
Deep Deterministic Policy Gradient with Reward Function Based on Fuzzy Logic for Robotic Peg-in-Hole Assembly Tasks


Abstract
:1. Introduction
- (1)
- The reward function with fuzzy logic based on assembly quality evaluation was designed in the actual industrial environment to improve the system learning performance;
- (2)
- The assembly process model was constructed and the robot completed the stiffness workpieces assembly;
- (3)
- The robot combined with the variable impedance in the course of operation to avoid the damage of the workpiece during the learning process;
- (4)
- A framework of learning robot assembly skills is proposed, and it is verified in the peg-in-hole assembly of weak stiffness workpieces.
- (5)
- The proposed method in this paper combines deep reinforcement learning with robotics technology, which provides theoretical support for the improvement of complex manipulation skills of a new generation of robots. It also provides a new idea for the application of artificial intelligence algorithms in the industrial field.
2. Related Work
3. Problem Formulation
4. Method
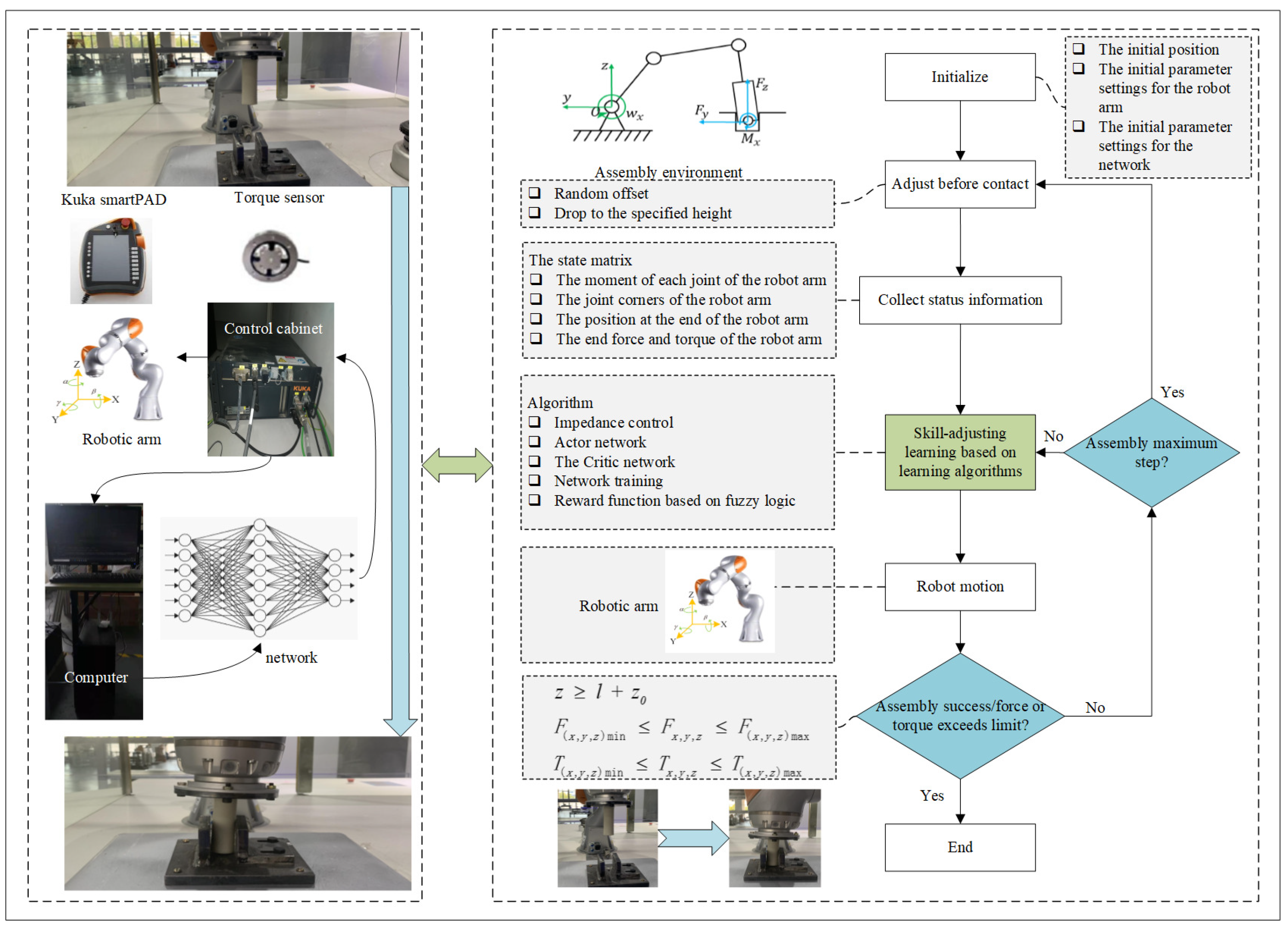
