
Bootstrap–CURE: A Novel Clustering Approach for Sensor Data—An Application to 3D Printing Industry



Abstract
:1. Introduction
2. 3D Printing Process
- Fused deposition modeling: Machine lets the plastic filament melt and extrude through nozzles onto the bed platform, where it is cooled and solidified.
- Binder jetting: Machine distributes a layer of powder onto a build platform, and a bonding agent helps to fuse the parts. The process keeps repeating until the parts are built up in the powder bed.
- Laser sintering: Uses a laser as a power source to aim at points in 3D space to sinter the powder material and create a solid part.
- Laser melting: Machine uses laser(s) to melt metal powder.
- Stereo-lithography: Machine builds parts out of liquid photopolymer through polymerization activated by a UV laser.
3. State-of-the-Art
3.1. Data Science Applications in Sensor Analysis
- Anomaly detection;
- Automatic reporting and visualization;
- Pattern analysis;
- Process control;
- Predictive maintenance.
3.1.1. Anomaly Detection
3.1.2. Automatic Reporting and Visualization
3.1.3. Pattern Analysis
3.1.4. Process Control
- The need to obtain supervised data every time a model has to be trained is unrealistic in real Industry 4.0 manufacturing.
- In a customer environment with a fleet of 3D printers installed, obtaining global knowledge of the machines’ health from the manufacturer’s perspective would require analyzing data anonymously, as any confidential data (involving 3D print design or the print images) other than the sensor records cannot be shared or stored outside the customer site.
- Additionally, some of these works assume the possibility of installing additional cameras into the 3D printers; however, in an industrial setting, this is not always possible, as only customers have the sole decision-making authority to make any changes.
3.1.5. Predictive Maintenance
3.2. Clustering Strategies
3.2.1. Hierarchical Clustering and Automatic Identification of the Number of Clusters
3.2.2. Clustering Using Representation (CURE)
3.2.3. Detection of the Number of Clusters
4. Contributions
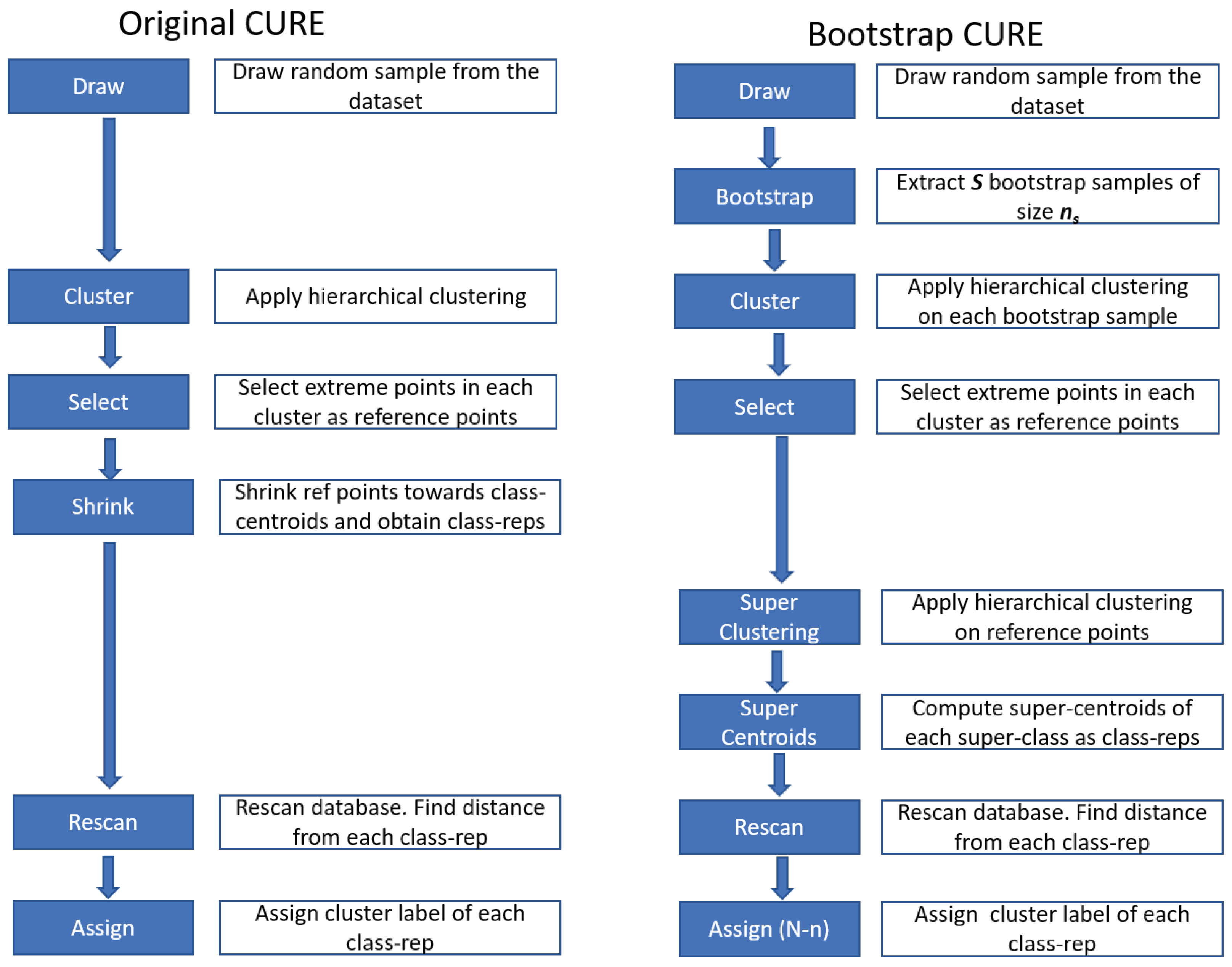
- A modification of the CURE approach consists of substituting the first phase of the original CURE approach by a bootstrap process that generates several small samples (S samples) from the original dataset and runs some clustering and super-classification processes to create the centroids that constitute the input of the second step of the CURE strategy. This contribution permits to scale up a hierarchical clustering process to large datasets and also reduces the CPU time drastically. Section 5.1.1 provides the details on it.
