
Latent Dimensions of Auto-Encoder as Robust Features for Inter-Conditional Bearing Fault Diagnosis

 , , , and
, , , and
Abstract
:1. Introduction
2. Problem Description and Related Work
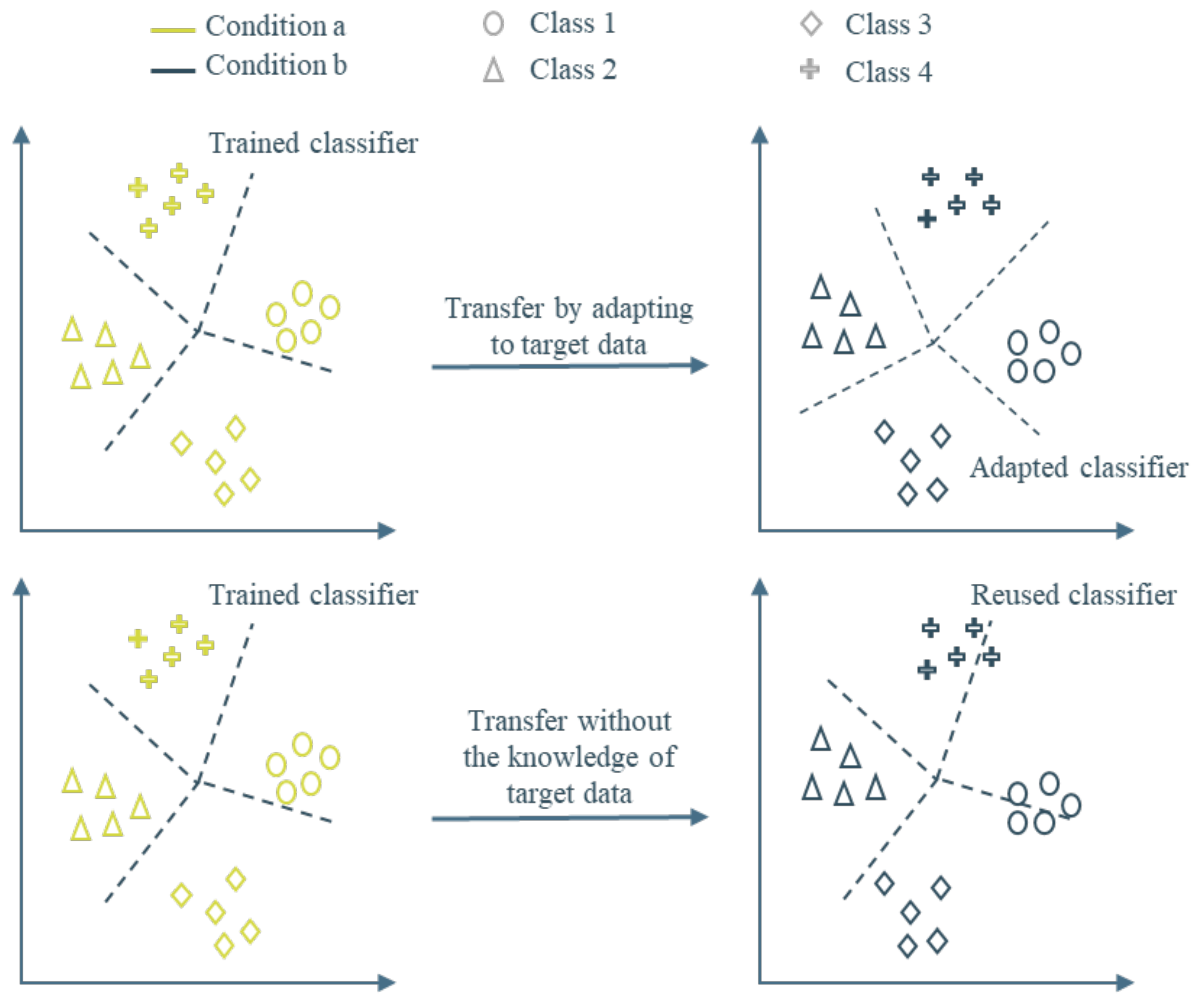
- The empirical evaluation of Auto-Encoder latent features as robust features across conditions was performed. It was systematically performed using various transfer tasks of two widely used open source bearing fault datasets.
