1. Introduction
In the latest years, society is becoming more and more saturated with the overwhelming amount of information available to costumers. For this reason, the use of algorithms for information retrieval and sorting is becoming a cornerstone in the technological solutions offered. An important instance of these methods is Recommender Systems (RSs), which aid users to match with items in the most efficient way possible, taking into account both the user’s own preferences and those of others with similar tastes. An evidence of the deep penetration of these algorithms in the industry is the high number of companies that use RSs as part of their business model, such as Amazon, eBay, Netflix, Twitter and many others. However, although improving recommendation accuracy has been the main target for academic researchers [
1], other objectives that are beyond improving accuracy have also attracted the interest of the community in recent years [
2]. Metrics such as coverage, diversity and novelty are goals of cutting-edge research since users typically prefer to be recommended items with a certain degree of novelty. Recent RSs research suggests that accurate recommendations are possible [
3]: when RSs recommend a restaurant by awarding it five stars, a human is likely to be skeptical of the rating. Some RSs provide some extra data that help us to deduce the rating’s trustworthiness such as the number of individuals who have voted for the restaurant. Almost everyone prefers a restaurant with an average rating of 4 stars and 5000 reviews to one with just 5 reviews and an average rating of 5 stars. In this framework, a recommendation does not only comprise the recommended item, but also an associated reliability value provided through RSs techniques and models for trustworthiness.
The core of every RS is its filtering mechanism. Broadly speaking, the system makes recommendations based on context [
4], content [
5], social environment [
6], demographic data [
7] and collaborative information, the latter being the most widely used approach [
8]. Hybrid methods [
9], which combine Collaborative Filtering (CF) and other filtering sources, are commonly used in commercial RS designs.
Among CF methods, Probabilistic Matrix Factorization (PMF) [
10] is arguably the most relevant contribution to the area in the latest times. It models the process of assigning a rating as regression process that follows a normal distribution with mean given by the inner product of two ‘hidden vectors’ associated to each user and item. Since it inception, other CF models have been proposed to extend the ideas PMF to work with more general frameworks. One of the most promising lines is to combine the hidden vectors in a non-linear way, in sharp contrast with the usual operation of PMF. For instance, in [
11], two new models are proposed inspired by deep learning techniques, namely, Generalized Matrix Factorization (GMF) and Neural Collaborative Filtering (NCF). In the former, instead of the standard inner product in the euclidean space, a more general inner product is allowed, which is learned during the training process. To definitely break with linearity, this work also proposes NCF, in which the inner product is fully substituted by a neural network able to combine the hidden vectors in a highly non-linear way.
Despite these advances, recent works show that, in the RSs field, providing precise reliability values that are connected with forecasts is a major aim, as it provides many advantages: new ways of providing recommendations to the user that take into account the reliability of the prediction, achieving better accuracy by filtering low reliability recommendations, and identifying a cold start problem when every recommendation for an user has low reliability. It is worth noticing that reliability and accuracy are different metrics of the performance of an RS: accuracy is the objective ability of the RS of issuing correct predictions (in the sense that they agree with the known values of the test split dataset), while reliability is a subjective perception of the model on the probability that its prediction is correct. In some sense, reliability measures the impression of the algorithm on the ‘difficulty’ of issuing the prediction. In this way, a good RS method labels controvert predictions with low reliability while clear trends are associated to high reliability. This reliability measure can be used to filter-out these controvert predictions, in such a way that only forecasts with high reliability are issued. If the RS models reliability correctly, this filtration will lead to an improvement of the accuracy of the predictions.
For this reason, several CF-based methods and models have been developed to provide reliability values based on both the Matrix Factorization (MF) and K Nearest Neighbors (KNN) approaches, in contrast with the aforementioned proposals which do not support this metric. For instance, Margaris et al. [
12] presents the notion of reliability in the domain of review-to-rating conversion, that is, the reliability of converting textual reviews to implicit ratings. In addition, Mesas and Bellogín [
13] looks at a few different ways of embedding awareness in an RS to analyze whether each item should be offered. The authors claim that, similar to our suggested strategy, confidence values may be used to filter the most trustworthy recommendations, resulting in an increase in accuracy and a drop in coverage.
