
Classification of Event-Related Potentials with Regularized Spatiotemporal LCMV Beamforming




Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Notation
2.2. Spatiotemporal Beamforming
2.3. Covariance Matrix Regularization
2.3.1. Empirical Covariance Estimation
2.3.2. Shrunk Covariance Estimation
2.3.3. Spatiotemporal Beamforming with Kronecker–Toeplitz-Structured Covariance
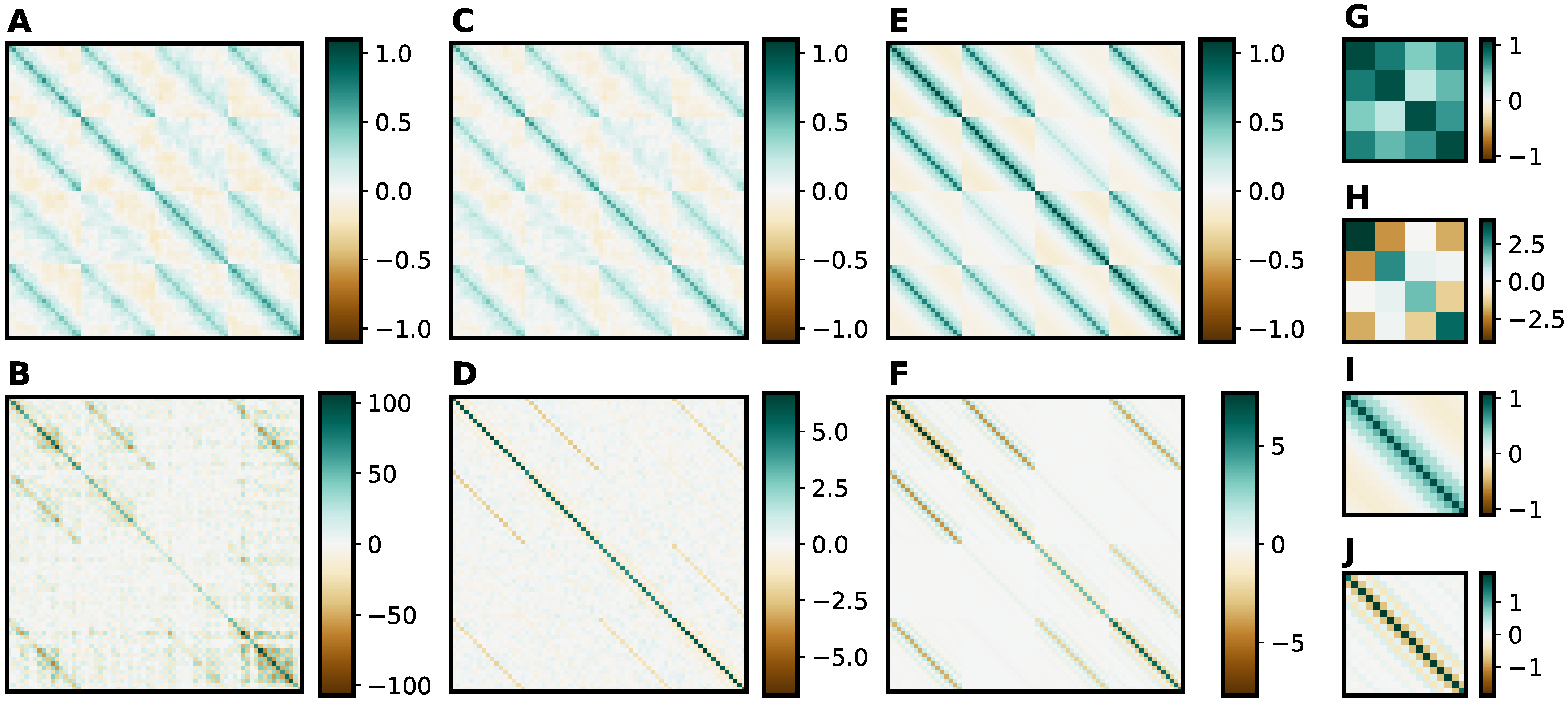
2.3.4. Kronecker–Toeplitz-Structured Covariance Estimation
2.4. Dataset
2.5. Software and Preprocessing
2.6. Classification
2.6.1. Cross-Validation Scheme per Subject
2.6.2. Spatiotemporal Beamformer Classifier
2.6.3. Riemannian Geometry Classifier
3. Results
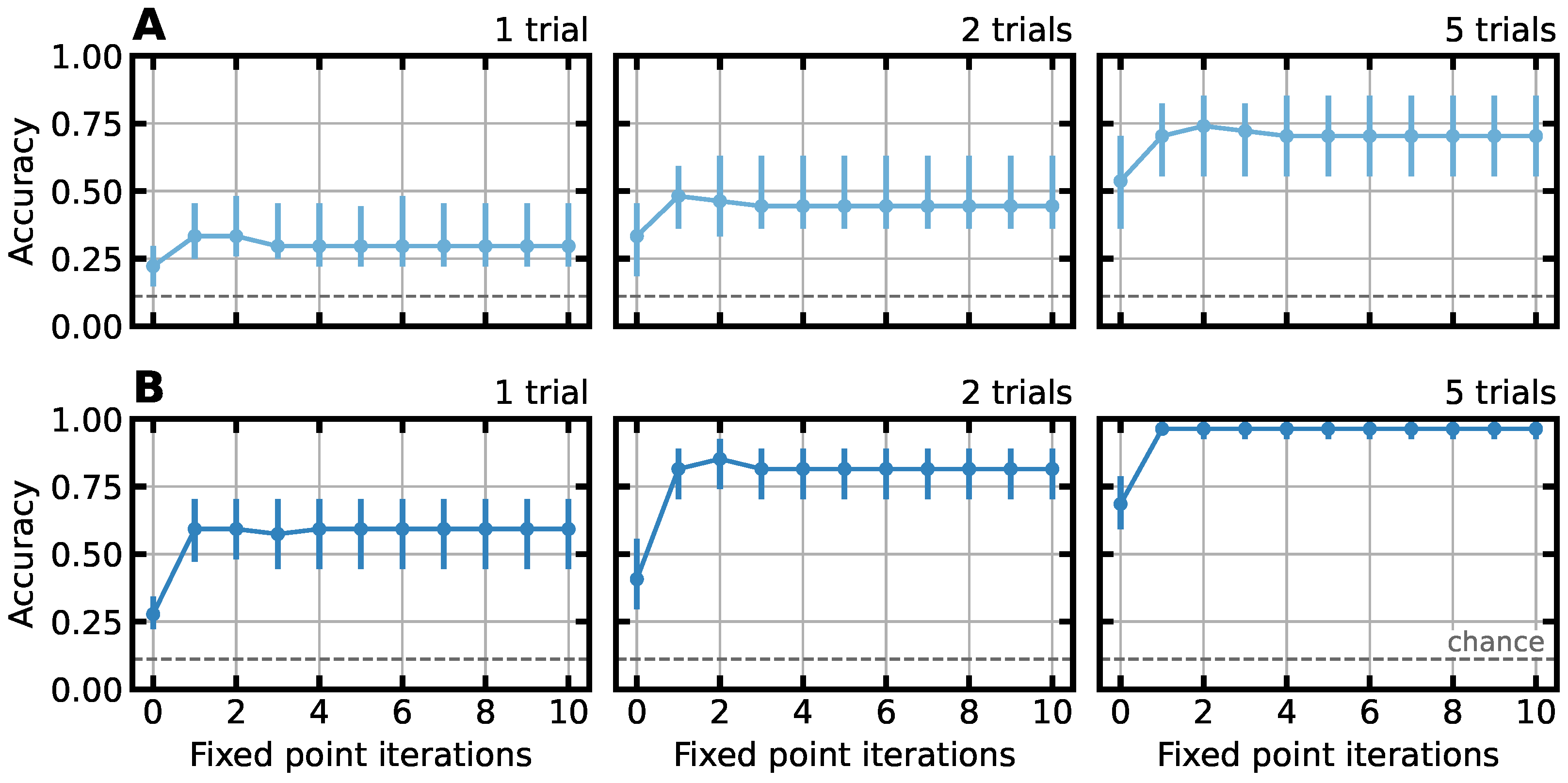
3.1. Minimum Required Fixed-Point Iterations
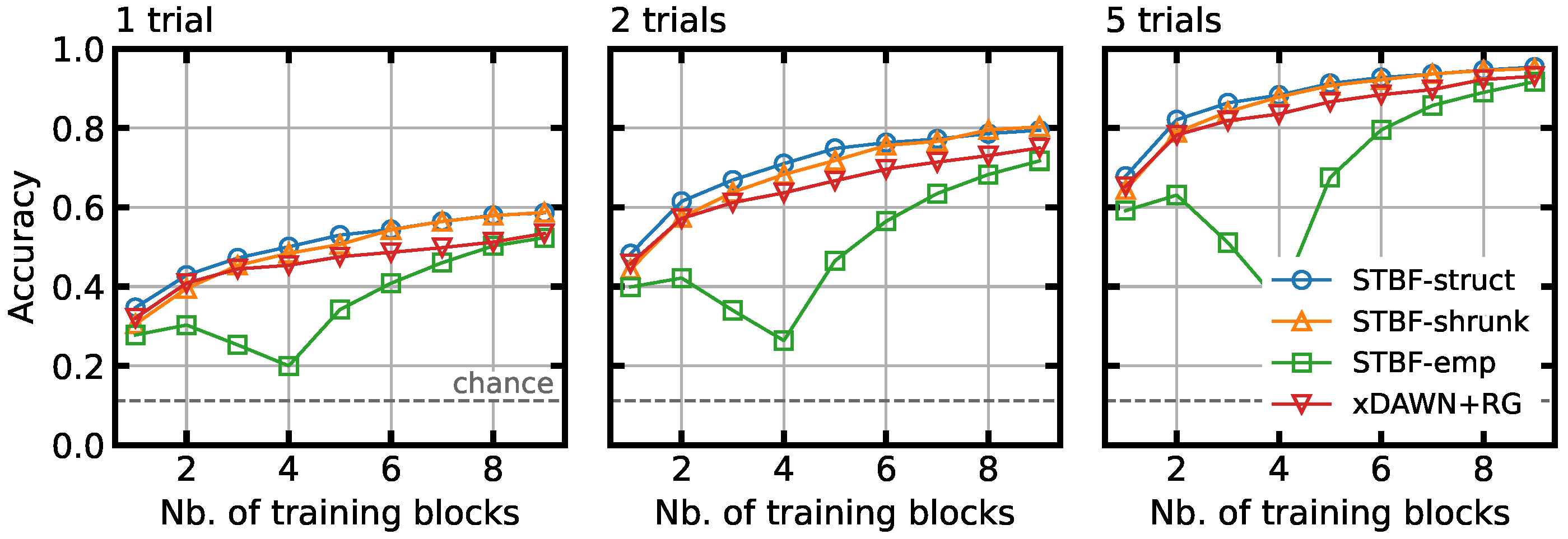
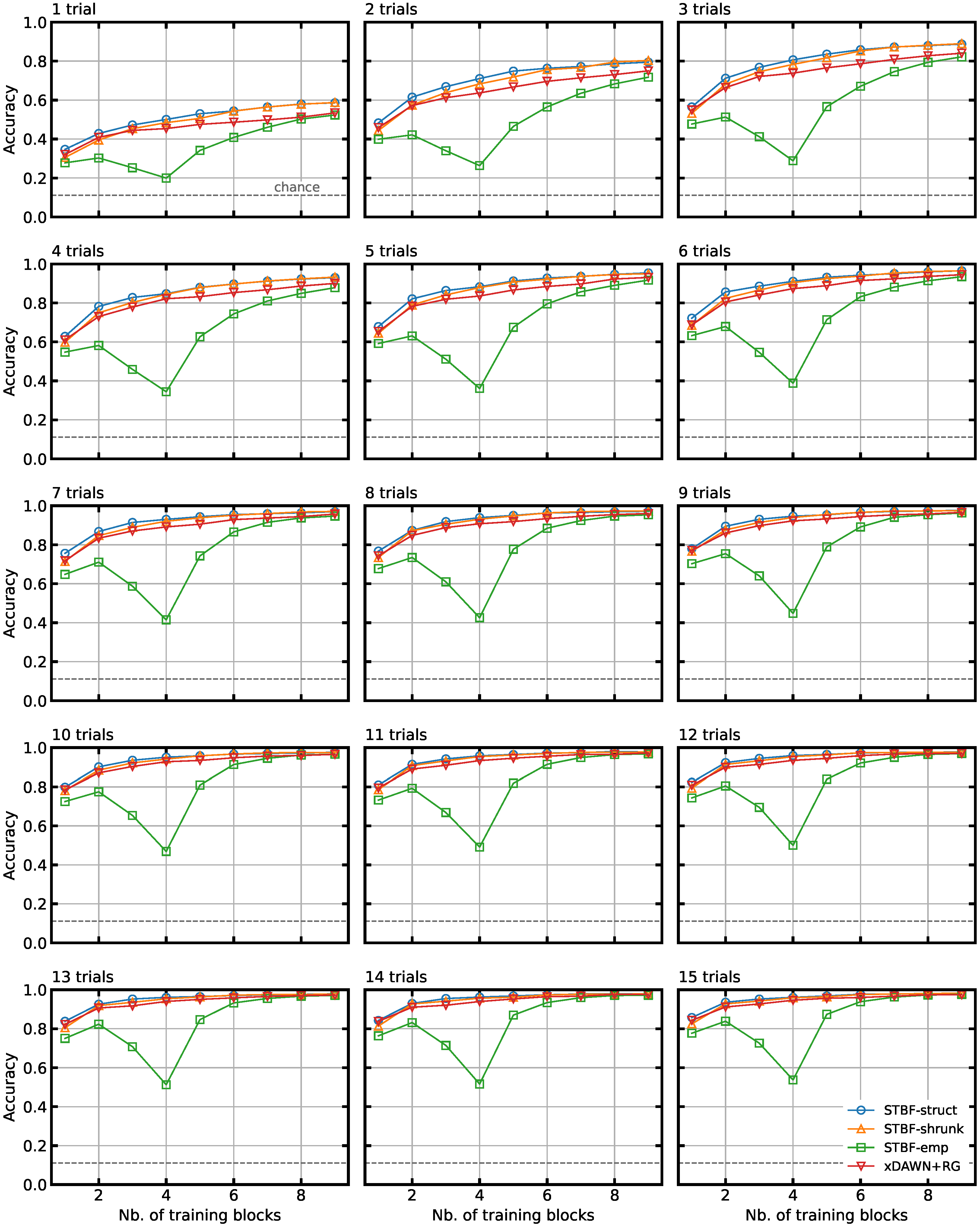
3.2. Classifier Accuracy for Limited Training Data
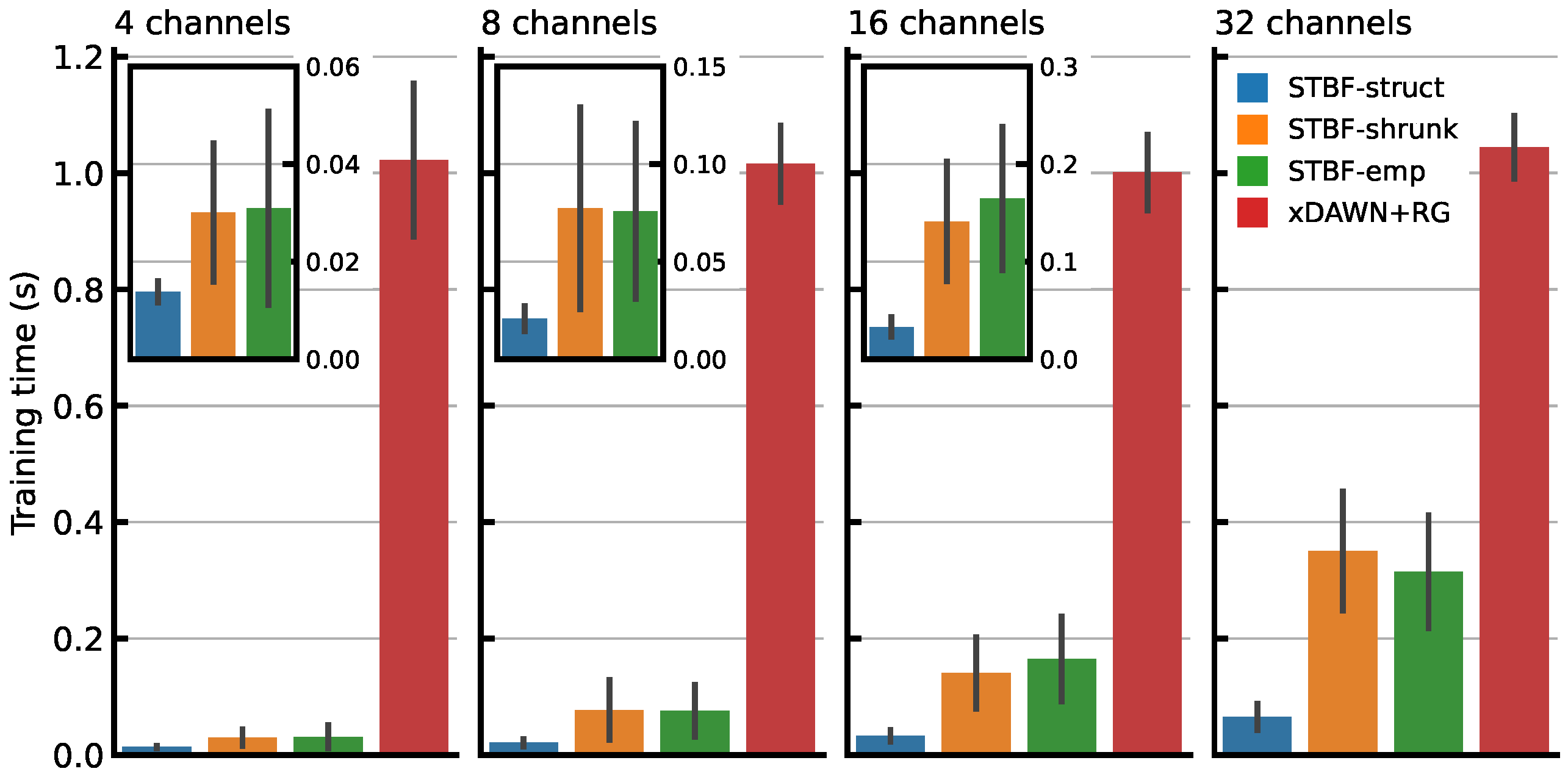
3.3. Classifier Training Time
4. Discussion
4.1. Classification Accuracy
4.2. Time and Memory Complexity
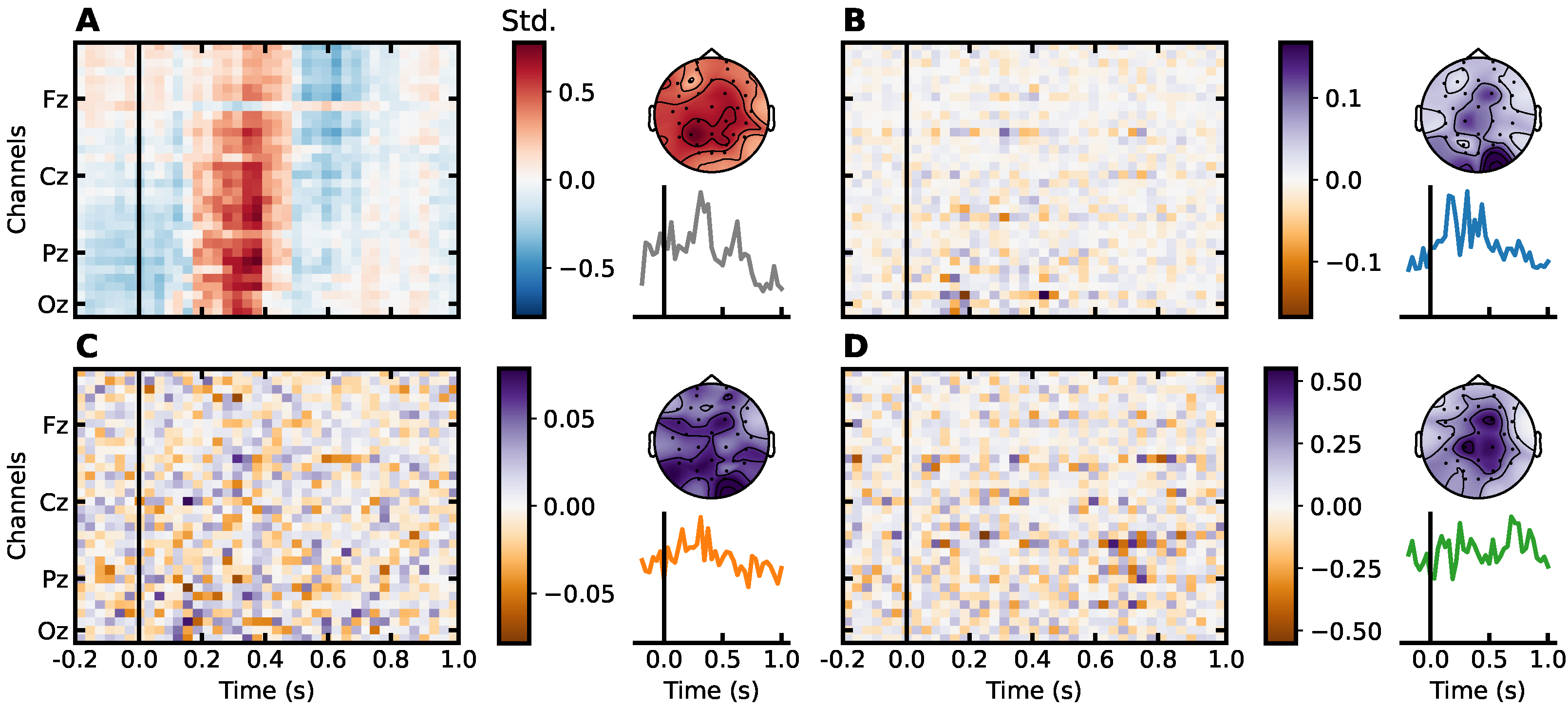
4.3. Interpreting the Weights
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Wolpaw, J.R.; Birbaumer, N.; McFarland, D.J.; Pfurtscheller, G.; Vaughan, T.M. Brain–computer interfaces for communication and control. Clin. Neurophysiol. 2002, 113, 767–791. [Google Scholar] [CrossRef]
- Naci, L.; Monti, M.M.; Cruse, D.; Kübler, A.; Sorger, B.; Goebel, R.; Kotchoubey, B.; Owen, A.M. Brain–computer interfaces for communication with nonresponsive patients. Ann. Neurol. 2012, 72, 312–323. [Google Scholar] [CrossRef] [PubMed]
- Chaudhary, U.; Birbaumer, N.; Ramos-Murguialday, A. Brain-computer interfaces for communication and rehabilitation. Nat. Rev. Neurol. 2016, 12, 513–525. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abiri, R.; Borhani, S.; Sellers, E.W.; Jiang, Y.; Zhao, X. A comprehensive review of EEG-based brain–computer interface paradigms. J. Neural Eng. 2019, 16, 11001. [Google Scholar] [CrossRef] [PubMed]
