
A Predictive Model for Student Achievement Using Spiking Neural Networks Based on Educational Data


Abstract
:1. Introduction
- Based on the analysis of educational data, an educational data mining model is discussed.
- Spiking neural network is used for the first time to predict student achievement.
- Evolutionary spiking neural network is designed and implemented on the basis of the student datasets.
- Simulation results verify the effectiveness of the proposed model in predicting student achievement.
- The research results of the proposed model can provide more targeted reference for scientific research and education management workers.
2. Related Works
2.1. Research Status of Educational Data Mining
2.2. Spiking Neural Network
- Neurons. Biological neurons generally simulate their functions through neuron models. The neuron model is the basis for building spiking neural network. Different types of neurons are connected to each other to form various types of neural network models. Common spiking neuron models include Izhikevich model, HH (Hodgkin and Huxley model), LIF (Leaky Integrate and Fire Model), SRM (spike response model), etc. Among them, LIF and SRM are the most commonly used learning algorithms. Many learning algorithms are designed and implemented on the basis of these neuron models or their variants.
- Network Topology. The topology of a neural network includes the number of network layers, the number of neurons in each layer, and the way each neuron connected to each other. The topology of artificial neural network is often divided into input layer, hidden layer and output layer, and each layer is connected in sequence. Among them, the neurons of input layer are responsible for receiving input information from the outside world and passing it to the neurons of hidden layer. The hidden layer is responsible for information processing and information transformation within the neural network. Usually, the hidden layer is designed as one or more layers according to the needs of transformation. Like the topology of traditional artificial neural network, the structure of spiking neural network mainly includes feedforward spiking neural network, recurrent spiking neural network and hybrid spiking neural network, etc.
- Spike sequence encoding. For the encoding of input information, researchers have proposed a variety of spike sequence encoding methods for spiking neural networks by learning the information encoding mechanism of biological neurons. For example, the first spike-triggered time coding method, the delayed phase coding method, the population coding method, etc.
- Learning algorithm. Spiking neural network contains hyperparameters such as network topology, number of neurons, and weights. During training network, these hyperparameters are determined by a learning algorithm. The learning algorithm directly determines the output accuracy of the spiking neural network. Therefore, scholars have carried out a lot of research on the learning algorithm of spiking neural network, and the research directions mainly focus on unsupervised learning, supervised learning, semi-supervised learning and reinforcement learning.
3. Proposed Method
3.1. Scheme of Student Achievement Prediction
- Datasets consist of raw data from databases, documents, or the website. Research on student achievement prediction has focused on education and psychology, using data mostly from questionnaires or student self-reports [29]. Generally, the acquisition of this kind of data should first understand data structure and meaning of the original student achievement data involved in the task, and determine the required data items and data extraction principles. Finally, the extraction of relevant student data is completed using appropriate means and strict operating specifications. The above process involves more relevant professional knowledge. We can try to combine the arguments of experts and users to obtain variables that are highly correlated with student performance. If the extraction of multi-source data is involved in the acquisition process, due to the different software and hardware platforms, it is necessary to pay attention to the connection of the data sources of these heterogeneous databases and the conversion of data formats. If the confidentiality of student data is involved, more attention should be paid to the operation of such relevant data during processing, and remarks should be made on the relevant data for reference. The study found that the possible reason why the prediction accuracy of the model could not be improved was caused by the quality of the data source. In the acquisition of raw data, it is particularly important to minimize errors and avoid mistakes from the source, especially to reduce human errors. Currently, the main sources of datasets on student achievement prediction are education management systems, offline datasets of educational history, and standardized test datasets.
