
DFDT: An End-to-End DeepFake Detection Framework Using Vision Transformer


Abstract
:1. Introduction
- An end-to-end deepfake detection framework, DFDT, is developed leveraging the unique characteristics of transformer models on learning hidden traces of perturbations from both local image features and global relationship of pixels at different forgery scales.
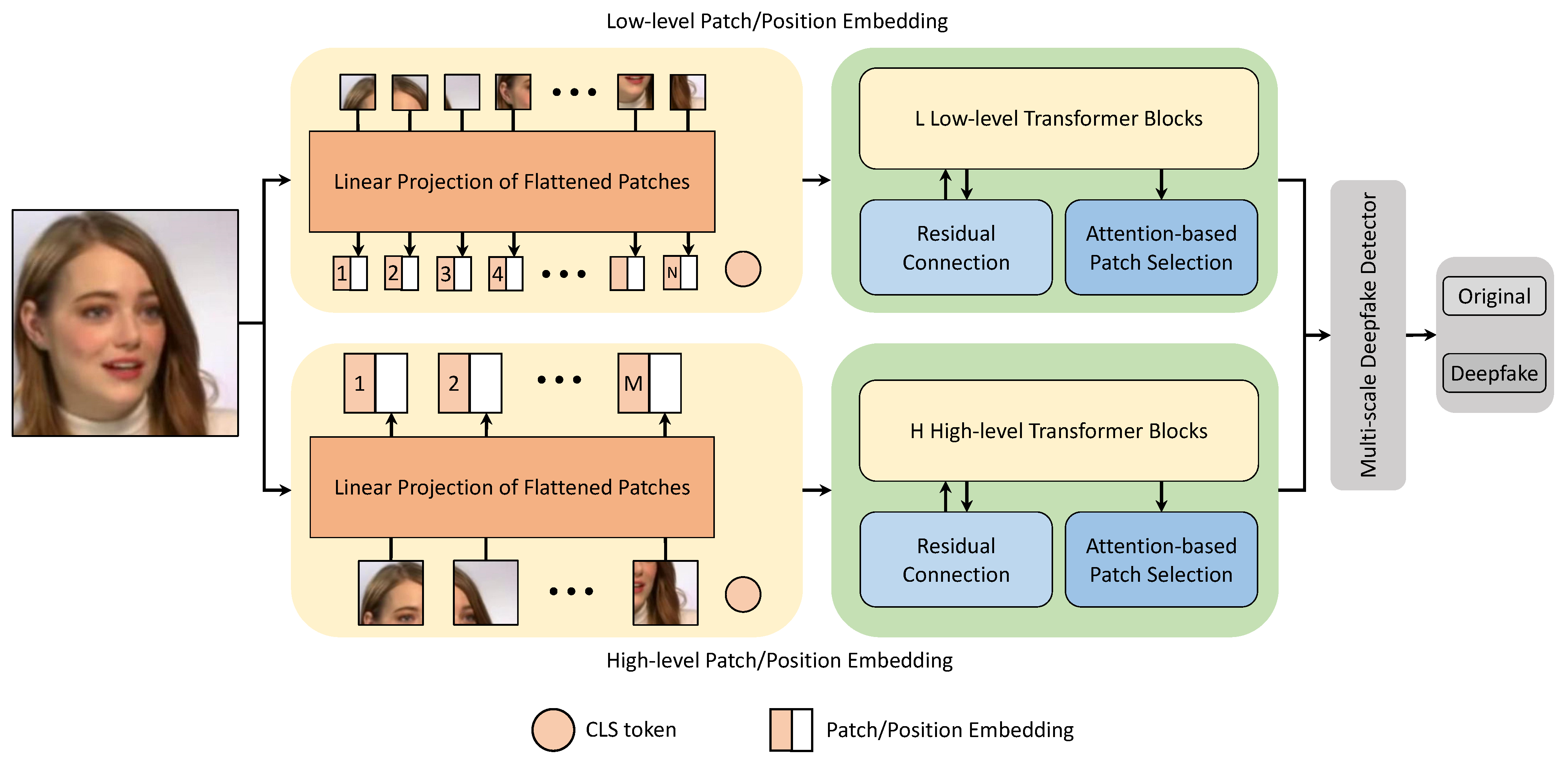
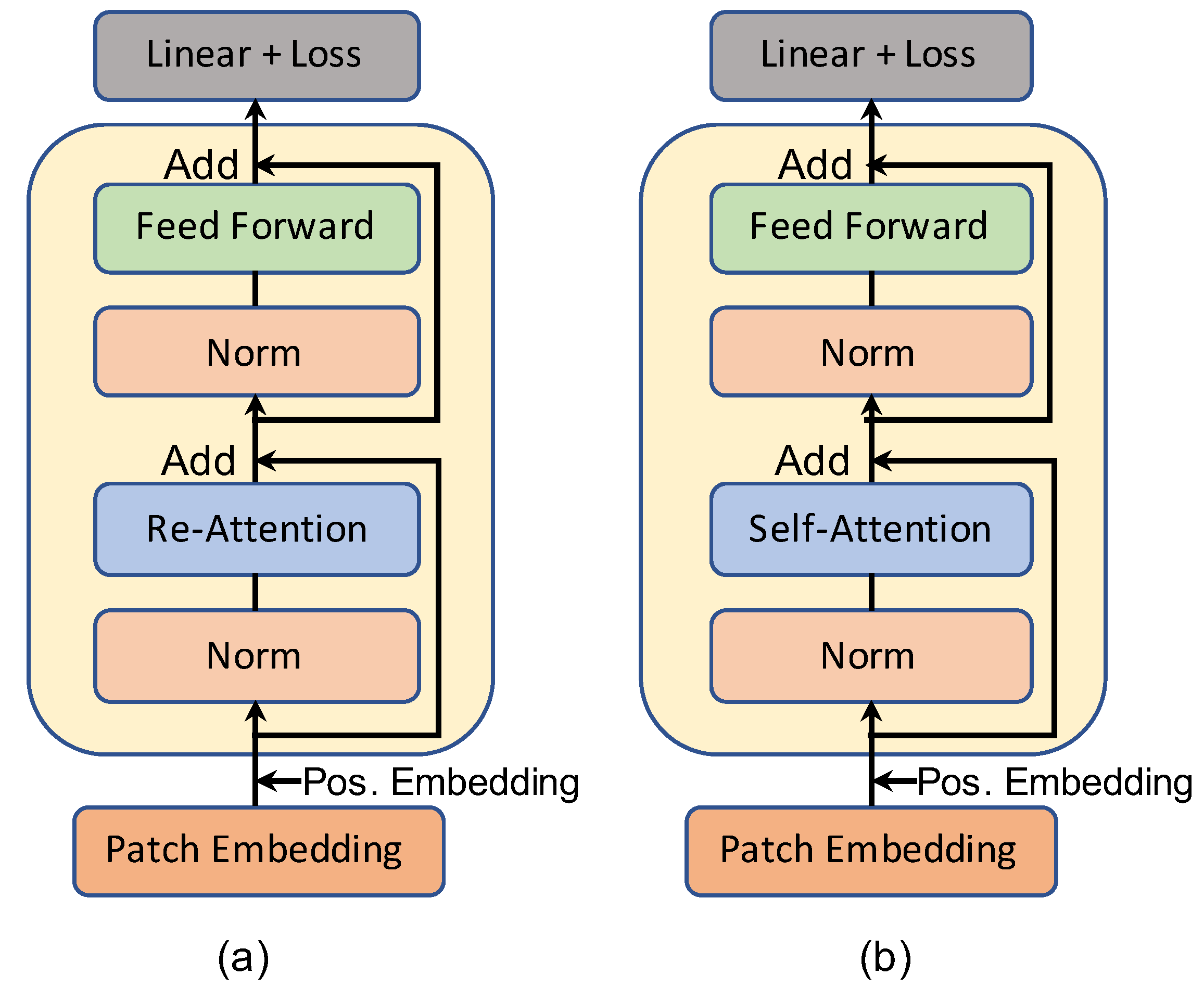
- DFDT is designed explicitly for deepfake detection tasks. DFDT comprises four main components, including patch extraction & embedding, multi-stream transformer block, attention-based patch selection followed by a multi-scale classifier. DFDT’s transformer layer benefits from the re-attention mechanism instead of the traditional multi-head self-attention layer.
- A comprehensive set of experiments are conducted on seven deepfake forensics benchmarks to evaluate the performance of the DFDT. Experimental results demonstrated the surpassing detection rate of the DFDT, achieving 99.41%, 99.31%, and 81.35% on FaceForensics++, Celeb-DF (V2), and WildDeepfake, respectively. Moreover, DFDT’s excellent cross-dataset & cross-manipulation generalization provides additional strong evidence on its effectiveness.
