
Burapha-TH: A Multi-Purpose Character, Digit, and Syllable Handwriting Dataset


Abstract
:1. Introduction
2. Overview of Thai Language Script
2.1. The Characteristics of Thai Characters
2.1.1. Consonants
2.1.2. Vowels
2.1.3. Tone Markers
2.1.4. Digits
2.2. How to Write
2.2.1. Character Head
2.2.2. Path of the Line
2.2.3. Character Size
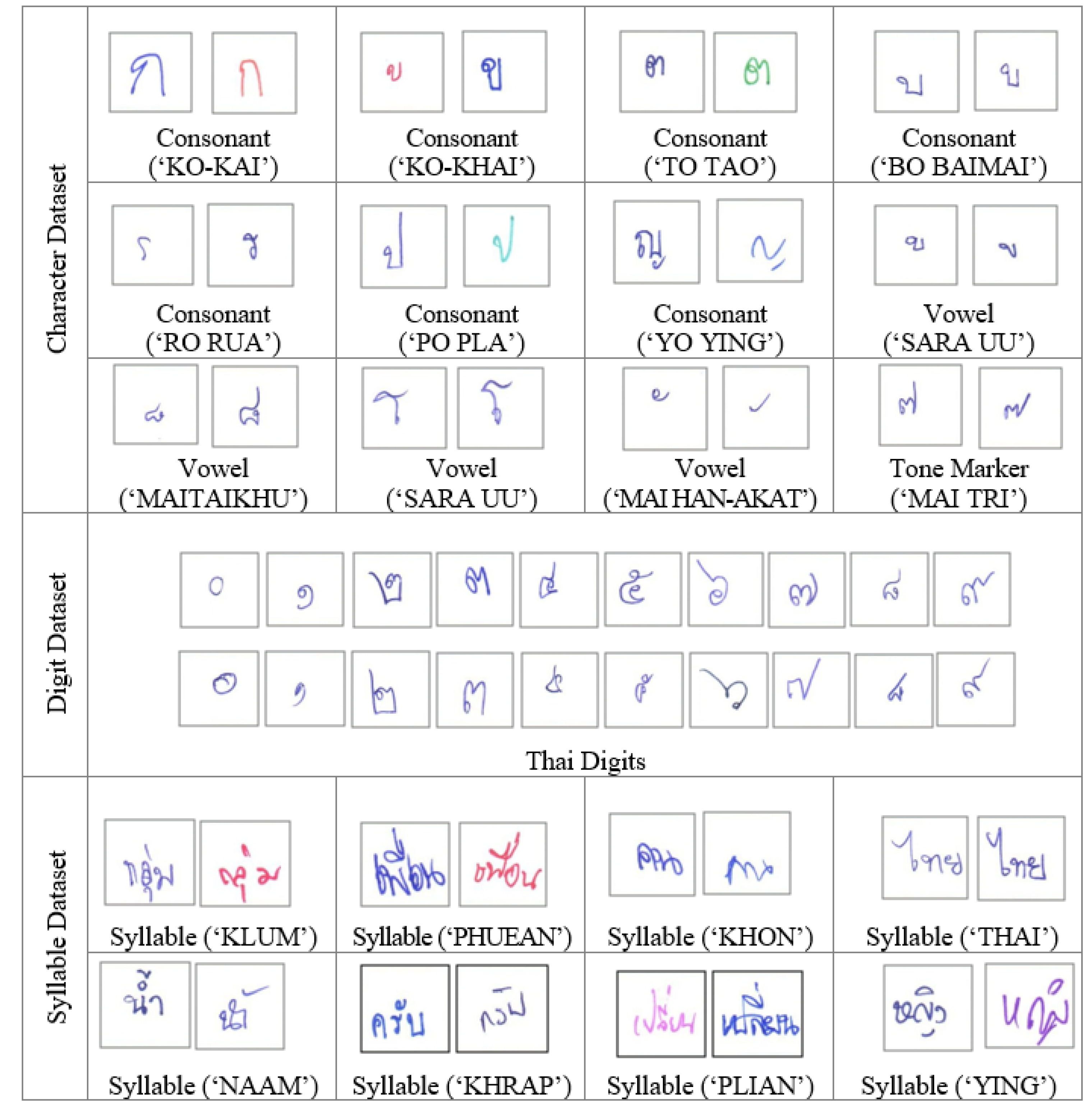
3. Burapha-TH Dataset Construction
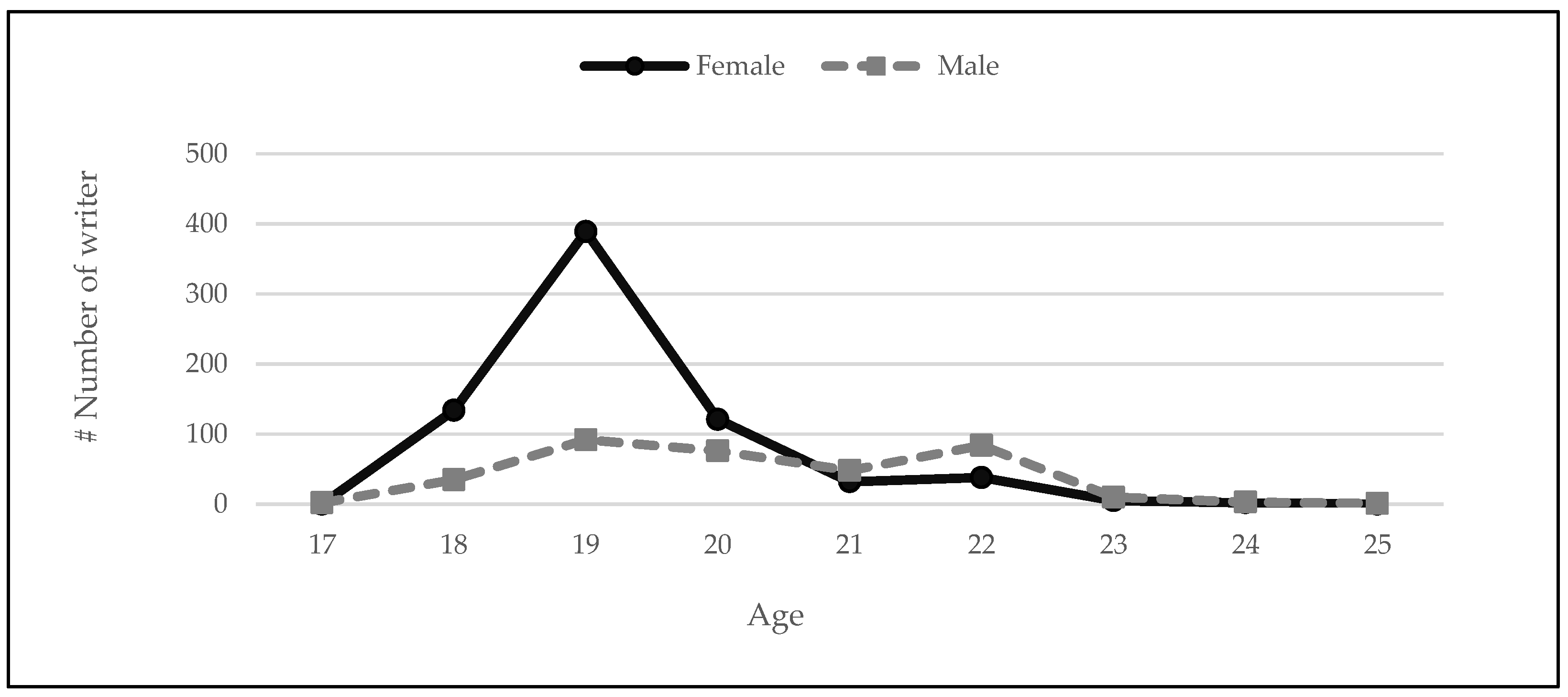
3.1. Writers
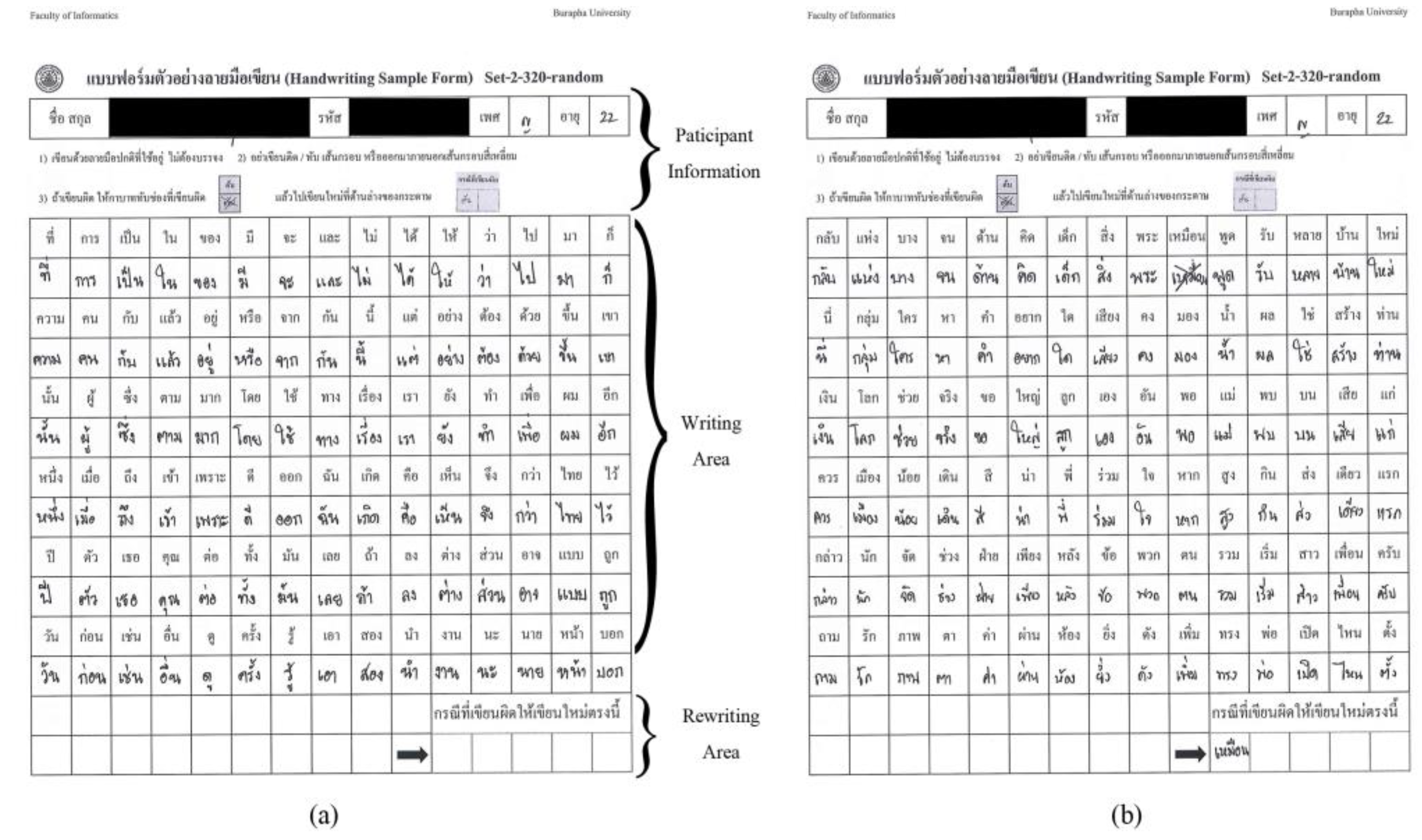
3.2. Data Collection Sheets
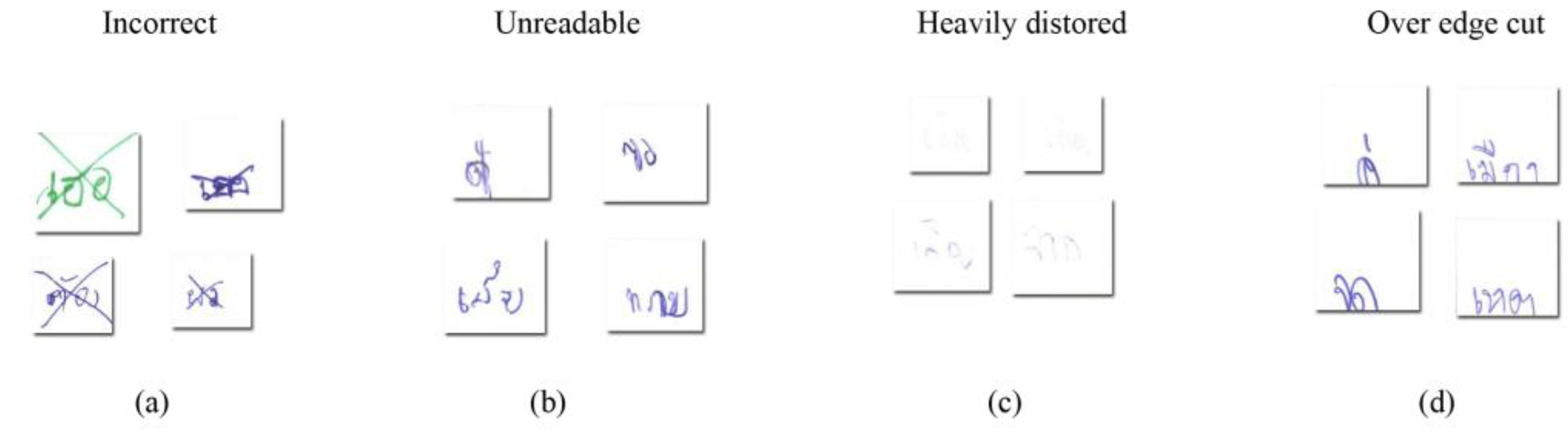
3.3. Data Preparation Process
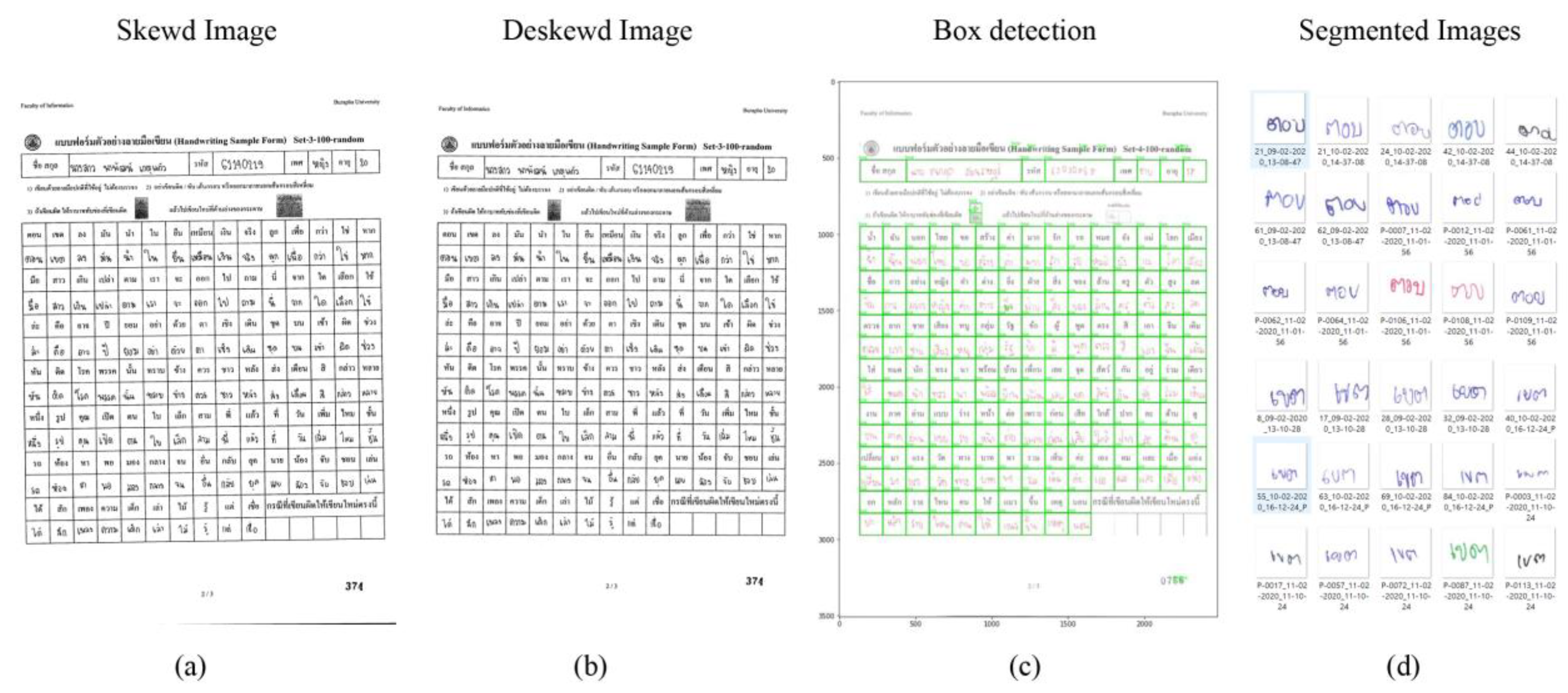
3.3.1. Image Deskewing
| Algorithm 1: Pseudo-code of Image_deskewing. |
| Input: dm #a original handwritten form image Output: ddm #a deskewing handwritten from image Procedure DeskewingImage(dm) 1: begin 2: from services.DatasetService import DatasetService 3: from services.DeskewService import DeskewService 4: from services.GraphicsService import GraphicsService 5: imageCv = GraphicsService().openImageCv(dm) 6: imagePath = dm.ImagePath() 7: deskewedImage, guessedAngle = DeskewService().deskew(imageCv) 8: if (guessedAngle < −20.0): 9: dd = GraphicsService().rotateImage(imageCv,(guessedAngle + 90.)* 1.0) 10: end if 11: DatasetService().saveData(imagePath, deskewedImage) 12: end |
3.3.2. Line Detection
| Algorithm 2: Pseudo-code of Line_detection. |
| Input: ddm #a deskewing handwritten from image Output: stats, labels # stat matrix and the label matrix Procedure DetectionBox(ddm, line_min_width = 5) 1: begin 2: gray_scale = convert ddm to gray scale 3: img_bin_h = find the outline of the horizontal gray_scale object 4: img_bin_v = find the outline of the veritical gray_scale object 5: img_bin_final = img_bin_h|img_bin_v 6: img_bin_final = increases the white region in the img_bin_final image 7: ret, labels, stats, centroids = Perform the operation of img_bin_final 8: end |
3.3.3. Image Segmentation
| Algorithm 3: Pseudo-code of Image_segmentation. |
