1. Introduction
Recently, thermal infrared cameras have become increasingly popular in security and military surveillance operations [
1,
2]. Thus, infrared object detection, including both classification and localization of the targets in thermal images, is a critical problem to be invested in. With the advent of Convolution Neural Network (CNN) in many applications [
3,
4,
5,
6,
7] such as action recognition and target tracking, a number of advanced models [
8,
9,
10] based on CNN are proposed in object detection. Those detectors lead to considerable achievements in visual RGB detection tasks because they are mainly driven by large training data, which are easily available in the RGB domain. However, the relative lack of large-scale infrared datasets restricts CNN-based methods to obtain the same level of success in the thermal infrared domain [
1,
11].
One popular solution is finetuning an RGB pre-trained model with limited infrared examples. Many researchers firstly initialize a detection network with parameters trained on public fully-annotated RGB datasets, such as PASCAL-VOC [
12] and MS-COCO [
13]. Then, the network is finetuned by limited infrared data for specific tasks. To extract infrared object features better, most of the infrared detectors improve existing detection frameworks by introducing some extra enhanced modules such as feature fusion and background suppression. For example, Zhou et al. [
14] apply a dual cascade regression mechanism to fuse high-level and low-level features. Miao et al. [
15] design an auxiliary foreground prediction loss to reduce background interference. To some extent, the aforementioned modules are effective for infrared object detection. However, it is hard for simple finetuning with inadequate infrared examples to eliminate the difference between thermal and visual images, which hinders the detection of infrared targets.