Regarding memory-based approaches, Fan et al. [
14] improves classic Pearson and cosine similarity metrics by applying the reliability concept. Previously, authors calculated the credibility of a user’s rating using the users’ scores on common products. Ahmadian et al. [
15] presented an aggregation of reliability metrics, including user-based reliability, rating profile reliability, and item-based reliability. Their model is able to make better suggestions as a result of this knowledge. Liang et al. [
16], Xu et al. [
17] both used an upper bound of confidence to improve recommendations, the former using event-based social networks and synthetic datasets, and the latter exploiting the user’s behavior temporal information to improve the accuracy of the recommendations.
Despite its effectiveness, the above-mentioned studies have two major flaws in terms of dependability. First, because of its lack of precision and scalability, the KNN technique is not used. Second, because social information is only available in a tiny portion of current RSs, social-based trust-aware techniques aimed at determining dependability values cannot be termed universal solutions.
In this direction, our previous model Bernoulli Matrix Factorization (BeMF) [
18] addressed the problem of providing accurate recommendations in addition to their associated reliability as a classification problem. This classification approach uses a finite set of ratings that should be assigned to the items as classes to predict. In this manner, the model returns the probability that a user would assign each of the
D possible ratings to an item, which was modeled as
D independent Bernoulli processes. Those
D probabilities can be aggregated to obtain the expected reliability result, in such a way that the model provides additional information to the recommendations.
Although our previous model achieves good results, we modeled the ratings as a D-dimensional vector of independent Bernoulli random variables, which is a rather strong assumption. To address this issue, in this work we propose a novel MF model that provides the reliability of the recommendations by using a classification-based approach. However, instead of assuming independence between the ratings, our novel proposal models them as a Dirichlet random variable to deal with the existing interdependence. Due to the key role that the Dirichlet distribution plays in the formulation of the model, as well as its crucial use of matrix factorization procedures, this new method is referred to as Dirichlet Matrix Factorization (DirMF).
The structure of this paper is as follows.
Section 2 explains the interstices of the proposed DirMF model, both regarding the mathematical formulation of the underlying classification problem (
Section 2.1) and the way in which prediction value and reliability can be extracted from these data (
Section 2.2). The presentation is complemented with a discussion of the time and space complexity of the proposed method in
Section 2.3, as well as a detailed running example shown in
Section 2.4. In
Section 3 we present the experiments conducted to evaluate the performance of DirMF. In particular,
Section 3.1 describes the experimental setting, whereas
Section 3.2 analyzes the obtained results. The paper finishes with some conclusions and future works, as outlined in
Section 4.
Our Contribution
The main results and novel proposals developed in the present manuscript are the following:
A new model, named DirMF, is introduced, and a complete description of its mathematical formulation, training procedure and prediction protocol is provided.
The new DirMF model introduces a new probabilistic interpretation of the rating process. Instead of considering the rating as a continuous random variable or seeing each vote as an independent feature, as in the existing literature, our method is flexible enough to model the ratings as interrelated discrete random variables. For this purpose, the method proposes the novelty of relying in the Dirichlet probability distribution to model the user’s rating behavior;
The performance of this new model is evaluated through an extensive collection of experiments. The results evidence that DirMF achieves a high performance both in terms of recommendation quality and management of reliability. The implementation of the reliability as an intrinsic part of the algorithm leads to a better performance of this method compared to the preexisting algorithms that do not treat reliability in this way;
Additionally, DirMF shows similar results to BeMF, the other method that embeds the reliability as part of its training process. Furthermore, thanks to its more flexible nature, DirMF presents a more conservative forecasting trend than BeMF, which leads to a better prediction in scenarios in which failure is highly penalized.
2. Proposed Model
Let us assume that there are N users that may rate M different items. Rating means a user can assign a score to an item chosen from a discrete set of scores . For instance, a rating consisting of giving one to five stars means . The ratings that are known are represented by the ratings matrix , where if user has assigned the score to item and if user u has not rated item i. The matrix R is decomposed into D binary matrices , such that if user u assigned the score s to item i (i.e., ), if user u assigned other score than s to the item i (i.e., ), and if the user u did not rate the item i (i.e., ).