| Input: D = {d1, d2, d3,…, d|D|} #a set of handwritten form image Output: DL = {dl1, dl2, dl3,…, dl|D|} #a set of segmented handwritten image Procedure LineDetection(DD) 1: begin 2: for each document dm in D do 3: ddm = DeskewingImage(dm) 4: stats, labels = DetectionBox(ddm, line_min_width = 5) 5: for left, top, width, height, area in stats [2:] do 6: if (top > 800 and width > 100 and height > 100) 7: dl = ddm [top: top + height, left: left + width] 8: append dl in a set of segmented handwritten image DL 9: end if 10: end for 11: end for 12: end |
3.4. Statistical Properties
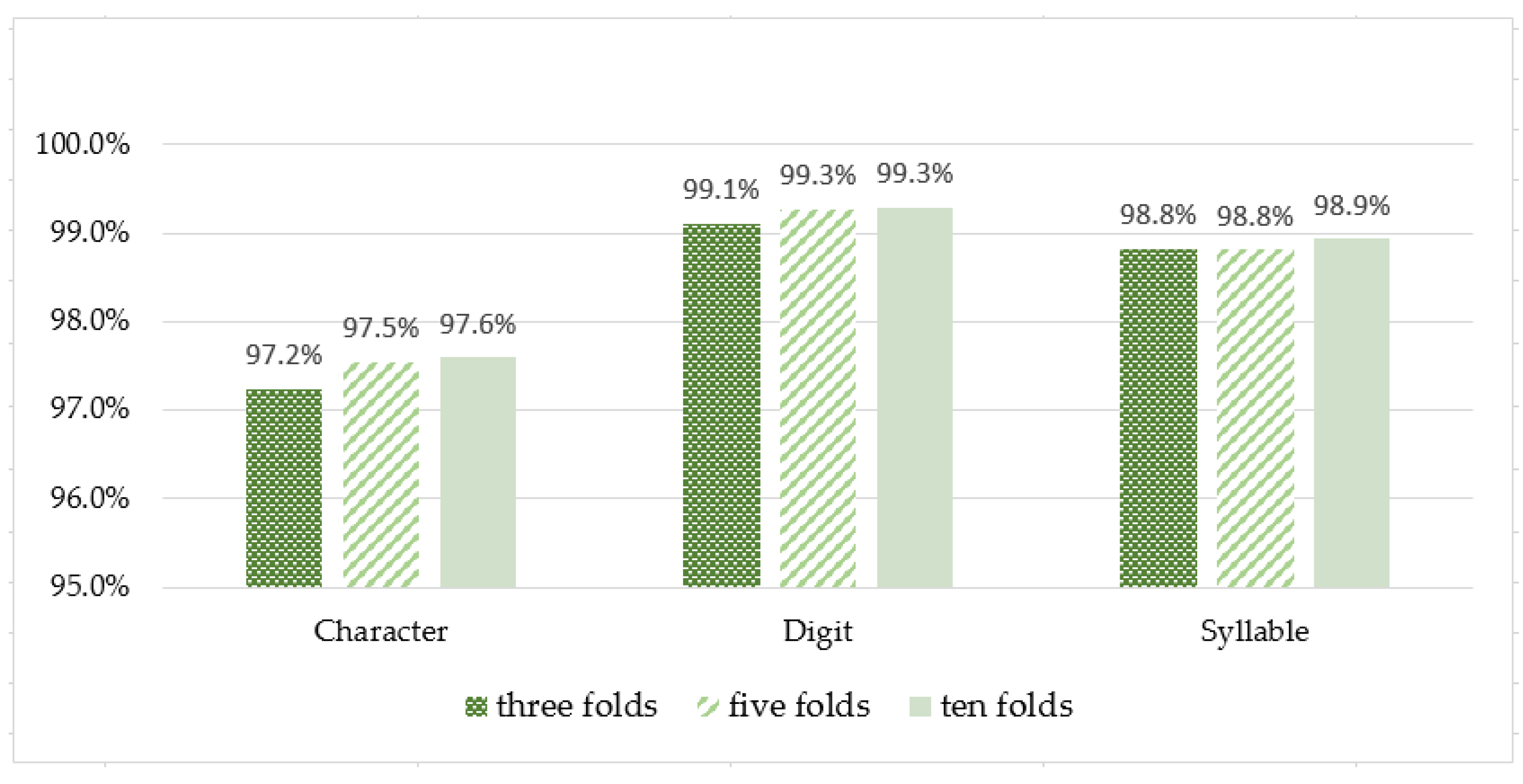
4. Experiments and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Consonants (44) | |||
|---|---|---|---|
| ก | 00-161-A1-KO KAI | ท | 22-183-B7-THO THAHAN |
| ข | 01-162-A2-KHO KHAI | ธ | 23-184-B8-THO THONG |
| ฃ | 02-163-A3-KHO KHUAT | น | 24-185-B9-NO NU |
| ค | 03-164-A4-KHO KHWAI | บ | 25-186-BA-BO BAIMAI |
| ต | 04-165-A5-KHO KHON | ป | 26-187-BB-PO PLA |
| ฆ | 05-166-A6-KHO RAKHANG | ผ | 27-188-BC-PHO PHUNG |
| ง | 06-167-A7-NGO NGU | ฝ | 28-189-BD-FO FA |
| จ | 07-168-A8-CHO CHAN | พ | 29-190-BE-PHO PHAN |
| ฉ | 08-169-A9-CHO CHING | ฟ | 30-191-BF-FO FAN |
| ช | 09-170-AA-CHO CHANG | ภ | 31-192-C0-PHO SAMPHAO |
| ซ | 10-171-AB-SO SO | ม | 32-193-C1-MO MA |
| ฌ | 11-172-AC-CHO CHOE | ย | 33-194-C2-YO YAK |
| ญ | 12-173-AD-YO YING | ร | 34-195-C3-RO RUA |
| ฎ | 13-174-AE-DO CHADA | ล | 36-197-C5-LO LING |
| ฏ | 14-175-AF-TO PATAK | ว | 38-199-C7-WO WAEN |
| ฐ | 15-176-B0-THO THAN | ศ | 39-200-C8-SO SALA |
| ฑ | 16-177-B1-THO NANGMONTHO | ษ | 40-201-C9-SO RUSI |
| ฒ | 17-178-B2-THO PHUTHAO | ส | 41-202-CA-SO SUA |
| ณ | 18-179-B3-NO NEN | ห | 42-203-CB-HO HIP |
| ด | 19-180-B4-DO DEK | ฬ | 43-204-CC-LO CHULA |
| ต | 20-181-B5-TO TAO | อ | 44-205-CD-O ANG |
| ถ | 21-182-B6-THO THUNG | ฮ | 45-206-CE-HO NOKHUK |
| Vowels (20) | |||
| ฯ | 46-207-CF-PAIYANNOI | ู | 56-217-D9-SARA UU |
| ะ | 47-208-D0-SARA A | เ | 57-224-E0-SARA E |
| ั | 48-209-D1-MAI HAN-AKAT | แ | 58-225-E1-SARA AE |
| า | 49-210-D2-SARA AA | โ | 59-226-E2-SARA O |
| ำ | 50-211-D3-SARA AM | ใ | 60-227-E3-SARA AI MAIMUAN |
| ิ | 51-212-D4-SARA I | ไ | 61-228-E4-SARA AI MAIMALAI |
| ี | 52-213-D5-SARA II | ็ | 62-231-E7-MAITAIKHU |
| ึ | 53-214-D6-SARA UE | ์ | 67-236-EC-THANTHAKHAT |
| ื | 54-215-D7-SARA UEE | ฤ | 35-196-C4-RU |
| ุ | 55-216-D8-SARA U | ฦ | 37-198-C6-LU |
| Tone Markers (4) | |||
| ่ | 63-232-E8-MAI EK | ๊ | 65-234-EA-MAI TRI |