An alternative solution is to borrow some features from a rich RGB domain. Compared to the finetuning, this method leverages abundant features from the RGB domain to boost accuracy in infrared detection. Konig et al. [
16] and Liu et al. [
17] combine visual and thermal information by constructing multi-modal networks. They feed paired RGB and infrared examples into the network to detect the objects in thermal images. However, the paired images from two domains are difficult to be obtained, which hampers the development of the multi-modal networks. To tackle this problem, Devaguptapu et al. [
1] employ a trainable image-to-image translation framework to generate pseudo-RGB equivalents from thermal images. Although this pseudo multi-modal detector is feasible in the absence of large-scale available datasets, the complicated architecture is difficult to train and thus rarely reaches advanced performance.
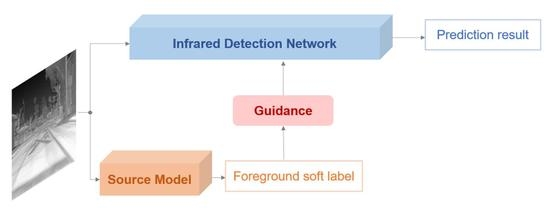
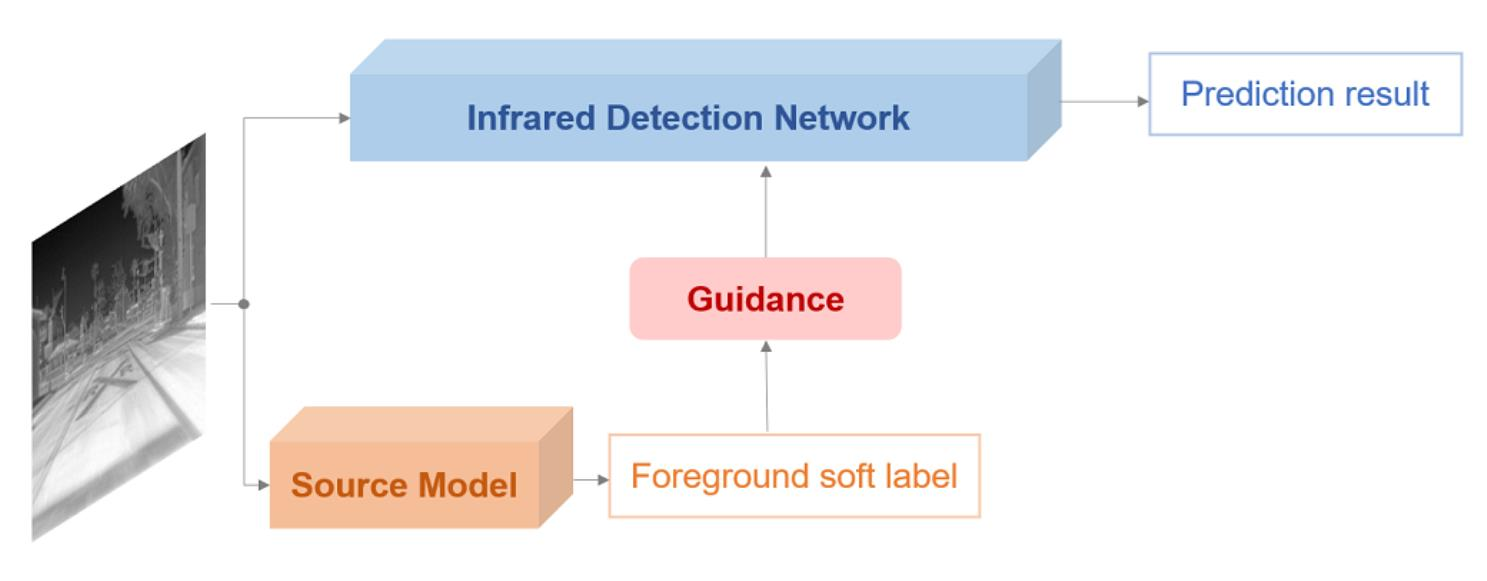
In this work, we address this problem from a novel perspective, knowledge transfer. Our proposed approach, named Source Model Guidance (SMG), is the first transfer learning solution for infrared limited-examples detection, to the best of our knowledge. By leveraging existing RGB detection models as source knowledge, we convert recent state-of-the-art RGB detectors to infrared detectors with inadequate thermal data. The basic idea is that if we already have an RGB model with strong ability to distinguish foreground from background, the model can be used as a source model to supervise another network training for infrared detection. Then, the problems becomes how to transfer the source knowledge between different domains and where to add the source supervision.
We first observe modern RGB detection frameworks including anchor-based (Faster RCNN [
