
Privacy-Aware and Secure Decentralized Air Quality Monitoring

 ,
,  ,
,  , , , , ,
, , , , ,  and
and 
Abstract
:1. Introduction
2. Motivating Scenario
- The Danilo Lokar primary school, located in Ajdovščina, Slovenia;
- The Peavey hall research laboratory, located in Corvallis, Oregon, USA;
- The Nobatek research building, located in Anglet, France;
- The InnoRenew research building, located in Izola, Slovenia;
- The AlbaComp company offices, located in Szeged, Hungary.
3. Related Work
3.1. Decentralized IAQ Monitoring Frameworks
3.2. Decentralized Data Mining
3.3. Security of WSN Data Processing
3.4. Decentralized Privacy-Aware Data Storage
3.5. Routing and Sink Placement Optimization
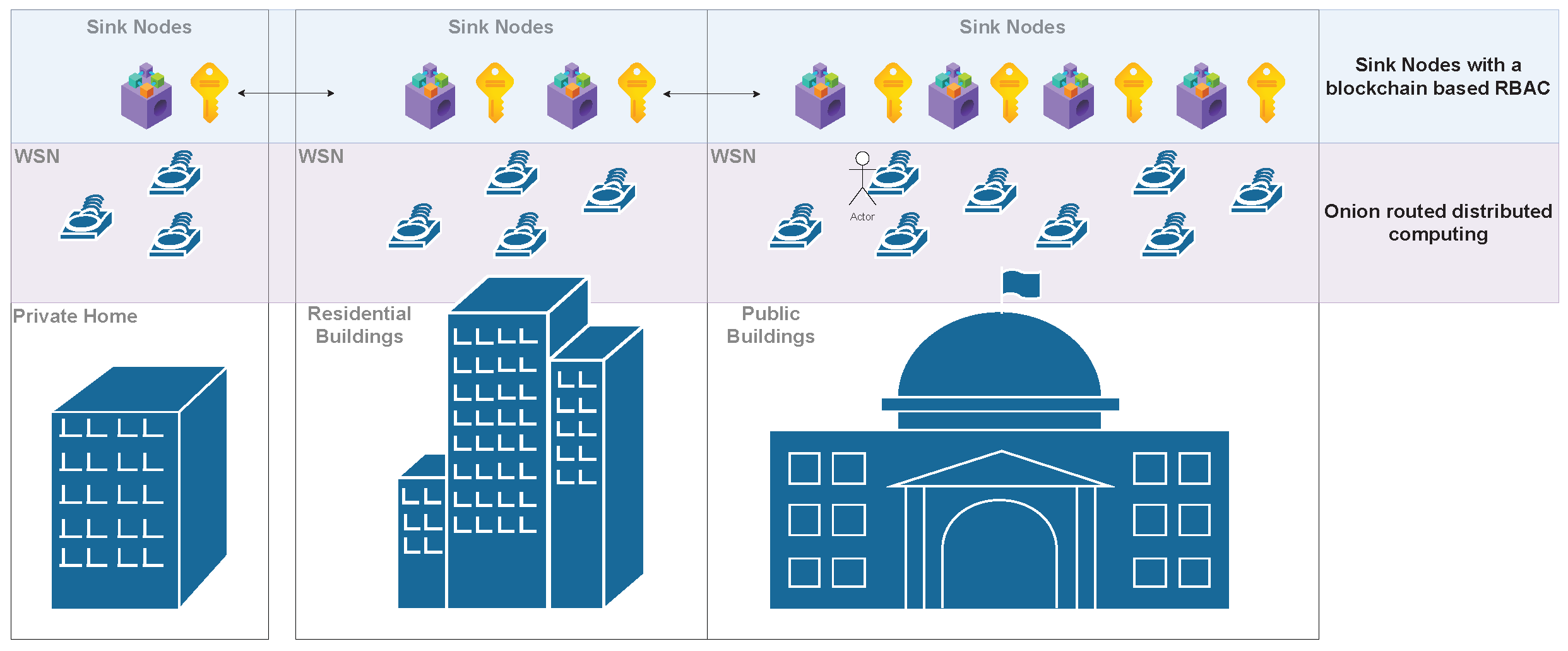
4. A Privacy-Aware and Secure Decentralized Framework
4.1. General Framework Overview
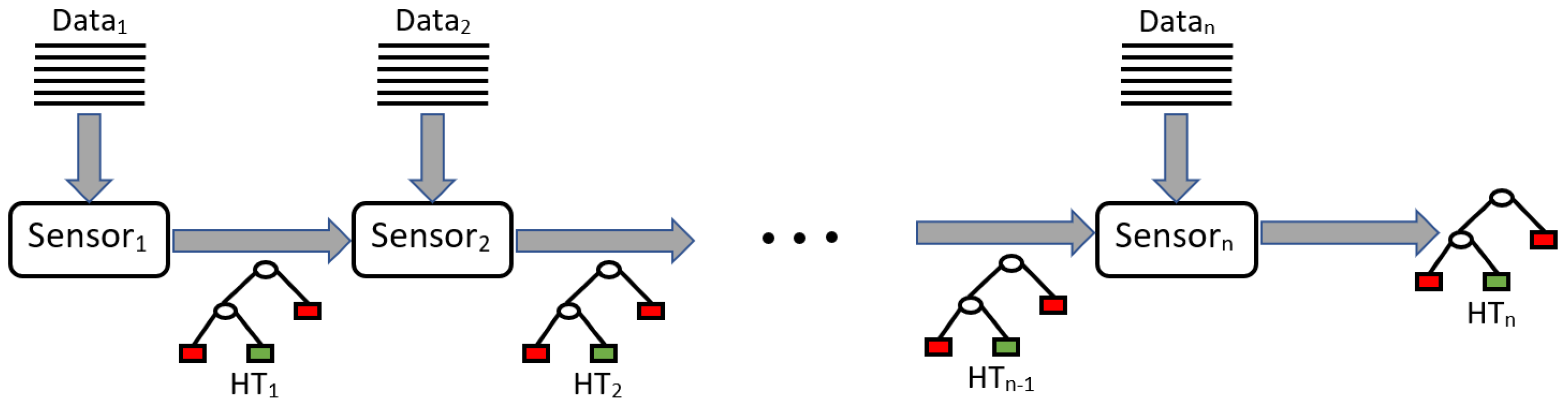
4.2. Decentralized Data Mining
4.3. Security of WSN Data Processing
4.4. Decentralized Privacy-Aware Data Storage
4.5. Routing and Sink Placement Optimization
- Phase 1:
- collect the information about the network at one node;
- Phase 2:
- compute the distance matrix D;
- Phase 3:
- build an MILP (Mixed Integer Linear Program) to solve the optimization problem from Equation (1);
- Phase 4:
- solve MILP;
- Phase 5:
- distribute solution.