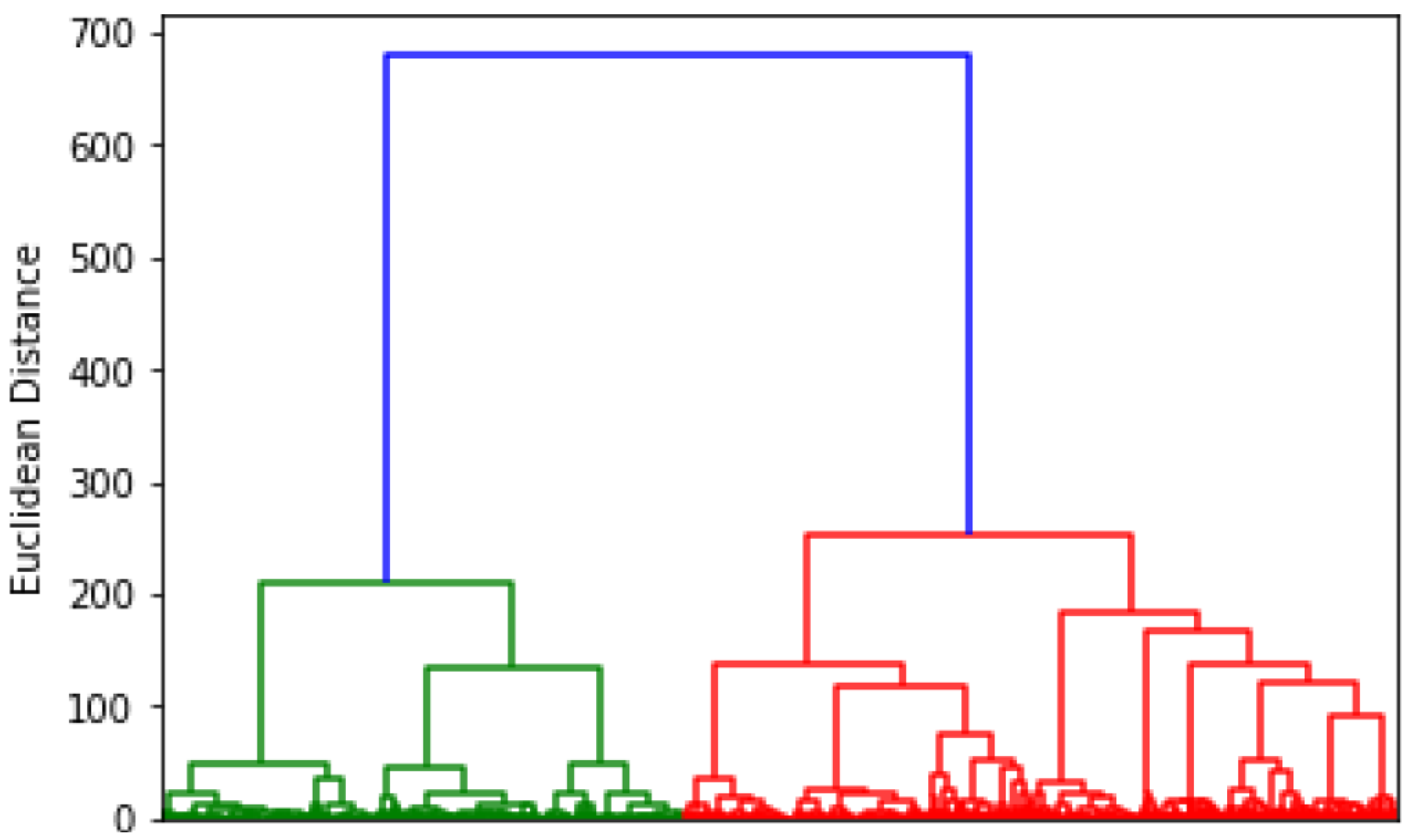
- As a consequence of using the bootstrap–CURE strategy in real large dataset applications, a new challenge appears of developing an automatic criterion to cut the resulting dendrograms () in order to identify the number of clusters in such a way that the number of clusters manually proposed by an expert is properly approached (see Section 5.2).
- A third contribution is the proposal of an entire data science process that inserts bootstrap–CURE with the automatic criterion to cut the dendrograms in a process, including the steps from the preprocessing to the interpretation-oriented tools. This automatically interprets the clusters emerging from this process, in line with the works in [89,90] and with the emerging field of explainable AI [91]. The proposal is described in Section 5.
5. Methodology
5.1. Preprocessing
5.1.1. The Proposed Bootstrap–CURE Approach
- Draw S random samples of a single reference dataset I, each of same size , without replacement.
- Subject each sample to hierarchical clustering (in this work with Euclidean distance and Ward’s method), and obtain the S dendrograms.
- Cut the S sample dendrograms and retrieve a set of clusters for each sample. In Section 5.2, a method to automatically determine the number of clusters in each dendrogram is proposed.
- Compute the centroid of all clusters found in the previous step and build a final dataset with all centroids.
- Super-classification step: Apply hierarchical clustering on the centroids dataset.
- Cut the resulting dendrogram by using the automatic criterion proposed in Section 5.2 and find the set of centroids belonging to each super-class.
- Compute the super-centroids of each super-class.
- Retrieve the list of original points belonging to each super-class by finding the centroids belonging to the super-class and the original elements used for each centroid.
- Assign the label of the corresponding super-class to all elements included in the S samples used.
- For all the elements that were not part of the S samples, compute the distances to each of the super-centroids.
- Assign each element the class of the nearest super-centroid.