| ้ | 64-233-E9-MAI THO | ๋ | 66-235-EB-MAI CHATTAWA |
| Digits (10) | |||
|---|---|---|---|
| ๐ | 68-240-F0-THAI DIGIT ZERO | ๕ | 73-245-F5-THAI DIGIT FIVE |
| ๑ | 69-241-F1-THAI DIGIT ONE | ๖ | 74-246-F6-THAI DIGIT SIX |
| ๒ | 70-242-F2-THAI DIGIT TWO | ๗ | 75-247-F7-THAI DIGIT SEVEN |
| ๓ | 71-243-F3-THAI DIGIT THREE | ๘ | 76-248-F8-THAI DIGIT EIGHT |
| ๔ | 72-244-F4-THAI DIGIT FOUR | ๙ | 77-249-F9-THAI DIGIT NINE |
| Syllables (320) | |||||
|---|---|---|---|---|---|
| เก็บ | 000-KEP1 | เมื่อ | 31-MUEA2 | แรง | 62-RAENG0 |
| เกิด | 001-KOET1 | เมือง | 32-MUEANG0 | แล้ว | 63-LAEO3 |
| เกิน | 002-KOEN0 | เรา | 33-RAO0 | และ | 64-LAE3 |
| เขต | 003-KHEET1 | เริ่ม | 34-ROEM2 | แห่ง | 65-HAENG1 |
| เขา | 004-KHAO4 | เรียก | 35-RIAK2 | โดย | 66-DOI0 |
| เข้า | 005-KHAO2 | เรียน | 36-RIAN0 | โต | 67-TOO0 |
| เขียน | 006-KHIAN4 | เรื่อง | 37-RUEANG2 | โรค | 68-ROOK2 |
| เครื่อง | 007-KHRUEANG2 | เล็ก | 38-LEK3 | โลก | 69-LOOK2 |
| เงิน | 008-NGOEN0 | เล่น | 39-LEN2 | ใกล้ | 70-KLAI2 |
| เจอ | 009-JOOE0 | เลย | 40-LOEI0 | ใคร | 71-KHRAI0 |
| เจ้า | 010-JAAO2 | เล่า | 41-LAO2 | ใจ | 72-JAI0 |
| เช่น | 011-CHEN2 | เลือก | 42-LUEAK2 | ใช่ | 73-CHAI2 |
| เชิง | 012-CHOENG0 | เสีย | 43-SIA4 | ใช้ | 74-CHAI3 |
| เชื่อ | 013-CHUEA2 | เสียง | 44-SIANG4 | ใด | 75-DAI0 |
| เด็ก | 014-DEK1 | เหตุ | 45-HEET1 | ใน | 76-NAI0 |
| เดิน | 015-DOEN0 | เห็น | 46-HEN4 | ใบ | 77-BAI0 |
| เดิม | 016-DOEM0 | เหมือน | 47-MUEAN4 | ใส่ | 78-SAI1 |
| เดียว | 017-DIAO0 | เหลือ | 48-LUEA4 | ให้ | 79-HAI2 |
| เดือน | 018-DUEAN0 | เอง | 49-EENG0 | ใหญ่ | 80-YAI1 |
| เท่า | 019-THAO0 | เอา | 50-AO0 | ใหม่ | 81-MAI1 |
| เธอ | 20-THOOE0 | แก | 51-KAAE0 | ไง | 82-NGAI0 |
| เป็น | 21-PEN0 | แก่ | 52-KAAE1 | ได้ | 83-DAI2 |
| เปล่า | 22-PLAAO1 | แก้ | 53-KAAE2 | ไทย | 84-THAI0 |
| เปลี่ยน | 23-PLIAN1 | แดง | 54-DAENG0 | ไป | 85-PAI0 |
| เปิด | 24-POOET1 | แต่ | 55-TAAE1 | ไม่ | 86-MAI2 |
| เพราะ | 25-PHROR3 | แทน | 56-THAAEN0 | ไม้ | 87-MAI3 |
| เพลง | 26-PHLEENG0 | แนว | 57-NAAEO0 | ไว้ | 88-WAI3 |
| เพิ่ม | 27-PHOEM2 | แบบ | 58-BAEP0 | ไหน | 89-NAI4 |
| เพียง | 28-PHIANG0 | แพทย์ | 59-PHAET2 | ไหม | 90-MAI4 |
| เพื่อ | 29-PHUEA2 | แม่ | 60-MAE2 | ก็ | 91-KOR2 |
| เพื่อน | 30-PHUEAN2 | แรก | 61-RAEK2 | กลับ | 92-KLAP1 |
| Syllables | |||||