5. Evaluation and Discussion
5.1. Decentralized Data Mining
5.1.1. Experimental Setting
5.1.2. Simulation Results
5.2. Security of WSN Data Processing
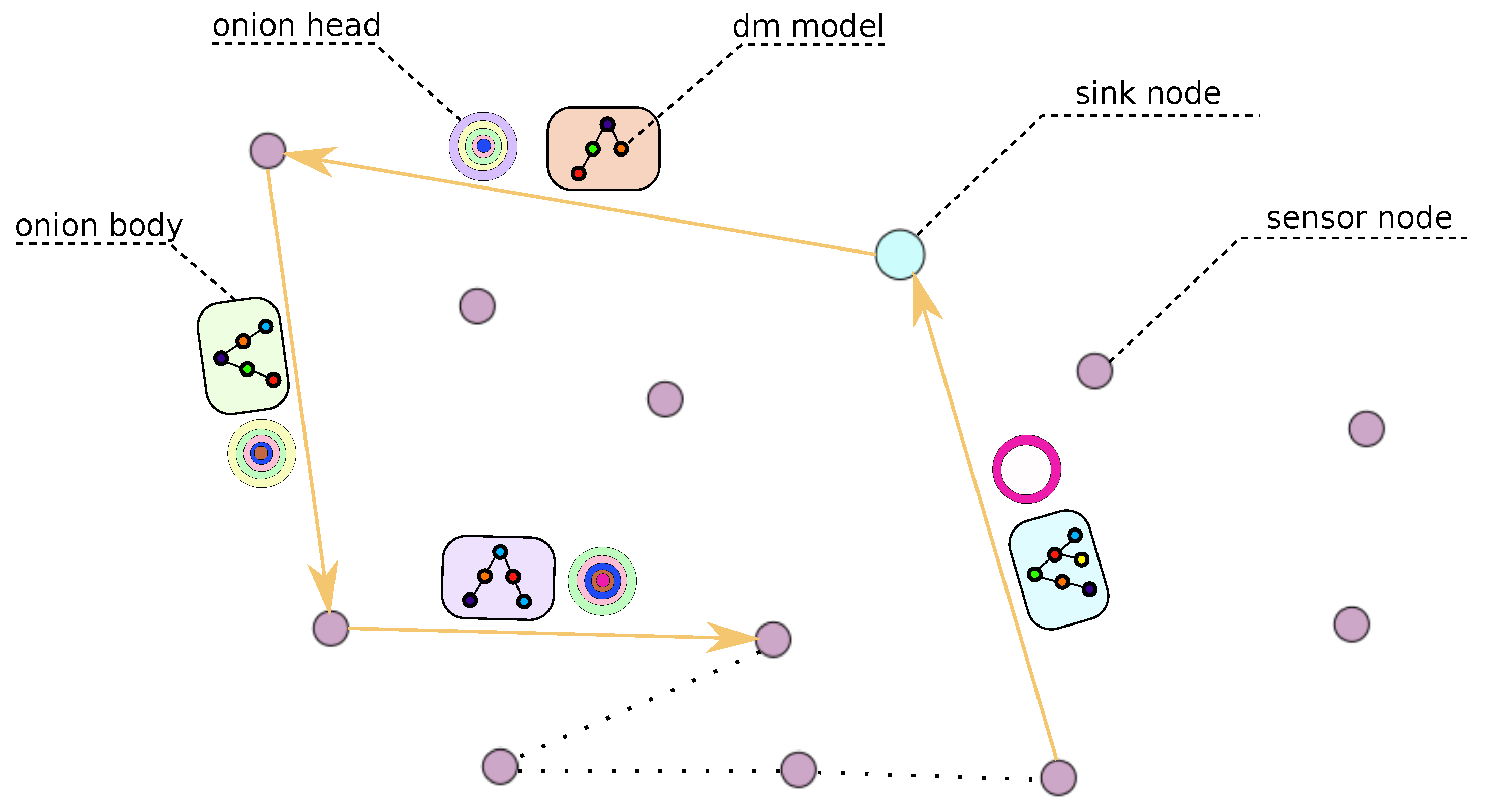
5.2.1. Privacy Preservation against Eavesdropping
- Sensor nodes are not reporting data to the sink node, but the sink node queries sensor nodes.
- All onion messages traveling the network are of the same size since padding is added at each message processing.
- DQ3P requires encryption at data-link-layer; therefore, after each message processing, the onion message is forwarded to the next-hop node completely changed by encryption.
