
Which Features Are More Correlated to Illuminant Estimation: A Composite Substitute


Abstract
:1. Introduction
2. Background
2.1. Imaging Model
2.2. Illuminant Estimation
2.3. Color Correction
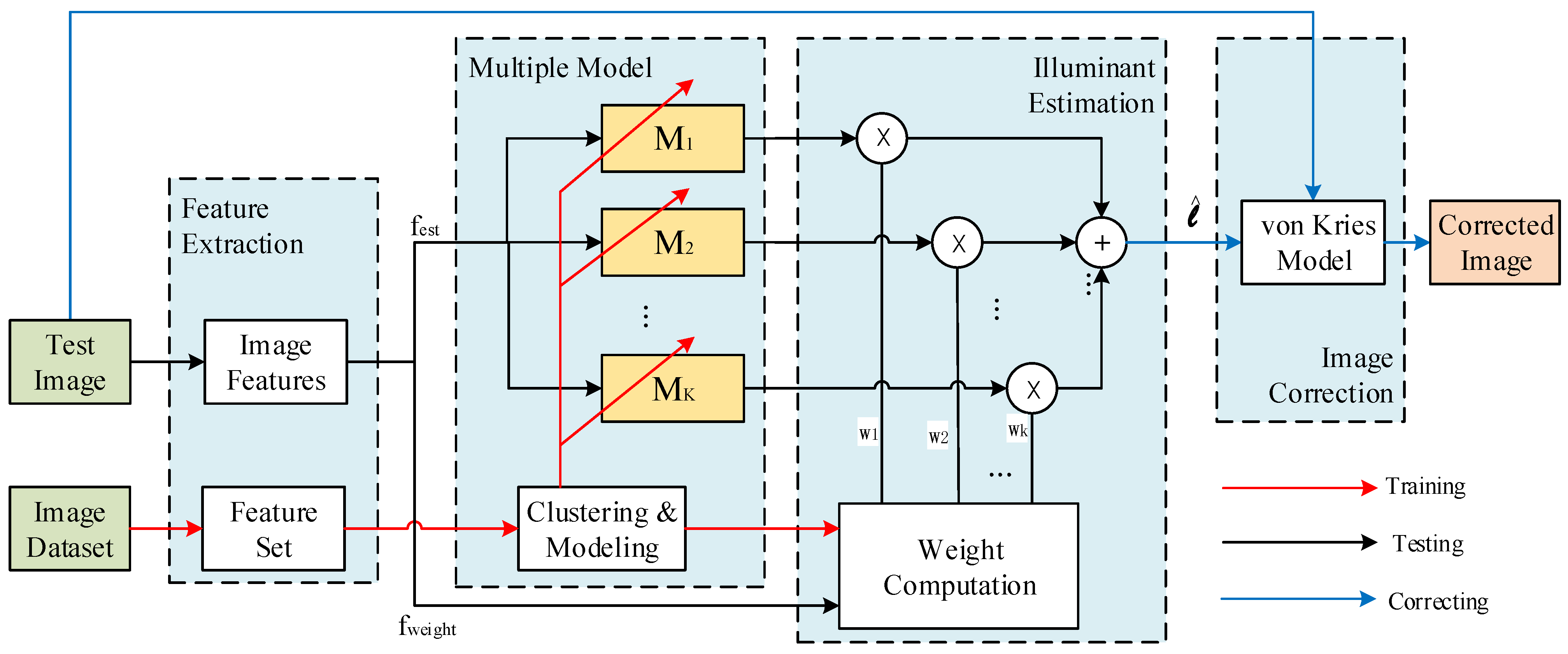
3. Proposed Method
3.1. Features Extraction
3.2. KFCM Clustering
3.3. Model Regression
3.4. Fuzzy Weighting
4. Experimental Results
4.1. Experimental Set-Up
4.2. Experiment A: Individually Testing on Different Datasets (Within Dataset)
4.3. Experiment B: Testing on Image Set from Identical Camera (Within Camera)
4.4. Experiment C: Cross-Dataset, Cross-Camera Testing
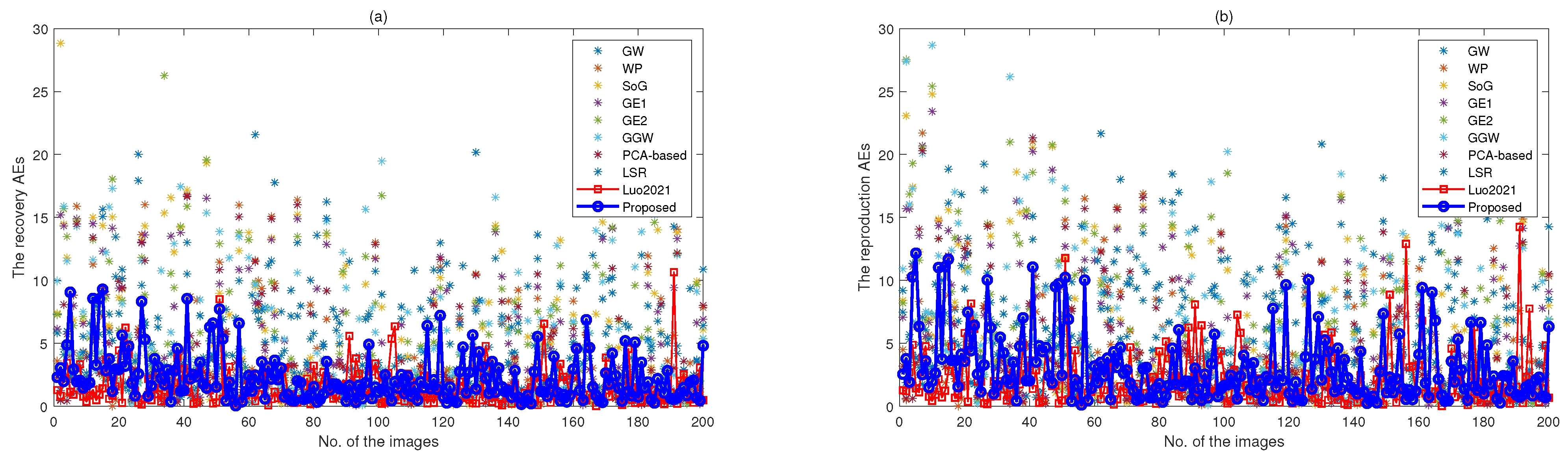
4.5. Additional Experiments
4.6. Discussion and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CCC | Computational color constancy |
| GW | Gray world |
| WP | White patch |
| SoG | Shades of gray |
| GE | Gray edge |
| GGW | General gray world |
| PCA | Primary component analysis |
| LSR | Local surface reflection |
| CM | Corrected moments |
| CDF | Color distribution feature |
| IIF | Initial illumination feature |
| KFCM | Kernel fuzzy c-means clustering |
| NLSR | Non-negative least square regression |
References
- Barnard, K.; Cardei, V.C.; Funt, B.V. A comparison of computational color constancy algorithms. I: Methodology and experiments with synthesized data. IEEE Trans. Image Process. 2002, 11, 972–984. [Google Scholar] [CrossRef] [PubMed]
- Barnard, K.; Martin, L.; Coath, A.; Funt, B.V. A comparison of computational color constancy algorithms. II. Experiments with image data. IEEE Trans. Image Process. 2002, 11, 985–996. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- von Kries, J. Influence of adaptation on the effects produced by luminous stimuli. In Sources of Color Vision; MacAdam, D.L., Ed.; The MIT Press: Cambridge, MA, USA, 1970; pp. 109–119. [Google Scholar]
- Buchsbaum, G. A spatial processor model for object colour perception. J. Frankl. Inst. 1980, 310, 1–26. [Google Scholar] [CrossRef]
- Provenzi, E.; Gatta, C.; Fierro, M.; Rizzi, A. A spatially variant white-patch and gray-world method for color image enhancement driven by local contrast. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1757–1770. [Google Scholar] [CrossRef]
- Land, E.H. The retinex theory of color vision. Sci. Am. 1977, 237, 108–128. [Google Scholar] [CrossRef]
- Finlayson, G.D.; Trezzi, E. Shades of gray and colour constancy. In Proceedings of the Twelfth Color Imaging Conference: Color Science and Engineering Systems, Technologies, Applications, CIC 2004, Scottsdale, AZ, USA, 9–12 November 2004; pp. 37–41. [Google Scholar]
- van de Weijer, J.; Gevers, T.; Gijsenij, A. Edge-based color constancy. IEEE Trans. Image Process. 2007, 16, 2207–2214. [Google Scholar] [CrossRef] [Green Version]
- Gijsenij, A.; Gevers, T. Color constancy using natural image statistics and scene semantics. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 687–698. [Google Scholar] [CrossRef]
- Agarwal, V.; Gribok, A.V.; Abidi, M.A. Machine learning approach to color constancy. Neural Netw. 2007, 20, 559–563. [Google Scholar] [CrossRef]
- Oh, S.W.; Kim, S.J. Approaching the computational color constancy as a classification problem through deep learning. Pattern Recognit. 2017, 61, 405–416. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Wang, B.; Lin, S. FC^4: Fully convolutional color constancy with confidence-weighted pooling. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 330–339. [Google Scholar] [CrossRef]
