
The Impact of Personality and Demographic Variables in Collaborative Filtering of User Interest on Social Media

 , , , ,
, , , , 
Abstract
:1. Introduction
- Building a novel model that extracts the explicit and implicit user interests’ topics: dependence on user modelling based on multi-faceted demographic data, big five personality (has explanation in Appendix A) traits and interests topics. Demographic data include user age and gender, while big five personality traits include openness, conscientiousness, extraversion, agreeableness, neuroticism. On the other hand, the big five model is the most popular and B extensively used in the literature to determine personality trait.
- Alleviating the cold start problem on social media: finding similar users to new user; these users must be similar in age, gender and personality traits, as these factors greatly affect the interests of the users.
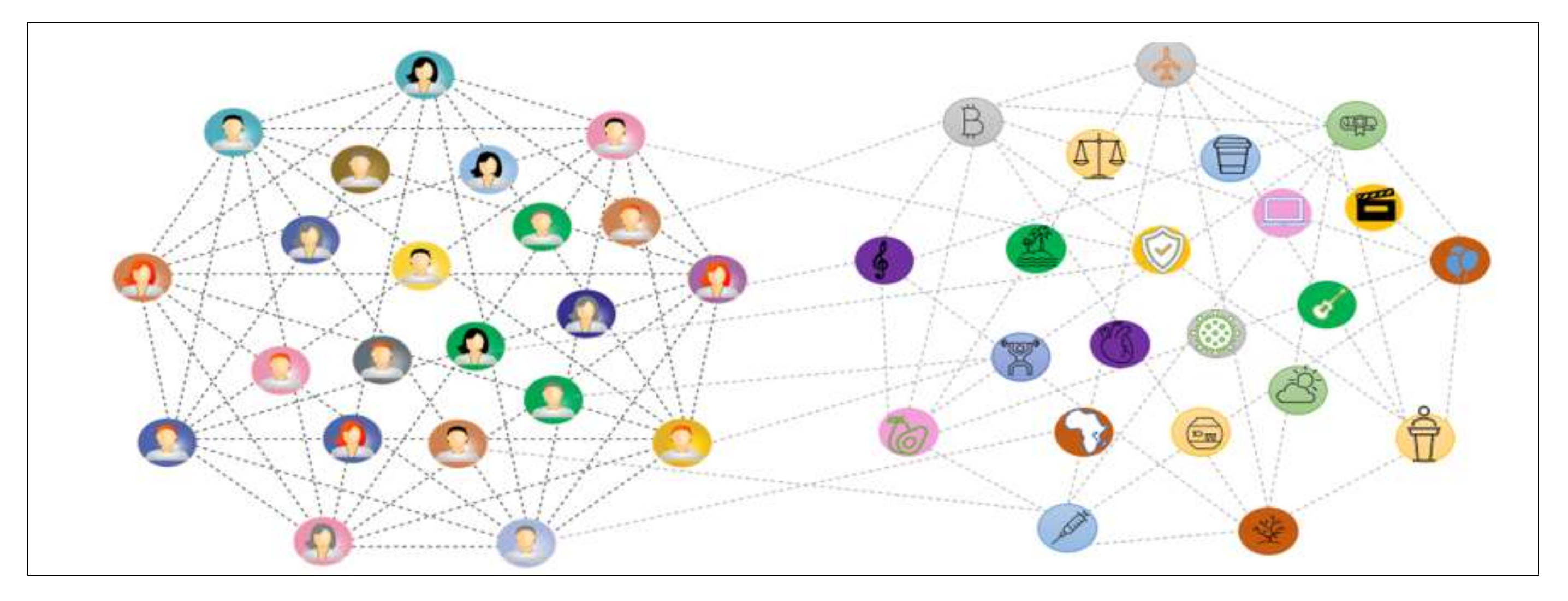