- Data preprocessing needs to complete data cleaning, data integration, data transformation and other operations. In the whole data mining process, data preprocessing takes about 60% of the time, and the subsequent mining work only accounts for about 10% of the total workload. The preprocessed data can not only save a lot of space and time, but also help the predictive model to make better decisions and predictions. Due to the different sources of educational data, the attributes and feature dimensions of student data are inconsistent. In order to obtain better quality modeling data, certain data cleaning, integration and transformation must be performed.Among them, data cleaning is the most time-consuming and tedious, but it is the most important step in the data preparation process. This step can effectively reduce the problem of conflict situations that may arise during the learning process. The raw data with conditions of noise, error, missing and redundant can be processed as follows.
- -
- Noise data. Data smoothing techniques are the most widely used methods for dealing with such noisy data [30].
- -
- Error data. For some wrong data tuples, we change, delete or ignore these wrong data by analyzing the datasets.
- -
- Missing data. We use global constants or mean values of attributes to fill nulls, and use regression methods or use derivation-based Bayesian methods or decision trees to fix certain attributes of the data [31].
- -
- Redundant data. We will remove redundant parts of the data to improve the processing speed of the prediction model.
Data integration is a data storage technology and process that combines data from different data sources such as databases, networks, or public files. Since the data integration of different disciplines involves different theoretical foundations and rules, data integration can be said to be a difficult point in data preprocessing. Naming rules and requirements for each data source may be inconsistent. To extract data from multiple data sources into a database, all data formats must be unified in order to ensure the accuracy of the experimental results. Generally, each data source needs to be modified according to a unified standard, and then the data of different data sources can be uniformly extracted into the same database.Data transformation is the use of linear or nonlinear mathematical transformation methods to compress multi-dimensional data into fewer dimensional data and eliminate their differences in characteristics such as space, attributes, time and precision. While these methods are usually lossy on the original data, the results tend to have greater utility. To a certain extent, the original data after data transformation operation makes the prediction model to have better prediction accuracy and execution efficiency. - Data extraction is to divide the data into training dataset and test dataset. The training dataset refers to building a classifier by matching some parameters to a dataset of learning samples. On the training dataset, the learning method is used to determine the hyperparameters of the model. That is, let the training model build a prediction method based on the training dataset. After training the model, the test dataset is mainly employed to evaluate the discriminative ability and generalization ability of the model.
- Data modeling addresses two main types of forecasting problems, including classification and numerical prediction. Classification and prediction are two ways of using data to make predictions that can be used to determine future outcomes. Classification is used to predict discrete categories of data objects, and the attribute values that need to be predicted are discrete and disordered. Numerical prediction is used to predict the continuous value of data objects, and the attribute values that need to be predicted are continuous and ordered. The classification data model reflects how to find out the characteristic knowledge of the common nature of similar things and the difference characteristic knowledge between different things. Classification is to build a classification model through guided learning training, and use the model to classify samples of unknown classification. A predictive model is similar to a classification model and can be viewed as a map or function , where x is the input tuple and the output y is a continuous or ordered value. Unlike the classification algorithm, the attribute values that the prediction algorithm needs to predict are continuous and ordered.
- Application refers to applying the above process to classification or prediction to solve practical problems. The specific application of the data model in this paper is for educational data mining. More specifically, the proposed model is applied to solve the problems of student achievement prediction.
3.2. Student Achievement Prediction Model
- We take the student dataset as the input of the proposed model, and encode these data as the input spike sequence using the first spike encoding [32].
- The input spike sequence is passed to neurons for transmission and processing, and then the learning rate and synaptic time delay are optimized using evolutionary membrane algorithm to achieve adaptive tuning the hyperparameters of the proposed model.
- The processing result of the neuron is passed to the output layer. The output layer outputs the predicted spike sequence, and calculates the mean squared error between the actual spike sequence and the expected output spike sequence.
- The model adjusts the learning rate and synaptic time delay by continuously calling the evolutionary membrane algorithm to reduce its prediction error value. Until the mean squared error is smaller than a certain limit or the number of iterations satisfies the requirement of stop learning, the proposed model outputs a spike sequence and decodes this sequence into a prediction result.