- A simple methodology combining latent values of the Auto-Encoder and their proximity in the latent space is proposed for robust inter-conditional bearing fault diagnosis, given only the source domain data for training.
- The results of the proposed method are presented and compared with the results of the other state-of-the-art methods.
3. Materials and Methods
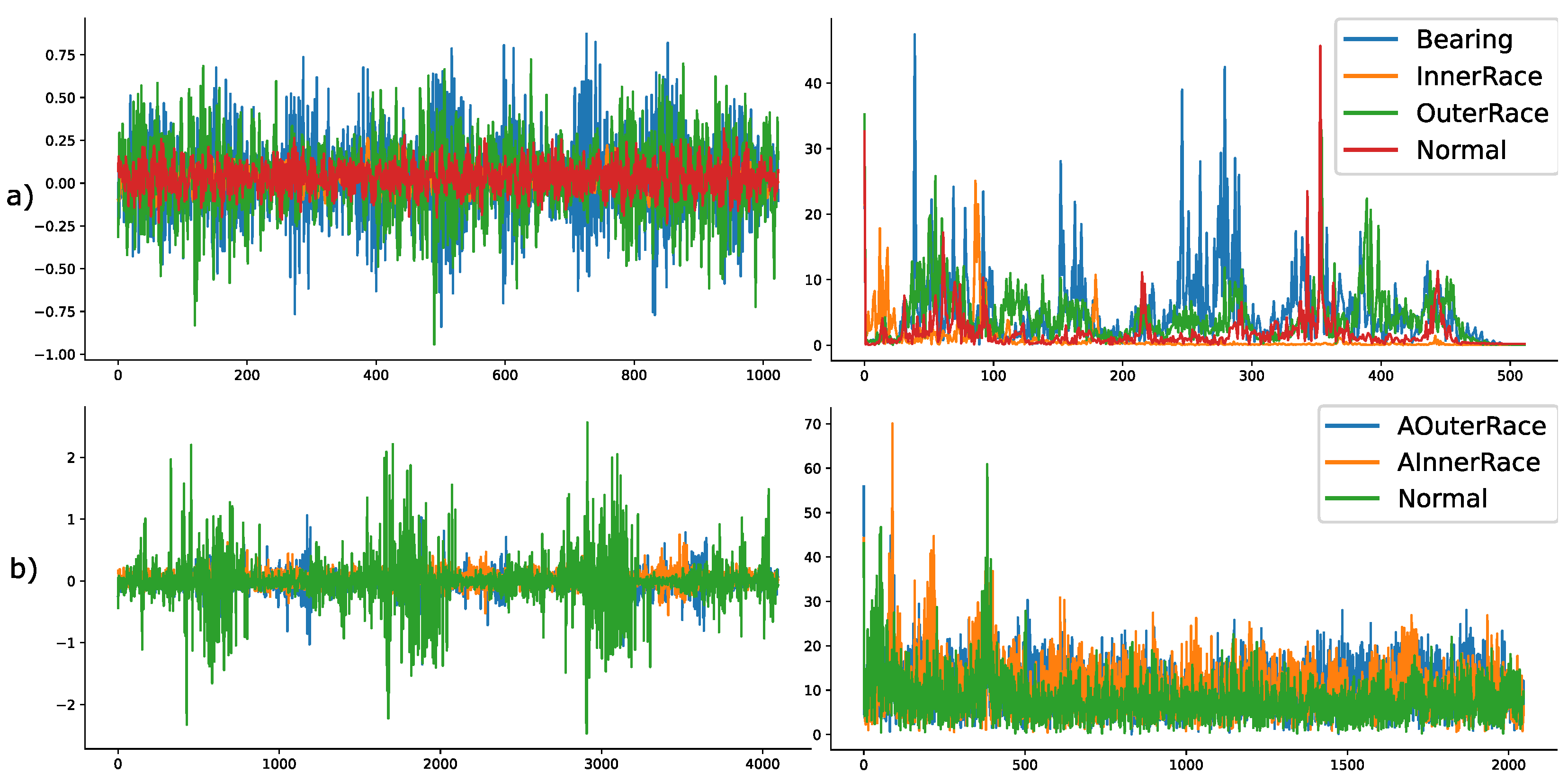
3.1. Data-Sets
3.1.1. CWRU Dataset
3.1.2. PU Data-Set
3.2. Transfer Tasks
