
Faster MDNet for Visual Object Tracking



Abstract
:1. Introduction
- We introduce a channel attention module after convolutional layers. Model robustness is improved by fast one-dimensional convolution without dimensionality reduction while adding only a few parameters. We use the ILSVRC dataset from the image classification domain as training data and design domain adaptation components for transferring feature information. The adaptive spatial pyramid pooling layer with a multi-scale feature fusion strategy is implemented to reduce model complexity and to improve model robustness.
- Our model has a simple structure that enables lightweight tracking. Due to a significant reduction in model complexity, the proposed tracker has a high real-time speed. The tracker uses both high-level semantic information and low-level semantic information for a higher tracking accuracy.
2. Related Work
2.1. MDNet-Based Trackers
2.2. Attention Mechanism in Computer Vision Tasks
3. Method
3.1. Network Structure
3.2. Channel Attention Module
3.2.1. Local Cross-Channel Interactions
3.2.2. Adaptive Selection of Channel Interactions
3.3. Domain Adaptive Components
3.4. Adaptive Spatial Pyramid Pooling Layer with Multi-Scale Feature Fusion Strategy
3.5. Tracking Process
| Algorithm 1. Tracking Algorithm |
| Input: Pretrained filters |
| Primary target position |
| Output: Optimal target positions |
| 1: Randomly initialize the fully-connected layer . |
| 2: Use to train a bounding box regression model. |
| 3: Generate positive samples and negative samples . |
| 4: Update by and . |
| 5: and . |
| 6: Optimal target positions |
| 7: Randomly initialize the fully-connected layer . |
| 8: repeat |
| 9: Generate target candidate samples . |
| 10: Obtain the optimal target state by (10). |
| 11: if then |
| 12: Plot training samples and . |
| 13: and |
| 14: if then . |
| 15: if then . |
| 16: Fit by bounding box regression model. |
| 17: if then |
| 18: Update using and . |
| 19: else if then |
| 20: Update using and . |
| 21: until end of sequence |
3.5.1. Multi-Domain Learning
3.5.2. Optimal Target Position Estimation
3.5.3. Bounding Box Regression
3.5.4. Network Update
3.5.5. Loss Function
4. Experiments
4.1. Implementation Details
4.2. Options of Kernel Size k
4.3. Comparisons of Different Attention Modules
4.4. Results on OTB100
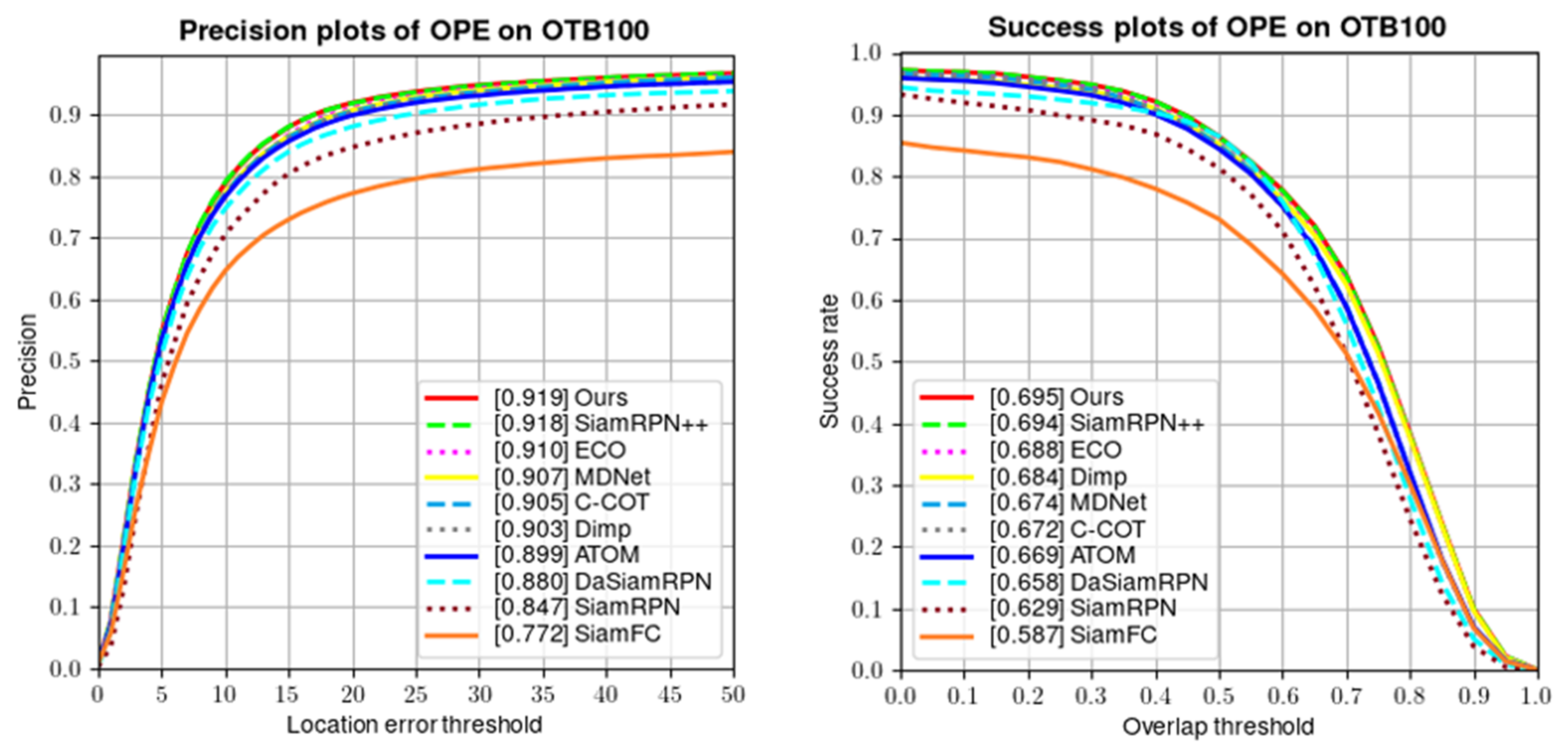
4.4.1. Comparisons with State-of-the-Art Trackers
4.4.2. Comparisons with MDNet-Based Trackers
4.5. Results on VOT2018
4.6. Results on TrackingNet
4.7. Comparisons on UAV123
4.8. Comparisons on NfS
4.9. Visualization Result
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Processing Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.-H. Hierarchical convolutional features for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3074–3082. [Google Scholar]
