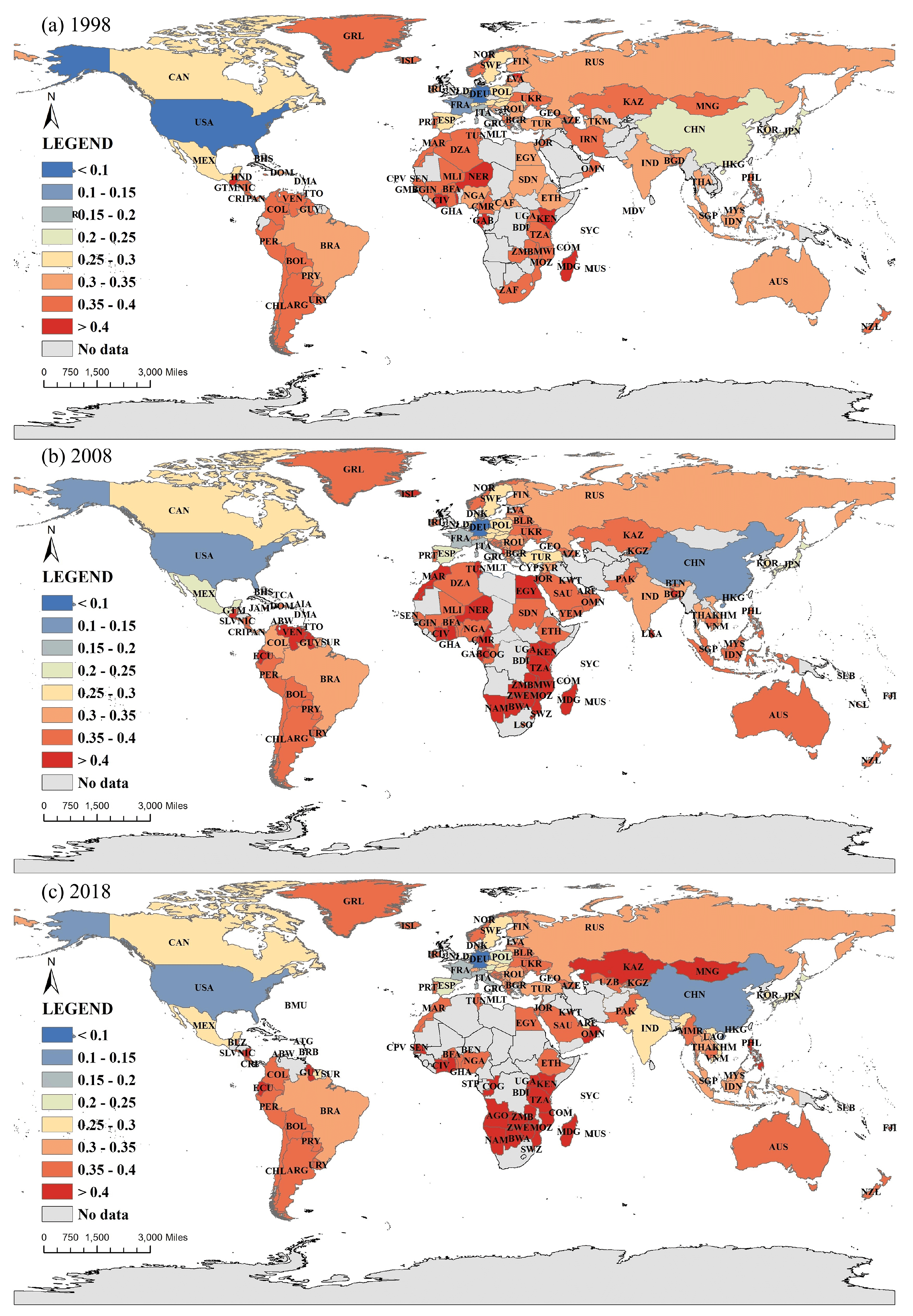
2.2.3. Deviation from Gaussianity Based on KS Test
2.2.4. Pooled OLS and Panel VAR
3. Results
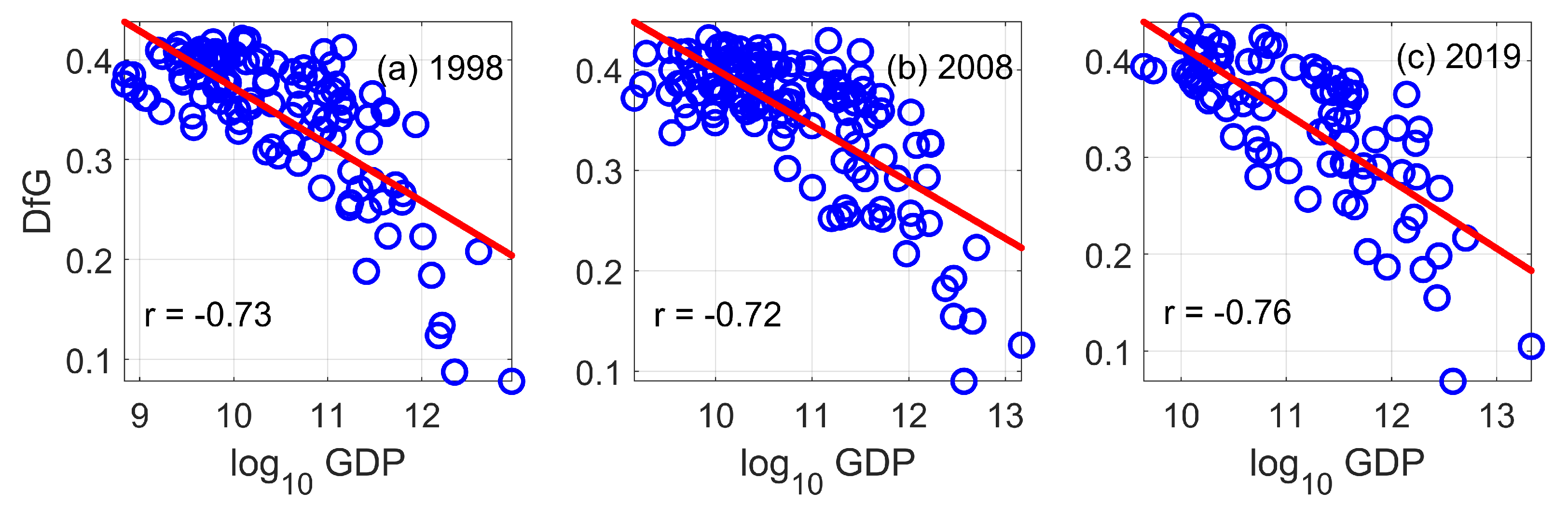
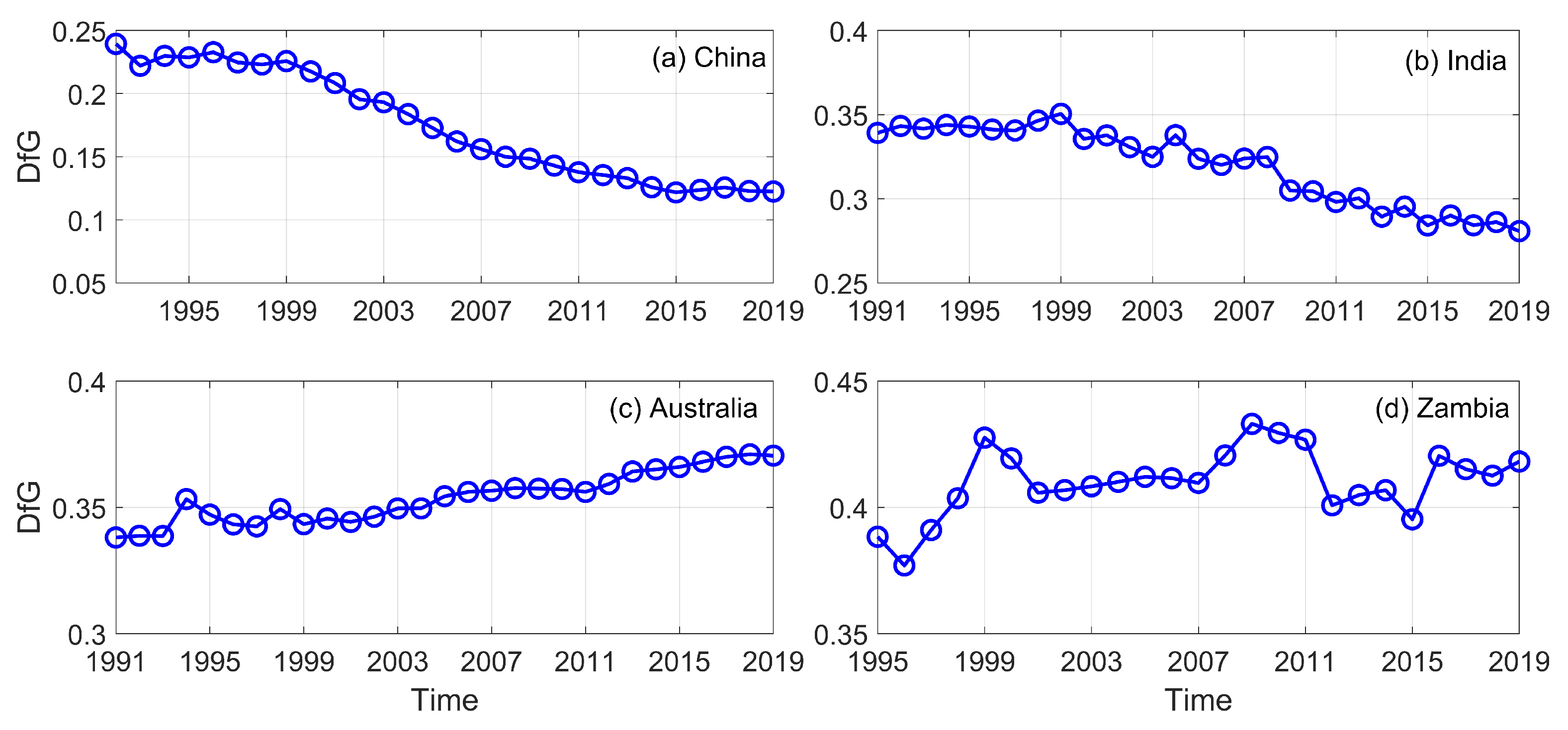
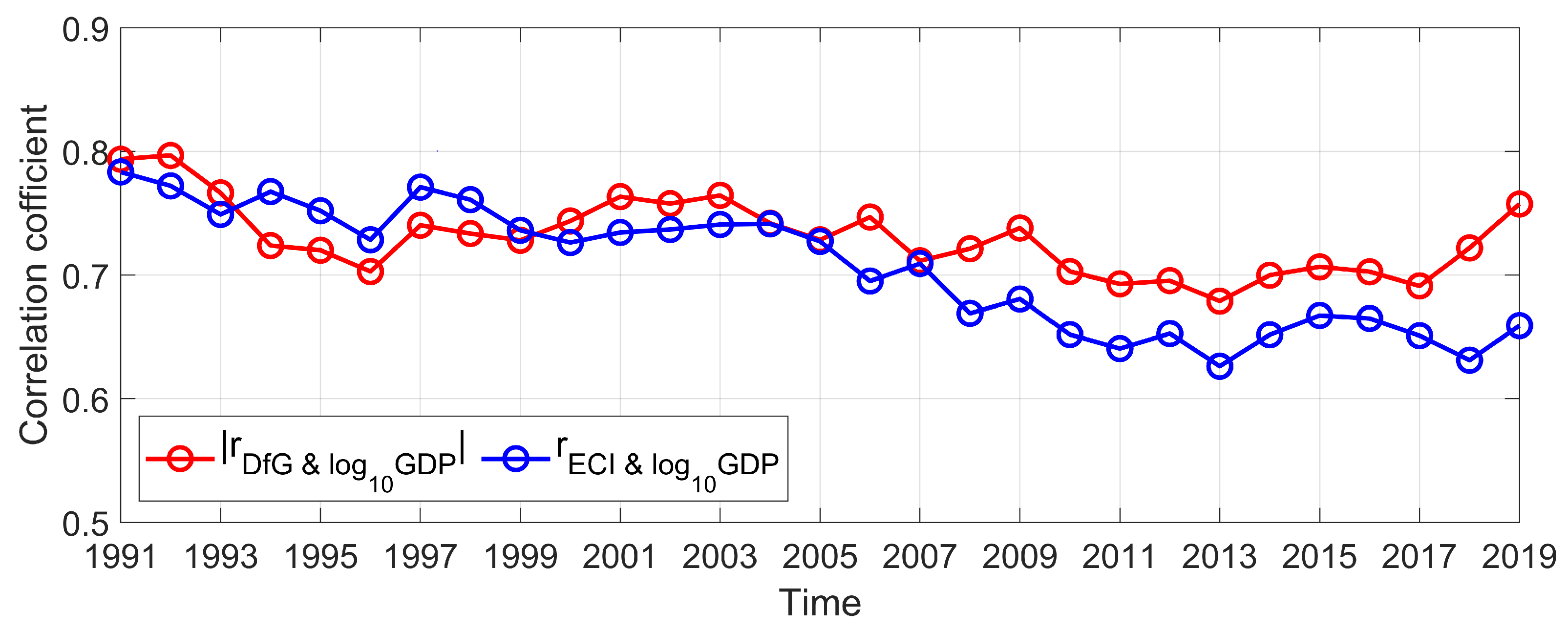
3.1. DfG and Economic Growth
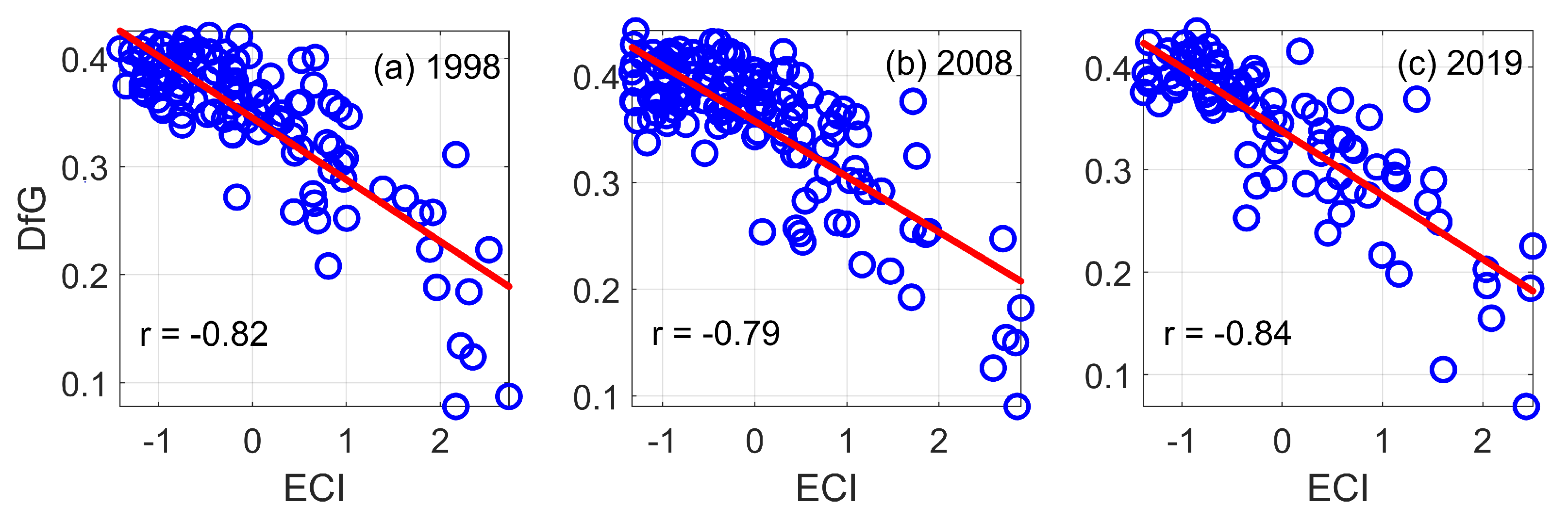
3.2. DfG and Economic Complexity
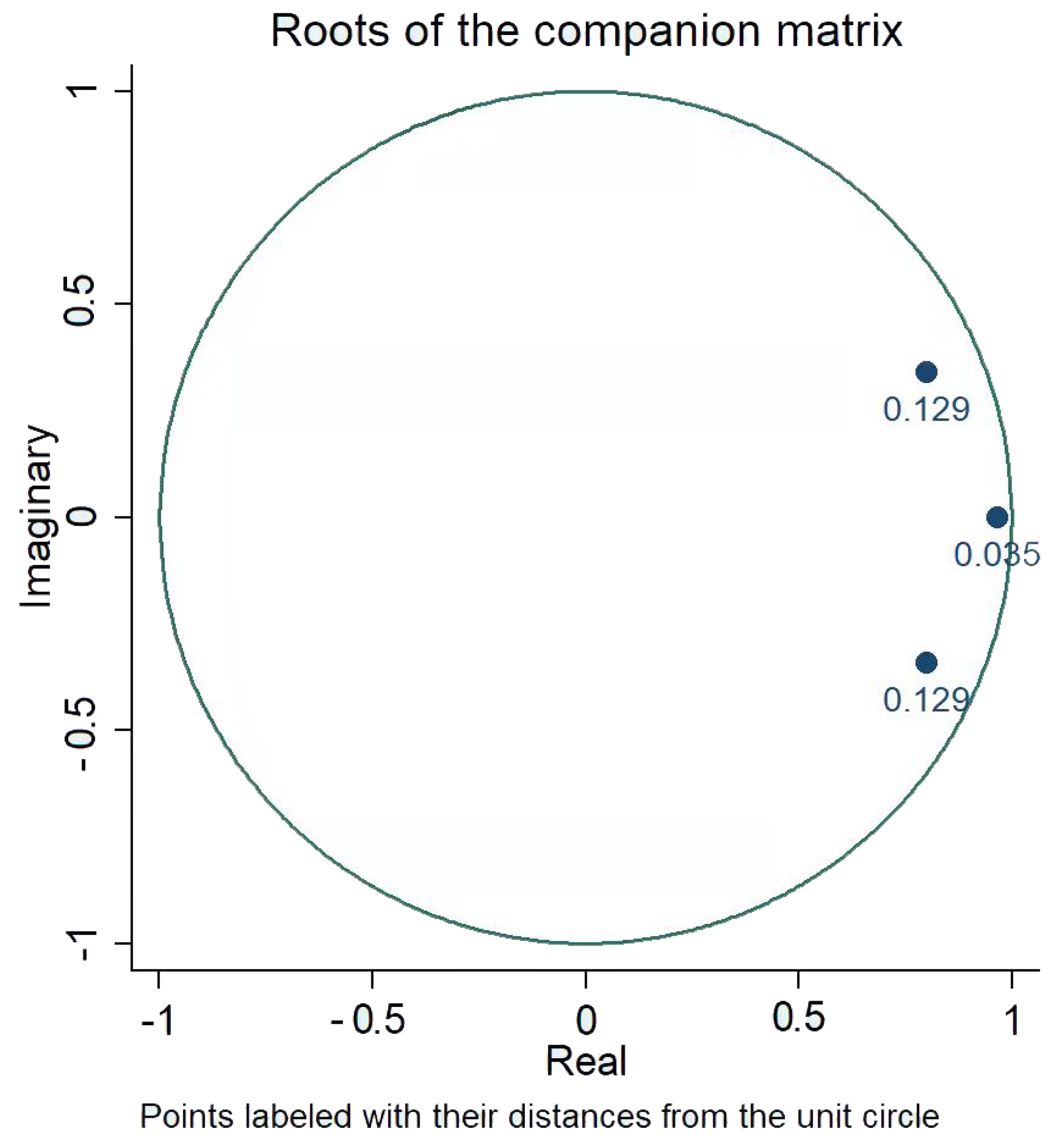
3.3. Regression and Causality Analysis
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Balassa, B. Trade liberalization and ‘revealed’ comparative advantage. Manch. Sch. Econ. Soc. Stud. 1965, 32, 99–123. [Google Scholar] [CrossRef]
- Yeats, A.J. On the Appropriate Interpretation of the Revealed Comparative Advantage Index: Implications of a Methodology based on Industry Sector Analysis. Weltwirtsch. Arch. 1985, 121, 61–73. [Google Scholar] [CrossRef]
- Leromain, E.; Orefice, G. New revealed comparative advantage index: Dataset and empirical distribution. Int. Econ. 2014, 139, 48–70. [Google Scholar] [CrossRef]
- Hoen, A.R.; Oosterhaven, J. On the measurement of comparative advantage. Ann. Reg. Sci. 2006, 40, 677–691. [Google Scholar] [CrossRef] [Green Version]
- Yu, R.; Cai, J.; Leung, P. The normalized revealed comparative advantage index. Ann. Reg. Sci. 2009, 43, 267–282. [Google Scholar] [CrossRef]
- Hinloopen, J.; Marrewijk, C.V. On the empirical distribution of the Balassa index. Weltwirtsch. Arch. 2001, 137, 1–35. [Google Scholar] [CrossRef] [Green Version]