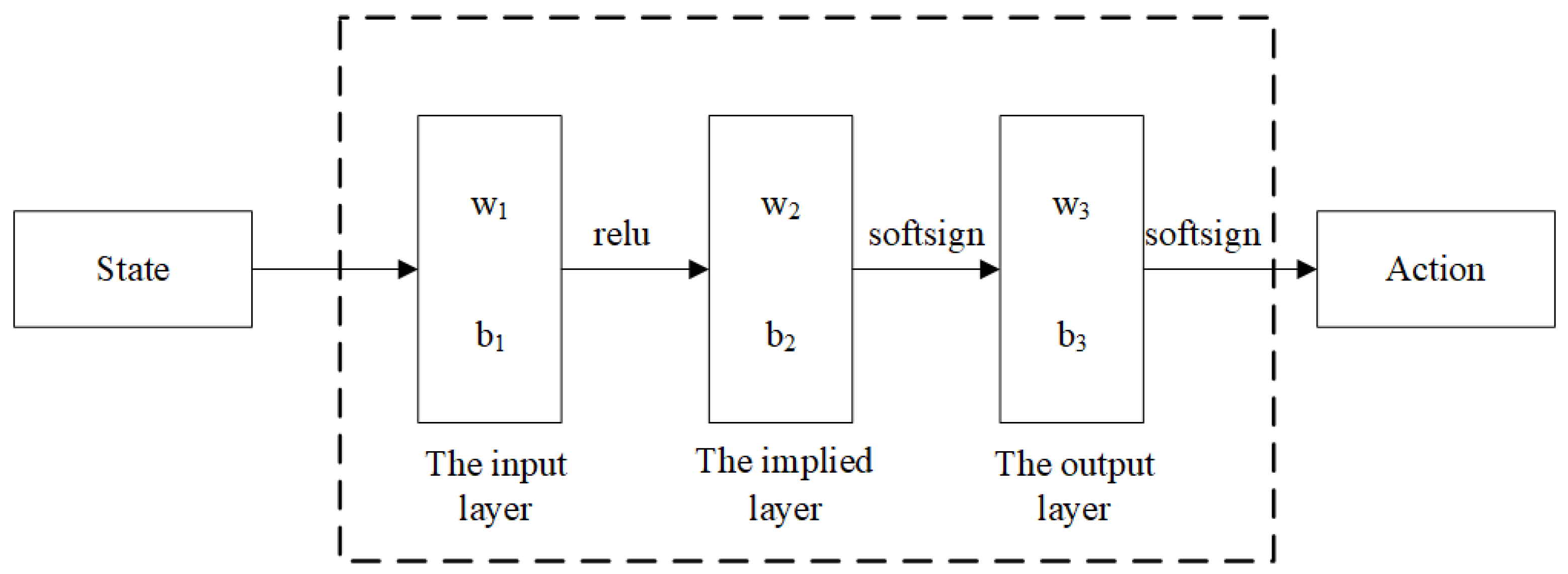
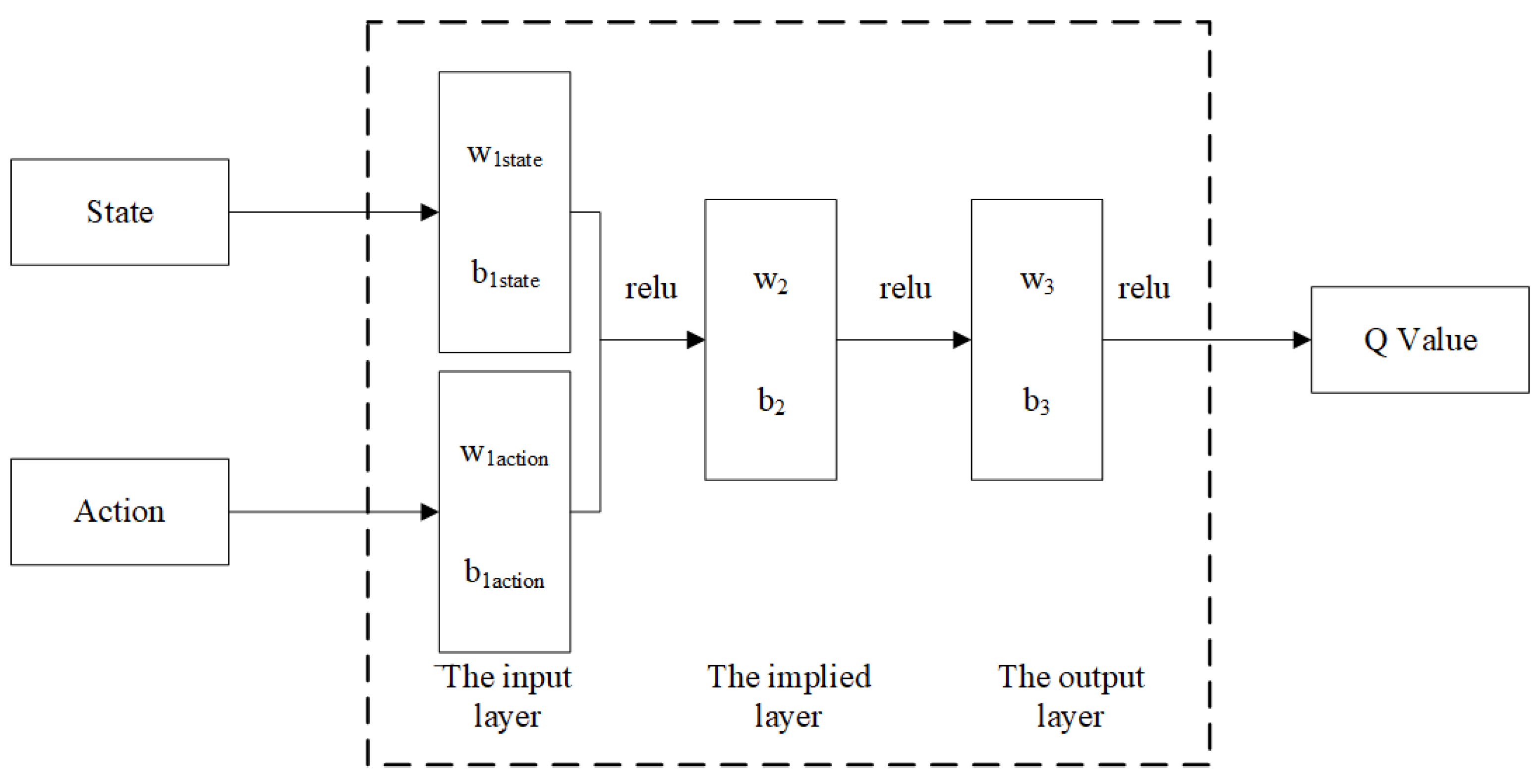
4.1. Assembly Policy Learning
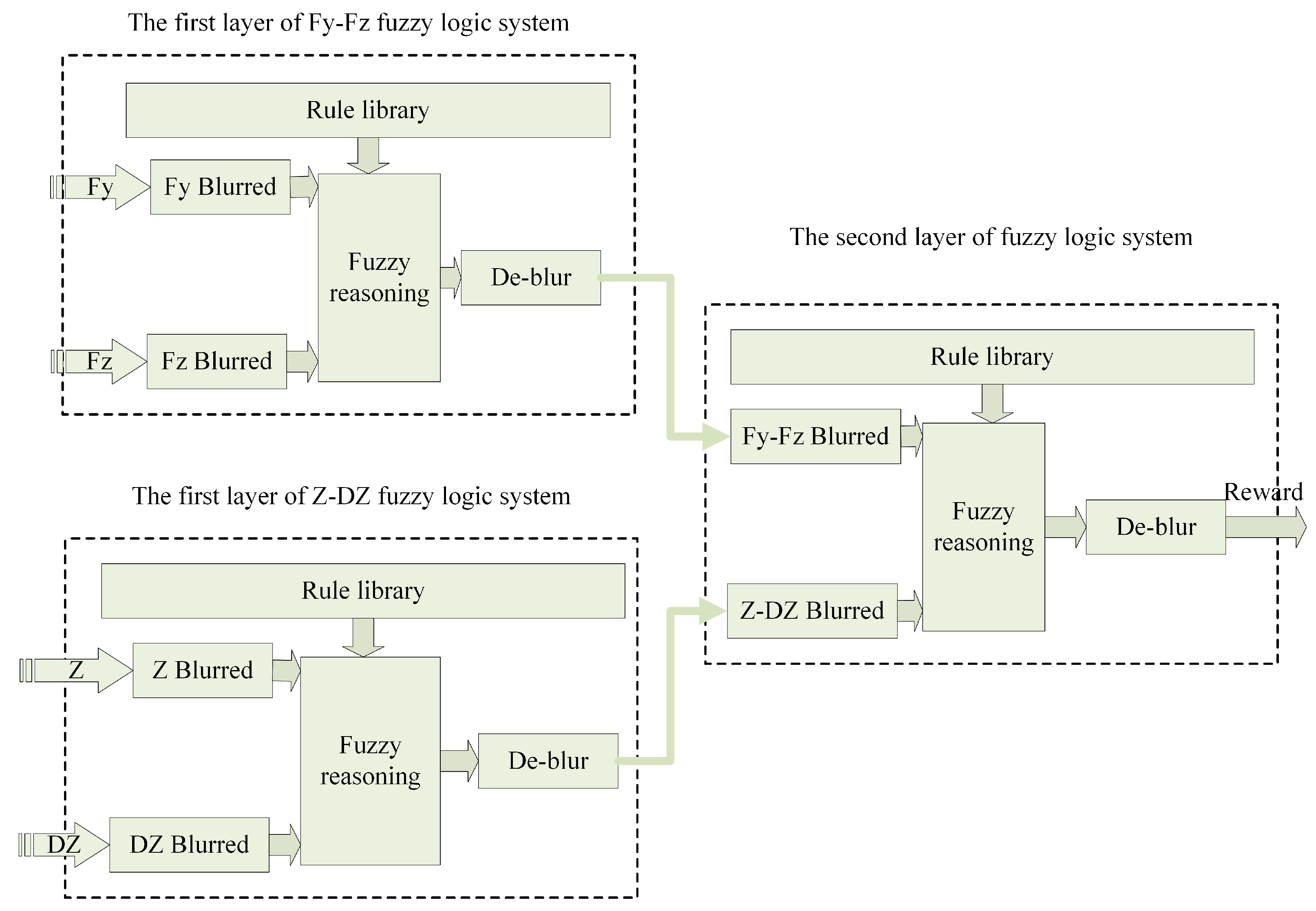
4.2. Reward Function
4.3. Network Training
4.4. Algorithm Pseudocode
| Algorithm 1 Fuzzy Rewards—DDPG Algorithm |
|
5. Experiments
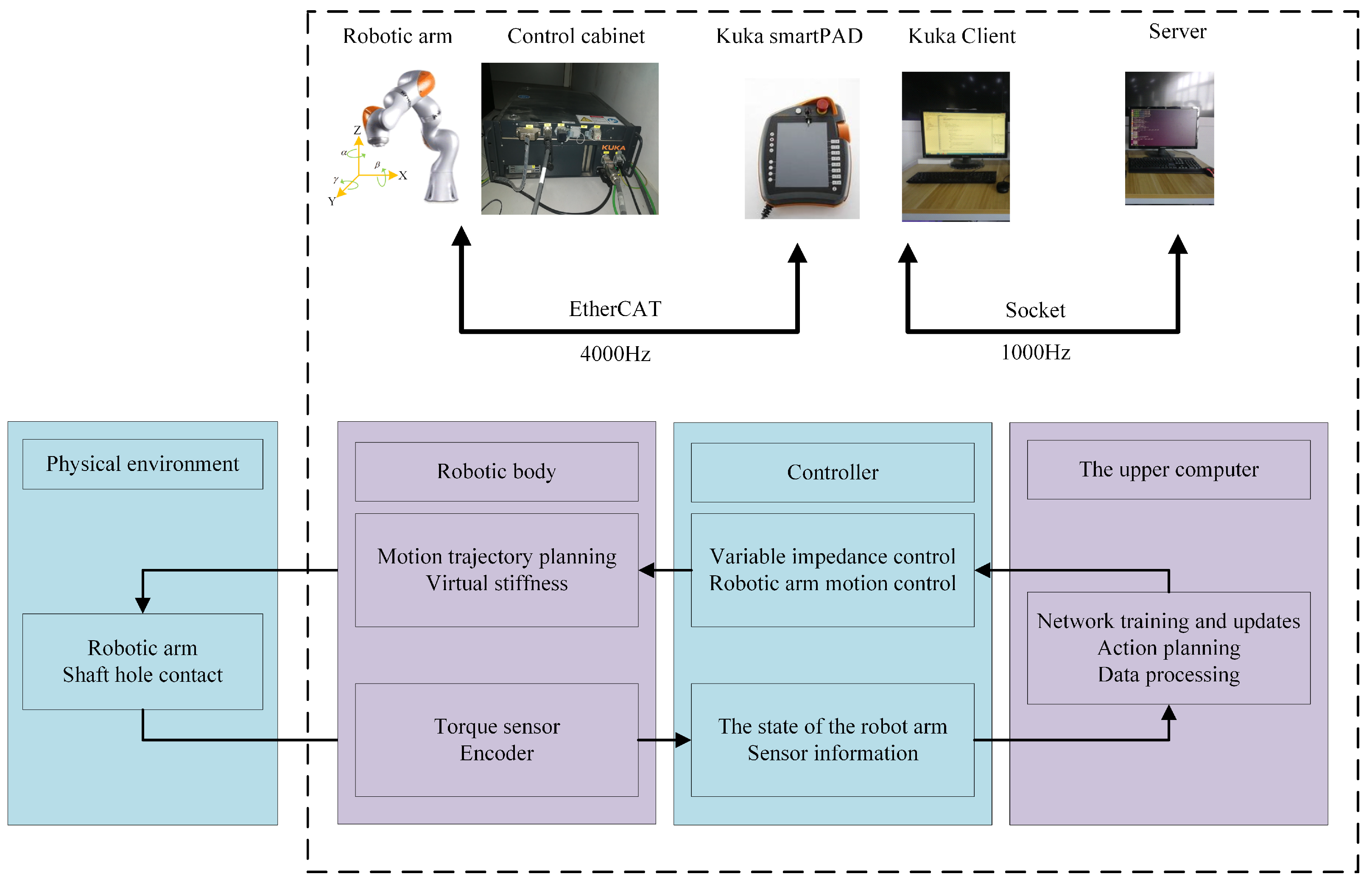
5.1. Platform Building
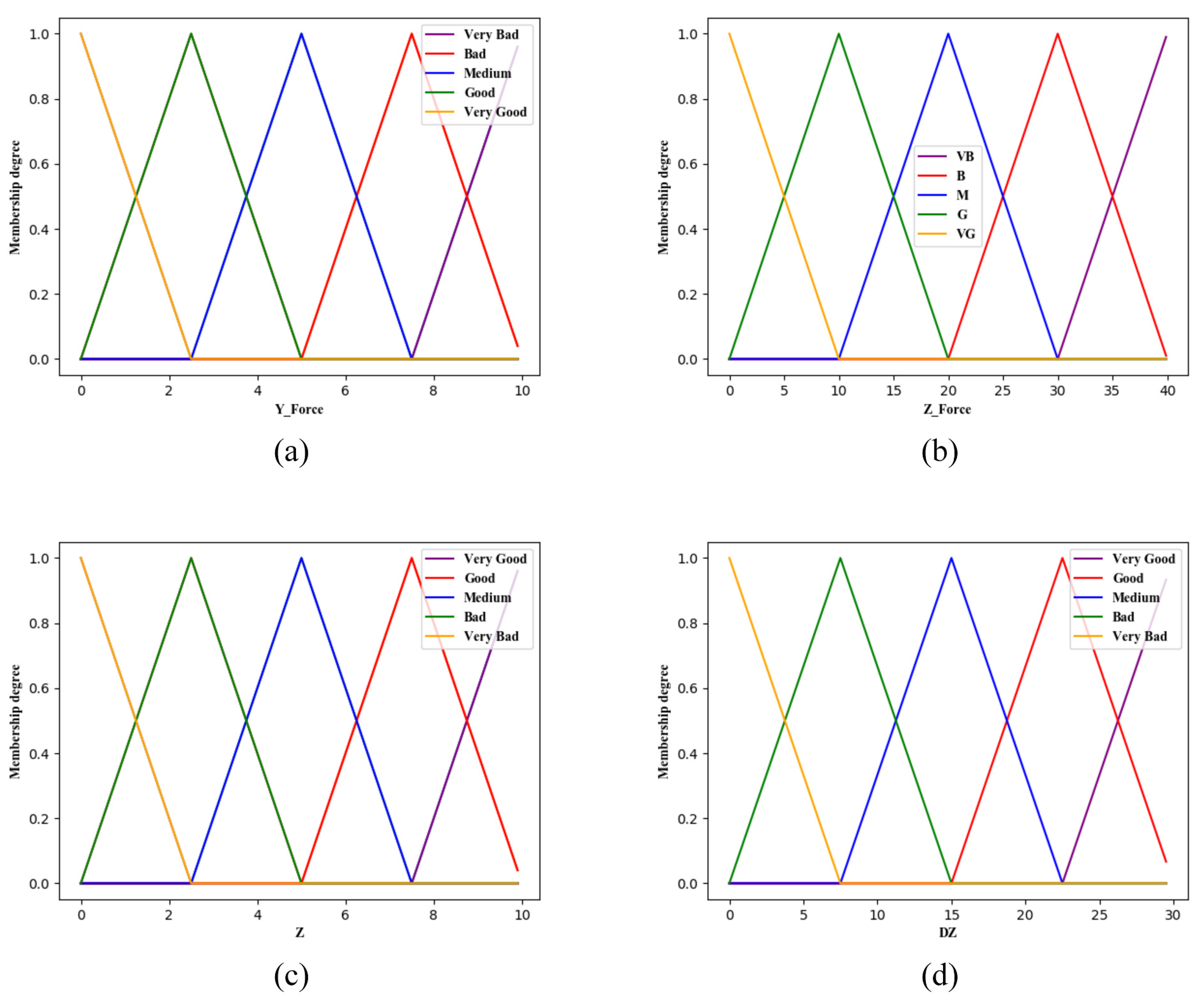
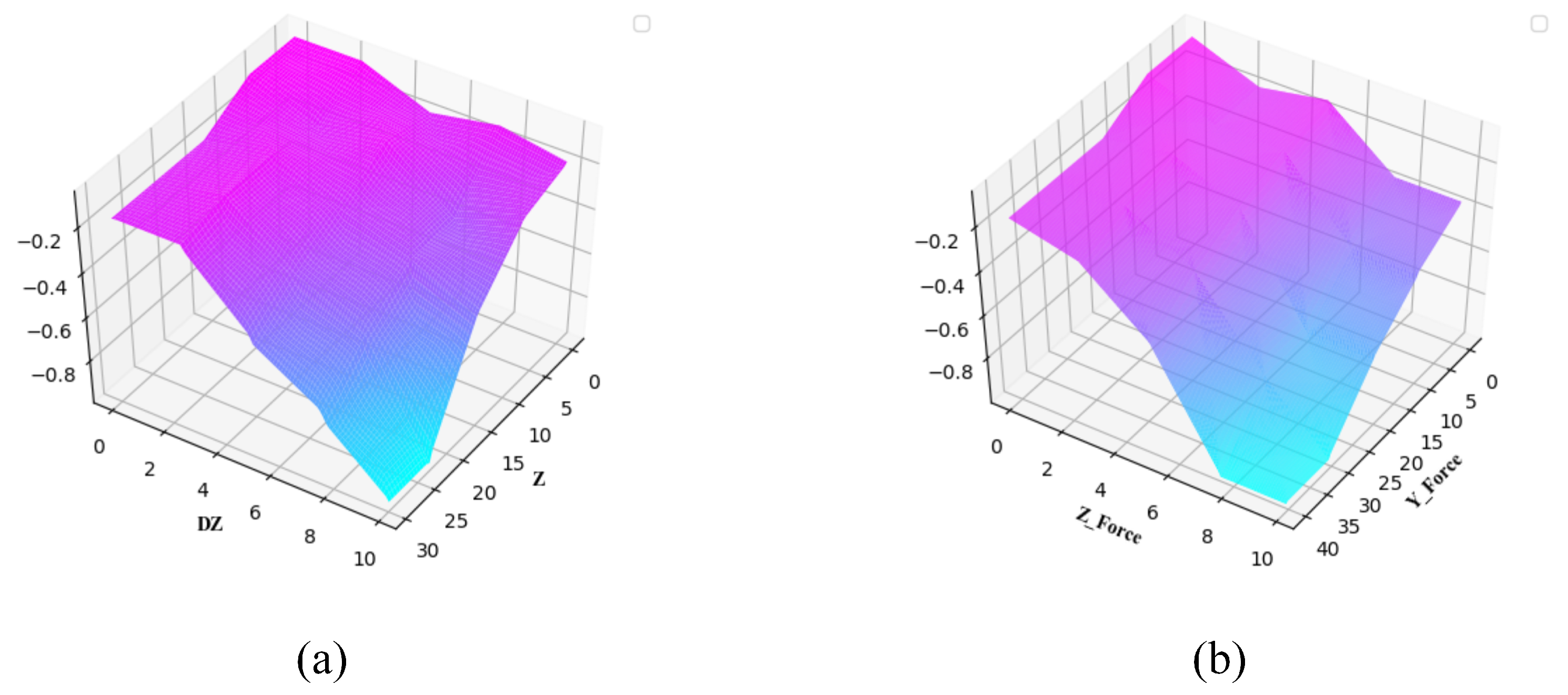
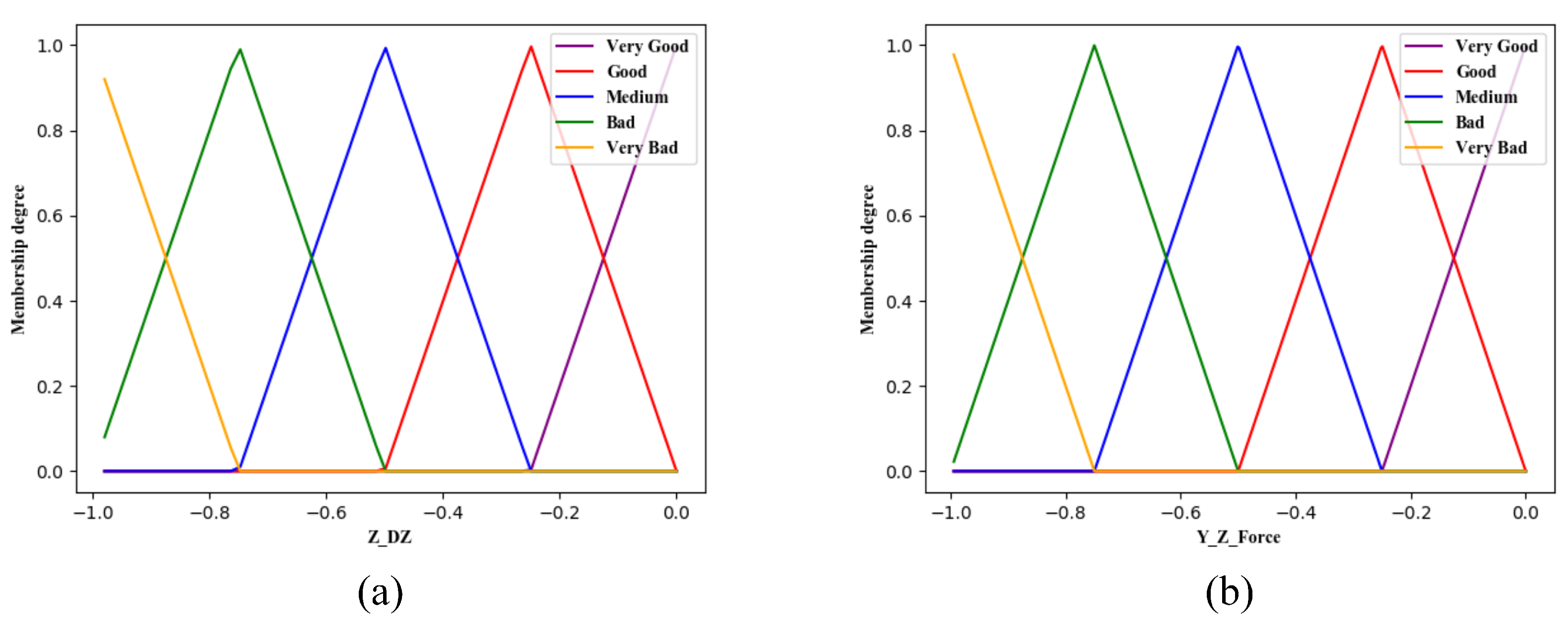
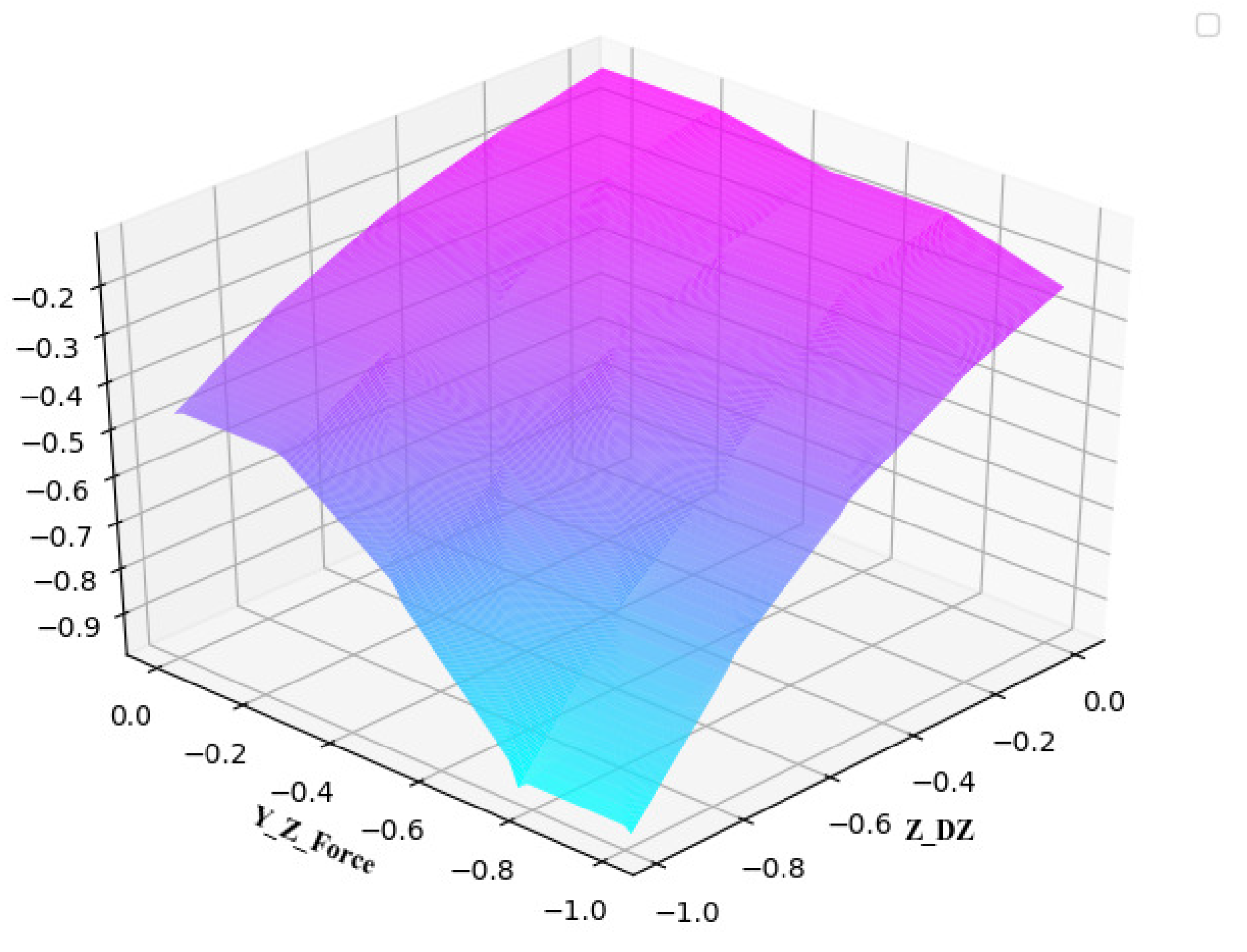
5.2. Fuzzy Reward System
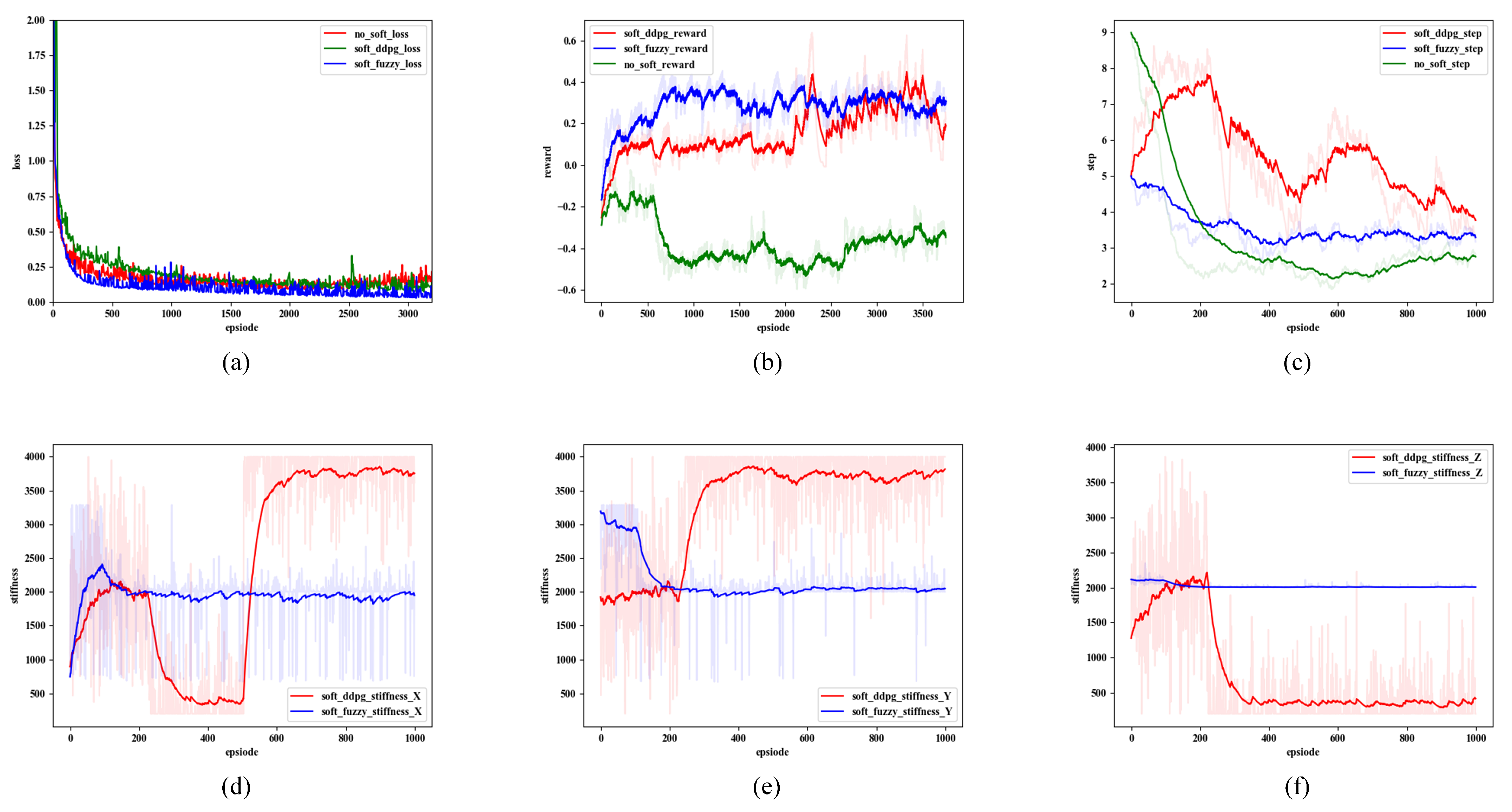
5.3. The Assembly Strategy Learning Process
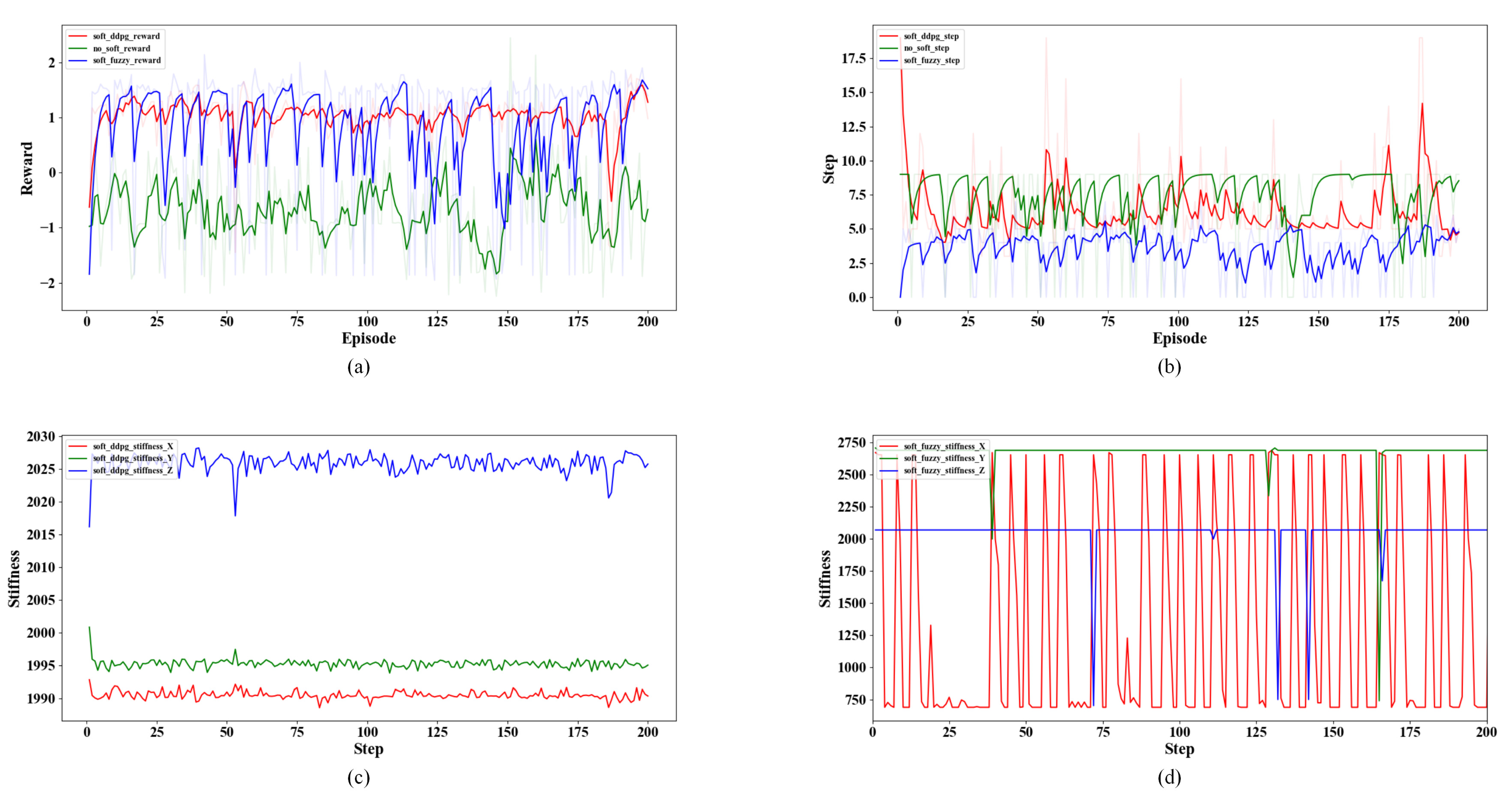
5.4. Assembly Strategy Experimental Validation
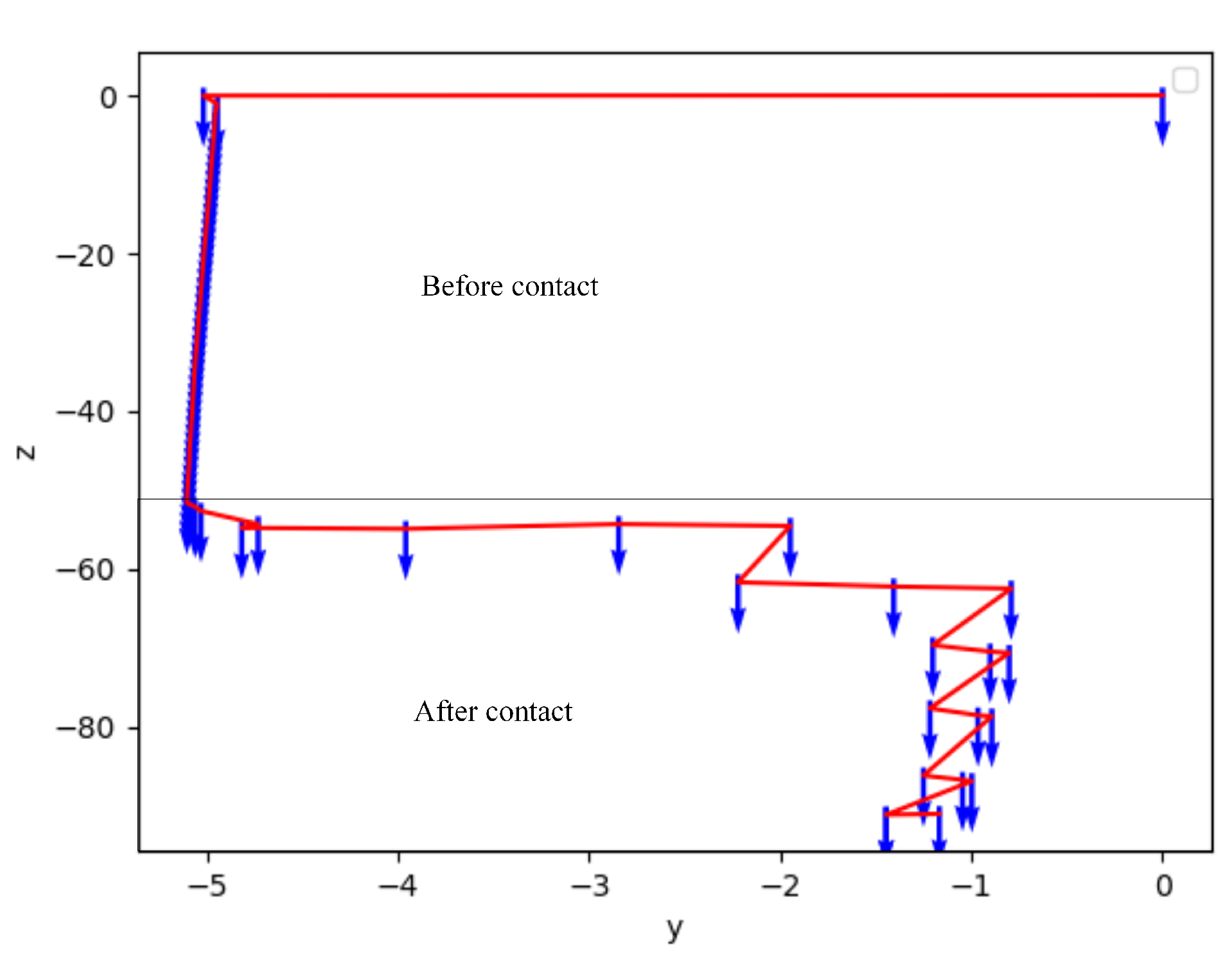
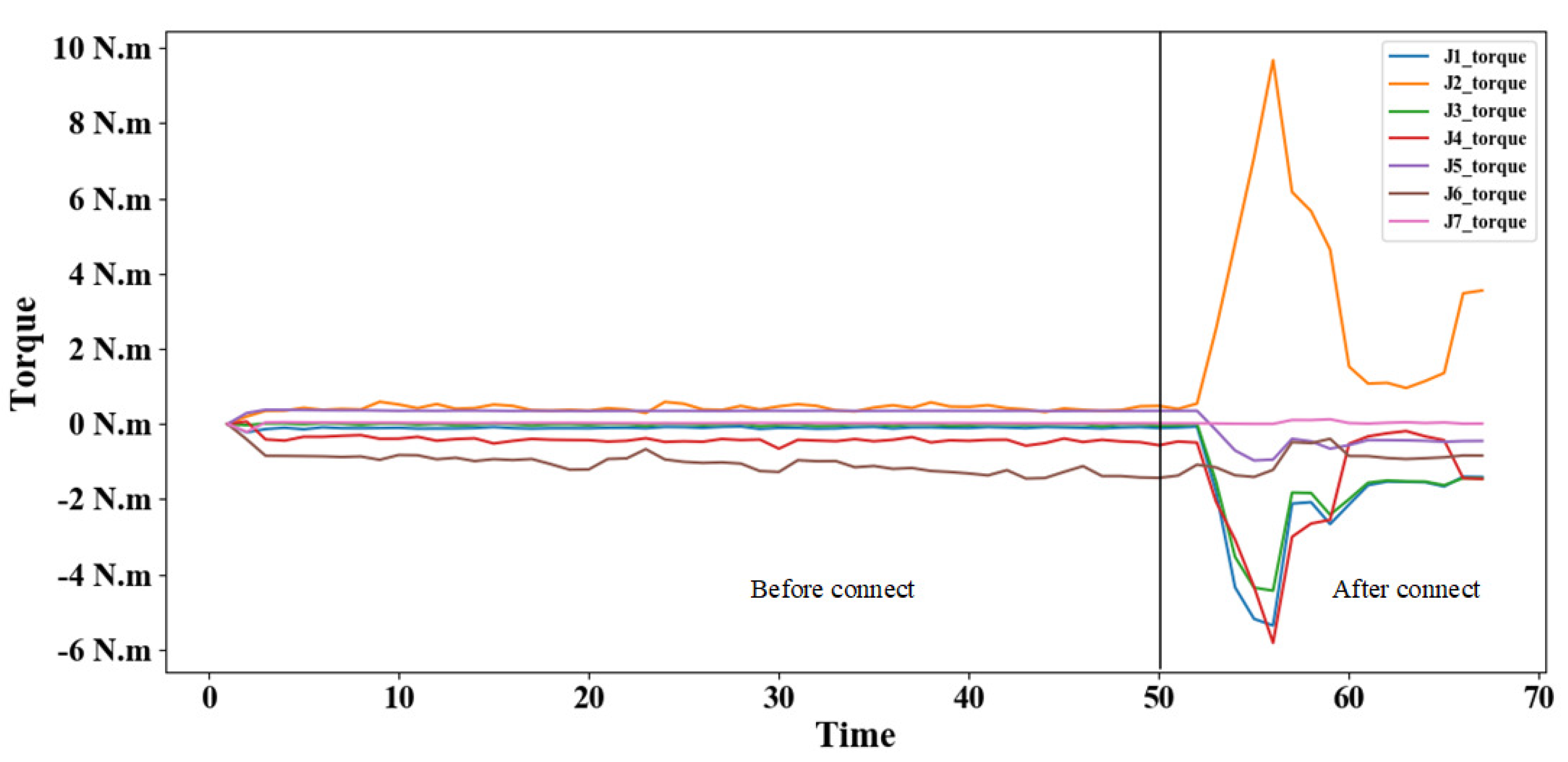
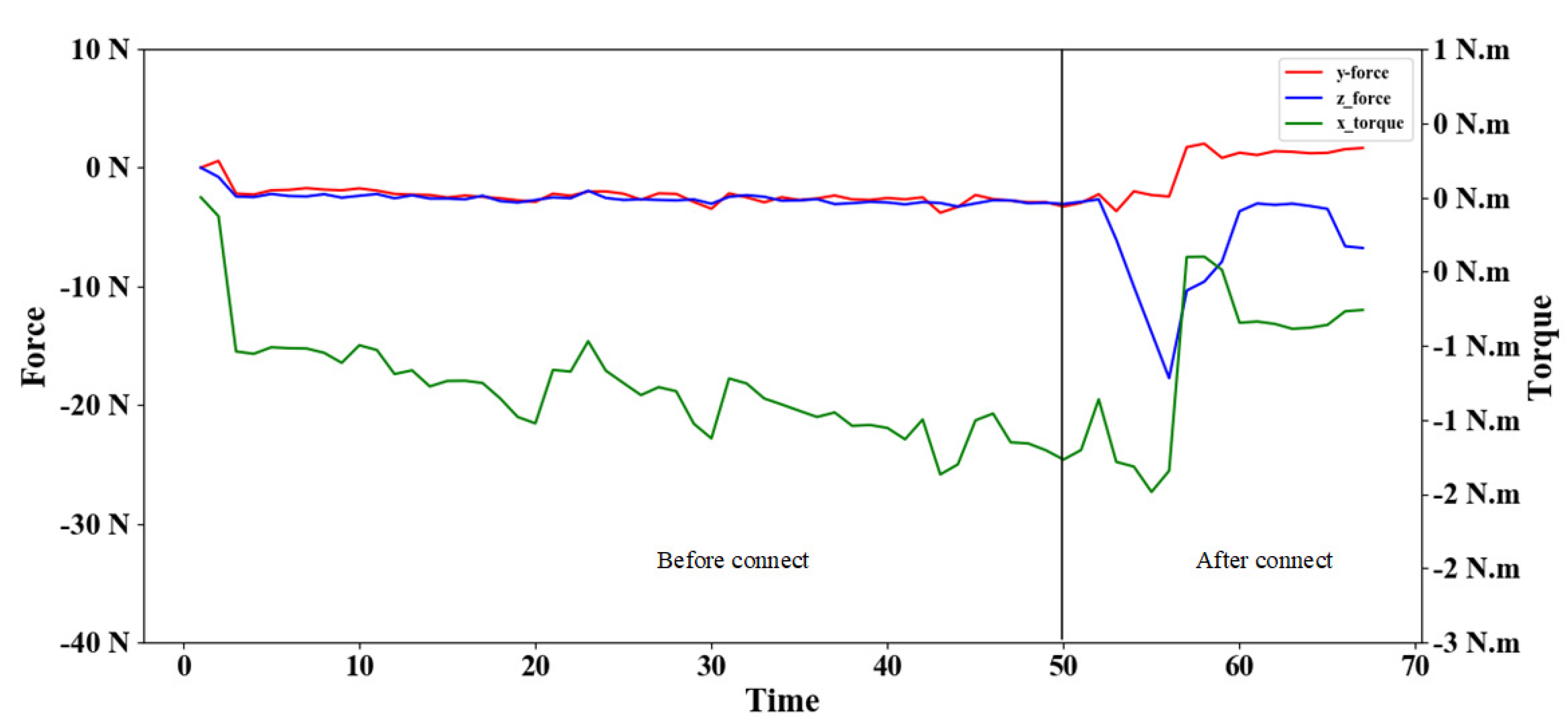
5.4.1. Test the Assembly Success Rate
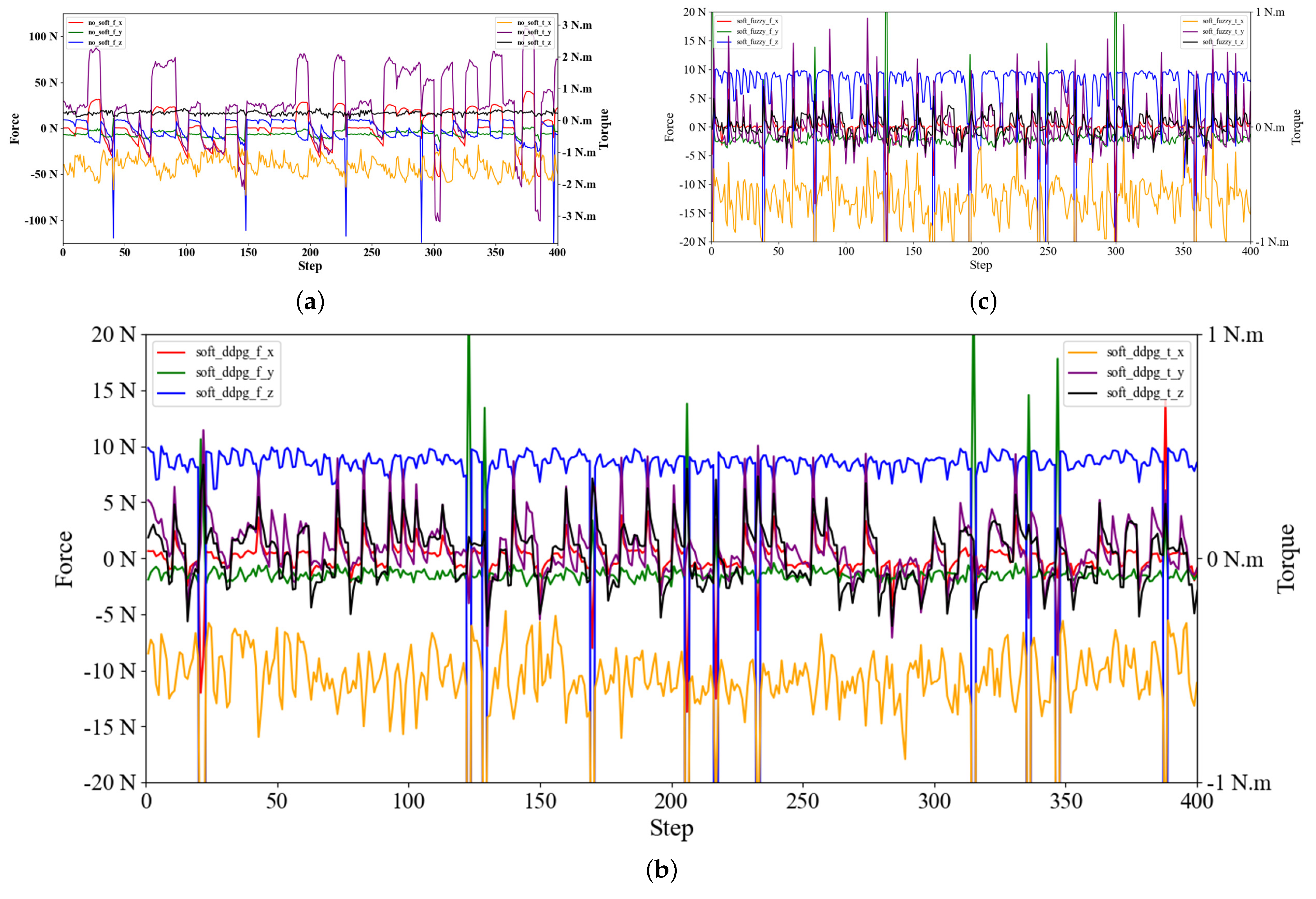
5.4.2. Assembly Process Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Inoue, T.; Magistris, G.D.; Munawar, A.; Yokoya, T.; Tachibana, R. Deep Reinforcement Learning for High Precision Assembly