4.5.1. Reference Co-Citation Network Analysis
As shown in
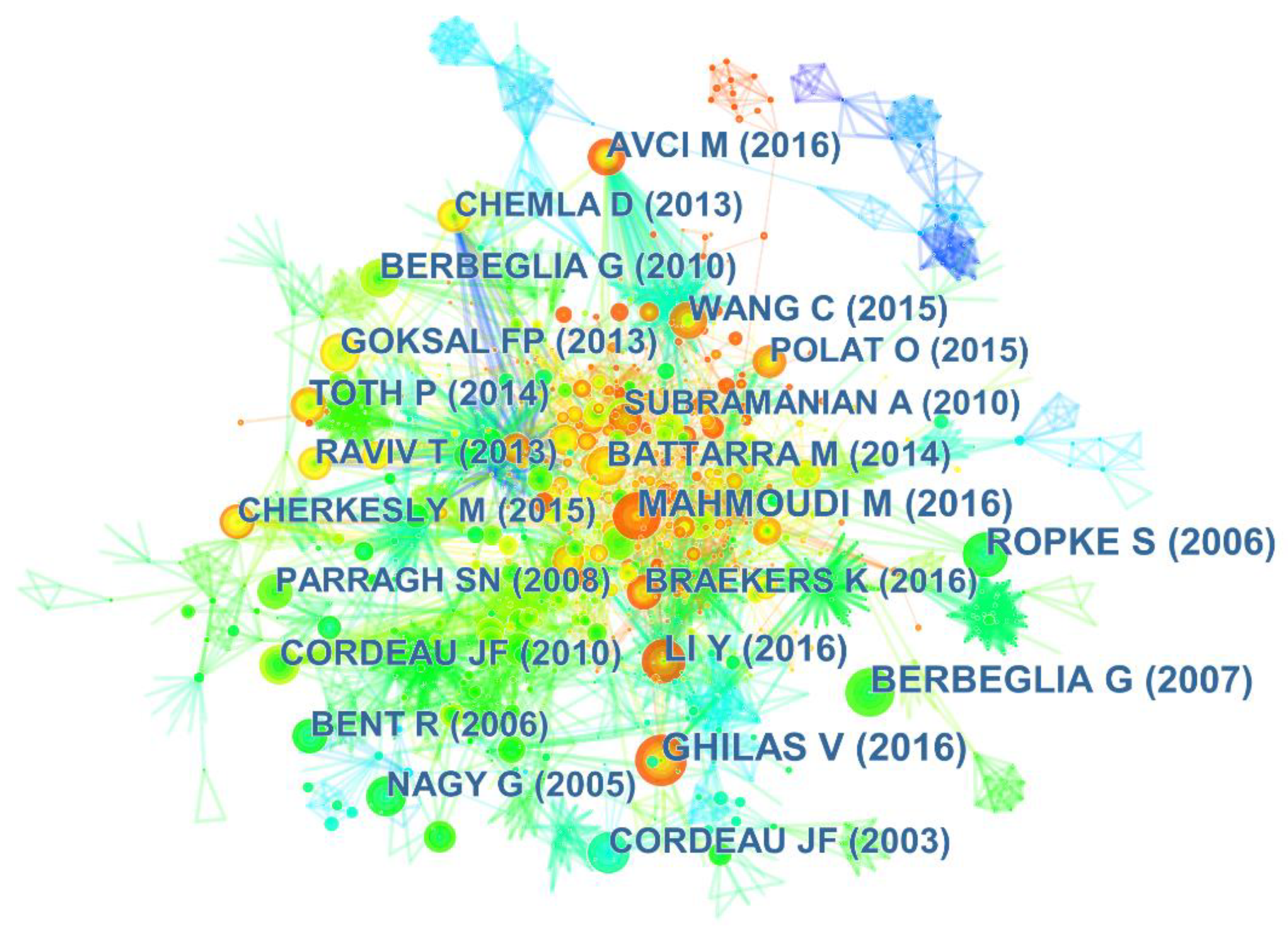
Figure 11, each node in references co-citation network denotes a reference, each link connecting two nodes denotes the co-citation relationship between two references. The larger the radius of the circle, the more frequently the reference is cited. Moreover, considering the overall density of co-citation network is only 0.0034, there may be few opportunities for co-citation between the core references because references contained in some academic documents might be from different disciplines.
