
ODEM-GAN: An Object Deformation Enhancement Model Based on Generative Adversarial Networks


Abstract
:1. Introduction
- We propose ODEM-GAN, an effective object deformation enhancement model based on GAN, which focuses on the irrelevance of object deformation and scale variability to improve the prediction of hard sample probabilities and coordinates.
- In ODEM-GAN, an online deformable sample creation module and an anchor-free box prediction layer are developed. The online deformable sample creation module is to deform and augment the dataset. The anchor-free box prediction layer not only avoids accurately aligning discrete spatial anchor boxes and ground-truth boxes but also reduces the amount of calculation.
- We propose the positioning accuracy loss which reduces the bounding box’s inaccurate positioning and jitter caused by the detection of severely deformed objects in a continuous image sequence. The hard deformed samples generated by GAN can improve the regression accuracy of the object detector.
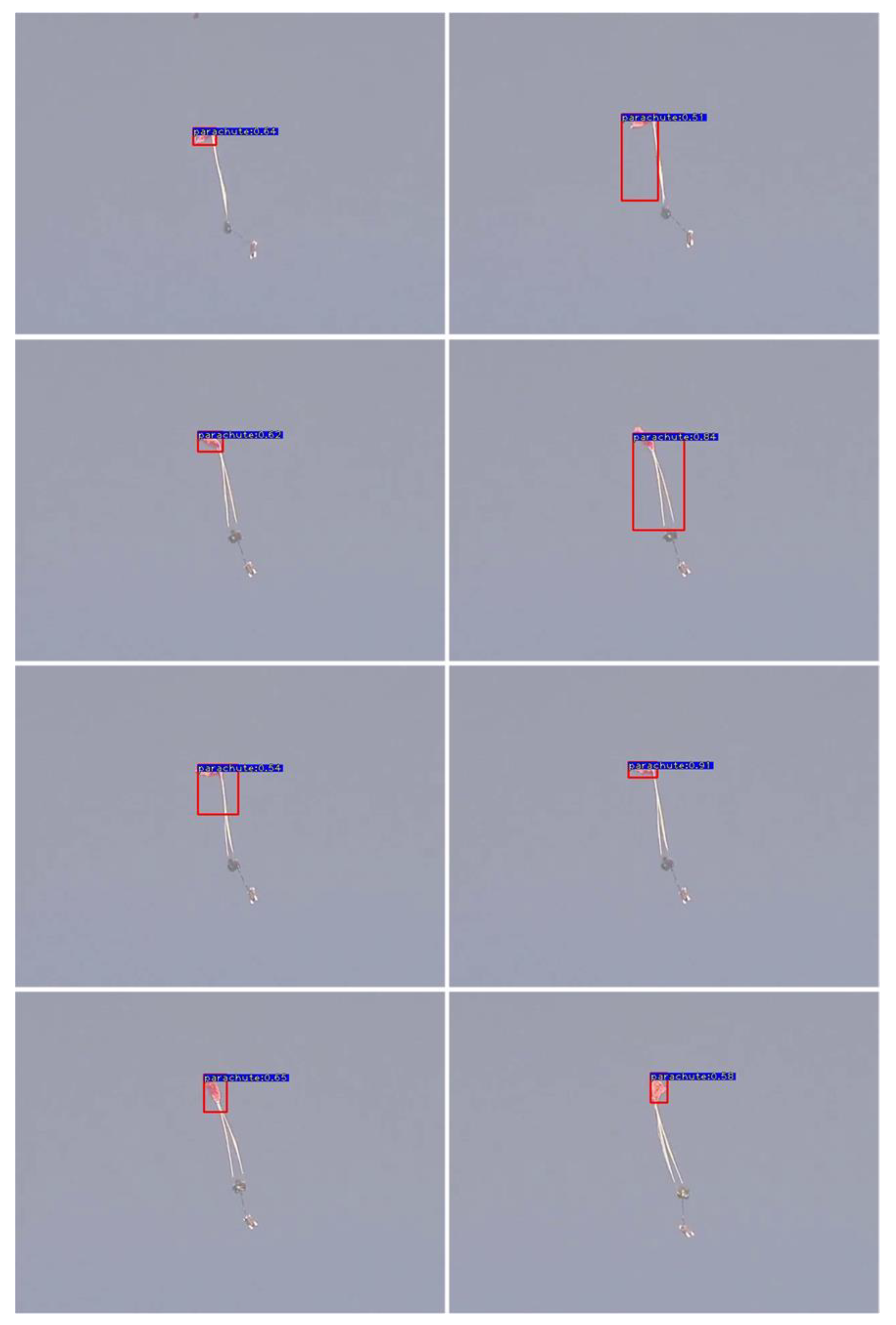
- The experimental results on the airdrop dataset show that our ODEM module has obvious advantages in object detection with severe deformation. Moreover, the experimental results on MS-COCO show that the ODEM module also has advantages for small target detection, while improving the baseline of small object detection. In addition, the method also provides a new idea for object detection to replace object tracking algorithms.