- By DQ3P design, half of the nodes processing an onion message only retain it for a time interval to simulate model learning. We refer to these nodes as decoy nodes.
- Onion messages travel a randomized path since decoy node addresses are encoded at random positions in the message path during message construction.
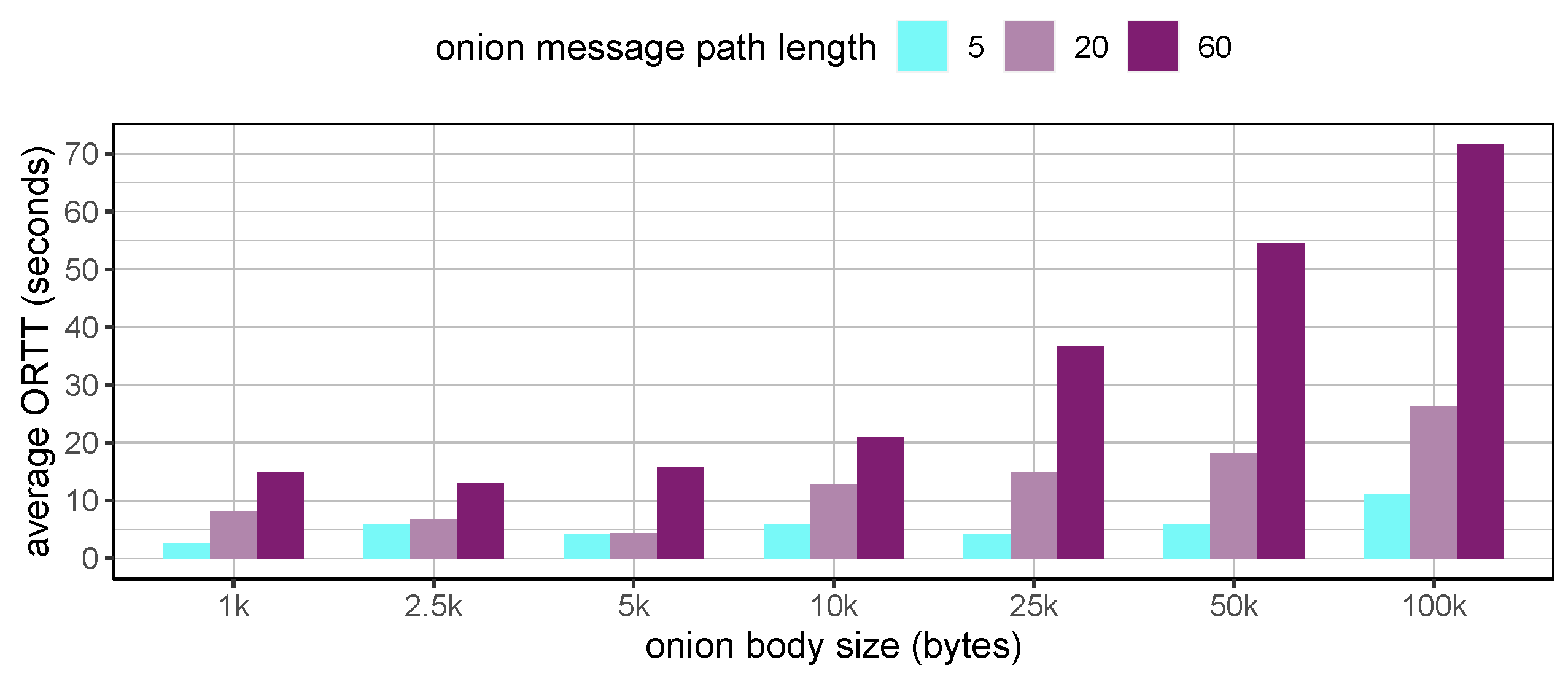
5.2.2. Evaluation of DQ3P for Distributed Data Mining
Experimental Setup
Simulation Results
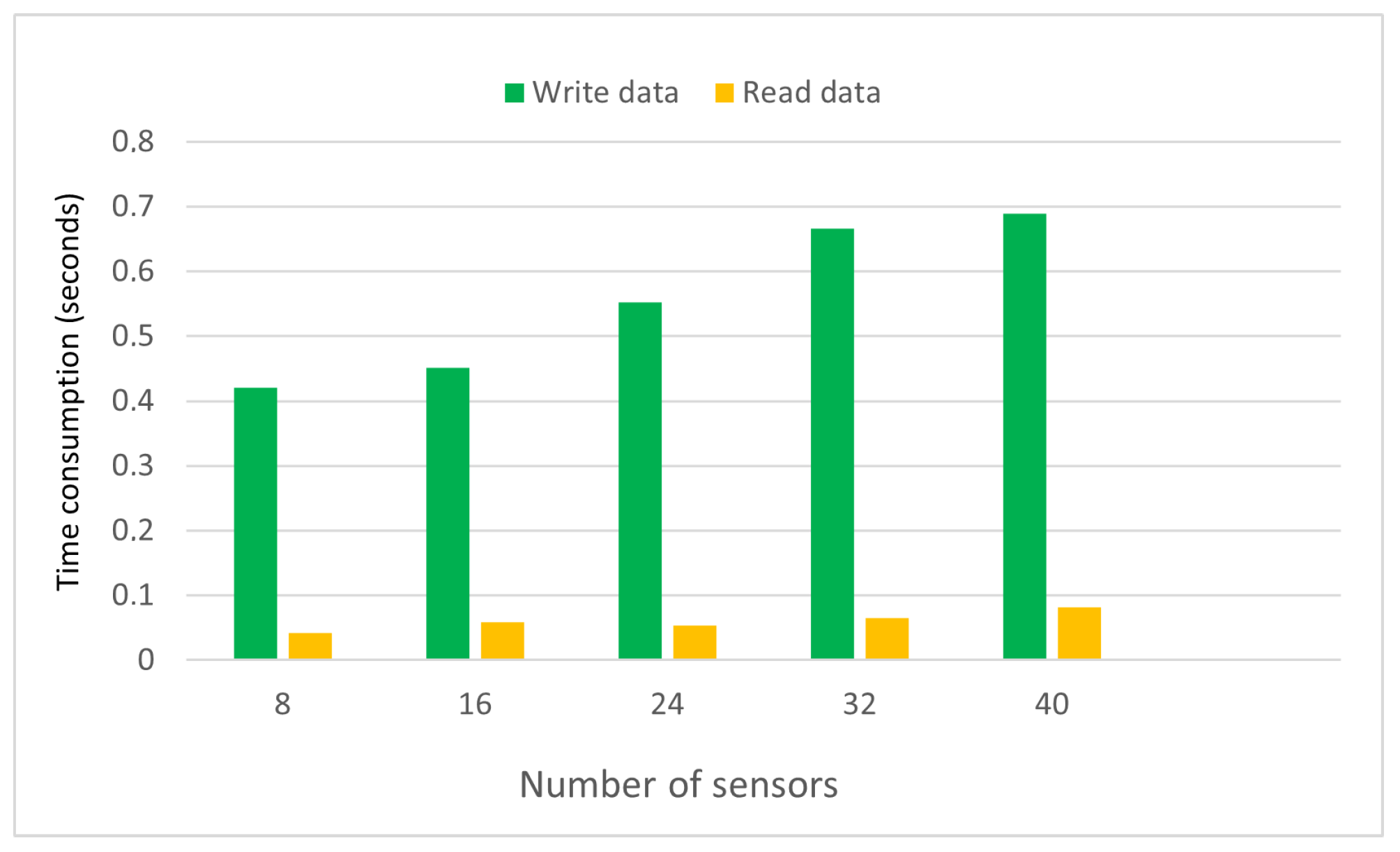
5.3. Decentralized Privacy-Aware Data Storage
5.4. Routing and Sink Placement Optimization
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tham, K.W. Indoor air quality and its effects on humans—A review of challenges and developments in the last 30 years. Energy Build. 2016, 130, 637–650. [Google Scholar] [CrossRef]
- Kumar, P.; Martani, C.; Morawska, L.; Norford, L.; Choudhary, R.; Bell, M.; Leach, M. Indoor air quality and energy management through real-time sensing in commercial buildings. Energy Build. 2016, 111, 145–153. [Google Scholar] [CrossRef]
- Garcia Lopez, P.; Montresor, A.; Epema, D.; Datta, A.; Higashino, T.; Iamnitchi, A.; Barcellos, M.; Felber, P.; Riviere, E. Edge-Centric Computing: Vision and Challenges; ACM SIGCOMM: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Saini, J.; Dutta, M.; Marques, G. Indoor Air Quality Monitoring Systems Based on Internet of Things: A Systematic Review. Int. J. Environ. Res. Public Health 2020, 17, 4942. [Google Scholar] [CrossRef] [PubMed]
- Abreu, A.; Lopes, S.I.; Manso, V.; Curado, A. Low-Cost LoRa-Based IoT Edge Device for Indoor Air Quality Management in Schools. In Science and Technologies for Smart Cities; Paiva, S., Lopes, S.I., Zitouni, R., Gupta, N., Lopes, S.F., Yonezawa, T., Eds.; Springer: Cham, Switzerland, 2021; pp. 246–258. [Google Scholar]
- Cocos, H.N.; Merkl, D. Decentralized Data Processing On The Edge—Accessing Wireless Sensor Networks with Edge Computing. In Proceedings of the 16th International Conference on Applied Computing, Cagliari, Italy, 15–16 September 2019; pp. 265–269. [Google Scholar]
- Sun, S.; Zheng, X.; Villalba-Díez, J.; Ordieres-Meré, J. Indoor Air-Quality Data-Monitoring System: Long-Term Monitoring Benefits. Sensors 2019, 19, 4157. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zheng, X.; Lu, J.; Sun, S.; Kiritsis, D. Decentralized industrial IoT data management based on blockchain and IPFS. In IFIP International Conference on Advances in Production Management Systems; Springer: Berlin/Heidelberg, Germany, 2020; pp. 222–229. [Google Scholar]
- Legault, M. A Practitioner’s View on Distributed Storage Systems: Overview, Challenges and Potential Solutions. Technol. Innov. Manag. Rev. 2021, 11, 32–41. [Google Scholar] [CrossRef]
- Benedict, S.; Rumaise, P.; Kaur, J. IoT blockchain solution for air quality monitoring in SmartCities. In Proceedings of the 2019 IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS), Goa, India, 16–19 December 2019; pp. 1–6. [Google Scholar]
- Shih, D.H.; Shih, P.Y.; Wu, T.W. An infrastructure of multi-pollutant air quality deterioration early warning system in spark platform. In Proceedings of the 2018 IEEE 3rd International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 20–22 April 2018; pp. 648–652. [Google Scholar]
