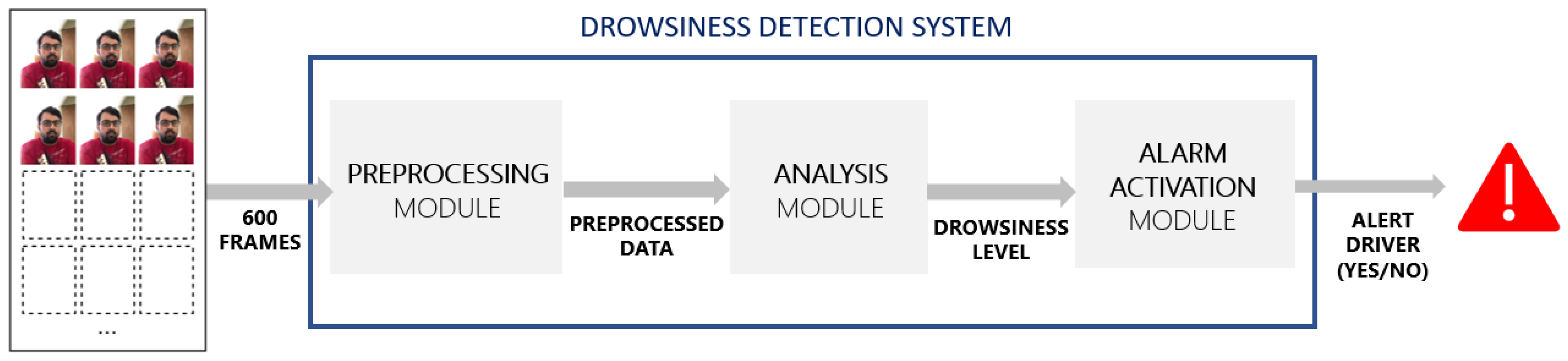
This section presents a complete analysis of the results obtained by both alternatives, including the limitations of the results and a comparison with the state of the art, some problems detected at the preprocessing module, and possible future improvements to the system that are identified.
5.1. Analysis and Limitations of the Results
After analyzing the results obtained, we can conclude that, even though both systems have potential, they are not ready for installation on the ADAS of a real vehicle. The accuracy of both systems is insufficient, especially on the test data, so they must be revised and improved.
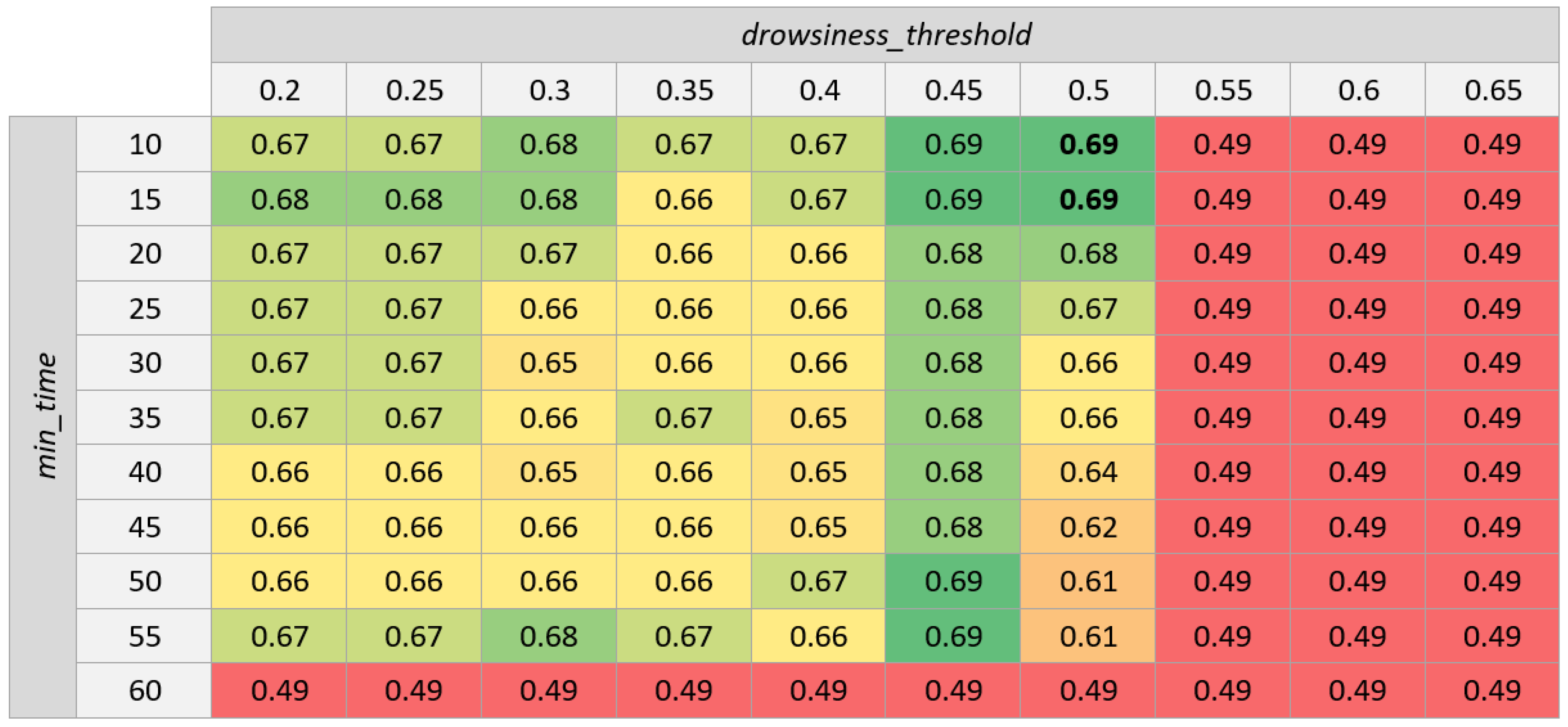
Both alternatives reached a similar accuracy: around 65% on training data and 55–65% on test data. This results are quite poor considering that we are only classifying two balanced classes (awake and drowsy), since a random classifier should obtain an accuracy of 50% and our system only sightly improves that number.