2. Related Works
2.1. Object Detection
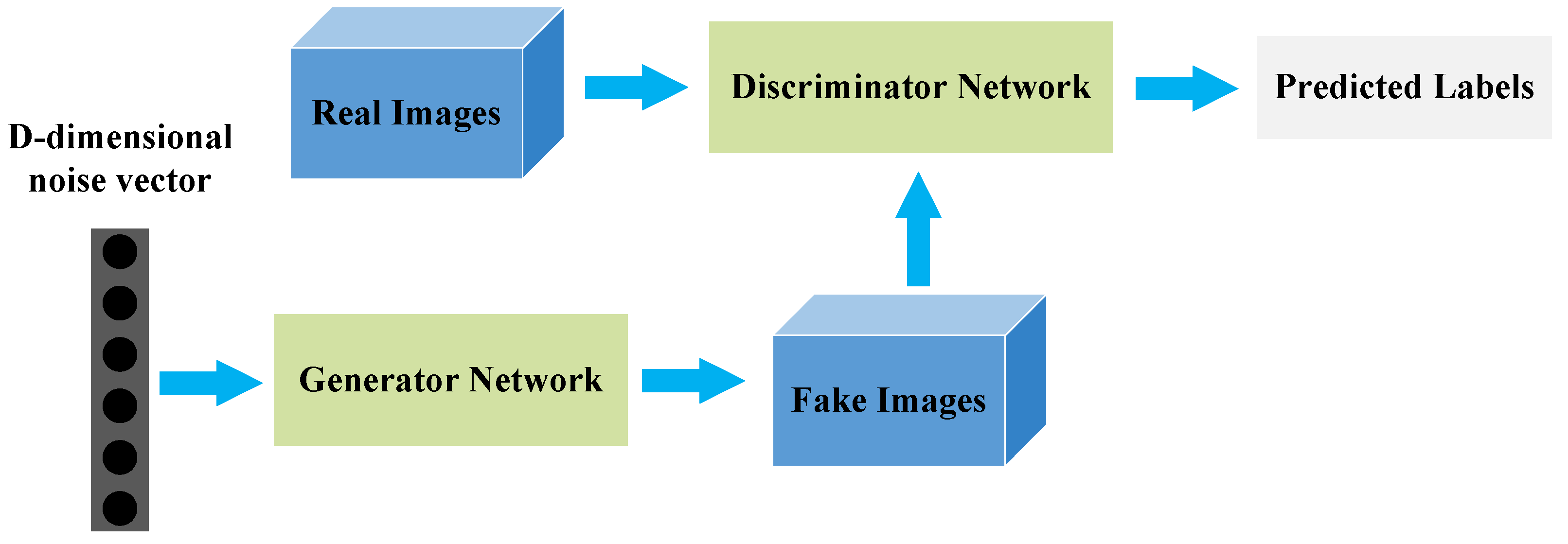
2.2. Generative Adversarial Networks
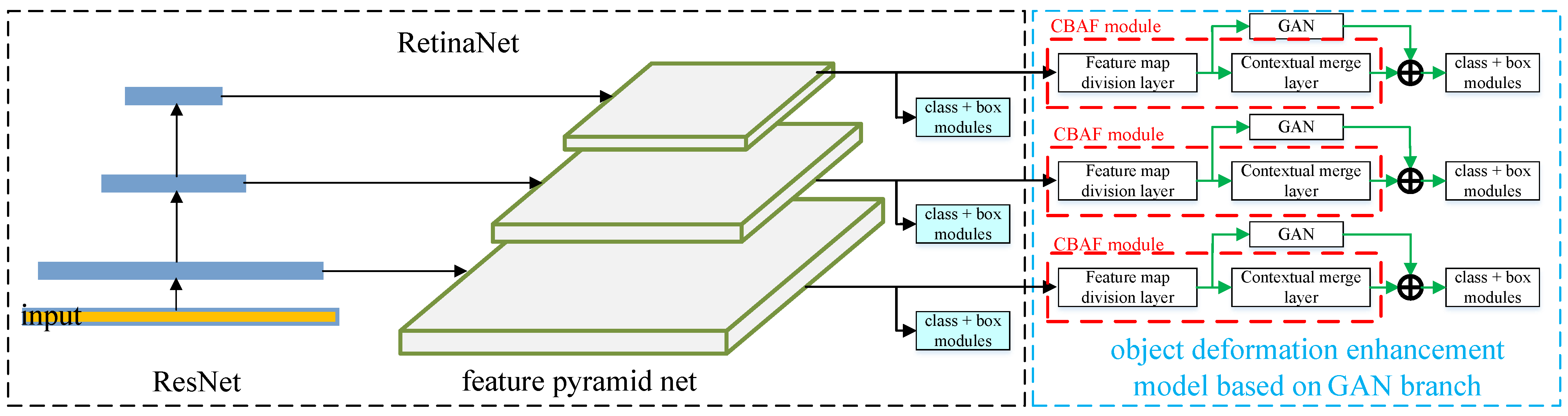
3. Approach
3.1. Overview
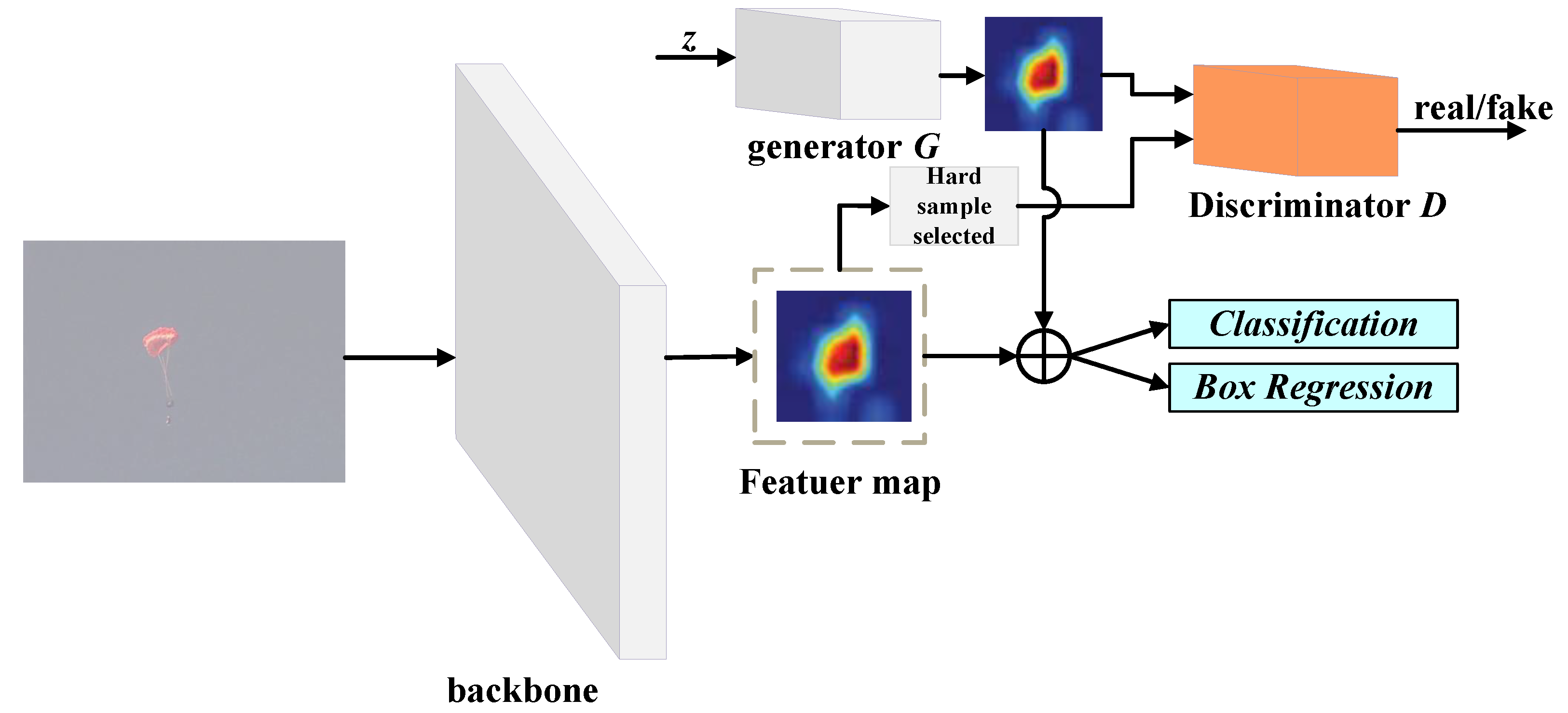
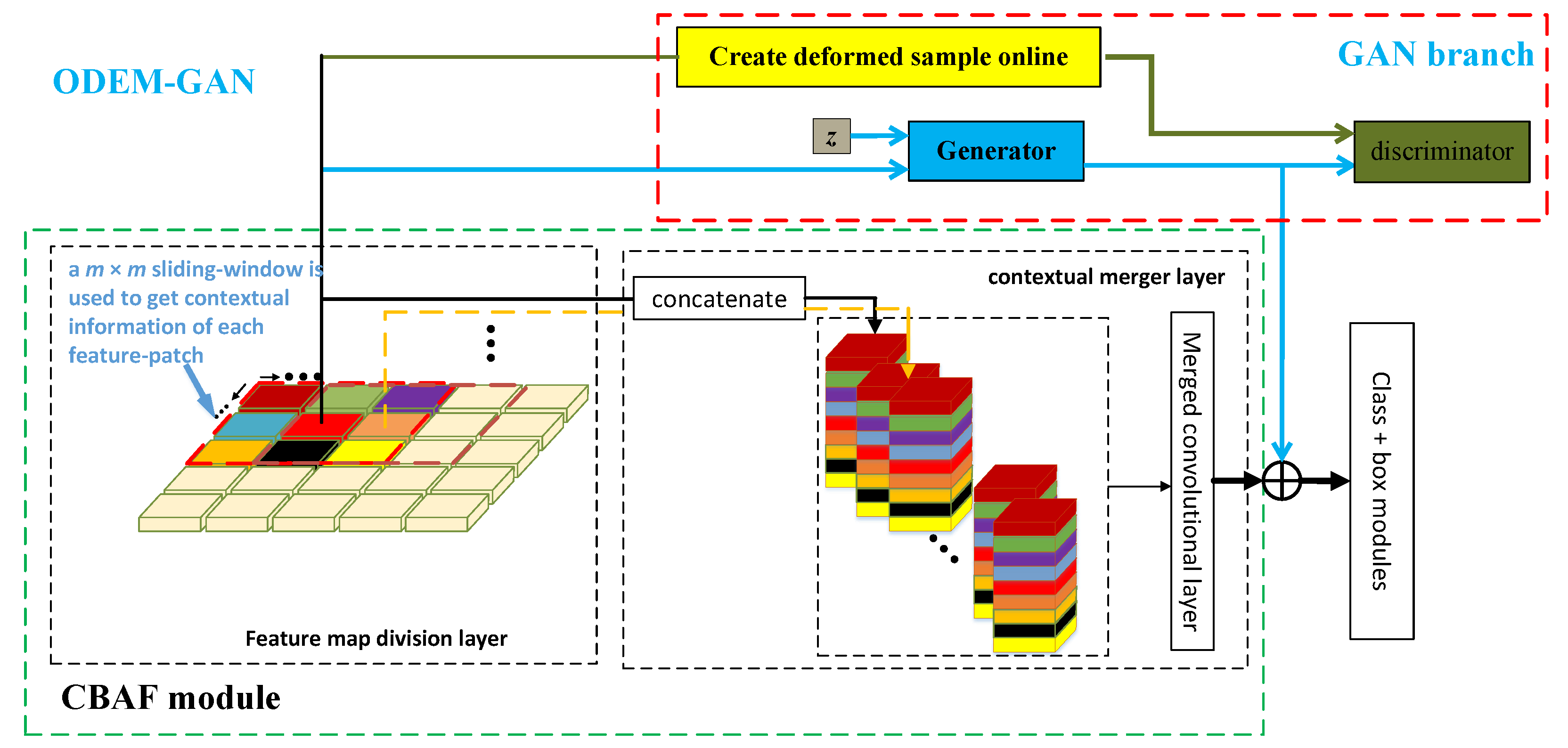
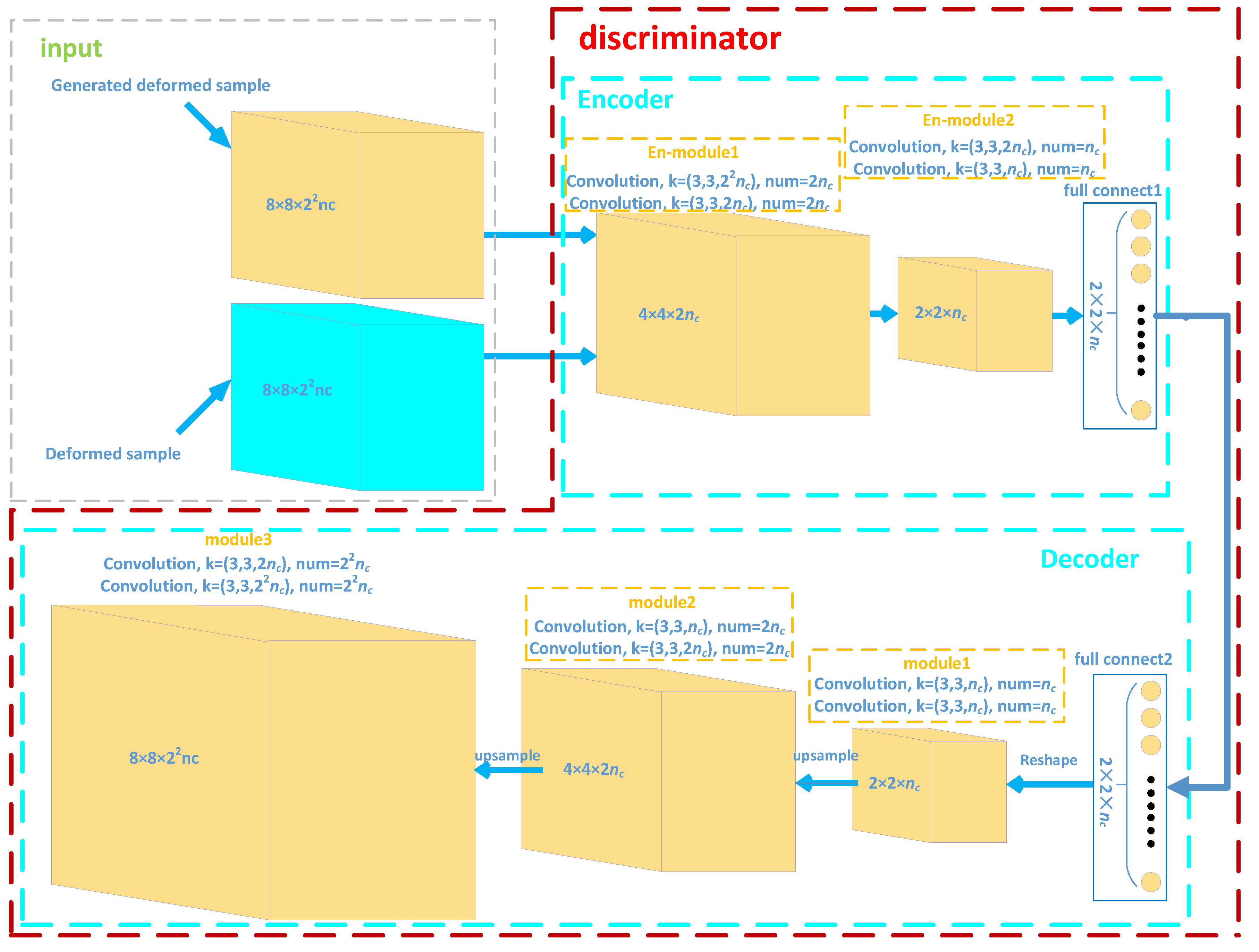
3.2. Network Architecture of the ODEM-GAN Module
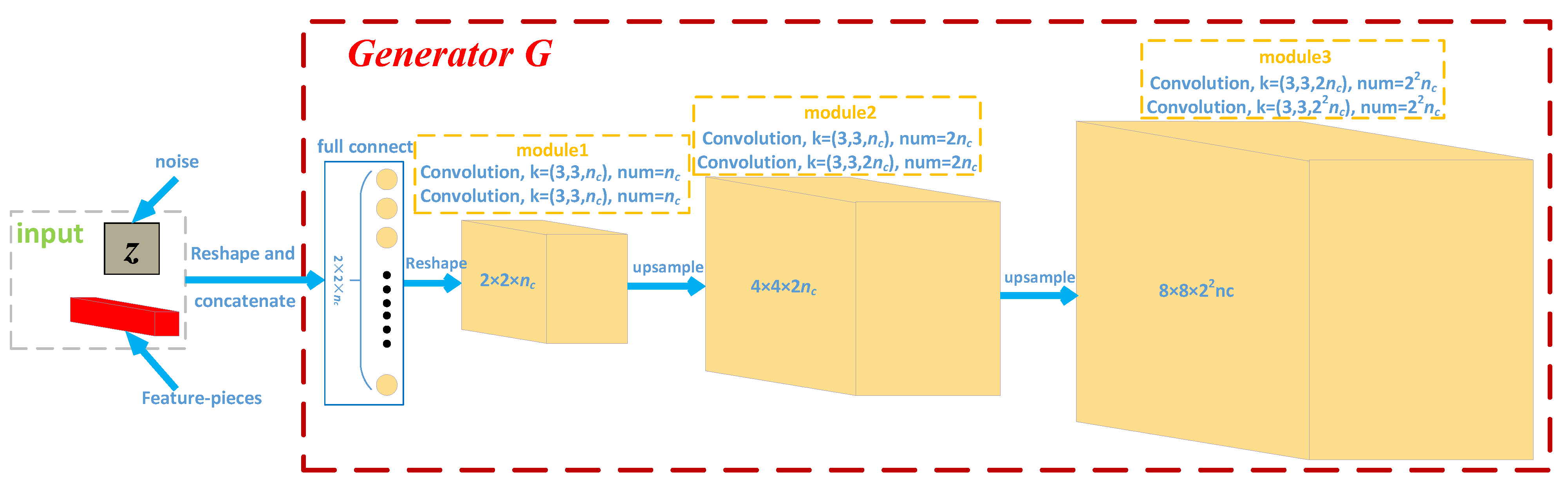
3.2.1. ODEM-GAN Module
3.2.2. Loss of the GAN Branch
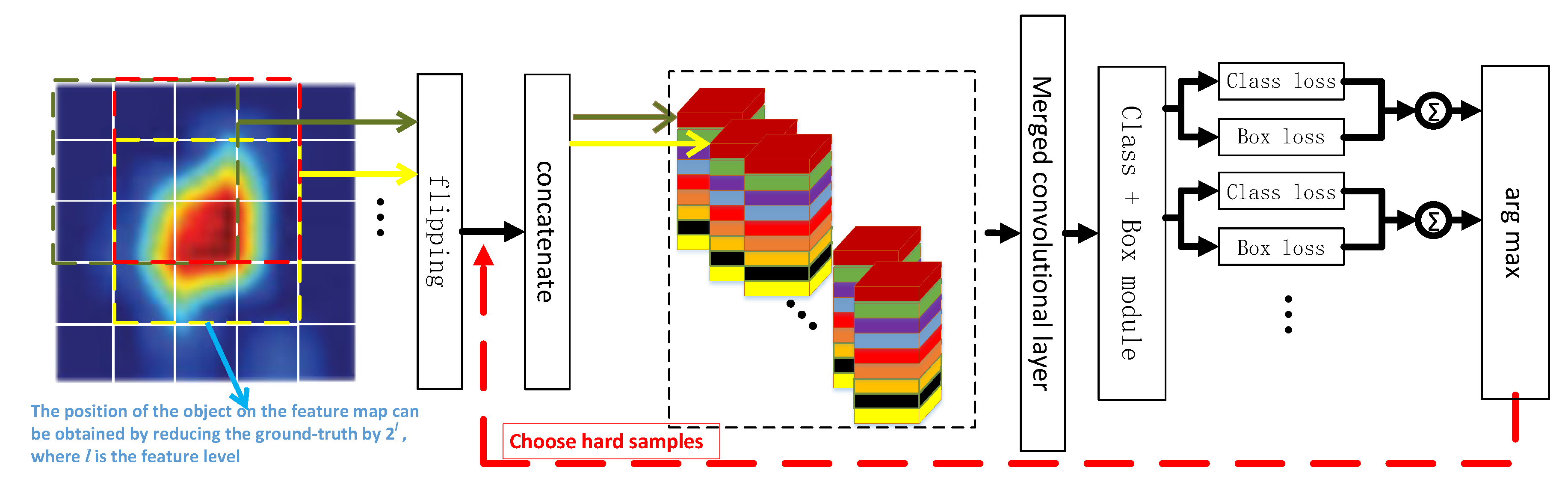
3.3. Ground Truth and Loss of the Detector
3.3.1. Classification Modules
3.3.2. Regression Modules
3.4. Joint Inference and Training
- The training dataset: a dataset that only contains specific hard deformation objects that need to be detected;
- Use the trained CBAF object detection model to extract the features of specific hard deformation objects and use the online deformable sample creation module to create various hard deformation object samples. Note: During the pretraining process of ODEM-GAN, all parameters of the CBAF object detection model are frozen and not updated;
- Minimize Formulas (6) and (8) to alternately train the discriminator and the generator (note: update the discriminator parameters first, then update the generator parameters) until the deformable samples generated by the generator are enough to be real. Throughout the pretraining process, ODEM-GAN is trained for 30 epochs using a dataset containing only specific hard deformation objects.The purpose of pretraining is to allow the ODEM-GAN module to have a preliminary understanding of specific hard deformation object samples and reduce the difficulty of joint training of the ODEM-GAN module and CBAF object detection model.