- Estrin, D.; Govindan, R.; Heidemann, J.; Kumar, S. Next Century Challenges: Scalable Coordination in Sensor Networks. In Proceedings of the 5th Annual ACM/IEEE International Conference on Mobile Computing and Networking, MobiCom ’99, Seattle, WA, USA, 15–20 August 1999; Association for Computing Machinery: New York, NY, USA, 1999; pp. 263–270. [Google Scholar] [CrossRef]
- Gan, W.; Lin, J.C.W.; Chao, H.C.; Zhan, J. Data mining in distributed environment: A survey. WIREs Data Min. Knowl. Discov. 2017, 7, e1216. [Google Scholar] [CrossRef]
- Laube, P.; Duckham, M. Decentralized Spatial Data Mining for Geosensor Networks. In Geographic Data Mining and Knowledge Discovery; Routledge: London, UK, 2008. [Google Scholar] [CrossRef]
- Gu, T.; Fang, Z.; Abhishek, A.; Mohapatra, P. IoTSpy: Uncovering Human Privacy Leakage in IoT Networks via Mining Wireless Context. In Proceedings of the 2020 IEEE 31st Annual International Symposium on Personal, Indoor and Mobile Radio Communications, London, UK, 31 August–3 September 2020; pp. 1–7. [Google Scholar]
- Zhang, F.; He, W.; Liu, X. Defending against traffic analysis in wireless networks through traffic reshaping. In Proceedings of the 2011 31st International Conference on Distributed Computing Systems, Minneapolis, MI, USA, 20–24 June 2011; pp. 593–602. [Google Scholar]
- Saltaformaggio, B.; Choi, H.; Johnson, K.; Kwon, Y.; Zhang, Q.; Zhang, X.; Xu, D.; Qian, J. Eavesdropping on fine-grained user activities within smartphone apps over encrypted network traffic. In Proceedings of the 10th {USENIX} Workshop on Offensive Technologies ({WOOT} 16), Austin, TX, USA, 10–11 August 2014. [Google Scholar]
- Xu, J.; Yang, G.; Chen, Z.; Wang, Q. A survey on the privacy-preserving data aggregation in wireless sensor networks. China Commun. 2015, 12, 162–180. [Google Scholar] [CrossRef]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In International Conference on the Theory and Applications of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 1999; pp. 223–238. [Google Scholar]
- Wilson, R.L.; Rosen, P.A. Protecting data through perturbation techniques: The impact on knowledge discovery in databases. J. Database Manag. 2003, 14, 14–26. [Google Scholar] [CrossRef] [Green Version]
- Conti, M.; Zhang, L.; Roy, S.; Di Pietro, R.; Jajodia, S.; Mancini, L.V. Privacy-preserving robust data aggregation in wireless sensor networks. Secur. Commun. Netw. 2009, 2, 195–213. [Google Scholar] [CrossRef]
- He, W.; Liu, X.; Nguyen, H.; Nahrstedt, K.; Abdelzaher, T. Pda: Privacy-preserving data aggregation in wireless sensor networks. In Proceedings of the IEEE INFOCOM 2007–26th IEEE International Conference on Computer Communications, Anchorage, AK, USA, 1–12 May 2007; pp. 2045–2053. [Google Scholar]
- He, W.; Nguyen, H.; Liuy, X.; Nahrstedt, K.; Abdelzaher, T. iPDA: An integrity-protecting private data aggregation scheme for wireless sensor networks. In Proceedings of the MILCOM 2008 IEEE Military Communications Conference, San Diego, CA, USA, 16–19 November 2008; pp. 1–7. [Google Scholar]
- Bista, R.; Yoo, H.K.; Chang, J.W. A new sensitive data aggregation scheme for protecting integrity in wireless sensor networks. In Proceedings of the 2010 10th IEEE International Conference on Computer and Information Technology, Bradford, UK, 29 June–1 July 2010; pp. 2463–2470. [Google Scholar]