2. Related Work
3. Methodology
3.1. Patch Extraction & Embedding
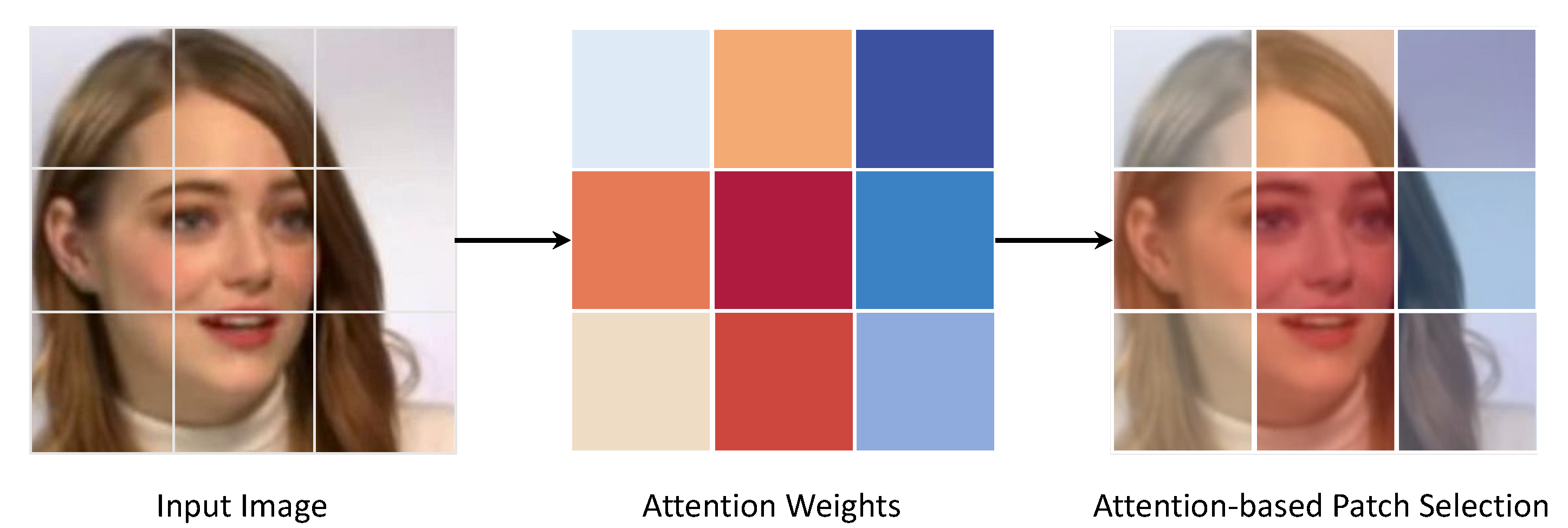
3.2. Attention-Based Patch Selection
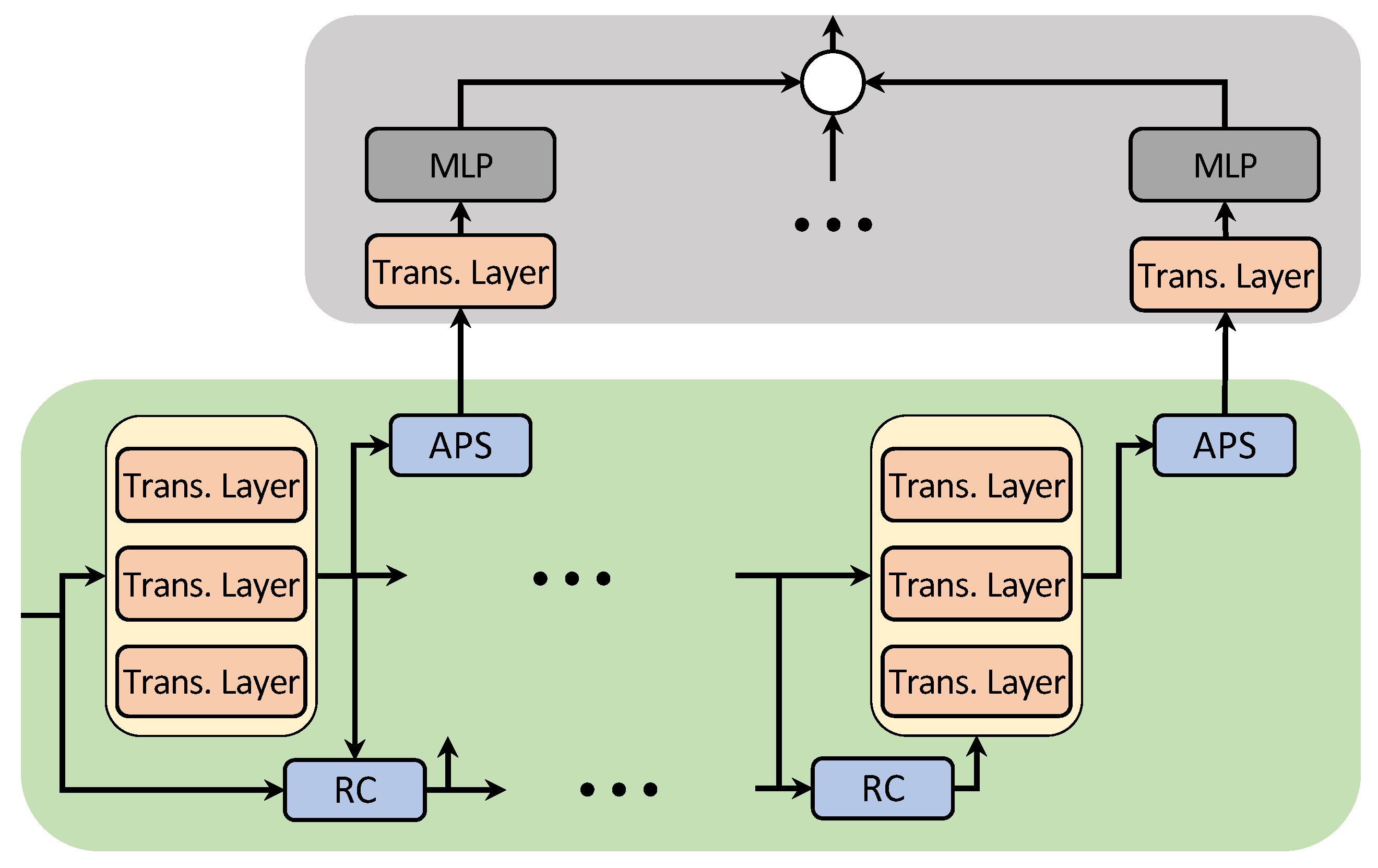
3.3. Multi-Stream Transformer Block
3.4. Multi-Scale Deepfake Detector
4. Evaluation Settings
4.1. Datasets
4.2. Implementation Specifics
