
AidIR: An Interactive Dialog System to Aid Disease Information Retrieval


Abstract
:1. Introduction
- Enabling users to retrieve information on diseases corresponding to coronaviruses and diseases transmitted by vector mosquitoes with natural language interaction;
- Enabling users to retrieve information with Line, a well-known chat medium in Asia;
- Fine-tuning the pre-trained BERT model [8] with the mask LM task and disease corpora;
- Proposing a weighting method to jointly train a BERT model [9] for domain classification and sequence labeling;
- Inventing regular expressions to match some types of numbers in the sentence and normalizing those numbers with special tokens;
- Allowing the system to continue learning the dialog policy online.
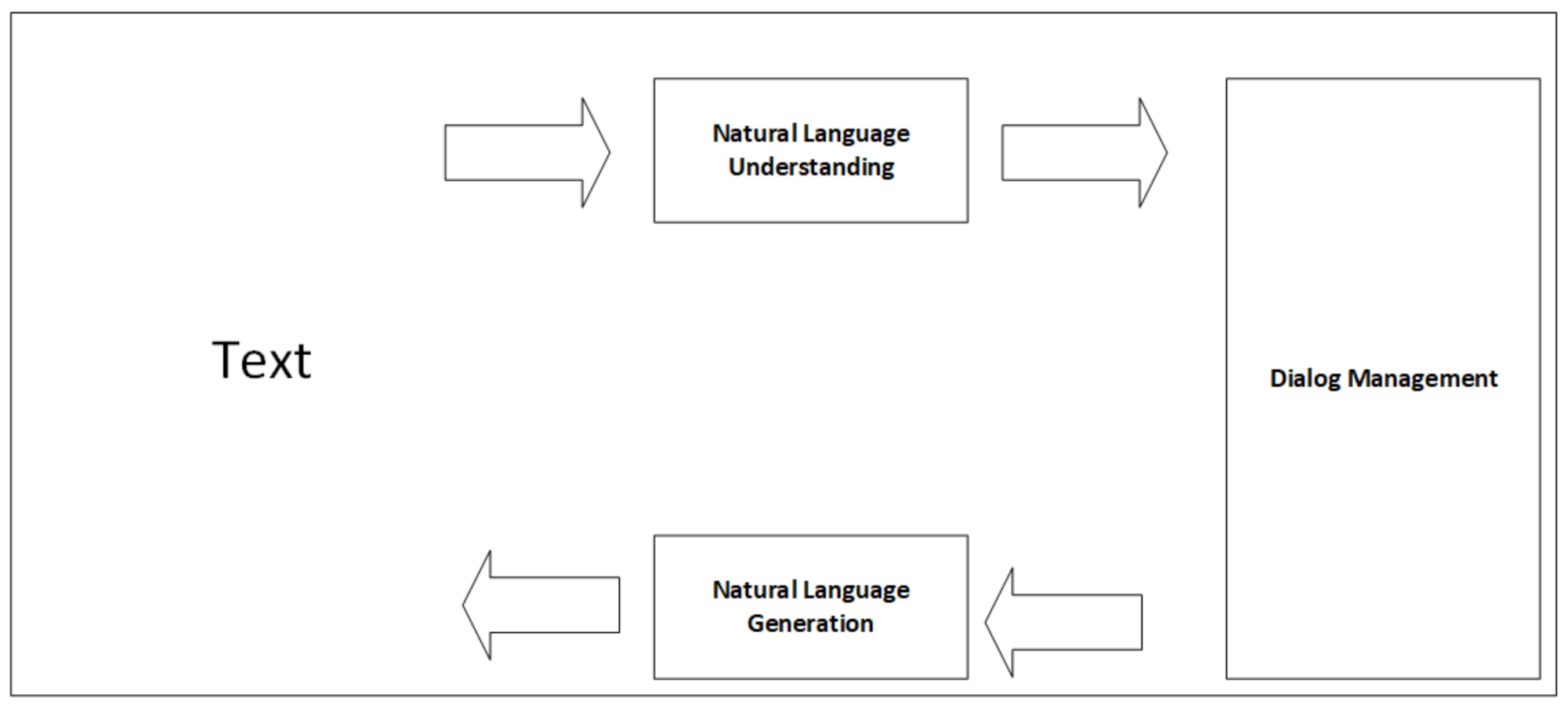
2. Task-Oriented Dialog System
2.1. Natural Language Understanding (NLU)
