1. Introduction
Observations of long-term natural processes, in particular magnetometry, at first sight, fully meet the initial requirements of mathematical statistics and, thus, the methods of this scientific discipline are widely used in data processing. At the same time, the characteristic of deviation (from mean values, baseline, mean scatter of instrument readings, etc.), which is usually referred to as the residual term, is important enough for estimating the quality of observations. Corresponding statistics are related to the simplest statistical formula, which works fine in theory in the situation of fairness of the Gaussian hypothesis for the recorded data. The same hypothesis, at first sight, should be fulfilled in the situation of vector magnetic measurements because the observed value of the magnetic vector is always a sum of magnetic influences from many local and global sources, and the distribution law for sums of random variables is predicted by the Central Limit Theorem of Probability Theory, which states that under rather simple conditions, the sum of many independent random influences is very well approximated by the Gaussian law.
Therefore, it is a common opinion that in processing observational data and calculating the characteristics of these data (for example, calculating the mean value of the residual), we can use Gaussian statistics without any restrictions and there is no reason to doubt the numerical value of the answer, which corresponds to the RMS deviation of a Gaussian random variable. However, the stationary nature of natural fluctuations can be assumed only with respect to specific time intervals: magnetic field measurements over a relatively short time can include significant nonstationarity of external factors—seasonal variations, magnetic storms, the presence of specific technological disturbances, etc. Thus, the idea that the observational series is just a sample of the general population corresponding to a fixed Gaussian random variable will generally give a very unrealistic picture. A more adequate model seems to be that of a mixture of random variables differing in parameters, and parameter variations are described by a separate random variable whose value distribution can be neglected only in a stationary situation.
Earlier, the general approach was outlined in the article [
1] for the example of real magnetic data, referring, however, not to ground-based magnetic observations, but to observations of magnetic satellites of the project Swarm, crossing different intensities of magnetic fields. In this case, in a relatively small time interval, it is possible to collect a lot of data that reflect random field variations, the corresponding data model was substantiated in detail in [
1].
In the present article, we will consider the computations and, for the convenience of understanding the statistical model of variability, we will refer to exactly the same data as in [
1]. The difference in the method of processing a large volume of SWARM magnetometer data and a large volume of observatory magnetometer data is insignificant for the explanation of the method as such.
Recall that typical appropriate statistical assumptions are being made with respect to the distribution of the uncertainties affecting the data used. The statistical properties of these uncertainties, however, are not always well characterized. In such circumstances, assuming that uncertainties follow a Gaussian distribution would a priori make sense, since such a distribution often arises naturally as a consequence of the central limit theorem (i.e., when errors act in an additive manner). Relying on this assumption, and provided that is an adequate measure of the error affecting the datum , standard statistical estimations are then used to infer the model. The normalized residuals ( here being the datum value predicted by the model) are expected to follow a standard normal distribution.
Yet, residuals of geomagnetic observations of an arbitrary type often display a sharper distribution, sometimes much closer to that of the so-called Laplace distribution (e.g., [
2,
3,
4,
5]). We suggested in [
1] that residuals may be incorrectly normalized and, therefore, their common statistical distribution is a mixture of Gaussian distributions. In particular, we demonstrated in [
1] several examples of the variability in
determination that indeed lead to the non-Gaussian shape of the histogram. Thus, we assume that the observable residual
is a mixture of individual Gaussian random variables with zero expectations and random variances
. In the present short note, we argue that the distribution of the random variable
can be well approximated by the lognormal distribution with pdf
We also provide the method that recovers the value of s in the real data case.
2. Mixture Model
2.1. The Unformal Interpretation
The mixture model is appropriate for the situation when the data are inhomogeneous, for instance, they come from several locations such that each region slightly perturbs the assumed data distribution law, i.e., the corresponding distribution formulae differ slightly in their parameters. In practice, we often face an even simpler situation: each set of regional data is Gaussian with mean zero but the corresponding -value depends on the region. However, we rarely can select the region with absolutely homogeneous data in it; therefore, we better simulate these situations by means of sequential small perturbations of the initially homogeneous Gaussian population. Can the limit distribution be described given the very small intermediate perturbations?