4.3. Evaluation Metrics
5. Results & Discussion
5.1. Intra-Dataset Evaluation
5.2. Cross-Dataset Generalization
5.3. Cross-Manipulation Generalization
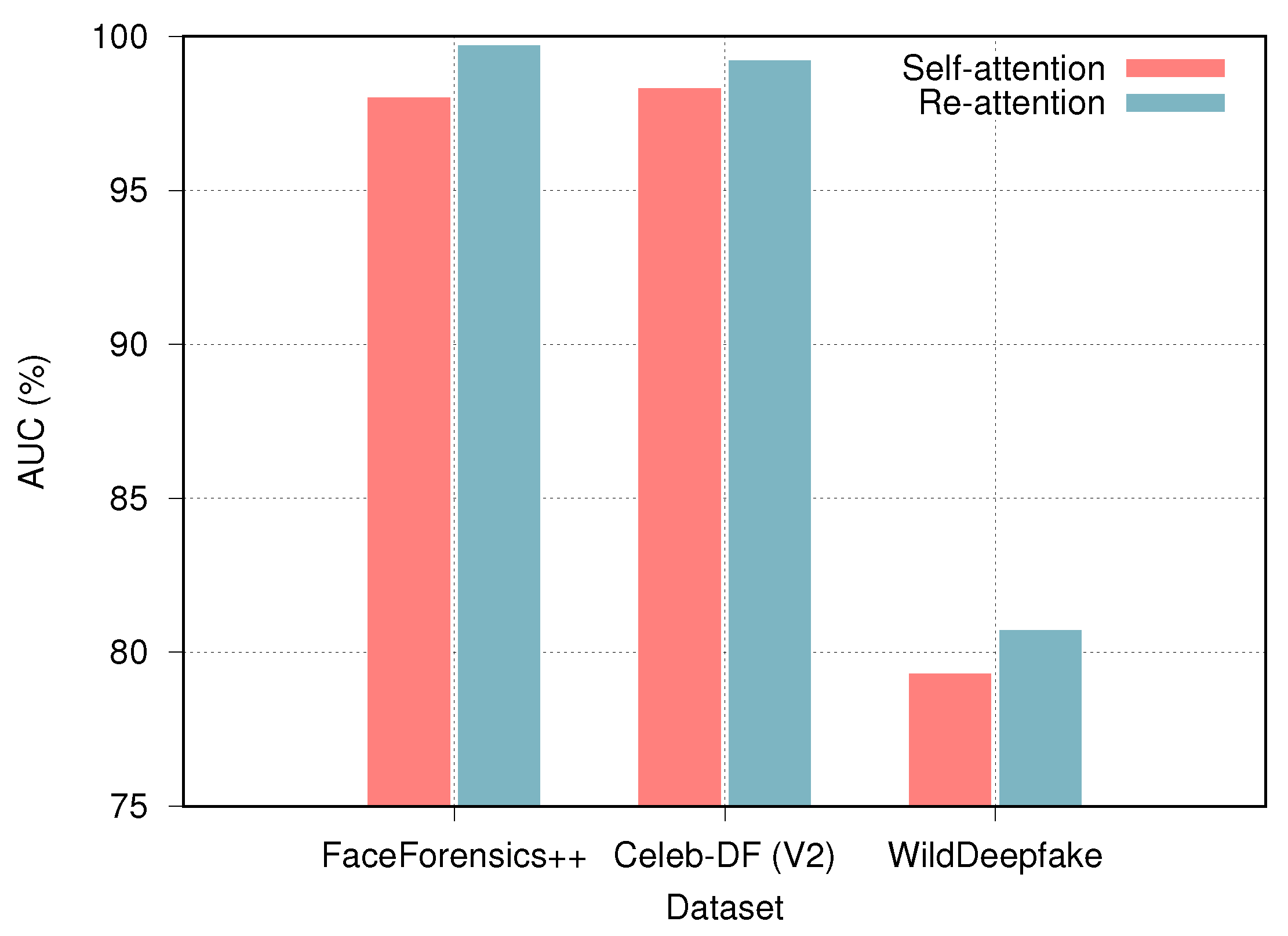
5.4. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. Available online: https://arxiv.org/abs/1406.2661 (accessed on 7 February 2022).