- The training set of joint training includes two parts: a dataset that only contains specific hard deformation object samples and a dataset that does not contain specific hard deformation object samples;
- Unfreeze all parameters of the CBAF object detection model and update the parameters;
- In each iteration, two images were taken from the datasets containing only specific hard deformation object samples and those without as the input of the network, so batch size = 4;
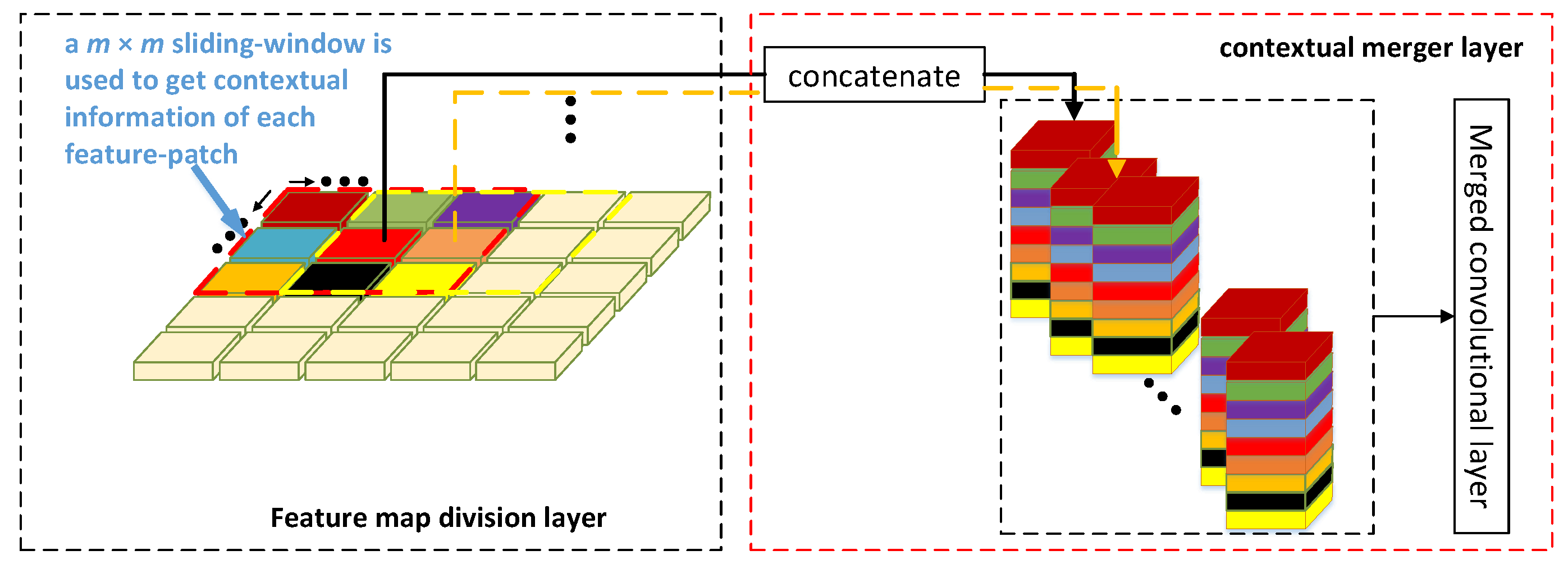
- After using the detector to extract the feature patches of the image containing specific hard deformation object samples and fuse the context information, use the training method of the pretraining process to update the parameters of the ODEM-GAN;
- Use the generator of ODEM-GAN to generate deformable samples of specific objects;
- Use the detector to extract feature patches that do not contain specific hard deformation object images and fuse context information;
- Place the fused feature patches of the specific hard deformation object images extracted by the detector, the fused contextual feature patches that do not contain the specific hard deformation object images, and the specific hard deformation object samples generated by ODEM-GAN together as a batch. Then, they are taken together as input to the classification and regression modules, and the optimizer is directly used to update the network parameters of the CBAF object detection model. Note that if the other specific category is changed, the GAN branch must be retrained.
