3.1. Model Structure
In this chapter, we present the architecture of MIss RoBERTa WiLDe, a model for Metaphor Identification using the RoBERTa language model. At its core, MIss WiLDe utilizes MelBERT (Metaphor-aware late interaction over BERT) published recently by Choi et al. [
10] and therefore the architecture of the two models is almost identical. For the model overview, whose design was inspired by the aforementioned work, see
Figure 1. Conceptually, MIss WiLDe and MelBERT take advantage of the same linguistic methods for metaphor detection, namely SPV (Selectional Preference Violation) and MIP (Metaphor Identification Procedure). While the implementation of the former in our model remains mostly unchanged, the latter is affected by a different kind of input, which is the first novelty of our approach.
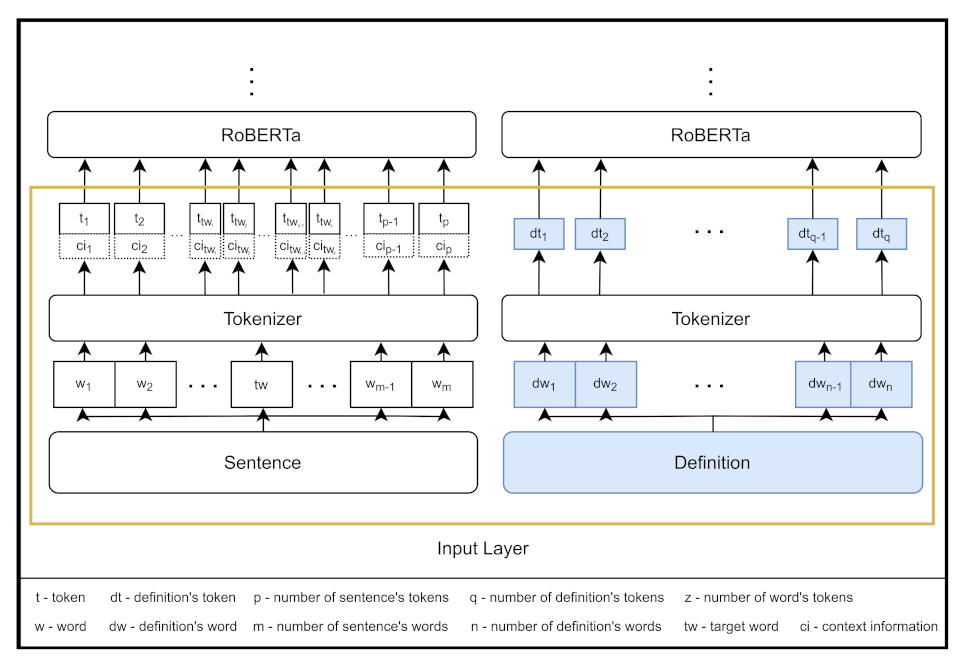
In order to determine whether the target word is used figuratively in the given context, Choi et al. utilize its isolated counterpart as a part of the input. This is done for the same purpose MIss WiLDe takes advantage of the target word’s definition (see
Figure 2 and
Figure 3). Although using uncontextualized embedding of the target word proved to yield satisfactory results in the work of Choi et al., from a theoretical perspective, this approach does not seem to be absolutely free of flaws. Its main issue lies in the fact that during the pre-training stage, the word embedding is constructed by looking at the word’s usages in various contexts. In consequence, at least some of these usages (depending on the word in question, even most of them) are already metaphorically motivated. On the other hand, using the target word’s lexical definition—more specifically, using the first of the definitions listed in the dictionary—should be able to bypass this problem. This is because lexicographers tend to place the definition representing what is called the word’s
basic meaning at the top of the definitions list. Given the definition is indeed representing the word’s basic sense, its embedding representation can be subsequently used to compare it with the contextualized embedding of the target word. If the gap between them is big enough, it can be estimated that the word is used figuratively.
Another motivation for using the definition rather than the target word itself is that—considering BERT was pre-trained on a large amount of text data with a sentence as its input unit—we anticipate that using sentences instead of single words might lead to some performance gains.