- Antipov, G.; Baccouche, M.; Dugelay, J.L. Face aging with conditional generative adversarial networks. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2089–2093. [Google Scholar]
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June 26–1July 2016; pp. 2387–2395. [Google Scholar]
- Maras, M.H.; Alexandrou, A. Determining authenticity of video evidence in the age of artificial intelligence and in the wake of Deepfake videos. Int. J. Evid. Proof 2019, 23, 255–262. [Google Scholar] [CrossRef]
- Vaccari, C.; Chadwick, A. Deepfakes and disinformation: Exploring the impact of synthetic political video on deception, uncertainty, and trust in news. Soc. Media+ Soc. 2020, 6, 2056305120903408. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.S.; Rouhsedaghat, M.; Ghani, H.; Hu, S.; You, S.; Kuo, C.C.J. DefakeHop: A Light-Weight High-Performance Deepfake Detector. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Virtual, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Tran, V.N.; Lee, S.H.; Le, H.S.; Kwon, K.R. High Performance deepfake video detection on CNN-based with attention target-specific regions and manual distillation extraction. Appl. Sci. 2021, 11, 7678. [Google Scholar] [CrossRef]
- Shelke, N.A.; Kasana, S.S. A comprehensive survey on passive techniques for digital video forgery detection. Multimed. Tools Appl. 2020, 80, 6247–6310. [Google Scholar] [CrossRef]
- Mirsky, Y.; Lee, W. The creation and detection of deepfakes: A survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–41. [Google Scholar] [CrossRef]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8261–8265. [Google Scholar]
- Li, Y.; Chang, M.C.; Lyu, S. In ictu oculi: Exposing ai created fake videos by detecting eye blinking. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Li, Y.; Lyu, S. Exposing DeepFake Videos By Detecting Face Warping Artifacts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 46–52. [Google Scholar]
- Du, M.; Pentyala, S.; Li, Y.; Hu, X. Towards Generalizable Deepfake Detection with Locality-aware AutoEncoder. In Proceedings of the 29th ACM International Conference on Information &Knowledge Management, Virtual, 19–23 October 2020; pp. 325–334. [Google Scholar]
- Jain, A.; Majumdar, P.; Singh, R.; Vatsa, M. Detecting GANs and retouching based digital alterations via DAD-HCNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 672–673. [Google Scholar]
- Ciftci, U.A.; Demir, I.; Yin, L. Fakecatcher: Detection of synthetic portrait videos using biological signals. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2307–2311. [Google Scholar]
- Haliassos, A.; Vougioukas, K.; Petridis, S.; Pantic, M. Lips Don’t Lie: A Generalisable and Robust Approach To Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 5039–5049. [Google Scholar]
- Khormali, A.; Yuan, J.S. ADD: Attention-Based DeepFake Detection Approach. Big Data Cogn. Comput. 2021, 5, 49. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations, Virtual, 26 April–1 May 2020. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual, 26 April–1 May 2020. [Google Scholar]
- Heo, Y.J.; Choi, Y.J.; Lee, Y.W.; Kim, B.G. Deepfake Detection Scheme Based on Vision Transformer and Distillation. arXiv 2021, arXiv:2104.01353. [Google Scholar]
- Wodajo, D.; Atnafu, S. Deepfake Video Detection Using Convolutional Vision Transformer. arXiv 2021, arXiv:2102.11126. [Google Scholar]
- Faceswap. Faceswap: Deepfakes Software for All. Available online: https://github.com/deepfakes/faceswap (accessed on 7 February 2022).
- FakeApp. FakeApp 2.2.0-Download for PC Free. Available online: https://www.malavida.com/en/soft/fakeapp/ (accessed on 7 February 2022).