8], SSD [
9], YOLOv3 [
18]) and anchor-free (CenterNet [
19], CornorNet [
20], ExtremeNet [
21], FCOS [
22]) methods. All of them consist of two main modules, a Feature Extraction Network (FEN) to calculate feature maps and a Detection Head (DH) to generate results. Many researchers have trained those frameworks with large-scale RGB datasets and exposed network weights as common RGB object detection models. Despite the fact that an RGB model is designed for visual images, it still can detect most infrared targets when given a thermal image. However, the precise categories and bounding boxes are hard to be predicted by it due to the difference between two domains. Therefore, we combine all category predictions as a foreground soft label, which is regarded as the source knowledge to be transferred. Then, we look for where to add the source supervision. Different from ground-truth supervision on the final DH, we propose a Background Suppression Module (BSM) to receive the source knowledge. BSM is inserted after FEN to enhance the feature maps and produce a foreground prediction at the same time. By calculating the transfer loss between the foreground prediction and the soft label, we introduce source supervision into the training process of the infrared detector, as shown in
Figure 1.
Theoretically, our transfer approach SMG can be implemented in any visual detection networks effortlessly. In this paper, we choose two popular frameworks, CenterNet [
19] and YOLOv3 [
18], as instantiations, and the frameworks we proposed are named SMG-C and SMG-Y, respectively. To validate the performance of SMG, we conduct extensive experiments on two infrared benchmarks, FLIR [
23] and Infrared Aerial Target (IAT) [
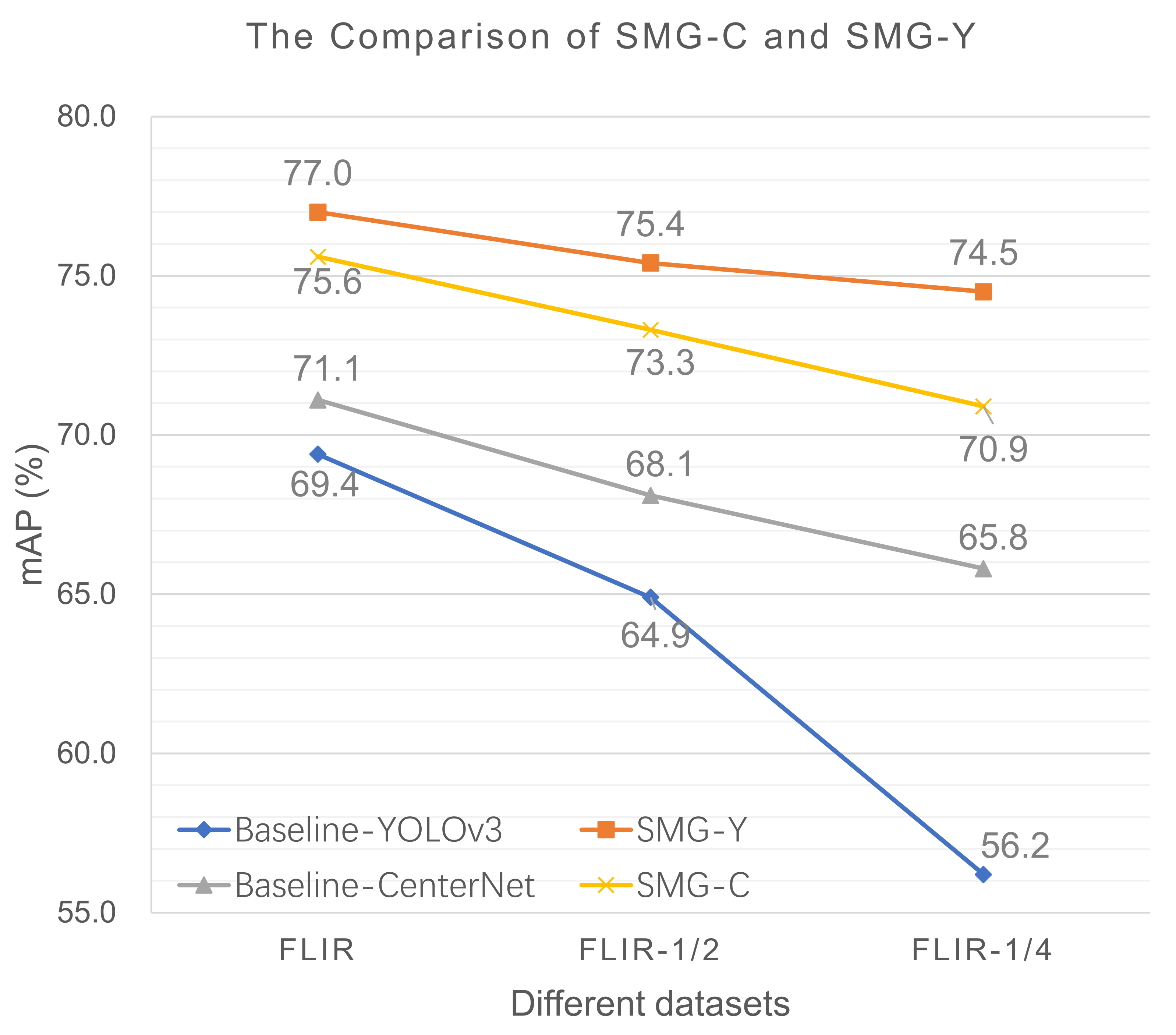