The second novelty of our method lies in the way in which the embedding representation of the sentence is constructed. In the work of Choi et al., sentence representation is calculated using the [CLS] special token. However, it has been experimentally established by Reimers and Gurevych in their work on Sentence-BERT [
41] that this approach falls short in comparison to using the mean value of tokens without the [CLS] and [SEP] tokens. It was also further confirmed by the results we achieved in a number of experimental trials with and without the use of the aforementioned special tokens.
We present 3 variants of the MIss WiLDe model, which we are going to interchangeably call the sub-models. These are:
MIss WiLDe_base. This is the core version of our model. See
Figure 1 for the model overview and
Figure 2 for its input layer using RoBERTa;
MIss WiLDe_cos. Both SPV and MIP are methods of using semantic gaps to determine if a target word is used metaphorically. Therefore, we also created a sub-model using cosine similarity to explicitly handle semantic gaps. This is shown by
in
Figure 1. Specifically, similarity between the meaning of the sentence and the meaning of the target word is calculated within the SPV block, while similarity between the meaning of the target word’s definition and the meaning of the target word itself is calculated within MIP. The input layer for this sub-model is common with the base variant visualized in
Figure 2;
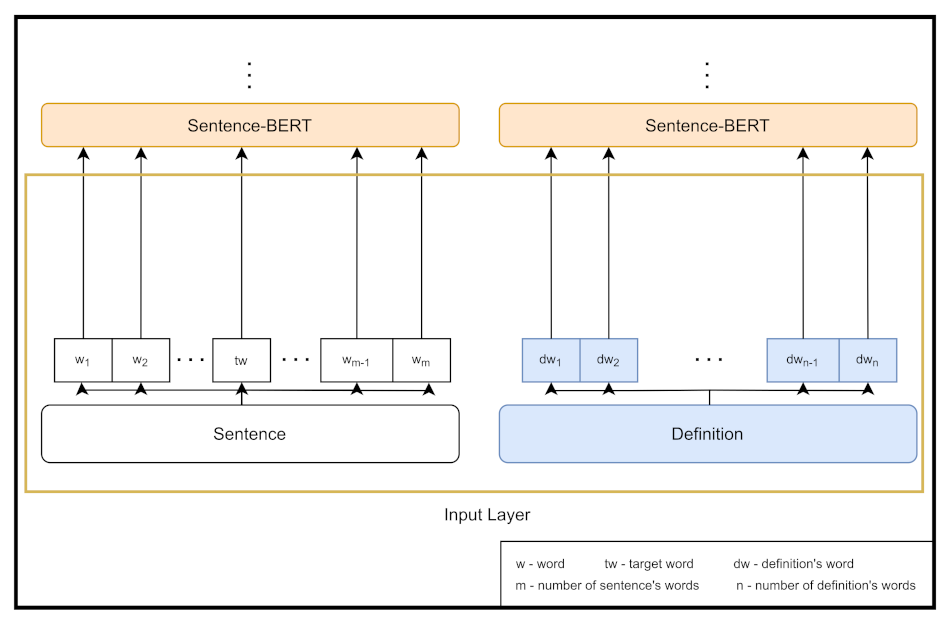
MIss WiLDe_sbert. Since the results published in [
41] suggest that using Sentence-BERT should result in acquiring sentence embeddings of better quality than those produced by both [CLS] tokens and averaged token vectors, we have decided to confirm it experimentally. We have therefore replaced RoBERTa with Sentence-BERT as an encoder in one of our 3 sub-models. The input layer using Sentence-BERT is depicted in
Figure 3.
The input to our model consists of the sentence comprising the target word on one side, and the definition of this target word on the other (depending on the part of speech and the availability of the definition in Wiktionary, lemma can be used instead of the definition; cf.
Section 3.3 for the details). The conversion of words into tokens is then performed using the improved implementation of Byte-Pair Encoding (BPE), as proposed by Radford et al. in [
42] and used by Choi et al. in [
10] as well. This can be described as follows:
;
where
stands for the tokenizer,
w represents a single word within the analyzed sentence, with
being the target word or, to put it differently, a metaphor candidate;
m in the subscript is the number of words in the input sentence.
t represents an output token, while
p is the number of the output tokens. Depending on a given target word
,
should be considered an abbreviation for
, where
z stands for the number of tokens the target word was split into. This can be observed in
Figure 2 as well. In the formulas presented in this section, we use the abbreviated forms for simplicity (a single input word is often transformed into multiple tokens: for more details on Byte-Pair Encoding cf.
https://huggingface.co/docs/transformers/tokenizer_summary; last accessed on 21 December 2021). In the second formula,
stands for a component word of the target word’s definition and
for an output token;
n and
q in the subscripts denote the number of words in the definition and the number of related output tokens, respectively.