Tasks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Luo, J.; Solowjow, E.; Wen, C.; Ojea, J.A.; Agogino, A.M. Deep Reinforcement Learning for Robotic Assembly of Mixed Deformable and Rigid Objects. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Li, F.; Jiang, Q.; Quan, W.; Cai, S.; Song, R.; Li, Y. Manipulation skill acquisition for robotic assembly based on multi-modal information description. IEEE Access 2019, 8, 6282–6294. [Google Scholar] [CrossRef]
- Hogan, N. Impedance Control—An Approach to Manipulation—Part 2—Implementation. J. Dyn. Syst. Meas. Control 1985, 107, 8–16. [Google Scholar] [CrossRef]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; MIT Press: Cambridge, UK, 1998. [Google Scholar]
- Tang, T.; Lin, H.C.; Tomizuka, M. A Learning-Based Framework for Robot Peg-Hole-Insertion. In Proceedings of the ASME Dynamic Systems and Control Conference, Columbus, OH, USA, 28–30 October 2015. [Google Scholar]
- Yucheng, W. Research on the Assembly Strategy of Macro-Microbot Peg-in-Hole Based on Force Feedback; Xi’an University of Technology: Xi’an, China, 2017. [Google Scholar]
- Weijun, W. An Automatic Precision Assembly System for Gentle Assembly of Hole Shafts; Dalian University of Technology: Dalian, China, 2009. [Google Scholar]
- Chan, S.P.; Liaw, H.C. Generalized impedance control of robot for assembly tasks requiring compliant manipulation. IEEE Trans. Ind. Electron. 1996, 43, 453–461. [Google Scholar] [CrossRef]
- Su, J.; Li, R.; Qiao, H.; Xu, J.; Ai, Q.; Zhu, J.; Loughlin, C. Study on Dual Peg-in-hole Insertion using of Constraints Formed in the Environment. Ind. Robot. 2017, 44, 730–740. [Google Scholar] [CrossRef]
- Al-Jarrah, O.M.; Zheng, Y.F. Intelligent compliant motion control. IEEE Trans. Syst. Man, Cybern. Part B Cybern. 1998, 28, 116–122. [Google Scholar] [CrossRef] [PubMed]
- Lin, J. Research on the Active Soft Assembly System of Industrial Robots Based on Force Sensors; South China University of Technology: Guangzhou, China, 2013. [Google Scholar]
- Hou, Z.; Dong, H.; Zhang, K.; Gao, Q.; Chen, K.; Xu, J. Knowledge-Driven Deep Deterministic Policy Gradient for Robotic Multiple Peg-in-Hole Assembly Tasks. In Proceedings of the 2018 IEEE International Conference on Robotics and Biomimetics (ROBIO), Kuala Lumpur, Malaysia, 12–15 December 2018. [Google Scholar]