Table 9 lists the top 10 high-cited documents in the research on PDP, ranking by the frequency of citations. Among them, Ropke and Pisinger [
38] first applied ALNS method to address the PDPTW with capacity constraints, which greatly motivated scholars to adopt ALNS heuristic to discover the better solution for other PDPs with different topics. For example, the top-ranked article entitled “An adaptive large neighborhood search heuristic for the Pickup and Delivery Problem with Time Windows and Scheduled Lines” [
55] analyzed the feasibility and flexibility of vehicles transport goods requested by customers in line with the predetermined routes and schedules, and an ALNS algorithm with ten removal operators and five insertion operators was proposed to generate good-quality route choice and time planning for pickup and delivery vehicles. The results of several computational experiments indicated that the implementation of scheduled line can reduce the operating costs and CO
2 emissions. Li et al. [
56] studied the PDP involving time windows, profits, and reserved requests together, which can be solved through their creative technique that the destroy/repair operator and local search procedure of ALNS running in successive segments are modified to generate the near optimal solutions.
Although the optimal solution is difficult to obtain, some researchers reformulated the PDP as a special optimization model and employed exact algorithm that matches the structure of proposed model to cope with the computational difficulties. Mahmoudi and Zhou [
57] formulated PDPTW on state–space–time transportation networks, which can be solved efficiently by utilizing Lagrangian relaxation algorithm to decompose the main problem to a sequence of time-dependent route choice problems that minimize the travel cost for each vehicle. In order to solve the PDP with LIFO loading optimally, Cordeau et al. [
58] attached valid inequalities to three correlative mathematical models, which not only increases the linear programming relaxation of these models but also integrates with branch and cut algorithm well in the calculation process.
There is an interesting phenomenon that
Table 9 lists two high-cited documents [
52,
59] related to the topic of “simultaneous pickup” and three high-cited documents [
38,
55,
56] related to the topic of “LNS”. Meanwhile, both “simultaneous pickup” and “LNS” are the current hotspots in the field of PDP as aforementioned. Therefore, as critical topics in the research on PDP, “simultaneous pickup” and “LNS” have received extensive attention from scholars and are still worthy of future research. The rest of the high-cited references in
Table 9 are mentioned in the previous section, to avoid repetition, it is not described again here.
4.5.2. Reference Co-Citation Clustering Analysis
Co-citation clustering analysis is an indispensable component of bibliometric studies. Primarily, the distribution of co-citation clusters usually represents the composition of knowledge base in a field, and the top terms included in each cluster can be regarded as the research frontiers in each knowledge domain. In addition, analyzing the co-citation clustering results over the entire time horizon can help us to perform time-series analysis of the historical development of knowledge system properly.