- Afifi, M.; Brown, M.S. Sensor-independent illumination estimation for DNN models. In Proceedings of the 30th British Machine Vision Conference 2019, BMVC 2019, Cardiff, UK, 9–12 September 2019; p. 282. [Google Scholar]
- Afifi, M.; Brown, M.S. Deep white-balance editing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 1394–1403. [Google Scholar] [CrossRef]
- Koscevic, K.; Subasic, M.; Loncaric, S. Deep learning-based illumination estimation using light source classification. IEEE Access 2020, 8, 84239–84247. [Google Scholar] [CrossRef]
- Qiu, J.; Xu, H.; Ye, Z. Color constancy by reweighting image feature maps. IEEE Trans. Image Process. 2020, 29, 5711–5721. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bianco, S.; Ciocca, G.; Cusano, C.; Schettini, R. Automatic color constancy algorithm selection and combination. Pattern Recognit. 2010, 43, 695–705. [Google Scholar] [CrossRef]
- Li, B.; Xiong, W.; Hu, W.; Funt, B.V. Evaluating combinational illumination estimation methods on real-world images. IEEE Trans. Image Process. 2014, 23, 1194–1209. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Wang, X.; Wang, Q.; Chen, Y. Illuminant estimation using adaptive neuro-fuzzy inference system. Appl. Sci. 2021, 11, 9936. [Google Scholar] [CrossRef]
- Finlayson, G.D. Corrected-moment illuminant estimation. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2013, Sydney, Australia, 1–8 December 2013; pp. 1904–1911. [Google Scholar] [CrossRef]
- Cheng, D.; Prasad, D.K.; Brown, M.S. Illuminant estimation for color constancy: Why spatial-domain methods work and the role of the color distribution. J. Opt. Soc. Am. A 2014, 31, 1049–1058. [Google Scholar] [CrossRef]
- Afifi, M.; Punnappurath, A.; Finlayson, G.; Brown, M.S. As-projective-as-possible bias correction for illumination estimation algorithms. J. Opt. Soc. Am. A 2019, 36, 71–78. [Google Scholar] [CrossRef]
- Gao, S.B.; Zhang, M.; Li, Y.J. Improving color constancy by selecting suitable set of training images. Opt. Express 2019, 27, 25611. [Google Scholar] [CrossRef]
- Gijsenij, A.; Gevers, T.; van de Weijer, J. Computational color constancy: Survey and experiments. IEEE Trans. Image Process. 2011, 20, 2475–2489. [Google Scholar] [CrossRef]
- Faghih, M.M.; Moghaddam, M.E. Multi-objective optimization based color constancy. Appl. Soft Comput. 2014, 17, 52–66. [Google Scholar] [CrossRef]
- Cepeda-Negrete, J.; Sánchez-Yáñez, R.E. Automatic selection of color constancy algorithms for dark image enhancement by fuzzy rule-based reasoning. Appl. Soft Comput. 2015, 28, 1–10. [Google Scholar] [CrossRef]
- Finlayson, G.D.; Hordley, S.D.; Hubel, P.M. Color by correlation: A simple, unifying framework for color constancy. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1209–1221. [Google Scholar] [CrossRef] [Green Version]
- Gijsenij, A.; Gevers, T.; van de Weijer, J. Generalized gamut mapping using image derivative structures for color constancy. Int. J. Comput. Vis. 2010, 86, 127–139. [Google Scholar] [CrossRef] [Green Version]
- Gehler, P.V.; Rother, C.; Blake, A.; Minka, T.P.; Sharp, T. Bayesian color constancy revisited. In Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2008), Anchorage, AK, USA, 24–26 June 2008. [Google Scholar] [CrossRef]