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1857–1865. [Google Scholar]
- Lu, Y.; Tai, Y.W.; Tang, C.K. Attribute-guided face generation using conditional cyclegan. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 282–297. [Google Scholar]
- Kim, H.; Garrido, P.; Tewari, A.; Xu, W.; Thies, J.; Niessner, M.; Pérez, P.; Richardt, C.; Zollhöfer, M.; Theobalt, C. Deep video portraits. ACM Trans. Graph. (TOG) 2018, 37, 1–14. [Google Scholar] [CrossRef]
- Li, L.; Bao, J.; Yang, H.; Chen, D.; Wen, F. Faceshifter: Towards high fidelity and occlusion aware face swapping. arXiv 2019, arXiv:1912.13457. [Google Scholar]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 83–92. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Cozzolino, D.; Thies, J.; Rössler, A.; Riess, C.; Nießner, M.; Verdoliva, L. Forensictransfer: Weakly-supervised domain adaptation for forgery detection. arXiv 2018, arXiv:1812.02510. [Google Scholar]
- Rana, M.S.; Sung, A.H. Deepfakestack: A deep ensemble-based learning technique for deepfake detection. In Proceedings of the 2020 7th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2020 6th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), New York, NY, USA, 1–3 August 2020; pp. 70–75. [Google Scholar]
- Kaur, S.; Kumar, P.; Kumaraguru, P. Deepfakes: Temporal sequential analysis to detect face-swapped video clips using convolutional long short-term memory. J. Electron. Imaging 2020, 29, 033013. [Google Scholar] [CrossRef]
- Wang, S.Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-generated images are surprisingly easy to spot... for now. In In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 8695–8704. [Google Scholar]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. Emotions Don’t Lie: An Audio-Visual Deepfake Detection Method using Affective Cues. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 2–16 October 2020; pp. 2823–2832. [Google Scholar]
- Quan, R.; Wu, Y.; Yu, X.; Yang, Y. Progressive transfer learning for face anti-spoofing. IEEE Trans. Image Process. 2021, 30, 3946–3955. [Google Scholar] [CrossRef]
- Floridi, L.; Chiriatti, M. GPT-3: Its nature, scope, limits, and consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Yang, F.; Zhai, Q.; Li, X.; Huang, R.; Luo, A.; Cheng, H.; Fan, D.P. Uncertainty-guided transformer reasoning for camouflaged object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4146–4155. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Khan, S.A.; Dai, H. Video Transformer for Deepfake Detection with Incremental Learning. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021; pp. 1821–1828. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1–11. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5203–5212. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Abnar, S.; Zuidema, W. Quantifying attention flow in transformers. arXiv 2020, arXiv:2005.00928. [Google Scholar]
- He, J.; Chen, J.N.; Liu, S.; Kortylewski, A.; Yang, C.; Bai, Y.; Wang, C.; Yuille, A. TransFG: A Transformer Architecture for Fine-grained Recognition. arXiv 2021, arXiv:2103.07976. [Google Scholar]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards deeper vision transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Li, Y.; Sun, P.; Qi, H.; Lyu, S. Celeb-DF: A Large-scale Challenging Dataset for DeepFake Forensics. In Proceedings of the IEEE Conference on Computer Vision and Patten Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zi, B.; Chang, M.; Chen, J.; Ma, X.; Jiang, Y.G. WildDeepfake: A Challenging Real-World Dataset for Deepfake Detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2382–2390. [Google Scholar]