Of course, the model of successive repeated small random perturbations applied to a stationary process is only one of many possible ones. However, this model allows statistical estimation of residuals in a simple and straightforward computational procedure and eventually allows the model data to be simulated in order to compare them with the actually observed data. Relevant comparison procedures are available in nonparametric statistics, such as the well-known Kolmogorov–Smirnov test.
The statistical Kolmogorov–Smirnov criterion on large samples is very sensitive and therefore can certainly indicate more subtle effects, even of non-random nature, present in the data.
2.2. Version of the General Formula
If
is an arbitrary random variable with density
, then for fixed
, the ratio
has density
, see also (see, e.g., [
6]). Let now the denominator not be fixed but a positive random variable with density
, then, we obtain the pdf for this ratio
We may now compare the mixture of unbiased Gaussian distributions (i.e., with pdf
) by randomizing their standard deviations using a random variable
:
Obviously, can be interpreted as the pdf of the ratio.
For instance, recall the following example of [
1]: the uniform mixture of unbiased Gaussian distributions with standard deviations varying between 0 and 1, i.e., mixing pdf is
We may treat that mixture as the ratio of standard Gaussian
divided by
—the inverse of the uniform distribution:
2.3. Sequential Small Mixtures
The
small multiplicative randomization is described in terms of a random
with pdf
out of
for some small
, we may assume
where expectancy
and variance
. For the sequential small mixtures (with independent
), we obtain the ratio
However, under the mild conditions, the distribution of
rapidly converges to a Gaussian distribution
with
and
. Thus, the limit pdf for sequential
arbitrary, but small mixtures can be approximated by
If we rescale
in this expression, then we obtain the representation for
; we also apply the change of variables
and derive another formula of
in terms of
:
for some suitable parameters
s and
.
Of course, the model of successive repeated small random perturbations applied to a stationary process is only one of many possible ones. However, this model allows statistical estimation of residuals in a simple and straightforward computational procedure and eventually allows the model data to be simulated in order to compare them with the actually observed data.