- Building a heterogeneous hybrid graph model that examines the patterns of interaction between users and topics, as well as finding implicit user interests based on topics clustering and semantic similarities between topics.
- Building introductory dataset including factors that have been studied in this research that influence and support explicit and implicit user interests mining.
2. Related Studies
3. Materials & Methods
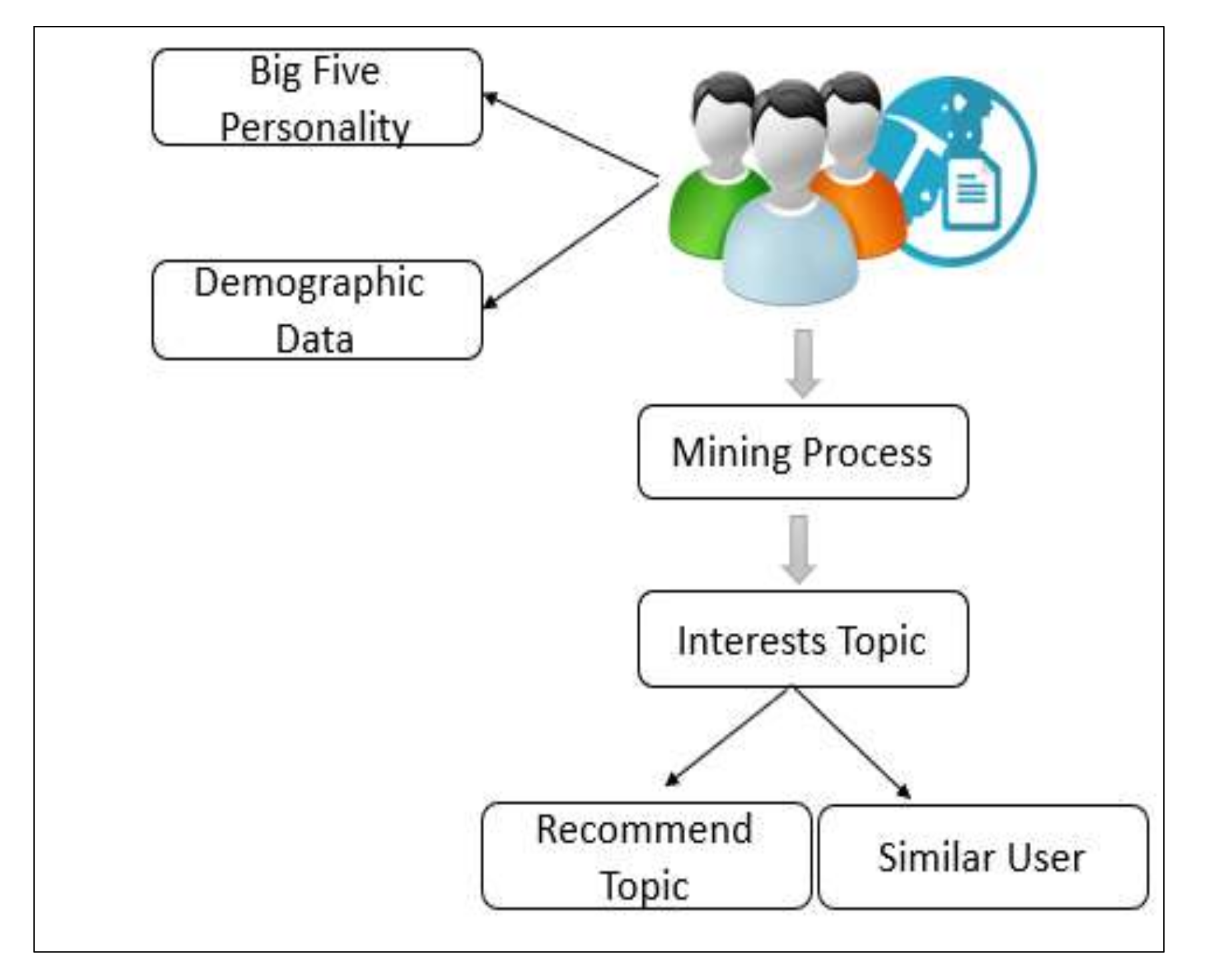
3.1. Model Architecture
3.2. User Modeling
| Algorithm 1 Get Similarity between Users | |
| 1: | Input: |
| 2: | |
| 3: | Output: Similarity between Users |
| 4: | |
| 5: | Compute Similarity of big five personality traits |
| 6: | |
| 7: | |
| 8: | |
| 9: | Compute similarity based on demographic data |
| 10: | |
| 11: | |
| 12: | |
| 13: | Interested topics extracted from each user |
| 14: | |
| 15: | Calculate similarity from topic vectors |
| 16: | |
| 17: | Set weight |
| 18: | |