- De Benedictis, L.; Tamberi, M. Overall specialization empirics: Techniques and applications. Open Econ. Rev. 2004, 15, 323–346. [Google Scholar] [CrossRef]
- Bowen, H.P. On the Theoretical Interpretation of Indices of Trade Intensity and Revealed Comparative Advantage. Weltwirtsch. Arch. 1983, 119, 464–472. [Google Scholar] [CrossRef]
- Laursen, K. Revealed comparative advantage and the alternatives as measures of international specialization. Eurasian Bus. Rev. 2015, 5, 99–115. [Google Scholar] [CrossRef]
- Deb, K.; Sengupta, B. On empirical distribution of RCA Indices. IIM Kozhikode Soc. Manag. Rev. 2017, 6, 23–41. [Google Scholar] [CrossRef] [Green Version]
- Vollrath, T.L. A Theoretical Evaluation of Alternative Trade Intensity Measures of Revealed Comparative Advantage. Weltwirtsch. Arch. 1991, 127, 265–280. [Google Scholar] [CrossRef]
- Dalum, B.; Laursen, K.; Villumsen, G. Structural change in OECD export specialisation patterns: De-specialisation and ‘stickiness’. Int. Rev. Appl. Econ. 1998, 12, 423–443. [Google Scholar] [CrossRef]
- Proudman, J.; Redding, S. Evolving patterns of international trade. Rev. Int. Econ. 2000, 8, 373–396. [Google Scholar] [CrossRef] [Green Version]
- Amador, J.; Cabral, S.; Maria, J.R. A simple cross-country index of trade specialization. Open Econ. Rev. 2011, 22, 447–461. [Google Scholar] [CrossRef]