- Cheng, D.; Price, B.L.; Cohen, S.; Brown, M.S. Effective learning-based illuminant estimation using simple features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 1000–1008. [Google Scholar] [CrossRef]
- Bianco, S.; Cusano, C.; Schettini, R. Single and multiple illuminant estimation using convolutional neural networks. IEEE Trans. Image Process. 2017, 26, 4347–4362. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barron, J.T.; Tsai, Y.T. Fast fourier color constancy. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6950–6958. [Google Scholar] [CrossRef] [Green Version]
- Afifi, M.; Barron, J.T.; LeGendre, C.; Tsai, Y.; Bleibel, F. Cross-camera convolutional color constancy. arXiv 2020, arXiv:2011.11890. [Google Scholar]
- Choi, H.H.; Kang, H.S.; Yun, B.J. CNN-based illumination estimation with semantic information. Appl. Sci. 2020, 10, 4806. [Google Scholar] [CrossRef]
- Xiao, J.; Gu, S.; Zhang, L. Multi-domain learning for accurate and few-shot color constancy. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 3255–3264. [Google Scholar] [CrossRef]
- Bianco, S.; Gasparini, F.; Schettini, R. Consensus-based framework for illuminant chromaticity estimation. J. Electron. Imaging 2008, 17, 023013. [Google Scholar] [CrossRef] [Green Version]
- Elfiky, N.M.; Gevers, T.; Gijsenij, A.; Gonzàlez, J. Color constancy using 3D scene geometry derived from a single image. IEEE Trans. Image Process. 2014, 23, 3855–3868. [Google Scholar] [CrossRef]
- Huang, X.; Li, B.; Li, S.; Li, W.; Xiong, W.; Yin, X.; Hu, W.; Qin, H. Multi-cue semi-supervised color constancy with limited training samples. IEEE Trans. Image Process. 2020, 29, 7875–7888. [Google Scholar] [CrossRef]
- van de Weijer, J.; Schmid, C.; Verbeek, J.J. Using high-level visual information for color constancy. In Proceedings of the IEEE 11th International Conference on Computer Vision, ICCV 2007, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Abedini, Z.; Jamzad, M. Weight-based colour constancy using contrast stretching. IET Image Process. 2021, 15, 2424–2440. [Google Scholar] [CrossRef]
- Joze, H.R.V.; Drew, M.S.; Finlayson, G.D.; Rey, P.A.T. The role of bright pixels in illumination estimation. In Proceedings of the 20th Color and Imaging Conference, CIC 2012, Los Angeles, CA, USA, 12–16 November 2012; pp. 41–46. [Google Scholar]
- Yang, K.; Gao, S.; Li, Y. Efficient illuminant estimation for color constancy using grey pixels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 2254–2263. [Google Scholar] [CrossRef]
- Qian, Y.; Nikkanen, J.; Kämäräinen, J.; Matas, J. On finding gray pixels. arXiv 2019, arXiv:1901.03198. [Google Scholar]
- Gao, S.; Han, W.; Yang, K.; Li, C.; Li, Y. Efficient color constancy with local surface reflectance statistics. In Proceedings of the Computer Vision—ECCV 2014—13th European Conference, Zurich, Switzerland, 6–12 September 2014; Volume 8690, pp. 158–173. [Google Scholar] [CrossRef]
- Ciurea, F.; Funt, B.V. A large image database for color constancy research. In Proceedings of the Eleventh Color Imaging Conference: Color Science and Engineering Systems, Technologies, Applications, CIC 2003, Scottsdale, AZ, USA, 4–7 November 2003; pp. 160–164. [Google Scholar]
- Bianco, S.; Cusano, C.; Schettini, R. Color constancy using CNNs. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2015, Boston, MA, USA, 7–12 June 2015; pp. 81–89. [Google Scholar] [CrossRef] [Green Version]