- Blaß, E.O.; Zitterbart, M. An efficient key establishment scheme for secure aggregating sensor networks. In Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security, Taipei, Taiwan, 21–24 March 2006; pp. 303–310. [Google Scholar]
- Westhoff, D.; Girao, J.; Acharya, M. Concealed data aggregation for reverse multicast traffic in sensor networks: Encryption, key distribution, and routing adaptation. IEEE Trans. Mob. Comput. 2006, 5, 1417–1431. [Google Scholar] [CrossRef] [Green Version]
- Castelluccia, C.; Mykletun, E.; Tsudik, G. Efficient aggregation of encrypted data in wireless sensor networks. In Proceedings of the Second Annual International Conference on Mobile and Ubiquitous Systems: Networking and Services, San Diego, CA, USA, 17–21 July 2005; pp. 109–117. [Google Scholar]
- Lin, Y.H.; Chang, S.Y.; Sun, H.M. CDAMA: Concealed data aggregation scheme for multiple applications in wireless sensor networks. IEEE Trans. Knowl. Data Eng. 2012, 25, 1471–1483. [Google Scholar] [CrossRef]
- Othman, S.B.; Bahattab, A.A.; Trad, A.; Youssef, H. Confidentiality and integrity for data aggregation in WSN using homomorphic encryption. Wirel. Pers. Commun. 2015, 80, 867–889. [Google Scholar] [CrossRef]
- Hayouni, H.; Hamdi, M.; Kim, T.H. A survey on encryption schemes in wireless sensor networks. In Proceedings of the 2014 7th International Conference on Advanced Software Engineering and Its Applications, Hainan Island, China, 20–23 December 2014; pp. 39–43. [Google Scholar]
- Zhao, C.; Zhao, S.; Zhao, M.; Chen, Z.; Gao, C.Z.; Li, H.; Tan, Y.A. Secure multi-party computation: Theory, practice and applications. Inf. Sci. 2019, 476, 357–372. [Google Scholar] [CrossRef]
- Vaidya, J.; Clifton, C. Secure set intersection cardinality with application to association rule mining. J. Comput. Secur. 2005, 13, 593–622. [Google Scholar] [CrossRef] [Green Version]
- Kantarcioglu, M.; Clifton, C. Privacy-preserving distributed mining of association rules on horizontally partitioned data. IEEE Trans. Knowl. Data Eng. 2004, 16, 1026–1037. [Google Scholar] [CrossRef] [Green Version]
- Du, W.; Zhan, Z. Building Decision Tree Classifier on Private Data. In Proceedings of the IEEE International Conference on Privacy, Security and Data Mining–Volume 14, Maebashi City, Japan, 1 December 2002; pp. 1–8. [Google Scholar]
- Cock, M.d.; Dowsley, R.; Nascimento, A.C.; Newman, S.C. Fast, privacy preserving linear regression over distributed datasets based on pre-distributed data. In Proceedings of the 8th ACM Workshop on Artificial Intelligence and Security, Denver, CO, USA, 8 June 2015; pp. 3–14. [Google Scholar]
- Jung, T.; Mao, X.; Li, X.Y.; Tang, S.J.; Gong, W.; Zhang, L. Privacy-preserving data aggregation without secure channel: Multivariate polynomial evaluation. In Proceedings of the 2013 IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 2634–2642. [Google Scholar]
- Hrovatin, N.; Tošić, A.; Mrissa, M.; Vičič, J. A General Purpose Data and Query Privacy Preserving Protocol for Wireless Sensor Networks. arXiv 2021, arXiv:cs.CR/2111.14994. [Google Scholar]
- Longo, F.; Nicoletti, L.; Padovano, A.; d’Atri, G.; Forte, M. Blockchain-enabled supply chain: An experimental study. Comput. Ind. Eng. 2019, 136, 57–69. [Google Scholar] [CrossRef]
- Chakravorty, A.; Rong, C. Ushare: User controlled social media based on blockchain. In Proceedings of the 11th International Conference on Ubiquitous Information Management and Communication, Beppu, Japan, 5–7 January 2017; pp. 1–6. [Google Scholar]