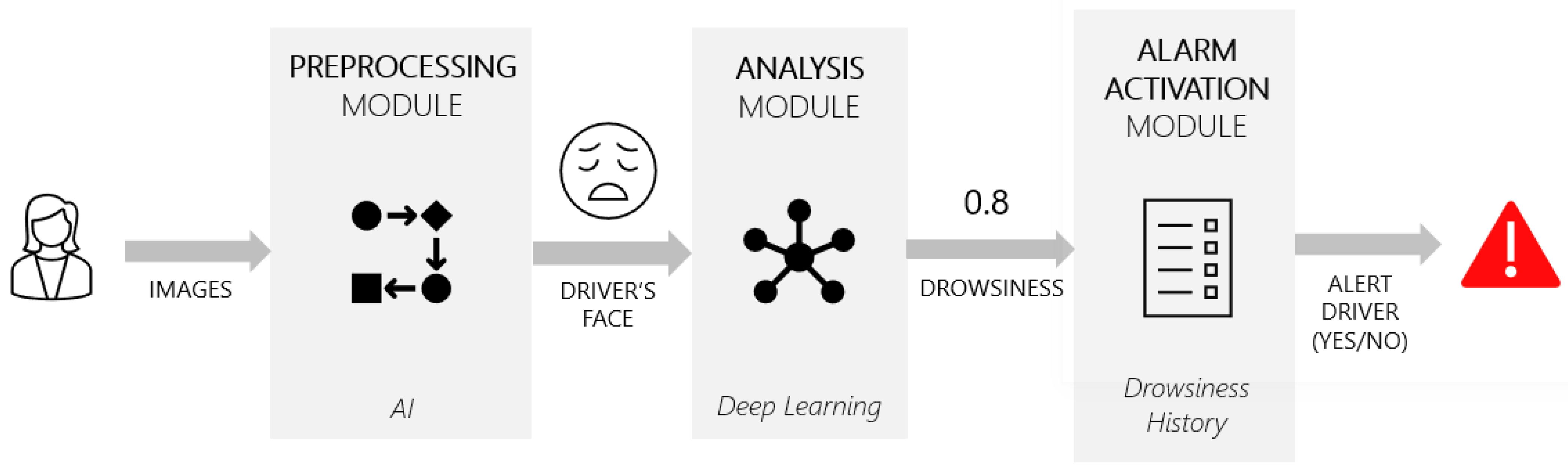
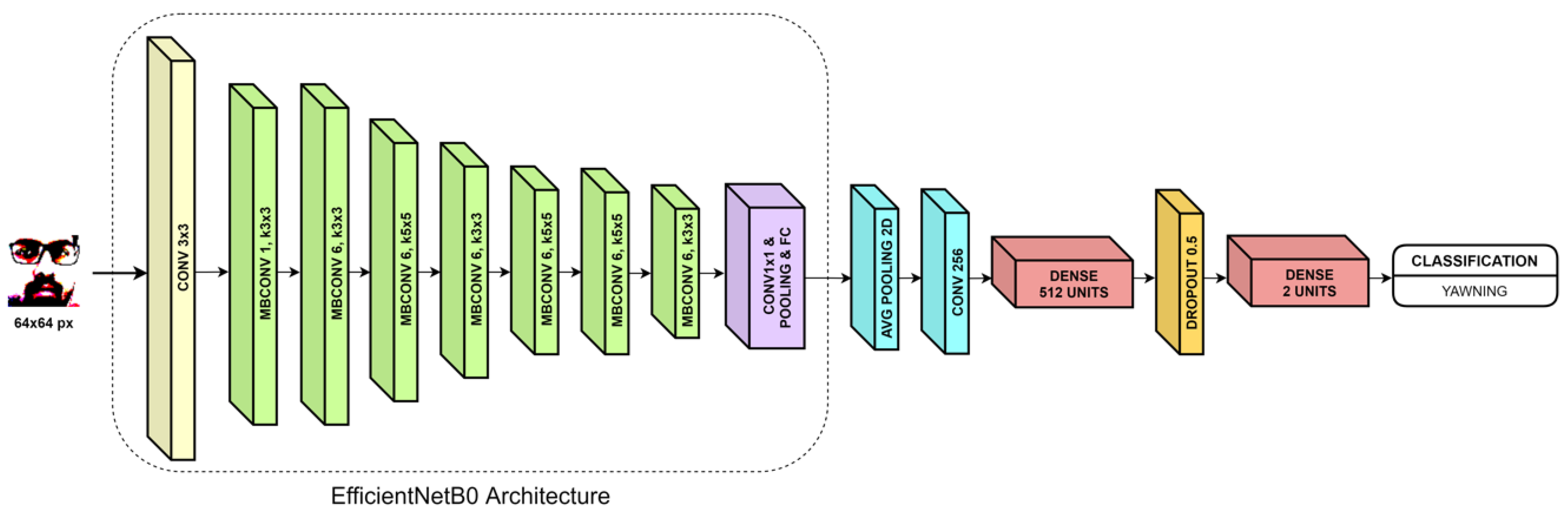
Even thought the results are similar, Alternative I falls behind Alternative II because it raises too many false positives to be tolerable to the driver. Until the false positive rate is minimized, this alternative cannot be considered for implementation in real driving environments. Since this solution uses a neural network that learns by itself the characteristics of data, to improve this results, it is necessary to tune the training parameters or even the architecture of the network used.
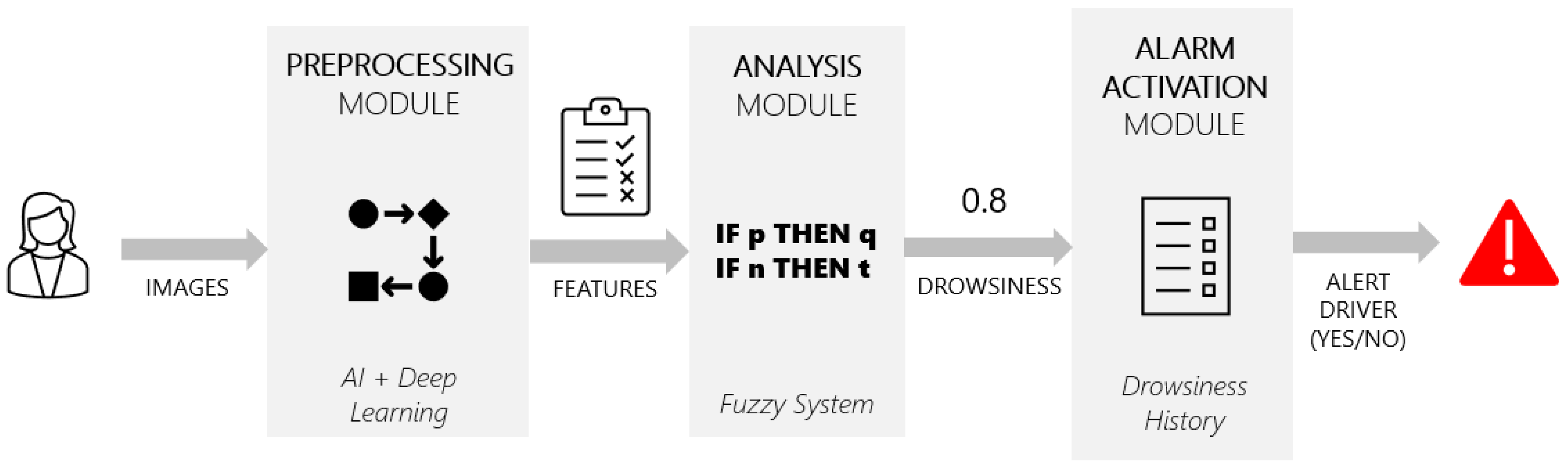
However, the results obtained by Alternative II, which uses deep learning combined with fuzzy logic, are promising, since it minimizes the number of false positives. From the 60 videos (around 10 h of video) where the driver was completely alert, the system only raised an alarm on 4 of them, so it stands as a reliable system that will not bother the driver with unnecessary alarms. Its precision while detecting actual fatigue is inferior to Alternative I, but we are working on improvements to the fuzzy inference system that will make the system capable of detecting more drowsy situations.
