
Semantic Segmentation of 12-Lead ECG Using 1D Residual U-Net with Squeeze-Excitation Blocks



Abstract
:1. Introduction
Related Work
2. Materials and Methods
2.1. Dataset
Data Preparation
- “0”—background;
- “1”—QRS block;
- “2”—T-wave;
- “3”— P-wave.
- Background—7,309,154 points,
- QRS complex—894,721 points;
- P-wave—1,516,929 points;
- T-wave—814,196 points.
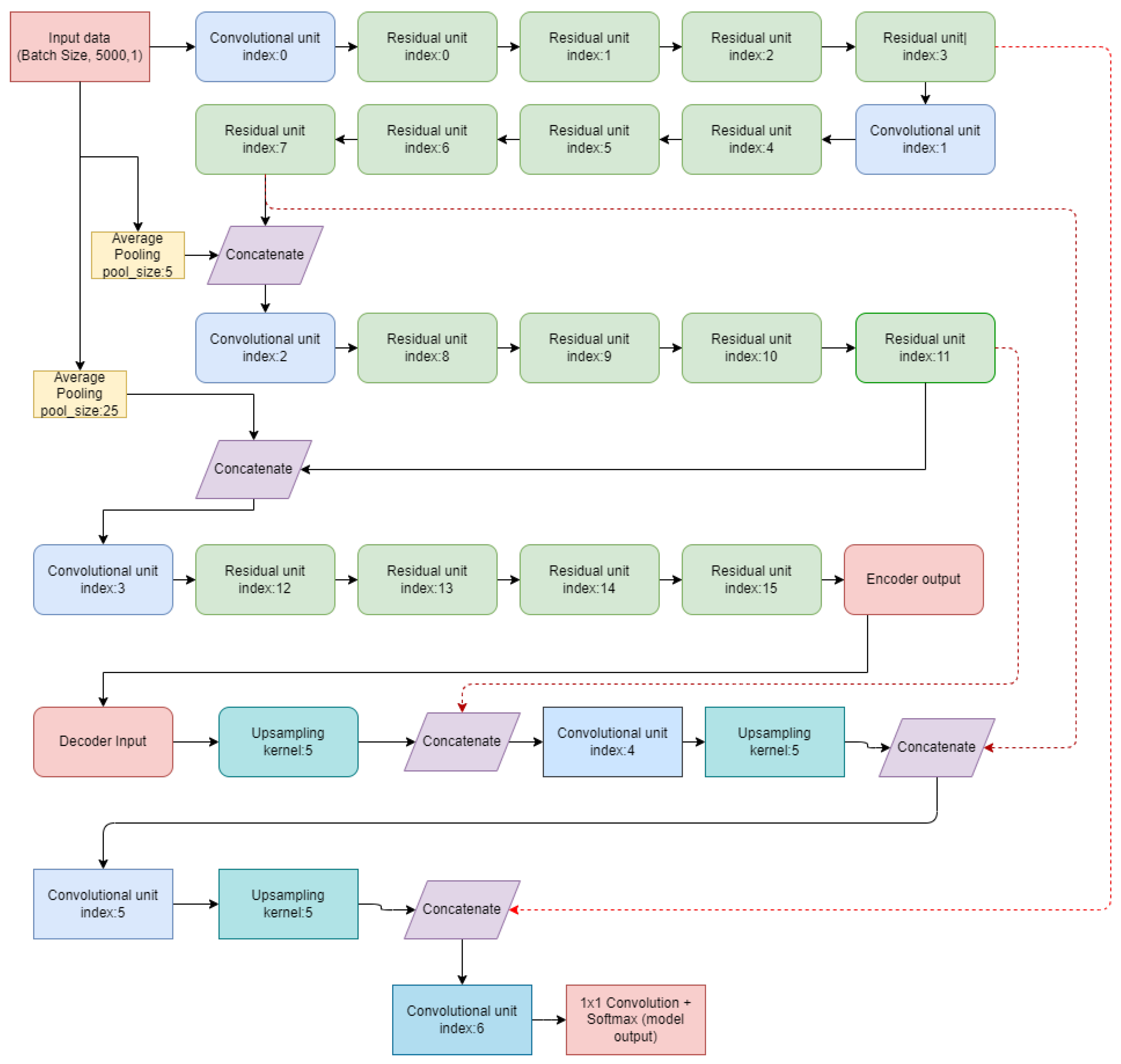
2.2. Model Architecture
2.2.1. Encoder
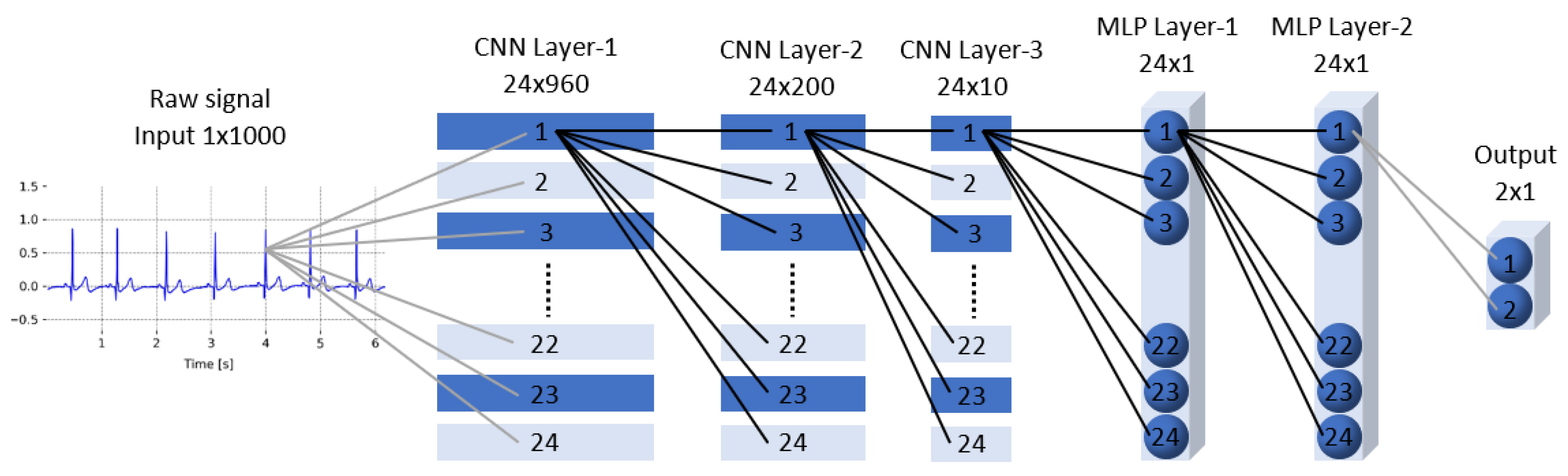
- Convolutional unit—this unit consists of a one-dimensional convolutional layer followed by batch normalization [25];
- Squeeze-exciting unit—is a cell designed to improve the representational power of a network by enabling it to perform channel-wise feature calibration. The inputs to this block are the feature maps generated by the convolutional unit. Each of the channels is being “squeezed” into a single numeric value using global average pooling. This value will be passed through two feed-forward layers activated by the ReLU and sigmoid functions to add nonlinearity and give each channel a smooth gating function. Then, the output of the sigmoid function is weighted by the input feature maps to get the excitation [26];
- Residual unit—this unit stacks two convolutional units, and on top of them, the squeeze-exciting unit is being stacked. The output is being added to the input feature maps.
2.2.2. Decoder
2.3. Training Process
- 32 mini-batch size;
- starting learning rate of 0.0005.
- Model checkpoint—saving the model that achieves the best validation loss score;
- Reduce learning rate—dynamic learning rate set to decrease by half each 3 epochs when the validation loss is not improving;
- Early stopping—stopping the training procedure when the model overfits the data (after 3 epochs).
3. Results
3.1. Numerical Results
- background—95%;
- QRS block—99.3%;
- P wave—99%;
- T wave—98%.
3.2. Visual Results
- black—background (0);
- red—QRS block (1);
- blue—T wave (2);
- cyan—P wave (3).