3. Method: Real Data Analysis
As in [
1], we consider the absolute scalar data acquired by two of the Swarm satellites (Satellites Alpha and Bravo) at quasi-latitudes ranging between
and
, and computed residuals with respect to the so-called VFM model of [
7]: for the the array
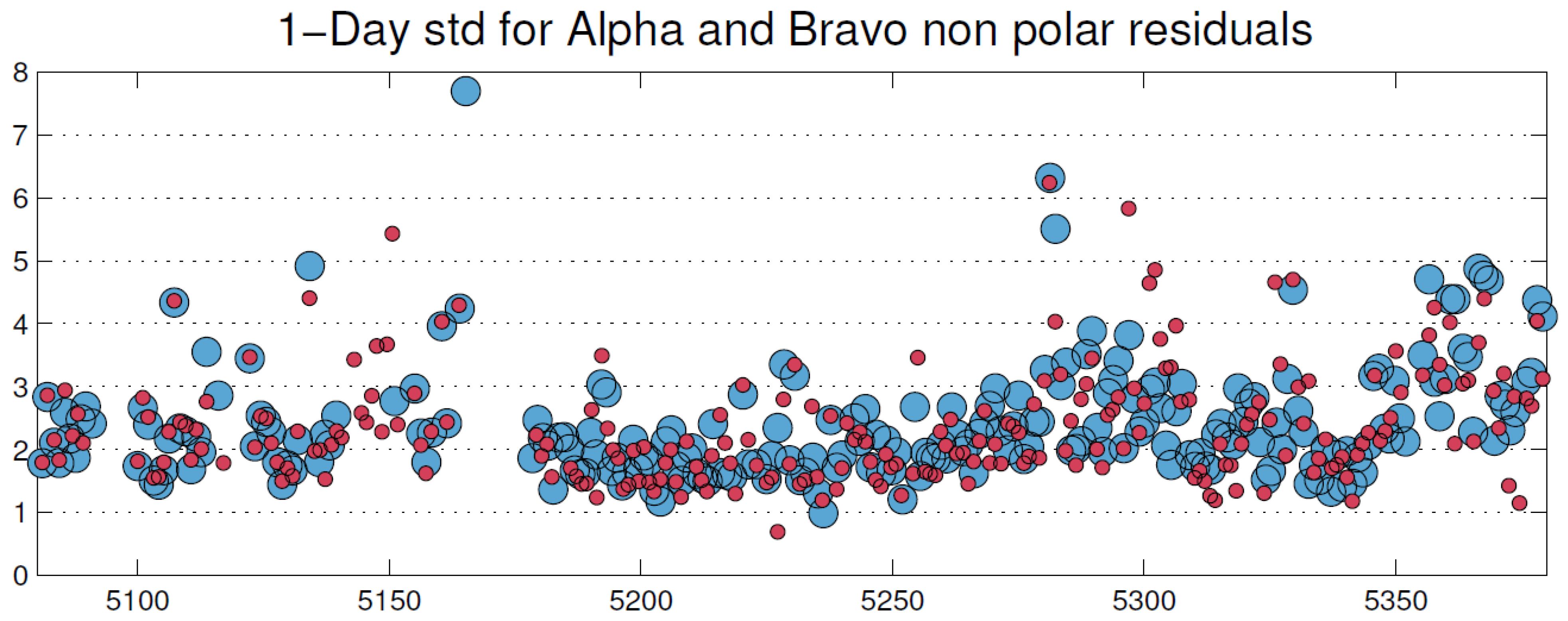
of one-day std of residuals, take a look at
Figure 1 borrowed from our article. Rescale this array
as
where
and
; by virtue of Equation (
2), the array
is expected to obey the lognormal distribution with parameter
(see Equation (
3)) and we can directly calculate
and
.
Now, repeat all these computations for arrays , , (i.e., corresponding to time intervals of 0.25 to 0.75 days). The results are as follows:
: Satellite A , Satellite B
: Satellite A , Satellite B
: Satellite A , Satellite B
: Satellite A , Satellite B
As often happens, a limited amount of lognormal data cannot provide stable statistical estimates. So, what are the “true values” of
s and
? To answer this question, let us use the following well-known method of the statistical moments of
, namely:
Thus, we obtain the explicit expressions of the unknown parameters
In practice, we recover from real data the estimates of the moments , and then get (the estimates of) the unknown parameters.
The satellite scalar data [
7] cover a little less than a year (between 29 November 2013 and 25 September 2014) and were further selected following a number of criteria, among which magnetically quiet and night-time conditions, to ensure that as little as possible non-modeled external signal is included in the data. This resulted in 42,160 data points for the Alpha satellite and 42,175 for the Bravo satellite. These data can be expected to reflect the signal of the field of internal origin the model tries to model, any other source of signal being treated as a source of noise acting on top of the very low instrumental and satellite noise (less than 0.3 nT, see [
8,
9,
10]).
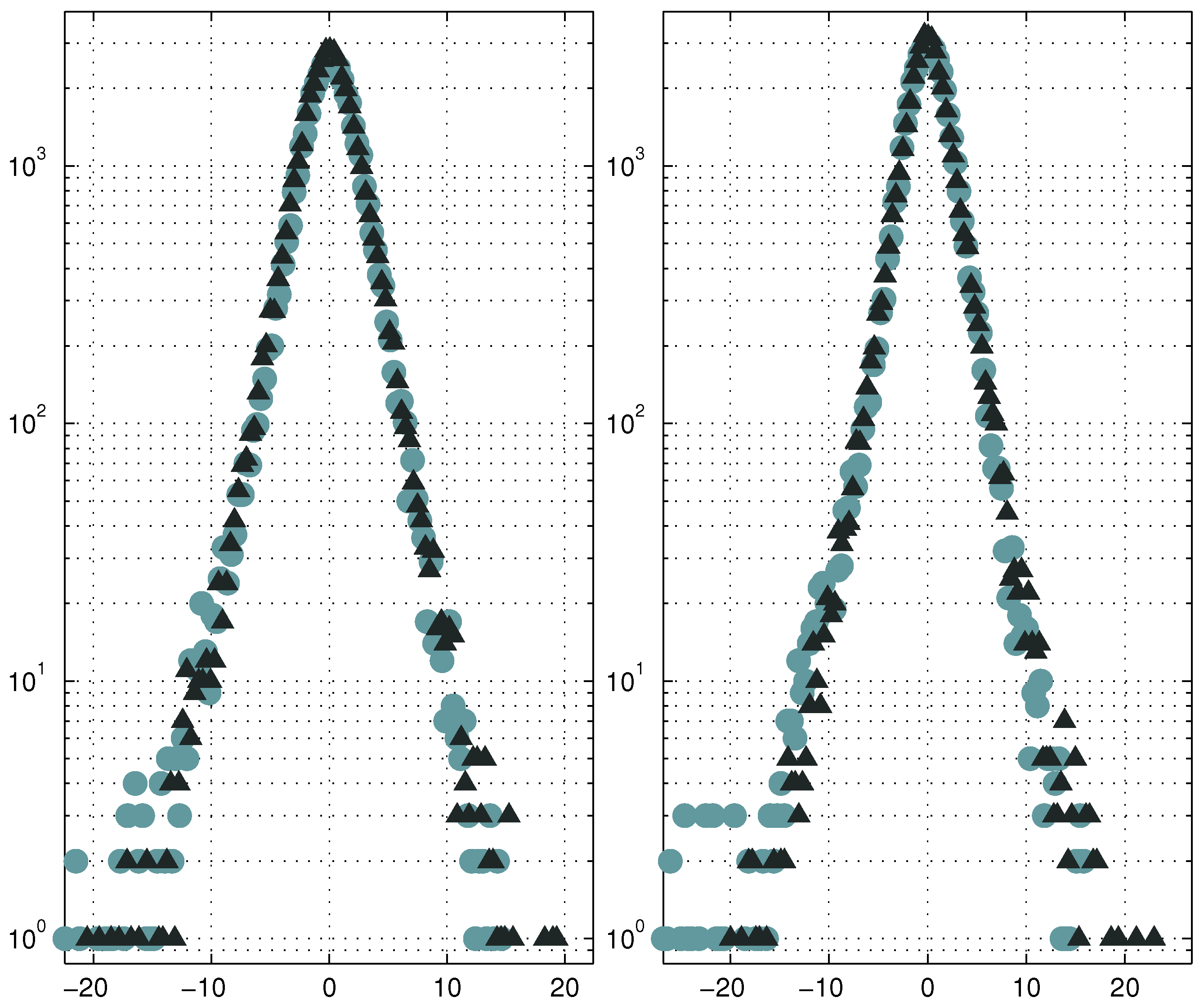
We may now add the quantitative details of the data distribution to the qualitative analysis of it that was published in [
1]: namely, using formula (
4), we may now recover the estimates of the parameters
s and