4. Experiments
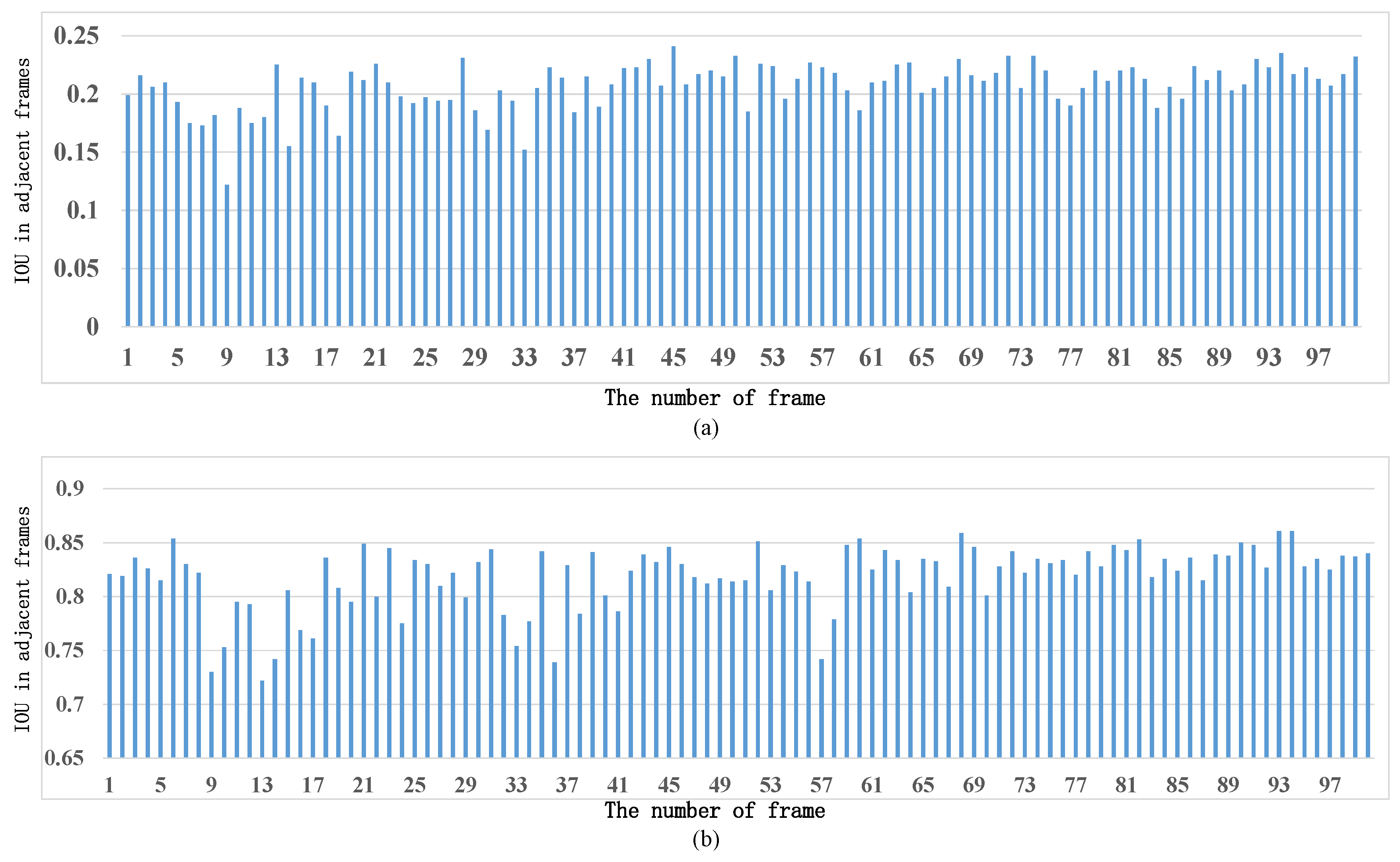
4.1. Ablation Studies
4.2. Determination of Hyperparameters
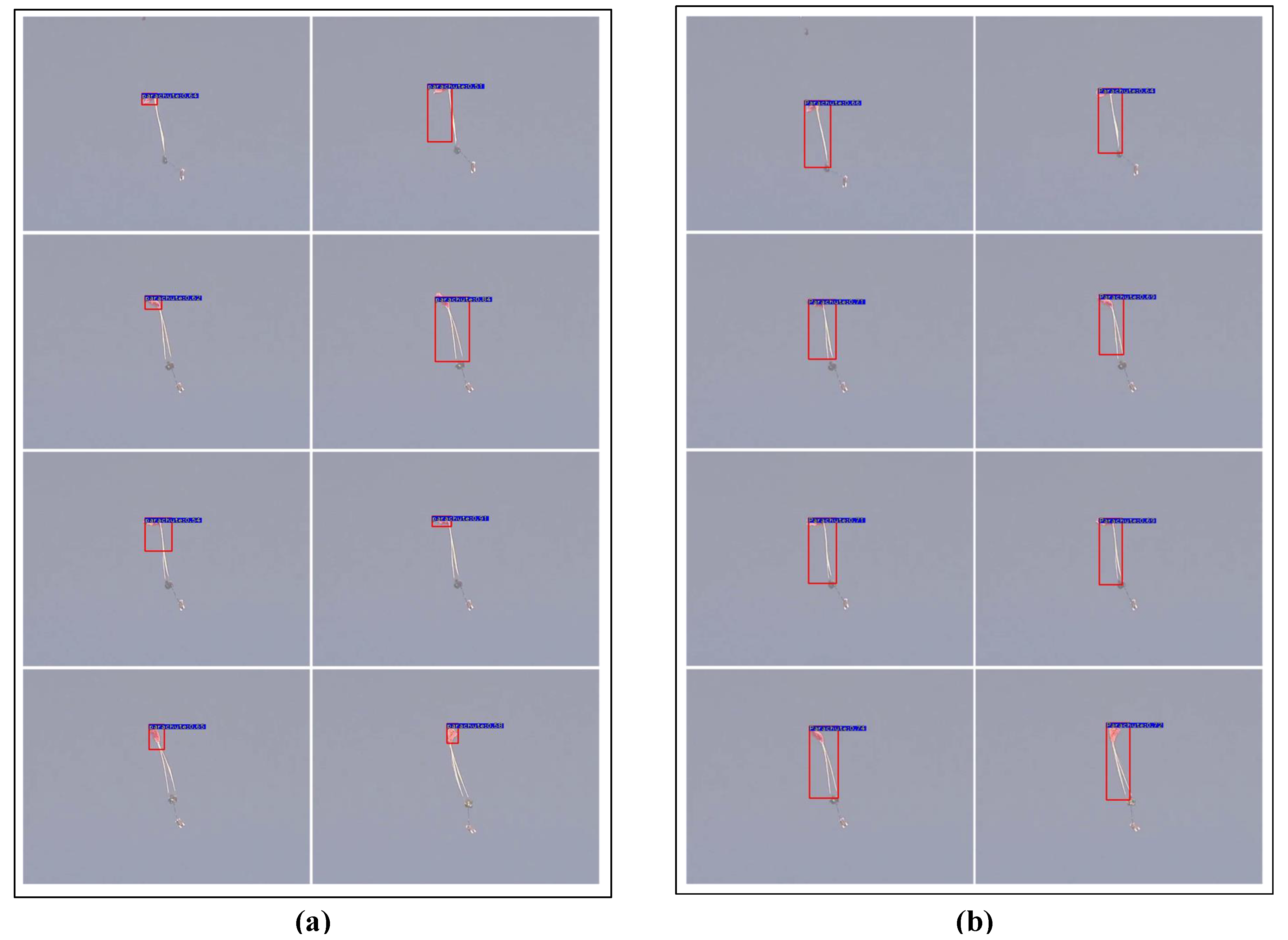
4.3. Results on PASCAL VOC 2012
4.4. Comparison to State of the Art
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Everingham, M.; Zisserman, A.; Williams, C.K.; Van Gool, L.; Allan, M.; Bishop, C.M.; Chapelle, O.; Dalal, N.; Deselaers, T.; Dorkó, G.; et al. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results. 2008. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.230.2543 (accessed on 25 March 2022).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Fischer, P.; Dosovitskiy, A.; Brox, T. Descriptor matching with convolutional neural networks: A comparison to sift. arXiv 2014, arXiv:1405.5769. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Detnet: A backbone network for object detection. arXiv 2018, arXiv:1804.06215. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar]
- Long, J.L.; Zhang, N.; Darrell, T. Do convnets learn correspondence? Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 761–769. [Google Scholar]
- Takác, M.; Bijral, A.; Richtárik, P.; Srebro, N. Mini-batch primal and dual methods for SVMs. In Proceedings of the International Conference on Machine Learning (PMLR), Atlanta, GA, USA, 17–19 June 2013; pp. 1022–1030. [Google Scholar]
- Tang, Z.; Yang, J.; Pei, Z.; Song, X. Coordinate-based anchor-free module for object detection. Appl. Intell. 2021, 51, 9066–9080. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Huang, L.; Yang, Y.; Deng, Y.; Yu, Y. Densebox: Unifying landmark localization with end to end object detection. arXiv 2015, arXiv:1509.04874. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Chen, Y.; Song, L.; Hu, Y.; He, R. Adversarial occlusion-aware face detection. In Proceedings of the 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), Redondo Beach, CA, USA, 22–25 October 2018; pp. 1–9. [Google Scholar]
- Wang, X.; Shrivastava, A.; Gupta, A. A-fast-rcnn: Hard positive generation via adversary for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2606–2615. [Google Scholar]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual generative adversarial networks for small object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1222–1230. [Google Scholar]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. Sod-mtgan: Small object detection via multi-task generative adversarial network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 206–221. [Google Scholar]
- Berthelot, D.; Schumm, T.; Metz, L. Began: Boundary equilibrium generative adversarial networks. arXiv 2017, arXiv:1703.10717. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2874–2883. [Google Scholar]
- Vinukonda, P. A Study of the Scale-Invariant Feature Transform on a Parallel Pipeline. Master’s Thesis, Louisiana State University, Baton Rouge, LA, USA, 2011. [Google Scholar]
- Yang, Z.; Xu, Y.; Xue, H.; Zhang, Z.; Urtasun, R.; Wang, L.; Lin, S.; Hu, H. Dense reppoints: Representing visual objects with dense point sets. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 227–244. [Google Scholar]