4. Discussion
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AF | Atrial Fibrillation |
| ANN | Artificial Neural Network |
| AUC | Area Under the Curve |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| ECG | Electrocardiography |
| HRV | Hear Rate Variability |
| PVC | Premature Ventricular Contractions |
| ReLU | Rectified Linear Unit |
| RNN | Recurrent Neural Network |
| WHO | World Health Organization |
References
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Faust, O.; Hagiwara, Y.; Hong, T.J.; Lih, O.S.; Acharya, U.R. Deep learning for healthcare applications based on physiological signals: A review. Comput. Methods Programs Biomed. 2018, 161, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Hong, S.; Zhou, Y.; Shang, J.; Xiao, C.; Sun, J. Opportunities and Challenges of Deep Learning Methods for Electrocardiogram Data: A Systematic Review. arXiv 2020, arXiv:2001.01550. [Google Scholar] [CrossRef] [PubMed]
- Novotna, P.; Vicar, T.; Hejc, J.; Ronzhina, M.; Kolarova, J. Deep-Learning Premature Contraction Localization in 12-lead ECG From Whole Signal Annotations. In Proceedings of the Computing in Cardiology, Rimini, Italy, 13–16 September 2020. [Google Scholar] [CrossRef]
- Du, N.; Cao, Q.; Yu, L.; Liu, N.; Zhong, E.; Liu, Z.; Shen, Y.; Chen, K. FM-ECG: A fine-grained multi-label framework for ECG image classification. Inf. Sci. 2021, 549, 164–177. [Google Scholar] [CrossRef]
- He, R.; Liu, Y.; Wang, K.; Zhao, N.; Yuan, Y.; Li, Q.; Zhang, H. Automatic Detection of QRS Complexes Using Dual Channels Based on U-Net and Bidirectional Long Short-Term Memory. IEEE J. Biomed. Health Inform. 2021, 25, 1052–1061. [Google Scholar] [CrossRef]
- Weimann, K.; Conrad, T.O.F. Transfer learning for ECG classification. Sci. Rep. 2021, 11, 5251. [Google Scholar] [CrossRef]
- Zheng, G.; Ji, S.; Dai, M.; Sun, Y. ECG Based Identification by Deep Learning. In Biometric Recognition; Zhou, J., Wang, Y., Sun, Z., Xu, Y., Shen, L., Feng, J., Shan, S., Qiao, Y., Guo, Z., Yu, S., Eds.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10568, pp. 503–510. [Google Scholar] [CrossRef]
- Beraza, I.; Romero, I. Comparative study of algorithms for ECG segmentation. Biomed. Signal Process. Control 2017, 34, 166–173. [Google Scholar] [CrossRef]
- Laguna, P.; Jané, R.; Caminal, P. Automatic Detection of Wave Boundaries in Multilead ECG Signals: Validation with the CSE Database. Comput. Biomed. Res. 1994, 27, 45–60. [Google Scholar] [CrossRef]
- Martinez, J.; Almeida, R.; Olmos, S.; Rocha, A.; Laguna, P. A Wavelet-Based ECG Delineator: Evaluation on Standard Databases. IEEE Trans. Biomed. Eng. 2004, 51, 570–581. [Google Scholar] [CrossRef]
- Singh, Y.N.; Gupta, P. ECG to Individual Identification. In Proceedings of the 2008 IEEE Second International Conference on Biometrics: Theory, Applications and Systems, Washington, DC, USA, 29 September–1 October 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Di Marco, L.Y.; Chiari, L. A wavelet-based ECG delineation algorithm for 32-bit integer online processing. Biomed. Eng. Online 2011, 10, 23. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Chan, K.L.; Krishnan, S.M. Characteristic wave detection in ECG signal using morphological transform. BMC Cardiovasc. Disord. 2005, 5, 28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martínez, A.; Alcaraz, R.; Rieta, J.J. Application of the phasor transform for automatic delineation of single-lead ECG fiducial points. Physiol. Meas. 2010, 31, 1467–1485. [Google Scholar] [CrossRef] [PubMed]
- Vázquez-Seisdedos, C.R.; Neto, J.E.; Marañón Reyes, E.J.; Klautau, A.; Limão de Oliveira, R.C. New approach for T-wave end detection on electrocardiogram: Performance in noisy conditions. BioMed. Eng. Online 2011, 10, 77. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vitek, M.; Hrubes, J.; Kozumplik, J. A Wavelet-Based ECG Delineation with Improved P Wave Offset Detection Accuracy. Anal. Biomed. Signals Images 2010, 20, 160–165. [Google Scholar]
- Hughes, N.P.; Tarassenko, L.; Roberts, S.J. Markov Models for Automated ECG Interval Analysis. In Proceedings of the NIPS 2003, Vancouver, BC, Canada, 8–13 December 2003. [Google Scholar]
- Laguna, P.; Mark, R.; Goldberg, A.; Moody, G. A database for evaluation of algorithms for measurement of QT and other waveform intervals in the ECG. In Proceedings of the Computers in Cardiology 1997, Lund, Sweden, 7–10 September 1997; IEEE: Lund, Sweden, 1997; pp. 673–676. [Google Scholar] [CrossRef]
- Kalyakulina, A.; Yusipov, I.; Moskalenko, V.; Nikolskiy, A.; Kosonogov, K.; Zolotykh, N.; Ivanchenko, M. Lobachevsky University Electrocardiography Database. Type: Dataset. Available online: https://physionet.org/content/ludb/1.0.0/ (accessed on 10 July 2021).