As stated above, predicting those missing values of is a classification problem, as means whether user u thought that a rating of s is the best for item i. The aim of our proposal is to model the random vector as a Dirichlet random variable with parameters . Therefore, quantifies both the affinity of the user u for item i and the reliability of the prediction.
Regarding how our model estimates the parameters , it supposes that there exists some K-dimensional hidden user factors vector and hidden item factors vector whose dot product is . This is consistent with other MF models in the literature. As may return any real number the model uses a logistic-like smooth function to normalize the result into . In this way, we set as a probability.
Figure 1 exhibits the plate diagram of the model, which is composed of
D different factorizations (one factorization for each possible score), each of which is composed of
N variables
(latent factors of each user) and
M variables
(latent factors of each item). The hyperparameters of the model are two positive real values
(which will play the role of standard deviation of gaussian priors for regularization), an integer
(the number of hidden factors) and a smooth logistic-like function
used for normalization.
2.1. Dirichlet Factorization
In this section, we shall describe the mathematical formulation of the Dirichlet factorization model. Recall that, given parameters
, the associated Dirichlet distribution is the
D-dimensional random vector with joint probability density function
given by
for variables
in the standard simplex, i.e.,
and
. The density function is zero elsewhere. Here, the normalization factor is the Beta function
with
the Gamma function (the analytic continuation of the factorial into a meromorphic function in the complex plane).
In this way, if we set as parameters
then, given the rating matrix
decomposed into binary matrices
, we obtain that the associated likelihood
is
Here, we have shortened .
However, observe that, since
is either 0 or 1, the previous likelihood is zero except for perfect prediction. To avoid this issue, we propose to use a ‘soft’ version of the binary labeling. To do so, we take the softmax of the hard labels:
Here, is a shape hyperparameter that controls the sharpness of the softmax function. It can be adjusted to increase the weight of some pairs in the likelihood function.
In this way, the modified likelihood function that we shall consider is:
Hence, the log-likelihood function,
, is given by:
To optimize this likelihood function, we will use a standard gradient ascent algorithm. The directional derivatives of the cost function in the directions
P and
Q are then given by:
where
denotes the digamma function
Therefore, the update rules for each known rating
are the following:
Notice that, for typical logistic-like functions, the derivative
can be easily computed. For instance, for
the genuine logistic function, we have that
We can also add Gaussian priors to the likelihood function (Equation (
3)) for the parameters
and
with mean zero and fixed standard deviation. Analogue computations with these Gaussian priors lead to an extra regularization term
in (Equation (
4)) and
in (
5)) for
a hyperparameter.
Algorithm 1 summarizes the fitting process of the DirMF model for the genuine logistic function and to control the sharpness of the softmax function.
The algorithm requires as input the sparse rating matrix (R), the number of latent factors (K), the set of scores (), and the hyper-parameters that are required by gradient ascent optimization: learning rate (), regularization () and number of iterations (m) as inputs. Its outputs are the fitted latent factors: P contains the latent factors for each score s, user u and factor k, whereas Q contains the latent factors for each score s, item i and factor k. Note that both the user’s (lines 3–20) and item’s update loops (lines 21–38) may be executed in parallel for each user and item, respectively.
2.2. Prediction
Once the model has been trained, we have obtained a collection of users’ latent vectors
as well as items’ latent vectors
for
. Given a new pair user–item
to be predicted, the Dirichlet MF method assigns to it the
D-dimensional continuous random vector
with parameters
. That is, it is the
D-dimensional random vector supported on the standard simplex whose probability density function is given by (
1):
From this distribution, discrete random variables with supports on can be sampled. These discrete probability distributions represent the probability that the user u would score item i with each of the possible ratings. However, observe that, in sharp contrast with other matrix factorization approaches, the output here is not a discrete distribution, but a random variable that takes values in discrete probability distributions.
Several criteria can be used to obtain the predicted ratings. In this work, we shall follow an approach based on the law of large numbers. Indeed, if we sampled
a large number of times, the mean probability of the score
would be the mean of the
s-th component of the Dirichlet distribution with parameters
, which is the value:
These means are positive and , so they give rise to a discrete robability distribution on . From it, we obtain two relevant data:
The final prediction
, which is the mode of the aforementioned distribution, that is,
The reliability
in the prediction, which is the probability attained at the mode of the distribution, that is,
In this manner, fixed a threshold , we can crop the predictions so that we artificially set (no prediction is issued) if the reliability does not achieves the given threshold, that is, if . Otherwise, when , we keep, as the prediction , the mode of the mean probability distribution.