3.3. Observation Definition
4. Proposed Method
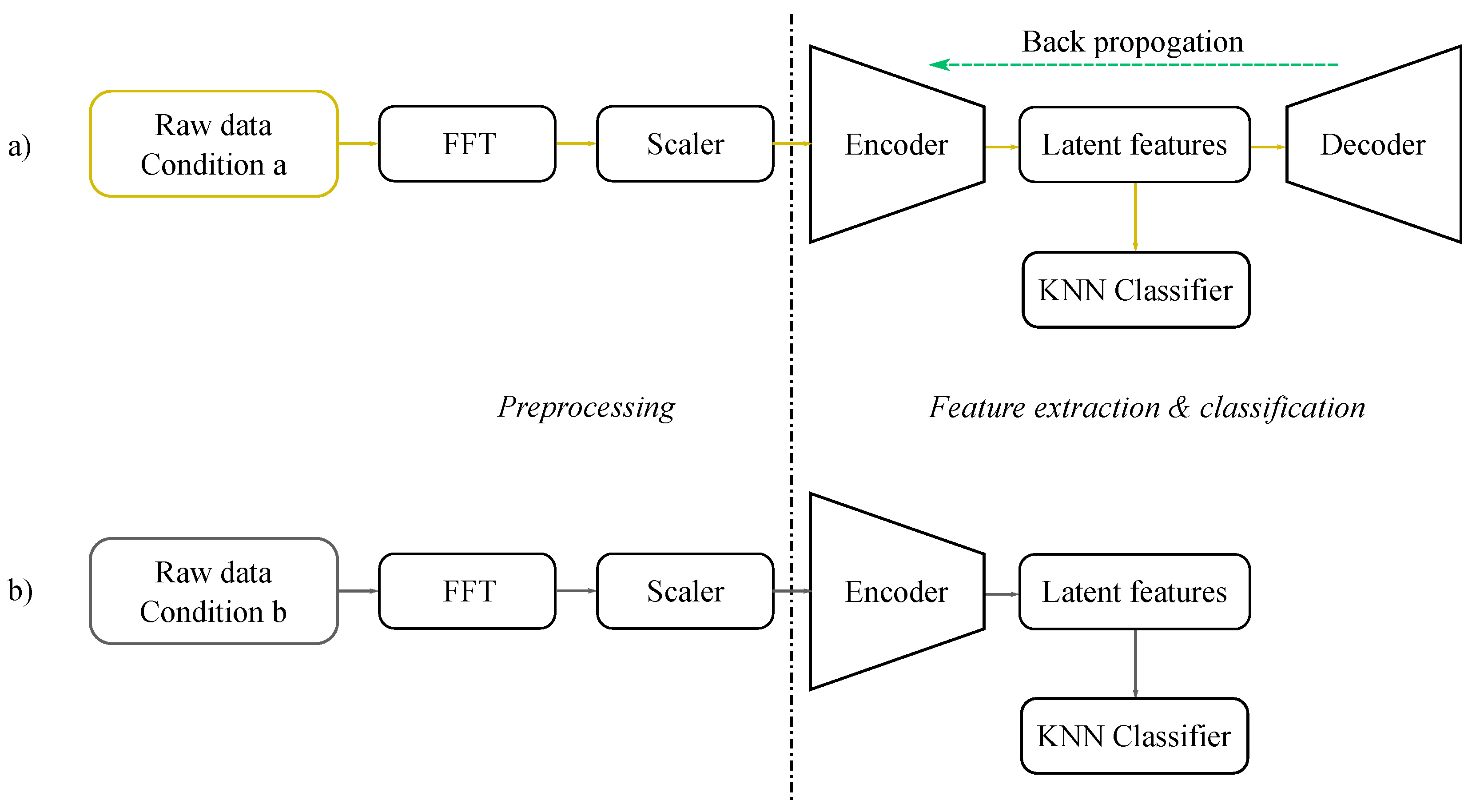
4.1. Auto-Encoder for Feature Extractor
Auto-Encoder Architecture
4.2. Data Preparation for Auto-Encoders
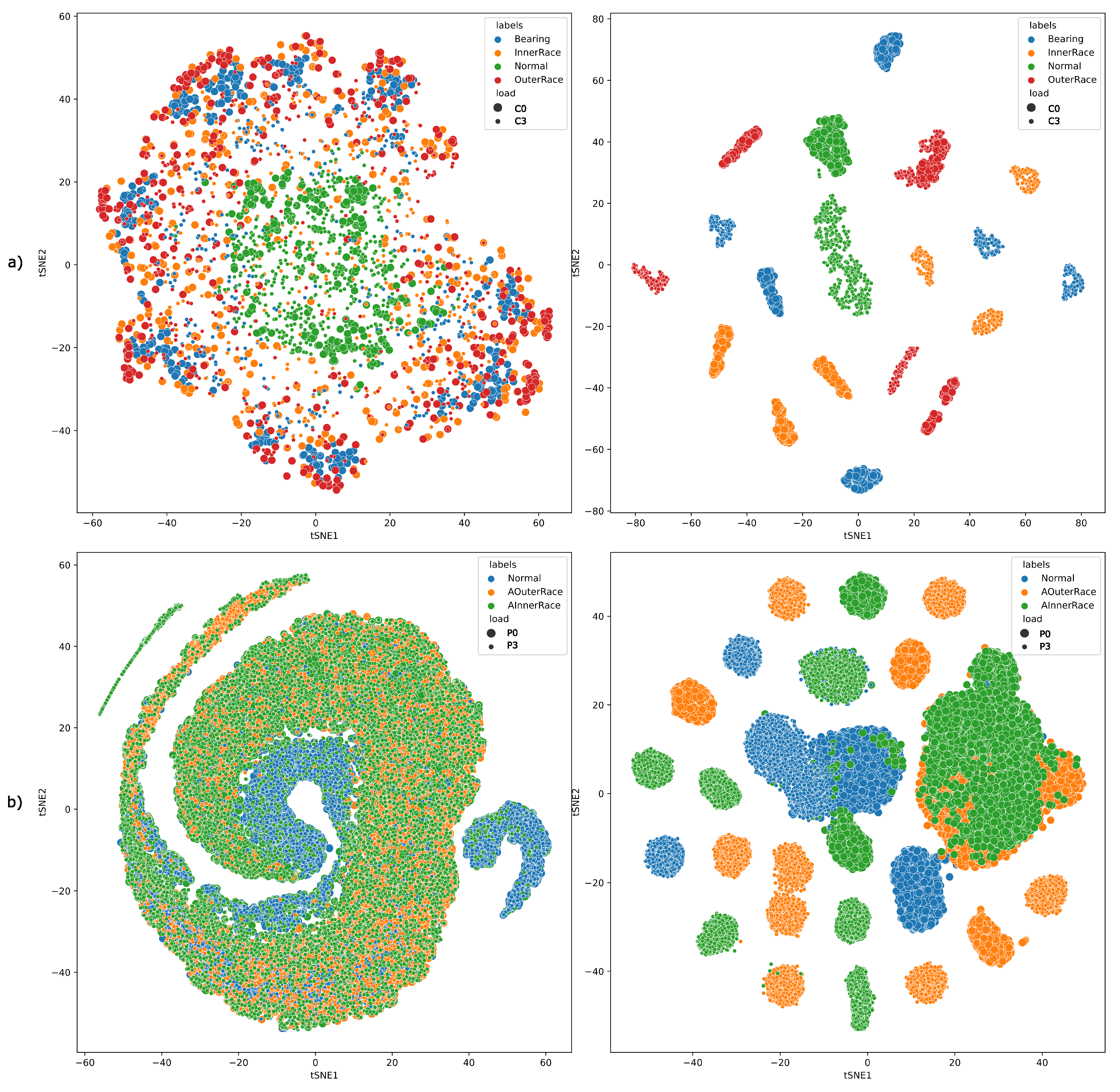
4.3. Feature Extraction and Analysis
4.4. K-Nearest Neighbors Classifier
5. Experimental Validation
5.1. Computational Unit and Training Time
5.2. Compared Methods
5.3. Evaluation Metric, Training and Testing Process
5.4. Architecture of the Auto-Encoder
| Algorithm 1 Pseudo algorithm used for training and testing various transfer tasks of CWRU and PU datasets. |
|
6. Results
6.1. CWRU Data-Set
6.2. Paderborn Dataset
7. Conclusions
- (1)
- The proposed method performs more robust classification compared to other transfer learning methods. For many inter-conditional transfer tasks, the MLCAE-KNN source-only method performs as good or better than the other domain adaptation methods that consider certain information from the target domain.