- Lou, Z.; Gevers, T.; Hu, N.; Lucassen, M.P. Color constancy by deep learning. In Proceedings of the British Machine Vision Conference 2015, BMVC 2015, Swansea, UK, 7–10 September 2015; pp. 76.1–76.12. [Google Scholar] [CrossRef] [Green Version]
- Finlayson, G.D.; Mackiewicz, M.; Hurlbert, A.C. Color correction using root-polynomial regression. IEEE Trans. Image Process. 2015, 24, 1460–1470. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Afifi, M.; Price, B.L.; Cohen, S.; Brown, M.S. When color constancy goes wrong: Correcting improperly white-balanced images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 1535–1544. [Google Scholar] [CrossRef]
- Ding, Y.; Fu, X. Kernel-based fuzzy c-means clustering algorithm based on genetic algorithm. Neurocomputing 2016, 188, 233–238. [Google Scholar] [CrossRef]
- Hemrit, G.; Finlayson, G.D.; Gijsenij, A.; Gehler, P.; Bianco, S.; Drew, M.S.; Funt, B.; Shi, L. Providing a single ground-truth for illuminant estimation for the ColorChecker dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1286–1287. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Banic, N.; Loncaric, S. Unsupervised learning for color constancy. In Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2018)—Volume 4: VISAPP, Funchal, Portugal, 27–29 January 2018; pp. 181–188. [Google Scholar] [CrossRef]
- Finlayson, G.D.; Zakizadeh, R. Reproduction angular error: An improved performance metric for illuminant estimation. In Proceedings of the 25th British Machine Vision Conference, BMVC 2014, Nottingham, UK, 1–5 September 2014. [Google Scholar] [CrossRef] [Green Version]
- Finlayson, G.D.; Zakizadeh, R.; Gijsenij, A. The reproduction angular error for evaluating the performance of illuminant estimation algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1482–1488. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, H.; Chen, K.; Wang, K.; Qian, Y.; Zhang, Z.; Jia, K. Cascading convolutional color constancy. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; pp. 12725–12732. [Google Scholar]
- Koscevic, K.; Subasic, M.; Loncaric, S. Guiding the illumination estimation using the attention mechanism. In Proceedings of the 2020 2nd Asia Pacific Information Technology Conference, APIT 2020, Bangkok, Thailand, 14–16 January 2022; pp. 143–149. [Google Scholar] [CrossRef] [Green Version]
- Koscevic, K.; Banic, N.; Loncaric, S. Color beaver: Bounding illumination estimations for higher accuracy. In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, VISIGRAPP 2019, Volume 4: VISAPP, Prague, Czech Republic, 25–27 February 2019; pp. 183–190. [Google Scholar] [CrossRef]
- Li, B.; Xiong, W.; Hu, W.; Funt, B.V.; Xing, J. Multi-cue illumination estimation via a tree-structured group joint sparse representation. Int. J. Comput. Vis. 2016, 117, 21–47. [Google Scholar] [CrossRef]
- Banic, N.; Loncaric, S. Illumination estimation is sufficient for indoor-outdoor image classification. In Proceedings of the Pattern Recognition—40th German Conference, GCPR 2018, Stuttgart, Germany, 9–12 October 2018; Volume 11269, pp. 473–486. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Method | Recovery AE | Reproduction AE | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Med. | Tri. | B25% | W25% | Max | Mean | Med. | Tri. | B25% | W25% | Max | |
| WP [6] | 7.55 | 5.68 | 6.35 | 1.45 | 16.12 | - | 8.1 | 6.5 | 7.1 | - | - | - |