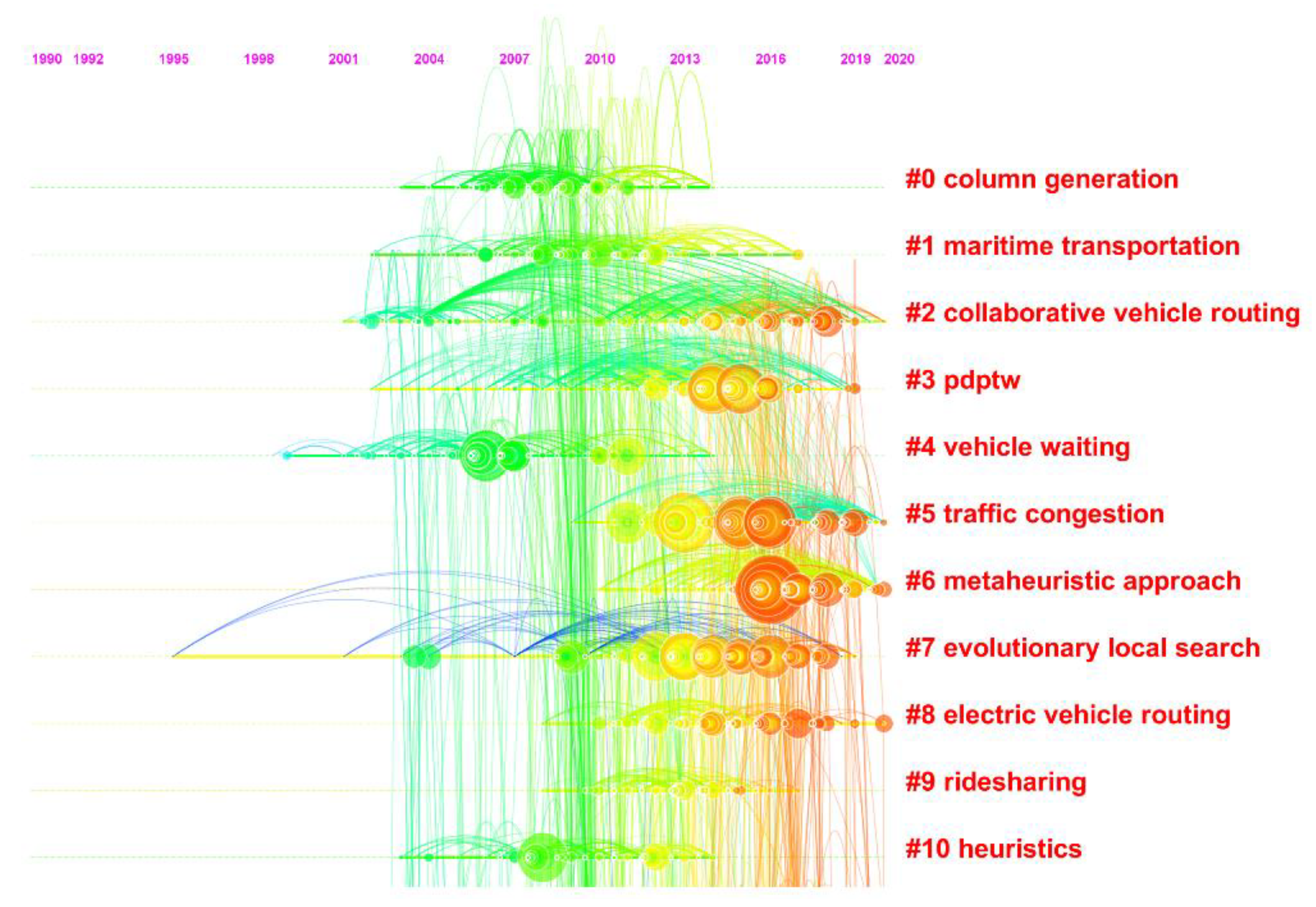
Based on the reference co-citation network as aforementioned, co-citation clusters are generated and labelled with log-likelihood ratio (LLR) weighting algorithm in CiteSpace, and the characteristics of the top 11 largest clusters are listed in
Table 10. As presented in
Table 10, cluster label is selected from the keywords by running the LLR algorithm that guarantees the label of each cluster has high uniqueness and coverage. Size means the number of documents grouped into the same cluster. Silhouette serves as an indicator to measure the level of cluster homogeneity or consistency. When the silhouette score is higher than 0.7, the results of clustering are reliable and convincing. Mean denotes the average citation year of references included in one cluster. Top terms reveal the mainstream research focuses of each cluster. In
Table 10, the silhouette scores of the top 11 largest clusters are all higher than 0.7, which implies the relevant results of clustering analysis are high-quality and reasonable.
Different from the descriptive co-citation analysis in traditional bibliometric studies, timeline/timezone visualization map of reference co-citation clusters in CiteSpace can show the chronological distribution and historical evolvement of knowledge domains more intuitively. As shown in
Figure 12, the top of the timeline visualization map displays the time when the reference was cited first, going from 1990 to 2020. The right of the timeline visualization map displays the top 11 largest co-citation clusters. References included in one cluster are represented by nodes, which are distributed on the horizontal timeline according to the year when they were first cited. Curves connecting two nodes represent the citation evolvement path of references.