- Mellinger, J.; Schalk, G.; Braun, C.; Preissl, H.; Rosenstiel, W.; Birbaumer, N.; Kübler, A. An MEG-based brain–computer interface (BCI). NeuroImage 2007, 36, 581–593. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hong, K.S.; Naseer, N.; Kim, Y.H. Classification of prefrontal and motor cortex signals for three-class fNIRS–BCI. Neurosci. Lett. 2015, 587, 87–92. [Google Scholar] [CrossRef] [PubMed]
- Paek, A.Y.; Kilicarslan, A.; Korenko, B.; Gerginov, V.; Knappe, S.; Contreras-Vidal, J.L. Towards a Portable Magnetoencephalography Based Brain Computer Interface with Optically-Pumped Magnetometers. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 3420–3423. [Google Scholar] [CrossRef]
- Schalk, G.; Leuthardt, E.C. Brain-computer interfaces using electrocorticographic signals. IEEE Rev. Biomed. Eng. 2011, 4, 140–154. [Google Scholar] [CrossRef] [PubMed]
- Maynard, E.M.; Nordhausen, C.T.; Normann, R.A. The Utah Intracortical Electrode Array: A recording structure for potential brain-computer interfaces. Electroencephalogr. Clin. Neurophysiol. 1997, 102, 228–239. [Google Scholar] [CrossRef]
- Willett, F.R.; Avansino, D.T.; Hochberg, L.R.; Henderson, J.M.; Shenoy, K.V. High-performance brain-to-text communication via handwriting. Nature 2021, 593, 249–254. [Google Scholar] [CrossRef]
- Gao, S.; Wang, Y.; Gao, X.; Hong, B. Visual and Auditory Brain–Computer Interfaces. IEEE Trans. Biomed. Eng. 2014, 61, 1436–1447. [Google Scholar] [CrossRef]
- Kapgate, D.; Kalbande, D. A Review on Visual Brain Computer Interface. In Advancements of Medical Electronics; Lecture Notes in Bioengineering; Gupta, S., Bag, S., Ganguly, K., Sarkar, I., Biswas, P., Eds.; Springer India: New Delhi, India, 2015; pp. 193–206. [Google Scholar] [CrossRef]
- Farwell, L.A.; Donchin, E. Talking off the top of your head: Toward a mental prosthesis utilizing event-related brain potentials. Electroencephalogr. Clin. Neurophysiol. 1988, 70, 510–523. [Google Scholar] [CrossRef]
- Sellers, E.W.; Donchin, E. A P300-based brain–computer interface: Initial tests by ALS patients. Clin. Neurophysiol. 2006, 117, 538–548. [Google Scholar] [CrossRef] [PubMed]
- Barachant, A.; Congedo, M. A Plug&Play P300 BCI Using Information Geometry. arXiv 2014, arXiv:1409.0107. [Google Scholar]