| กลาง | 93-KLANG0 | จะ | 132-JA1 | ติด | 171-TIT1 |
| กล่าว | 94-KLAAO1 | จัด | 133-JAT1 | ถ้า | 172-THAA2 |
| กลุ่ม | 95-KLUM1 | จับ | 134-JAP1 | ถาม | 173-THAAM4 |
| กว่า | 96-KWAA1 | จาก | 135-JAAK1 | ถึง | 174-THUENG4 |
| ก่อน | 97-KORN1 | จิต | 136-JIT1 | ถือ | 175-THUE4 |
| กัน | 98-KAN0 | จีน | 137-JIIN0 | ถูก | 176-THUUK1 |
| กับ | 99-KAP1 | จึง | 138-JUENG0 | ทรง | 177-SONG0 |
| การ | 100-KAAN0 | จุด | 139-JUT1 | ทราบ | 178-SAAP2 |
| กิน | 101-KIN0 | ฉัน | 140-CHAN4 | ทั้ง | 179-THANG3 |
| ขอ | 102-KHOR4 | ช่วง | 141-CHUANG2 | ทั่ว | 180-THAW1 |
| ข้อ | 103-KHOR2 | ช่วย | 142-CHUAI2 | ทาง | 181-THAANG0 |
| ของ | 104-KHORNG4 | ชอบ | 143-CHORP2 | ท่าน | 182-THAAN2 |
| ข้าง | 105-KHAANG2 | ชั้น | 144-CHAN3 | ทำ | 183-THAM0 |
| ขาด | 106-KHAD0 | ชาติ | 145-CHAAT2 | ที | 184-THII0 |
| ขาย | 107-KHAAI4 | ชาย | 146-CHAAI0 | ที่ | 185-THII2 |
| ขาว | 108-KHAAO4 | ชาว | 147-CHAAO0 | นอก | 186-NORK2 |
| ข่าว | 109-KHAAO1 | ชื่อ | 148-CHUE2 | น้อง | 187-NORNG3 |
| ข้าว | 110-KHAAO2 | ชุด | 149-CHUT3 | นอน | 188-NORN0 |
| ขึ้น | 111-KHUEN2 | ซึ่ง | 150-SUENG2 | น้อย | 189-NOI3 |
| คง | 112-KHONG0 | ซื้อ | 151-SUE3 | นะ | 190-NA3 |
| คน | 113-KHON0 | ด้วย | 152-DUAI2 | นัก | 191-NAK3 |
| ครั้ง | 114-KHRANG3 | ดัง | 153-DANG0 | นั่ง | 192-NANG2 |
| ครับ | 115-KHRAP3 | ด้าน | 154-DAAN2 | นั้น | 193-NAN3 |
| ครู | 116-KHRUU0 | ดี | 155-DII0 | นา | 194-NAA0 |
| ควร | 117-KHUAN0 | ดู | 156-DUU0 | น่า | 195-NAA2 |
| ความ | 118-KHWAAM0 | ตน | 157-TON0 | นาน | 196-NAAN0 |
| ค่ะ | 119-KHA2 | ต้น | 158-TON2 | นาย | 197-NAAI0 |
| ค่า | 120-KHAA2 | ตรง | 159-TRONG0 | นำ | 198-NAM0 |
| คำ | 121-KHAM0 | ตรวจ | 160-TRUAT1 | น้ำ | 199-NAAM3 |
| คิด | 122-KHIT3 | ต่อ | 161-TOR1 | นี่ | 200-NII2 |
| คืน | 123-KHUEN0 | ต้อง | 162-TORNG2 | นี้ | 201-NII3 |
| คือ | 124-KHUE0 | ตอน | 163-TORN0 | บท | 202-BOT1 |
| คุณ | 125-KHUN0 | ตอบ | 164-TORP0 | บน | 203-BON0 |
| คู่ | 126-KHUU2 | ตั้ง | 165-TANG2 | บอก | 204-BORK1 |
| งาน | 127-NGAAN0 | ตัว | 166-TUA0 | บาง | 205-BAANG0 |
| ง่าย | 128-NGAAI2 | ตา | 167-TAA0 | บาท | 206-BAAT1 |
| จน | 129-JON0 | ต่าง | 168-TAANG1 | บ้าน | 207-BAAN2 |
| จบ | 130-JOP1 | ตาม | 169-TAAM0 | ปรับ | 208-PRAP1 |
| จริง | 131-JING0 | ตาย | 170-TAAI0 | ปล่อย | 209-PLOI1 |
| Syllables | |||||