2.2. Dialog Management (DM)
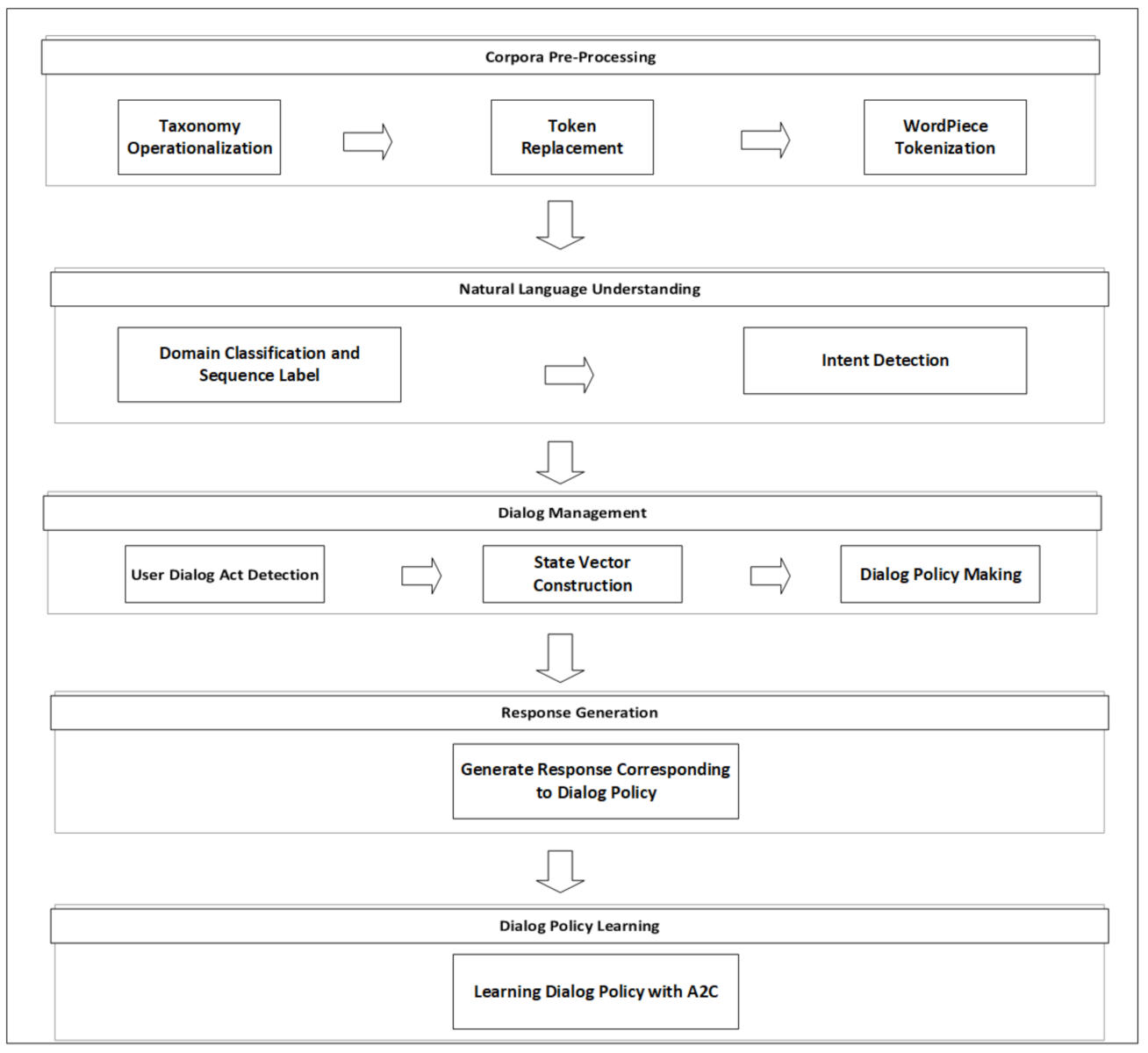
3. Architecture of AidIR
3.1. Corpus Pre-Processing
3.1.1. Operationalization of Taxonomy
3.1.2. Token Replacement
- : a special token for ? degrees Celsius;
- : a special token for the start of the incubation period;
- : a special token for the end of the incubation period.
- 潛伏期.?[09]+∖.?[0-9]?至[0-9]+.?[0-9]天: this matches sentences such as 潛伏期5 至10 天(incubation period is from 5 to 10 days);
- .*[0-9]+∖.?[0-9]: this matches sentences such as 體溫39 C (body temperature is 39 degrees Celsius).
3.1.3. WordPiece Tokenization
- 痢: one of the Chinese characters for diarrhea;
- 泌: one of the Chinese characters for secretion;
- 沫: one of the Chines characters for droplets;
- : our special token for body temperature;
- and [end_incubation]: our special token for the start and end of the incubation period.