| Edge-based Gamut [28] | 6.52 | 5.04 | 5.43 | 1.90 | 13.58 | - | - | - | - | - | - | - |
| GW [4,5] | 6.36 | 6.28 | 6.28 | 2.33 | 10.58 | - | 7.0 | 6.8 | 6.9 | - | - | - |
| GE1 [8] | 5.33 | 4.52 | 4.73 | 1.86 | 10.03 | - | 6.4 | 4.9 | 5.3 | - | - | - |
| GE2 [8] | 5.13 | 4.44 | 4.62 | 2.11 | 9.26 | - | 6.0 | 4.8 | 5.2 | - | - | - |
| SoG [7] | 4.93 | 4.01 | 4.23 | 1.14 | 10.20 | - | 5.8 | 4.4 | 4.9 | - | - | - |
| Bayesian [29] | 4.82 | 3.46 | 3.88 | 1.26 | 10.49 | - | 5.6 | 3.9 | 4.4 | - | - | - |
| GGW [8] | 4.66 | 3.48 | 3.81 | 1.00 | 10.09 | - | 5.3 | 4.0 | 4.4 | - | - | - |
| Natural Image Statistics [9] | 4.19 | 3.13 | 3.45 | 1.00 | 9.22 | - | 4.8 | 3.5 | 3.9 | - | - | - |
| CART-based Combination [17] | 3.9 | 2.9 | 3.3 | - | - | - | 4.5 | 3.5 | 3.8 | - | - | - |
| WCS with partitioning [40] | 3.66 | 2.05 | 2.45 | 0.44 | 9.49 | - | 4.83 | 2.52 | 3.24 | - | - | - |
| PCA-based [21] | 3.52 | 2.14 | 2.47 | 0.50 | 8.74 | - | 4.71 | 2.72 | 3.28 | - | - | - |
| LSR [44] | 3.31 | 2.80 | 2.87 | 1.14 | 6.39 | - | - | - | - | - | - | - |
| CNN-based method [46] | 2.63 | 1.98 | 2.10 | 0.72 | 3.90 | - | - | - | - | - | - | - |
| FFCC [32] | 1.61 | 0.86 | 1.02 | 0.23 | 4.27 | - | 2.12 | 1.07 | 1.35 | - | - | - |
| C4-SqueezeNet-FC4 [55] | 1.35 | 0.88 | 0.99 | 0.28 | 3.21 | - | - | - | - | - | - | - |
| Proposed | ||||||||||||
| ClrM | 2.59 | 1.35 | 1.76 | 0.00 | 7.53 | 19.28 | 3.34 | 1.57 | 2.13 | 0.00 | 9.82 | 25.43 |
| 3.33 | 2.62 | 2.76 | 0.69 | 7.26 | 19.94 | 4.29 | 3.30 | 3.50 | 0.85 | 9.53 | 23.42 | |
| 3.62 | 2.95 | 3.05 | 0.80 | 7.72 | 20.43 | 4.67 | 3.55 | 3.81 | 0.98 | 10.25 | 33.69 | |
| CDF | 8.65 | 2.60 | 3.11 | 0.00 | 29.53 | 177.12 | 9.64 | 3.05 | 3.82 | 0.00 | 32.31 | 177.44 |
| IIF | 4.14 | 3.03 | 3.37 | 0.97 | 9.06 | 22.34 | 5.40 | 3.68 | 4.28 | 1.13 | 12.37 | 36.04 |
| RGBuv | 3.25 | 2.35 | 2.55 | 0.67 | 7.35 | 24.81 | 4.39 | 2.98 | 3.22 | 0.79 | 10.48 | 110.51 |
| ChengSF | 4.17 | 3.03 | 3.41 | 0.85 | 9.29 | 19.04 | 5.47 | 3.63 | 4.30 | 0.98 | 12.72 | 30.84 |
| RGBuv+ChengSF | 3.06 | 2.20 | 2.40 | 0.68 | 6.85 | 18.25 | 3.98 | 2.73 | 2.99 | 0.79 | 9.27 | 29.51 |
| RGBuv+ChengSF+IIF | 3.01 | 2.24 | 2.40 | 0.67 | 6.70 | 19.48 | 3.94 | 2.75 | 2.97 | 0.79 | 9.17 | 47.80 |
| RGBuv+ChengSF+IIF+ | 2.99 | 2.17 | 2.36 | 0.68 | 6.68 | 19.16 | 3.90 | 2.80 | 3.02 | 0.80 | 9.12 | 45.81 |
| Method | Recovery AE | Reproduction AE | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Med. | Tri. | B25% | W25% | Max | Mean | Med. | Tri. | B25% | W25% | Max | |
| WP [6] | 9.69 | 7.48 | 8.56 | 1.72 | 20.49 | - | - | - | - | - | - | - |
| GW [4,5] | 7.71 | 4.29 | 4.98 | 1.01 | 20.19 | - | - | - | - | - | - | - |
| Gray pixels [42] | 6.65 | 3.26 | 3.95 | 0.68 | 18.75 | - | - | - | - | - | - | - |
| Color Tiger [52] | 3.91 | 2.05 | 2.53 | 0.98 | 10.00 | - | - | - | - | - | - | - |
| SoG [7] | 2.59 | 1.73 | 1.93 | 0.46 | 6.19 | - | - | - | - | - | - | - |
| GE1 [8] | 2.50 | 1.59 | 1.78 | 0.48 | 6.08 | - | - | - | - | - | - | - |
| GE2 [8] | 2.41 | 1.52 | 1.72 | 0.45 | 5.89 | - | - | - | - | - | - | - |
| GGW [8] | 2.38 | 1.43 | 1.66 | 0.35 | 6.01 | - | - | - | - | - | - | - |
| Attention CNN [56] | 2.05 | 1.32 | 1.53 | 0.42 | 4.84 | - | - | - | - | - | - | - |
| Lighting classification DL [15] | 1.86 | 1.27 | 1.39 | 0.42 | 4.31 | - | - | - | - | - | - | - |
| Luo [19] | 1.69 | 1.12 | 1.24 | 0.31 | 4.06 | - | - | - | - | - | - | - |