5.2. Determining the Number of Clusters: Calinski–Harabasz Index
5.3. Post-Processing: Toward Explaining the Clusters
5.4. Validation of the Proposal
6. Applications to 3D Printer Data
6.1. Data Collection
6.2. Data Preprocessing
6.3. Hierarchical Clustering
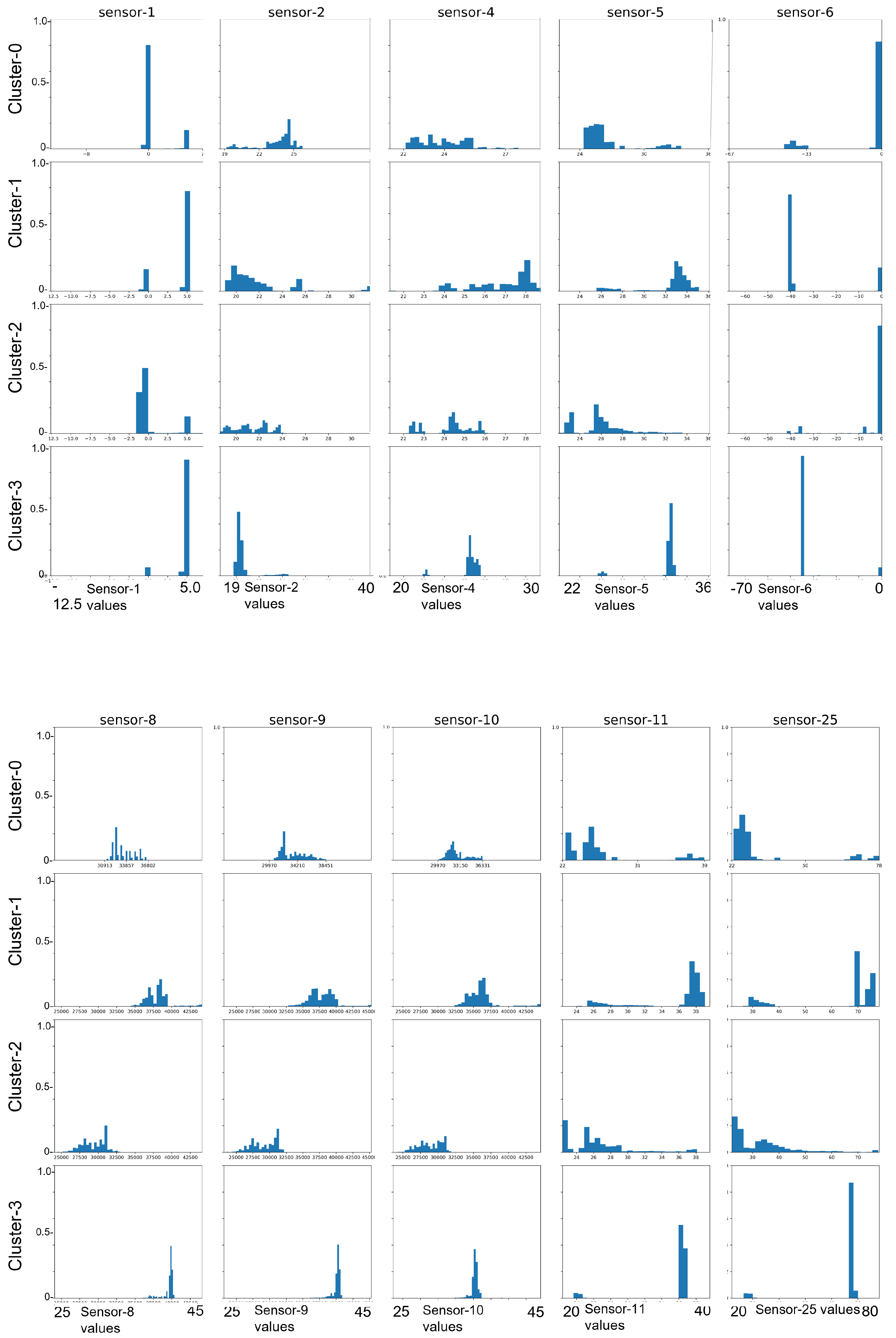
- Cluster 0: Specific sensors not meeting the required conditions to print without error.
- Cluster 1: Shows many sensors reaching the acceptable threshold (to initiate printing).
- Cluster 2: Conditions associated with print job to fail.
- Cluster 3: Imbalance in the internal cooling which would result in system error.