- (2)
- Though the proposed methodology is robust, for some transfer tasks, it has a certain deviation in the accuracies across different runs (up to 6% for certain tasks of the Paderborn dataset, as presented in Table 5).
- (3)
- In our observation with the experiments of MLCAE-KNN, training a classifier using data from higher parameter settings (rotational speed, radial load, etc.) and transferring the learning onto lower settings provides better a transfer of class learning compared to the other way around.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Z.; Wang, K.; He, Y. Industry 4.0—Potentials for Predictive Maintenance. In 6th International Workshop of Advanced Manufacturing and Automation; Atlantis Press: Paris, France, 2016. [Google Scholar] [CrossRef] [Green Version]
- Teixeira, H.N.; Lopes, I.; Braga, A.C. Condition-based maintenance implementation: A literature review. Procedia Manuf. 2020, 51, 228–235. [Google Scholar] [CrossRef]
- Jung, D.; Sundstrom, C. A Combined Data-Driven and Model-Based Residual Selection Algorithm for Fault Detection and Isolation. IEEE Trans. Control Syst. Technol. 2019, 27, 616–630. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez-Jimenez, D.; Del-Olmo, J.; Poza, J.; Garramiola, F.; Madina, P. Data-driven fault diagnosis for electric drives: A review. Sensors 2021, 21, 4024. [Google Scholar] [CrossRef]
- Aherwar, A. An investigation on gearbox fault detection using vibration analysis techniques: A review. Aust. J. Mech. Eng. 2012, 10, 169–183. [Google Scholar] [CrossRef]
- Wei, Y.; Li, Y.; Xu, M.; Huang, W. A review of early fault diagnosis approaches and their applications in rotating machinery. Entropy 2019, 21, 409. [Google Scholar] [CrossRef] [Green Version]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Wang, X.; Shen, C.; Xia, M.; Wang, D.; Zhu, J.; Zhu, Z. Multi-scale deep intra-class transfer learning for bearing fault diagnosis. Reliab. Eng. Syst. Saf. 2020, 202, 107050. [Google Scholar] [CrossRef]