- Huang, H.; Zhou, X.; Liu, J. Food supply chain traceability scheme based on blockchain and EPC technology. In International Conference on Smart Blockchain; Springer: Berlin/Heidelberg, Germany, 2019; pp. 32–42. [Google Scholar]
- Zyskind, G.; Nathan, O. Decentralizing privacy: Using blockchain to protect personal data. In Proceedings of the 2015 IEEE Security and Privacy Workshops, San Jose, CA, USA, 21–22 May 2015; pp. 180–184. [Google Scholar]
- Shafagh, H.; Burkhalter, L.; Hithnawi, A.; Duquennoy, S. Towards blockchain-based auditable storage and sharing of IoT data. In Proceedings of the 2017 on Cloud Computing Security Workshop, Dallas, TX, USA, 3 November 2017; pp. 45–50. [Google Scholar]
- Ali, S.; Wang, G.; White, B.; Cottrell, R.L. A blockchain-based decentralized data storage and access framework for pinger. In Proceedings of the 2018 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; pp. 1303–1308. [Google Scholar]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Hedrick, C. Routing Information Protocol; RFC 1058; Internet Engineering Task Force: Fremont, CA, USA, 1988. [Google Scholar]
- Malkin, G. RIP Version 2; RFC 2453; Internet Engineering Task Force: Fremont, CA, USA, 1998. [Google Scholar]
- Malkin, G.; Minnear, R. RIPng for IPv6; RFC 2080; Internet Engineering Task Force: Fremont, CA, USA, 1997. [Google Scholar]
- Brodnik, A.; Grgurovič, M.; Požar, R. Modifications of the Floyd-Warshall algorithm with nearly quadratic expected-time. Ars Math. Contemp. 2021, 22. [Google Scholar] [CrossRef]
- Zhang, L.Y.; Jian, M.; Li, K.P. A Parallel Floyd-Warshall algorithm based on TBB. In Proceedings of the 2010 2nd IEEE International Conference on Information Management and Engineering, Kunming, China, 26–28 November 2010; pp. 429–433. [Google Scholar] [CrossRef]
- Yu, J.; Chen, Y.; Ma, L.; Cheng, X. On Connected Target k-Coverage in Heterogeneous Wireless Sensor Networks. Sensors 2016, 16, 104. [Google Scholar] [CrossRef] [Green Version]
- Bhushan, M.; Narasimhan, S.; Rengaswamy, R. Robust sensor network design for fault diagnosis. Comput. Chem. Eng. 2008, 32, 1067–1084. [Google Scholar] [CrossRef]
- Zorbas, D.; Raveneau, P.; Ghamri-Doudane, Y. Assessing the cost of deploying and maintaining indoor wireless sensor networks with RF-power harvesting properties. Pervasive Mob. Comput. 2017, 43, 64–77. [Google Scholar] [CrossRef]
- Engmann, F.; Katsriku, F.; Abdulai, J.D.; Adu-Manu, K.; Banaseka, F. Prolonging the Lifetime of Wireless Sensor Networks: A Review of Current Techniques. Wirel. Commun. Mob. Comput. 2018, 2018, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Haynes, T.W.; Hedetniemi, S.T.; Slater, P.J. Domination in Graphs: Advanced Topics; Routledge: London, UK, 1998. [Google Scholar]
- Zanjirani Farahani, R.; Hekmatfar, M. Facility Location: Concepts, Models, Algorithms and Case Studies; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Frendrup, A.; Tuza, Z.; Dahl, P. Distance Domination in Vertex Partitioned Graphs; Research Report Series No. R-2009-10; Department of Mathematical Sciences, Aalborg University: Aalborg, Denmark, 2009. [Google Scholar]
- Zhang, Z.; Liu, Q.; Li, D. Two Algorithms for Connected R-Hop k-Dominating Set. Discret. Math. Algorithms Appl. 2009, 1, 485–498. [Google Scholar] [CrossRef]