| Color Beaver (GW) [57] | 1.49 | 0.77 | 0.98 | 0.21 | 3.94 | - | - | - | - | - | - | - |
| Proposed | ||||||||||||
| ClrM | 2.45 | 1.76 | 1.95 | 0.47 | 5.53 | 143.54 | 3.36 | 2.39 | 2.61 | 0.61 | 7.73 | 76.69 |
| 2.16 | 1.52 | 1.71 | 0.41 | 4.97 | 20.51 | 2.88 | 1.96 | 2.26 | 0.52 | 6.69 | 25.38 | |
| 2.36 | 1.73 | 1.92 | 0.47 | 5.23 | 18.19 | 3.36 | 2.34 | 2.60 | 0.61 | 7.84 | 121.57 | |
| IIF | 2.28 | 1.58 | 1.73 | 0.46 | 5.32 | 21.22 | 3.31 | 2.13 | 2.37 | 0.58 | 8.17 | 113.33 |
| RGBuv | 1.95 | 1.39 | 1.51 | 0.35 | 4.48 | 15.72 | 2.63 | 1.86 | 2.02 | 0.44 | 6.15 | 22.12 |
| ChengSF | 2.24 | 1.49 | 1.68 | 0.41 | 5.36 | 33.70 | 3.08 | 1.97 | 2.25 | 0.51 | 7.49 | 42.90 |
| RGBuv+ChengSF | 1.92 | 1.37 | 1.50 | 0.38 | 4.37 | 15.02 | 2.58 | 1.85 | 2.03 | 0.47 | 6.01 | 19.88 |
| RGBuv+ChengSF+IIF | 1.79 | 1.31 | 1.41 | 0.36 | 4.06 | 14.22 | 2.43 | 1.74 | 1.90 | 0.44 | 5.62 | 20.04 |
| RGBuv+ChengSF+IIF+ | 1.80 | 1.31 | 1.42 | 0.36 | 4.08 | 14.33 | 2.44 | 1.73 | 1.89 | 0.45 | 5.64 | 20.18 |
| Method | Recovery AE | Reproduction AE | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Med. | Tri. | B25% | W25% | Max | Mean | Med. | Tri. | B25% | W25% | Max | |
| GW [4,5] | 4.90 | 3.59 | 3.99 | 0.96 | 10.82 | 20.02 | 6.23 | 4.75 | 5.14 | 1.17 | 13.65 | 24.81 |
| WP [6] | 3.82 | 2.49 | 2.89 | 0.50 | 9.37 | 23.44 | 4.81 | 3.10 | 3.59 | 0.61 | 11.70 | 31.12 |
| SoG [7] | 6.34 | 3.89 | 4.72 | 0.76 | 15.56 | 35.75 | 7.16 | 4.89 | 5.69 | 0.92 | 16.73 | 25.69 |
| GE1 [8] | 5.89 | 4.08 | 4.69 | 0.75 | 14.00 | 32.43 | 6.74 | 5.20 | 5.69 | 0.89 | 15.41 | 27.41 |
| GE2 [8] | 6.43 | 3.83 | 4.66 | 0.92 | 16.05 | 37.27 | 7.18 | 4.77 | 5.64 | 1.06 | 17.15 | 31.32 |
| PCA-based [21] | 6.94 | 4.36 | 5.33 | 1.05 | 16.69 | 45.97 | 7.62 | 5.28 | 6.19 | 1.20 | 17.39 | 32.77 |
| GGW [8] | 4.11 | 2.51 | 2.96 | 0.52 | 10.23 | 28.60 | 5.15 | 3.16 | 3.82 | 0.64 | 12.75 | 40.59 |
| LSR [44] | 3.94 | 2.99 | 3.30 | 1.36 | 7.96 | 17.92 | 4.84 | 3.88 | 4.16 | 1.61 | 9.69 | 20.08 |
| Proposed | ||||||||||||
| ClrM | 2.32 | 0.68 | 1.24 | 0.00 | 7.20 | 16.46 | 3.23 | 0.84 | 1.66 | 0.00 | 10.23 | 44.45 |
| 2.83 | 2.14 | 2.34 | 0.53 | 6.32 | 15.04 | 3.67 | 2.69 | 3.00 | 0.65 | 8.32 | 21.28 | |
| 3.06 | 2.28 | 2.45 | 0.58 | 6.74 | 14.88 | 4.14 | 2.96 | 3.20 | 0.70 | 9.49 | 35.81 | |
| CDF | 8.49 | 1.54 | 2.19 | 0.00 | 29.92 | 179.08 | 9.87 | 1.63 | 2.66 | 0.00 | 34.39 | 178.91 |
| IIF | 3.00 | 2.12 | 2.32 | 0.73 | 6.80 | 25.02 | 4.00 | 2.56 | 2.95 | 0.82 | 9.53 | 42.86 |
| RGBuv | 2.97 | 2.17 | 2.27 | 0.58 | 6.84 | 51.56 | 4.14 | 2.67 | 2.91 | 0.73 | 10.10 | 112.29 |
| ChengSF | 3.23 | 2.21 | 2.48 | 0.60 | 7.57 | 30.31 | 4.35 | 2.88 | 3.23 | 0.71 | 10.62 | 38.42 |
| RGBuv+ChengSF | 2.85 | 2.15 | 2.23 | 0.57 | 6.51 | 33.46 | 4.08 | 2.72 | 2.88 | 0.69 | 10.05 | 115.51 |
| RGBuv+ChengSF+IIF | 2.83 | 2.08 | 2.18 | 0.57 | 6.51 | 39.05 | 4.02 | 2.68 | 2.86 | 0.68 | 9.90 | 116.17 |
| RGBuv+ChengSF+IIF+ | 2.78 | 1.99 | 2.13 | 0.61 | 6.31 | 32.80 | 4.02 | 2.51 | 2.75 | 0.72 | 9.91 | 120.15 |
| Method | Recovery AE | Reproduction AE | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Med. | Tri. | B25% | W25% | Max | Mean | Med. | Tri. | B25% | W25% | Max | |
| GW [4,5] | 4.36 | 2.73 | 3.11 | 0.61 | 10.82 | 39.54 | 5.45 | 3.63 | 4.09 | 0.77 | 13.11 | 42.57 |
| WP [6] | 3.62 | 2.37 | 2.59 | 0.55 | 8.93 | 20.65 | 4.42 | 3.02 | 3.33 | 0.71 | 10.53 | 24.99 |
| SoG [7] | 4.48 | 2.66 | 3.20 | 0.47 | 11.39 | 22.91 | 5.31 | 3.36 | 4.03 | 0.60 | 13.02 | 25.28 |