- Toma, R.N.; Prosvirin, A.E.; Kim, J.M. Bearing fault diagnosis of induction motors using a genetic algorithm and machine learning classifiers. Sensors 2020, 20, 1884. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Xing, K.; Bai, R.; Sun, D.; Meng, Z. An enhanced convolutional neural network for bearing fault diagnosis based on time–frequency image. Meas. J. Int. Meas. Confed. 2020, 157, 107667. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, Y.; Guo, L.; Gao, H.; Hong, X.; Song, H. A new bearing fault diagnosis method based on modified convolutional neural networks. Chin. J. Aeronaut. 2020, 33, 439–447. [Google Scholar] [CrossRef]
- Patel, S.P.; Upadhyay, S.H. Euclidean distance based feature ranking and subset selection for bearing fault diagnosis. Expert Syst. Appl. 2020, 154, 113400. [Google Scholar] [CrossRef]
- Zhang, K.; Xu, Y.; Liao, Z.; Song, L.; Chen, P. A novel Fast Entrogram and its applications in rolling bearing fault diagnosis. Mech. Syst. Signal Process. 2021, 154, 107582. [Google Scholar] [CrossRef]
- Hoang, D.T.; Kang, H.J. A survey on Deep Learning based bearing fault diagnosis. Neurocomputing 2019, 335, 327–335. [Google Scholar] [CrossRef]
- Li, C.; Zhang, S.; Qin, Y.; Estupinan, E. A systematic review of deep transfer learning for machinery fault diagnosis. Neurocomputing 2020, 407, 121–135. [Google Scholar] [CrossRef]
- Li, X.; Hu, Y.; Zheng, J.; Li, M.; Ma, W. Central moment discrepancy based domain adaptation for intelligent bearing fault diagnosis. Neurocomputing 2021, 429, 12–24. [Google Scholar] [CrossRef]
- Ma, H.; Li, S.; An, Z. A fault diagnosis approach for rolling bearing based on convolutional neural network and nuisance attribute projection under various speed conditions. Appl. Sci. 2019, 9, 1603. [Google Scholar] [CrossRef] [Green Version]
- Guo, S.; Zhang, B.; Yang, T.; Lyu, D.; Gao, W. Multitask Convolutional Neural Network with Information Fusion for Bearing Fault Diagnosis and Localization. IEEE Trans. Ind. Electron. 2020, 67, 8005–8015. [Google Scholar] [CrossRef]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]
- Lessmeier, C.; Kimotho, J.K.; Zimmer, D.; Sextro, W. Condition monitoring of bearing damage in electromechanical drive systems by using motor current signals of electric motors: A benchmark data set for data-driven classification. In Proceedings of the Third European Conference of the Prognostics and Health Management Society 2016, Bilbao, Spain, 5–8 July 2016. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
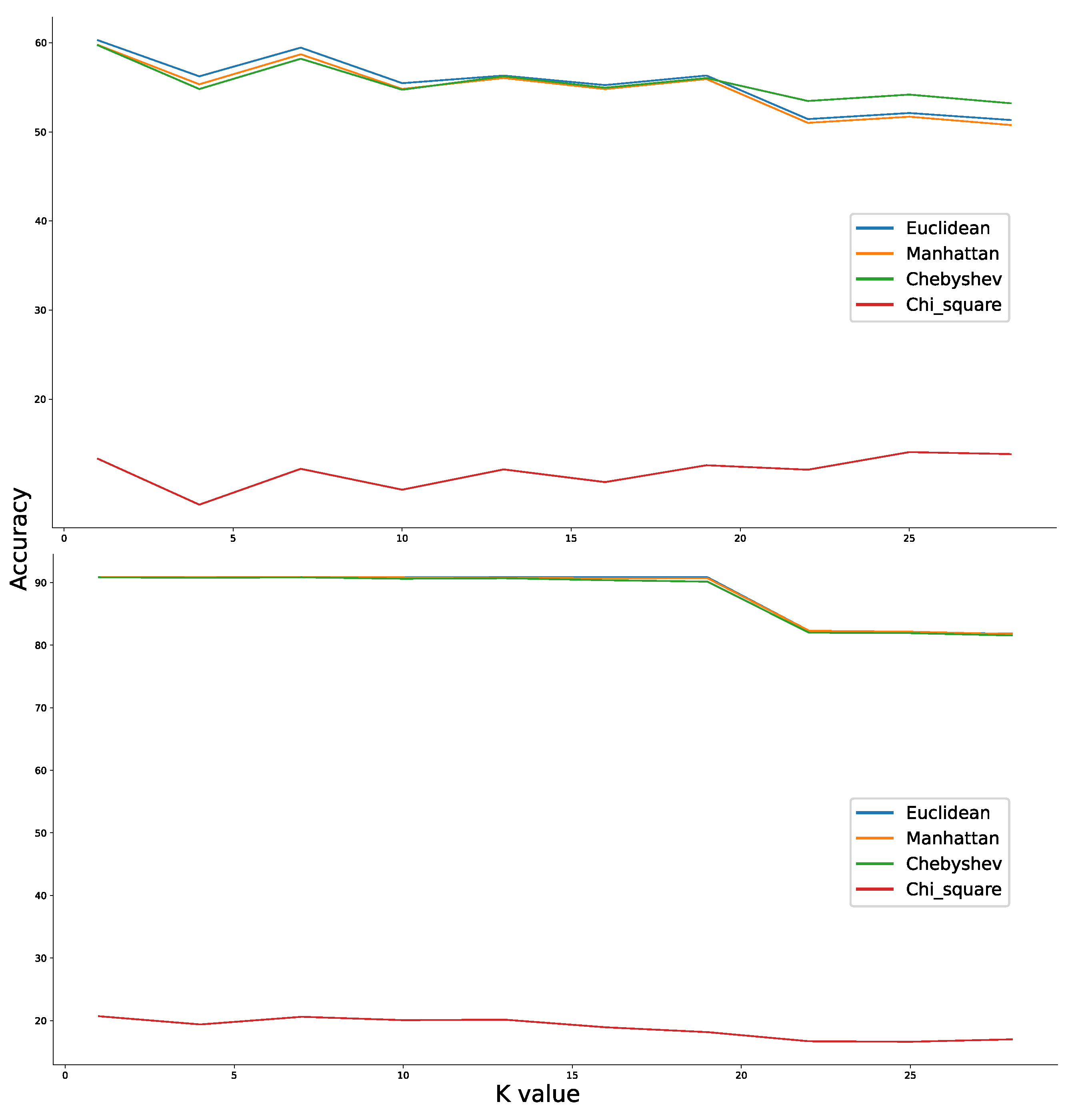