- Santos Coelho, R.; Moura, P.; Wakabayashi, Y. The k-hop connected dominating set problem: Hardness and polyhedra. Electron. Notes Discret. Math. 2015, 50, 59–64. [Google Scholar] [CrossRef]
- Nguyen, M.; Hà, M.; Nguyen, D.; Tran, T. Solving the k-dominating set problem on very large-scale networks. Comput. Soc. Netw. 2020, 7, 1–5. [Google Scholar] [CrossRef]
- Shang, W.; Wan, P.J.; Yao, F.; Hu, X. Algorithms for minimum -connected -tuple dominating set problem. Theor. Comput. Sci. 2007, 381, 241–247. [Google Scholar] [CrossRef] [Green Version]
- Sheng, H.; Du, D.; Sun, Y.; Sun, J.; Zhang, X. Approximation Algorithm for Stochastic Set Cover Problem. In Proceedings of the Algorithmic Aspects in Information and Management, 14th International Conference, AAIM 2020, Jinhua, China, 10–12 August 2020; pp. 37–48. [Google Scholar]
- Eisenbrand, F.; Grandoni, F.; Rothvoß, T.; Schaefer, G. Approximating connected facility location problems via random facility sampling and core detouring. In Proceedings of the Annual ACM-SIAM Symposium on Discrete Algorithms, San Francisco, CA, USA, 20–22 January 2008. [Google Scholar]
- Swamy, C.; Kumar, A. Primal–Dual Algorithms for Connected Facility Location Problems. Algorithmica 2004, 40, 245–269. [Google Scholar] [CrossRef] [Green Version]
- Bandyapadhyay, S.; Roy, A.B. Approximate Covering with Lower and Upper Bounds via LP Rounding. arXiv 2020, arXiv:abs/2007.11476. [Google Scholar]
- Bifet, A.; Gavald, R.; Holmes, G.; Pfahringer, B. Machine Learning for Data Streams: With Practical Examples in MOA; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Domingos, P.; Hulten, G. Mining High-Speed Data Streams. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; Association for Computing Machinery: New York, NY, USA, 2000; pp. 71–80. [Google Scholar] [CrossRef]
- Syverson, P.F.; Goldschlag, D.M.; Reed, M.G. Anonymous connections and onion routing. In Proceedings of the 1997 IEEE Symposium on Security and Privacy (Cat. No. 97CB36097), Oakland, CA, USA, 4–7 May 1997; pp. 44–54. [Google Scholar]
- Aslam, S.; Tošić, A.; Mrissa, M. Secure and Privacy-Aware Blockchain Design: Requirements, Challenges and Solutions. J. Cybersecur. Priv. 2021, 1, 164–194. [Google Scholar] [CrossRef]
- Bertino, E. RBAC models—Concepts and trends. Comput. Secur. 2003, 22, 511–514. [Google Scholar] [CrossRef]
- Radi, M.; Dezfouli, B.; Abu Bakar, K.; Lee, M. Multipath Routing in Wireless Sensor Networks: Survey and Research Challenges. Sensors 2012, 12, 650–685. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brodnik, A.; Grgurovič, M. Parallelization of Ant System for GPU under the PRAM Model. Comput. Inform. 2018, 37, 229–243. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining, Fourth Edition: Practical Machine Learning Tools and Techniques, 4th ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2016. [Google Scholar]
- Hulten, G.; Spencer, L.; Domingos, P. Mining time-changing data streams. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 97–106. [Google Scholar]
- Henderson, T.R.; Lacage, M.; Riley, G.F.; Dowell, C.; Kopena, J. Network simulations with the ns-3 simulator. SIGCOMM Demonstr. 2008, 14, 527. [Google Scholar]
- Hrovatin, N.; Tošić, A.; Vičič, J. PPWSim: Privacy Preserving Wireless Sensor Network Simulator. 2021. Available online: https://ssrn.com/abstract=3978796 (accessed on 20 December 2021).