Afterwards, tokens are transformed into embedding vectors via the encoder layer. Input and output of our two encoders can be illustrated with the following formulas:
;
where stands for the function producing contextualized vector representation for a given input, t represents a single token within the analyzed sentence, with in the subscript denoting the target word. is the vector embedding representation that corresponds to the input token with the same index, while is the embedding representation of the target word’s tokens. Analogously, stands for a token coming from the definition of the target word and for a vector embedding of the said token. Additionally, p and q denote the length of the sentence and the length of the target word’s definition measured in the number of tokens, respectively.
Subsequently, the mean value of the sentence’s token vectors on one side and the mean value of the definition’s token vectors on the other are computed within the pooling layer. To the output of this layer, dropout is subsequently applied. On both sides, an output vector is then concatenated with the vector representation of the target word’s tokens having undergone the same operations. In case of the cosine-similarity sub-model, an additional third vector representing similarity between the two respective vectors is also concatenated. In order to calculate the gap between these vectors, a multilayer perceptron is applied on the output of the concatenation function. The formulas for the hidden vectors obtained this way in SPV and MIP layers are presented below.
;
where represents concatenation; p and q denote length of the sentence and length of the definition, respectively (measured in number of tokens); i is the index of the sentence’s token such that , ; and j is the index of the definition’s token such that , . The hidden vector represents a vector being the output of the SPV layer while the is used to depict a hidden vector that is the output of the MIP layer.
As mentioned, for the cosine-similarity sub-model, the similarity vector becomes the third element concatenated in order to obtain the aforementioned hidden vectors. Similarity vectors are obtained as follows:
;
where
stands for the cosine similarity value measured between the average sentence vector and the target word vector; analogously
represents the cosine similarity between the average definition vector and the target word vector. The
denotes the Euclidean norm, the · stands for the dot product between the vectors, and
is a parameter of a small value used to avoid division by zero (
https://pytorch.org/docs/stable/generated/torch.nn.CosineSimilarity.html; last accessed on 21 December 2021). The output of the model is calculated by adding bias to the concatenation function that takes in the two hidden vectors and applies the log-softmax activation function onto the result. Finally, the candidate with the higher probability score is chosen as the predicted label. The process can be represented with the following formula:
where is the label predicted by the model, such that . This prediction is the result of the argmax operation applied on , which in turn stands for the natural logarithm of the value output by the softmax function denoted with . Softmax outputs two values that are the probabilities for each class (literal and metaphor) that range from 0 to 1 and sum up to 1. denotes the weights matrix, stands for concatenation, and b signifies bias.
We use the negative log-likelihood loss function, which in combination with log-softmax activation, acts essentially the same as cross-entropy combined with softmax, but has improved numerical stability in PyTorch [
43].
3.2. Datasets
In this section, we present the datasets used in the experiments. We wanted to confirm the validity of our hypothesis that utilizing lexical definitions of target words would improve the algorithm’s performance and in order to do so we have adopted the same datasets as in the work of Choi et al. [
10]. The original data is available at the authors’ drive, a link to which can be found on their GitHub (
https://drive.google.com/file/d/1738aqFObjfcOg2O7knrELmUHulNhoqRz/view?usp=sharing via
https://github.com/jin530/MelBERT; last accessed on 21 December 2021). The downloadable repository consists of MOH-X, TroFi, VUA-20 (variant of VUA-ALL-POS known from Metaphor Detection Shared Task [
15,
44]), VUA-18 (variant of VUA-SEQ known from Gao et al. [
35] and Mao et al. [
36]), VUA-VERB, 8 subsets of VUA-18, 4 of which are selected based on the POS tags of the target words (nouns, verbs, adjectives, and adverbs), and another 4 on the genre to which the sentence comprising target word belongs (academic, conversation, fiction, and news). Both Genres and POS are used only for testing. The same datasets enriched with the Wiktionary definitions can be downloaded directly from our GitHub (
https://github.com/languagemedialaboratory/ms_wilde/tree/main/data; last accessed on 21 December 2021).