- Hu, L.Y.; Huang, M.W.; Ke, S.W.; Tsai, C.F. The distance function effect on k-nearest neighbor classification for medical datasets. SpringerPlus 2016, 5, 1304. [Google Scholar] [CrossRef] [Green Version]
- Abu Alfeilat, H.A.; Hassanat, A.B.; Lasassmeh, O.; Tarawneh, A.S.; Alhasanat, M.B.; Eyal Salman, H.S.; Prasath, V.S. Effects of Distance Measure Choice on K-Nearest Neighbor Classifier Performance: A Review. Big Data 2019, 7, 221–248. [Google Scholar] [CrossRef] [PubMed] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CWRU Dataset | |||
| Name | Motor Speed (RPM) | Load (HP) | Sampling Frequency |
| C0 | 1797 | 0 | 12 KHz |
| C1 | 1772 | 1 | 12 KHz |
| C2 | 1750 | 2 | 12 KHz |
| C3 | 1730 | 3 | 12 KHz |
| Paderborn Dataset | |||
| Name | Condition (N_M_F) | Sampling Frequency | |
| P0 | N09_M07_F10 | 64 KHz | |
| P1 | N15_M01_F10 | 64 KHz | |
| P2 | N15_M07_F04 | 64 KHz | |
| P3 | N15_M07_F10 | 64 KHz | |
| Method | Reference | Source Only |
|---|---|---|
| SVM | [8] | Yes |
| CNN | [8] | Yes |
| CNN-MMD | [8] | No |
| MDDAN | [8] | No |
| MDIAN | [8] | No |
| CMD | [16] | No |
| MLCAE-KNN | Proposed | Yes |
| Layers | Parameters |
|---|---|
| Conv1 | Kernel size: (5,1), number of Kernels: 30, Stride: 1, activation: relu, Padding: Same |
| Pool1 | Average Pooling, Size: 4, Stride: 1 |
| Conv2 | Kernel size: (3,1), number of Kernels: 15, Stride: 1, activation: relu, Padding: Same |
| Pool2 | Average Pooling, Size: 2, Stride: 1 |
| Flat1 | converts 2d output from previous layer to 1d |
| Dense1 | Dense, Size: (50,1), activation: relu |
| Latent | Dense, Size: (20,1), activation: relu |
| Dense2 | Dense, Size: (CWRU: (100,1), PU: (256,1)), activation: relu |
| UpSamp1 | Upsampling1d, Size: 2 |
| ConvT1 | Conv1dTranspose, Kernel size: (3,1), number of Kernels: 15, Stride: 1, activation: |
| relu, Padding: Same | |
| UpSamp2 | Upsampling1d, Size: 4 |
| ConvT2 | Conv1dTranspose, Kernel size: (5,1), number of Kernels: 30 Stride: 1, activation: |
| relu, Padding: Same | |
| ConvT3 | Conv1dTranspose, Kernel size: (3,1), number of Kernels: 1 |
| Stride: 1, activation: sigmoid, Padding: Same |
| Transfer Task | SVM | CNN | CNN-MMD | MDDAN | MDIAN | CMD | MLCAE-KNN |
|---|---|---|---|---|---|---|---|
| C0 → C1 | 70.70 | 72.25 | 81.00 | 87.15 | 99.60 | - | 100 |
| C0 → C2 | 66.45 | 70.55 | 79.90 | 90.60 | 99.30 | 95.54 | 100 |