- Philip, J.T.; George, S.T. Visual P300 Mind-Speller Brain-Computer Interfaces: A Walk through the Recent Developments with Special Focus on Classification Algorithms. Clin. EEG Neurosci. 2020, 51, 19–33. [Google Scholar] [CrossRef] [PubMed]
- Tayeb, S.; Mahmoudi, A.; Regragui, F.; Himmi, M.M. Efficient detection of P300 using Kernel PCA and support vector machine. In Proceedings of the 2014 Second World Conference on Complex Systems (WCCS), Agadir, Morocco, 10–12 November 2014; pp. 17–22. [Google Scholar] [CrossRef]
- Vařeka, L. Evaluation of convolutional neural networks using a large multi-subject P300 dataset. Biomed. Signal Process. Control. 2020, 58, 101837. [Google Scholar] [CrossRef] [Green Version]
- Borra, D.; Fantozzi, S.; Magosso, E. Convolutional neural network for a P300 brain-computer interface to improve social attention in autistic spectrum disorder. In Mediterranean Conference on Medical and Biological Engineering and Computing—MEDICON 2019; Henriques, J., Neves, N., de Carvalho, P., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 1837–1843. [Google Scholar] [CrossRef]
- Van Vliet, M.; Chumerin, N.; De Deyne, S.; Wiersema, J.R.; Fias, W.; Storms, G.; Van Hulle, M.M. Single-trial erp component analysis using a spatiotemporal lcmv beamformer. IEEE Trans. Biomed. Eng. 2015, 63, 55–66. [Google Scholar] [CrossRef] [PubMed]
- Wittevrongel, B.; Van Hulle, M.M. Faster p300 classifier training using spatiotemporal beamforming. Int. J. Neural Syst. 2016, 26, 1650014. [Google Scholar] [CrossRef]
- Wittevrongel, B.; Van Hulle, M.M. Spatiotemporal Beamforming: A Transparent and Unified Decoding Approach to Synchronous Visual Brain-Computer Interfacing. Front. Neurosci. 2017, 11, 630. [Google Scholar] [CrossRef] [Green Version]
- Libert, A.; Wittevrongel, B.; Van Hulle, M.M. Effect of stimulus direction on motion-onset visual evoked potentials decoded using spatiotemporal beamforming Abstract. In Proceedings of the 2021 10th International IEEE/EMBS Conference on Neural Engineering (NER), Virtual, 4–6 May 2021; pp. 503–506. [Google Scholar] [CrossRef]