| 19: | Get Users similarity |
| 20: | |
| 21: | End |
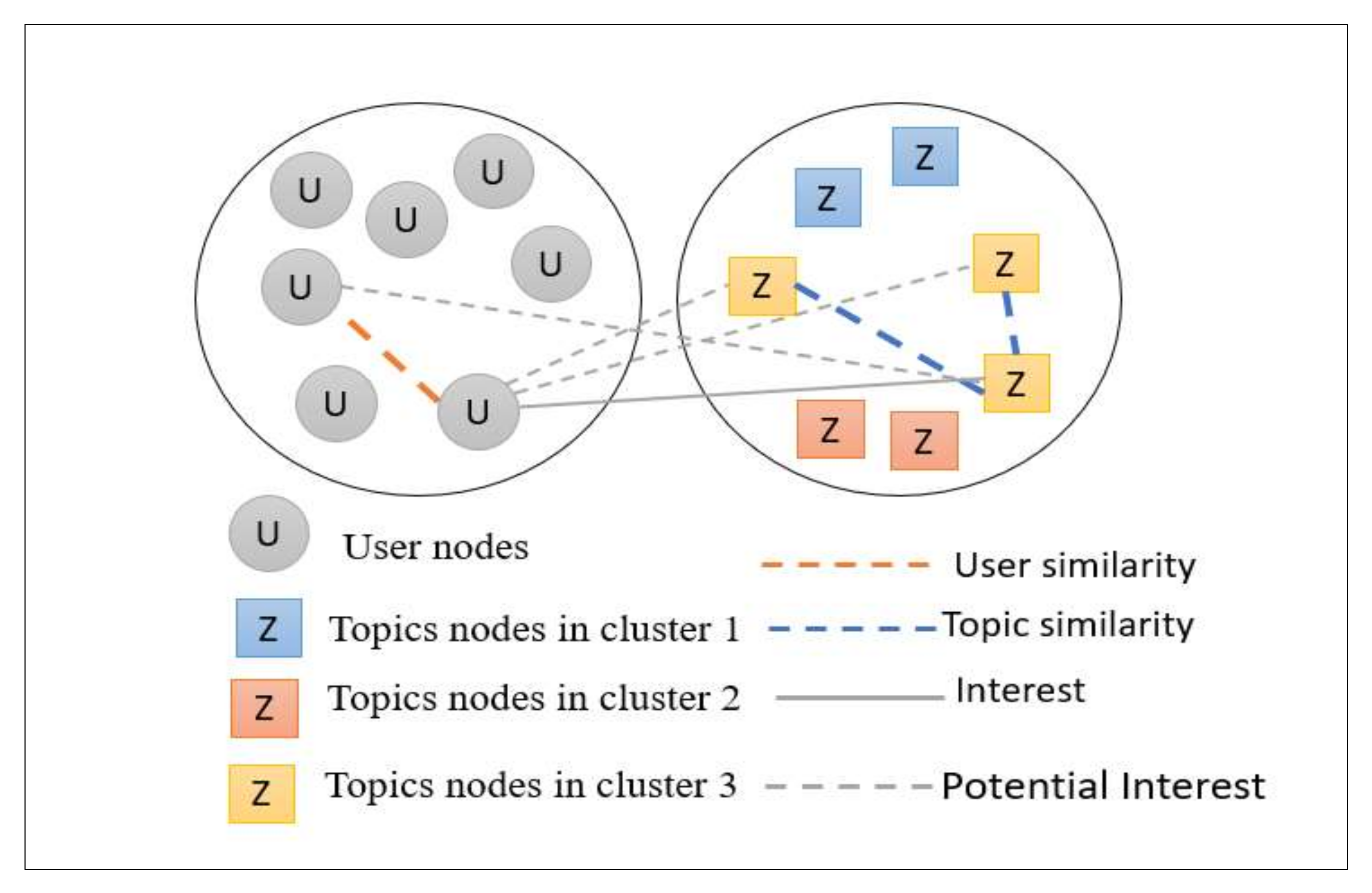
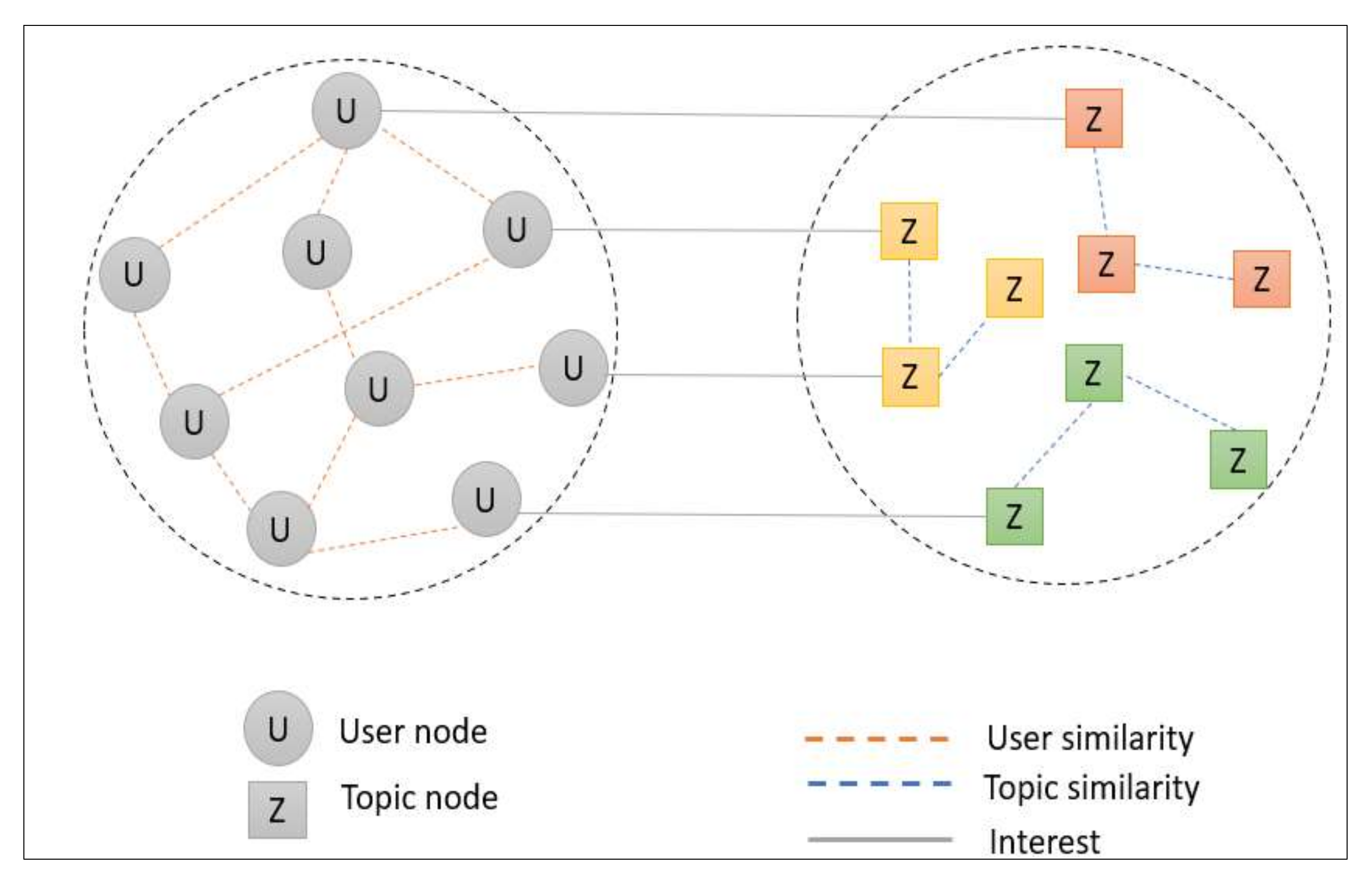
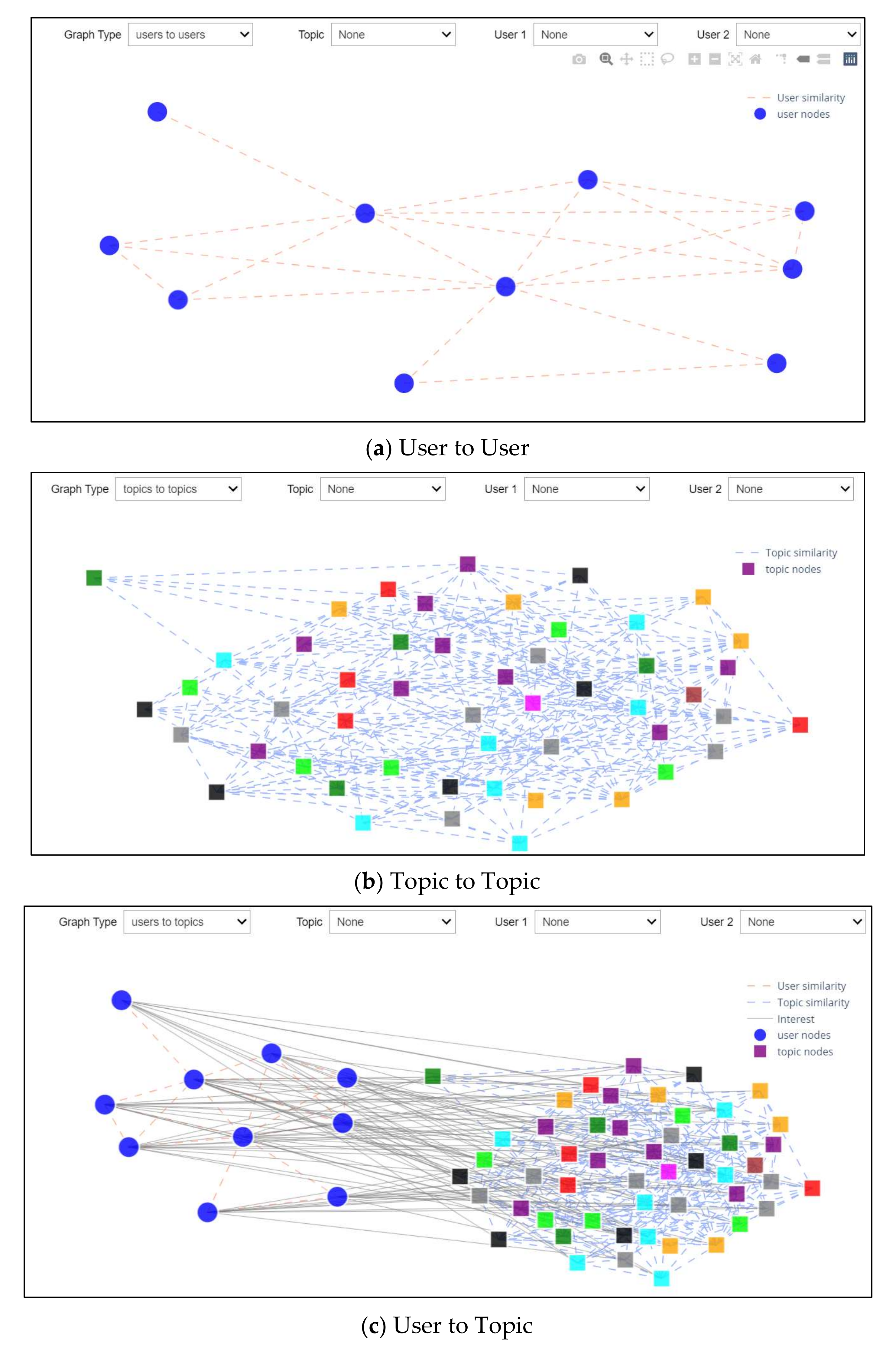
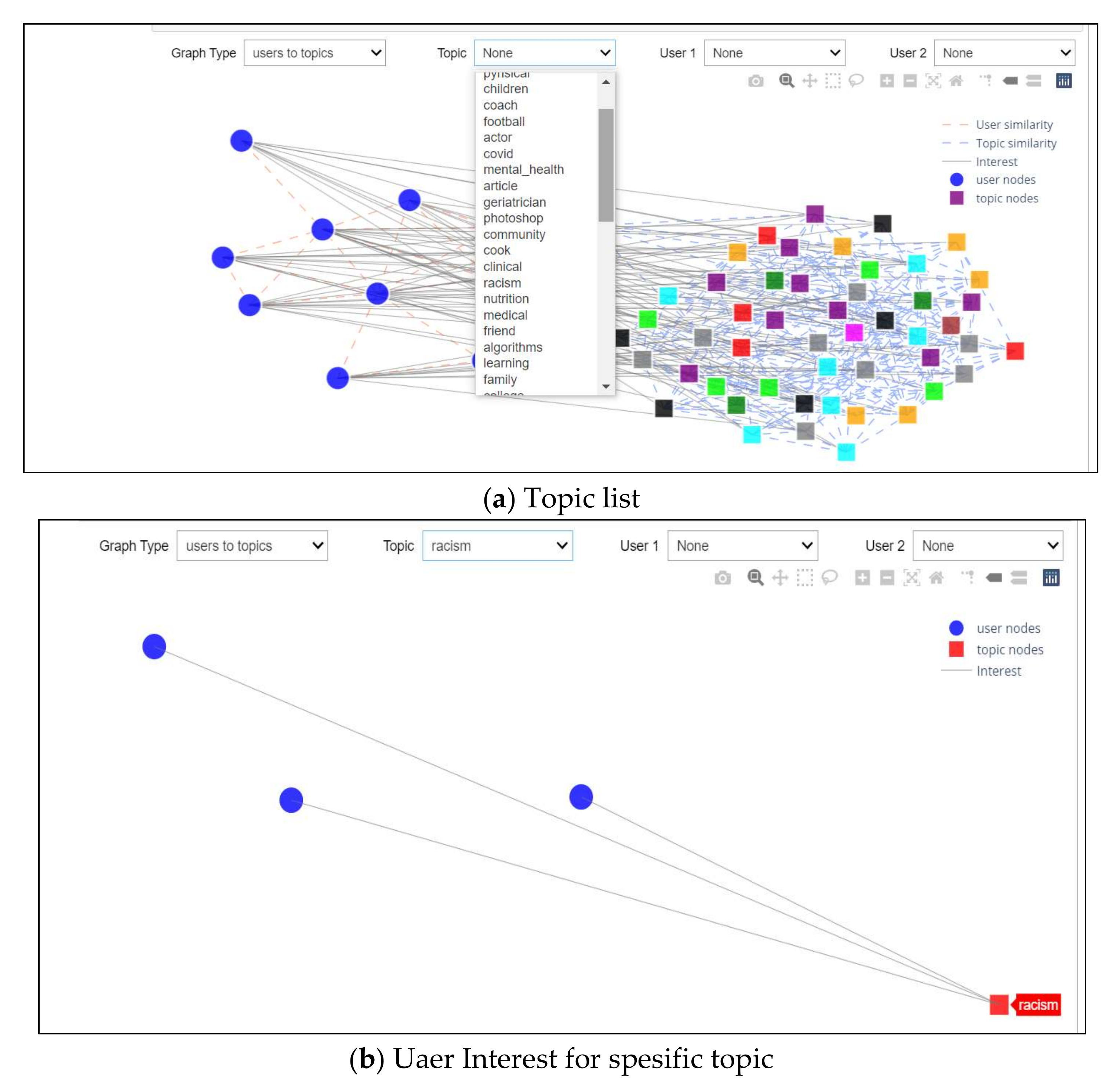
3.3. Graph Modeling
| Algorithm 2 Generate User Graph | |
| 1: | Input: |
| 2: | Output: |
| 3: | Begin |
| 4: | \\ Assign as new empty graph |
| 5: | |
| 6: | \\ Add user nodes |
| 7: | for do |
| 8: | Create node for user |
| 9: | Add node to graph |
| 10: | end for |
| 11: | \\ Add user edges |
| 12: | for do |
| 13: | |
| 14: | if then |
| 15: | Create edge between , |
| 16: | Add edge to graph |
| 17: | end if |
| 18: | end for |
| 19: | return |
| 20: | End |
| Algorithm 3 Generate Topic Graph | |
| 1: | Input: |
| 2: | Output: |
| 3: | Begin |
| 4: | Initialize semantic similarity matrix between topics |
| 5: | Initialize topic cluster assignment matrix |
| 6: | k-means clustering on Z to get a set of k cluster centers |