- Qi, Y.; Zhang, S.; Qin, L.; Yao, H.; Huang, Q.; Lim, J.; Yang, M.-H. Hedged deep tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4303–4311. [Google Scholar]
- Wang, N.; Zhou, W.; Tian, Q.; Hong, R.; Wang, M.; Li, H. Multi-cue correlation filters for robust visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4844–4853. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 472–488. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-convolutional siamese networks for object tracking. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 850–865. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Processing Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4282–4291. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-aware anchor-free tracking. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXI 16. Springer International Publishing: Cham, Switzerland, 2020; pp. 771–787. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. Atom: Accurate tracking by overlap maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4660–4669. [Google Scholar]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning discriminative model prediction for tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6182–6191. [Google Scholar]
- Danelljan, M.; Gool, L.V.; Timofte, R. Probabilistic regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7183–7192. [Google Scholar]
- Wang, N.; Zhou, W.; Wang, J.; Li, H. Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1571–1580. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8126–8135. [Google Scholar]
- Lin, L.; Fan, H.; Xu, Y.; Ling, H. SwinTrack: A Simple and Strong Baseline for Transformer Tracking. arXiv Preprint 2021, arXiv:2112.00995. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Song, Y.; Ma, C.; Wu, X.; Gong, L.; Bao, L.; Zuo, W.; Shen, C.; Lau, R.W.; Yang, M.-H. Vital: Visual tracking via adversarial learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8990–8999. [Google Scholar]
- Jung, I.; Son, J.; Baek, M.; Han, B. Real-time mdnet. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 83–98. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.-H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [Green Version]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Čehovin, Z.L.; Vojíř, T.; Bhat, G.; Lukežič, A.; Eldesokey, A.; et al. The sixth visual object tracking vot2018 challenge results. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Muller, M.; Bibi, A.; Giancola, S.; Alsubaihi, S.; Ghanem, B. Trackingnet: A large-scale dataset and benchmark for object tracking in the wild. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 300–317. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 445–461. [Google Scholar]