4. Experimental Studies
4.1. Benchmark Datasets and Evaluation Indicators
4.1.1. Benchmark Datasets
4.1.2. Evaluation Indicators
4.1.3. Experimental Conditions
4.2. Comparing the Results of All Experimental Algorithms
4.2.1. Comparing Results with All Experimental Algorithms on the xAPI-Edu-Data Datasets
4.2.2. Comparing Results with All Experimental Algorithms on the Student Performance Datasets
4.2.3. Discussion
5. Conclusions
- Analyzes and preprocesses student information. It is necessary to have a comprehensive understanding of student attribute data. One aspect is understanding the structure of the data in the student dataset and transforming the raw data into something that all experimental algorithms can use. On the other hand, it is for better feature extraction to find out the key elements in student data that affect final student achievement.
- On the basis of a comprehensive understanding of all experimental algorithms, a student achievement prediction model based on evolutionary spiking neural network is established. This paper uses six different data mining algorithms for student achievement as a comparison between the experimental algorithms and the proposed prediction algorithm, and analyzes the effect of each prediction model.
- A specific application case of a student achievement prediction model is proposed, which lays a foundation for the wider application of future student achievement prediction, and aims to provide new perspectives and ideas for the application of data mining in the field of education data mining.
- The proposed model realizes the prediction of student achievement, and it can provide effective technical support for teaching management work such as teaching students in accordance with their aptitude in the early stage of the course, academic early warning, etc., thus providing theoretical basis and technical support for the management of students in colleges and universities.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Namoun, A.; Alshanqiti, A. Predicting student performance using data mining and learning analytics techniques: A systematic literature review. Appl. Sci. 2020, 11, 237. [Google Scholar] [CrossRef]
- Hooshyar, D.; Pedaste, M.; Yang, Y. Mining educational data to predict students’ performance through procrastination behavior. Entropy 2019, 22, 12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Romero, C.; Ventura, S. Educational data mining and learning analytics: An updated survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1355. [Google Scholar] [CrossRef]