| 7: | for do |
| 8: | |
| 9: | where is score of ith cluster of topics |
| 10: | |
| 11: | Assign topic cluster as maximum cluster |
| 12: | |
| 13: | end for |
| 14: | \\ Assign as new entry graph |
| 15: | |
| 16: | \\ Add topic nodes |
| 17: | for do |
| 18: | Create node for topic |
| 19: | Assign node group to and set node color |
| 20: | Add node to graph |
| 21: | end for |
| 22: | \\ Add topic edges |
| 23: | for do |
| 24: | |
| 25: | if then |
| 26: | Create edge between , |
| 27: | Add edge to graph |
| 28: | end if |
| 29: | end for |
| 30: | return |
| 31: | End |
| Algorithm 4 Generate Heterogeneous Graphs with two types of nodes | |
| 1: | Input: |
| 2: | Output: |
| 3: | Begin |
| 4: | \\ Assign as heterogeneous graph between subgraphs |
| 5: | and |
| 6: | |
| 7: | \\ Add user topic edges |
| 8: | for do |
| 9: | |
| 10: | for each topic in do |
| 11: | Create edge between , and |
| 12: | Add edge to graph |
| 13: | end for |
| 14: | end for |
| 15: | return |
| 16: | End |
4. Experiment and Results
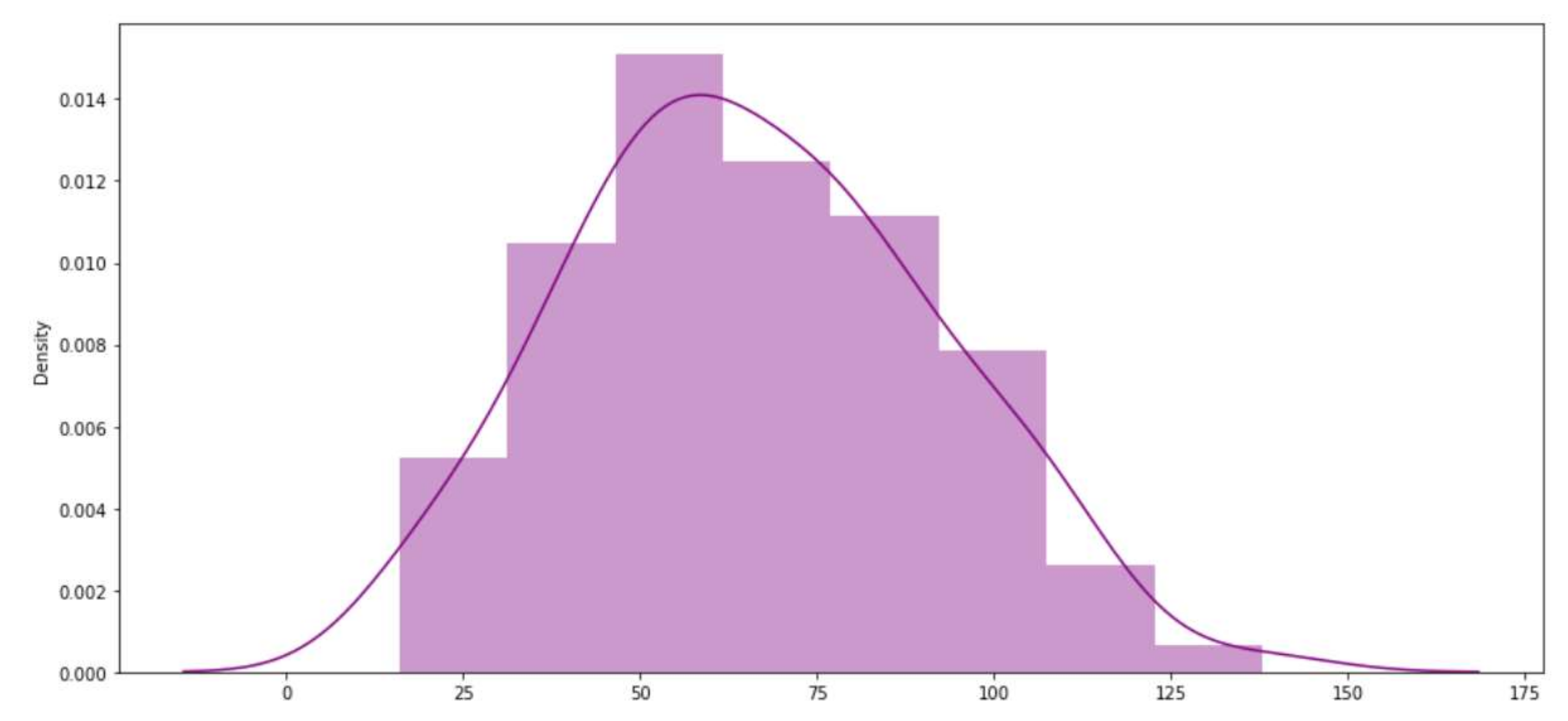
4.1. Dataset
4.2. Experiments Settings
4.3. Interest Topics Experiment
4.4. Proposed Similarity Measure Experiment
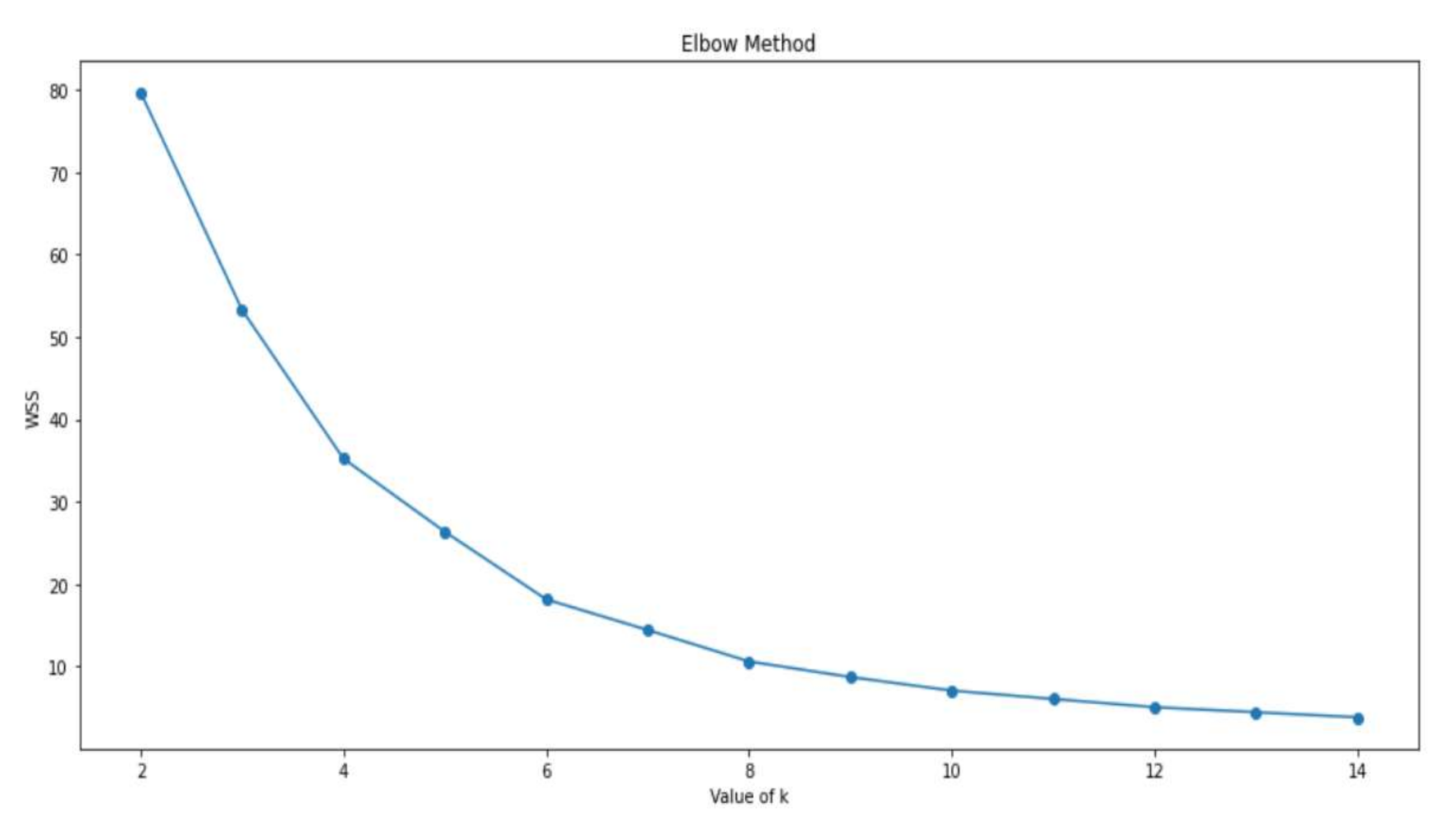
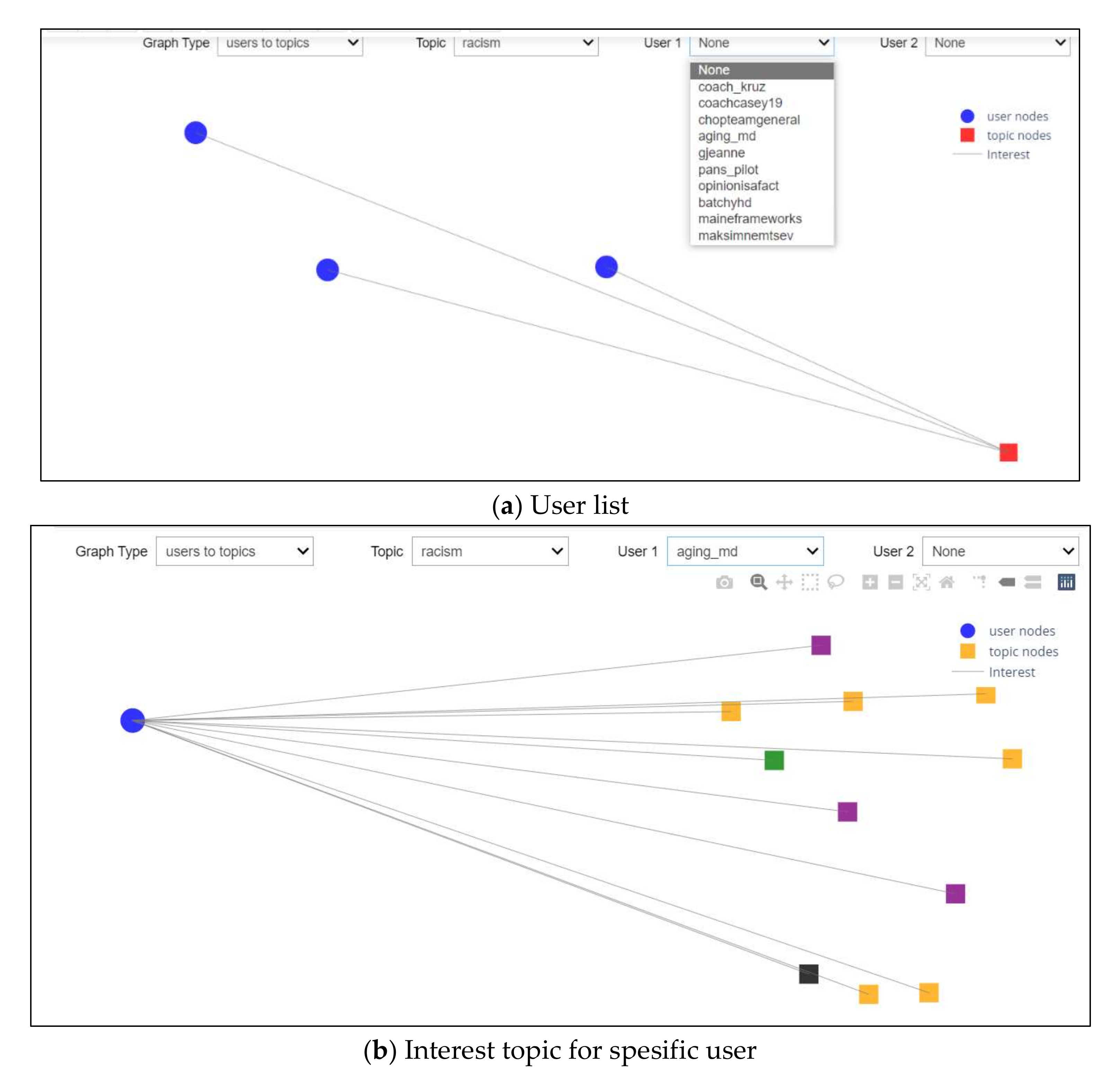
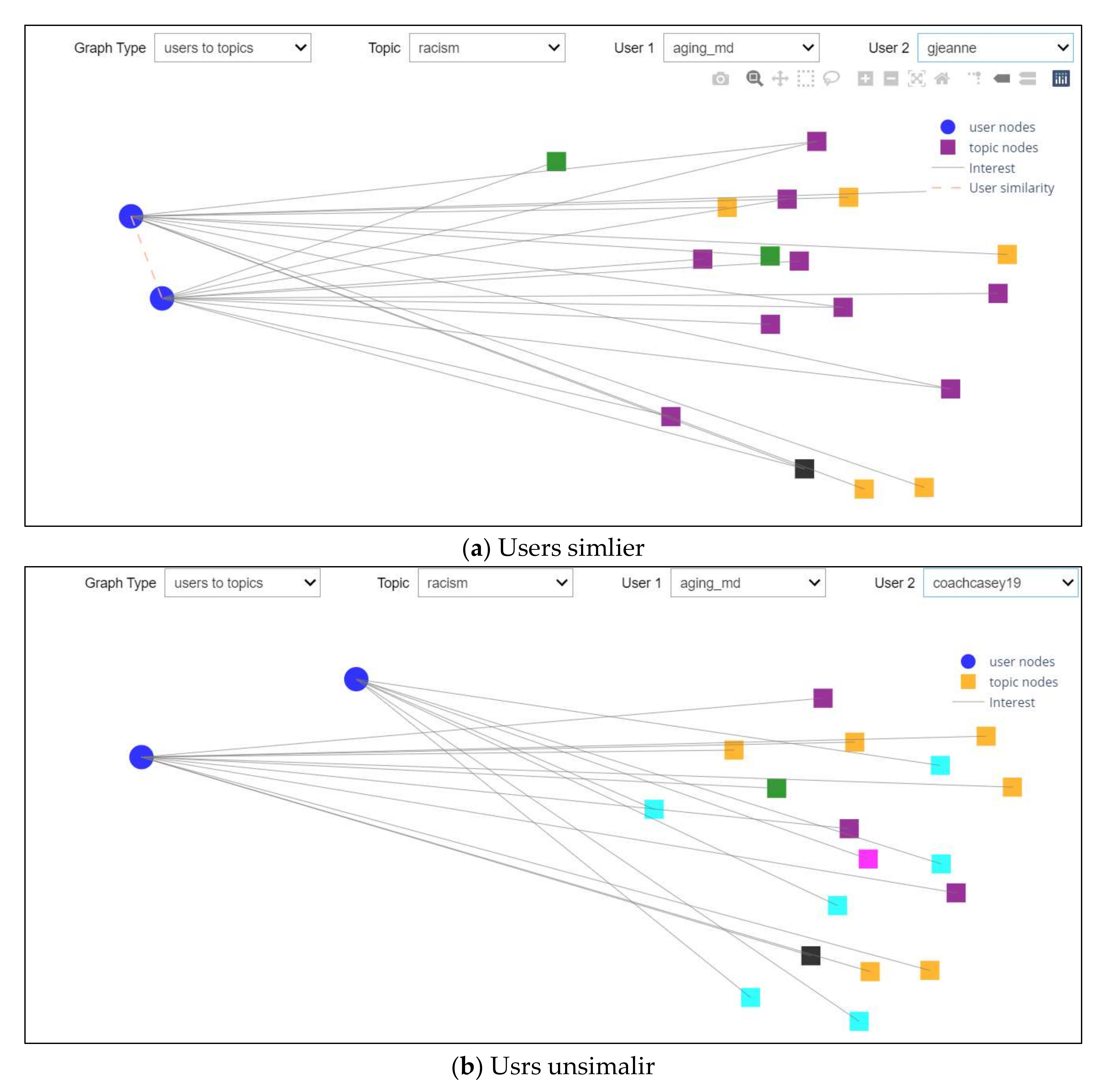
4.5. Graph-Based Experiment
5. Results
- Case 1: Similar Personality, Demographics Data and Interests
- Case 2: Similar Personality but Different in Demographics Data (Age), and Interests
- Case 3: Similar Personality and Different Demographics Data (Age and Gender) and Interests
- Case 4: Different Personality, Interests and Similar Demographics Data (Age and Gender)
6. Result Discussion
- Depending on the first case, if the personality and demographic data are similar, such as age and gender, then the likelihood of having the same interests and similarity rate is high and confident.