3.2. Domain Classification and Sequence Label in AidIR
3.2.1. Pre-Training with Mask LM Task and Medical Corpora
3.2.2. BERT for Sequence Label and Domain Classification
3.3. Dialog Management in AidIR
3.3.1. User Dialog Act Detection
3.3.2. Dialog Policy Making
3.4. Response Templates Corresponding to Each Dialog Policy
3.5. Dialog Policy Learning
3.5.1. Warm-Up Stage
3.5.2. Online Learning Stage
3.5.3. Rewards Corresponding to Each State
3.6. Implementation of AidIR
4. Experimental Results
4.1. Fine-Tuning Results of BERT Model with Mask LM Task
4.2. Training Results of ABERT
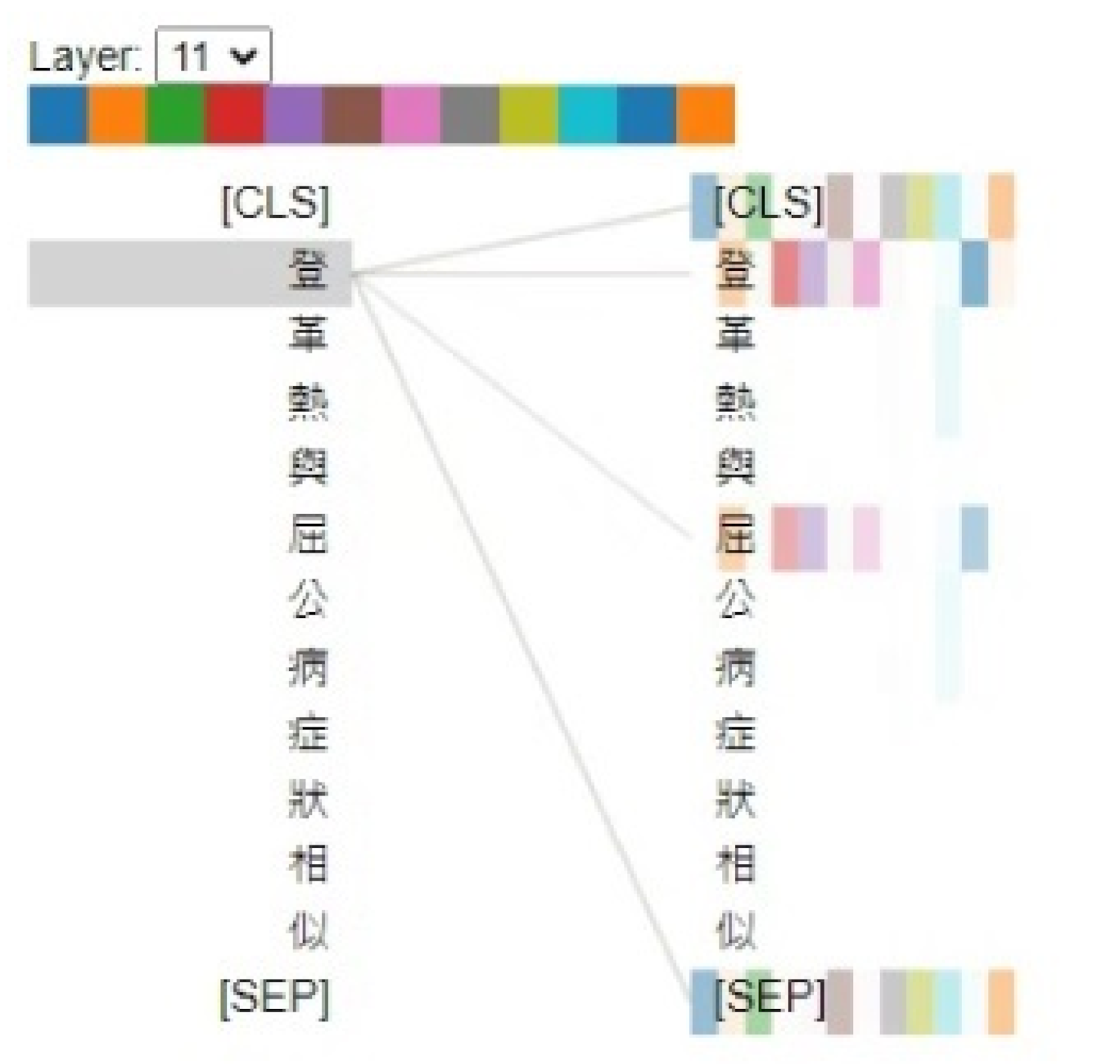
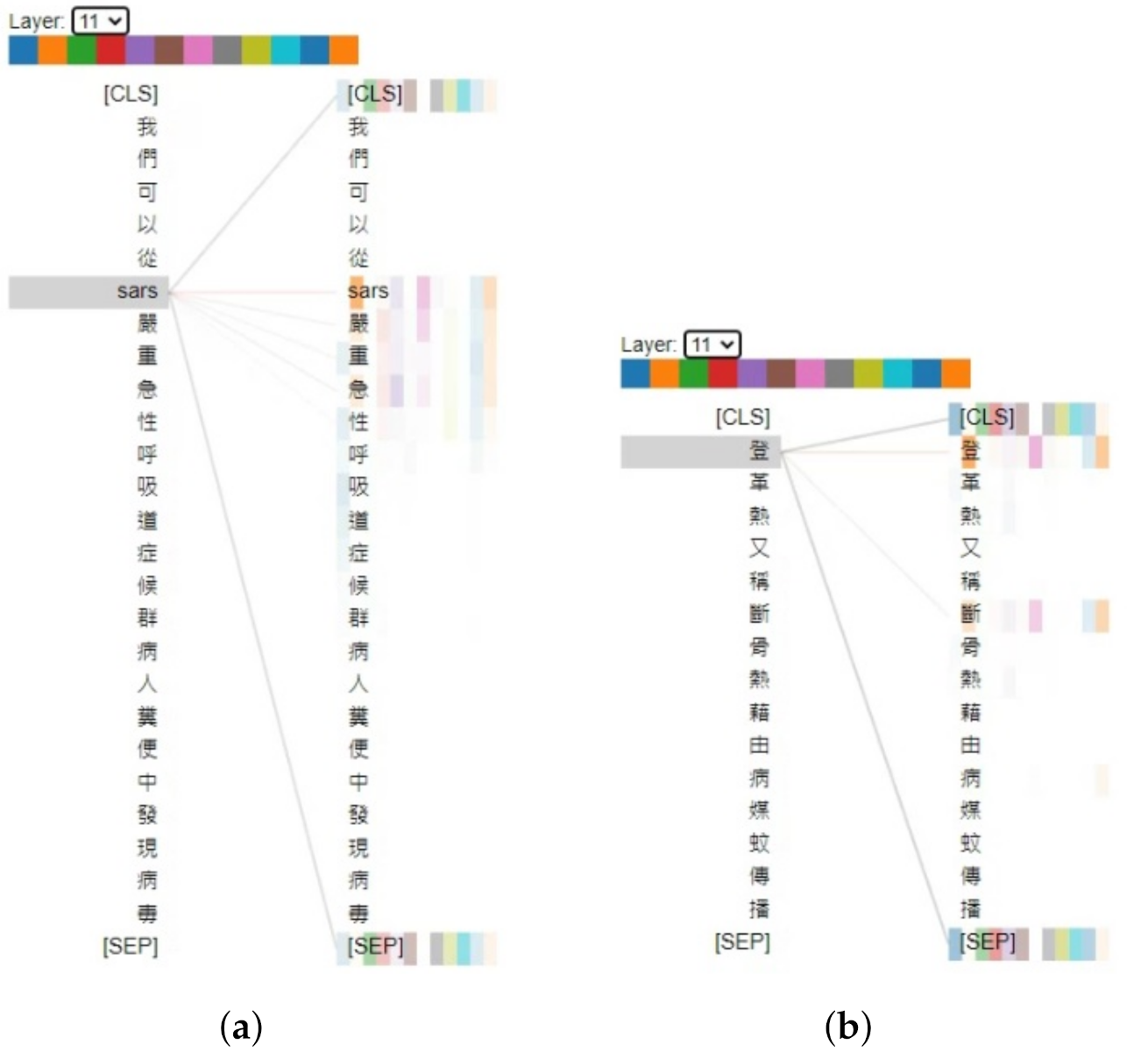
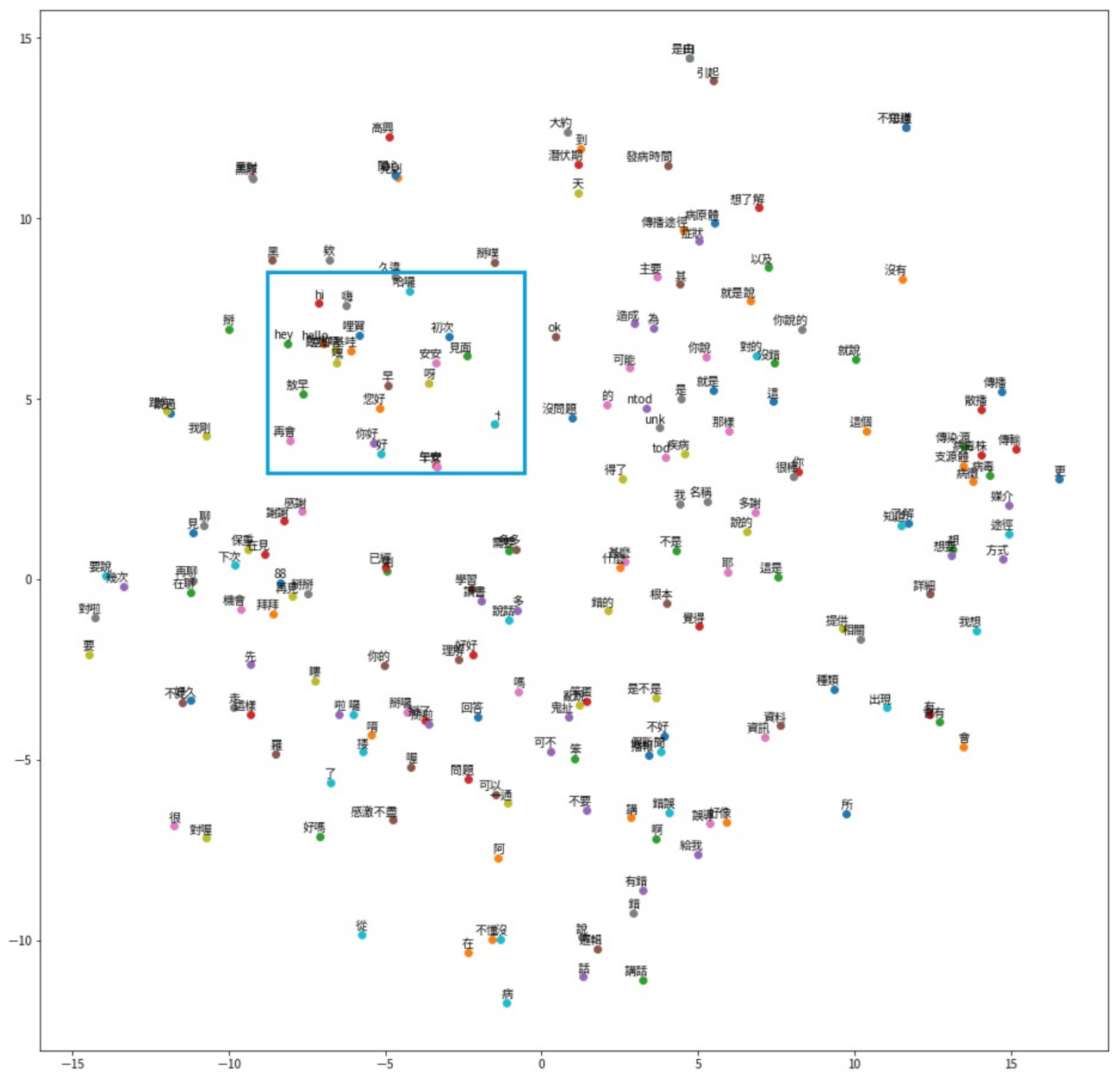
4.3. Visualization of ABERT Model
4.4. Results of Dialog Act Models
4.5. Results of Subjective Evaluation
4.6. Comparison between AidIR and Systems with GUI
5. Dialog Samples of AidIR
5.1. User Provides Enough Information at First
5.2. AidIR Requests and Checks Information
5.3. AidIR Checks with User but Got Rejected
5.4. User Asks Many Questions Related to One Disease
5.5. Error Information Included in Rejection Dialog
5.6. AidIR Requests More Information
6. Conclusions
7. Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Digital 2021: Global Overview Report. Available online: https://datareportal.com/reports/digital-2021-global-overview-report (accessed on 30 June 2021).