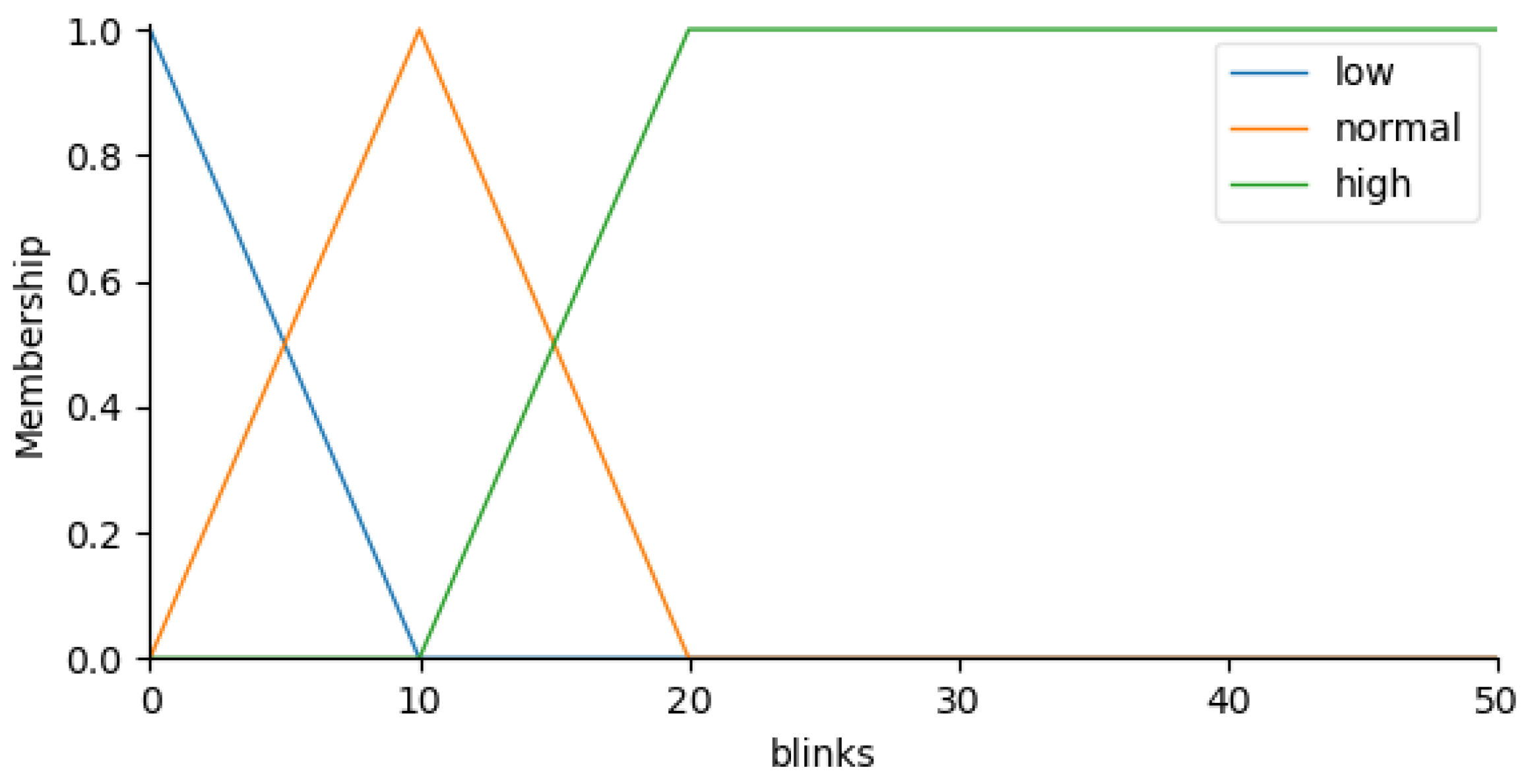
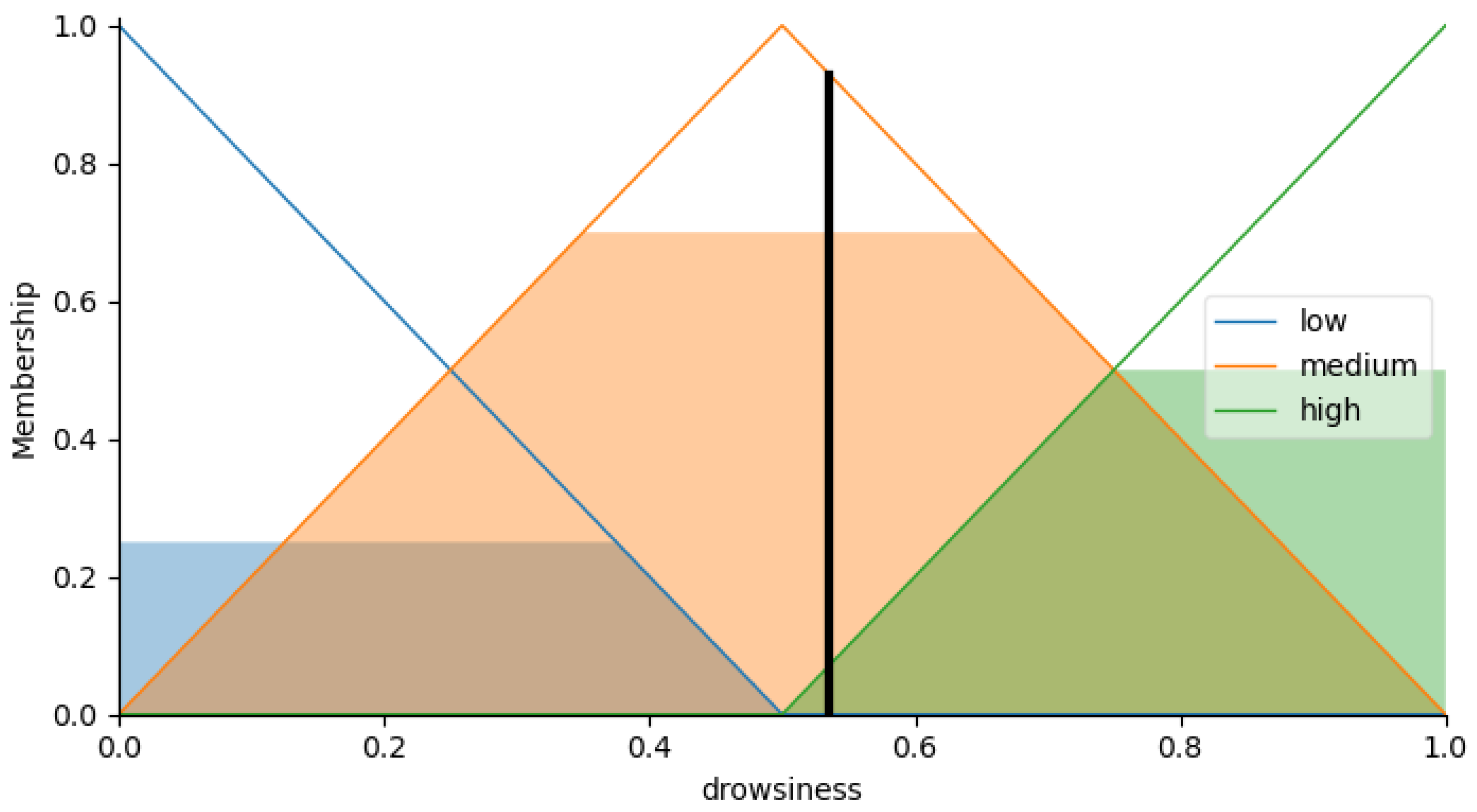
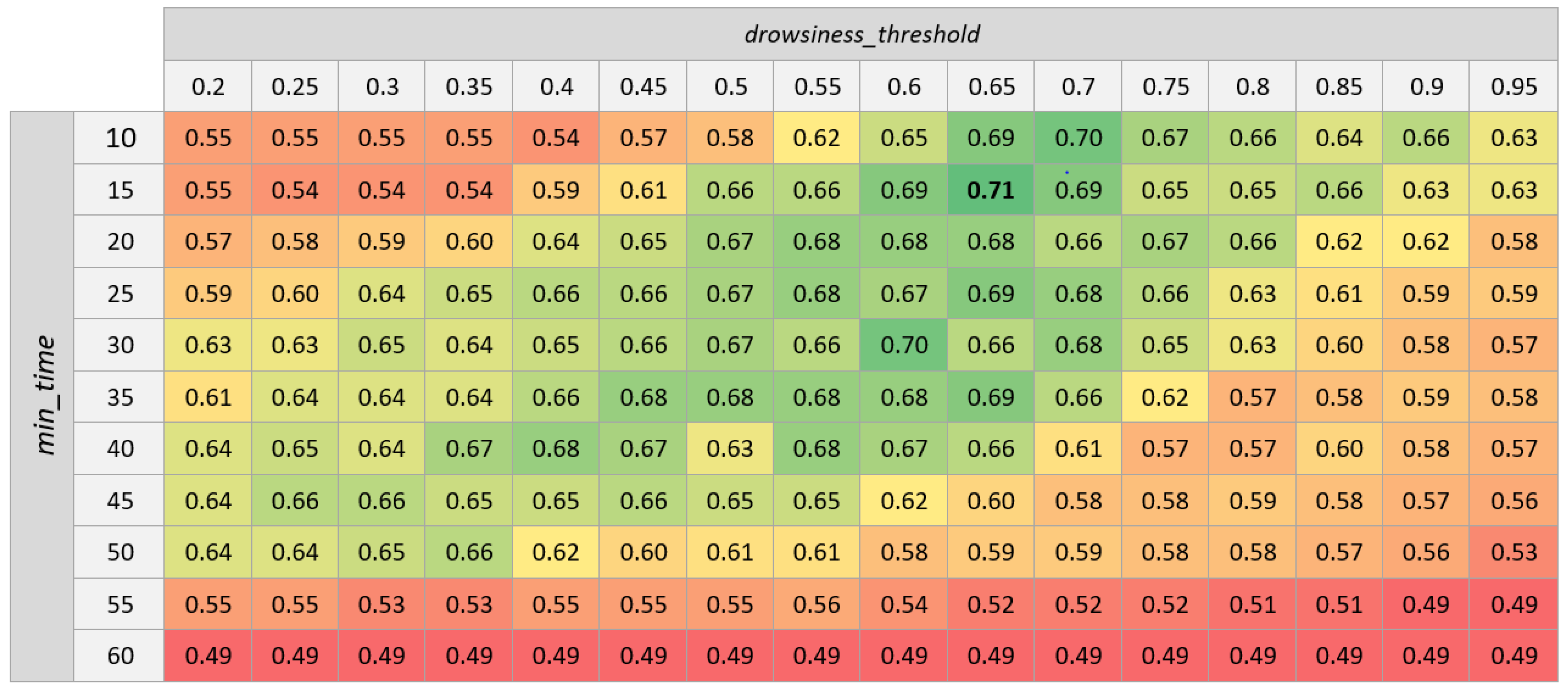
Apart from the accuracy, another aspect that requires analysis for future versions of the system is the value of parameters and . This value remains relatively stable among the tests performed ( is in the range of [0.50, 0.65] or [0.45, 0.50] depending on the alternative, while is usually in the range of [0.10, 0.15]), but there are some outliers among the results of the different folds, and the tests performed are insufficient for choosing the best value.
Because of this, more tests are necessary to obtain the best combination of parameters for which it could be beneficial to use other databases and a cross validation that considers more folds (e.g., using 10 folds instead of 5). By comparing the best performing combinations of each of those tests, we will be able to determine values that work almost universally.
5.2. Comparison with Systems of the State of the Art
Unfortunately, currently there are not a lot of works where the UTA-RLDD dataset is used, so we are limited when comparing our work to a baseline. The most relevant works at this moment are [
22,
23,
36,
37,
38,
39,
40,
41,
42].