(the latter can be treated as an estimate for the “inner precision” of measurements);
Figure 2 actually confirms the fact that this close-to-Laplacian distribution indeed can be represented as the result of a lognormal mixture according to formula (
3).
4. Discussion
In general, the study of the behavior of residuals in the case of magnetic observations is aimed at quantifying the accuracy of instrumental measurements and to quantify external influences, which are calculated differently in the Gaussian data model and in the mixed model.
As part of the reasoning for the applicability of the aforementioned mixture model in case of SWARM data, it appears that for moderate amounts of data (), the KS test does not reject the model; nevertheless, as N grows to several tens of thousands measurements, the model clearly does not exhaust the complexity of inhomogeneous effects available in the SWARM magnetic data and is therefore formally rejected by the KS criterion.
An important detail related to our model is that we assume a continuous mixture and obtain its analytic form. This is certainly an idealistic assumption, which needs not be absolutely true, especially if we have strong discrete effects in the magnetic data: for example, if we consider daytime and nighttime observations simultaneously. In this case, we are better off using a probabilistic model, which assumes that all data points appear from a mixture of a finite number of Gaussian distributions with unknown parameters. Fortunately, when the number of Gaussian distributions involved is known (at least approximately), then a well-known EM algorithm can provide (via maximum likelihood estimation) the parameters of the corresponding discrete statistical model.
5. Conclusions
This purely numerical approach is not new, but in the present study, we consider an assumption that seems to be a rather novel approach to practical residuals. Which approach is more appropriate depends on the specific situation. For example, the continuous analytical formula given above gives hope that in the case of ground-based magnetic observations over a relatively short time interval, our methods for calculating the unsteadiness will prove to be a useful refinement and, at the same time, allow us to isolate subtle effects of unsteady field behavior.



{kind=link}
{kind=link}