MOH-X (Mohammad et al. [2016] dataset) [
27] and TroFi (Trope Finder) [
24] are relatively small datasets annotated only for verbs. MOH-X is built with the example sentences taken from WordNet [
45], and TroFi with the ones from the Wall Street Journal [
46]. For the sake of fair comparison with Choi et al., we use these two datasets only as the test sets for the models trained beforehand on the VUA-20, in the same way as performed by the authors of MelBERT. As they note in the paper, this can be viewed as the zero-shot transfer learning. VUAMC (Vrjie Universiteit Amsterdam Metaphor Corpus [
20,
47],
http://www.vismet.org/metcor/documentation/home.html; last accessed on 21 December 2021) is the biggest publicly available corpus annotated for token-level metaphor detection and it is seemingly the most popular one in the field. It comprises text fragments sampled from the British National Corpus (
http://www.natcorp.ox.ac.uk/; last accessed on 21 December 2021). Sentences it contains were labeled in accordance with MIPVU (Metaphor Identification Procedure VU University Amsterdam), the refined and adjusted version of the already described MIP (Metaphor Identification Precedure). Both VUA-ALL-POS (all-part-of-speech) and VUA-SEQ (Sequential) are based on VUAMC, which has been used in the Metaphor Detection Shared Task, first in 2018 and later in 2020 [
15,
44]. The repository prepared for the Metaphor Detection Shared Task is provided under the following URL:
https://github.com/EducationalTestingService/metaphor/tree/master/VUA-shared-taskl (last accessed on 21 December 2021). Inside, we can find links allowing for downloading:
VUAMC corpus in XML format;
Starter kits for obtaining training and testing splits of VUAMC corpus
(vuamc_corpus_train, vuamc_corpus_test);
Lists of ids (all_pos_tokens, all_pos_tokens_test, verb_tokens, verb_tokens_test) specifying the tokens from VUAMC to be used as targets for classification in the two tracks of the Metaphor Detection Shared Task: All-Part-Of-Speech and Verbs.
In the 12,122 sentences comprised by vuamc_corpus_train, all of their component words are labeled for metaphoricity, irrespective of the part of speech they belong to. For example, in the input sentence “The villagers seemed unimpressed, but were M_given no choice M_in the matter .”, there are altogether 14 tokens, including punctuation marks. Two of the tokens are labeled as metaphors (the verb
given and the preposition
in), and the remaining ten as non-metaphors. This is indicated by the prefix “M” attached to the metaphors. In all_pos_tokens, only six out of these 14 tokens are chosen as targets for classification. These tokens are:
villagers,
seemed,
unimpressed,
given,
choice, and
matter. In this work, after Neidlein et al. [
19], the name VUA-ALL-POS refers to the dataset utilizing only the target words specified by all_pos_tokens and all_pos_tokens_test. The dataset called VUA-20, which we adopt from Choi et al. [
10] and which we use in the experiments, comprises the same testing data, yet it produces more training samples from vuamc_corpus_train than specified by all_pos_tokens. In the example sentence above, VUA-20 uses all of the available tokens, excluding punctuation, as targets for classification. VUA-20 takes advantage of both content words (belonging to verbs, nouns, adjectives and adverbs) and function words (members of remaining parts of speech), while VUA-ALL-POS is said to limit itself to the content words only (excluding verbs
have,
do and
be). This difference results in a much bigger number of target tokens available in the former’s training set (160,154 and 72,611 for VUA-20 and VUA-ALL-POS, respectively). At the same time, for reasons unknown, VUA-20 lacks 86 of the target tokens used in VUA-ALL-POS. With this exception, VUA-20 can be therefore viewed as an extended variant of VUA-ALL-POS. VUA-20 includes all of the sentences utilized by VUA-ALL-POS plus those excluded from the latter due to the POS-related restrictions. As a result, while there are 12,122 unique sentences provided in total by vuamc_corpus_train, the numbers of sentences used for training in VUA-20 and VUA-ALL-POS are 12,093 and 10,894, respectively. The 29 “sentences”, which VUA-20 is lacking with respect to vuamc_corpus_train, were excluded, presumably because they are either empty strings or single punctuation characters (“”, “.”, “!”, and “?”). As mentioned, testing data is common for both datasets: they comprise the same 22,196 target tokens coming from 3698 sentences selected from 4080 available in total in vuamc_corpus_test.