- Tagliabue, F.; Galassi, L.; Mariani, P. The “Pandemic” of Disinformation in COVID-19. SN Compr. Clin. Med. 2020, 2, 1287–1289. [Google Scholar] [CrossRef] [PubMed]
- Swire-Thompson, B.; Lazer, D. Public Health and Online Misinformation: Challenges and Recommendations. Annu. Rev. Public Health 2020, 41, 433–451. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Loomba, S.; de Figueiredo, A.; Piatek, S.J.; de Graaf, K.; Larson, H.J. Measuring the impact of COVID-19 vaccine misinformation on vaccination intent in the UK and USA. Nat. Hum. Behav. 2021, 5, 337–348. [Google Scholar] [CrossRef] [PubMed]
- Leung, J.; Schoultz, M.; Chiu, V.; Bonsaksen, T.; Ruffolo, M.; Thygesen, H.; Price, D.; Geirdal, A. Concerns over the spread of misinformation and fake news on social media—Challenges amid the coronavirus pandemic. In Proceedings of the 3rd International Electronic Conference on Environmental Research and Public Health, Online, 11–25 January 2021; pp. 1–6. [Google Scholar]
- PubMed. Available online: https://pubmed.ncbi.nlm.nih.gov/ (accessed on 30 June 2021).
- LINE—Statistics and Facts. Available online: https://www.statista.com/topics/1999/line/#dossierKeyfigures (accessed on 30 June 2021).
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Chen, H.; Liu, X.; Yin, D.; Tang, J. A Survey on Dialogue Systems: Recent Advances and New Frontiers. SIGKDD Explor. Newsl. 2017, 19, 25–35. [Google Scholar] [CrossRef]
- Williams, J.D.; Raux, A.; Henderson, M. The Dialog State Tracking Challenge Series: A Review. Dialogue Discourse 2016, 7, 4–33. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing. 2020. Available online: https://web.stanford.edu/~jurafsky/slp3/ (accessed on 30 June 2021).
- Chen, Y.N.; Celikyilmaz, A.; Hakkani-Tür, D. Deep Learning for Dialogue Systems. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 8–14. [Google Scholar]
- Raschka, S. Naive Bayes and Text Classification I-Introduction and Theory. arXiv 2017, arXiv:1410.5329. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Website of Center for Disease Control in Taiwan, ROC. Available online: https://www.cdc.gov.tw/ (accessed on 30 June 2021).
- Regular Expression Language-Quick Reference. 2021. Available online: https://docs.microsoft.com/en-us/dotnet/standard/base-types/regular-expression-language-quick-reference (accessed on 30 June 2021).
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef] [Green Version]
- Jieba Tokenization Tool. Available online: https://github.com/fxsjy/jieba (accessed on 30 June 2021).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 2, pp. 3111–3119. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.Y.; Dernoncourt, F. Sequential Short-Text Classification with Recurrent and Convolutional Neural Networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 515–520. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Harley, T.; Lillicrap, T.P.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1928–1937. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In Proceedings of the 12th International Conference on Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999; pp. 1057–1063. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Vitay, J. Deep Reinforcement Learning. Available online: https://julien-vitay.net/deeprl/ (accessed on 30 June 2021).
- Su, P.H.; Gasic, M.; Mrksic, N.; Rojas-Barahona, L.; Ultes, S.; Vandyke, D.; Wen, T.H.; Young, S. Continuously Learning Neural Dialogue Management. arXiv 2016, arXiv:1606.02689. [Google Scholar]
- Su, P.H.; Budzianowski, P.; Ultes, S.; Gašić, M.; Young, S. Sample-efficient Actor-Critic Reinforcement Learning with Supervised Data for Dialogue Management. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, Saarbrücken, Germany, 7–9 September 2017; pp. 147–157. [Google Scholar] [CrossRef]
- Threading—Thread-Based Parallelism. Available online: https://docs.python.org/3/library/threading.html#module-threading (accessed on 30 June 2021).