| ปลา | 210-PLAA0 | ยิ่ง | 247-YING2 | สาย | 284-SAAI4 |
| ปาก | 211-PAAK1 | ยิ้ม | 248-YIM3 | สาว | 285-SAAO4 |
| ปี | 212-PII0 | ยืน | 249-YUEN0 | สิ | 286-SI1 |
| ผม | 213-PHOM4 | ยุค | 250-YUK3 | สิ่ง | 287-SING1 |
| ผล | 214-PHON4 | รถ | 251-ROT3 | สิบ | 288-SIP1 |
| ผ่าน | 215-PHAAN1 | รวม | 252-RUAM0 | สี | 289-SII4 |
| ผิด | 216-PHIT1 | ร่วม | 253-RUAM2 | สุข | 290-SUK1 |
| ผู้ | 217-PHUU2 | รอ | 254-ROR0 | สู่ | 291-SUU1 |
| ฝ่าย | 218-FAAI1 | รอบ | 255-RORP2 | สูง | 292-SUUNG4 |
| พบ | 219-PHOP3 | รัก | 256-RAK3 | หญิง | 293-YING4 |
| พรรค | 220-PHAK3 | รัฐ | 257-RAT3 | หน้า | 294-NAA2 |
| พร้อม | 221-PHRORM3 | รับ | 258-RAP3 | หนึ่ง | 295-NUENG1 |
| พระ | 222-PHRA3 | ร่าง | 259-RAANG2 | หนู | 296-NUU4 |
| พวก | 223-PHUAK2 | ร้าน | 260-RAAN3 | หมด | 297-MOT1 |
| พอ | 224-PHOR0 | ราย | 261-RAAI0 | หมอ | 298-MOR4 |
| พ่อ | 225-PHOR2 | รีบ | 262-RIIP2 | หรือ | 299-RUE4 |
| พา | 226-PHAA0 | รู้ | 263-RUU3 | หลัก | 300-LAK1 |
| พี่ | 227-PHII2 | รูป | 264-RUUP2 | หลัง | 301-LANG4 |
| พูด | 228-PHUUT2 | ลง | 265-LONG0 | หลาย | 302-LAAI4 |
| ฟัง | 229-FANG0 | ลด | 266-LOT3 | ห้อง | 303-HORNG2 |
| ภาค | 230-PHAAK2 | ละ | 267-LA3 | หัน | 304-HAN4 |
| ภาพ | 231-PHAAP2 | ล่ะ | 268-LA4 | หัว | 305-HUA4 |
| มอง | 232-MORNG0 | ล้าน | 269-LAAN3 | หา | 306-HAA4 |
| มัก | 233-MAK3 | ลูก | 270-LUUK2 | หาก | 307-HAAK1 |
| มัน | 234-MAN0 | วัด | 271-WAT3 | หาย | 308-HAAI4 |
| มา | 235-MAA0 | วัน | 272-WAN0 | อย่า | 309-YAA1 |
| มาก | 236-MAAK2 | ว่า | 273-WAA2 | อยาก | 310-YAAK1 |
| มิ | 237-MI3 | วาง | 274-WAANG0 | อย่าง | 311-YAANG1 |
| มี | 238-MII0 | ส่ง | 275-SONG1 | อยู่ | 312-YOO1 |
| มือ | 239-MUE0 | สร้าง | 276-SAANG2 | ออก | 313-ORK1 |
| ยก | 240-YOK3 | ส่วน | 277-SUAN1 | อัน | 314-AN0 |
| ยอม | 241-YORM0 | สวย | 278-SUAI4 | อา | 315-ARE0 |
| ย่อม | 242-YORM2 | สอง | 279-SORNG4 | อาจ | 316-AAT1 |
| ยัง | 243-YANG0 | สอน | 280-SORN4 | อีก | 317-IIK1 |
| ยา | 244-YAA0 | สัก | 281-SAK1 | อ่าน | 318-AAN1 |
| ยาก | 245-YAAK2 | สัตว์ | 282-SAT1 | อื่น | 319-UEN1 |
| ยาว | 246-YAAO0 | สาม | 283-SAAM4 | ||
References
- Singh, A.; Bacchuwar, K.; Bhasin, A. A survey of OCR applications. Int. J. Mach. Learn. Comput. 2012, 2, 314. [Google Scholar] [CrossRef] [Green Version]