- Jenny, P.D.B.; Rémi, S. A New Class of Revealed Comparative Advantage Indexes. Open Econ. Rev. 2021, 1–27. [Google Scholar] [CrossRef]
- Liu, B.; Gao, J.B. Understanding the non-Gaussian distribution of revealed comparative advantage index and its alternatives. Int. Econ. 2019, 158, 1–11. [Google Scholar] [CrossRef]
- Hidalgo, C.A.; Klinger, B.; Barabási, A.L.; Hausmann, R. The product space conditions the development of nations. Science 2007, 317, 482–487. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hidalgo, C.; Hausmann, R. The building blocks of economic complexity. Proc. Natl. Acad. Sci. USA 2009, 106, 10570–10575. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mealy, P.; Farmer, J.D.; Teytelboym, A. Interpreting economic complexity. Sci. Adv. 2019, 5, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Andrea, T.; Mazzilli, D.; Pietronero, L. A dynamical systems approach to gross domestic product forecasting. Nat. Phys. 2018, 14, 861–865. [Google Scholar]
- Gao, J.; Zhang, Y.C.; Zhou, T. Computational socioeconomics. Phys. Rep. 2019, 817, 1–104. [Google Scholar] [CrossRef] [Green Version]
- Tacchella, A.; Cristelli, M.; Caldarelli, G.; Gabrielli, A.; Pietronero, L. A new metrics for countries’ fitness and products’ complexity. Sci. Rep. 2012, 2, 723. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tacchella, A.; Cristelli, M.; Caldarelli, G.; Gabrielli, A.; Pietronero, L. Economic complexity: Conceptual grounding of a new metrics for global competitiveness. J. Econ. Dynam. Control 2013, 37, 1683–1691. [Google Scholar] [CrossRef]