6.4. CURE and Bootstrap–CURE
6.5. Comparison of Original CURE against Bootstrap–CURE
6.6. Post-Processing in Bootstrap–CURE Method
- Cluster 0 (non-conformable jobs):
- Cluster 1 (successful jobs):
- Cluster 2 (failed jobs due to malfunction of components):
- Cluster 3 (failed jobs due to imbalance of sensors):
7. Discussion
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CVI | Cluster validity indices |
| Optimal number of clusters using criterion f | |
| Height of ith node in dendrogram | |
| Height of the root node in dendrogram | |
| CPG | Class panel graph |
| Calinksi–Harabasz index | |
| Total CPU time in seconds | |
| Proposed CVI based on dendrogram height |
References
- Rüßmann, M.; Lorenz, M.; Gerbert, P.; Waldner, M.; Justus, J.; Engel, P.; Harnisch, M. Industry 4.0: The future of productivity and growth in manufacturing industries. Boston Consult. Group 2015, 9, 54–89. [Google Scholar]
- Sureshkumar, P.; Rajesh, R. The Analysis of Different Types of IoT Sensors and security trend as Quantum chip for Smart City Management. IOSR J. Bus. Manag. (IOSR-JBM) 2018, 20, 55–60. [Google Scholar]
- Kang, H.S.; Lee, J.Y.; Choi, S.; Kim, H.; Park, J.H.; Son, J.Y.; Kim, B.H.; Do Noh, S. Smart manufacturing: Past research, present findings, and future directions. Int. J. Precis. Eng. Manuf.-Green Technol. 2016, 3, 111–128. [Google Scholar] [CrossRef]
- Gibert, K.; Rodríguez-Silva, G.; Rodríguez-Roda, I. Knowledge discovery with clustering based on rules by states: A water treatment application. Environ. Model. Softw. 2010, 25, 712–723. [Google Scholar] [CrossRef]
- Gibert, K.; Nonell, R. Impact of mixed metrics on clustering. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2003; pp. 464–471. [Google Scholar]
- Marti-Puig, P.; Blanco-M, A.; Cárdenas, J.J.; Cusidó, J.; Solé-Casals, J. Effects of the pre-processing algorithms in fault diagnosis of wind turbines. Environ. Model. Softw. 2018, 110, 119–128. [Google Scholar] [CrossRef]
- Wong, V.K.; Hernandez, A. A Review of Additive Manufacturing. ISRN Mech. Eng. 2012, 2012, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Nale, S.B.; Kalbande, A.G. A Review on 3D Printing Technology. Int. J. Innov. Emerg. Res. Eng. 2015, 2, 2394–5494. [Google Scholar]
- Karna, A.; Gibert, K. Using Hierarchical Clustering to Understand Behavior of 3D Printer Sensors. Adv. Intell. Syst. Comput. 2020, 976, 150–159. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based encoder-decoder for multi-sensor anomaly detection. arXiv 2016, arXiv:1607.00148. [Google Scholar]
- van Wyk, F.; Wang, Y.; Khojandi, A.; Masoud, N. Real-Time Sensor Anomaly Detection and Identification in Automated Vehicles. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1264–1276. [Google Scholar] [CrossRef]
- Sakurada, M.; Yairi, T. Anomaly detection using autoencoders with nonlinear dimensionality reduction. In Proceedings of the MLSDA 2014 2nd Workshop on Machine Learning for Sensory Data Analysis, Gold Coast, QLD, Australia, 2 December 2014; pp. 4–11. [Google Scholar]
- Parllaku, F.; Zaman, A.; Shah, F.; Karna, A.; de Pena, S. Using computational intelligence for smart device operation monitoring. In Proceedings of the 2019 International Conference on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, United Arab Emirates, 11–12 December 2019; pp. 124–129. [Google Scholar]
- Karna, A.; Shah, F. Machine Learning Based Approach to Process Characterization for Smart Devices in 3D Industrial Manufacturing. In Proceedings of the 2020 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Istanbul, Turkey, 12–13 June 2020; pp. 1–6. [Google Scholar]
- Ouyang, Z.; Niu, J.; Guizani, M. Improved vehicle steering pattern recognition by using selected sensor data. IEEE Trans. Mob. Comput. 2017, 17, 1383–1396. [Google Scholar] [CrossRef]
- Erfani, S.M.; Rajasegarar, S.; Karunasekera, S.; Leckie, C. High-dimensional and large-scale anomaly detection using a linear one-class SVM with deep learning. Pattern Recognit. 2016, 58, 121–134. [Google Scholar] [CrossRef]
- Emadi, H.S.; Mazinani, S.M. A novel anomaly detection algorithm using DBSCAN and SVM in wireless sensor networks. Wirel. Pers. Commun. 2018, 98, 2025–2035. [Google Scholar] [CrossRef]
- Liu, L.; Guo, Q.; Liu, D.; Peng, Y. Data-driven remaining useful life prediction considering sensor anomaly detection and data recovery. IEEE Access 2019, 7, 58336–58345. [Google Scholar] [CrossRef]
- Wulsin, D.; Blanco, J.; Mani, R.; Litt, B. Semi-Supervised Anomaly Detection for EEG Waveforms Using Deep Belief Nets. In Proceedings of the 2010 Ninth International Conference on Machine Learning and Applications, Washington, DC, USA, 12–14 December 2010; pp. 436–441. [Google Scholar] [CrossRef]
- Salem, O.; Naseem, A.; Mehaoua, A. Epileptic seizure detection from EEG signal using Discrete Wavelet Transform and Ant Colony classifier. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, Australia, 10–14 June 2014; pp. 3529–3534. [Google Scholar] [CrossRef]
- Wibisono, A.; Jatmiko, W.; Wisesa, H.A.; Hardjono, B.; Mursanto, P. Traffic big data prediction and visualization using fast incremental model trees-drift detection (FIMT-DD). Knowl.-Based Syst. 2016, 93, 33–46. [Google Scholar] [CrossRef]
- Riveiro, M.; Falkman, G. Interactive Visualization of Normal Behavioral Models and Expert Rules for Maritime Anomaly Detection. In Proceedings of the 2009 Sixth International Conference on Computer Graphics, Imaging and Visualization, Tianjin, China, 11–14 August 2009; pp. 459–466. [Google Scholar] [CrossRef]
- Salehi, A.; Jimenez-Berni, J.; Deery, D.M.; Palmer, D.; Holland, E.; Rozas-Larraondo, P.; Chapman, S.C.; Georgakopoulos, D.; Furbank, R.T. SensorDB: A virtual laboratory for the integration, visualization and analysis of varied biological sensor data. Plant Methods 2015, 11, 53. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nowak, R.D. Distributed EM algorithms for density estimation and clustering in sensor networks. IEEE Trans. Signal Process. 2003, 51, 2245–2253. [Google Scholar] [CrossRef]