- PyTorch. Available online: https://pytorch.org/ (accessed on 30 June 2021).
- Scikit-Learn. Available online: https://scikit-learn.org/stable/index.html (accessed on 30 June 2021).
- LINE Developers. Available online: https://developers.line.biz/en/ (accessed on 30 June 2021).
- re—Regular Expression Operations. Available online: https://docs.python.org/3/library/re.html (accessed on 30 June 2021).
- Vig, J. A Multiscale Visualization of Attention in the Transformer Model. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Florence, Italy, 28 July–2 August 2019; pp. 37–42. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types of Intents | Description |
|---|---|
| Disease | Enable users to retrieve types of diseases |
| Pathogen | Enable users to retrieve pathogen of diseases |
| Symptom | Enable users to retrieve symptom of diseases |
| Transmission | Enable users to retrieve how the disease is transmitted |
| Type of Label | Description |
|---|---|
| TOD | Label type of disease |
| Neural_System | Label neural system |
| Symptom | Label symptom |
| Organ | Label organ |
| Cell | Label cell |
| Pathogen | Label pathogen |
| Transmission | Label transmission |
| Incubation_Period | Label incubation period |
| Precaution | Label precaution |
| O | None of the above |
| Act of Dialog | AidIR | Users |
|---|---|---|
| Greeting | ✓ | ✓ |
| Farewell | ✓ | ✓ |
| Request | ✓ | ✓ |
| Inform | ✓ | ✓ |
| Reject | × | ✓ |
| Confirm | × | ✓ |
| Check | ✓ | × |
| Types of Response | Response Template |
|---|---|
| Greeting | 你好,請問有甚麼問題? (Hello, what questions do you want to ask?) |
| Farewell | 掰掰啦! (Goodbye!) |
| Request (Intent) | 請提供所要搜尋的資訊種類 (Please provide the type of information that you’d like to retrieve.) |
| Request (Feature) | 請提供更多疾病資訊 (Please provide more disease information.) |
| Request (Both) | 請提供所要搜尋的資訊種類及疾病資訊 (Please provide the disease information and type of information that you’d like to retrieve.) |
| Check (Intent) | 你所要查詢的資料種類為__嗎? (Is the type of information that you’d like to retrieve __?) |
| Check (Feature) | 你所提供的疾病資訊為<slot_type>:<slot_value>嗎? (Is the disease information that you provide <slot_type>:<slot_value>?) |
| Check (Both) | 你所要查詢的資料種類為__嗎? (Is the type of information that you’d like to retrieve __?) 你所提供的疾病資訊為<slot_type>:<slot_value>嗎? (Is the disease information that you provide <slot_type>:<slot_value>?) |
| Termination | 不好意思, 無法回答您的問題 (Sorry! We cannot answer your questions.) |
| Dialog Act of User | Reward Values |
|---|---|
| Bye | 10 |
| Request | 0 |
| Inform | |
| Rejection |
| Original Sentence | Sentence with [MASK] | Token/Probability (%) | Sentence in English | |||
|---|---|---|---|---|---|---|
| 新冠肺炎潛伏期通常為[end_incubation]天 | 新冠肺炎潛伏期通常為[MASK]天 | [end_incubation]/99 | The incubation period of COVID-19 is usually [end_incubation] days. | |||
| 茲卡病毒感染症潛伏期通常為[start_incubation] 至[end_incubation] 天最長可達[end_incubation]天 | 茲卡病毒感染症潛伏期通常為[start_incubation] 至[end_incubation] 天最長可達[MASK]天 | [end_incubation]/99 | The incubation period of Zika virus is usually from [start_incubation] to [end_incubation]. The longest incubation period is [end_incubation] days. | |||
| SARS 和新冠肺炎都可能造成高燒>[temp]C | SARS 和新冠肺炎都可能造成高燒>[MASK]C | [temp]/98 | SARS and COVID-19 may cause high fever which means the temperature is greater than [temp]C. | |||
| [CLS]登革熱會造成高燒[temp]C | 登革熱會造成高燒[MASK]C | [temp]/56 | Dengue fever may cause high fever [temp]C. | |||
| [CLS]登革熱可能會發燒至[temp]C | 登革熱可能會發燒至[MASK]C | [temp]/87 | Dengue fever may cause fever up to 39 C. | |||