- Jangid, M.; Srivastava, S. Handwritten Devanagari character recognition using layer-wise training of deep convolutional neural networks and adaptive gradient methods. J. Imaging 2018, 4, 41. [Google Scholar] [CrossRef] [Green Version]
- Ahlawat, S.; Choudhary, A.; Nayyar, A.; Singh, S.; Yoon, B. Improved handwritten digit recognition using convolutional neural networks (CNN). Sensors 2020, 20, 3344. [Google Scholar] [CrossRef] [PubMed]
- Arora, S.; Bhatia, M.S. Handwriting recognition using deep learning in keras. In Proceedings of the 2018 International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida, India, 12–13 October 2018; pp. 142–145. [Google Scholar]
- Vaidya, R.; Trivedi, D.; Satra, S.; Pimpale, P.M. Handwritten Character Recognition Using Deep-Learning. In Proceedings of the second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; pp. 772–775. [Google Scholar] [CrossRef]
- Eltay, M.; Zidouri, A.; Ahmad, I. Exploring deep learning approaches to recognize handwritten Arabic texts. IEEE Access 2020, 8, 89882–89898. [Google Scholar] [CrossRef]
- LeCun, Y.A. The MNIST Database of Handwritten Digits. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 1 March 2021).
- Cohen, G.; Afshar, S.; Tapson, J.; Van Schaik, A. EMNIST: Extending MNIST to handwritten letters. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2921–2926. [Google Scholar] [CrossRef]
- Liu, C.L.; Yin, F.; Wang, D.H.; Wang, Q.F. CASIA online and offline Chinese handwriting databases. In Proceedings of the International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 37–41. [Google Scholar] [CrossRef]
- Clanuwat, T.; Bober-Irizar, M.; Kitamoto, A.; Lamb, A.; Yamamoto, K.; Ha, D. Deep learning for classical Japanese literature. arXiv 2018, arXiv:1812.01718. [Google Scholar]
- Manjusha, K.; Kumar, M.A.; Soman, K.P. On developing handwritten character image database for Malayalam language script. Eng. Sci. Technol. Int. J. 2019, 22, 637–645. [Google Scholar] [CrossRef]
- Kim, I.J.; Xie, X. Handwritten Hangul recognition using deep convolutional neural networks. Int. J. Doc. Anal. Recognit. (IJDAR) 2015, 18, 1–13. [Google Scholar] [CrossRef]
- KIM, D.H.; Hwang, Y.S.; Park, S.T.; Kim, E.J.; Paek, S.H.; BANG, S.Y. Handwritten Korean character image database PE92. IEICE Trans. Inf. Syst. 1996, 79, 943–950. [Google Scholar]