- Dutt, A.; Ismail, M.A.; Herawan, T. A Systematic Review on Educational Data Mining. IEEE Access 2017, 5, 15991–16005. [Google Scholar] [CrossRef]
- Salal, Y.; Abdullaev, S.; Kumar, M. Educational data mining: Student performance prediction in academic. Int. J. Eng. Adv. Technol. 2019, 8, 54–59. [Google Scholar]
- Chaparro-Pelaez, J.; Iglesias-Pradas, S.; Rodriguez-Sedano, F.J.; Acquila-Natale, E. Extraction, processing and visualization of peer assessment data in moodle. Appl. Sci. 2019, 10, 163. [Google Scholar] [CrossRef] [Green Version]
- Tsiakmaki, M.; Kostopoulos, G.; Kotsiantis, S.; Ragos, O. Implementing AutoML in educational data mining for prediction tasks. Appl. Sci. 2019, 10, 90. [Google Scholar] [CrossRef] [Green Version]
- Injadat, M.; Moubayed, A.; Nassif, A.B.; Shami, A. Systematic ensemble model selection approach for educational data mining. Knowl.-Based Syst. 2020, 200, 105992. [Google Scholar] [CrossRef]
- Cortez, P.; Silva, A.M.G. Using data mining to predict secondary school student performance. In Proceedings of the 5th Annual Future Business Technology Conference, Porto, Portugal, 9–11 April 2008. [Google Scholar]
- Ramesh, V.; Parkavi, P.; Ramar, K. Predicting student performance: A statistical and data mining approach. Int. J. Comput. Appl. 2013, 63, 35–39. [Google Scholar] [CrossRef]
- Arora, N.; Saini, J.R. A fuzzy probabilistic neural network for student’s academic performance prediction. Int. J. Innov. Res. Sci. Eng. Technol. 2013, 2, 4425–4432. [Google Scholar]
- Ezz, M.; Elshenawy, A. Adaptive recommendation system using machine learning algorithms for predicting student’s best academic program. Educ. Inf. Technol. 2020, 25, 2733–2746. [Google Scholar] [CrossRef]
- Pimentel, J.S.; Ospina, R.; Ara, A. Learning Time Acceleration in Support Vector Regression: A Case Study in Educational Data Mining. Stats 2021, 4, 41. [Google Scholar] [CrossRef]
- Yousafzai, B.K.; Khan, S.A.; Rahman, T.; Khan, I.; Ullah, I.; Ur Rehman, A.; Baz, M.; Hamam, H.; Cheikhrouhou, O. Student-performulator: Student academic performance using hybrid deep neural network. Sustainability 2021, 13, 9775. [Google Scholar] [CrossRef]
- Rastrollo-Guerrero, J.L.; Gómez-Pulido, J.A.; Durán-Domínguez, A. Analyzing and predicting students’ performance by means of machine learning: A review. Appl. Sci. 2020, 10, 1042. [Google Scholar] [CrossRef] [Green Version]