Summarizing, the workflow associated to a cycle of training and exploitation phases of the DirMF model is as follows:
Collect the rating matrix R of shape with the known votes per user and item;
Choose hyperparameters K (number of latent factors), (learning rate), (regularization), m (number of iterations) and (reliability threshold, for the exploitation phase);
Execute the training algorithm for DirMF (Algorithm 1) with the chosen hyperparameters. The output of the training is a collection of pairs of matrices for each possible vote s;
Given a new pair
of an user
and an item
to be predicted, compute the quantities
for each possible score
s;
The prediction is the vote for which is maximum. The reliability is the value .
If , then return prediction ; otherwise return that no reliable prediction can be issued.
2.3. Computational Complexity
From the information of Algorithm 1, it is possible to analyze the complexity of the DirMF model in terms of time and space consumption.
Let us first focus on the spent time. From lines 3–4 and 21–22, we observe that, for each training epoch, the training algorithm must iterate over the set of known votes, let us denote it by . Now, the entry corresponding to each of the matrix factorizations must be updated, and there are of them (lines 6, 9, 24 and 27). Finally, each updating operation requires to modify each of the entries of the hidden vectors for users and items, and there are K of them (lines 14 and 32). Notice that the updates only require standard arithmetic operations, which are performed in constant time. Hence, taking the total number of training steps, we obtain an exact time consumption of .
To analyze how this quantity scales with the size of the dataset, we can estimate it further. Typically in real world datasets, the number of known values is a constant proportion (around 1–5%) of the total numbers of pairs (user, item), and there are
of these pairs. On the other hand,
uses to be a small set (of the order of 10 possible ratings) and
m is a hyperparameter that is fixed independently of the number of entries of the dataset. Hence, the time complexity can be estimated by
, that is, the time complexity increases linearly with the number of users and items in the dataset, as well as with the number of hidden factors.
| Algorithm 1: DirMF model fitting algorithm fixing for the logistic function and shape parameters . |
![Applsci 12 01223 i001]() |
With respect to space consumption, notice that all the operations can be conducted in-place, so no extra space is needed apart from the computed values. These values correspond to the pairs of matrices of the corresponding matrix factorization for the binary matrix . Since each of these pairs has shape and , we get a space complexity of . Again, since is a fixed value independent of the size of the dataset, this complexity scales as , that is, linearly in the number of users and items and quadratically in the number of hidden factors.
2.4. Running Example
Here we describe a running example of the DirMF model using a synthetic dataset with three users and five items. For the sake of simplicity, the set of possible ratings is
, that is, like and dislike. The original rating matrix used for this example can be checked in
Table 1.
Given the ratings, we can build the softmax of every rating
(i.e., like, dislike) according to Equation (
2), as shown in
Table 2.
The parameters of the model are the latent factors for both users and items for every possible rating:
. For the sake of simplicity, we fixed the number of latent factors to
. The random initialization of the parameters for this running example is shown in
Table 3.
The optimization of the parameters is performed by a gradient descent algorithm, so the update rules defined by Equations (
4) and (
5) are applied on each
m iteration step. For instance, the update rule for the second latent factor
of item
and dislike rating (✖) is:
hence we should update that hidden factor as follows:
with
and
being the learning rate and regularization, respectively.
Table 4 contains the latent factors after one iteration using regularization
and learning rate
.
Predictions can be computed after the model has been trained by finding the score that maximizes the probability in the classification task. For instance, to determine user
’s rating of item
,
, we may compute the probability distribution of this rating as follows:
then, the model selects the most likely outcome
with a reliability of
.
3. Evaluation of Dirichlet Matrix Factorization
This section features a comprehensive description of the experiments conducted to assess the suggested model. The experimental setup, which defines the datasets, baselines and quality metrics used during the evaluation, is described in
Section 3.1.
Section 3.2 contains the experimental data as well as a comparison of the proposed method’s performance against the chosen baselines.