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Yan, W.; Hua, Y. Deep Residual SENet for Foliage Recognition. In Transactions on Edutainment XVI; Pan, Z., Cheok, A.D., Müller, W., Zhang, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 11782, pp. 92–104. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. arXiv 2019, arXiv:1709.01507. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Jaccard, P. The distribution of the flora in the alpine zone. 1. New Phytol. 1912, 11, 37–50. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2021, 17, 168–192. [Google Scholar] [CrossRef]
- Keras—Sensitivity at Specificity|TensorFlow Core v2.8.0. Available online: https://www.tensorflow.org/api_docs/python/tf/keras/metrics/SensitivityAtSpecificity (accessed on 14 March 2022).
- The Top 10 Causes of Death. Available online: https://www.who.int/news-room/fact-sheets/detail/the-top-10-causes-of-death (accessed on 25 June 2021).
- Stabenau, H.F.; Bridge, C.P.; Waks, J.W. ECGAug: A novel method of generating augmented annotated electrocardiogram QRST complexes and rhythm strips. Comput. Biol. Med. 2021, 134, 104408. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Choromanski, K.; Likhosherstov, V.; Dohan, D.; Song, X.; Gane, A.; Sarlos, T.; Hawkins, P.; Davis, J.; Mohiuddin, A.; Kaiser, L.; et al. Rethinking Attention with Performers. arXiv 2020, arXiv:2009.14794. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-Attention with Linear Complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the Inherence of Convolution for Visual Recognition. arXiv 2021, arXiv:2103.06255. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Without Squeeze-Exciting | With Squeeze-Exciting | |||||
|---|---|---|---|---|---|---|
| Dataset | Train | Validation | Test | Train | Validation | Test |
| Accuracy | 0.97 | 0.92 | 0.92 | 0.97 | 0.95 | 0.95 |
| AUC | 0.99 | 0.98 | 0.98 | 0.99 | 0.99 | 0.99 |
| Specificity | 1.0 | 0.99 | 0.97 | 0.99 | 0.99 | 0.95 |
| Sensitivity | 1.0 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| Recall | 0.97 | 0.92 | 0.92 | 0.98 | 0.95 | 0.95 |
| Precision | 0.97 | 0.92 | 0.92 | 0.97 | 0.95 | 0.95 |
| Loss | 0.06 | 0.25 | 0.39 | 0.06 | 0.14 | 0.14 |
| Jaccard Index | F1-Score | |||||
|---|---|---|---|---|---|---|
| Macro | Micro | Weighted | Macro | Micro | Weighted | |
| Without squeeze-exciting | 0.8 | 0.86 | 0.86 | 0.87 | 0.92 | 0.92 |
| With squeeze-exciting | 0.87 | 0.91 | 0.91 | 0.93 | 0.96 | 0.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duraj, K.; Piaseczna, N.; Kostka, P.; Tkacz, E. Semantic Segmentation of 12-Lead ECG Using 1D Residual U-Net with Squeeze-Excitation Blocks. Appl. Sci. 2022, 12, 3332. https://doi.org/10.3390/app12073332
Duraj K, Piaseczna N, Kostka P, Tkacz E. Semantic Segmentation of 12-Lead ECG Using 1D Residual U-Net with Squeeze-Excitation Blocks. Applied Sciences. 2022; 12(7):3332. https://doi.org/10.3390/app12073332
Chicago/Turabian StyleDuraj, Konrad, Natalia Piaseczna, Paweł Kostka, and Ewaryst Tkacz. 2022. "Semantic Segmentation of 12-Lead ECG Using 1D Residual U-Net with Squeeze-Excitation Blocks" Applied Sciences 12, no. 7: 3332. https://doi.org/10.3390/app12073332
APA StyleDuraj, K., Piaseczna, N., Kostka, P., & Tkacz, E. (2022). Semantic Segmentation of 12-Lead ECG Using 1D Residual U-Net with Squeeze-Excitation Blocks. Applied Sciences, 12(7), 3332. https://doi.org/10.3390/app12073332