- Khan, A.; Ghosh, S.K. Student performance analysis and prediction in classroom learning: A review of educational data mining studies. Educ. Inf. Technol. 2021, 26, 205–240. [Google Scholar] [CrossRef]
- Liu, C.; Du, Y. A membrane algorithm based on chemical reaction optimization for many-objective optimization problems. Knowl.-Based Syst. 2019, 165, 306–320. [Google Scholar] [CrossRef]
- Liu, C.; Shen, W.; Zhang, L.; Du, Y.; Yuan, Z. Spike Neural Network Learning Algorithm Based on an Evolutionary Membrane Algorithm. IEEE Access 2021, 9, 17071–17082. [Google Scholar] [CrossRef]
- Ma, Y.; Cui, C.; Nie, X.; Yang, G.; Shaheed, K.; Yin, Y. Pre-course student performance prediction with multi-instance multi-label learning. Sci. China Inf. Sci. 2019, 62, 200–205. [Google Scholar] [CrossRef] [Green Version]
- Karthikeyan, V.G.; Thangaraj, P.; Karthik, S. Towards developing hybrid educational data mining model (HEDM) for efficient and accurate student performance evaluation. Soft Comput. 2020, 24, 18477–18487. [Google Scholar] [CrossRef]
- Ang, K.L.M.; Ge, F.L.; Seng, K.P. Big educational data & analytics: Survey, architecture and challenges. IEEE Access 2020, 8, 116392–116414. [Google Scholar]
- Sokkhey, P.; Navy, S.; Tong, L.; Okazaki, T. Multi-models of educational data mining for predicting student performance in mathematics: A case study on high schools in Cambodia. IEIE Trans. Smart Process. Comput. 2020, 9, 217–229. [Google Scholar] [CrossRef]
- Taherkhani, A.; Belatreche, A.; Li, Y.; Cosma, G.; Maguire, L.P.; McGinnity, T.M. A review of learning in biologically plausible spiking neural networks. Neural Netw. 2020, 122, 253–272. [Google Scholar] [CrossRef] [PubMed]
- Lobo, J.L.; Del Ser, J.; Bifet, A.; Kasabov, N. Spiking neural networks and online learning: An overview and perspectives. Neural Netw. 2020, 121, 88–100. [Google Scholar] [CrossRef] [PubMed]
- Demertzis, K.; Iliadis, L.; Bougoudis, I. Gryphon: A semi-supervised anomaly detection system based on one-class evolving spiking neural network. Neural Comput. Appl. 2020, 32, 4303–4314. [Google Scholar] [CrossRef]
- Salt, L.; Howard, D.; Indiveri, G.; Sandamirskaya, Y. Parameter optimization and learning in a spiking neural network for UAV obstacle avoidance targeting neuromorphic processors. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3305–3318. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Jin, Y.; Ding, J. Surrogate-assisted evolutionary search of spiking neural architectures in liquid state machines. Neurocomputing 2020, 406, 12–23. [Google Scholar] [CrossRef]