- Caldarelli, G.; Cristelli, M.; Gabrielli, A.; Pietronero, L.; Scala, A.; Tacchella, A. A network analysis of countries’ export flows: Firm grounds for the building blocks of the economy. PLoS ONE 2012, 7, e47278. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cristelli, M.; Gabrielli, A.; Tacchella, A.; Caldarelli, G.; Pietronero, L. Measuring the intangibles: A metrics for the economic complexity of countries and products. PLoS ONE 2013, 8, e70726. [Google Scholar] [CrossRef] [Green Version]
- Battiston, F.; Cristelli, M.; Tacchella, A.; Pietronero, L. How metrics for economic complexity are affected by noise. Complex. Econ. 2014, 3, 1–22. [Google Scholar]
- Mariani, M.S.; Vidmer, A.; Medo, M.; Zhang, Y.C. Measuring economic complexity of countries and products: Which metric to use? Eur. Phys. J. B 2015, 88, 293. [Google Scholar] [CrossRef]
- Wu, R.J.; Shi, G.Y.; Zhang, Y.C.; SebastianMariani, M. The mathematics of non-linear metrics for nested networks. Phys. A 2016, 460, 254–269. [Google Scholar] [CrossRef] [Green Version]
- Felipe, J.; Kumar, U.; Abdon, A.; Bacate, M. Product complexity and economic development. Struct. Chang. Econ. Dyn. 2012, 23, 36–68. [Google Scholar] [CrossRef] [Green Version]