- Kober, J.; Peters, J. Reinforcement Learning in Robotics: A Survey. Int. J. Robot. Res. 2013, 32, 1238–1247. [Google Scholar] [CrossRef] [Green Version]
- Levine, S.; Wagener, N.; Abbeel, P. Learning Contact-Rich Manipulation Skills with Guided Policy Search. Proc. IEEE Int. Conf. Robot. Autom. 2015, 26–30. [Google Scholar] [CrossRef]
- Gullapalli, V.; Grupen, R.A.; Barto, A.G. Learning reactive admittance control. ICRA 1992, 1475–1480. [Google Scholar] [CrossRef]
- Nuttin, M.; Brussel, H. Learning the peg-into-hole assembly operation with a connectionist reinforcement technique. Comput. Ind. 1997, 33, 101–109. [Google Scholar] [CrossRef]
- Jing, X.; Hou, Z.; Wei, W.; Xu, B.; Zhang, K.; Chen, K. Feedback Deep Deterministic Policy Gradient With Fuzzy Reward for Robotic Multiple Peg-in-Hole Assembly Tasks. IEEE Trans. Ind. Inform. 2018, 15, 1658–1667. [Google Scholar]
- Erickson, D.; Weber, M.; Sharf, I. Contact Stiffness and Damping Estimation for Robotic Systems. Int. J. Robot. Res. 2003, 22, 41–58. [Google Scholar] [CrossRef]