- Jiang, L.; Li, R.; Wu, W.; Qian, C.; Loy, C.C. Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2889–2898. [Google Scholar]
- Dolhansky, B.; Howes, R.; Pflaum, B.; Baram, N.; Ferrer, C.C. The deepfake detection challenge (dfdc) preview dataset. arXiv 2019, arXiv:1910.08854. [Google Scholar]
- Faceswap. Faceswap. Available online: https://github.com/MarekKowalski/FaceSwap/ (accessed on 7 February 2022).
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Wang, J.; Wu, Z.; Chen, J.; Jiang, Y.G. M2TR: Multi-modal Multi-scale Transformers for Deepfake Detection. arXiv 2021, arXiv:2104.09770. [Google Scholar]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-attentional deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2185–2194. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Two-stream neural networks for tampered face detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1839. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representation, Lisbon, Portugal, 1–15 September 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2016; pp. 630–645. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Nguyen, H.H.; Fang, F.; Yamagishi, J.; Echizen, I. Multi-task Learning for Detecting and Segmenting Manipulated Facial Images and Videos. In Proceedings of the 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems (BTAS), Tampa, FL, USA, 23–26 September 2019; pp. 1–8. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Use of a capsule network to detect fake images and videos. arXiv 2019, arXiv:1910.12467. [Google Scholar]
- Masi, I.; Killekar, A.; Mascarenhas, R.M.; Gurudatt, S.P.; AbdAlmageed, W. Two-branch recurrent network for isolating deepfakes in videos. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 667–684. [Google Scholar]
- Liu, H.; Li, X.; Zhou, W.; Chen, Y.; He, Y.; Xue, H.; Zhang, W.; Yu, N. Spatial-phase shallow learning: Rethinking face forgery detection in frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 772–781. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face X-ray for more general face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5001–5010. [Google Scholar]
- Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in frequency: Face forgery detection by mining frequency-aware clues. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 86–103. [Google Scholar]
- Güera, D.; Delp, E.J. Deepfake video detection using recurrent neural networks. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Charitidis, P.; Kordopatis-Zilos, G.; Papadopoulos, S.; Kompatsiaris, I. Investigating the Impact of Pre-processing and Prediction Aggregation on the DeepFake Detection Task. In Proceedings of the Truth and Trust Conference, Virtual, 16–17 October 2020. [Google Scholar]
- Chai, L.; Bau, D.; Lim, S.N.; Isola, P. What makes fake images detectable understanding properties that generalize. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 103–120. [Google Scholar]
- Sabir, E.; Cheng, J.; Jaiswal, A.; AbdAlmageed, W.; Masi, I.; Natarajan, P. Recurrent convolutional strategies for face manipulation detection in videos. Interfaces (GUI) 2019, 3, 80–87. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Statistics | Source | |||||
|---|---|---|---|---|---|---|---|
| Videos | Frames | Train | Test | Val. | |||
| FaceForensics++ [49] | Real | 1000 | 509.9 K | 800 | 100 | 100 | YouTube |
| Deepfake | 4000 | 1830.1 K | 3200 | 400 | 400 | DF | |
| Celeb-DF (V2) [55] | Real | 590 (+300) 1 | 225.4 K | 632 | 62 | 196 | YouTube |
| Deepfake | 5639 | 2116.8 K | 4736 | 536 | 340 | DF | |