- Gonzalez-Navarro, P.; Moghadamfalahi, M.; Akçakaya, M.; Erdogmus, D. Spatio-temporal EEG models for brain interfaces. Signal Process. 2017, 131, 333–343. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Vliet, M.; Salmelin, R. Post-hoc modification of linear models: Combining machine learning with domain information to make solid inferences from noisy data. NeuroImage 2020, 204, 116221. [Google Scholar] [CrossRef]
- Van Veen, B.D.; Van Drongelen, W.; Yuchtman, M.; Suzuki, A. Localization of brain electrical activity via linearly constrained minimum variance spatial filtering. IEEE Trans. Biomed. Eng. 1997, 44, 867–880. [Google Scholar] [CrossRef] [PubMed]
- Treder, M.S.; Porbadnigk, A.K.; Avarvand, F.S.; Müller, K.R.; Blankertz, B. The LDA beamformer: Optimal estimation of ERP source time series using linear discriminant analysis. NeuroImage 2016, 129, 279–291. [Google Scholar] [CrossRef] [PubMed]
- Wittevrongel, B.; Hulle, M.M.V. Frequency- and Phase Encoded SSVEP Using Spatiotemporal Beamforming. PLoS ONE 2016, 11, e0159988. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wittevrongel, B.; Van Wolputte, E.; Van Hulle, M.M. Code-modulated visual evoked potentials using fast stimulus presentation and spatiotemporal beamformer decoding. Sci. Rep. 2017, 7, 15037. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stein, C. Inadmissability of the usual estimator for the mean of a multivariate normal distribution. In Contribution to the Theory of Statistics; University of California Press: Berkeley, CA, USA, 1956; Volume 1, pp. 197–206. [Google Scholar] [CrossRef]
- Khatri, C.; Rao, C. Effects of estimated noise covariance matrix in optimal signal detection. IEEE Trans. Acoust. Speech, Signal Process. 1987, 35, 671–679. [Google Scholar] [CrossRef]
- Ledoit, O.; Wolf, M. A well-conditioned estimator for large-dimensional covariance matrices. J. Multivar. Anal. 2004, 88, 365–411. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Wiesel, A.; Eldar, Y.C.; Hero, A.O. Shrinkage algorithms for MMSE covariance estimation. IEEE Trans. Signal Process. 2010, 58, 5016–5029. [Google Scholar] [CrossRef] [Green Version]