- Poncet, S.; Waldemar, F.S.D. Export upgrading and growth: The prerequisite of domestic embeddedness. World Dev. 2013, 51, 104–118. [Google Scholar] [CrossRef] [Green Version]
- Hausmann, R.; Hidalgo, C. The Atlas of Economic Complexity: Mapping Paths to Prosperity; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Zhu, S.; Yu, C.; He, C. Export structures, income inequality and urban-rural divide in China. Appl. Geogr. 2020, 115, 102150. [Google Scholar] [CrossRef]
- Neagu, O.; Teodoru, M.C. The relationship between economic complexity, energy consumption structure and greenhouse gas emission: Heterogeneous panel evidence from the EU countries. Sustainability 2019, 11, 497. [Google Scholar] [CrossRef] [Green Version]
- Romero, J.P.; Gramkow, C. Economic complexity and greenhouse gas emissions. World Dev. 2021, 139, 105317. [Google Scholar] [CrossRef]
- Lapatinas, A. Economic complexity and human development: A note. Econ. Bull. 2016, 366, 1441–1452. [Google Scholar]
- Vu, T.V. Economic complexity and health outcomes: A global perspective. Soc. Sci. Med. 2020, 265, 113480. [Google Scholar] [CrossRef] [PubMed]
- Hartmann, D.; Guevara, M.R.; Jara-Figueroa, C.; Manuel, A.; Hidalgo, C.A. Linking economic complexity, institutions, and income inequality. World Dev. 2017, 93, 75–93. [Google Scholar] [CrossRef] [Green Version]