15]. Experimental results show that SMG is an effective method to boost detection accuracy especially when there are limited training examples. On FLIR, using only a quarter of training data, SMG-Y obtains higher mAP than the original YOLOv3 finetuned on the entire dataset. Furthermore, compared to other infrared detectors, both SMG-C and SMG-Y achieve state-of-the-art accuracy and inference speed.
The main contributions are described as the following three folds:
First, we propose a cross-domain transfer approach SMG, which easily converts a visual RGB detection framework to an infrared detector.
Second, SMG decreases the data dependency for an infrared network. The detectors with SMG maintain remarkable performance even if trained on the small-scale datasets.
Third, two proposed instantiations of SMG, SMG-C and SMG-Y, outperform other advanced approaches in accuracy and speed, showing that SMG is a preferable strategy for infrared detection.
The structure of this paper is as follows. In
Section 2, we briefly present some aspects related to our work.
Section 3 shows the proposed method SMG in detail. Extensive experiments and ablation studies are conducted in
Section 4 and
Section 5, respectively. We explain why SMG works well and analyze the failure cases of our detectors in
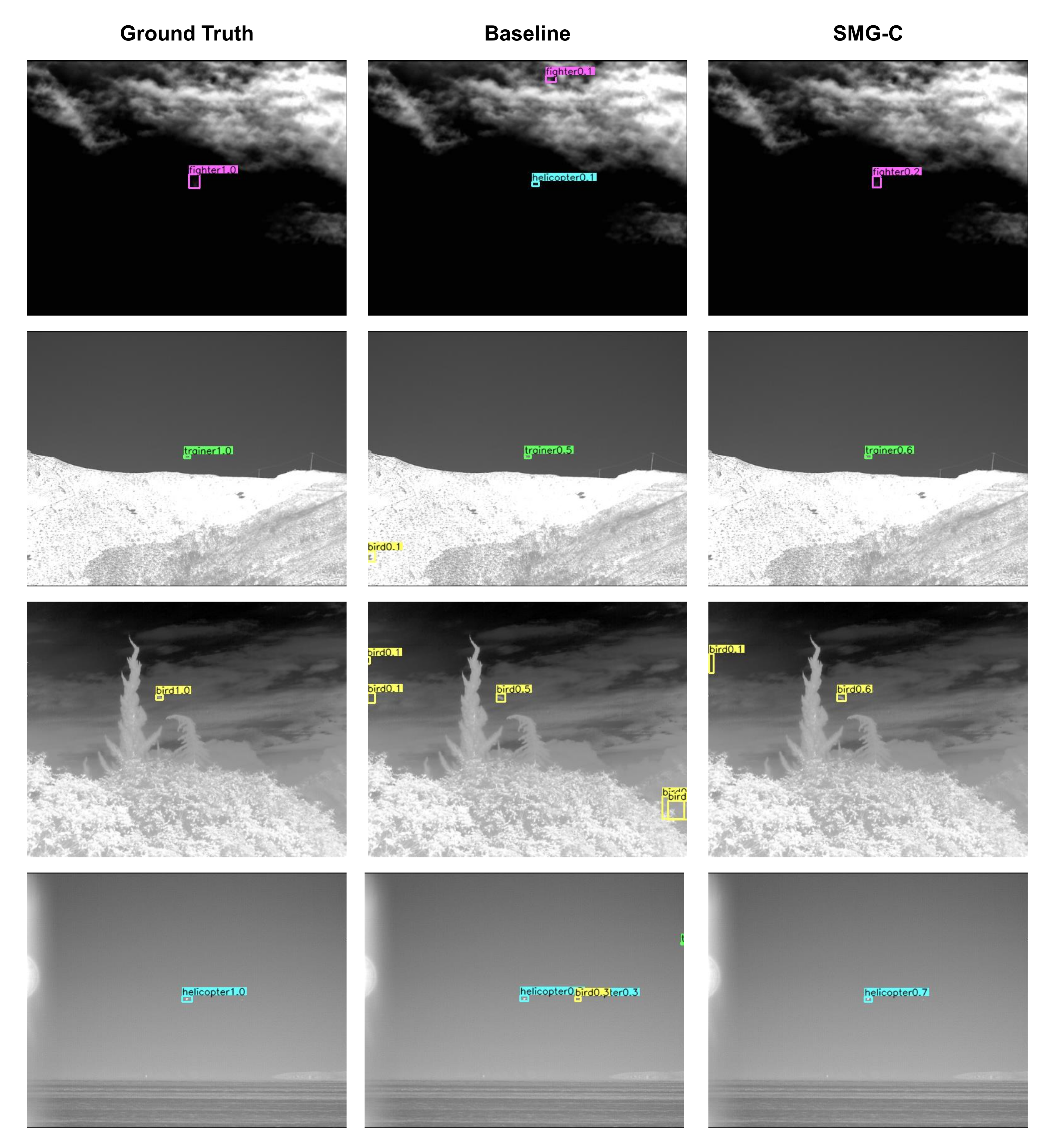
Section 6. Finally, the summary is drawn in
Section 7.
3. Method
In this section, we detail our method Source Model Guidance (SMG). First, we introduce the structure of SMG, including the overall framework and proposed Background Suppression Module (BSM). Then, we describe the training details of SMG, including how to transfer knowledge from the source model to the target network and how to train the whole network. Finally, we show two explicit instantiations of SMG, SMG-C and SMG-Y.
3.1. Overall Framework
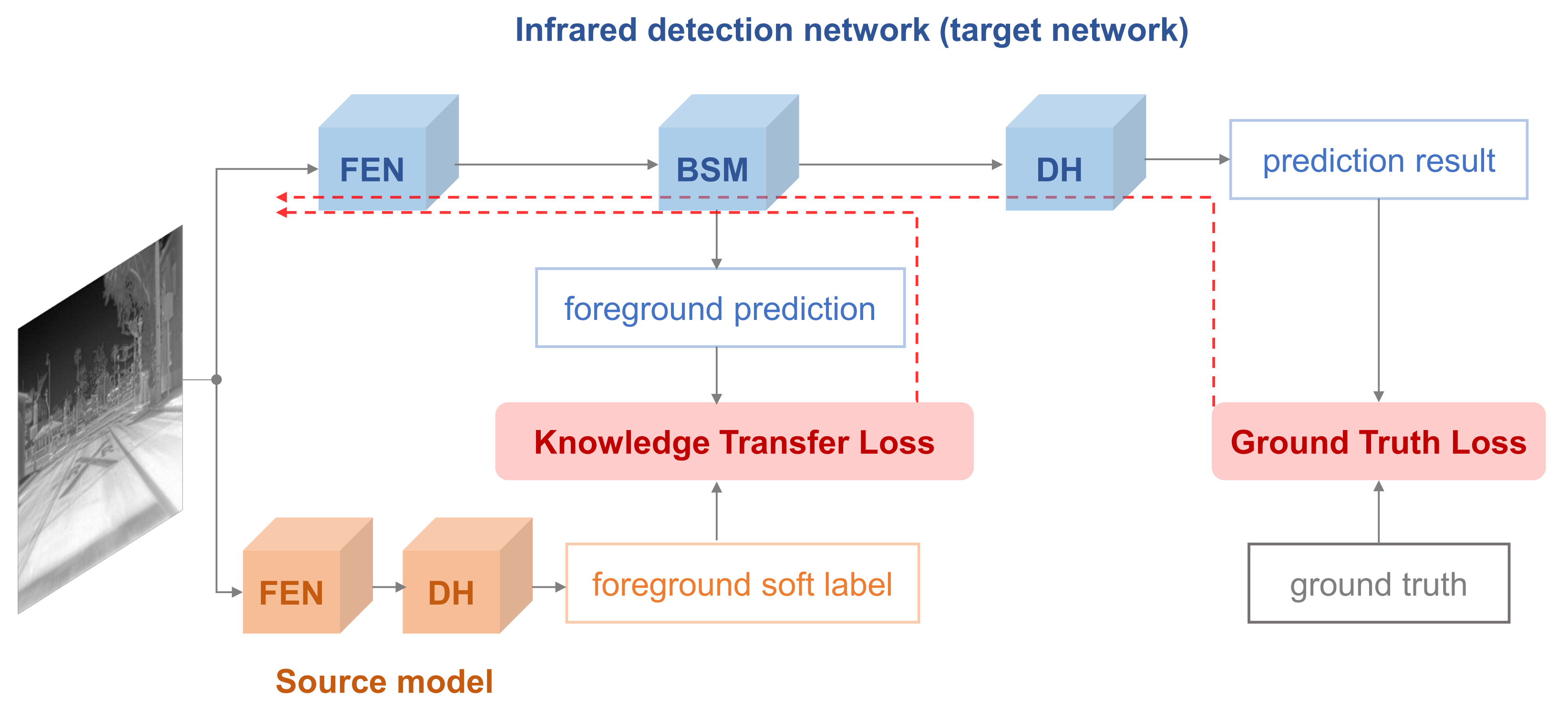
As illustrated in