- Duan, K.; Xie, L.; Qi, H.; Bai, S.; Huang, Q.; Tian, Q. Corner proposal network for anchor-free, two-stage object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 399–416. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Yao, L.; Xu, H.; Zhang, W.; Liang, X.; Li, Z. SM-NAS: Structural-to-modular neural architecture search for object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12661–12668. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Wang, S.; Gong, Y.; Xing, J.; Huang, L.; Huang, C.; Hu, W. RDSNet: A new deep architecture forreciprocal object detection and instance segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12208–12215. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Li, L.H.; Zhang, P.; Zhang, H.; Yang, J.; Li, C.; Zhong, Y.; Wang, L.; Yuan, L.; Zhang, L.; Hwang, J.N.; et al. Grounded Language-Image Pre-training. arXiv 2021, arXiv:2112.03857. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Fang, Y.; Yang, S.; Wang, X.; Li, Y.; Fang, C.; Shan, Y.; Feng, B.; Liu, W. Instances as queries. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6910–6919. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. You only learn one representation: Unified network for multiple tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7363–7372. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6569–6578. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. Foveabox: Beyound anchor-based object detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. Brief: Binary robust independent elementary features. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 778–792. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Output Size (Height, Width, Channel) | Act. | Layer (Filter_h, Filter_w, Num, Stride) | |
|---|---|---|---|---|
| feature-patch + z | (128, -, -) | - | - | |
| full connect layer | (2 × 2 × , -, -) | - | - | |
| module1 | conv1 | (2, 2, ) | Relu | (3, 3, , 1) |
| conv2 | (2, 2, ) | Relu | (3, 3, , 1) | |
| module2 | conv1 | (4, 4, 2) | Relu | (3, 3, 2, 1) |
| conv2 | (4, 4, 2) | Relu | (3, 3, 2, 1) | |
| module3 | conv1 | (8, 8, ) | Relu | (3, 3, , 1) |
| conv2 | (8, 8, ) | - | (3, 3, , 1) | |
| Name | Output Size (Height, Width, Channel) | Act. | Layer (Filter_h, Filter_w, Num, Stride) | |
|---|---|---|---|---|
| (8, 8, 22) | Provided by generator and online deformable sample creation module | |||
| en-module1 | conv1 | (8, 8, 2) | Relu | (3, 3, 2, 1) |
| conv2 | (4, 4, 2) | Relu | (3, 3, 2, 2) | |
| en-module2 | conv1 | (4, 4, ) | Relu | (3, 3, , 1) |
| conv2 | (2, 2, ) | Relu | (3, 3, , 2) | |
| full connect layer1 | (, -, -) | - | - | |
| full connect layer1 | (, -, -) | - | - | |
| conv1 | (2, 2, ) | Relu | (3, 3, , 1) | |
| conv2 | (2, 2, ) | Relu | (3, 3, , 1) | |
| conv1 | (4, 4, 2) | Relu | (3, 3, 2, 1) | |
| conv2 | (4, 4, 2) | Relu | (3, 3, 2, 1) | |
| conv1 | (8, 8, ) | Relu | (3, 3, , 1) | |
| conv2 | (8, 8, ) | - | (3, 3, , 1) | |
| Name | Output Size (Height, Width, Channel) | Act. | Layer (Filter_h, Filter_w, Num, Stride, Padding) | |
|---|---|---|---|---|
| classification module | class_conv1 | (8, 8, 256) × 64 | ReLU | (3, 3, 256, 1, 1) |
| class_conv2 | (8, 8, 256) × 64 | ReLU | (3, 3, 256, 1, 1) | |
| class_conv3 | (8, 8, 256) × 64 | ReLU | (3, 3, 256, 1, 1) | |
| class_conv4 | (8, 8, 256) × 64 | ReLU | (3, 3, 256, 1, 1) | |
| class_output | (8, 8, K) × 64 | Sigmoid | (3, 3, K, 1, 1) | |
| regression module | regress_conv1 | (8, 8, 256) × 64 | ReLU | (3, 3, 256, 1, 1) |
| regress_conv2 | (8, 8, 256) × 64 | ReLU | (3, 3, 256, 1, 1) | |
| regress_conv3 | (8, 8, 256) × 64 | ReLU | (3, 3, 256, 1, 1) | |
| regress_conv4 | (8, 8, 256) × 64 | ReLU | (3, 3, 256, 1, 1) | |
| regress_output | (8, 8, K) × 64 | - | (3, 3, 4, 1, 1) | |
| 1st | ODEM-GAN | Generator Addition Conditions | Loss of Positioning Accuracy | AP (%) |
|---|---|---|---|---|
| 2nd | no | - | - | 84.8 |
| 3rd | yes | no | no | 76.4 |
| 4th | yes | yes | no | 85.1 |
| 5th | yes | yes | yes | 88.4 |
| 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | |
| AP | 35.6 | 36.3 | 36.5 | 36.7 | 36.9 | 36.4 | 36.3 | 36.1 | 35.7 |
| 0.02 | 0.04 | 0.06 | 0.08 | 0.1 | 0.12 | 0.14 | 0.16 | 0.18 | |
| AP (parachute) | 85.1 | 85.5 | 86.3 | 87.3 | 88.4 | 88.0 | 86.3 | 84.2 | 83.4 |
| Object | RetinaNet | CBAF | ODEM-GAN |
|---|---|---|---|
| mAP | 73.8 | 75.1 | 76.8 |
| aero | 85.3 | 86.8 | 87.5 |
| bike | 79.2 | 80.6 | 82.8 |
| bird | 76.9 | 78.2 | 79.5 |
| boat | 59.9 | 62.1 | 66.2 |
| bottle | 50.8 | 51.6 | 58.1 |
| bus | 80.9 | 82 | 83.2 |
| car | 73.3 | 75 | 77.1 |
| cat | 93.9 | 94 | 94 |
| chair | 56.5 | 59.1 | 60 |
| cow | 80.1 | 81 | 83 |
| table | 60.2 | 62.1 | 62.5 |
| dog | 89 | 89.9 | 89.9 |
| horse | 85.8 | 87 | 88.5 |
| mbike | 84.8 | 85.4 | 85.9 |
| person | 78.6 | 80 | 82.3 |
| plant | 45.6 | 47.2 | 50.1 |
| sheep | 71.3 | 72.3 | 74.3 |
| sofa | 70.6 | 71 | 75.6 |
| train | 82.6 | 83.2 | 83 |
| tv | 70.9 | 72.7 | 74 |
| Methods | Backbone | ||||||
|---|---|---|---|---|---|---|---|
| DINO [43] | ResNet-50 | 50.2 | 68 | 54.7 | 32.8 | 53 | 64.8 |
| YOLOR-D6 [47] | YOLOv4-P6-light | 52.5 | 70.5 | 57.6 | 37.1 | 57.2 | 65.4 |
| YOLOv4 [35] | CSPDarknet-53 | 41.2 | 62.8 | 44.3 | 20.4 | 44.4 | 56 |
| CPN [38] | DLA-34 | 41.7 | 58.9 | 44.9 | 20.2 | 44.1 | 56.4 |
| EfficientDet-D2 [39] | Efficient-B2 | 43 | 62.3 | 46.2 | 22.5 | 47 | 58.4 |
| DETR [41] | Transformer | 43.5 | 63.8 | 46.4 | 21.9 | 48 | 61.8 |
| SM-NAS: E2 [40] | - | 40 | 58.2 | 43.4 | 21.1 | 42.4 | 51.7 |
| CenterNet [49] | Hourglass-104 | 44.9 | 62.4 | 48.1 | 25.6 | 47.4 | 57.4 |
| DINO [43] | Swin-T | 63.3 | 80.8 | 69.9 | 46.7 | 66 | 76.5 |
| DyHead [45] | Swin-T | 49.7 | 68 | 54.3 | 33.3 | 54.2 | 64.2 |
| GLIP [44] | Swin-T | 61.5 | 79.5 | 67.7 | 45.3 | 64.9 | 75 |
| QueryInst [46] | Swin-T | 49.1 | 74.2 | 53.8 | 31.5 | 51.8 | 63.2 |
| RDSNet [42] | ResNet-101 | 38.1 | 58.5 | 40.8 | 21.2 | 41.5 | 48.2 |
| CBAF [22] | ResNet-101 | 40.9 | 60.2 | 43.2 | 22.5 | 43.3 | 50.4 |
| DyHead [45] | ResNet-101 | 46.5 | 64.5 | 50.7 | 28.3 | 50.3 | 57.5 |
| QueryInst [46] | ResNet-101 | 42.8 | 65.6 | 46.7 | 24.6 | 45 | 55.5 |
| our (RetinaNet + ODEM-GAN) | ResNet-101 | 41.3 | 60.5 | 43.2 | 24.8 | 43.3 | 51.4 |
| Grid R-CNN w/FPN [48] | ResNeXt-101 | 43.2 | 63 | 46.6 | 25.1 | 46.5 | 55.2 |
| Dense RepPoints [37] | ResNeXt-101 | 40.2 | 63.8 | 43.1 | 23.1 | 43.6 | 52 |
| FoveaBox [50] | ResNeXt-101 | 42.1 | 61.9 | 45.2 | 24.9 | 46.8 | 55.6 |
| RetinaNet [7] | ResNeXt-101 | 40.8 | 61.1 | 44.1 | 24.1 | 44.2 | 51.2 |
| CBAF [22] | ResNeXt-101 | 43 | 63.2 | 46.3 | 25.9 | 45.6 | 51.4 |
| DyHead [45] | ResNeXt-101 | 47.7 | 65.7 | 51.9 | 31.5 | 51.7 | 60.7 |
| QueryInst [46] | ResNeXt-101 | 44.6 | 68.1 | 48.7 | 26.6 | 46.9 | 57.7 |
| our (RetinaNet + ODEM-GAN) | ResNeXt-101 | 43.2 | 63.4 | 46.8 | 27.9 | 45.6 | 52.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Pei, Z.; Tang, Z.; Gu, F. ODEM-GAN: An Object Deformation Enhancement Model Based on Generative Adversarial Networks. Appl. Sci. 2022, 12, 4609. https://doi.org/10.3390/app12094609
Zhang Z, Pei Z, Tang Z, Gu F. ODEM-GAN: An Object Deformation Enhancement Model Based on Generative Adversarial Networks. Applied Sciences. 2022; 12(9):4609. https://doi.org/10.3390/app12094609
Chicago/Turabian StyleZhang, Zeyang, Zhongcai Pei, Zhiyong Tang, and Fei Gu. 2022. "ODEM-GAN: An Object Deformation Enhancement Model Based on Generative Adversarial Networks" Applied Sciences 12, no. 9: 4609. https://doi.org/10.3390/app12094609
APA StyleZhang, Z., Pei, Z., Tang, Z., & Gu, F. (2022). ODEM-GAN: An Object Deformation Enhancement Model Based on Generative Adversarial Networks. Applied Sciences, 12(9), 4609. https://doi.org/10.3390/app12094609