- Tan, C.; Šarlija, M.; Kasabov, N. NeuroSense: Short-term emotion recognition and understanding based on spiking neural network modelling of spatio-temporal EEG patterns. Neurocomputing 2021, 434, 137–148. [Google Scholar] [CrossRef]
- Son, L.H.; Fujita, H. Neural-fuzzy with representative sets for prediction of student performance. Appl. Intell. 2019, 49, 172–187. [Google Scholar] [CrossRef]
- Mourad, N. Robust smoothing of one-dimensional data with missing and/or outlier values. IET Signal Process. 2021, 15, 323–336. [Google Scholar] [CrossRef]
- Xing, Y.Y.; Wu, X.Y.; Jiang, P.; Liu, Q. Dynamic Bayesian evaluation method for system reliability growth based on in-time correction. IEEE Trans. Reliab. 2010, 59, 309–312. [Google Scholar] [CrossRef]
- Oh, S.; Lee, S.; Woo, S.Y.; Kwon, D.; Im, J.; Hwang, J.; Bae, J.H.; Park, B.G.; Lee, J.H. Spiking Neural Networks With Time-to-First-Spike Coding Using TFT-Type Synaptic Device Model. IEEE Access 2021, 9, 78098–78107. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
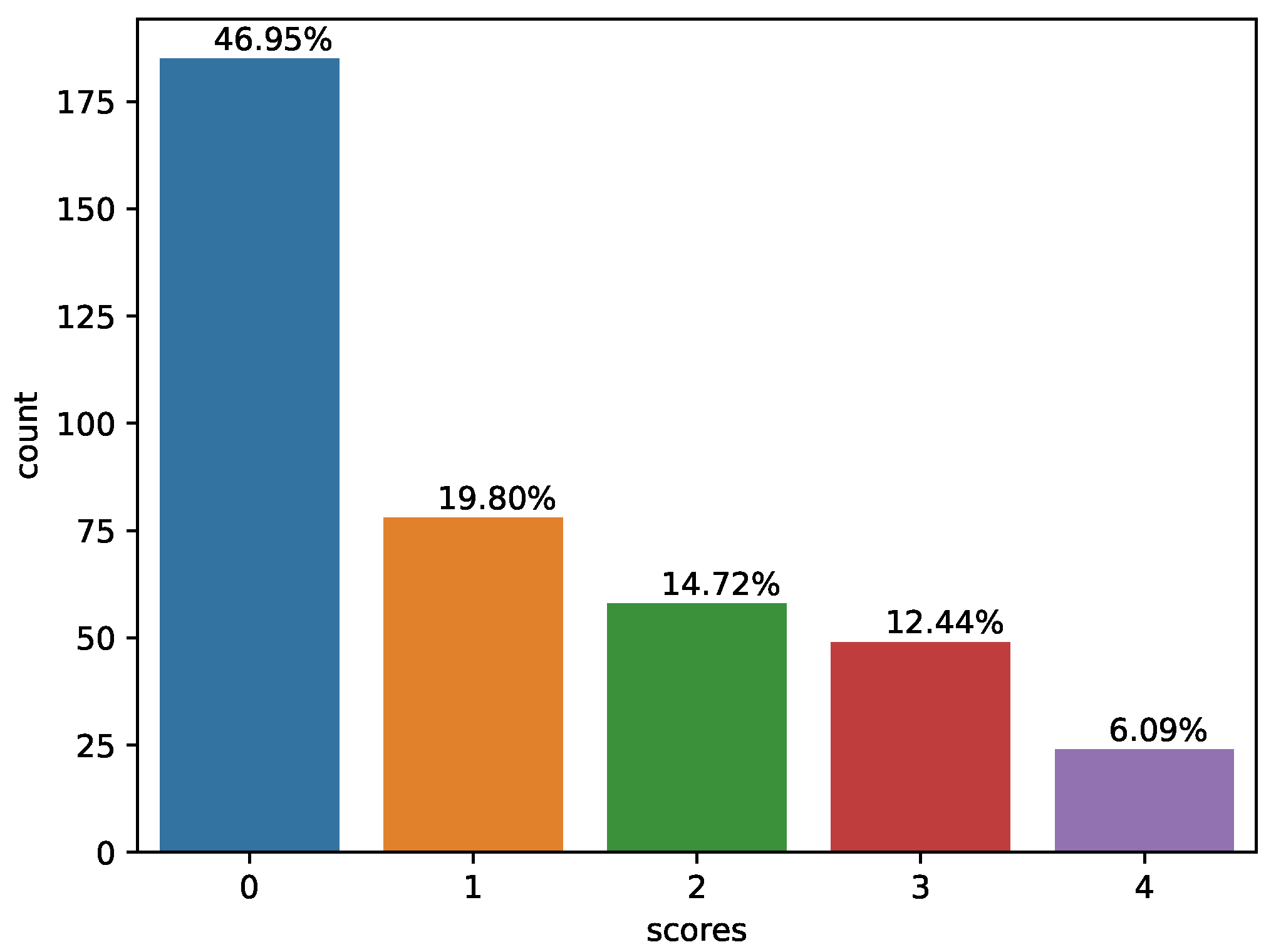{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Excellent/Very Good | Good | Satisfactory | Sufficient | Fail |
|---|---|---|---|---|---|
| Original value | 16–20 | 14–15 | 12–13 | 10–11 | 0–9 |
| Classification | A | B | C | D | E |
| Encoding | 4 | 3 | 2 | 1 | 0 |
| Actual Value | Positive | Negative | |
|---|---|---|---|
| Predicted Value | |||
| Positive | TP | FN | |
| Negative | FP | TN | |
| Algorithm | Class | Precision | Recall | F1-Score | Support | Accuracy |
|---|---|---|---|---|---|---|
| Logistic Regression | L | 0.87 | 1.00 | 0.93 | 26 | 0.7604166666666666 |
| M | 0.80 | 0.69 | 0.74 | 48 | ||
| H | 0.56 | 0.64 | 0.60 | 22 | ||
| Decision Tree | L | 0.73 | 0.85 | 0.79 | 26 | 0.7291666666666666 |
| M | 0.75 | 0.69 | 0.72 | 48 | ||
| H | 0.68 | 0.68 | 0.68 | 22 | ||
| XGBoost | L | 0.86 | 0.92 | 0.89 | 26 | 0.82133333334 |
| M | 0.86 | 0.79 | 0.83 | 48 | ||
| H | 0.75 | 0.82 | 0.78 | 22 | ||
| AdaBoost | L | 0.86 | 0.92 | 0.89 | 26 | 0.8333333333333334 |
| M | 0.90 | 0.75 | 0.82 | 48 | ||
| H | 0.69 | 0.91 | 0.78 | 22 | ||
| Neural Network | L | 0.86 | 0.92 | 0.89 | 26 | 0.71875 |
| M | 0.77 | 0.62 | 0.69 | 48 | ||
| H | 0.52 | 0.68 | 0.59 | 22 | ||
| SVM | L | 0.80 | 0.92 | 0.86 | 26 | 0.8020833333333334 |
| M | 0.81 | 0.79 | 0.80 | 48 | ||
| H | 0.79 | 0.68 | 0.73 | 22 | ||
| Proposed Algorithm | L | 0.77 | 0.77 | 0.77 | 26 | 0.84375 |
| M | 0.85 | 0.83 | 0.84 | 48 | ||