| WildDeepfake [56] | Real | 3805 | 680 K | 3044 | 380 | 381 | Internet |
| Deepfake | 3509 | 500 K | 2807 | 350 | 351 | Internet | |
| Dataset ↓ Metrics | ACC (%) | AUC (%) | |
|---|---|---|---|
| FaceForensics++ | (LQ) | 93.67 | 94.48 |
| (HQ) | 98.18 | 99.26 | |
| (Raw) | 99.41 | 99.94 | |
| Celeb-DF (V2) | 99.31 | 99.26 | |
| WildDeepfake | 81.35 | 80.74 | |
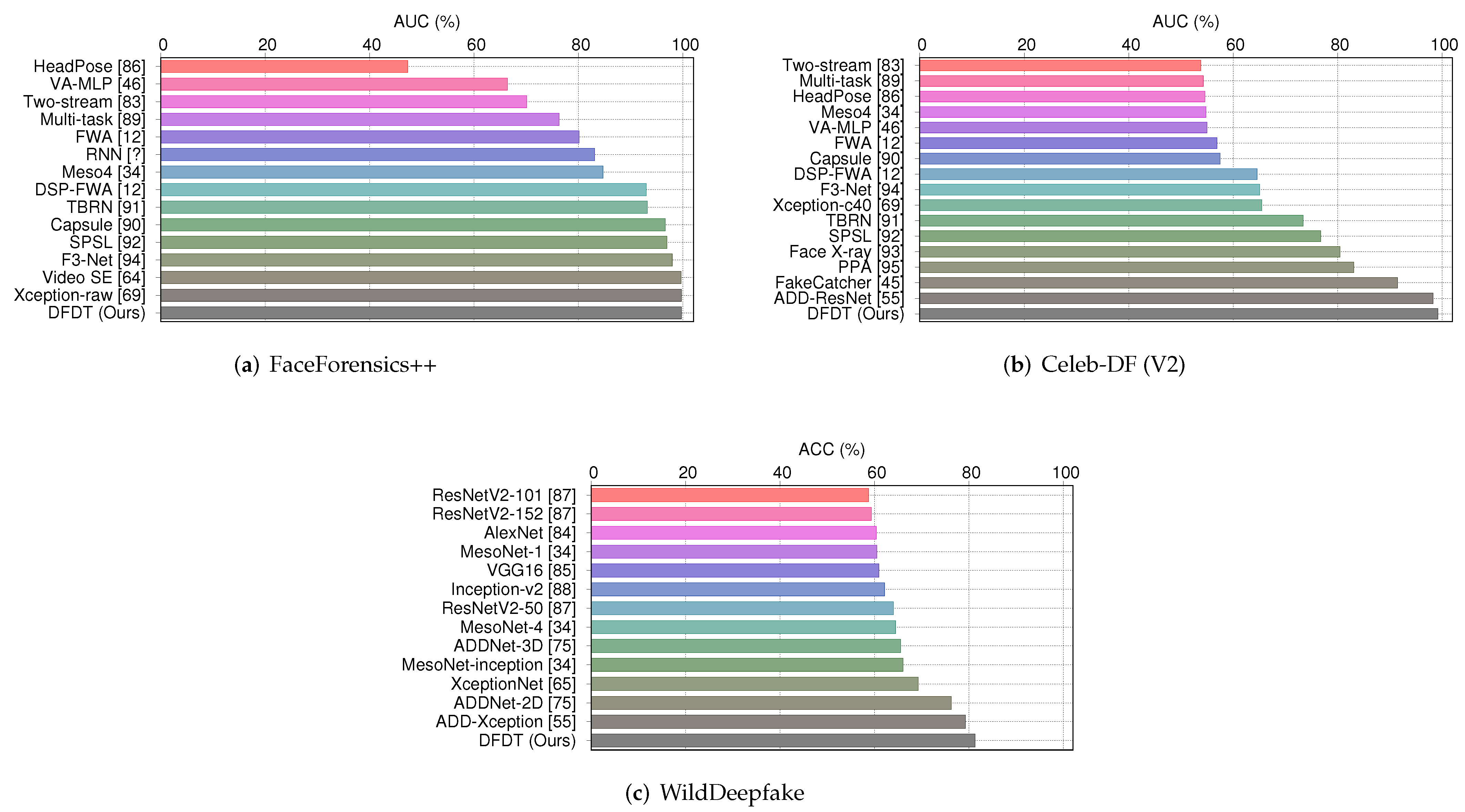
| Methods ↓ | FaceForensics++ | Methods ↓ | Celeb-DF (V2) | Methods ↓ | WideDeepfake |
|---|---|---|---|---|---|
| AUC (%) | AUC (%) | (AR %) | |||
| Two-stream [63] | 70.1 | Two-stream [63] | 53.8 | AlexNet [64] | 60.37 |
| Meso4 [35] | 84.7 | Meso4 [35] | 54.8 | VGG16 [65] | 60.92 |
| HeadPose [10] | 47.3 | HeadPose [10] | 54.6 | ResNetV2-50 [66] | 63.99 |
| FWA [12] | 80.1 | FWA [12] | 56.9 | ResNetV2-101 [66] | 58.73 |
| VA-MLP [34] | 66.4 | VA-MLP [34] | 55.0 | ResNetV2-152 [66] | 59.33 |
| Xception-raw [49] | 99.7 | Xception-c40 [49] | 65.5 | Inception-v2 [67] | 62.12 |
| Multi-task [68] | 76.3 | Multi-task [68] | 54.3 | MesoNet-1 [35] | 60.51 |
| Capsule [69] | 96.6 | Capsule [69] | 57.5 | MesoNet-4 [35] | 64.47 |
| DSP-FWA [12] | 93 | DSP-FWA [12] | 64.6 | MesoNet-inception [35] | 66.03 |
| TBRN [70] | 93.2 | TBRN [70] | 73.4 | XceptionNet [47] | 69.25 |
| SPSL [71] | 96.94 | Face X-ray [72] | 80.5 | ADDNet-2D [56] | 76.25 |
| F3-Net [73] | 97.97 | SPSL [71] | 76.8 | ADDNet-3D [56] | 65.5 |
| Video SE [46] | 99.64 | F3-Net [73] | 65.1 | ADD-Xception [18] | 79.23 |
| RNN [74] | 83.10 | PPA [75] | 83.1 | ||
| DefakeHop [6] | 90.5 | ||||
| FakeCatcher [15] | 91.5 | ||||
| ATS-DE [7] | 97.8 | ||||
| ADD-ResNet [18] | 98.3 | ||||
| DFDT (Ours) | 99.7 | DFDT (Ours) | 99.2 | DFDT (Ours) | 81.3 |
| Methods ↓ | Celeb-DF | DFDC | FaceShifter | DeeperForensics | Avg |
|---|---|---|---|---|---|
| Xception [49] | 73.7 | 70.9 | 72 | 84.5 | 75.3 |
| CNN-aug [39] | 75.6 | 72.1 | 65.7 | 74.4 | 72 |
| Patch-based [76] | 69.6 | 65.6 | 57.8 | 81.8 | 68.7 |
| Face X-Ray [72] | 79.5 | 65.5 | 92.8 | 86.8 | 81.2 |
| CNN-GRU [77] | 69.8 | 68.9 | 80.8 | 74.1 | 73.4 |
| Multi-task [68] | 75.7 | 68.1 | 66 | 77.7 | 71.9 |
| DSP-FWA [12] | 69.5 | 67.3 | 65.5 | 50.2 | 63.1 |
| Two-branch [70] | 76.7 | - | - | - | - |
| LipForensics [17] | 82.4 | 73.5 | 97.1 | 97.6 | 87.8 |
| DFDT (Ours) | 88.3 | 76.1 | 97.8 | 96.9 | 89.7 |
| Methods ↓ | Train DFDT on Other Three Subsets | Avg. | |||
|---|---|---|---|---|---|
| Deepfakes | FaceSwap | Face2Face | NeuralTextures | ||
| Xception [49] | 93.9 | 51.2 | 86.8 | 79.7 | 77.9 |
| CNN-aug [39] | 87.5 | 56.3 | 80.1 | 67.8 | 72.9 |
| Patch-based [76] | 94 | 60.5 | 87.3 | 84.8 | 81.7 |
| Face X-ray [72] | 99.5 | 93.2 | 94.5 | 92.5 | 94.9 |
| CNN-GRU [77] | 97.6 | 47.6 | 85.8 | 86.6 | 79.4 |
| LipForensics [17] | 99.7 | 90.1 | 99.7 | 99.1 | 97.1 |
| DFDT (Ours) | 99.8 | 93.1 | 99.6 | 99.2 | 97.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khormali, A.; Yuan, J.-S. DFDT: An End-to-End DeepFake Detection Framework Using Vision Transformer. Appl. Sci. 2022, 12, 2953. https://doi.org/10.3390/app12062953
Khormali A, Yuan J-S. DFDT: An End-to-End DeepFake Detection Framework Using Vision Transformer. Applied Sciences. 2022; 12(6):2953. https://doi.org/10.3390/app12062953
Chicago/Turabian StyleKhormali, Aminollah, and Jiann-Shiun Yuan. 2022. "DFDT: An End-to-End DeepFake Detection Framework Using Vision Transformer" Applied Sciences 12, no. 6: 2953. https://doi.org/10.3390/app12062953
APA StyleKhormali, A., & Yuan, J. -S. (2022). DFDT: An End-to-End DeepFake Detection Framework Using Vision Transformer. Applied Sciences, 12(6), 2953. https://doi.org/10.3390/app12062953