3.1. Experimental Setup
The MovieLens [
20], FilmTrust [
21], MyAnimeList [
22] and Netflix [
23] datasets were used to conduct the experiment. These datasets were chosen to see how splitting the rating matrix into binary rating matrices with various discrete sets of possible scores affected the results. Both MovieLens and Netflix datasets comprise ratings ranging from one to five stars. FilmTrust ratings vary from 0.5 to 4.0 in half-step increments, while the MyAnimeList dataset has a score range of 1 to 10. Furthermore, all of these experiments were conducted using the benchmark version of these datasets, which is supplied in CF4J, to assure reproducibility.
Table 5 summarizes the basic features of these datasets.
According to
Section 1, all MF models in the literature can estimate a user’s rating prediction for an item, but only a few are able to offer the reliability of both their predictions and recommendations. Baselines were chosen to provide a diverse representation of all the known MF models. The selected baselines and their resulting outputs are:
Bernoulli Matrix Factorization (BeMF) [
18], which provides both prediction and recommendation reliability;
PMF [
10], which provides predictions but no reliability;
GMF [
11], which provides predictions only;
NCF [
11], which provides predictions but no reliability.
Several hyperparameters in both the specified baselines and our model must be tweaked. By executing a grid search optimization that minimizes the mean absolute prediction error, we evaluated the prediction error of baseline models with varied values of these hyperparameters. The hyperparameters derived by this optimization method for each baseline and dataset are listed in
Table 6.
Additionally, we set the DirMF method to work with the logistic activation function . As shape parameters for the softmax function we took . Notice that this choice allows the system to straighten the most relevant votes (those with high) using a more spiky softmax function, compared to the less relevant votes (those with small) for which the softmax function used is flatter.
To assess the quality of the predictions and recommendations provided by a RS based on CF we define Mean Absolute Error (MAE) (Equation (
6)) as the mean absolute difference between the test ratings (
) and their predictions (
), and coverage (Equation (
7)) as the proportion of test ratings that CF can predict (
) with respect to the total number of test ratings. Here,
is the set of pairs
of user
u and item
i in the test split of the dataset, and
denotes its cardinality.
Furthermore, two adapted quality measures emerge by fixing a number
of top recommendations to consider: precision is defined as the averaged ratio of successful recommendations that are included in the top
n recommendations for the user
u,
, with respect to the size
n of the recommendation list (Equation (
8)); recall is the averaged proportion of successful recommendations included in the recommendation list of user
u,
, with respect to the total number of test items that user
u likes (Equation (
9)).
Here, the variable u runs over the users of the dataset, N is the total number of users, is the collection of items rated by user u in the test split and is a threshold to discern whether a user likes an item () or not ().
3.2. Experimental Results
As mentioned above, we are able to tune the output of the DirMF model by filtering out less reliable predictions, hence decreasing the coverage of the model as some predictions cannot be recommended because the model does not have enough confidence to make them, but increasing the prediction accuracy at the same time. It is fair to believe that high-reliability predictions are more evident than low-reliability predictions. For instance, if a user gave The Lord of the Rings: The Fellowship of the Ring and The Lord of the Rings: The Two Towers favorable ratings, the model will have high confidence in the user’s positive interest in The Lord of the Rings: The Return of the King and will give this prediction a high reliability score. In contrast, the same algorithm will have less trust in the user’s interest in other fantasy films, such as The Princess Bride or Willow, and will give these predictions lower reliability scores.