| GE1 [8] | 4.02 | 2.80 | 3.14 | 0.55 | 9.58 | 20.31 | 5.05 | 3.61 | 4.03 | 0.67 | 11.82 | 24.59 |
| GE2 [8] | 4.40 | 2.55 | 3.07 | 0.60 | 11.24 | 24.58 | 5.22 | 3.26 | 3.94 | 0.78 | 12.86 | 27.53 |
| PCA-based [21] | 4.98 | 2.99 | 3.55 | 0.75 | 12.35 | 26.80 | 5.85 | 3.88 | 4.50 | 0.94 | 13.83 | 27.84 |
| GGW [8] | 3.28 | 1.97 | 2.26 | 0.44 | 8.49 | 20.40 | 4.07 | 2.57 | 2.95 | 0.57 | 10.20 | 26.87 |
| LSR [44] | 5.25 | 4.15 | 4.58 | 1.34 | 10.79 | 17.17 | 6.51 | 5.51 | 5.84 | 1.57 | 13.09 | 20.80 |
| Proposed | ||||||||||||
| ClrM | 2.64 | 2.13 | 2.25 | 0.61 | 5.50 | 26.98 | 3.68 | 2.87 | 3.06 | 0.81 | 7.89 | 36.12 |
| 2.30 | 1.69 | 1.84 | 0.55 | 5.06 | 22.16 | 3.06 | 2.22 | 2.44 | 0.70 | 6.78 | 27.69 | |
| 2.52 | 1.98 | 2.11 | 0.62 | 5.32 | 18.27 | 3.61 | 2.54 | 2.83 | 0.81 | 8.07 | 113.87 | |
| CDF | 49.20 | 6.49 | 40.98 | 1.36 | 173.44 | 179.68 | 50.28 | 8.62 | 41.39 | 1.85 | 171.63 | 179.64 |
| IIF | 2.50 | 1.78 | 1.95 | 0.57 | 5.74 | 21.02 | 3.64 | 2.30 | 2.60 | 0.71 | 8.89 | 110.91 |
| RGBuv | 2.04 | 1.45 | 1.59 | 0.43 | 4.63 | 28.63 | 2.79 | 1.96 | 2.15 | 0.54 | 6.42 | 44.16 |
| ChengSF | 2.44 | 1.59 | 1.83 | 0.47 | 5.83 | 34.98 | 3.34 | 2.13 | 2.45 | 0.58 | 8.12 | 47.04 |
| RGBuv+ChengSF | 2.00 | 1.43 | 1.57 | 0.43 | 4.49 | 22.39 | 2.71 | 1.95 | 2.12 | 0.53 | 6.20 | 32.05 |
| RGBuv+ChengSF+IIF | 1.88 | 1.41 | 1.50 | 0.41 | 4.16 | 20.35 | 2.54 | 1.82 | 2.00 | 0.51 | 5.77 | 26.24 |
| RGBuv+ChengSF+IIF+ | 1.87 | 1.44 | 1.53 | 0.42 | 4.14 | 20.52 | 2.53 | 1.86 | 2.02 | 0.51 | 5.74 | 27.23 |
| Method | Recovery AE | Reproduction AE | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Med. | Tri. | B25% | W25% | Max | Mean | Med. | Tri. | B25% | W25% | Max | |
| GW [4,5] | 4.41 | 3.05 | 3.36 | 0.68 | 10.53 | 39.54 | 5.56 | 4.00 | 4.39 | 0.88 | 12.89 | 42.57 |
| WP [6] | 3.57 | 2.30 | 2.57 | 0.52 | 8.89 | 23.44 | 4.39 | 3.00 | 3.30 | 0.66 | 10.58 | 31.12 |
| SoG [7] | 4.85 | 2.83 | 3.47 | 0.53 | 12.38 | 35.75 | 5.65 | 3.59 | 4.29 | 0.67 | 13.81 | 26.08 |
| GE1 [8] | 4.42 | 2.88 | 3.36 | 0.60 | 10.71 | 32.43 | 5.40 | 3.71 | 4.26 | 0.74 | 12.69 | 27.41 |
| GE2 [8] | 4.82 | 2.77 | 3.36 | 0.65 | 12.37 | 37.27 | 5.58 | 3.46 | 4.12 | 0.81 | 13.72 | 31.32 |
| PCA-based [21] | 5.39 | 3.15 | 3.87 | 0.81 | 13.49 | 45.97 | 6.19 | 4.01 | 4.74 | 1.00 | 14.69 | 32.77 |
| GGW [8] | 3.40 | 2.00 | 2.34 | 0.45 | 8.77 | 28.60 | 4.21 | 2.64 | 3.04 | 0.57 | 10.61 | 40.59 |
| LSR [44] | 4.80 | 3.78 | 4.10 | 1.35 | 10.00 | 20.48 | 5.96 | 4.79 | 5.17 | 1.59 | 12.22 | 21.47 |
| Luo [19] | 1.97 | 1.30 | 1.45 | 0.36 | 4.75 | 25.38 | 2.57 | 1.64 | 1.86 | 0.45 | 6.32 | 37.14 |
| Proposed | ||||||||||||
| ClrM | 2.50 | 1.69 | 1.91 | 0.12 | 6.23 | 40.80 | 3.43 | 2.23 | 2.48 | 0.14 | 8.80 | 113.29 |
| 2.61 | 1.90 | 2.09 | 0.61 | 5.79 | 20.87 | 3.41 | 2.45 | 2.70 | 0.75 | 7.73 | 124.29 | |
| 2.86 | 2.23 | 2.38 | 0.66 | 6.13 | 20.67 | 3.91 | 2.97 | 3.17 | 0.82 | 8.69 | 102.71 | |
| CDF | 45.00 | 4.96 | 9.27 | 0.26 | 167.64 | 179.54 | 45.42 | 6.33 | 11.33 | 0.32 | 166.02 | 179.40 |
| IIF | 2.88 | 2.06 | 2.22 | 0.60 | 6.61 | 22.85 | 3.93 | 2.58 | 2.86 | 0.77 | 9.41 | 49.67 |
| RGBuv | 2.34 | 1.70 | 1.81 | 0.51 | 5.33 | 21.96 | 3.12 | 2.21 | 2.38 | 0.63 | 7.22 | 34.57 |
| ChengSF | 2.90 | 1.97 | 2.21 | 0.54 | 6.80 | 34.91 | 4.02 | 2.55 | 2.90 | 0.68 | 9.87 | 123.33 |
| RGBuv+ChengSF | 2.22 | 1.60 | 1.74 | 0.45 | 5.06 | 18.22 | 2.93 | 2.04 | 2.26 | 0.57 | 6.77 | 21.28 |