As shown in
Table 10 and
Figure 12, the largest Cluster #0 (column generation) has 152 members and a silhouette score of 0.873, which mainly focuses on handling large-scale linear programming and can be well combined with exact algorithms (e.g., branch-and-cut and branch-and-price) as part of the methodology in the research on PDP. Column generation initially solves the restricted master problem considering a subset of the entire decision space, and iteratively adds additional columns that have the potential to generate a negative reduced cost to the restricted master problem until no newer columns can be included [
60]. Dumas et al. [
61] first applied column generation to formulate a pricing subproblem (i.e., shortest path problem) for the PDPTW considering precedence, capacity, and pairing constraints, where each column represents an admissible route. In addition, a label elimination algorithm was proposed to accelerate the efficiency of dynamic programming for solving this subproblem. Inspired by their work, Ropke and Cordeau [
62] introduced a branch-and-cut-and-price algorithm to address PDPTW, where the lower bound defined as the set partitioning relaxation formulation of original mixed-integer program was computed through column generation. Venkateshan and Mathur [
63] considered a kind of PDPTW in which a freight vehicle of heterogeneous fleet may need to visit a customer’s location multiple times to satisfy his all demand. To avoid the proliferation of nodes in branch-and-bound tree caused by excessive suboptimal routes developed by standard column generation, they designed an improved column generation that inhibits from regenerating the routes with the same route vectors. Nowadays, the solution algorithms based on column generation have become predominant among several exact algorithms that were developed to collect the optimal vehicle routes of many variants of PDPs.
However, with the deepening of the research contents, mathematical models with complex structure and multiple constraints impose higher requirements on the solution algorithm, the scenarios where the exact algorithms can be applied are somewhat limited. Therefore, more powerful and efficient heuristic algorithms and metaheuristics are often used by scholars in PDP research. It can be seen from
Figure 12 that both Cluster #5 (metaheuristic approach) and Cluster #10 (heuristics) have roughly undergone a decade of development, and the references related to metaheuristics have been cited frequently in recent years. In fact, metaheuristic algorithm can be interpreted as a more general method compared to the heuristic algorithm, because it is an integrated algorithm of several modular algorithms and does not depend on problem-specific conditions. Specifically, LNS and variable neighborhood search (VNS) are the two most frequently adopted heuristic algorithms in the research on PDP; metaheuristic algorithms designed to address PDPs mainly include tabu search, genetic algorithm, simulated annealing, evolutionary algorithm, and particle swarm optimization. In recent years, some scholars focused on developing more computationally efficient hybrid algorithms, and its core concept is how to properly insert part or all of an algorithm into the execution of another method. Up to now, hybrid algorithms frequently used in PDP research include hybrid LNS [
64,
65], hybrid evolutionary algorithm [
66], hybrid genetic algorithm [
44,
67], hybrid VNS or simulated annealing [
68], and hybrid metaheuristic [
46,
69,
70]. However, the hybrid algorithms are usually designed according to the characteristics of specific problem, the applicability and adaptability of them are relatively weak compared with underlying algorithms belonging to heuristics and metaheuristics.