- Tong, J.; Hu, R.; Xi, J.; Xiao, Z.; Guo, Q.; Yu, Y. Linear shrinkage estimation of covariance matrices using low-complexity cross-validation. Signal Process. 2018, 148, 223–233. [Google Scholar] [CrossRef] [Green Version]
- De Munck, J.; Vijn, P.; Lopes da Silva, F. A random dipole model for spontaneous brain activity. IEEE Trans. Biomed. Eng. 1992, 39, 791–804. [Google Scholar] [CrossRef]
- De Munck, J.C.; Van Dijk, B.W. The Spatial Distribution of Spontaneous EEG and MEG; Springer Series in Synergetics; Springer: Berlin/Heidelberg, Germany, 1999; pp. 202–228. [Google Scholar] [CrossRef]
- Huizenga, H.M.; De Munck, J.C.; Waldorp, L.J.; Grasman, R.P. Spatiotemporal EEG/MEG source analysis based on a parametric noise covariance model. IEEE Trans. Biomed. Eng. 2002, 49, 533–539. [Google Scholar] [CrossRef]
- Bijma, F.; de Munck, J.C.; Huizenga, H.M.; Heethaar, R.M. A mathematical approach to the temporal stationarity of background noise in MEG/EEG measurements. NeuroImage 2003, 20, 233–243. [Google Scholar] [CrossRef] [Green Version]
- Langville, A.N.; Stewart, W.J. The Kronecker product and stochastic automata networks. J. Comput. Appl. Math. 2004, 167, 429–447. [Google Scholar] [CrossRef]
- Loan, C.F.V. The ubiquitous Kronecker product. J. Comput. Appl. Math. 2000, 123, 85–100. [Google Scholar] [CrossRef] [Green Version]
- De Munck, J.C.; Huizenga, H.M.; Waldorp, L.J.; Heethaar, R. Estimating stationary dipoles from MEG/EEG data contaminated with spatially and temporally correlated background noise. IEEE Trans. Signal Process. 2002, 50, 1565–1572. [Google Scholar] [CrossRef]
- Beltrachini, L.; von Ellenrieder, N.; Muravchik, C.H. Shrinkage Approach for Spatiotemporal EEG Covariance Matrix Estimation. IEEE Trans. Signal Process. 2013, 61, 1797–1808. [Google Scholar] [CrossRef]
- Gonzalez-Navarro, P.; Moghadamfalahi, M.; Akcakaya, M.; Erdogmus, D. A kronecker product structured EEG covariance estimator for a language model assisted-BCI. In International Conference on Augmented Cognition; Springer: Cham, Switzerland, 2016; pp. 35–45. [Google Scholar] [CrossRef]