- Chavez, J.C.; Marco, T.M.; Manuel, G.Z. Economic complexity and regional growth performance: Evidence from the Mexican Economy. Rev. Reg. Stud. 2017, 47, 201–219. [Google Scholar] [CrossRef]
- Gao, J.; Zhou, T. Quantifying China’s regional economic complexity. Phys. A Stat. Mech. Its Appl. 2018, 492, 1591–1603. [Google Scholar] [CrossRef] [Green Version]
- Fritz, B.S.; Robert, A.M. The economic complexity of US metropolitan areas. Reg. Stud. 2021, 1–12. [Google Scholar] [CrossRef]
- Hidalgo, C.A. Economic complexity theory and applications. Nat. Rev. Phys. 2021, 3, 92–113. [Google Scholar] [CrossRef]
- Stojkoski, V.; Utkovski, Z.; Kocarev, L. The impact of services on economic complexity: Service sophistication as route for economic growth. PLoS ONE 2016, 11, e0161633. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wooldridge, J.M. Selection corrections for panel data models under conditional mean independence assumptions. J. Econom. 1995, 68, 115–132. [Google Scholar] [CrossRef]
- Wooldridge, J.M. Econometric Analysis of Cross Section and Panel Data; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Love, I.; Zicchino, L. Financial development and dynamic investment behavior: Evidence from panel VAR. Q. Rev. Econ. Financ. 2006, 46, 190–210. [Google Scholar] [CrossRef]
- Koutsomanoli-Filippaki, A.; Mamatzakis, E. Performance and Merton-type default risk of listed banks in the EU: A panel VAR approach. J. Bank. Financ. 2009, 33, 2050–2061. [Google Scholar] [CrossRef] [Green Version]