| RGBuv+ChengSF+IIF | 2.13 | 1.55 | 1.69 | 0.48 | 4.76 | 14.83 | 2.80 | 2.06 | 2.23 | 0.59 | 6.35 | 18.79 |
| RGBuv+ChengSF+IIF+ | 2.10 | 1.52 | 1.67 | 0.46 | 4.74 | 16.91 | 2.77 | 1.99 | 2.18 | 0.58 | 6.28 | 18.81 |
| Clustering | Recovery AE | Reproduction AE | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Number | Mean | Med. | Tri. | B25% | W25% | Max | Mean | Med. | Tri. | B25% | W25% | Max |
| K-means | 2 | 2.12 | 1.53 | 1.68 | 0.48 | 4.76 | 18.32 | 2.80 | 1.99 | 2.21 | 0.59 | 6.35 | 23.79 |
| KFCM | 2 | 2.10 | 1.52 | 1.67 | 0.47 | 4.70 | 15.71 | 2.76 | 1.98 | 2.19 | 0.58 | 6.25 | 18.18 |
| K-means | 3 | 2.12 | 1.51 | 1.65 | 0.46 | 4.84 | 15.15 | 2.77 | 1.95 | 2.16 | 0.57 | 6.37 | 20.10 |
| KFCM | 3 | 2.13 | 1.53 | 1.67 | 0.46 | 4.83 | 18.87 | 2.79 | 1.97 | 2.18 | 0.56 | 6.43 | 27.39 |
| twoStep | 2 × 2 | 5.98 | 4.05 | 5.29 | 2.49 | 10.35 | 10.98 | 8.55 | 4.16 | 6.81 | 3.47 | 15.36 | 15.68 |
| K-means | 4 | 2.15 | 1.46 | 1.61 | 0.45 | 5.06 | 51.86 | 2.84 | 1.86 | 2.10 | 0.57 | 6.77 | 91.14 |
| KFCM | 4 | 2.14 | 1.54 | 1.69 | 0.48 | 4.80 | 14.83 | 2.82 | 2.06 | 2.23 | 0.58 | 6.41 | 18.86 |
| K-means | 5 | 2.11 | 1.40 | 1.56 | 0.43 | 4.99 | 31.64 | 2.78 | 1.79 | 2.04 | 0.53 | 6.64 | 52.73 |
| KFCM | 5 | 2.17 | 1.50 | 1.69 | 0.47 | 4.95 | 14.77 | 2.85 | 1.95 | 2.18 | 0.58 | 6.61 | 18.81 |
| twoStep | 2 × 3 | 6.29 | 5.30 | 5.00 | 2.37 | 12.02 | 17.75 | 8.58 | 6.42 | 7.04 | 3.16 | 16.24 | 25.69 |
| K-means | 6 | 2.27 | 1.44 | 1.60 | 0.44 | 5.57 | 108.90 | 3.08 | 1.81 | 2.06 | 0.55 | 7.74 | 119.54 |
| KFCM | 6 | 2.22 | 1.53 | 1.70 | 0.45 | 5.16 | 21.96 | 2.91 | 1.97 | 2.20 | 0.55 | 6.86 | 28.93 |
| Kernel Width | Recovery AE | Reproduction AE | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Med. | Tri. | B25% | W25% | Max | Mean | Med. | Tri. | B25% | W25% | Max | |
| 30 | 2.16 | 1.54 | 1.69 | 0.46 | 4.91 | 26.05 | 2.84 | 1.99 | 2.20 | 0.57 | 6.53 | 27.08 |
| 60 | 2.14 | 1.55 | 1.68 | 0.48 | 4.82 | 18.85 | 2.80 | 2.03 | 2.20 | 0.58 | 6.39 | 27.35 |
| 100 | 2.15 | 1.56 | 1.70 | 0.49 | 4.83 | 15.38 | 2.83 | 2.04 | 2.23 | 0.59 | 6.43 | 18.79 |
| 140 | 2.14 | 1.55 | 1.70 | 0.48 | 4.82 | 14.83 | 2.82 | 2.04 | 2.22 | 0.59 | 6.42 | 18.71 |
| 180 | 2.14 | 1.55 | 1.70 | 0.48 | 4.79 | 15.36 | 2.81 | 2.03 | 2.23 | 0.59 | 6.38 | 18.64 |
| 240 | 2.16 | 1.52 | 1.69 | 0.46 | 4.95 | 14.93 | 2.85 | 1.94 | 2.20 | 0.57 | 6.62 | 19.46 |
| 300 | 2.16 | 1.52 | 1.69 | 0.47 | 4.92 | 14.93 | 2.85 | 1.97 | 2.21 | 0.57 | 6.60 | 18.97 |
| 400 | 2.19 | 1.52 | 1.70 | 0.46 | 5.02 | 19.92 | 2.88 | 1.97 | 2.22 | 0.57 | 6.71 | 23.64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Y.; Wang, X.; Wang, Q. Which Features Are More Correlated to Illuminant Estimation: A Composite Substitute. Appl. Sci. 2022, 12, 1175. https://doi.org/10.3390/app12031175
Luo Y, Wang X, Wang Q. Which Features Are More Correlated to Illuminant Estimation: A Composite Substitute. Applied Sciences. 2022; 12(3):1175. https://doi.org/10.3390/app12031175
Chicago/Turabian StyleLuo, Yunhui, Xingguang Wang, and Qing Wang. 2022. "Which Features Are More Correlated to Illuminant Estimation: A Composite Substitute" Applied Sciences 12, no. 3: 1175. https://doi.org/10.3390/app12031175
APA StyleLuo, Y., Wang, X., & Wang, Q. (2022). Which Features Are More Correlated to Illuminant Estimation: A Composite Substitute. Applied Sciences, 12(3), 1175. https://doi.org/10.3390/app12031175