- Lu, N.; Zimmerman, D.L. The likelihood ratio test for a separable covariance matrix. Stat. Probab. Lett. 2005, 73, 449–457. [Google Scholar] [CrossRef]
- Werner, K.; Jansson, M.; Stoica, P. On estimation of covariance matrices with Kronecker product structure. IEEE Trans. Signal Process. 2008, 56, 478–491. [Google Scholar] [CrossRef]
- Wirfält, P.; Jansson, M. On Toeplitz and Kronecker structured covariance matrix estimation. In Proceedings of the 2010 IEEE Sensor Array and Multichannel Signal Processing Workshop, Jerusalem, Israel, 4–7 October 2010; pp. 185–188. [Google Scholar] [CrossRef] [Green Version]
- Wiesel, A. Geodesic Convexity and Covariance Estimation. IEEE Trans. Signal Process. 2012, 60, 6182–6189. [Google Scholar] [CrossRef]
- Wiesel, A. On the convexity in Kronecker structured covariance estimation. In Proceedings of the 2012 IEEE Statistical Signal Processing Workshop (SSP), Ann Arbor, MI, USA, 5–8 August 2012; pp. 880–883. [Google Scholar] [CrossRef]
- Greenewald, K.; Hero, A.O. Regularized block Toeplitz covariance matrix estimation via Kronecker product expansions. In Proceedings of the 2014 IEEE Workshop on Statistical Signal Processing (SSP), Gold Coast, Australia, 29 June–2 July 2014; pp. 9–12. [Google Scholar] [CrossRef] [Green Version]
- Breloy, A.; Sun, Y.; Babu, P.; Ginolhac, G.; Palomar, D. Robust rank constrained kronecker covariance matrix estimation. In Proceedings of the 2016 50th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 6–9 November 2016; pp. 810–814. [Google Scholar] [CrossRef]
- Xie, L.; He, Z.; Tong, J.; Liu, T.; Li, J.; Xi, J. Regularized Estimation of Kronecker-Structured Covariance Matrix. arXiv 2021, arXiv:2103.09628. [Google Scholar]
- Chen, Y.; Wiesel, A.; Hero, A. Robust Shrinkage Estimation of High-Dimensional Covariance Matrices. IEEE Trans. Signal Process. 2010, 59, 4097–4107. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gramfort, A.; Luessi, M.; Larson, E.; Engemann, D.A.; Strohmeier, D.; Brodbeck, C.; Goj, R.; Jas, M.; Brooks, T.; Parkkonen, L.; et al. MEG and EEG Data Analysis with MNE-Python. Front. Neurosci. 2013, 7, 267. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pernet, C.R.; Appelhoff, S.; Gorgolewski, K.J.; Flandin, G.; Phillips, C.; Delorme, A.; Oostenveld, R. EEG-BIDS, an extension to the brain imaging data structure for electroencephalography. Sci. Data 2019, 6, 103. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Appelhoff, S.; Sanderson, M.; Brooks, T.L.; Vliet, M.V.; Quentin, R.; Holdgraf, C.; Chaumon, M.; Mikulan, E.; Tavabi, K.; Höchenberger, R.; et al. MNE-BIDS: Organizing electrophysiological data into the BIDS format and facilitating their analysis. J. Open Source Softw. 2019, 4, 1896. [Google Scholar] [CrossRef] [Green Version]
- Barachant, A. MEG Decoding Using Riemannian Geometry and Unsupervised Classification; Grenoble University: Grenoble, France, 2014. [Google Scholar]
- Castaneda, M.H.; Nossek, J.A. Estimation of rank deficient covariance matrices with Kronecker structure. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 394–398. [Google Scholar] [CrossRef]
- Blankertz, B.; Lemm, S.; Treder, M.; Haufe, S.; Müller, K.R. Single-trial analysis and classification of ERP components—A tutorial. NeuroImage 2011, 56, 814–825. [Google Scholar] [CrossRef]
- Raudys, S.; Duin, R.P.W. Expected classification error of the Fisher linear classifier with pseudo-inverse covariance matrix. Pattern Recognit. Lett. 1998, 19, 385–392. [Google Scholar] [CrossRef]
- Schäfer, J.; Strimmer, K. An empirical Bayes approach to inferring large-scale gene association networks. Bioinformatics 2004, 21, 754–764. [Google Scholar] [CrossRef]
- Kraemer, N. On the Peaking Phenomenon of the Lasso in Model Selection. arXiv 2009, arXiv:0904.4416. [Google Scholar]
- Haufe, S.; Meinecke, F.; Görgen, K.; Dähne, S.; Haynes, J.D.; Blankertz, B.; Bießmann, F. On the interpretation of weight vectors of linear models in multivariate neuroimaging. NeuroImage 2014, 87, 96–110. [Google Scholar] [CrossRef] [Green Version]
- Treder, M.S.; Blankertz, B. (C)overt attention and visual speller design in an ERP-based brain-computer interface. Behav. Brain Funct. 2010, 6, 28. [Google Scholar] [CrossRef] [PubMed] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 Trial | Nb. of Training Blocks | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| stbf-struct > stbf-shrunk | – | – | |||||||