- Levin, A.; Lin, C.F.; Chu, C.S.J. Unit root tests in panel data: Asymptotic and finite-sample properties. J. Econom. 2002, 108, 1–24. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Model 1–3 (1996–2019) | Model 4–6 (1996–2007) | Model 7–9 (2008–2019) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ln GDP | ln GDP | ln GDP | ln GDP | ln GDP | ln GDP | ln GDP | ln GDP | ln GDP | |
| DfG | −18.97 *** (−43.95) | −15.04 *** (−21.29) | −19.78 *** (−33.74) | −13.65 *** (−14.34) | −18.48 *** (−33.05) | −16.88 *** (−14.34) | |||
| ECI | 1.26 *** (34.78) | 0.37 *** (6.95) | 1.43 *** (29.2) | 0.58 *** (7.98) | 1.11 *** (22.73) | 0.14 ** (2.16) | |||
| Constant | 31.94 *** (221.73) | 25.16 *** (593.36) | 30.48 *** (120.6) | 31.75 *** (163.24) | 24.67 *** (442.62) | 29.49 *** (86.8) | 32.22 *** (171.91) | 25.64 *** (437.45) | 31.64 *** (96.43) |
| Observations | 1440 | 1440 | 1440 | 720 | 720 | 720 | 720 | 720 | 720 |
| Adjusted | 0.573 | 0.457 | 0.587 | 0.623 | 0.543 | 0.645 | 0.603 | 0.418 | 0.605 |
| F-Statistics | 1931.66 | 1209.56 | 1021.59 | 1138.19 | 852.59 | 650.51 | 1092.18 | 516.62 | 551.22 |
| Prob > F | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Response of | Response to | ||
|---|---|---|---|
| 0.961 *** (130.16) | −0.313 (−1.40) | 0.027 (0.6) | |
| −0.008 *** (−7.96) | 0.734 *** (24.23) | 0.027 *** (4.41) | |
| 0.292 *** (15.10) | −4.864 *** (−8.31) | 0.874 *** (7.43) | |