- Xiao, S.; Shouping, Y.; Xing, W. Research on Adaptive Impedance Control of Multi-joint Robot. J. Hunan Univ. Technol. 2017, 31, 5. [Google Scholar]
- Ferraguti, F.; Secchi, C.; Fantuzzi, C. A tank-based approach to impedance control with variable stiffness. In Proceedings of the IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013. [Google Scholar]
- Ficuciello, F.; Villani, L.; Siciliano, B. Variable Impedance Control of Redundant Manipulators for Intuitive Human–Robot Physical Interaction. IEEE Trans. Robot. 2015, 31, 850–863. [Google Scholar] [CrossRef] [Green Version]
- Howard, M.; Braun, D.J.; Vijayakumar, S. Transferring Human Impedance Behavior to Heterogeneous Variable Impedance Actuators. IEEE Trans. Robot. 2013, 29, 847–862. [Google Scholar] [CrossRef] [Green Version]
- Chao, L.; Zhi, Z.; Xia, G.; Xie, X.; Zhu, Q.J.S. Efficient Force Control Learning System for Industrial Robots Based on Variable Impedance Control. Sensors 2018, 18, 2539. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Surdilovic, D. Robust control design of impedance control for industrial robots. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007. [Google Scholar]
- Song, P.; Yu, Y.; Zhang, X. A Tutorial Survey and Comparison of Impedance Control on Robotic Manipulation. Robotica 2019, 37, 801–836. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VG | G | M | B | VB | |
|---|---|---|---|---|---|
| VG | |||||
| G | |||||
| M | |||||
| B | |||||
| VB |
| Diameter | Depth | Minimum Clearance | Center Deviation | Axis Angle |
|---|---|---|---|---|
| 24 mm | 30 mm | 0.5 mm | (−5 mm, 5 mm) |
| Parameter | Symbol | Value |
|---|---|---|
| Contact force threshold | (−10, 10) N | |
| (−10, 10) N | ||
| Track increment threshold | 0 mm | |
| 1 mm | ||
| 5/3 mm | ||
| 0.02/3 | ||
| 0.02/3 | ||
| Stiffness threshold | (0, 4000) |
| Without Soft | Soft with DDPG | Soft with Fuzzy | |||
|---|---|---|---|---|---|
| Symbol | Value | Symbol | Value | Symbol | Value |
| episode | 1000 | episode | 1000 | episode | 1000 |
| stepmax | 20 | stepmax | 20 | stepmax | 20 |
| Groups | Without Soft Success | Soft DDPG Success | Soft Fuzzy Success |
|---|---|---|---|
| 1 | 0% | 95% | 85% |
| 2 | 0% | 100% | 85% |
| 3 | 0% | 95% | 80% |
| 4 | 0% | 100% | 90% |
| 5 | 0% | 100% | 80% |
| 6 | 0% | 100% | 85% |