- Based on the second and third cases, if the personalities of users are similar and the demographic (age/gender) data differ, either one or both, then the state of confidence here is that their interests will often be different. It has also been observed that similarity in the demographic data mathematically gives a very high result, which is due to the encoding of gender to zero and one, and this makes it mathematically close to the first case; however, theoretically, and in reality, they are different. Hence, the interests were diverse for this reason; thus, a higher weight for interest topics was placed in the improved equation. Consequently, the similarity percentage decreased dramatically between the users, something which is in stark contrast to the initial example presented.
- The fourth case showed a difference between users’ personality traits, even though their demographic data were identical, and from which it could be seen that their interests differed. Thus, both demographic data and personality characteristics are intrinsic factors in determining users’ interests and neither can be overlooked.
- Including the location from the demographic data to rely upon in extracting the users’ implicit interests, as the users are affected by the community’s culture to which they belong. Often, the inhabitants of the same geographic region revolve around the same interests. Geographical data is currently excluded from this research because the majority of Twitter users did not disclose their data in general, or the location field mentions other information that is not related to reality.
- It was difficult to obtain Twitter data as there are many restrictions from Twitter as it gives few tweets that are collected daily.
7. Conclusions
- Enable the cross-system models, which study the user’s account in more than one social media platform. However, it leads to data integration challenges.
- Study users’ interests in social media based on time and link predication. That is, examining the change in user interests over the years, enabling future interests to be anticipated. For example, a study of Users A, B, and C interests from the first year they joined social networking sites, suppose the first year 2016, i.e., a study of interests in 2016–2021.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- Openness to Experience (a measure of Adventure seekers, Openness to new experience)
- Conscientiousness (a measure of the ability of any person to be organized)
- Extraversion (a measure of the tendency to seek stimulation in the external world)
- Agreeableness (a measure of tender tender-mindness)
- Neuroticism (a measure of the tendency for any user to be impulsive)
References
- Alhujaili, R.F.; Yafooz, W.M. Sentiment Analysis for YouTube Videos with User Comments. In Proceedings of the International Conference on Artificial Intelligence and Smart Systems (ICAIS), Pichanur, India, 25–27 March 2021. [Google Scholar]
- De Salve, A.; Guidi, B.; Ricci, L.; Mori, P. Discovering Homophily in Online Social Networks. Mob. Netw. Appl. 2018, 23, 1715–1726. [Google Scholar] [CrossRef]
- Clement, J. Number of Social Media Users 2025, Statista. 2020. Available online: https://www.statista.com/statistics/278414/number-of-worldwide-social-network-users/ (accessed on 23 January 2021).
- Feng, W.; Wang, J. Retweet or not? Personalized tweet re-ranking. In Proceedings of the 6th ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013. [Google Scholar]
- Konstan, J.A.; Conejo, R.; Marzo, J.L.; Oliver, N. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). In Proceedings of the 19th International Conference on User Modeling, Adaptation and Personalization, Girona, Spain, 11 July 2011. [Google Scholar]
- Kapanipathi, P.; Jain, P.; Venkataramani, C.; Sheth, A. User interests identification on Twitter using a hierarchical knowledge base. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). In Proceedings of the European Semantic Web Conference, Crete, Greece, 25–29 May 2014. [Google Scholar]
- Zarrinkalam, F.; Fani, H.; Bagheri, E.; Kahani, M.; Du, W. Semantics-enabled user interest detection from Twitter. In Proceedings of the 2015 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology, Singapore, 6–9 December 2015. [Google Scholar]
- Li, J.; Wang, Z.L.; Zhao, H.; Gravina, R.; Fortino, G.; Jiang, Y.; Tang, K. Networked human motion capture system based on quaternion navigation. In Proceedings of the BodyNets International Conference on Body Area Networks, Dalian, China, 28–29 September 2017. [Google Scholar]
- Piao, G.; Breslin, J.G. Inferring user interests for passive users on Twitter. In Proceedings of the HT ‘17: 28th ACM Conference on Hypertext and Social Media, Prague, Czech Republic, 4–7 July 2017. [Google Scholar]
- Shen, W.; Wang, J.; Luo, P.; Wang, M. Linking named entities in tweets with knowledge base via user interest modeling. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013. [Google Scholar]
- Zarrinkalam, F.; Fani, H.; Bagheri, E.; Kahani, M. Inferring implicit topical interests on twitter. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). In Proceedings of the European Conference on Information Retrieval, Padua, Italy, 20–23 March 2016. [Google Scholar]
- Piao, G.; Breslin, J.G. Transfer learning for item recommendations and knowledge graph completion in item related domains via a co-factorization model. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 3–7 June 2018. [Google Scholar]
- Zarrinkalam, F.; Fani, H.; Bagheri, E. Extracting, Mining and Predicting Users’ Interests from Social Networks. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019. [Google Scholar]
- Zarrinkalam, F.; Fani, H.; Bagheri, E. Social user interest mining: Methods and applications. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Kuanr, M.; Mohapatra, P. Recent Challenges in Recommender Systems: A Survey. In Progress in Advanced Computing and Intelligent Engineering; Kacprzyk, J., Ed.; Springer: Singapore, 2021; Volume 1199, pp. 353–365. [Google Scholar]
- Alrehili, M.M.; Yafooz, W.M. A Review of Extracting and Mining User Interest from Social Media Based on Personality. In Proceedings of the 3rd International Youth Conference on Radio Electronics, Electrical and Power Engineering (REEPE), Moscow, Russia, 11–13 March 2021. [Google Scholar]
- Kumar, M.R.; Venkatesh, J.; Rahman, A.M.J. Data mining and machine learning in retail business: Developing efficiencies for better customer retention. J. Ambient. Intell. Humaniz. Comput. 2021, 1–13. [Google Scholar] [CrossRef]
- Li, Y.; Guo, X.; Lin, W.; Zhong, M.; Li, Q.; Liu, Z.; Zhong, W.; Zhu, Z. Learning Dynamic User Interest Sequence in Knowledge Graphs for Click-Through Rate Prediction; IEEE Transactions on Knowledge and Data Engineering: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Kang, S.; Ji, L.; Zhang, J.; Kang, S.; Ji, L.; Zhang, J. Heterogeneous Information Network Representation Learning Framework Based on Graph Attention Network. J. Electron. Inf. Technol. 2021, 43, 915–922. [Google Scholar]
- Shi, C.; Ding, J.; Cao, X.; Hu, L.; Wu, B.; Li, X. Entity set expansion in knowledge graph: A heterogeneous information network perspective. Front. Comput. Sci. 2020, 15, 1–12. [Google Scholar] [CrossRef]
- Xie, T.; Xu, Y.; Chen, L.; Liu, Y.; Zheng, Z. Sequential Recommendation on Dynamic Heterogeneous Information Network. In Proceedings of the IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 22 June 2021. [Google Scholar]
- Chen, Y.C.; Hui, L.; Thaipisutikul, T. A collaborative filtering recommendation system with dynamic time decay. J. Supercomput. 2021, 77, 244–262. [Google Scholar] [CrossRef]
- Ma, B.; Lu, M.; Taniguchi, Y.; Konomi, S. Exploration and explanation: An interactive course recommendation system for university environments. In Proceedings of the IUI ‘21 Companion: 26th International Conference on Intelligent User Interfaces—Companion, College Station, TX, USA, 14–17 April 2021. [Google Scholar]
- Tahmasebi, F.; Meghdadi, M.; Ahmadian, S.; Valiallahi, K. A hybrid recommendation system based on profile expansion technique to alleviate cold start problem. Multimed. Tools Appl. 2020, 80, 2339–2354. [Google Scholar] [CrossRef]
- Roccas, S.; Sagiv, L.; Schwartz, S.H.; Knafo, A. The big five personality factors and personal values. Personal. Soc. Psychol. Bull. 2002, 28, 789–801. [Google Scholar] [CrossRef]
- Dhelim, S.; Aung, N.; Bouras, M.A.; Ning, H.; Cambria, E. A Survey on Personality-Aware Recommendation Systems. Artifcial Intelligence Review, Published Online, 19 September 2021. Available online: https://link.springer.com/content/pdf/10.1007/s10462-021-10063-7.pdf (accessed on 11 January 2021).