Figure 1, we train an infrared object detector by using the knowledge of a source model. The source model is a high-capacity RGB detection model, which has been trained with large-scale RGB datasets. The source model is composed of two modules, a Feature Extraction Network (FEN) for feature map calculation and a Detection Head (DH) to generate the prediction. We choose two popular detection models, CenterNet [
19] and YOLOv3 [
18], as source models to guide different infrared detectors, named SMG-C and SMG-Y, respectively.
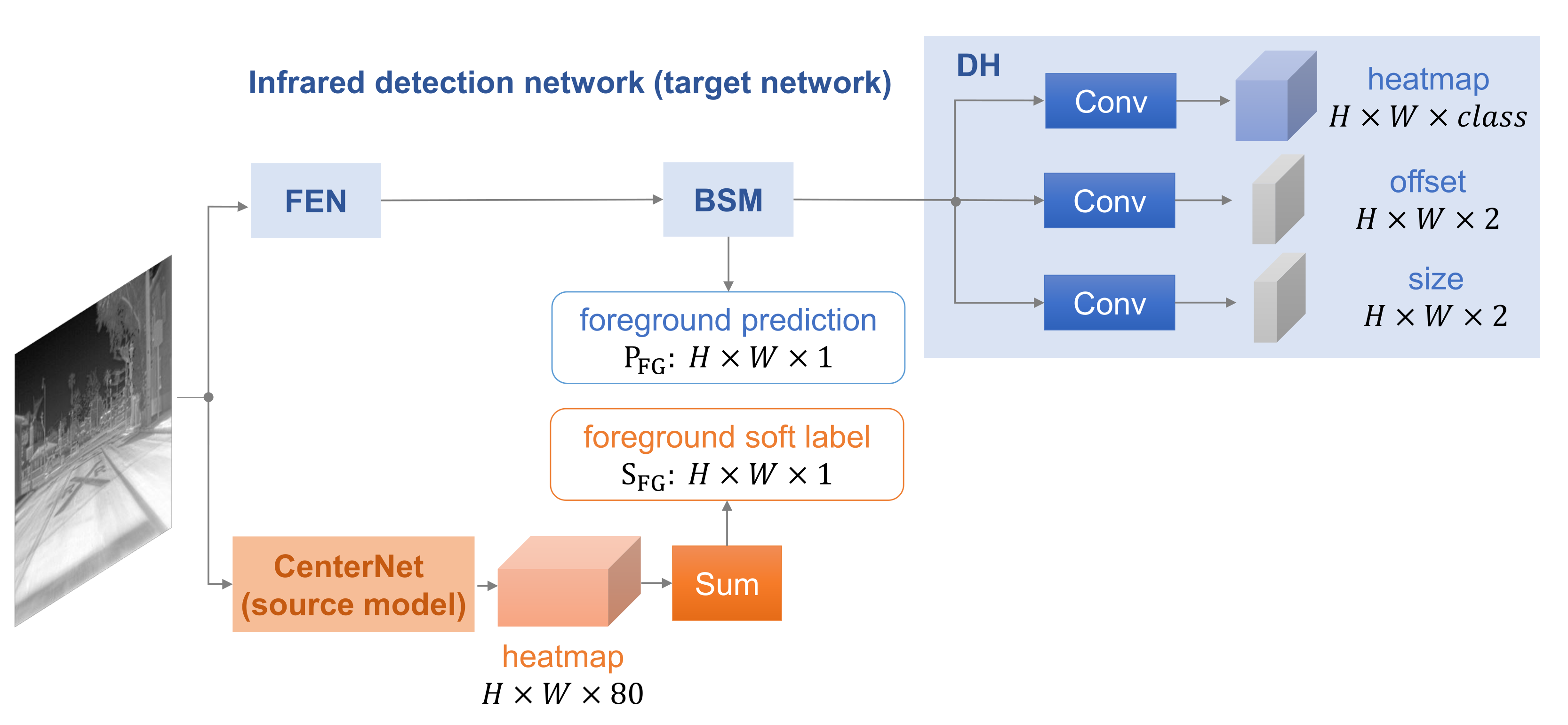
Compared to the source model, the infrared detection network not only consists of FEN and DH but also has an extra part, Background Suppression Module (BSM). The structure of FEN is flexible, and it can be the same or different from the source model. The DH in an infrared detection network is similar to the source model except for the predicted category. For BSM, it is a novel part with two functions, predicting the foreground and enhancing the feature map from FEN.
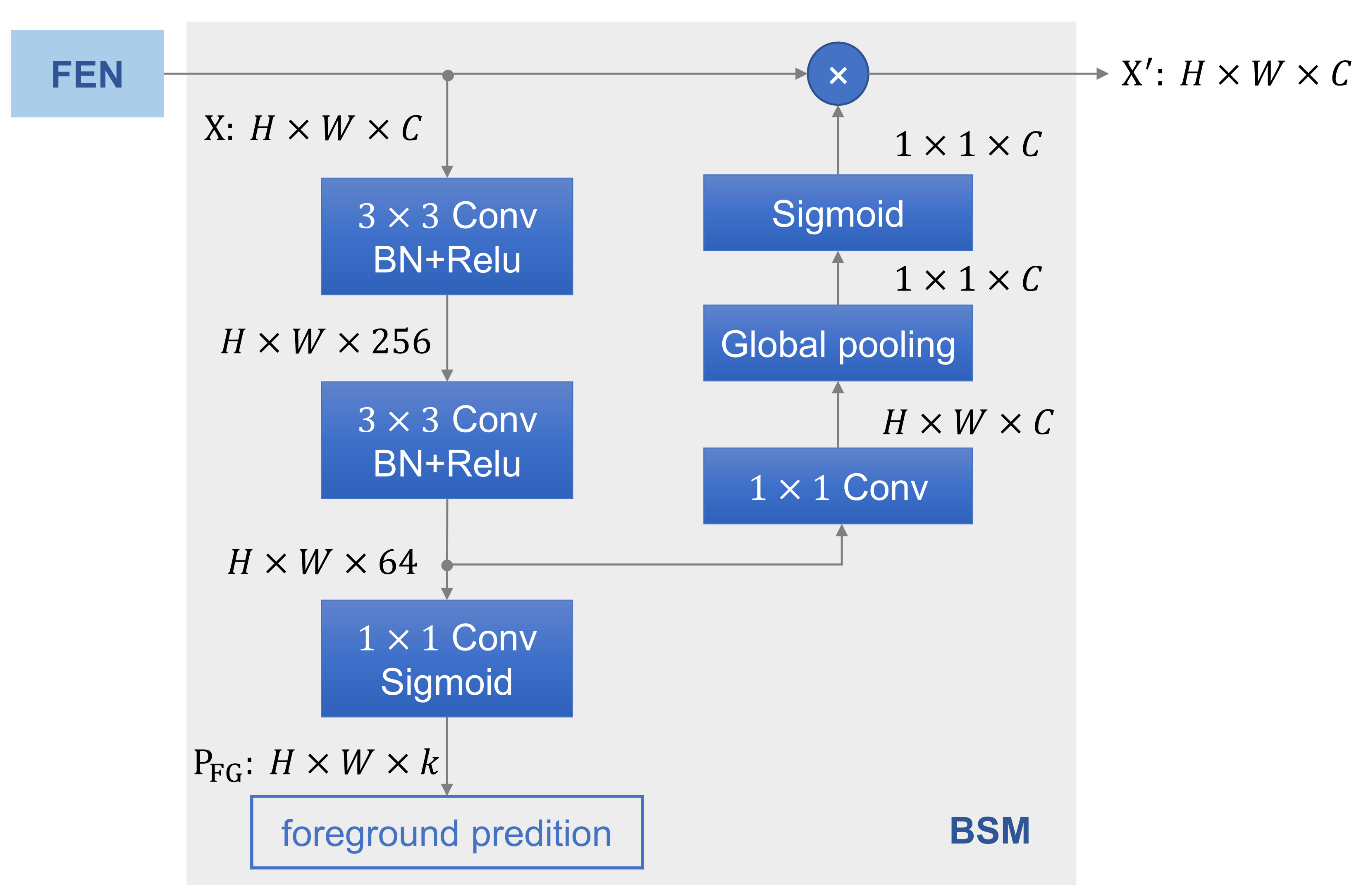
3.2. BSM
The BSM in the infrared detection network (target network) is a key module to receive the knowledge transferred from the source model. We describe the principle of BSM, as shown in
Figure 2. The idea of BSM is inspired by the concept of attention mechanism [
33,
34,
35,
36,
37], and thus, its main structure is a transformation mapping from the input
to an enhanced feature map
. In addition, an extra prediction, named foreground prediction
, is obtained in BSM. The
is defined as the combination of ground-truth targets based on anchors, where
k is the number of anchors and
k is 1 for anchor-free methods.