In the majority of the works available, the experimentation methodology differs from ours: they extract and classify individual frames from each video and verify whether the classification was correct or not, while we test our systems over the full videos and count the number of alarms raised during each video. Therefore, and although the evaluation of our system is described in terms of videos classified as awake or drowsy, technically the system does not classify the videos, but rather counts the number of alarms raised by the alarm activation module during each video and considers that the system detects the driver as “awake” when it does not raise any alarm and “drowsy” when it raises at least one. Because of this, some works are not exactly comparable, but it is interesting to check their results nevertheless.
It is also important to note that UTA-RLDD provides videos classified in three categories (awake, low vigilant, and drowsy). Some works use all categories, while others perform the classification using only two of the labels (awake and drowsy, as in this work), which is relevant when evaluating results and comparing systems.
A summary of the results collected in some of the works that use the UTA-RLDD database is shown in
Table 11. As we have mentioned before, we consider that avoiding false positives is critical in this domain, so that drivers do not turn off the alert system. Because of this, besides the global accuracy, we also compare the false positives rate, when possible. It is worth noting that after thoroughly revising the related works, we verified that the false positive rate is only available in Refs. [
22] (where three classes are used) and [
36,
41,
42] (where two classes are used, but classification is performed using frames instead of videos).
In [
22], the work where the UTA-RLDD was presented, four methods are used to classify videos as one of the three available categories. These methods obtain global accuracies between 57% and 65%, and the model that obtains the highest accuracy is the HM-LTSM network, with 65.20% accuracy. The accuracy on awake and drowsy videos is high, reaching a notable 80% in both categories. Although these results are very positive, false alarms would be raised in 19% of the cases, so the system could be improved to reduce this rate.
It is also interesting to analyze their comparison to a human judgment baseline, in which four volunteers classified the drowsiness level of each video. Human judgment reached a 57.8% accuracy, which is closer to the accuracy obtained by our systems. It makes sense that the fuzzy logic-based system approaches the accuracy obtained by human judgment, since the variables and the rules defined are based on the expert knowledge of humans. The false positive rate is higher, however, while using human judgment, and alerts the driver unnecessarily in 37% of the cases.