| [CLS]茲卡病毒感染症潛伏期通最長可達[end_incubation]天 | 茲卡病毒感染症潛伏期通最長可達[MASK]天 | [end_incubation]/99 | The longest incubation period of Zika virus is [end_incubation] days. | |||
| 登革熱可以經由病媒蚊傳播傳播 | 登革熱可以經由[MASK]媒蚊傳播傳播 | 病/95 | Dengue fever is transmitted by vector mosquitoes. | |||
| SARS 及新冠肺炎主要是由飛沫傳播但也有可能從氣溶膠傳播 | SARS 及新冠肺炎主要是由飛沫傳播但也有可能從氣[MASK]膠傳播 | 溶/99 | SARS and COVID-19 are mainly transmitted by droplets but they are possibly transmitted by aerosol. | |||
| 屆公病會讓患者感覺關節疼痛 | 屆[MASK]病會讓患者感覺關節疼痛 | 公/7 | Chikungunya causes arthralgia. | |||
| 登革熱又稱斷骨熱是由黃病毒所造成 | 登革熱又稱斷骨[MASK]是由黃病毒所造成 | 熱/55 | Dengue fever is also known as 斷骨熱(another name for dengue fever in Chinese) is caused by the flavivirus. | |||
| 冠狀病毒是造成新冠肺炎及SARS的主要病毒 | 冠[MASK]病毒是造成新冠肺炎及SARS的主要病毒 | 狀/99 | Coronavirus is the virus that causes COVID-19 and SARS. | |||
| SARS可能造成乾咳四肢無力也可能會從胸部x光看出肺炎的現象 | SARS可能造成乾咳四肢無力也可能會從胸部x光看出肺[MASK]的現象 | [-0.8em]炎/99 | SARS may cause dry cough and limb weakness. We may also find pneumonia by chest X-ray. | |||
| 茲卡病毒只要在病媒蚊如埃及斑蚊體內增殖幾天後就具有傳播力 | 茲卡病毒只要在病媒蚊如埃及[MASK]蚊體內增殖幾天後就具有傳播力 | 斑/99 | Zika virus will be transmissible after incubation in the body of vector mosquitoes such as yellow fever mosquito for a few days. | |||
| 新冠肺炎以及SARS病毒藉由飛沫及氣溶膠傳播 | [MASK]冠肺炎以及SARS病毒藉由飛沫及氣溶膠傳播 | 新/34 | The virus of COVID-19 and SARS is transmitted by droplets and aerosol. | |||
| SARS與新冠肺炎病毒為具有套膜正性單股的rna病毒 | SARS與新冠肺炎病毒為具有套膜正性單股的[MASK]病毒 | rna/82 | The virus of SARS and COVID-19 is an enveloped and positive-strand RNA virus. |
| Original Sentence | Sentence with [MASK] | Token/Probability (%) | Sentence in English |
|---|---|---|---|
| 新冠肺炎潛伏期通常為14天 | 新冠肺炎潛伏期通常為[MASK]天 | 10/36 | The incubation period of COVID-19 is usually 14 days. |
| 茲卡病毒感染症潛伏期通常為3至7天最長可達12天 | 茲卡病毒感染症潛伏期通常為3至7天最長可達[MASK]天 | 10/75 | The incubation period of Zika virus is usually from 3 to 7. The longest incubation period is 12 days. |
| SARS 和新冠肺炎都可能造成高燒 > 38 °C | SARS 和新冠肺炎都可能造成高燒 > [MASK]°C | 38/42 | SARS and COVID-19 may cause high fever which means the temperature is greater than 38 °C. |
| 登革熱會造成高燒40 °C | 登革熱會造成高燒[MASK]°C | 40/11 | Dengue fever may cause high fever 40 °C. |
| 登革熱可能會發燒至40 °C | 登革熱可能會發燒至[MASK]°C | 40/11 | Dengue fever may cause fever up to 40 °C. |
| 茲卡病毒感染症潛伏期通最長可達12天 | 茲卡病毒感染症潛伏期通最長可達[MASK]天 | 30/7 | The longest incubation period of Zika virus is 30 days. |
| 登革熱可以經由病媒蚊傳播傳播 | 登革熱可以經由[MASK]媒蚊傳播傳播 | 病/95 | Dengue fever is transmitted by vector mosquitoes. |
| SARS 及新冠肺炎主要是由飛沫傳播但也有可能從氣溶膠傳播 | SARS 及新冠肺炎主要是由飛沫傳播但也有可能從氣[MASK]膠傳播 | 溶/99 | SARS and COVID-19 are mainly transmitted by droplets but they are possibly transmitted by aerosol. |
| 屆公病會讓患者感覺關節疼痛 | 屆[MASK]病會讓患者感覺關節疼痛 | × | Chikungunya causes arthralgia. |
| 登革熱又稱斷骨熱是由黃病毒所造成 | 登革熱又稱斷骨[MASK]是由黃病毒所造成 | 熱/0 | Dengue fever is also known as 斷骨熱(another name for dengue fever in Chinese) is caused by the flavivirus. |
| 冠狀病毒是造成新冠肺炎及SARS的主要病毒 | 冠[MASK]病毒是造成新冠肺炎及SARS的主要病毒 | 狀/42 | Coronavirus is the virus that causes COVID-19 and SARS. |
| SARS可能造成乾咳四肢無力也可能會從胸部x光看出肺炎的現象 | SARS可能造成乾咳四肢無力也可能會從胸部x光看出肺[MASK]的現象 | 炎/52 | SARS may cause dry cough and limb weakness. We may also find pneumonia by chest X-ray. |
| 茲卡病毒只要在病媒蚊如埃及斑蚊體內增殖幾天後就具有傳播力 | 茲卡病毒只要在病媒蚊如埃及[MASK]蚊體內增殖幾天後就具有傳播力 | 斑/14 | Zika virus will be transmissible after incubation in the body of vector mosquitoes such as yellow fever mosquito for a few days. |
| 新冠肺炎以及SARS病毒藉由飛沫及氣溶膠傳播 | [MASK]冠肺炎以及SARS病毒藉由飛沫及氣溶膠傳播 | × | The virus of COVID-19 and SARS is transmitted by droplets and aerosol. |