To be specific, the input first passes two convolutional layers to produce an intermediate feature map. Then, it is fed into to two different branches: one for predicting foreground and the other for feature enhancement. The foreground prediction is achieved by a convolution with sigmoid function to generate a score . The intermediate feature map is also employed to re-weight the input feature map over spatial dimension because it reflects the feature of the foreground. After a convolution for channel transformation, we use an average pooling to squeeze global information into channel-wise weights. Finally, the enhanced feature map branch is obtained by rescaling input with the weights.
3.3. Transfer-Knowledge Regularization
Although the foreground enhancement in BSM can alleviate the disturbance of background, the foreground prediction from BSM should be supervised in the limited-examples scenario. For this reason, we propose a novel transfer-knowledge regularization by leveraging the source model as a guidance.
In this paper, the foreground prediction with values within 0 and 1 is supervised by the foreground soft label generated from the source model. Different from the hard label in ground-truth supervision, we adopt the soft label in knowledge transfer because it contains hidden information about how the source model makes inferences when given samples. In every position of , the value of the soft label is in based on anchor, while the hard label is either 0 or 1.
For different source models, we choose different methods to obtain the foreground soft label
. We sum the label prediction (heatmap) for all positions in SMG-C and use the anchor confidence directly in SMG-Y, as shown in
Figure 3 and
Figure 4. The soft label
is the foreground score based on anchor and has the same size with foreground prediction
from the target network. We take
as source-domain knowledge to regularize the training of target network. Mean Squared Error (MSE) is applied as a transfer-knowledge regularization:
In this case, the trained RGB detection model can be integrated into the training procedure of the infrared detector, which achieves cross-domain transfer in SMG.