- Sae-Tang, S.; Methasate, L. Thai handwritten character corpus. IEEE Int. Symp. Commun. Inf. Technol. 2004, 1, 486–491. [Google Scholar] [CrossRef]
- Surinta, O.; Karaaba, M.F.; Schomaker, L.R.; Wiering, M.A. Recognition of handwritten characters using local gradient feature descriptors. Eng. Appl. Artif. Intell. 2015, 45, 405–414. [Google Scholar] [CrossRef]
- Liu, C.L.; Nakagawa, M. Evaluation of prototype learning algorithms for nearest-neighbor classifier in application to handwritten character recognition. Pattern Recognit. 2001, 34, 601–615. [Google Scholar] [CrossRef]
- Ciresan, D.C.; Meier, U.; Gambardella, L.M.; Schmidhuber, J. Convolutional neural network committees for handwritten character classification. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 1135–1139. [Google Scholar] [CrossRef] [Green Version]
- Pratt, S.; Ochoa, A.; Yadav, M.; Sheta, A.; Eldefrawy, M. Handwritten digits recognition using convolution neural networks. J. Comput. Sci. Coll. 2019, 34, 40–46. [Google Scholar]
- Michie, D.; Spiegelhalter, D.J.; Taylor, C.C. Machine Learning, Neural and Statistical Classification; Ellis Horwood Ltd.: Chichester, UK, 1994. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Uppakitsinlapasn. Principles of Thai Language—Akkhawawithi, Wachiwiphak, Wakkayasamphan, Chanthalak. Thai Wattana Phanit Publisher: Bangkok, Thailand, 1931. (In Thailand) [Google Scholar]
- Iwasaki, S.; Ingkaphirom, P.; Horie, I.P. A Reference Grammar of Thai; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Koanantakool, H.T.; Karoonboonyanan, T.; Wutiwiwatchai, C. Computers and the Thai language. IEEE Ann. Hist. Comput. 2009, 31, 46–61. [Google Scholar] [CrossRef]
- Flachot, A.; Gegenfurtner, K.R. Color for object recognition: Hue and chroma sensitivity in the deep features of convolutional neural networks. Vis. Res. 2021, 182, 89–100. [Google Scholar] [CrossRef] [PubMed]
- Bradski, G. The open CV library. Dr. Dobb’s J. Softw. Tools Prof. Program. 2000, 25, 120–123. [Google Scholar]
- Ertuna, L. (n.d.) Open CV Library: GitHub—JPLeoRX/Opencv-text-deskew. Available online: https://github.com/JPLeoRX/opencv-text-deskew (accessed on 1 December 2021).