- Singh, B.K.; Katiyar, M.; Gupta, S.; Ganpatrao, N.G. A Survey on: Personality Prediction from Multimedia through Machine Learning. In Proceedings of the 5th International Conference on Computing Methodologies and Communication, Erode, India, 8–10 April 2021. [Google Scholar]
- Kang, J.; Lee, H. Modeling user interest in social media using news media and wikipedia. Inf. Syst. 2017, 65, 52–64. [Google Scholar] [CrossRef]
- Shi, C.; Hu, B.; Zhao, W.X.; Yu, P.S. Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 2019, 31, 357–370. [Google Scholar] [CrossRef] [Green Version]
- Herce-Zelaya, J.; Porcel, C.; Bernabé-Moreno, J.; Tejeda-Lorente, A.; Herrera-Viedma, E. New technique to alleviate the cold start problem in recommender systems using information from social media and random decision forests. Inf. Sci. 2020, 536, 156–170. [Google Scholar] [CrossRef]
- Yafooz, W.M.; Hizam, E.A.; Alromema, W.A. Arabic Sentiment Analysis on Chewing Khat Leaves using Machine Learning and Ensemble Methods. Eng. Technol. Appl. Sci. Res. 2021, 11, 6845–6848. [Google Scholar] [CrossRef]
- Ferwerda, B.; Schedl, M. Personality-based user modeling for music recommender systems. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 9853 LNCS; Springer: Cham, Switzerland, 2016; pp. 254–257. [Google Scholar] [CrossRef]
- Ferwerda, B.; Tkalcic, M.; Schedl, M. Personality traits and music genre preferences: How music taste varies over age groups. CEUR Workshop Proc. 2017, 1922, 16–20. [Google Scholar]
- Tkalčič, M.; Kunaver, M.; Tasič, J.; Košir, A. Personality Based User Similarity Measure for a Collaborative Recommender System. In Proceedings of the 5th Workshop on Emotion in Human-Computer Interaction-Real World Challenges, Cambridge, UK, 1 September 2009; Available online: http://publica.fraunhofer.de/documents/N-113443.html (accessed on 11 January 2021).
- Hemkiran, S.; Sudha Sadasivam, G. A review of similarity measures and link prediction models in social networks. Int. J. Comput. Digit. Syst. 2020, 9, 239–248. [Google Scholar] [CrossRef]
- Jiao, Y.; Zhang, J.; Xiong, Y.; Zhu, Y. Collective link prediction oriented network embedding with hierarchical graph attention. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 419–428. [Google Scholar] [CrossRef] [Green Version]
- Al-Shamri, M.Y.H. User profiling approaches for demographic recommender systems. Knowl.-Based Syst. 2016, 100, 175–187. [Google Scholar] [CrossRef]
- Hawashin, B.; Lafi, M.; Kanan, T.; Mansour, A. An efficient hybrid similarity measure based on user interests for recommender systems. Expert Syst. 2020, 37, e12471. [Google Scholar] [CrossRef]
- Asabere, N.Y.; Acakpovi, A.; Michael, M.B. Improving Socially-Aware Recommendation Accuracy through Personality. IEEE Trans. Affect. Comput. 2018, 9, 351–361. [Google Scholar] [CrossRef]
- Bahrani, P.; Minaei-Bidgoli, B.; Parvin, H.; Mirzarezaee, M.; Keshavarz, A.; Alinejad-Rokny, H. User and item profile expansion for dealing with cold start problem. J. Intell. Fuzzy Syst. 2020, 38, 4471–4483. [Google Scholar] [CrossRef]
- Dhelim, S.; Aung, N.; Ning, H. Mining user interest based on personality-aware hybrid filtering in social networks. Knowl. -Based Syst. 2020, 206, 106227. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet allocation (LDA) and topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef] [Green Version]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar] [CrossRef]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y. Based on user interest level of modeling scenarios and browse content. In Proceedings of the AIP Conference, Chongqing, China, 27–28 May 2017. [Google Scholar]
- Wang, X.; Ji, H.; Cui, P.; Yu, P.; Shi, C.; Wang, B.; Ye, Y. Heterogeneous graph attention network. In Proceedings of the Web Conference 2019—The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Yun, S.; Jeong, M.; Kim, R.; Kang, J.; Kim, H.J. Graph transformer networks. Adv. Neural Inf. Process. Syst. 2019, 32, 11983–11993. [Google Scholar]
- Cobb-Clark, D.A.; Schurer, S. The stability of big-five personality traits. Econ. Lett. 2012, 115, 11–15. [Google Scholar] [CrossRef] [Green Version]
- Larson, L.M.; Rottinghaus, P.J.; Borgen, F.H. Meta-analyses of Big Six Interests and Big Five Personality Factors. J. Vocat. Behav. 2002, 61, 217–239. [Google Scholar] [CrossRef]
- Golino, H.; Christensen, A.; Moulder, R.G.; Kim, S.; Boker, S. Modeling latent topics in social media using Dynamic Exploratory Graph Analysis: The case of the right-wing and left-wing trolls in the 2016 US elections. Psychometrika 2021, 1–32. [Google Scholar] [CrossRef] [PubMed]
- Khalil Ibrahim, R.; Jacksi, K.; Rafeeq Mohammed Zeebaree, S. Survey on Semantic Similarity Based on Document Clustering Performance Analysis of Different Clus-ter-based and None Cluster-based Web Servers in Normal and Under TCP SYN Flood DDoS Attack View pro-ject Parallel processing View project Survey on Semantic Si. Adv. Sci. Technol. Eng. Syst. J. 2019, 4, 115–122. [Google Scholar] [CrossRef]
- Dhillon, P.S.; Aral, S. Modeling Dynamic User Interests: A Neural Matrix Factorization Approach. Mark. Sci. 2021, 40, 1059–1080. [Google Scholar] [CrossRef]
- Najafabadi, M.K.; Mohamed, A.H.; Mahrin, M.N. A survey on data mining techniques in recommender systems. Soft Comput. 2019, 23, 627–654. [Google Scholar] [CrossRef]
- Connelly, L.M. Demographic data in research studies. MedSurg Nurs. 2013, 22, 269–271. [Google Scholar]
- Mauro, N.; Ardissono, L.; Filippo, H.Z. Multi-faceted Trust-based Collaborative Filtering. In Proceedings of the UMAP 19: 27th Conference on User Modeling, Adaptation and Personalization, Larnaca, Cyprus, 9–12 June 2019; pp. 216–224. [Google Scholar] [CrossRef] [Green Version]
- Lesly, A.; Gonzalez, C.; Alves Souza, S.N. Social network data to alleviate cold-start in recommender system: A systematic review. Inf. Process. Manag. 2018, 54, 529–544. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author(s) | Type | Heterogeneous Network | Personality | Demographic | User Content | Approaches | |
|---|---|---|---|---|---|---|---|
| Age | Gender | ||||||
| [29] | Recommender System | Yes | No | No | No | Rating | Multiple Similarity Models |
| [35] | Recommender System | Yes | No | No | No | Rating | Multiple Similarity Models |
| [36] | User Interest | Yes | Yes | No | No | Text Content | Meta Path |