| stbf-struct > stbf-emp | < | < | < | < | < | < | < | < | < |
| stbf-struct > xdawn+rg | < | < | < | < | < | < | < | ||
| stbf-shrunk > stbf-emp | < | < | < | < | < | < | < | < | < |
| stbf-shrunk > xdawn+rg | – | < | < | < | < | ||||
| 2 Trials | Nb. of Training Blocks | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| stbf-struct > stbf-shrunk | – | – | |||||||
| stbf-struct > stbf-emp | < | < | < | < | < | < | < | < | < |
| stbf-struct > xdawn+rg | < | < | < | < | < | < | < | ||
| stbf-shrunk > stbf-emp | < | < | < | < | < | < | < | < | < |
| stbf-shrunk > xdawn+rg | – | – | < | < | < | < | |||
| 5 Trials | Nb. of Training Blocks | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| stbf-struct > stbf-shrunk | – | – | |||||||
| stbf-struct > stbf-emp | < | < | < | < | < | < | < | < | < |
| stbf-struct > xdawn+rg | < | < | < | < | < | ||||
| stbf-shrunk > stbf-emp | < | < | < | < | < | < | < | < | < |
| stbf-shrunk > xdawn+rg | – | < | < | < | < | < | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Van Den Kerchove, A.; Libert, A.; Wittevrongel, B.; Van Hulle, M.M. Classification of Event-Related Potentials with Regularized Spatiotemporal LCMV Beamforming. Appl. Sci. 2022, 12, 2918. https://doi.org/10.3390/app12062918
Van Den Kerchove A, Libert A, Wittevrongel B, Van Hulle MM. Classification of Event-Related Potentials with Regularized Spatiotemporal LCMV Beamforming. Applied Sciences. 2022; 12(6):2918. https://doi.org/10.3390/app12062918
Chicago/Turabian StyleVan Den Kerchove, Arne, Arno Libert, Benjamin Wittevrongel, and Marc M. Van Hulle. 2022. "Classification of Event-Related Potentials with Regularized Spatiotemporal LCMV Beamforming" Applied Sciences 12, no. 6: 2918. https://doi.org/10.3390/app12062918
APA StyleVan Den Kerchove, A., Libert, A., Wittevrongel, B., & Van Hulle, M. M. (2022). Classification of Event-Related Potentials with Regularized Spatiotemporal LCMV Beamforming. Applied Sciences, 12(6), 2918. https://doi.org/10.3390/app12062918