- Clausen, T.; Jacquet, P.; Adjih, C.; Laouiti, A.; Minet, P.; Muhlethaler, P.; Qayyum, A.; Viennot, L. Optimized Link State Routing Protocol (OLSR); RFC3626; INRIA: Cedex, France, 2003. [Google Scholar]
- Miller, V.S. Use of elliptic curves in cryptography. In Conference on the Theory and Application of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 1985; pp. 417–426. [Google Scholar]
- Libsodium The Sodium Crypto Library. Available online: https://libsodium.gitbook.io/doc/ (accessed on 28 May 2021).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Cicalese, F.; Cordasco, G.; Gargano, L.; Milanič, M.; Peters, J.G.; Vaccaro, U. Spread of influence in weighted networks under time and budget constraints. Theor. Comput. Sci. 2015, 586, 40–58. [Google Scholar] [CrossRef]
- Hajdu, L.; Dávid, B.; Krész, M. Gateway placement and traffic load simulation in sensor networks. Pollack Period. 2021, 16, 102–108. [Google Scholar] [CrossRef]
- Hajdu, L.; Krész, M.; Bóta, A. Evaluating the role of community detection in improving influence maximization heuristics. Soc. Netw. Anal. Min. 2021, 11, 1–11. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Units | Value Range |
|---|---|---|
| T | °C | 0–30 |
| RH | % | 40–90 |
| CO2 | ppm | 400–1700 |
| P | hPa | 910–1015 |
| AL | lux | 0–50 |
| PM10 | g/m3 | 0–2000 |
| Run | Subsets Sequence |
|---|---|
| R1 | 1 → 2 → 3 → 4 → 5 → 6 → 7 → 8 → 9 → 10 |
| R2 | 1 → 3 → 4 → 5 → 6 → 7 → 8 → 9 → 2 → 10 |
| R3 | 1 → 4 → 5 → 6 → 7 → 8 → 9 → 2 → 3 → 10 |
| R4 | 1 → 5 → 6 → 7 → 8 → 9 → 2 → 3 → 4 → 10 |
| R5 | 1 → 6 → 7 → 8 → 9 → 2 → 3 → 4 → 5 → 10 |
| R6 | 1 → 7 → 8 → 9 → 2 → 3 → 4 → 5 → 6 → 10 |
| R7 | 1 → 8 → 9 → 2 → 3 → 4 → 5 → 6 → 7 → 10 |
| R8 | 1 → 9 → 2 → 3 → 4 → 5 → 6 → 7 → 8 → 10 |
| R9 | 1 → 6 → 3 → 5 → 4 → 7 → 2 → 9 → 8 → 10 |
| R10 | 1 → 8 → 4 → 9 → 5 → 6 → 7 → 3 → 2 → 10 |
| Run | Accuracy (%) | Size (# Leaves) |
|---|---|---|
| R1 | 65.34 | 285 |
| R2 | 63.12 | 291 |
| R3 | 66.01 | 280 |
| R4 | 67.88 | 279 |
| R5 | 64.32 | 285 |
| R6 | 63.76 | 290 |
| R7 | 64.91 | 281 |
| R8 | 65.50 | 292 |
| R9 | 67.46 | 291 |
| R10 | 66.72 | 285 |
| ALL | 64.15 | 291 |
| Avg. | 65.38 | 286.36 |
| Std. | 1.46 | 4.66 |
| Onion Body Size (Bytes) | Message Path Length (Number of Hops) | Onion Head Size (Bytes) | min ORTT (s) | avg ORTT (s) | max ORTT (s) | std ORTT (s) | # of Interrupted Onion Messages |
|---|---|---|---|---|---|---|---|
| 1 k | 5 | 267 | 0.07 | 2.66 | 12.32 | 3.33 | 3 |
| 20 | 1047 | 0.29 | 8.07 | 47.4 | 9.91 | 3 | |
| 60 | 3127 | 1.56 | 14.97 | 41.84 | 12.11 | 1 | |
| 2.5 k | 5 | 267 | 0.09 | 5.78 | 26.24 | 7.67 | 1 |
| 20 | 1047 | 0.46 | 6.76 | 21.52 | 5.83 | 6 | |
| 60 | 3127 | 1.64 | 12.93 | 36.19 | 9.87 | 7 | |
| 5 k | 5 | 267 | 0.14 | 4.22 | 24.21 | 7.03 | 2 |
| 20 | 1047 | 0.63 | 4.34 | 16.33 | 4.11 | 5 | |
| 60 | 3127 | 5.04 | 15.85 | 60.12 | 11.82 | 6 | |
| 10 k | 5 | 267 | 0.22 | 5.89 | 25.39 | 6.5 | 4 |
| 20 | 1047 | 0.93 | 12.84 | 58.81 | 13.28 | 3 | |
| 60 | 3127 | 9.22 | 20.87 | 78.34 | 13.44 | 2 | |
| 25 k | 5 | 267 | 0.37 | 4.26 | 23.75 | 4.96 | 2 |
| 20 | 1047 | 4.42 | 14.82 | 43.97 | 10.22 | 1 | |
| 60 | 3127 | 16.45 | 36.63 | 72.51 | 13.46 | 5 | |
| 50 k | 5 | 267 | 0.76 | 5.78 | 21.47 | 4.58 | 0 |
| 20 | 1047 | 6.29 | 18.29 | 46.13 | 11.11 | 4 | |
| 60 | 3127 | 30.06 | 54.44 | 98.2 | 17.2 | 5 | |
| 100 k | 5 | 267 | 1.32 | 11.13 | 30.42 | 6.94 | 1 |
| 20 | 1047 | 8.64 | 26.23 | 45.94 | 9.52 | 2 | |
| 60 | 3127 | 49.71 | 71.66 | 107.16 | 13.58 | 8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mrissa, M.; Tošić, A.; Hrovatin, N.; Aslam, S.; Dávid, B.; Hajdu, L.; Krész, M.; Brodnik, A.; Kavšek, B. Privacy-Aware and Secure Decentralized Air Quality Monitoring. Appl. Sci. 2022, 12, 2147. https://doi.org/10.3390/app12042147
Mrissa M, Tošić A, Hrovatin N, Aslam S, Dávid B, Hajdu L, Krész M, Brodnik A, Kavšek B. Privacy-Aware and Secure Decentralized Air Quality Monitoring. Applied Sciences. 2022; 12(4):2147. https://doi.org/10.3390/app12042147
Chicago/Turabian StyleMrissa, Michael, Aleksandar Tošić, Niki Hrovatin, Sidra Aslam, Balázs Dávid, László Hajdu, Miklós Krész, Andrej Brodnik, and Branko Kavšek. 2022. "Privacy-Aware and Secure Decentralized Air Quality Monitoring" Applied Sciences 12, no. 4: 2147. https://doi.org/10.3390/app12042147
APA StyleMrissa, M., Tošić, A., Hrovatin, N., Aslam, S., Dávid, B., Hajdu, L., Krész, M., Brodnik, A., & Kavšek, B. (2022). Privacy-Aware and Secure Decentralized Air Quality Monitoring. Applied Sciences, 12(4), 2147. https://doi.org/10.3390/app12042147