3.4. Training Algorithm
The whole loss
of SMG consists of two parts: one is the standard detection loss with ground truth supervision
, and the other is the transfer-knowledge loss
mentioned in the above subsection:
The weight represents hyper-parameters to control the balance between different losses. We fix it to be 1 in SMG-C. In SMG-Y, is 0.3 because we introduce 3 BSMs to generate the transfer-knowledge loss in SMG-Y, as explained in the following subsection.
During the training, we first initialize the source model with public parameters trained on COCO, which is a large-scale RGB detection dataset. For the target network, the FEN is initialized with ImageNet pretrained parameters, and other modules are randomly initialized. Then, training loss is calculated according to Equation (
2). Finally, we update the weights of target network in the back propagation. It is notable that the source model is not updated, and thus, we just employ the target network as an infrared detector in the inference.
3.5. Instantiations
SMG can be implemented in standard visual RGB detection networks and convert those networks to infrared detectors. To illustrate this point, we apply SMG in both anchor-free and anchor-based detection frameworks, which is described next.
We first consider CenterNet [
19], an anchor-free model, as an instantiation, and the framework we proposed is named SMG-C. As shown in
Figure 3, CenterNet predicts center points of targets directly by producing a heatmap
, where
is the number of categories (for RGB models trained on COCO,
). Therefore, the sum of the heatmap represents foreground prediction, and we use it as
to transfer knowledge. For the infrared detection network of SMG-C, only a BSM is inserted in between FEN and DH in comparison with CenterNet.