In [
36], they use the categories “awake” and “drowsy”, like our system, leaving out the “low-vigilant” videos. In this case, the authors use around 100–120 images per recording. The model chosen for the fatigue detection task is a simple CNN created from scratch that combines five convolutional layers with a flatten layer and a dense layer. Although the global accuracy on the test images reaches 69%, this model cannot be considered for a real implementation on an ADAS because of the high rate of false positives (56% of the images tested).
It might be noted that, according to the author’s code, the random train/test split (80% train/20% test) of data was performed after extracting the images. Because of this, the accuracy might have been affected if frames extracted from the same video were used both in train and in test sets. Since every video is recorded under different conditions, the network could be learning to recognize the situation that is shown at a particular frame (person, angle, illumination), instead of recognizing the fatigue of the subject.
In [
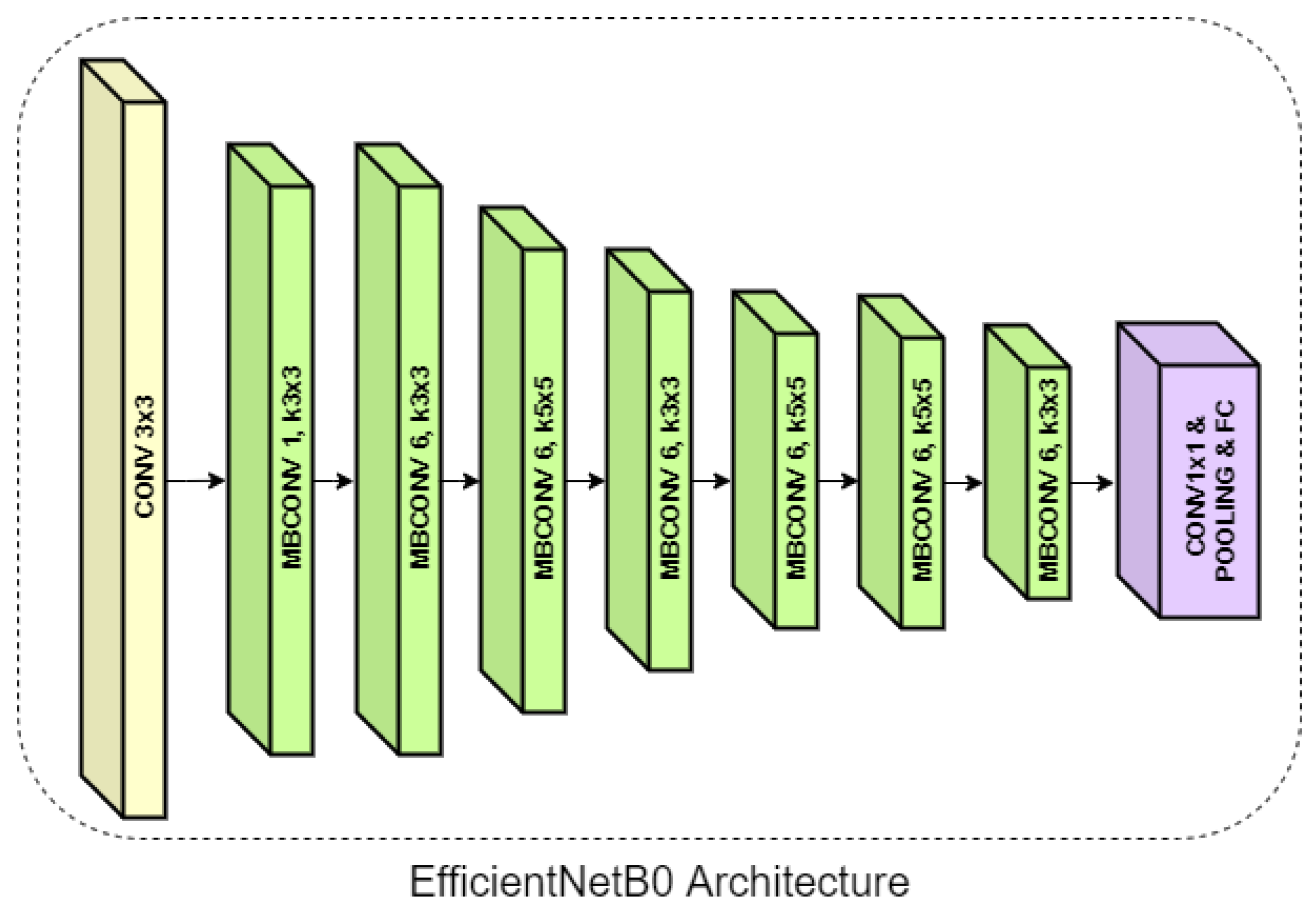
38], the authors present two CNNs trained to classify individual frames and predict whether the driver is drowsy or awake. One of the CNNs is created from scratch with three convolutional layers and one fully connected layer, and one is based on the AlexNet architecture [
7], where they apply transfer learning. The CNN created from scratch obtains slightly better results, reaching a notable 96% accuracy.