3.2.1. Mae vs. Coverage
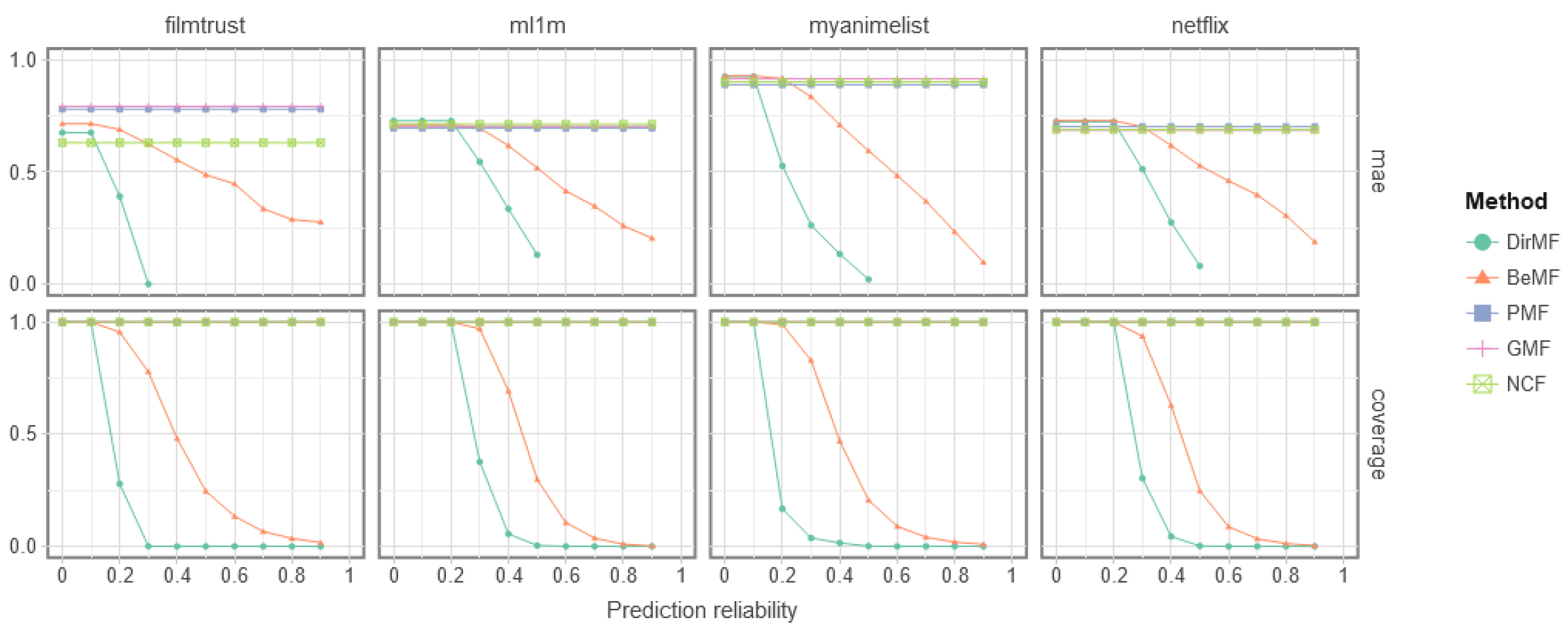
Figure 2 shows the effect of using a reliability threshold on the quality of the predictions. The plots were created by filtering out any prediction with lower reliability than the x-axis reliability. Notice that only those models that output prediction reliabilities can filter their forecasts. For this reason, PMF, GMF and NCF are represented in the graphic as a horizontal line since varying the threshold do not affect their predictions.
To be precise, the plots of
Figure 2 represent the evolution of the MAE and coverage quality measures, as specified in Equations (
6) and (
7). In this way, we compared the prediction error to the model’s predictability. As can be seen, there is a consistent trend within the plots, as unreliable predictions are filtered out, both the coverage and prediction error decrease. Furthermore, DirMF exhibits a more conservative behavior compared to BeMF, as shown by the sudden decrease in coverage which accompanies a similarly sudden decrease in MAE. This points out that the holistic interpretation of DirMF compared to BeMF allows it to extract subtle features of the data, which decreases its reliability in the prediction but also improves its ability to issue correct forecasts.
3.2.2. Recommendation Quality
To assess the recommendation quality, we calculated the precision (Equation (
8)) and recall (Equation (
9)) of the top ten recommendations (
) for each model. We set the threshold
for determining which items attract a user based on his/her test ratings to
for MovieLens and Netflix,
for FilmTrust, and
for MyAnimeList.
To create the recommendation lists predicted by each method, we have chosen the top 10 test items with the highest prediction (), omitting those with a prediction lower than . Moreover, for those methods that also provide a reliability metric, we only considered those predictions with a reliability greater than or equal to the set reliability threshold (reliability ). Notice that the roles of and are distinct: the former is a threshold in desired reliability, whereas the latter is a threshold in predicted score.