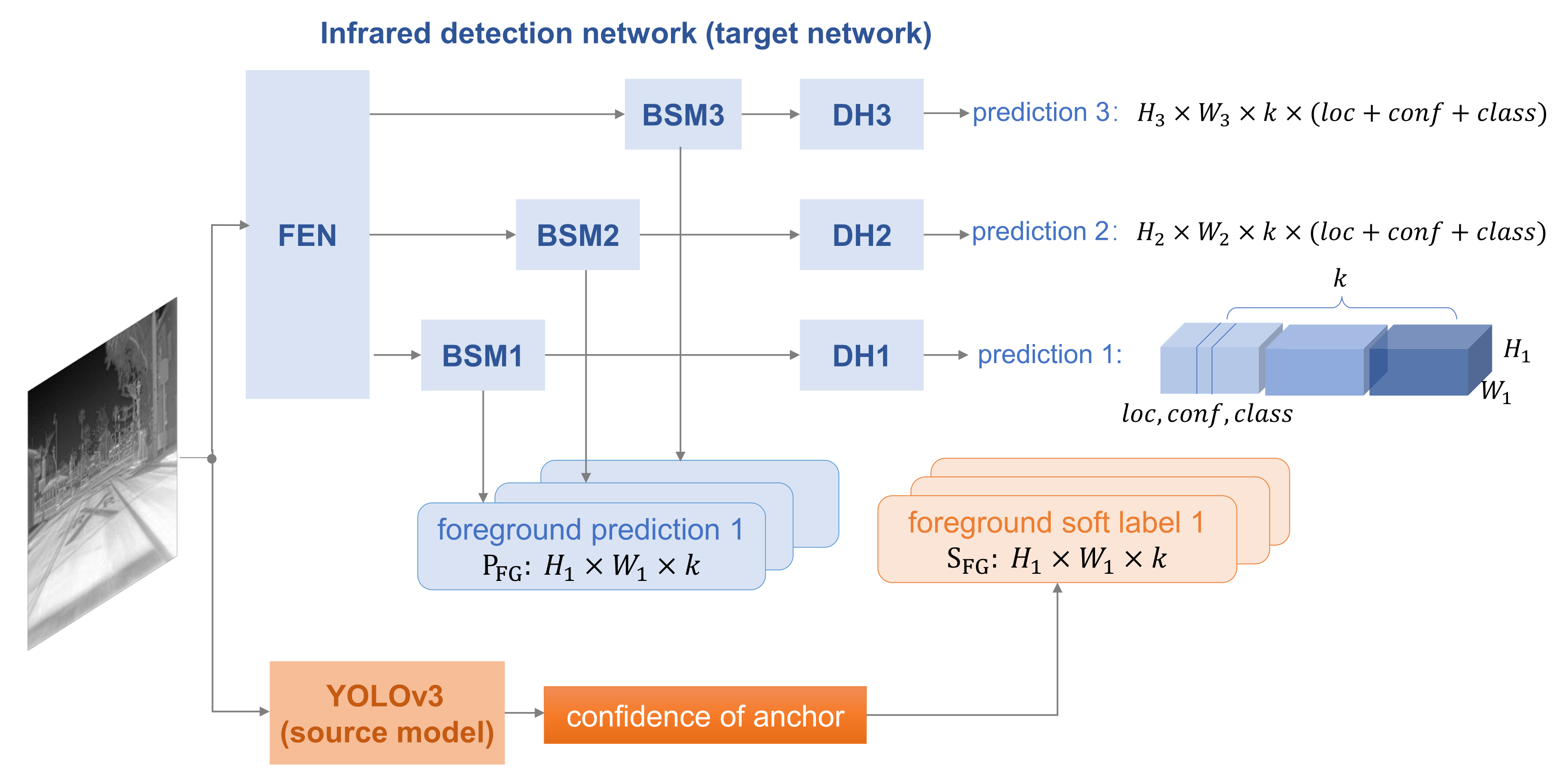
SMG is also applied in YOLOv3 [
18], an anchor-based model, and
Figure 4 shows the framework of SMG-Y. YOLOv3 predicts bounding boxes at 3 different scales by extracting features from 3 scales. As a result, we add 3 BSMs in the infrared detection network. Furthermore, YOLOv3 sets
k anchors with different sizes, and thus, the prediction in every scale is a
k-d tensor encoding location, confidence, and class. The confidence reflects whether there is an object in the anchor, and we adapt it as the foreground soft label
directly. In this work, we set
according to the original paper [
18].
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}