- Kravchik, M.; Shabtai, A. Detecting Cyber Attacks in Industrial Control Systems Using Convolutional Neural Networks. In Proceedings of the 2018 Workshop on Cyber-Physical Systems Security and PrivaCy, Toronto, ON, Canada, 19 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 72–83. [Google Scholar] [CrossRef] [Green Version]
- Dong, B.; Andrews, B. Sensor-based occupancy behavioral pattern recognition for energy and comfort management in intelligent buildings. In Proceedings of the Eleventh International IBPSA Conference, Glasgow, Scotland, 27–30 July 2009; International Building Performance Simulation Association: Vancouver, BC, Canada, 2009; pp. 1444–1451. [Google Scholar]
- Hromic, H.; Le Phuoc, D.; Serrano, M.; Antonić, A.; Žarko, I.P.; Hayes, C.; Decker, S. Real time analysis of sensor data for the internet of things by means of clustering and event processing. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 685–691. [Google Scholar]
- Loane, J.; O’Mullane, B.; Bortz, B.; Knapp, R.B. Interpreting presence sensor data and looking for similarities between homes using cluster analysis. In Proceedings of the 2011 5th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth) and Workshops, Dublin, Ireland, 23–26 May 2011; pp. 438–445. [Google Scholar]
- Uhlmann, E.; Pontes, R.P.; Laghmouchi, A.; Bergmann, A. Intelligent pattern recognition of a SLM machine process and sensor data. Procedia CIRP 2017, 62, 464–469. [Google Scholar] [CrossRef]
- Grasso, M.; Colosimo, B.M. Process defects and in situ monitoring methods in metal powder bed fusion: A review. Meas. Sci. Technol. 2017, 28, 044005. [Google Scholar] [CrossRef] [Green Version]
- Grasso, M.; Colosimo, B. A statistical learning method for image-based monitoring of the plume signature in laser powder bed fusion. Robot. Comput.-Integr. Manuf. 2019, 57, 103–115. [Google Scholar] [CrossRef]
- Mani, M.; Feng, S.; Lane, B.; Donmez, A.; Moylan, S.; Fesperman, R. Measurement science needs for real-time control of additive manufacturing powder bed fusion processes. Int. J. Prod. Res. 2017, 55, 1400–1418. [Google Scholar] [CrossRef] [Green Version]
- Repossini, G.; Laguzza, V.; Grasso, M.; Colosimo, B.M. On the use of spatter signature for in-situ monitoring of Laser Powder Bed Fusion. Addit. Manuf. 2017, 16, 35–48. [Google Scholar] [CrossRef]
- Colosimo, B.M.; Grasso, M. Spatially weighted PCA for monitoring video image data with application to additive manufacturing. J. Qual. Technol. 2018, 50, 391–417. [Google Scholar] [CrossRef]
- Yuan, B.; Guss, G.M.; Wilson, A.C.; Hau-Riege, S.P.; DePond, P.J.; McMains, S.; Matthews, M.J.; Giera, B. Machine-Learning-Based Monitoring of Laser Powder Bed Fusion. Adv. Mater. Technol. 2018, 3, 1800136. [Google Scholar] [CrossRef]
- Salahshoor, K.; Mosallaei, M.; Bayat, M. Centralized and decentralized process and sensor fault monitoring using data fusion based on adaptive extended Kalman filter algorithm. Measurement 2008, 41, 1059–1076. [Google Scholar] [CrossRef]
- He, K.; Zhang, Q.; Hong, Y. Profile monitoring based quality control method for fused deposition modeling process. J. Intell. Manuf. 2019, 30, 947–958. [Google Scholar] [CrossRef] [Green Version]
- Zang, Y.; Qiu, P. Phase I monitoring of spatial surface data from 3D printing. Technometrics 2018, 60, 169–180. [Google Scholar] [CrossRef]
- March, S.T.; Scudder, G.D. Predictive maintenance: Strategic use of IT in manufacturing organizations. Inf. Syst. Front. 2019, 21, 327–341. [Google Scholar] [CrossRef]
- Poór, P.; Basl, J.; Zenisek, D. Predictive Maintenance 4.0 as next evolution step in industrial maintenance development. In Proceedings of the 2019 International Research Conference on Smart Computing and Systems Engineering (SCSE), Colombo, Sri Lanka, 28 March 2019; pp. 245–253. [Google Scholar]
- Ruiz-Sarmiento, J.R.; Monroy, J.; Moreno, F.A.; Galindo, C.; Bonelo, J.M.; Gonzalez-Jimenez, J. A predictive model for the maintenance of industrial machinery in the context of industry 4.0. Eng. Appl. Artif. Intell. 2020, 87, 103289. [Google Scholar] [CrossRef]
- Bonci, A.; Longhi, S.; Nabissi, G.; Verdini, F. Predictive Maintenance System using motor current signal analysis for Industrial Robot. In Proceedings of the 2019 24th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Zaragoza, Spain, 10–13 September 2019; pp. 1453–1456. [Google Scholar]
- Lin, C.; Hsieh, Y.; Cheng, F.; Huang, H.; Adnan, M. Time Series Prediction Algorithm for Intelligent Predictive Maintenance. IEEE Robot. Autom. Lett. 2019, 4, 2807–2814. [Google Scholar] [CrossRef]
- Gibert, K.; Marti-Puig, P.; Cusidó, J.; Solé-Casals, J. Identifying health status of wind turbines by using self organizing maps and interpretation-oriented post-processing tools. Energies 2018, 11, 723. [Google Scholar]
- Luo, B.; Wang, H.; Liu, H.; Li, B.; Peng, F. Early Fault Detection of Machine Tools Based on Deep Learning and Dynamic Identification. IEEE Trans. Ind. Electron. 2019, 66, 509–518. [Google Scholar] [CrossRef]
- Nguyen, K.T.; Medjaher, K. A new dynamic predictive maintenance framework using deep learning for failure prognostics. Reliab. Eng. Syst. Saf. 2019, 188, 251–262. [Google Scholar] [CrossRef] [Green Version]
- der Mauer, M.A.; Behrens, T.; Derakhshanmanesh, M.; Hansen, C.; Muderack, S. Applying sound-based analysis at porsche production: Towards predictive maintenance of production machines using deep learning and internet-of-things technology. In Digitalization Cases; Springer: Berlin/Heidelberg, Germany, 2019; pp. 79–97. [Google Scholar]
- Shi, S.; Wang, Q.; Xu, P.; Chu, X. Benchmarking state-of-the-art deep learning software tools. In Proceedings of the 2016 7th International Conference on Cloud Computing and Big Data (CCBD), Macau, China, 16–18 November 2016; pp. 99–104. [Google Scholar] [CrossRef] [Green Version]
- HP Jet Fusion 3D 4200 Printer Review 2018 | Industrial 3D Printer Reviews, 0. Available online: https://www.3dbeginners.com/hp-jet-fusion-3d-4200-review/ (accessed on 19 October 2019).