Cluster #1 (maritime transportation) occupies the second position with 145 members, which indicates one of the real-life scenarios where the PDPs are taken seriously by logistics practitioners. In the practical transportation and packaging activities, the impact of various constraints on the carrier vehicle’s route choice behavior is not negligible. Among them, the first and most mentioned is Cluster #3 (PDPTW), many of the literatures mentioned above (e.g., [
33,
38,
55,
56,
57]) can be regarded as enriching the study of PDPTW from different perspectives. Another critical constraint considered frequently is loading operations, which means the goods must be implemented with the specified operations for loading or unloading. Bortfeldt and Wäscher [
71] conducted a comprehensive review of practically relevant loading constraints including weight limits, orientation, stacking, stability, LIFO, FIFO, and allocation, as well as summarized the contents of literatures related to how to introduce loading constraints into the model and solve them further. The current research directions related to loading constraints in PDP can be classified into two aspects: two-dimensional and three-dimensional, and the difference between them is whether packages are allowed to stack on top of each other. Fuellerer et al. [
72] developed an ant colony algorithm to analyze the strategy space for two-dimensional loading VRP, and lower bounds, heuristics, and branch-and-bounds were used to examine the feasibility of loading on each route. In terms of three-dimensional loading, Männel and Bortfeldt [
64] introduced five variants of the PDP with three-dimensional loading constraints (3L-PDP) from the perspective of routing and packing constraints discussed by Gendreau et al. [
73], including LIFO loading constraints, weight constraints, orientation constraints, and support constraints. A hybrid algorithm combining LNS with tree search was further proposed in [
64] to determine the optimal solution of aforementioned five extension models. With the above discussions, it can be found that only a few exact algorithms and heuristic algorithms have been developed for loading constraints so far.
Cluster #5 (traffic congestion) focuses on assessing the negative effects on vehicle routes and schedules caused by congestion on roads, such as economic cost, wasted time, pollution emission, and public health. Actually, traffic congestion is always time-varying, i.e., the average travel speed on routes can transition from one phase to another in an anticipated trend. Zhang et al. [
74] presented a dynamic memetic algorithm to solve the PDP considering congestion in several time windows. Cortés et al. [
75] proposed a new adaptive predictive control model for dynamic PDP, which is characterized by the hybrid consideration of additional costs caused by unknown requests and uncertain travel time caused by time-varying congestion. Because a growing number of people choose private car as their transportation, the traffic systems of some developed cities are already overburdened; hence, how to balance the benefits of capital agglomeration and the downsides of congestion is a crucial issue that needs to be taken into account in urban development. Nowadays, with the upsurge of sharing economy and intelligent transportation systems, Cluster #9 (ridesharing) is advertised as an effective and eco-friendly way to mitigate traffic congestion, and the automated matching between drivers and passengers in dynamic ridesharing system can be seen as the DARP. So far, most of the literatures related to ridesharing matching problem seeks to match drivers and riders at a higher accuracy or complete the orders of passengers with a minimum fleet scale. Zhao et al. [
76] developed a hybrid algorithm to acquire the optimal matching scheme and route choice for the ridesharing matching problem considering space-time window, flexible pickup locations, and flexible delivery locations. Meanwhile, the results of numerical experimentation showed that the introduction of flexible service strategy can increase the ratio of passengers-vehicles matching without additional system costs. Hua and Qi [
77] designed an ALNS algorithm to solve the dynamic ridesharing problem involving the redistribution of previously scheduled passengers, and found that the loss of total profit is less than 20% compared to the case where no reassignment of scheduled passengers is required.
A low-carbon non-motorized traffic mode emerging with smart payment and sharing economy is bike-sharing, which is expected to ease the traffic congestion in short-distance trips through increasing the usage of bicycles. Specifically, the research topic relevant to bike-sharing and belonging to the extensive class of PDP is termed as “bike-sharing rebalancing problem” (BRP), which attempts to determine minimum cost routes for a fleet of capacitated vehicles to redistribute bikes among stations in bike-sharing system [
78]. The research findings in this area can be divided into two main categories, namely, static situation and dynamic situation. Static situation supposes the rebalancing process occurs when the bike-sharing system is closed, that is, no consideration of the customer’s real-time demand during allocation. In contrast, dynamic rebalancing problem needs to consider the daily operational demands in bike-sharing system when redistributing bikes among stations. Ren et al. [
79] incorporated the depot inventory cost into the objective function of static bike-sharing rebalancing problem, and reformulated the whole problem into a MILP. To solve it more efficiently, they proposed an improved general VNS algorithm that integrated the improvement strategy of basic VNS algorithm with the best neighbor strategy of general VNS algorithm. Ho and Szeto [
80] formulated a revised model for static repositioning problem concerning multiple capacitated vehicles, total travel time cost, and penalty cost, which can be viewed as an in-depth exploration of the model proposed in [
81]. Meanwhile, they designed a hybrid LNS that combines tabu search with five insertion/removal operators to address revised model, and verified the proposed algorithm can obtain better results in three test sets compared with CPLEX and three-step heuristic [
82]. In dynamic case, Kloimüllner et al. [
83] proposed a dynamic BRP model considering the weighted sum objectives of unfulfilled user demands and target fill level, capacity constraints of carrier vehicle, and travel time. Caggiani and Ottomanelli [
84] developed a modular algorithm based on fuzzy decision support system to determine the optimal route choice decision, time intervals, and the quantity of bikes to be rebalanced in a dynamic system concerning rebalancing cost and user’s satisfaction level.