| H | 0.68 | 0.68 | 0.68 | 22 |
| Algorithm | Class | Precision | Recall | F1-Score | Support | Accuracy |
|---|---|---|---|---|---|---|
| Logistic Regression | A | 0.60 | 0.75 | 0.67 | 4 | 0.7215189873417721 |
| B | 0.75 | 0.64 | 0.69 | 14 | ||
| C | 0.33 | 0.62 | 0.43 | 8 | ||
| D | 0.69 | 0.43 | 0.53 | 21 | ||
| E | 0.91 | 0.97 | 0.94 | 32 | ||
| Decision Tree | A | 0.75 | 0.75 | 0.75 | 4 | 0.7468354430379747 |
| B | 0.90 | 0.64 | 0.75 | 14 | ||
| C | 0.38 | 0.75 | 0.50 | 8 | ||
| D | 0.71 | 0.57 | 0.63 | 21 | ||
| E | 0.91 | 0.91 | 0.91 | 32 | ||
| XGBoost | A | 1.00 | 0.25 | 0.40 | 4 | 0.7721518987341772 |
| B | 0.80 | 0.86 | 0.83 | 14 | ||
| C | 0.38 | 0.38 | 0.38 | 8 | ||
| D | 0.72 | 0.62 | 0.67 | 21 | ||
| E | 0.86 | 1.00 | 0.93 | 32 | ||
| AdaBoost | A | 0.00 | 0.00 | 0.00 | 4 | 0.46835443037974683 |
| B | 0.75 | 0.86 | 0.80 | 14 | ||
| C | 0.60 | 0.75 | 0.67 | 8 | ||
| D | 0.36 | 0.90 | 0.51 | 21 | ||
| E | 0.00 | 0.00 | 0.00 | 32 | ||
| Neural Network | A | 0.60 | 0.75 | 0.67 | 4 | 0.6835443037974683 |
| B | 0.73 | 0.57 | 0.64 | 14 | ||
| C | 0.33 | 0.50 | 0.40 | 8 | ||
| D | 0.67 | 0.38 | 0.48 | 21 | ||
| E | 0.79 | 0.97 | 0.87 | 32 | ||
| SVM | A | 1.00 | 1.00 | 1.00 | 4 | 0.7974683544303798 |
| B | 0.92 | 0.86 | 0.89 | 14 | ||
| C | 0.33 | 0.50 | 0.40 | 8 | ||
| D | 0.75 | 0.57 | 0.65 | 21 | ||
| E | 0.91 | 0.97 | 0.94 | 32 | ||
| Proposed Algorithm | A | 1.00 | 0.75 | 0.86 | 4 | 0.8140212658227848 |
| B | 0.92 | 0.86 | 0.89 | 14 | ||
| C | 0.50 | 0.75 | 0.60 | 8 | ||
| D | 0.83 | 0.71 | 0.77 | 21 | ||
| E | 0.94 | 0.97 | 0.95 | 32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Wang, H.; Du, Y.; Yuan, Z. A Predictive Model for Student Achievement Using Spiking Neural Networks Based on Educational Data. Appl. Sci. 2022, 12, 3841. https://doi.org/10.3390/app12083841
Liu C, Wang H, Du Y, Yuan Z. A Predictive Model for Student Achievement Using Spiking Neural Networks Based on Educational Data. Applied Sciences. 2022; 12(8):3841. https://doi.org/10.3390/app12083841
Chicago/Turabian StyleLiu, Chuang, Haojie Wang, Yingkui Du, and Zhonghu Yuan. 2022. "A Predictive Model for Student Achievement Using Spiking Neural Networks Based on Educational Data" Applied Sciences 12, no. 8: 3841. https://doi.org/10.3390/app12083841
APA StyleLiu, C., Wang, H., Du, Y., & Yuan, Z. (2022). A Predictive Model for Student Achievement Using Spiking Neural Networks Based on Educational Data. Applied Sciences, 12(8), 3841. https://doi.org/10.3390/app12083841