- Xu, R.; Wunsch, D. Survey of clustering algorithms. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [Green Version]
- Gupta, A.; Datta, S.; Das, S. Fuzzy clustering to identify clusters at different levels of fuzziness: An evolutionary multiobjective optimization approach. IEEE Trans. Cybern. 2019, 51, 2601–2611. [Google Scholar] [CrossRef] [Green Version]
- Lahmar, I.; Zaier, A.; Yahia, M.; Bouallegue, R. A New Self Adaptive Fuzzy Unsupervised Clustering Ensemble Based On Spectral Clustering. In Proceedings of the 2020 17th International Multi-Conference on Systems, Signals & Devices (SSD), Sfax, Tunisia, 20–23 July 2020; pp. 1–5. [Google Scholar]
- Shirkhorshidi, A.S.; Wah, T.Y.; Shirkhorshidi, S.M.R.; Aghabozorgi, S. Evolving Fuzzy Clustering Approach: An Epoch Clustering That Enables Heuristic Postpruning. IEEE Trans. Fuzzy Syst. 2021, 29, 560–568. [Google Scholar] [CrossRef]
- Sebastian, A.; Cistulli, P.A.; Cohen, G.; de Chazal, P. Characterisation of Upper Airway Collapse in OSA Patients Using Snore Signals: A Cluster Analysis Approach. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 5124–5127. [Google Scholar]
- Chakraborty, S.; Das, S. Detecting meaningful clusters from high-dimensional data: A strongly consistent sparse center-based clustering approach. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Gondeau, A.; Aouabed, Z.; Hijri, M.; Peres-Neto, P.; Makarenkov, V. Object weighting: A new clustering approach to deal with outliers and cluster overlap in computational biology. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 18, 633–643. [Google Scholar] [CrossRef]
- Li, K.; Cao, X.; Ge, X.; Wang, F.; Lu, X.; Shi, M.; Yin, R.; Mi, Z.; Chang, S. Meta-heuristic optimization-based two-stage residential load pattern clustering approach considering intra-cluster compactness and inter-cluster separation. IEEE Trans. Ind. Appl. 2020, 56, 3375–3384. [Google Scholar]
- Zhao, X.; Wang, Z.; Gao, L.; Li, Y.; Wang, S. Incremental face clustering with optimal summary learning via graph convolutional network. Tsinghua Sci. Technol. 2021, 26, 536–547. [Google Scholar] [CrossRef]
- Menon, V.; Muthukrishnan, G.; Kalyani, S. Subspace clustering without knowing the number of clusters: A parameter free approach. IEEE Trans. Signal Process. 2020, 68, 5047–5062. [Google Scholar] [CrossRef]
- Firdaus, S.; Uddin, M. A Survey on Clustering Algorithms and Complexity Analysis. Int. J. Comput. Sci. Issues (IJCSI) 2015, 12, 62. [Google Scholar]
- Kuchaki Rafsanjani, M.; Asghari Varzaneh, Z.; Emami Chukanlo, N. A Survey Of Hierarchical Clustering Algorithms. J. Math. Comput. Sci. 2012, 05, 229–240. [Google Scholar] [CrossRef] [Green Version]
- Guha, S.; Rastogi, R.; Shim, K. CURE: An efficient clustering algorithm for large databases. Inf. Syst. 2001, 26, 35–58. [Google Scholar] [CrossRef]
- Jagadish, H.; Gehrke, J.; Labrinidis, A.; Papakonstantinou, Y.; Patel, J.M.; Ramakrishnan, R.; Shahabi, C. Big data and its technical challenges. Commun. ACM 2014, 57, 86–94. [Google Scholar] [CrossRef]
- Kawamoto, T.; Kabashima, Y. Cross-validation estimate of the number of clusters in a network. Sci. Rep. 2017, 7, 3327. [Google Scholar] [CrossRef] [Green Version]
- Fu, W.; Perry, P.O. Estimating the number of clusters using cross-validation. J. Comput. Graph. Stat. 2020, 29, 162–173. [Google Scholar] [CrossRef]
- McIntyre, R.M.; Blashfield, R.K. A nearest-centroid technique for evaluating the minimum-variance clustering procedure. Multivar. Behav. Res. 1980, 15, 225–238. [Google Scholar] [CrossRef]
- Krieger, A.M.; Green, P.E. A cautionary note on using internal cross validation to select the number of clusters. Psychometrika 1999, 64, 341–353. [Google Scholar] [CrossRef]
- Overall, J.E.; Magee, K.N. Replication as a rule for determining the number of clusters in hierarchial cluster analysis. Appl. Psychol. Meas. 1992, 16, 119–128. [Google Scholar] [CrossRef]
- Tonidandel, S.; Overall, J.E. Determining the number of clusters by sampling with replacement. Psychol. Methods 2004, 9, 238. [Google Scholar] [CrossRef] [PubMed]
- Fang, Y.; Wang, J. Selection of the number of clusters via the bootstrap method. Comput. Stat. Data Anal. 2012, 56, 468–477. [Google Scholar] [CrossRef]
- Sevilla-Villanueva, B.; Gibert, K.; Sànchez-Marrè, M. Using CVI for understanding class topology in unsupervised scenarios. In Proceedings of the Spanish Association for Artificial Intelligence, Salamanca, Spain, 14–16 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 135–149. [Google Scholar]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2001, 63, 411–423. [Google Scholar] [CrossRef]
- Jung, Y.; Park, H.; Du, D.Z.; Drake, B.L. A decision criterion for the optimal number of clusters in hierarchical clustering. J. Glob. Optim. 2003, 25, 91–111. [Google Scholar] [CrossRef]