Cluster #2 (collaborative vehicle routing) is another manifestation of resource sharing, which refers to the providers of logistics service want to reduce transportation costs and improve logistics operation efficiency by sharing their limited logistics resources (e.g., vehicles and facilities) [
85]. Due to the increasing variety and volume of freights to be transported, classical independent distribution scenario, i.e., a single logistics provider utilizes his resources to serve all customers in the distribution area, will lead to low service quality, roundabout delivery, and high distribution price. Therefore, collaborative distribution scenario that several logistics service providers form partnerships to fulfill the orders is becoming more and more prevalent in the activities of logistics management. However, the optimal coalition structure and feasible cost allocation are two main tasks of multiple participators in collaborative vehicle routing. Wang et al. [
85] formulated the collaborative multicenter pickup and delivery problem with time windows assignment (CMPDPTW) into a bi-objective programming model, and a hybrid algorithm including k-means clustering, clarke–wright saving, and non-dominated sorting genetic algorithm-II was developed for solving it. By applying snowball theory to evaluate the stability of alliance caused by different profit allocation schemes, game quadratic programming mechanism has the highest probability of potential collaborators agreeing to join the alliance. Farvaresh and Shahmansouri [
86] proposed a hierarchical heuristic algorithm to determine the optimal coalition structure in collaborative PDPTW considering maximum cardinality constraint, and the cost allocation mechanism realized by calculating the weighted sum of contributions of collaborators, i.e., Shapely value method, was further designed for guaranteeing the fairness in allocations.
In recent years, as customer enthusiasm for electric vehicle (EV) has grown rapidly in emerging markets, logistics service providers have shown a keen interest in taking EVs into their fleets. In contrast to traditional fuel vehicle (FV), electric vehicle (EV) as a type of new energy vehicle can significantly reduce greenhouse gas emissions and operation costs in transport sector, and targeted government policies and particular public demands greatly drive the sustainable development of EV industry in global countries. However, Cluster #8 (electric vehicle routing) as an extension of the previous VRP studies involves additional non-negligible considerations while finding the optimal visit paths for electric vehicles, such as charging technology [
87], battery swapping [
88,
89], energy consumption [
90,
91], recharging strategies [
92,
93], and the capacity of charging stations [
94]. If customers in electric VRP have three types of demands, i.e., pickup, delivery, or both pickup and delivery, and EVs are dispatched to satisfy the pickup and delivery requests during a single visit, electric VRP will be reformulated into electric PDP. Masmoudi et al. [
95] developed three variants of evolutionary VNS algorithm to improve the quality of solutions of electric DARP considering battery swapping of EVs. Goeke [
96] designed a granular tabu search algorithm for solving the electric PDPTW with full or partial recharging strategy, and this method was verified to perform better than Gurobi in solution quality and running time with regard to the small-sized instance. Soysal et al. [
97] proposed a chance-constrained nonlinear programming model and its linear approximation to describe the electric PDP where the battery depletion level of electric freight vehicles follows a normal distribution. The results of computational experiment have shown that the vehicle routes obtained from approximation model are feasible in practice, especially with a large number of visited locations. Along with the overwhelming trend of EV gradually replacing FV in many areas of life, research on electric PDP and electric VRP will have broad prospects in the future.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}