| SARS與新冠肺炎病毒為具有套膜正性單股的rna病毒 | SARS與新冠肺炎病毒為具有套膜正性單股的[MASK]病毒 | rna/8 | The virus of SARS and COVID-19 is an enveloped and positive-strand RNA virus. |
| Parameters | Accuracy (%) | Pre-Trained | ST c | ||
|---|---|---|---|---|---|
| DC a | SL b | ||||
| 1 | 1 | 95 | 87 | ✓ | ✓ |
| 0.5 | 1.5 | 94 | 89 | ✓ | ✓ |
| 1.5 | 0.5 | 97 | 87 | ✓ | ✓ |
| 0.05 | 1.95 | 63 | 92 | ✓ | ✓ |
| 0.2 | 1.8 | 92 | 92 | ✓ | ✓ |
| 0.2 | 1.8 | 68 | 89 | × | ✓ |
| 0.2 | 1.8 | 80 | 87 | ✓ | × |
| Parameters | Value |
|---|---|
| Accuracy (%) | 98 |
| Optimizer | Adam [37] |
| Epoch | 300 |
| Learning rate | 0.001 |
| 安安 (Morning) | 哈囉 (Hello) | Hello |
|---|---|---|
| 呀 (AW a) | 久違 (LTNS c) | 歐嗨唷 (morning) |
| 初次 (FT b) | 初次 (FT b) | 嘿 (hey) |
| 見面 (meet) | 安安 (hi) | 空你基哇 (morning) |
| 早 (morning) | 再會 (SY d) | 哩賀 (hi) |
| 哩賀 (Hi) | 見面 (meet) | hey |
| 哈囉 (Hello) | 哩賀 (Hi) | 嗨 (hi) |
| 歐嗨唷 (morning) | 嘿 (hey) | 黑 (hey) |
| 黑 (hey) | 空你基哇 (morning) | 敖早 (morning) |
| hey | 歐嗨唷 (morning) | hi |
| Task | Average Scores |
|---|---|
| Intuitiveness | |
| Usability | |
| User experience |
| Questions | Yes (%) | No (%) |
|---|---|---|
| Is it more intuitive to retrieve information with AidIR than GUI? | 75 | 25 |
| Is the user experience of AidIR better than GUI? | 70 | 30 |
| Is the user experience of integrating AidIR to Line chat media better than without integrating AidIR to Line chat media? | 75 | 25 |
| Would you like to use the systems such as AidIR to retrieve information? | 80 | 20 |
| Is the user experience of AidIR better than the single-turn system? | 90 | 10 |
| Original Feedback | Feedback in English |
|---|---|
| 在獲得醫療資訊方面可以更方便、快速∘ | It is very convenient to obtain medical information with this system. |
| 整合到Line 更貼近生活 | Integrating this system to Line is easier to use in daily life. |
| 使用習慣後相當方便∘ | It is very convenient to use after getting used to it. |
| 在問答方面可以直覺性的回答出所需要的資訊 | It is very intuitive to retrieve the information. |
| 可迅速了解相關疾病的正確資訊 | This system can help to understand the correct medical information quickly. |
| 相當方便對於我自己有很好的使用者體驗 | It is very convenient. I have a good user experience. |
| 可以更為精準地傳達想要檢索的內容, 讓搜尋引擎能找到更貼合所想要的資訊內容 | AidIR delivers the information more precisely and this information can be treated as the keywords for search engines to enable search engines to find more precise information. |
| Original Feedback | Feedback in English |
|---|---|
| 對於對話內容種類內容還有可以增加的空間∘ | More types of content can be added to the system. |
| 在回答問題時可提供相關圖片, 以便更了解資訊 | It is better to provide some pictures in the answer to help the understanding of information. |
| 建議可加入圖片輔助說明 | It is better to add pictures to aid the explanation of the information. |
| 如果能結合圖片搭配檢索內容會更好 | It would be better if we can use pictures to retrieve information. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.-J.; Chen, T.-Y.; Su, C.-Y. AidIR: An Interactive Dialog System to Aid Disease Information Retrieval. Appl. Sci. 2022, 12, 1875. https://doi.org/10.3390/app12041875
Wang D-J, Chen T-Y, Su C-Y. AidIR: An Interactive Dialog System to Aid Disease Information Retrieval. Applied Sciences. 2022; 12(4):1875. https://doi.org/10.3390/app12041875
Chicago/Turabian StyleWang, Da-Jinn, Tsong-Yi Chen, and Chia-Yi Su. 2022. "AidIR: An Interactive Dialog System to Aid Disease Information Retrieval" Applied Sciences 12, no. 4: 1875. https://doi.org/10.3390/app12041875
APA StyleWang, D. -J., Chen, T. -Y., & Su, C. -Y. (2022). AidIR: An Interactive Dialog System to Aid Disease Information Retrieval. Applied Sciences, 12(4), 1875. https://doi.org/10.3390/app12041875