| [30] | Recommender System | No | No | No | No | Rating | Random Forests and Classification Trees |
| [37] | Recommender System | No | No | Yes | Yes | Rating | Cascaded Profiling Approach |
| [38] | Recommender System | No | No | No | No | Rating | Hybrid Similarity Measure |
| [32] | Recommender System | No | Yes | No | No | Text Content | Recommender Approach |
| [33] | Recommender System | No | Yes | Yes | No | Music Listening Histories | Recommender Approach |
| [34] | Recommender System | No | Yes | No | No | Ratings | Similarity Based Collaborative Filtering |
| Symbol | Meaning |
|---|---|
| u | User u |
| v | User v |
| Average value of the personality traits vector for user u |
| Attribute | Attribute Description |
|---|---|
| Username | The account name for user in Twitter |
| User Id | Unique id for each user |
| Age | The user age |
| Gender | The user gender |
| Extraversion | Scores measure the proclivity for positive feelings and a positive behavior toward themselves and the community surrounding. |
| Openness | Scores measure the degree to which an individual is special, has a diverse range of interests, and is able to take chances. |
| Agreeableness | Scores measure the proclivity to get solitary with everyone. |
| Neuroticism | Scores measure the proclivity for negative feelings and a pessimistic perception of themselves and the surrounding community. |
| Conscientiousness | Scores measure the degree to which an individual is cautious, meticulous, and persistent. |
| Tweet | The individual tweet for specific user. |
| Parameter | Value |
|---|---|
| Youngest user | 13 |
| Oldest user | 70 |
| The number of users in the age group (≥18) | 7 |
| The number of users in the age group (19–29) | 40 |
| The number of users in the age group (30–40) | 39 |
| The number of users in the age group (≤41) | 14 |
| Parameter | Value |
|---|---|
| Twitter dataset users | 100 |
| Passive users | 24 |
| Active users | 73 |
| Male users | 50 |
| Female users | 50 |
| Number of tweets | 86,256 |
| Users | User 1 | User 2 | User 3 | User 4 | User 5 | User 6 |
|---|---|---|---|---|---|---|
| User 1 | 1.000000 | 0.989397 | 0.98959 | 0.798963 | 0.995085 | 0.368327 |
| User 2 | 0.989397 | 1.000000 | 0.989676 | 0.801039 | 0.976672 | 0.349782 |
| User 3 | 0.98959 | 0.989676 | 1.000000 | 0.861633 | 0.970762 | 0.451998 |
| User 4 | 0.798963 | 0.801039 | 0.861633 | 1.000000 | 0.753588 | 0.834950 |
| User 5 | 0.995085 | 0.976672 | 0.970762 | 0.753588 | 1.000000 | 0.320103 |
| User 6 | 0.368327 | 0.349782 | 0.451998 | 0.83495 | 0.320103 | 1.000000 |
| Max (for 100 users) | 1.00000 | |||||
| Min (for 100 users) | −0.27906 | |||||
| Mean(for 100 users) | 0.823224 | |||||
| IQR | 0.016541 | |||||
| Users | User 1 | User 2 | User 3 | User 4 | User 5 | User 6 |
|---|---|---|---|---|---|---|
| User 1 | 1.000000 | 0.999999 | 0.999133 | 0.999133 | 0.999133 | 0.999383 |
| User 2 | 0.999999 | 1.000000 | 0.999201 | 0.999201 | 0.999201 | 0.999323 |
| User 3 | 0.999133 | 0.999201 | 1.000000 | 1.000000 | 1.000000 | 0.997054 |
| User 4 | 0.999133 | 0.999201 | 1.000000 | 1.000000 | 1.000000 | 0.997054 |
| User 5 | 0.999133 | 0.999201 | 1.000000 | 1.000000 | 1.000000 | 0.997054 |
| User 6 | 0.999383 | 0.999323 | 0.997054 | 0.997054 | 0.997054 | 1.000000 |
| Max (for 100 users) | 1.000000 | |||||
| Min (for 100 users) | 0.997906 | |||||
| Mean(for 100 users) | 0.999568 | |||||
| IQR | 0.000594 | |||||
| Users | User 1 | User 2 | User 3 | User 4 | User 5 | User 6 |
|---|---|---|---|---|---|---|
| User 1 | 1.000000 | 0.857143 | 0.169031 | 0.104828 | 0.000000 | 0.000000 |
| User 2 | 0.857143 | 1.000000 | 0.169031 | 0.000000 | 0.000000 | 0.000000 |
| User 3 | 0.169031 | 0.169031 | 1.000000 | 0.248069 | 0.129099 | 0.200000 |
| User 4 | 0.000000 | 0.000000 | 0.248069 | 1.000000 | 0.240192 | 0.000000 |
| User 5 | 0.000000 | 0.000000 | 0.129099 | 0.240192 | 1.000000 | 0.000000 |
| User 6 | 0.000000 | 0.000000 | 0.200000 | 0.000000 | 0.000000 | 1.000000 |
| Max (for 100 users) | 1.000000 | |||||
| Min (for 100 users) | 0.000000 | |||||
| Mean(for 100 users) | 0.129431 | |||||
| IQR | 0.176777 | |||||
| Users | User 1 | User 2 | User 3 | User 4 | User 5 | User 6 |
|---|---|---|---|---|---|---|
| User 1 | 1.000000 | 92.591937 | 58.104612 | 50.128816 | 49.790427 | 34.146484 |
| User 2 | 92.591937 | 1.000000 | 58.113528 | 44.946074 | 49.336891 | 92.591937 |
| User 3 | 58.104612 | 58.113528 | 1.000000 | 58.944294 | 55.724032 | 46.005403 |
| User 4 | 50.128816 | 44.946074 | 58.944294 | 1.000000 | 55.849316 | 45.579209 |
| User 5 | 49.790427 | 49.336891 | 55.724032 | 55.849316 | 1.000000 | 32.708021 |
| User 6 | 34.146484 | 33.676882 | 46.005403 | 45.579209 | 32.708021 | 1.000000 |
| Max (for 100 users) | 1.000000 | |||||
| Min (for 100 users) | 20.94735 | |||||
| Mean(for 100 users) | 51.93254 | |||||
| IQR | 9.055079 | |||||
| Measure | Mathematical Formula |
|---|---|
| Precision | |
| Recall | |
| F-measure | |
| Sensitivity | |
| Specificity | |
| Accuracy | |
| Match score |
| Precision | Recall | F1-Score | Accuracy | Match Score | Hamming Loss |
|---|---|---|---|---|---|
| 0.905063 | 0.93832 | 0.921392 | 0.854241 | 0.925065 | 0.103164 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alrehili, M.M.; Yafooz, W.M.S.; Alsaeedi, A.; Emara, A.-H.M.; Saad, A.; Al Aqrabi, H. The Impact of Personality and Demographic Variables in Collaborative Filtering of User Interest on Social Media. Appl. Sci. 2022, 12, 2157. https://doi.org/10.3390/app12042157
Alrehili MM, Yafooz WMS, Alsaeedi A, Emara A-HM, Saad A, Al Aqrabi H. The Impact of Personality and Demographic Variables in Collaborative Filtering of User Interest on Social Media. Applied Sciences. 2022; 12(4):2157. https://doi.org/10.3390/app12042157
Chicago/Turabian StyleAlrehili, Marwa M., Wael M. S. Yafooz, Abdullah Alsaeedi, Abdel-Hamid M. Emara, Aldosary Saad, and Hussain Al Aqrabi. 2022. "The Impact of Personality and Demographic Variables in Collaborative Filtering of User Interest on Social Media" Applied Sciences 12, no. 4: 2157. https://doi.org/10.3390/app12042157
APA StyleAlrehili, M. M., Yafooz, W. M. S., Alsaeedi, A., Emara, A. -H. M., Saad, A., & Al Aqrabi, H. (2022). The Impact of Personality and Demographic Variables in Collaborative Filtering of User Interest on Social Media. Applied Sciences, 12(4), 2157. https://doi.org/10.3390/app12042157