To test the CNNs, they use videos from 28 out of the 60 subjects available at UTA-RLDD dataset, gathering around 55,000 frames. The authors mention that they use 70% of the data for training and 30% for testing, but there are no details on how the separation is done, so it is possible that it presents the same problem explained in the previous case.
In [
23], they use the UTA-RLDD dataset to train and test a CNN inspired by LeNet architecture [
39] to detect fatigue in drivers. They also use the “awake” and “drowsy” videos, and their methodology is to classify a randomly generated frame of each video. The accuracy of the model is assessed using stratified five-fold cross validation and, according to the authors, in each fold, there are about 152 sleepy samples and about 151 vigilant samples. However, since there is no indication about if the training and test sets share frames from the same video, it is possible that it presents the same problems as [
36,
38].
This way, it is reported an accuracy of 91.8% when classifying a single frame, much higher than the accuracy obtained by our systems when raising alarms on the full videos. In that same work, they also use an implementation of [
43], which uses multiple CNNs to classify fatigue, over UTA-RLDD. In this case, the accuracy reaches 63%, which is more similar to the results reported by our systems.
In [
37], the authors use the FaceNet CNN [
44] to extract facial features from the drivers’ images, and then use either a multiclass SVM or a K-NN to classify those features into one of the three categories of the UTA-RLDD dataset. The accuracy obtained by both systems is high: the multiclass SVM reaches a 89% accuracy when classifying individual frames, while the K-NN outperforms it with a 94% accuracy. They use a total of 3000 images to train the models and another 300 images to validate them, but it is unknown to what videos these images belong or how they were selected.
In [
40], the authors combine convolutional neural networks and long short-term memory for fatigue detection. The proposed hybrid architecture is trained and evaluated on a relabeled dataset that combines multiple datasets, including UTA-RLDD, and classifies their videos into three classes: “alert”, “low vigilant”, and “fatigue”. The relabeling process is performed at two levels: at the frame level (each frame is classified as one of the three categories) and at the minute level (each minute is classified).
The accuracy obtained by this architecture is 54.71% on frame segment cases, and 43.05% on minute segment cases. According to the authors, unlike other databases, UTA-RLDD contains subtle facial features that are difficult to capture through the training process. This could explain the low accuracy values obtained.
In [
41], authors compare a CNN and a LSTM that evaluate drowsiness driver detection on UTA-RLDD dataset. Dlib’s pretrained face detector is used for detecting landmarks of eyes and mouth and extracting the eye aspect ratio (EAR), mouth aspect ratio (MAR), mouth over eye aspect ratio (MOEAR) and pupil circularity (PC). After extracting these four features, the data of all participants are merged and a new dataset is created. In total, 75% of the data are used to train the models, and the remaining 25% are used to test these models. The overall accuracy obtained by the LSTM network is 0.64, and that obtained by CNN is 0.72. As in [
36], the system accuracy may be affected by the fact that images from the same video are used in both the training and test sets. In addition, the false positive rate of both systems is around 22%, which makes them unsuitable for implementation in an ADAS.
In [
42], the authors use a LSTM that receives facial features (changes in eyes and mouth movements) as input data to predict fatigue. In this work, the dataset used to model the system include frames from alert and drowsy videos of only 16 participants. In this case, the training of the model is performed by applying a cross-validation process that uses 74% of the data. Once the cross validation is completed, the best performing model is chosen as the final model. According to the authors, the accuracy (63%) and true positive rate (70%) achieved by the system are not satisfactory. Their argument is that facial landmark data are not sufficient to make a reliable prediction and that other characteristics, such as body temperature and heart rate, should be used to make a reliable prediction. The false positive rate of this system (0.48) is also not tolerable in a real driving environment.
Overall, the models that reach the highest accuracy (around 90%) are those who use CNNs to classify individual frames extracted from the videos. Even though these results are positive and promising, we consider that it would be necessary to evaluate its performance over the full duration of the videos, as is done in [
22] and in this work, to guarantee that false alarms are not raised. Since some of the works compared do not describe exhaustively the split process of training and testing samples, it would be necessary to revise that the systems recognize fatigue symptoms and not other characteristics of the subjects.
Finally, it should be noted that the low false positive rate (0.07) obtained by the system that combines AI and fuzzy logic techniques (alternative II), together with its accuracy value (0.63), indicate that this proposal meets the objectives set in this work: to design a system that can be integrated into an ADAS that is able to detect fatigue states in driving environments and minimizes the false alarms raised.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}