| Observations | 1440 | ||
| N countries | 60 | ||
| Hypothesis | chi2 | df | Prob > chi2 |
|---|---|---|---|
| ln GDP does not Granger cause DfG | 1.971 | 1 | 0.160 |
| ln GDP does not Granger cause ECI | 0.365 | 1 | 0.546 |
| DfG does not Granger cause ln GDP | 63.338 | 1 | 0.000 *** |
| DfG does not Granger cause ECI | 19.434 | 1 | 0.000 *** |
| ECI does not Granger cause ln GDP | 227.91 | 1 | 0.000 *** |
| ECI does not Granger cause DfG | 69.104 | 1 | 0.000 *** |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Gao, J. Normality in the Distribution of Revealed Comparative Advantage Index for International Trade and Economic Complexity. Appl. Sci. 2022, 12, 1125. https://doi.org/10.3390/app12031125
Liu B, Gao J. Normality in the Distribution of Revealed Comparative Advantage Index for International Trade and Economic Complexity. Applied Sciences. 2022; 12(3):1125. https://doi.org/10.3390/app12031125
Chicago/Turabian StyleLiu, Bin, and Jianbo Gao. 2022. "Normality in the Distribution of Revealed Comparative Advantage Index for International Trade and Economic Complexity" Applied Sciences 12, no. 3: 1125. https://doi.org/10.3390/app12031125
APA StyleLiu, B., & Gao, J. (2022). Normality in the Distribution of Revealed Comparative Advantage Index for International Trade and Economic Complexity. Applied Sciences, 12(3), 1125. https://doi.org/10.3390/app12031125