| C0 → C3 | 63.40 | 62.45 | 55.85 | 91.65 | 99.10 | 99.54 | 100 (3%) |
| C1 → C0 | 71.30 | 87.30 | 88.95 | 84.00 | 99.70 | - | 100 |
| C1 → C2 | 70.00 | 89.80 | 88.70 | 92.40 | 99.65 | - | 100 |
| C1 → C3 | 74.00 | 74.70 | 80.50 | 94.20 | 99.80 | - | 100 (5%) |
| C2 → C0 | 62.85 | 60.35 | 64.65 | 87.40 | 97.60 | 100 | 99.8 |
| C2 → C1 | 61.60 | 75.50 | 79.80 | 91.95 | 99.45 | - | 99.7 |
| C2 → C3 | 67.65 | 84.30 | 79.95 | 91.50 | 99.45 | 96.9 | 100 (2%) |
| C3 → C0 | 65.30 | 66.90 | 75.25 | 84.25 | 97.45 | 100 | 99.9 (2%) |
| C3 → C1 | 65.70 | 81.15 | 71.15 | 87.35 | 98.60 | - | 99.9 (3%) |
| C3 → C2 | 63.25 | 74.95 | 74.85 | 92.15 | 99.50 | 100 | 100 |
| Transfer Task | CNN | CMD | MLCAE-KNN |
|---|---|---|---|
| P0 → P1 | 39.65 | 70.44 | 59.1 (6%) |
| P0 → P2 | 51.33 | 75.30 | 62.7 (6%) |
| P0 → P3 | 40.04 | 69.73 | 58.8 (6%) |
| P1 → P0 | 44.43 | 82.62 | 45.3 (5%) |
| P1 → P2 | 82.32 | 94.01 | 83.8 (3%) |
| P1 → P3 | 89.39 | 91.63 | 94.9 (1%) |
| P2 → P0 | 39.23 | 78.03 | 72.5 (5%) |
| P2 → P1 | 57.10 | 89.97 | 88.7 (6%) |
| P2 → P3 | 50.94 | 80.34 | 89.6 (6%) |
| P3 → P0 | 43.52 | 70.93 | 51.0 (4%) |
| P3 → P1 | 94.11 | 94.99 | 95.2 (1%) |
| P3 → P2 | 47.43 | 88.87 | 85.6 (5%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kancharla, C.R.; Vankeirsbilck, J.; Vanoost, D.; Boydens, J.; Hallez, H. Latent Dimensions of Auto-Encoder as Robust Features for Inter-Conditional Bearing Fault Diagnosis. Appl. Sci. 2022, 12, 965. https://doi.org/10.3390/app12030965
Kancharla CR, Vankeirsbilck J, Vanoost D, Boydens J, Hallez H. Latent Dimensions of Auto-Encoder as Robust Features for Inter-Conditional Bearing Fault Diagnosis. Applied Sciences. 2022; 12(3):965. https://doi.org/10.3390/app12030965
Chicago/Turabian StyleKancharla, Chandrakanth R., Jens Vankeirsbilck, Dries Vanoost, Jeroen Boydens, and Hans Hallez. 2022. "Latent Dimensions of Auto-Encoder as Robust Features for Inter-Conditional Bearing Fault Diagnosis" Applied Sciences 12, no. 3: 965. https://doi.org/10.3390/app12030965
APA StyleKancharla, C. R., Vankeirsbilck, J., Vanoost, D., Boydens, J., & Hallez, H. (2022). Latent Dimensions of Auto-Encoder as Robust Features for Inter-Conditional Bearing Fault Diagnosis. Applied Sciences, 12(3), 965. https://doi.org/10.3390/app12030965