- Kiani Galoogahi, H.; Fagg, A.; Huang, C.; Ramanan, D.; Lucey, S. Need for speed: A benchmark for higher frame rate object tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1125–1134. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global second-order pooling convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3024–3033. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. Eca-net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv Preprint 2014, arXiv:1409.1556. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Parameters | FLOPs | Mean IoU |
|---|---|---|---|
| Baseline | 4,170,370 | 122.14 M | 0.689 |
| +SE Module [31] | 4,203,138 | 122.17 M | 0.674 |
| +GSop Module [32] | 4,480,264 | 252.11 M | 0.695 |
| +CBAM Module [33] | 4,203,236 | 122.17 M | 0.676 |
| +ECA Module [34] | 4,170,375 | 122.14 M | 0.694 |
| Trackers | Precision | AUC | FPS |
|---|---|---|---|
| MDNet [20] | 0.907 | 0.674 | 1 |
| VITAL [21] | 0.902 | 0.674 | <1 |
| RT-MDNet [22] | 0.868 | 0.657 | 25 |
| Ours-conf | 0.912 | 0.681 | 35 |
| Ours | 0.919 | 0.695 | 36 |
| Trackers | Accuracy | Robustness | EAO |
|---|---|---|---|
| ATOM [14] | 0.59 | 0.20 | 0.401 |
| C-COT [5] | 0.50 | 0.32 | 0.267 |
| DaSiamRPN [10] | 0.59 | 0.28 | 0.383 |
| DiMP [15] | 0.60 | 0.15 | 0.440 |
| ECO [6] | 0.48 | 0.28 | 0.276 |
| MDNet [20] | 0.55 | 0.38 | 0.383 |
| PrDiMP [16] | 0.62 | 0.17 | 0.442 |
| SiamFC [7] | 0.50 | 0.59 | 0.188 |
| SiamRPN [8] | 0.59 | 0.28 | 0.383 |
| SiamRPN++ [11] | 0.60 | 0.23 | 0.414 |
| Ours-conf | 0.60 | 0.21 | 0.409 |
| Ours | 0.62 | 0.16 | 0.432 |
| Trackers | AUC | Precision | |
|---|---|---|---|
| ATOM [14] | 0.703 | 0.648 | 0.771 |
| DaSiamRPN [10] | 0.638 | 0.591 | 0.733 |
| DiMP [15] | 0.723 | 0.633 | 0.785 |
| ECO [6] | 0.554 | 0.492 | 0.618 |
| MDNet [20] | 0.606 | 0.565 | 0.705 |
| PrDiMP [16] | 0.750 | 0.691 | 0.803 |
| RT-MDNet [22] | 0.584 | 0.533 | 0.694 |
| SiamFC [7] | 0.571 | 0.533 | 0.663 |
| SiamRPN++ [11] | 0.733 | 0.694 | 0.800 |
| TransT [18] | 0.814 | 0.803 | 0.867 |
| Ours-conf | 0.705 | 0.672 | 0.788 |
| Ours | 0.738 | 0.696 | 0.802 |
| Trackers | ATOM [14] | C-COT [5] | DiMP [15] | ECO [6] | MDNet [20] | PrDiMP [16] | RT-MDNet [22] | SiamFC [7] | SiamRPN++ [11] | TransT [18] | Ours |
|---|---|---|---|---|---|---|---|---|---|---|---|
| UAV123 | 0.642 | 0.513 | 0.653 | 0.522 | 0.528 | 0.680 | 0.528 | 0.498 | 0.613 | 0.691 | 0.648 |
| NfS | 0.584 | 0.488 | 0.620 | 0.466 | 0.429 | 0.635 | - | - | 0.502 | 0.657 | 0.632 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Q.; Fan, K.; Wang, Y.; Zheng, Y. Faster MDNet for Visual Object Tracking. Appl. Sci. 2022, 12, 2336. https://doi.org/10.3390/app12052336
Yu Q, Fan K, Wang Y, Zheng Y. Faster MDNet for Visual Object Tracking. Applied Sciences. 2022; 12(5):2336. https://doi.org/10.3390/app12052336
Chicago/Turabian StyleYu, Qianqian, Keqi Fan, Yiyang Wang, and Yuhui Zheng. 2022. "Faster MDNet for Visual Object Tracking" Applied Sciences 12, no. 5: 2336. https://doi.org/10.3390/app12052336
APA StyleYu, Q., Fan, K., Wang, Y., & Zheng, Y. (2022). Faster MDNet for Visual Object Tracking. Applied Sciences, 12(5), 2336. https://doi.org/10.3390/app12052336