| Before (5) | After (5) | Above (5) | Below (2) |
|---|---|---|---|
| เ | ะ | ิ | ุ |
| แ | า | ี | ู |
| ไ | ำ | ึ | |
| ใ | ฤ | ื | |
| โ | ฦ | ั |
| Category | Collection Sheets | Segmented Images | Image Dataset |
|---|---|---|---|
| Character + Digit | 1156 | 107,506 | 87,600 |
| Syllable | 1920 | 279,730 | 268,056 |
| Total | 3076 | 387,236 | 355,656 |
| Statistic Topics | Character Dataset | Digit Dataset | Syllable Dataset |
|---|---|---|---|
| Number of Class | 68 | 10 | 320 |
| Number of Train sample | 63,327 | 8673 | 236,056 |
| Number of Test sample | 13,600 | 2000 | 32,000 |
| Average sample in Train/class | 931 | 867 | 738 |
| Min—Max sample in Train/class | 790–995 | 772–923 | 503–905 |
| Number of samples in Test/class | 200 | 200 | 100 |
| Total | 3076 | 387,236 | 355,656 |
| Dataset | Recognizer | Recognition Accuracy (%) | ||
|---|---|---|---|---|
| Training | Validation | Testing | ||
| CNN (4 conv) | 87.34 | 75.28 | 78.51 | |
| Character | LeNet-5 | 88.16 | 75.42 | 78.84 |
| VGG_13_BN | 97.88 | 92.64 | 95.00 | |
| CNN (4 conv) | 94.01 | 83.00 | 83.93 | |
| Digit | LeNet-5 | 95.40 | 85.63 | 87.26 |
| VGG_13_BN | 98.51 | 94.03 | 98.29 | |
| CNN (4 conv) | 83.61 | 75.00 | 78.25 | |
| Syllable | LeNet-5 | 76.15 | 71.64 | 74.98 |
| VGG_13_BN | 98.41 | 94.40 | 96.16 | |
| Dataset | Language | Year | Content | Class | No. of Writers | Statistics (Train/Validate/Test) |
|---|---|---|---|---|---|---|
| MNIST | EN | 1998 | Digit | 10 | - | 60,000/0/10,000 |
| EMNIST | EN | 2017 | Letter | 26 | >500 | 124,800/0/20,800 |
| CASIA-HWDB | CN | 2011 | Text, Character | 7356 | 1020 | 3.5 M isolated character, 1.35 M characters in text |
| Kuzushiji-49 | JP | 2016 | Character | 49 | - | 232,365/0/38,547 |
| Malayalam | IN | 2019 | Character | 85 | 77 | 17,236/5706/6360 |
| PE92 | KR | 1992 | Syllable | 2350 | ~100 per class | |
| SERI95 | KR | 1997 | Syllable | 520 | 465,675/0/51,785 | |
| Thai handwritten character corpus 1 | TH | 2004 | Character | 79 | 143 | 14,000 |
| ALICE-THI | TH | 2015 | Character | 68 | 150 | 13,138/0/1360 |
| ALICE-THI | TH | 2015 | Digit | 10 | 150 | 8555/0/1000 |
| Burapha-TH | TH | 2021 | Character | 68 | 1072 | 63,327/0/13,600 |
| Burapha-TH | TH | 2021 | Digit | 10 | 8673/0/2000 | |
| Burapha-TH | TH | 2021 | Syllable | 320 | 236,056/0/32,000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Onuean, A.; Buatoom, U.; Charoenporn, T.; Kim, T.; Jung, H. Burapha-TH: A Multi-Purpose Character, Digit, and Syllable Handwriting Dataset. Appl. Sci. 2022, 12, 4083. https://doi.org/10.3390/app12084083
Onuean A, Buatoom U, Charoenporn T, Kim T, Jung H. Burapha-TH: A Multi-Purpose Character, Digit, and Syllable Handwriting Dataset. Applied Sciences. 2022; 12(8):4083. https://doi.org/10.3390/app12084083
Chicago/Turabian StyleOnuean, Athita, Uraiwan Buatoom, Thatsanee Charoenporn, Taehong Kim, and Hanmin Jung. 2022. "Burapha-TH: A Multi-Purpose Character, Digit, and Syllable Handwriting Dataset" Applied Sciences 12, no. 8: 4083. https://doi.org/10.3390/app12084083
APA StyleOnuean, A., Buatoom, U., Charoenporn, T., Kim, T., & Jung, H. (2022). Burapha-TH: A Multi-Purpose Character, Digit, and Syllable Handwriting Dataset. Applied Sciences, 12(8), 4083. https://doi.org/10.3390/app12084083