VUA-SEQ (we use this name after Neidlein et al. [
19]) is another dataset built upon VUAMC. It was used in the works of Gao et al. [
35] and Mao et al. [
36], among the others. It differs from VUA-ALL-POS in that it employs different splits of VUAMC and in that it uses all of the tokens available in a sentence as targets for classification (including punctuation marks). This results in a much bigger number of target tokens used by VUA-SEQ in comparison with VUA-ALL-POS (205,425 and 94,807, respectively). However, VUA-SEQ uses a smaller number of unique sentences than VUA-ALL-POS (10,567 and 14,974, respectively). Unlike VUA-ALL-POS, VUA-SEQ has a development set as well. VUA-18, which we adopt from Choi et al. [
10], is very similar to VUA-SEQ, as it uses the same sentences in each of the subsets (6323, 1550, and 2694 sentences for training, development, and testing sets, respectively). What does not allow for calling the two datasets identical is that VUA-18 does not count contractions and punctuation marks as separate tokens (there is a very small number of exceptions to this general rule). For example, the sentence coded in VUAMC as: “M_Lot of M_things daddy has n’t seen .” is divided into 8 tokens in VUA-SEQ, whereas in VUA-18 it is presented as “Lot of things daddy hasn’t seen.”, which results in using only 6 tokens and 6 corresponding labels (without “n’t” and “.”). In consequence, the numbers of tokens are: 116,622 and 101,975 in the training sets, 38,628 and 34,253 in the development sets, 50,175 and 43,947 in the testing sets of VUA-SEQ and VUA-18, respectively. We are not utilizing VUA-18’s development set in the experimental trials.
VUA-VERB, which we adopt from Choi et al. [
10], utilizes the same sentences as those selected in the lists prepared for the Metaphor Detection Shared Task (verb_tokens and verb_tokens_test), although it splits the original training data into training and validation subsets. While in verb_tokens there are 17,240 target tokens used for training, in VUA-VERB there are 15,516 and 1724 tokens comprised by its training and development sets, respectively. The number of tokens used for testing equals 5873, which is the same in both cases. In the experimental trials, we are not taking advantage of VUA-VERB’s development set.
Although Neidlein et al. [
19] claim that it is only the content words (verbs, nouns, adjectives, and adverbs), whose labels are being predicted in VUA-ALL-POS, this is not entirely accurate. There are instances of interjections (
Ah in “Ah, yeah.”), prepositions (
like in “(…) it would be interesting to know what he thought children were like.”), conjunctions (
either in “(…) criminal behaviour is either inherited or a consequence of unique, individual experiences.”), etc.
While in their paper Su et al. formulate the opinion that “POS such as punctuation, prepositions, and conjunctions are unlikely to trigger metaphors” ([
21], p. 32), at the same time they provide the evidence for the opposite, at least with regard to the prepositions: from Figure 5 they attach, it is clear that the adpositions are annotated as being used metaphorically more often than any other part of speech in VUAMC ([
21], p. 35). This should come as no surprise, as, for example, there are entire tomes devoted to the analysis of the primarily spatial senses of temporal prepositions and related metaphorical meaning extensions (cf. [
48,
49,
50]).
3.3. Data Preprocessing
For data preprocessing, we use Python equipped with WordNetLemmatizer (
https://www.nltk.org/_modules/nltk/stem/wordnet.html; last accessed on 21 December 2021) for obtaining the dictionary forms of given words and Wiktionary Parser (
https://github.com/Suyash458/WiktionaryParser; last accessed on 21 December 2021) for retrieving their definitions. As the outputs are different for different parts of speech, we take advantage of the POS tags already included in the datasets. These, however, have to be first mapped to the format used by Wiktionary. It is noteworthy that not all of these POS tags are accurate, which sometimes prevents the algorithm from retrieving the appropriate definition.