- Zhou, S.; Xu, Z.; Liu, F. Method for determining the optimal number of clusters based on agglomerative hierarchical clustering. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 3007–3017. [Google Scholar] [CrossRef] [PubMed]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat.-Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Milligan, G.W. A Monte Carlo study of thirty internal criterion measures for cluster analysis. Psychometrika 1981, 46, 187–199. [Google Scholar] [CrossRef]
- Karna, A.; Gibert, K. Automatic identification of the number of clusters in hierarchical clustering. Neural Comput. Appl. 2021, 34, 119–134. [Google Scholar] [CrossRef]
- Cowgill, M.C.; Harvey, R.J.; Watson, L.T. A genetic algorithm approach to cluster analysis. Comput. Math. Appl. 1999, 37, 99–108. [Google Scholar] [CrossRef] [Green Version]
- Bruzzese, D.; Vistocco, D. Cutting the dendrogram through permutation tests. In Proceedings of the COMPSTAT’2010, Paris, France, 22–27 August 2010; pp. 847–854. [Google Scholar]
- Bruzzese, D.; Vistocco, D. DESPOTA: DEndrogram slicing through a pemutation test approach. J. Classif. 2015, 32, 285–304. [Google Scholar] [CrossRef] [Green Version]
- Sander, J.; Qin, X.; Lu, Z.; Niu, N.; Kovarsky, A. Automatic extraction of clusters from hierarchical clustering representations. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Seoul, Korea, 30 April–2 May 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 75–87. [Google Scholar]
- Vogogias, A.; Kennedy, J.; Archaumbault, D.; Smith, V.A.; Currant, H. Mlcut: Exploring multi-level cuts in dendrograms for biological data. In Proceedings of the Computer Graphics and Visual Computing Conference (CGVC), London, UK, 10–11 September 2016; Eurographics Association: Bournemouth, UK, 2016. [Google Scholar]
- Vogogias, A.; Kennedy, J.; Archambault, D.W. Hierarchical Clustering with Multiple-Height Branch-Cut Applied to Short Time-Series Gene Expression Data. In Proceedings of the 2016 Eurographics Conference on Visualization (EuroVis), Groningen, The Netherlands, 6–10 June 2016; pp. 1–3. Available online: https://diglib.eg.org/handle/10.2312/eurp20161127 (accessed on 19 October 2019).
- Sevilla-Villanueva, B.; Gibert, K.; Sànchez-Marrè, M. A methodology to discover and understand complex patterns: Interpreted Integrative Multiview Clustering (I2MC). Pattern Recognit. Lett. 2017, 93, 85–94. [Google Scholar] [CrossRef]
- Gibert, K.; Cortés García, C.U. Weighting quantitative and qualitative variables in clustering methods. Mathw. Soft Comput. 1997, 4, 3. [Google Scholar]
- Gibert, K.; Valls, A.; Batet, M. Introducing semantic variables in mixed distance measures: Impact on hierarchical clustering. Knowl. Inf. Syst. 2014, 40, 559–593. [Google Scholar] [CrossRef] [Green Version]
- Suman, S.; Karna, A.; Gibert, K. Towards Expert-nspired Automatic Criterion to Cut a Dendrogram for Real-Industrial Applications. Artif. Intell. Res. Dev. 2021, 339, 235. [Google Scholar]
- Gibert, K.; García-Rudolph, A.; Rodríguez-Silva, G. The Role of KDD Support- Interpretation Tools in the Conceptualization of Medical Profiles: An Application to Neurorehabilitation. ACTA Inform. Medica 2008, 16, 178–182. [Google Scholar]
- Gibert, K.; Sevilla-Villanueva, B.; Sànchez-Marrè, M. The role of significance tests in consistent interpretation of nested partitions. J. Comput. Appl. Math. 2016, 292, 623–633. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Gibert, K.; Horsburgh, J.S.; Athanasiadis, I.N.; Holmes, G. Environmental Data Science. Environ. Model. Softw. 2018, 106, 4–12. [Google Scholar] [CrossRef]
- Gibert, K.; Sànchez-Marrè, M.; Izquierdo, J. A survey on pre-processing techniques: Relevant issues in the context of environmental data mining. AI Commun. 2016, 29, 627–663. [Google Scholar] [CrossRef] [Green Version]
- Gibert, K.; Izquierdo, J.; Sànchez-Marrè, M.; Hamilton, S.H.; Rodríguez-Roda, I.; Holmes, G. Which method to use? An assessment of data mining methods in Environmental Data Science. Environ. Model. Softw. 2019, 110, 3–27. [Google Scholar] [CrossRef] [Green Version]
- Choi, S.S.; Cha, S.H.; Tappert, C.C. A Survey of Binary Similarity and Distance Measures. J. Syst. Cybern. Inform. 2010, 8, 43–48. [Google Scholar]
- Jain, A.K. Data Clustering: 50 Years Beyond K-means. In Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2010; pp. 3–4. [Google Scholar] [CrossRef] [Green Version]
- Maulik, U.; Bandyopadhyay, S. Performance evaluation of some clustering algorithms and validity indices. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1650–1654. [Google Scholar] [CrossRef] [Green Version]
- Gurrutxaga, I.; Muguerza, J.; Arbelaitz, O.; Perez, J.M.; Martin, J.I. Towards a standard methodology to evaluate internal cluster validity indices. Pattern Recognit. Lett. 2011, 32, 505–515. [Google Scholar] [CrossRef] [Green Version]
- Salvador, S.; Chan, P. Determining the Number of Clusters/Segments in Hierarchical Clustering/Segmentation Algorithms. In Proceedings of the 16th IEEE International Conference on Tools with Artificial Intelligence, Boca Raton, FL, USA, 15–17 November 2004; pp. 576–584. [Google Scholar]