| 7 | 0% | 100% | 75% |
| 8 | 10% | 100% | 65% |
| 9 | 0% | 100% | 80% |
| 10 | 0% | 90% | 90% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Li, F.; Men, Y.; Fu, T.; Yang, X.; Song, R. Deep Deterministic Policy Gradient with Reward Function Based on Fuzzy Logic for Robotic Peg-in-Hole Assembly Tasks. Appl. Sci. 2022, 12, 3181. https://doi.org/10.3390/app12063181
Wang Z, Li F, Men Y, Fu T, Yang X, Song R. Deep Deterministic Policy Gradient with Reward Function Based on Fuzzy Logic for Robotic Peg-in-Hole Assembly Tasks. Applied Sciences. 2022; 12(6):3181. https://doi.org/10.3390/app12063181
Chicago/Turabian StyleWang, Ziyue, Fengming Li, Yu Men, Tianyu Fu, Xuting Yang, and Rui Song. 2022. "Deep Deterministic Policy Gradient with Reward Function Based on Fuzzy Logic for Robotic Peg-in-Hole Assembly Tasks" Applied Sciences 12, no. 6: 3181. https://doi.org/10.3390/app12063181
APA StyleWang, Z., Li, F., Men, Y., Fu, T., Yang, X., & Song, R. (2022). Deep Deterministic Policy Gradient with Reward Function Based on Fuzzy Logic for Robotic Peg-in-Hole Assembly Tasks. Applied Sciences, 12(6), 3181. https://doi.org/10.3390/app12063181