In Delahunty and Garvey’s book [
51], nouns, verbs, adjectives, and adverbs are termed as the
major parts of speech, and as such are contrasted with the
minor parts of speech (all the others). Alternatively, they can be called the
content words and the
function words, respectively (cf. Haspelmath’s analysis [
52]). The former have more specific or detailed semantic content, while the latter have a more
non-conceptual meaning and fulfill an essentially
grammatical function [
53]. As a result of this, in general, definitions of the function words do not add much of semantic information that could be used in metaphor detection. On the contrary, using averaged vectors of their component tokens could become a source of unnecessary noise, leading to performance decay (consider the first definition of the very frequently occurring determiner
the found in Wiktionary: “Definite grammatical article that implies necessarily that an entity it articulates is presupposed; something already mentioned, or completely specified later in that same sentence, or assumed already completely specified”). When it comes to function words, we therefore decided to use their lemmas instead of definitions. In this regard, we have made an exception for 12 prepositions, namely:
above,
below,
between,
down,
in,
into,
on,
over,
out,
through,
under, and
up. These are all very frequent, as they all constitute a part of the stopwords from NLTK’s
corpus package (
https://www.nltk.org/_modules/nltk/corpus.html; last accessed on 21 December 2021). When present in utterances, they often manifest the underlying image schemata well known from the Conceptual Metaphor Theory first popularized by Lakoff and Johnson in [
54] and further described in detail by other authors, for example by Gibbs in [
55]. Admittedly, the choice of the words from the outside of the major parts of speech category is subjective and could be made differently.
We assumed that it is likely that the first definition available in the Wiktionary is going to be the one representing a word’s
basic meaning and therefore we retrieve only the first of the definitions available for the given part of speech. This choice was preceded with the lecture of Wiktionary guidelines (
https://en.wiktionary.org/wiki/Wiktionary:Style_guide#Definitions; last accessed on 21 December 2021), where—at least for the complex entries—it is explicitly recommended to use the logical hierarchy of the word senses, meaning:
core sense at the root. The relation between basic meanings and metaphoricity within the logical hierarchy is explained in [
56] (p. 285; emphasis added):
The logical ordering runs from core senses to subsenses. Core meanings or basic meanings are the meanings which are felt as the most literal or central ones. The relation between core sense and subsense may be understood in various ways, e.g., as the relation between general and specialised meaning, central and peripheral, literal and non-literal, concrete and abstract, original and derived.
Following the general strategy of using only the first of the available definitions, we make an exception for the words whose first definitions include the tags
archaic and
obsolete. Although, as mentioned in
Section 2.2.1, the MIP (Metaphor Identification Procedure) postulates considering the historical antecedence as one of the cues in establishing a given word’s basic meaning, studying the data coming from Wiktionary led us to the conclusion that very often the definitions comprising the aforementioned labels stand for the senses that are no longer accessible to contemporary language users. For this reason, we argue that they should not be treated as the
basic senses and that it is not appropriate to compare them with the contextual senses in order to decide whether a word is used figuratively. In practice, our algorithm collects the first definition of a given target word without the words
archaic and
obsolete (or their derivatives) inside the brackets. For example, the definitions of the verb
consist available in the Wiktionary are as follows:
(obsolete, copulative) To be.
(obsolete, intransitive) To exist.
(intransitive, with in) To be comprised or contained.
(intransitive, with of) To be composed, formed, or made up (of).
Out of these four, it is the third definition that includes neither of the tags mentioned above and thus becomes accepted by our algorithm. Furthermore, as with all other definitions we collect, the brackets along with their content become erased. The final shape of the definition adopted for the target word contain is therefore: To be comprised or contained. In the case where all the definitions of a given word include either archaic or obsolete labels, we keep the first definition from the list.
Using the algorithm illustrated above, the definitions are collected automatically and without supervision, which significantly reduces costs. Experimental results presented in the following section prove that this simple method is in fact very efficient.


 ,
, 




{kind=link}
{kind=link}
{kind=link}