These findings are presented in
Figure 3. Again, the
x-axis represents the reliability threshold
below which predictions are filtered away. In this way, as we increase the threshold, for those methods that support reliability (DirMF and BeMF), the recall value falls while the precision value rises, as shown in that figure. Both our new DirMF approach and our previous BeMF model achieve better recall results than the other baselines when the prediction reliability is very low (between 0.4 and 0.6, depending on the dataset). Compared to BeMF, the recall of DirMF decreases more prematurely with respect to the reliability of the predictions, reinforcing the idea that the DirMF model is more conservative.
With respect to precision, it can be observed that DirMF and BeMF manage to improve the result obtained by the baselines, although each one achieves it with different levels of reliability indicating, once again, the more conservative approach of DirMF. In any case, DirMF manages to outperform not only BeMF, but all other baselines in absolute terms of precision.
3.2.3. Time and Space Complexity
We would like to finish this section with some words on the time and space complexity of the used algorithms. As computed in
Section 2.3, DirMF has a time complexity of
and a space complexity of
. These values are similar to the ones of PMF and BeMF, since both are based on a matrix factorization. Additionally, these bounds are smaller than the time and space complexity of the neural network-based models GMF and NCF. Indeed, these methods, apart from computing a matrix factorization, also need to compute the weights of the inner product (GMF) or even those of a whole neural network (NCF) used to combine the hidden factors.
In this way, DirMF is as efficient in terms of time and space as the existing MF methods, and even more efficient with respect to those that apply deep learning techniques.
4. Conclusions
The DirMF model, which is an MF-based CF method that yields not just predictions for things that have not been evaluated by users, but also the reliability of these predictions, is provided in this study. By approaching the recommendation process as a classification problem rather than a regression one, this result is accomplished. The DirMF model’s output pair of both prediction and reliability allows us to calibrate it to achieve the correct balance between the quality and quantity of the predictions (i.e., to reduce the prediction error by limiting the model’s coverage).
DirMF builds on the progress made with our previous model, BeMF [
18], where the use of other probability distributions as underlying assumptions for the MF method was identified as future work worth pursuing. This is exactly what has been done, using a Dirichlet probability distribution as the underlying assumption instead of Bernoulli random variables, which assume independence between the ratings.
Experimental results show that DirMF and BeMF achieve better recall results than the baselines when the prediction reliability is very low (between 0.4 and 0.6, depending on the dataset), although the recall of the former decreases more quickly with respect to the reliability of the predictions. Regarding precision, again, our model DirMF achieves better values than those obtained by the baselines, improving BeMF’s results on some datasets. According to those results, we can conclude that our model DirMF is more conservative with its predictions than BeMF. This means that DirMF tends to be more prudent when issuing predictions, but those emitted have a much larger chance of being accurate. In this manner, the quality of the DirMF predictions with large thresholds is better that for BeMF, at the cost of issuing less predictions. This behavior is desirable in those scenarios in which failure is highly penalized, like customers with a small chance of re-entering the system, medical predictions, or critical industrial forecasting.
It is worth mentioning that BeMF and DirMF are two methods that, by design, incorporate reliability at the core of the training process of the matrix factorization algorithm. For this reason, BeMF and DirMF are able to outperform other methods, which do not intrinsically treat reliability, in terms of accuracy of predictions. The probabilistic assumption that rating is a process that must be modeled as several binary classification problems (as done by BeMF and DirMF), instead of a single regression problem (as done by PMF, GMF, NCF) seems to be much more accurate in most scenarios, leading to better predictions. This trend becomes even more prominent when we set a reliability threshold : with this threshold, BeMF and DirMF are able to filter out non-reliable prediction, which are those that, more likely, will be misclassified; whereas PMF, GMF and NCF cannot make use of this capability, since they do not implement a native management of reliability.
As a future work, we suggest examining the quality of our model in terms other than accuracy, that is, novelty, diversity and discovery. Similarly, we advise testing the model’s stability against shilling attacks, which are used to discredit or promote some items over the rest. Furthermore, our model might be expanded to include both social and content information to increase the quality of the predictions.


 ,
, 






{kind=link}
{kind=link}
{kind=link}