- Gibert, K.; Conti, D.; Vrecko, D. Assisting the end-user in the interpretation of profiles for decision support. an application to wastewater treatment plants. Environ. Eng. Manag. J. 2012, 11, 931–944. [Google Scholar] [CrossRef]
- Pérez-Bonilla, A.; Gibert, K. Towards automatic generation of conceptual interpretation of clustering. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2007; pp. 653–663. [Google Scholar]
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. From data mining to knowledge discovery in databases. AI Mag. 1996, 17, 37. [Google Scholar]
- Gunning, D. Explainable artificial intelligence (xai). Def. Adv. Res. Proj. Agency (DARPA) 2017, 2, 2. [Google Scholar] [CrossRef] [PubMed] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Description |
|---|---|
| Timestamp | Timestamp of the sensor recording |
| Sensor_1 | To measure pressure in Air release system |
| Sensor_2 | To measure Ambient temperature |
| Sensor_3 | To measure temperature in cooling system-1 |
| Sensor_4 | To measure temperature in cooling system-2 |
| Sensor_5 | To measure temperature in cooling system-3 |
| Sensor_6 | To detect glass breakage on left fusing system |
| Sensor_7 | To detect glass breakage on right fusing lamp |
| Sensor_8 | To measure temperature in carriage back |
| Sensor_9 | To measure temperature in carriage front |
| Sensor_10 | To measure temperature in carriage middle |
| Sensor_11 | Internal camera reading |
| Sensor_12 | To measure the reference temperature in subsystem–back |
| Sensor_13 | To measure the reference temperature in subsystem–front |
| Sensor_14 | To measure the reference temperature in subsystem–middle |
| Sensor_15 | To measure the temperature in the subsystem–back |
| Sensor_16 | To measure the temperature in the subsystem–front |
| Sensor_17 | To measure the temperature in the subsystem–middle |
| Sensor_18 | To measure the reference temperature in subsystem–back |
| Sensor_19 | To measure the reference temperature in subsystem–front |
| Sensor_20 | To measure the reference temperature in subsystem-middle |
| Sensor_21 | To measure the temperature in the subsystem–back |
| Sensor_22 | To measure the temperature in the subsystem–front |
| Sensor_23 | To measure the temperature in the subsystem–middle |
| Sensor_24 | To check obstruction in pressure system-left |
| Sensor_25 | Temperature coefficient sensor |
| Sensor_26 | Temp. coefficient for fusing system1–left |
| Sensor_27 | Temp. coefficient for fusing system1–right |
| Sensor_28 | Temp. coefficient for fusing system2–left |
| Sensor_29 | Temp. coefficient for fusing system2–right |
| Sensor_30 | Temp. coefficient for camera system |
| Sensor_31 | Temp. coefficient for Cooling left air exit |
| Sensor_32 | Temp. coefficient for Top heating |
| Sensor_33 | Temp. coefficient for right air exit |
| Sensor_34 | Humidity sensor for subsystem XX |
| Sensor_35 | Temperature sensor for subsystem XX |
| Sensor_36 | Connectivity check sensor for fusing system-left |
| Sensor_37 | Connectivity check sensor for fusing system–right |
| Sensor_38 | To check obstruction in pressure system-right |
| Sensor_39 | Sensor in subsystem |
| Sensor_40 | Temperature Sensor in subsystem_z1 |
| Sensor_41 | Temperature Sensor in subsystem_z2 |
| Data Size | Hierarchical Clustering | CURE | Bootstrap–CURE |
|---|---|---|---|
| 5000 | 36.296 | 2.922 | 0.578 |
| 10,000 | 68.875 | 4.125 | 1.406 |
| 15,000 | 101.094 | 8.297 | 2.094 |
| 20,000 | 139.625 | 14.25 | 3.156 |
| 25,000 | 257.375 | 22.125 | 4.187 |
| 30,000 | 262.718 | 32.422 | 5.328 |
| 35,000 | 274.109 | 47.469 | 6.75 |
| 40,000 | 330.391 | 62.703 | 8.062 |
| 45,000 | 443.578 | 76.078 | 10.141 |
| Bootstrap–CURE | |||||
|---|---|---|---|---|---|
| Cluster 0 | Cluster 1 | Cluster 2 | Cluster 3 | ||
| Hierarchical Clustering | Cluster_0 | 1476 | 549 | 770 | 133 |
| Cluster 1 | 157 | 2324 | 0 | 0 | |
| Cluster 2 | 201 | 0 | 2639 | 0 | |
| Cluster 3 | 54 | 0 | 0 | 1697 | |
| Attributes | Hierarchical Clustering | Original CURE | Bootstrap–CURE |
|---|---|---|---|
| Sample size | 10,000 | 10,000 | 10,000 |
| No. of clusters | 4 | 4 | 4 |
| Calinski–Harabasz | 9208.0117 | 2885.2101 | 5198.4981 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suman, S.; Karna, A.; Gibert, K. Bootstrap–CURE: A Novel Clustering Approach for Sensor Data—An Application to 3D Printing Industry. Appl. Sci. 2022, 12, 2191. https://doi.org/10.3390/app12042191
Suman S, Karna A, Gibert K. Bootstrap–CURE: A Novel Clustering Approach for Sensor Data—An Application to 3D Printing Industry. Applied Sciences. 2022; 12(4):2191. https://doi.org/10.3390/app12042191
Chicago/Turabian StyleSuman, Shikha, Ashutosh Karna, and Karina Gibert. 2022. "Bootstrap–CURE: A Novel Clustering Approach for Sensor Data—An Application to 3D Printing Industry" Applied Sciences 12, no. 4: 2191. https://doi.org/10.3390/app12042191
APA StyleSuman, S., Karna, A., & Gibert, K. (2022). Bootstrap–CURE: A Novel Clustering Approach for Sensor Data—An Application to 3D Printing Industry. Applied Sciences, 12(4), 2191. https://doi.org/10.3390/app12042191